[논문 리뷰] Improving Language Understanding by Generative Pre-Training (GPT-1) (2018)
Paper Review

From OpenAI Research, June 2018
0. Abstract
- NLU(자연어 이해: NLP의 하위 집합)는 Textual Entailment(의미적 포함관계 판단), QA, 문서 분류, 의미 유사성 평가 등 광범위한 작업들로 구성된다.
- 이러한 작업들에서 unlabelled된 데이터는 풍부하지만 labelled된 데이터는 부족하므로, Discriminative(분류) task에 특화된 모델은 적절한 성능을 보여주기 힘들다.
- 따라서 우리는 unlabelled된 방대한 텍스트에 대해 generative하게 pre-train한 다음, 각 다운 스트림 작업에 대해 discriminative 하게 fine-tuning 함으로써 각 작업들에 대해 큰 성능 이득을 볼 수 있음을 보여준다.
- (각 작업마다로의) 모델 변경을 최소화하기 위해 fine-tuning 중에 Task-aware input transformation을 사용
- 각 작업에 맞게 input structure를 변환하는 방식
- NLU의 여러 벤치마크에서 우리가 제안하는 방식의 효율성을 검증한다.
- 일반 GPT모델(특정 작업에 fine-tuned되지 않은)이 다른 fine-tuned된 discriminative 모델들보다 더 성능이 좋다.
- 실험한 12개 task 중 9개 작업에서 SOTA 달성
1. Introduction
-
Raw Text로부터 효과적으로 학습하는 것은 지도 학습에 대한 의존도를 낮추기 위해 매우 중요하다.
-
많은 딥러닝 방법에서는 labelled 데이터가 필요하므로, 데이터가 부족한 분야에서의 적용이 제한된다.
- 따라서 labelled되지 않은 언어 데이터를 사용할 수 있는 모델은 좋은 대안이 된다.
- 라벨을 다는데 필요한 시간, 비용이 들지 않으므로
- 따라서 labelled되지 않은 언어 데이터를 사용할 수 있는 모델은 좋은 대안이 된다.
-
또한, 지도 학습이 가능한 많은 경우들에도 비지도 학습으로 좋은 표현(representations)을 학습할 경우 많은 성능 향상을 이룰 수 있다.
- 가장 강력한 증거) NLP 작업들의 성능을 높이기 위해서 1) 비지도 데이터셋을 사전학습한 뒤, 2) 구체적인 지도학습 NLP 작업에 다시 적용되는 방식으로 사용됨
-
그러나 라벨이 없는 데이터에서 단어 수준 이상의 정보를 활용하는 것은 두 가지 이유로 어려움
- 1) 전이 학습에 유용한 최적화(optimization) 목적이 무엇인지 불분명하다.
- 최근 연구들은 다양한 최적화 목적들(언어 모델링, 기계 번역, 담화 일관성(discourse coherence) 등)에서 서로의 모델이 각 작업에서 다른 모델보다 성능이 뛰어나다.
- 2) 이러한 학습된 표현을 target task로 전이(transfer)하는 가장 효과적인 방법이 무엇인가에 대한 합의(consensus)가 없다.
- 1) 전이 학습에 유용한 최적화(optimization) 목적이 무엇인지 불분명하다.
-
이런 불확실성은 자연어처리를 위한 준지도(semi-supervised) 접근법을 개발하는 것을 어렵게 한다.
-
이 논문은 Language Understanding tasks에 대해, 비지도 학습 방식과 fine-tuning 지도학습 방식을 결합한 준지도 학습 방식을 연구한다.
- 많은 작업들에 대해서 모델의 큰 수정없이 전이학습이 가능한 universal한 representation을 만드는 것이 목표이다.
-
제안하는 모델은 2단계의 학습 절차를 사용한다.
- 1) 네트워크의 초기 파라미터를 학습하기 위해 unlabelled data를 language modeling optimization을 사용하여 학습
- 2) 이후, 학습된 파라미터를 supervised한 대상 작업에 적용한다.
