
From NeurIPS, 2024
0. Abstract
- Debate를 이론적으로 분석하고, 수학적으로 분석하는 framework를 제안한다.
- 이를 바탕으로 Multi-Agent 에서의 Debate에 대한 여러 이론적 결과를 제시한다.
- 모델 간 비슷한 성능이나 응답은 토론 과정이 majority opinion으로 단순 수렴되는 정적 토론을 초래할 수 있음을 보인다.
- 이런 majority opinion이 common misconception(모델의 공유된 학습 데이터에 의해 가능)에서 비롯된 경우, 토론은 이런 misconception과 관련된 답변으로 수렴할 가능성이 크다.
- 이런 이론적 결과를 바탕으로, 토론의 efficacy를 개선하는 3가지 intervention을 제안.
- 각 intervention에 대해 개선 방법을 설명하는 이론적 결과를 제시하고, 4가지 벤치마크 작업에서 성능이 향상됨을 보인다.
1. Introduction
- LLM은 다른 모델로부터 의견을 수집하고 처리할 수 있는 능력을 갖고 있다.
- 이전 연구에서는 위 능력을 바탕으로 LLM이 토론에 참여해 협력적으로 task를 해결함을 보인다.
- Multi-agent debate는 각 모델에게서 응답을 얻고, 그 응답을 모델들 간에 배포하며, 각 모델로부터 갱신된 응답을 다시 얻는 방식으로 진행된다.
- 이 연구는 debate process를 더 잘 이해할 수 있는 이론적 프레임워크를 제시하여 이를 탐구한다.
- 베이지안 추론과 In-Context Learning에서 영감을 얻어, 토론을 부분적으로 ICL의 특수 유형으로 볼 수 있음을 보인다.
- 이 프레임워크를 통해 Multi-agent debate가 Echo-Chamber Effects에 취약하다는 것을 입증한다.
- Echo-Chamber effect는 특히 모델 다수 사이에 공유된 misconception에서 비롯된 경우 더 큰 영향을 미친다.
- 참고: Echo-Chamber effect(반향실 효과): 같은 입장을 지닌 정보만 지속적으로 되풀이하여 수용하는 현상을 비유적으로 나타낸 말 (위키백과)
- 이후 프레임워크에서 도출한 결과를 활용해 토론 절차의 효율성을 개선하기 위한 세 가지 intervention을 제안한다.
- 1) Diversity Pruning: 각 debate 단계에서 모델 응답의 information entropy를 최대화하는 것을 목표로 한다.
- 2) Quality Prunung: 각 모델의 응답의 관련성을 최대화 하는 것을 목표로 한다.
- 3) Misconception Refutation: 모델 응답에서 오해를 식별하고 반박하려고 시도한다.
- 이 interventions은 모델이 직접 답변을 제공하는 것보다 평가하는 데 더 능숙하다는 이전 연구들에서 영감을 얻었다.
- 각 intervention에 대해 토론이 어떻게 개선되는지 설명하는 이론적 결과를 제시하고, 4개의 벤치마크에서 interventions이 실제로 토론의 efficacy를 개선함을 실험적으로 증명한다.
- 기여점
- 베이지안 추론과 ICL의 연관성을 활용한 Multi-LLM debate의 이론적 프레임워크 제안
- Multi-LLM debate의 여러 주요 원칙에 대한 이론적 통찰 제공
- 이 통찰을 활용해 4개의 언어적 벤치마크 및 3개의 LLM에서 debate의 성능을 일관되게 개선시키는 3가지 debate interventions을 설계
2. Related Work
- 본 연구는 Multi-agent debate와 밀접한 관련이 있다.
- agent들 간의 iterative 협력을 통해 결정을 내리는 과정에 초점을 맞추고 있다.
- 이런 연구들은 주로 QA task의 맥락에서 multi-agent debate을 다루며, single model보다 더 높은 품질의 답변을 제공하기 위해 여러 모델을 토론에 참여시키는 것을 목표로 한다.
- Du et al. [2023, Improving factuality and reasoning in language models through multiagent debate]이 제안한 초기 debate framework에서는 먼저 각 모델에 질문을 던지고, 이전 라운드에서 모든 모델의 응답을 맥락화하여 동일한 질문을 다시 던지는 방식으로 토론을 진행한다.
- 이 절차의 다양한 변형도 제안된다.
- 다른 기능을 가진 모델 간의 debate (Liang et al. [2023, Encouraging divergent thinking in large language models through multi-agent debate])
- Round-robin 방식의 debate (Chat et al. [2023, Towards better llm-based evaluators through multi-agent debate])
- agent 간 의견 차이를 동적으로 조절하는 debate (Chang [2024, Evince: Optimizing adversarial llm dialogues via conditional statistics and information theory])
- debater의 correctness를 평가하기 위한 judge를 사용하는 방식 (Khan et al. [2024, Debating with more persuasive llms leads to more truthful answers])
- 답변 품질을 iterative하게 향상시키기 위한 다른 기법도 제안되었다.