-
모델의 아키텍처는 Transformer를 기반으로 한다.
- Transformer는 장기 종속성을 처리하기 위한 구조를 갖고 있으며, 다양한 작업에서 전이학습을 통해 좋은 성능을 달성한다.
- 모델의 구조를 최소한으로 변경하면서 효과적으로 fine-tuning할 수 있다.
-
모델 평가는 4가지 종류의 Language Understanding tasks에 대해 이뤄진다.
- NLI(Natural Language Inference, 자연어 추론), QA(Question Answering, 질의응답), Sementic Similarity(의미 유사성), Text Classification(텍스트 분류)
-
12개 task 중 9개 task에서 SOTA 달성
-
또한, 4가지 서로 다른 setting으로 pre-trained된 모델의 zero-shot 동작을 분석해, 다운스트림 작업에 유용한 언어적 지식을 획득한다는 것을 확인했다.
2. Related Work
- Semi-supervised learning for NLP (NLP에서의 준지도 학습)
- 자연어 처리에서의 준지도 학습은 초기 방식과 최근 접근 방식이 다르다.
- 초기에는 라벨이 없는 데이터로부터 단어 수준이나 구문(phrase) 수준의 통계를 계산하고, 이를 지도학습 모델의 feature로 사용하는 수준에 그친다.
- 최근에는, 라벨이 없는 코퍼스에서 훈련된 워드 임베딩을 사용하여 다양한 task의 성능을 향상시키는데 중점을 둔다.
- 그러나 이러한 접근법은 주로 단어 수준의 정보를 전달하는데, 우리는 더 높은 수준(구문, 문장 이상)의 의미를 포착하고자 한다.
- 최근에는 라벨이 없는 데이터에서 단어 수준 이상의 의미를 학습하는 방법을 연구한다.
- Unsupervised pre-training (비지도 사전학습)
- 비지도 사전학습은 준지도 학습의 특별한 형태이다.
- 초기에는 이미지 분류 및 회귀 작업에서 연구되었고, 이어진 연구에서는 사전 훈련이 정규화처럼 작용해서 Deep Neural Network에서 더 나은 일반화가 가능하다는 사실이 증명됐다.
- 최근에는 다양한 작업에서 DNN을 훈련하는데 사용되었다.
- GPT와 가장 가까운 연구: 언어 모델링 목표를 통해 사전훈련한 뒤, supervised하게 target task에 fine tuning 하는 것
- 사전 훈련을 하는 것이 언어 정보를 포착하는 데 도움이 되지만, LSTM을 사용할 경우 예측 능력이 short range로 제한된다.
- Transformer를 사용할 경우 더 긴 range의 언어 구조를 포착할 수 있음을 실험으로 보여준다.
- 다른 접근법들은 사전 훈련된 모델의 representation을 각 작업에서의 보조 feature로 사용하여 supervised 모델을 학습시킨다.
- 하지만 이는 각각의 대상 작업마다 많은 양의 파라미터를 필요로 한다.
- 반면, GPT는 전이학습 과정에서 모델 아키텍처에 최소한의 변경만이 필요하다.
- Auxiliary training objectives (보조 학습 목표)
- 보조 비지도 학습 목표를 추가하는 것은 준지도 학습의 대안적인 형태이다.
- (라벨이 없는 데이터에 추가적인 학습 목표를 설정해서 모델 성능을 향상시키는 방법)
- 초기 연구에서는 다양한 NLP 작업들(POS 태깅 등)을 보조 작업으로 사용하여 라벨링 성능을 향상시켰다.
- GPT도 보조 학습 목표를 사용하지만, 비지도 사전훈련이 이미 target task에 대한 여러 언어적인 측면을 미리 학습한다는 것을 실험을 통해 보여준다.
- (GPT의 접근 방식은 기존과 달리 비지도 사전훈련을 통해 이미 다양한 언어 지식을 얻으며, 이는 곧 성능 향상으로 이어짐)
- 보조 비지도 학습 목표를 추가하는 것은 준지도 학습의 대안적인 형태이다.
3. Framework
- 훈련은 2단계로 구성됨
- 1) 대규모 corpus로 대용량 언어 모델을 학습하는 단계
- 2) labelled 데이터를 통해 discriminative 작업에 모델을 fine-tuning하는 단계
3.1 Unsupervised pre-training
- (비지도 사전학습 단계의 목표는 언어 모델을 학습해서 자연어의 기본 구조를 모델에게 이해시키는 것 → 일반적인 언어 모델의 목적 함수와 동일)
- U={u_1, u_2, … , u_n} : 비지도 학습을 위한 토큰 corpus
- L_1(U) : corpus에서 각 토큰(u_i)에 대한 로그 확률의 합을 최대화하는 우도(likelihood) 함수
- 참고) 우도(likelihood)
- 특정한 사건이 확률 모델에 의해 발생할 정도
- 확률과는 다른 개념
- 참고) 우도(likelihood)
- Θ : 신경망의 가중치를 포함하는 모델의 매개변수들, SGD로 학습된다.
- P(ui|u{i−k}, ... ,u_{i−1}) : 이전 토큰의 문맥(context)를 기반으로 한 다음 토큰의 조건부 확률값
- 본 연구에서는 multi-layer transformer decoder를 사용한다.
- h_0 : 초기 입력 임베딩, 두 임베딩의 합으로 이루어짐
- UW_e : U는 입력 토큰 시퀀스, W_e는 토큰 임베딩 행렬. → 각 토큰을 고차원 벡터로 변환
- W_p : 포지션 임베딩 행렬, 시퀀스 내의 각 토큰의 위치 정보를 인코딩.
- h_l : Transformer 블록, 이전 레이어 h_l-1의 출력을 입력으로 받음.
- n : 모델의 전체 레이어 수
- 각 블록은 Multi-head self-attention 메커니즘과 Position-wise Feed Forward Network Layer를 포함한다.
- P(u) : output 확률
- h_n은 최종 레이어 출력이며, W^T_e는 토큰 임베딩 매트릭스의 transpose
- 두 값을 곱한 뒤 softmax를 거쳐 각 target 토큰의 확률 계산
3.2 Supervised fine-tuning
- 사전 학습된 언어 모델을 특정 지도 학습 작업에 맞게 fine-tuning 하는 과정
- Fine-tuning 과정은 아래 수식과 같이 표현됨
-
x_1, x_2, … , x_m : 입력 토큰 시퀀스
-
y : 예측해야 할 라벨
-
h^l_m : 사전 훈련 모델을 통과한 후 마지막 transformer 블록에서 얻어진 activation(출력)
-
W_y : fine-tuning될 때 추가된 linear output layer의 parameter
-
softmax로 확률분포로 변환
-
최적화 목적 함수는 아래와 같이 표현됨
-
입력 x에 대해 모델이 정확한 라벨 y를 예측할 로그 확률을 최대화하도록 학습
- (이는 cross entropy loss function의 negative log likelihood와 동일)
-
Fine-tuning 과정에서 언어 모델링을 보조 목표로 포함하는 것은 2가지 이점이 있다:
- 1) 지도학습 모델의 일반화 성능을 개선한다.
- 2) 모델의 수렴을 가속화한다.
-
이는 아래의 합성 objective function을 최적화함으로써 수행됨
- (λ : 두 objective 사이의 상대적 중요도를 조절하는 하이퍼파라미터)
- 전반적으로 fine-tuning 과정에서 필요한 추가적인 파라미터는 W_y와, Delimeter token에 대한 임베딩(3.3에서 설명) 뿐이다.
3.3 Task-specific input transformations
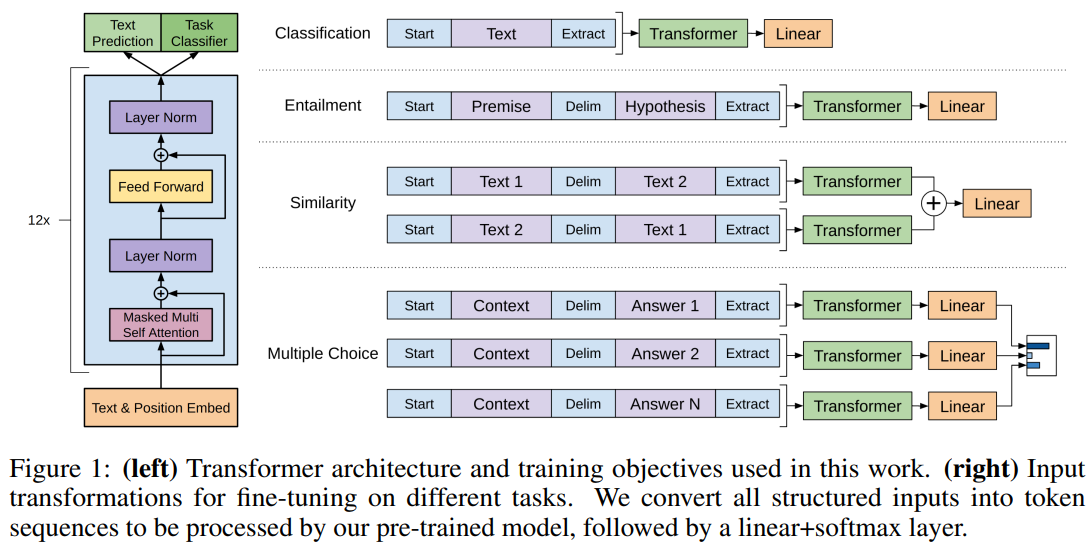
- 텍스트 분류와 같은 일부 작업에서는 직접 모델을 fine-tuning할 수 있지만, QA나 Textual Entailment과 같은 작업들은 문장쌍이나 문서, 질문, 답변의 삼중항과 같은 구조화된 입력이 존재한다.
- GPT는 연속된 텍스트 시퀀스로 훈련되었기 때문에, 이러한 작업들에 적응하기 위해서는 모델의 일부 수정이 필요하다.
- 이전 연구들은 전이된 표현 위에 task에 특화된 아키텍처를 학습하는 것을 제안했다.
- 그러나 이런 접근법들은 작업들마다 아키텍처를 변환하고, 추가된 아키텍처 요소에는 전이학습이 사용되지 않음.
- GPT는 순회(traversal) 방식의 접근법을 사용하여 복잡한 구조의 입력을 pre-trained 모델이 처리할 수 있는 순서가 있는 시퀀스로 변환한다.
- 이는 작업에 따라 아키텍처를 광범위하게 바꾸지 않게 한다.
- Textual Entailment (텍스트 수반/함축)
- Text Entail 작업에서는, 주장(premise) p와 가설(hypothesis) h 토큰 시퀀스를 연결하고, 그 사이에 구분 기호 토큰($)을 넣는다.
- Similarity (유사도)
- 두 문장의 유사도를 평가할 때는 문장의 순서가 중요하지 않으므로, 두가지 순서를 모두 고려하여 각 문장의 시퀀스 표현 h_l^m를 생성한다. 그 표현들은 element-wise하게 추가되어 linear output layer에 공급된다.
- Question Answering and Commonsense Reasoning (질문 답변 & 상식 추론)
- 위 작업들에 대해서는, context 문서 z, 질문 q, 가능한 답변들의 집합 {a_k}를 제공받는다.
- 문서 문맥과 질문을 각각의 가능한 답변과 연결하고, 사이에 구분 기호 토큰을 넣어 [z; q; $; ak]를 얻는다.
- 이 시퀀스들은 독립적으로 처리되고, 그 다음 소프트맥스를 통해 정규화되어 가능한 답변들에 대한 출력을 생성한다.
4. Experiments
4.1 Setup
- Unsupervised pre-training
- 7,000권 이상의 다양한 장르의 미출판 책으로 구성된 BooksCorpus 데이터셋을 사용해 모델을 훈련한다.
- 긴 연속된 텍스트를 포함
- ELMo가 사용한 1B Word Benchmark와 달리 문장 레벨에서 섞이지 않아 장기적 구조를 파괴하지 않는다.
- GPT는 이 corpus에서 매우 낮은 토큰 레벨의 PPL (18.4) 를 기록했다.
- 7,000권 이상의 다양한 장르의 미출판 책으로 구성된 BooksCorpus 데이터셋을 사용해 모델을 훈련한다.
- Model specifications
- GPT는 기존의 Transformer를 대체로 따르며, Masked self-attention heads를 가진 12개 layer의 decoder-only Transformer를 학습시켰다.
- 768차원, 12개의 attention head
- Position-wise feed-forward network에서, 3072차원의 내부 상태
- Adam optimization, 최대 학습률 2.5e-4. 학습률은 2000번의 업데이트 동안 선형적으로 증가하며, 코사인 스케줄을 사용하여 0으로 감소시켰다.
- 64의 미니배치에서 무작위로 샘플링된 연속적인 512 토큰 시퀀스에 대해 100 에폭을 훈련시켰다.
- 모델 전체에 걸쳐 LayerNorm이 사용되기 때문에, 단순한 가중치 초기화 N(0, 0.02)로 충분하다.
- 바이트페어 인코딩(BPE) 어휘를 사용했고, regularization을 위해 residual, embedding, attention에 0.1 dropout 적용.
- non bias나 gain weight에 대해 w = 0.01의 수정된 L2 규제 버전을 사용했다.
- Activation function으로 GELU 사용
- spaCy 토크나이저 사용
- GPT는 기존의 Transformer를 대체로 따르며, Masked self-attention heads를 가진 12개 layer의 decoder-only Transformer를 학습시켰다.
- Fine-tuning details
- 비지도 사전훈련에서 사용된 하이퍼 파라미터 설정을 재사용한다.(특별한 언급이 없으면)
- 분류기에 0.1 비율의 드롭아웃을 추가한다.
- 대부분의 작업에서 6.25e-5의 학습률과 32의 배치 크기를 사용한다.
- GPT는 빠르게 파인튜닝되며, 대부분의 경우 3 에폭이면 충분했다.
- 학습의 0.2% 동안 웜업을 포함하는 선형 학습률 감소 스케줄을 사용한다.
4.2 Supervised fine-tuning
- NLI(자연어 추론), QA(질문 응답), Semantic Similarity(의미론적 유사성), Classification(텍스트 분류)를 포함한 다양한 지도학습 작업에 대한 실험을 진행한다.
- 이 작업 중 일부는 최근 발표된 GLUE 다중 작업 벤치마크로 진행한다.

-
Natural Language Inference(자연어 추론, 텍스트적 함축)
- 텍스트적 함축을 인식하는 작업은 두 문장의 쌍을 읽고, 그들 사이의 관계를 포함, 모순, 중립 중 하나로 판단하는 것을 의미한다.
- 이 작업은 어휘적인 함축, 모호성 등으로 인해 어려운 task로 남아있다.
- SNLI, MNLI, QNLI, SciTail, RTE 등의 다양한 데이터셋에 대해 평가한다.
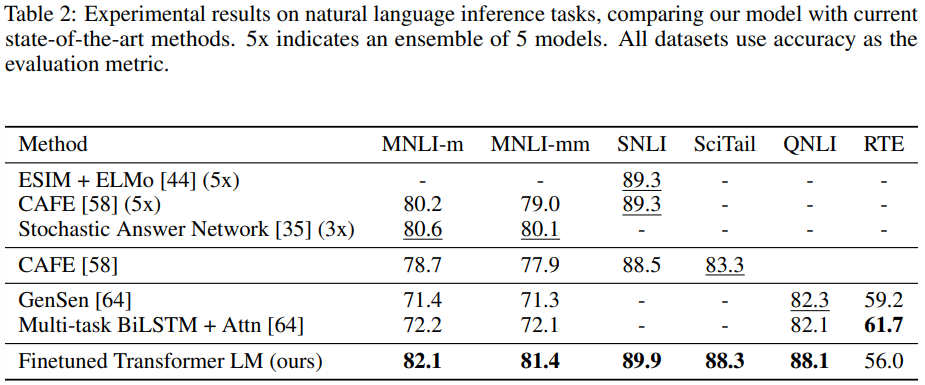
- 표 2는 결과를 나타내며, 5개의 데이터셋 중 4개에서 SOTA를 달성했다.
- GPT가 여러 문장에 대해 더 잘 추론하고 언어적 모호성을 더 잘 처리할 수 있는 능력이 있음을 보여준다.
-
Question answering and commonsense reasoning
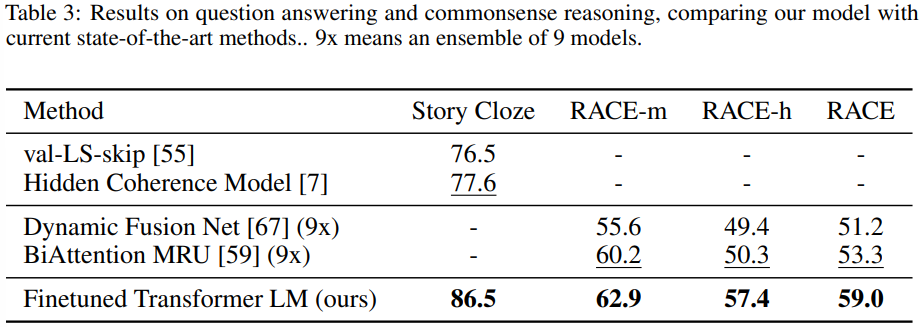
- 문장 추론이 필요한 또 다른 작업은 QA다.
- 영어 지문과 관련된 질문들로 구성된 RACE 데이터셋 사용
- 다른 데이터셋들 보다 더 많은 추론 유형의 질문을 포함한다.
- Story Cloze Test에 대해서도 평가
- 두 가지 옵션 중에서 올바른 결말을 선택하는 것
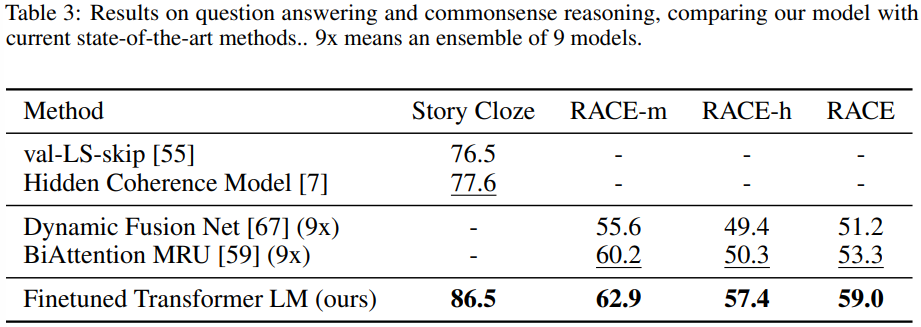
- 두 작업에서 모두 SOTA
- GPT가 장기적인 문맥을 효과적으로 처리할 수 있음을 보여준다.
-
Semantic Similarity
- 의미론적 유사성 task는 두 문장이 의미론적으로 동등한지 여부를 예측하는 것을 의미한다.
- 3개의 데이터셋 사용
- MRPC, QQP, STS-B
- 3개 중 2가지 데이터셋에서 SOTA 달성
- Classification
- 두가지 다른 텍스트 분류 작업에 대해 평가한다.
- 1) Corpus of Linguistic Acceptability(CoLA)는 문장이 문법적으로 맞는지에 대한 전문가의 판단을 포함한다.
- 훈련된 모델의 내재된 언어적 편향을 테스트한다.
- 2) Stanford Sentiment Treebank(SST-2)는 표준적인 이진 분류 작업이다.
- CoLA에서 SOTA 달성
- GLUE 벤치마크에서 성능 향상
- 전반적으로, 12개 데이터셋 중 9개에서 SOTA 달성했고, 많은 경우에는 앙상블 모델도 능가한다.
- 또한 크기가 작은 데이터셋(5.7k)부터 크기가 큰 데이터셋(550k)에서까지 잘 동작한다는 것을 보여준다.
5. Analysis
-
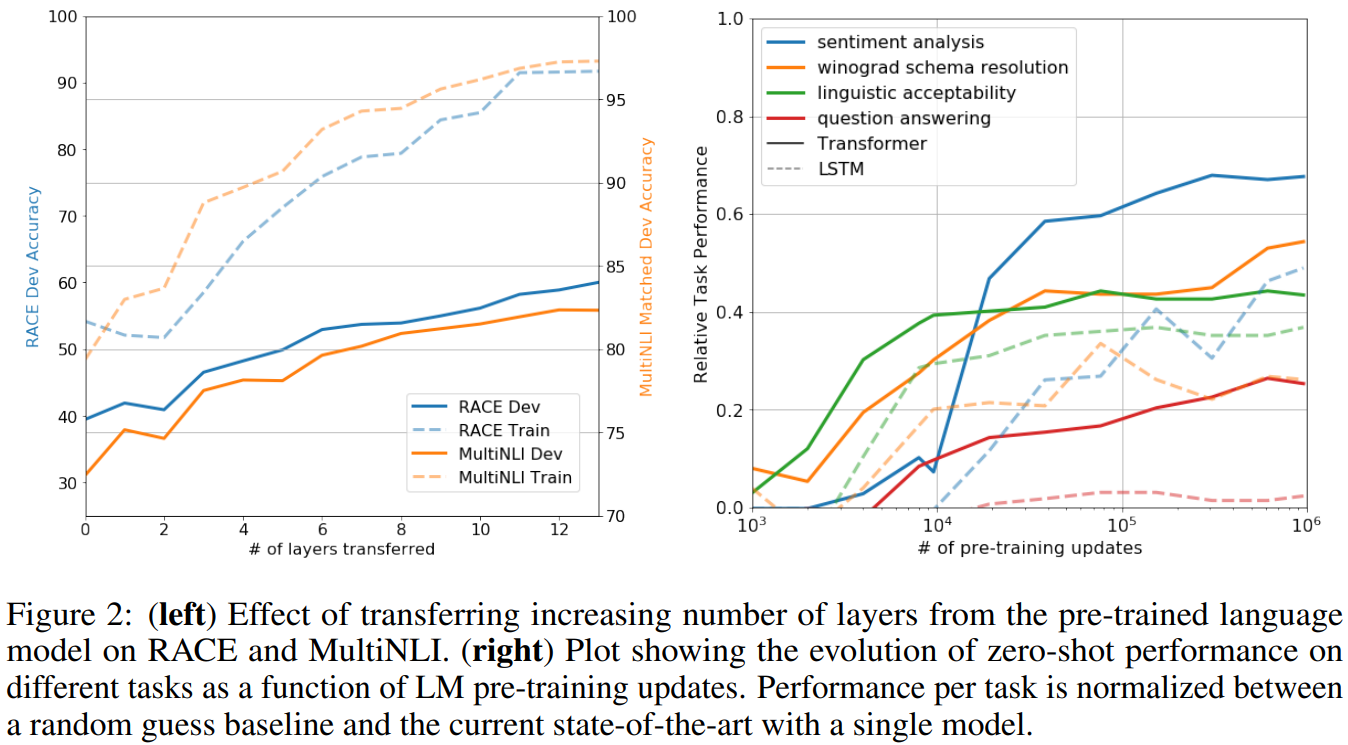
Impact of number of layers transferred (전이하는 레이어 수의 영향)
- 비지도 사전 훈련에서 target 지도학습으로 transfer하는 layer의 수가 달라짐에 따른 영향을 관찰했다.
- Figure 2의 왼쪽 그림은 transfer되는 layer의 수에 따라 실험하는 데이터셋에서의 성능을 나타낸다.
- pre-trained된 레이어를 더 많이 전이할 수록 target task의 성능이 올라감을 보여준다.
-
Zero-shot Behaviors
- Transformer 의 사전 훈련이 효과적인 이유를 더 잘 이해하고 싶다.
- GPT는 사전훈련(이건 generative한 작업을 위한 사전학습)을 하는 동안에도 다른 복잡한 NLP task에 필요한 지식들을 학습한다.
- LSTM과 Transformer를 비교한 결과는, Transformer가 언어처리 작업에 대해 더 나은 전이 학습 능력을 가지고 있음을 보여준다.
- 또한 Transformer는 LSTM보다 제로샷 학습 성능에서 더 변동성이 적고 안정적으로 증가하는 성능을 보인다.
-
Ablation studies
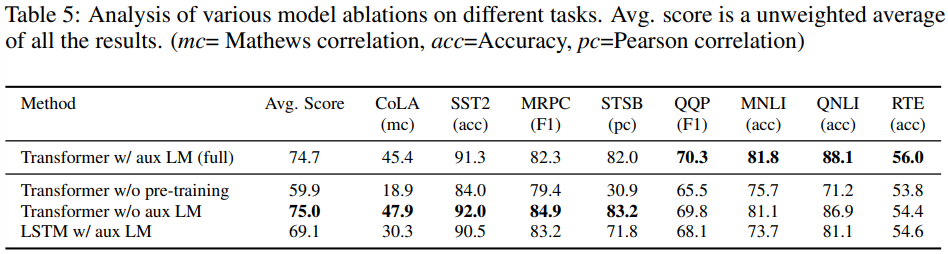
- 3가지 다른 제거 실험을 수행했다.
- 1) Fine-tuning에서 보조 LM 목표를 제거하고 성능을 확인했다.
- 보조 LM 목표가 NLI 작업과 QQP 작업에 도움이 된다는 것을 확인했다.
- 전반적으로, 더 큰 데이터셋이 보조 목표로부터 이득을 얻는 것 같다.
- 2) 동일 조건에서 LSTM과 Transformer의 성능을 비교했다.
- LSTM은 MRPC에서만 Transformer보다 더 나은 성능을 보였고, 나머지는 전부 다 Transformer보다 성능이 낮았다.
- 3) 사전 훈련 없이 직접 지도학습된 target task에 대해 사전 훈련된 일반 모델과 성능 비교도 이뤄졌다.
- 사전 훈련이 없으면 모든 작업에서 성능이 떨어졌다.
- 복잡한 NLP 작업들에서는 결국 사전 훈련이 중요하다.
6. Conclusion
- 우리는 Generative한 Pre-training과, Discriminative한 Fine-tuning을 통한 single model을 통해 자연어 이해 작업에서 강력한 성능을 달성하는 프레임워크를 소개했다.
- (기존 방식들이 각 task 별로 아키텍처를 설계하거나, fine-tuning을 새로 하거나 하는 것과는 차별적이고 휠씬 편한 방식임)
- 다양한 긴 문장을 포함하는 corpus에 대한 pre-train을 통해 장거리 종속성을 해결하고, 12개 중 9개 task에서 SOTA 달성했다.
- 비지도 사전학습을 사용하여 discriminative task의 성능을 높이는 것은 ML의 오랜 목표였다.
- GPT 모델은 이것이 실제로 가능하다는 것을 보여주며, Transformer라는 모델과 장거리 종속성이 있는 텍스트를 사용할 때 성능 향상이 이루어 짐을 보여줬다.
- 이 연구가 자연어 이해 및 다른 영역에서도 비지도 학습이 언제 어떻게 동작하는지에 대한 이해를 더 높이는데 도움이 되기를 기대한다.