- CoT, Zero-shot-CoT, self-consistency(+Med-PALM2), self-reflection
- 토론과 유사한 방식의 LLM 활용에 대한 연구도 진행되어 왔다.
- 서로 다른 LLM이 상효작용하는 방식이나,
- (Liu et al. [2023, Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization])
- (Abdelnabi et al. [2023, Llm-deliberation: Evaluating llms with interactive multi-agent negotiation games])
- (Zhang et al. [2023, Exploring collaboration mechanisms for llm agents: A social psychology view])
- (Li et al. [2023, Tradinggpt: Multi-agent system with layered memory and distinct characters for enhanced financial trading performance])
- (Park et al. [2023, Choicemates: Supporting unfamiliar online decision-making with multi-agent conversational interactions])
- LLM이 자신의 추론을 설명하는 방식,
- (Wang et al. [2024, Can chatgpt defend its belief in truth? evaluating llm reasoning via debate])
- general task에 협력적으로 수행하는 방식
- (Li et al. [2023, Communicative agents for" mind" exploration of large scale language model society])
- 등등
- 서로 다른 LLM이 상효작용하는 방식이나,
- 일부 연구에서는 토론 과정이 불안정할 수 있으며, 단일 모델을 사용하는 것보다 오히려 성능이 저하될 수 있음을 보여주기도 했다.
- (Wang et al. [2024, Rethinking the bounds of llm reasoning: Are multi-agent discussions the key?])
- (Smit et al. [2023, Are we going mad? benchmarking multi-agent debate between language models for medical q&a])
- 본 연구는 ICL과 베이지안 추론과도 관련이 있다.
- ICL은 LLM이 몇가지 example만 제공받았을 때도 unseen task를 수행할 수 있음을 보인다.
- 다른 연구들은 ICL과 베이지안 추론 간의 연관성을 보여준다.
- 모델에 제공되는 additional example은 토큰에 대한 모델의 사후 분포(posterior distribution)을 업데이트하는 것으로 볼 수 있다.
3. Preliminaries
Debate
- x를 question, y를 관련 답변이라 하자. 예를 들어, x=’하늘은 무슨 색인가요?’ 이고 y=’파랑’ 일 수 있다.
- Du et al. [2023, Improving factuality and reasoning in language models through multiagent debate] 이 제안한 토론 절차에 따르면, n개의 LLM(이하 agent라고도 함)으로 구성된 집합이 T 라운드에 걸쳐 iterative하게 discussion을 수행해 올바른 답변 y을 추론하며 절차는 다음과 같다.
- t=0 라운드에서, 각 에이전트 i는 작업 x를 관찰한 후 응답 z_i^(0)을 제공한다.
- t>0 라운드에서, 각 에이전트 i는 작업 x와 이전 라운드의 모든 에이전트 응답 Z^(t-1) = z_1^(t-1), … , z_n^(t-1))을 관찰한 후, 갱신된 응답 z_i^(t)를 제공한다.
- 토론 과정은 t = T이거나, 에이전트들이 합의에 도달할 경우 종료된다.
- 합의에 도달했는지 여부를 측정하기 위해 함수 a가 주어진 응답 z에서 답변을 추출한다.
- 예를 들어, z=’낮에는 하늘이 파랗습니다’라면 a(z)=’파랑’이다.
- t 라운드에서, agent i가 갱신된 응답 z_i^(t+1)을 제공할 확률은 다음과 같다.
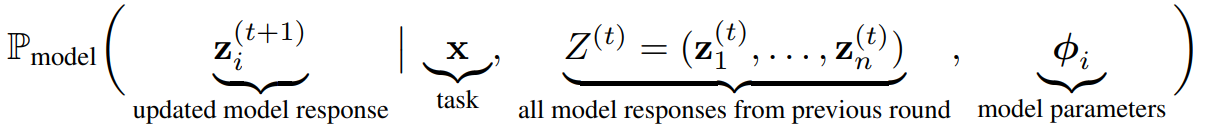
- 모델의 하이퍼 파라미터는 훈련 데이터, 아키텍처 등을 의미한다.
- 각 라운드에서 모든 agent는 동일한 입력(Z^(t), x)를 관찰한다.
- 따라서 출력z_i^(t+1)의 차이는 출력 생성의 확률적 성격과, 각 모델의 하이퍼 파라미터에 의해 결정된다.
- 본 연구에서의 접근 방식과 ‘일반적인’ 토론의 주요 차이점은 각 토론 라운드 사이에 Z^(t) 응답을 수정하기 위해 latent concept을 활용한다는 것이다.
Latent Concepts
-
이전 연구에서 설명되었듯이, 잠재 개념은 언어가 무작위로 생성되지 않는다는 생각을 담고 있다.
-
즉, 인간이든 모델이든 언어를 생성할 때, 먼저 마음 속에서 아이디어나 의도가 형성된 후, 그 아이디어나 의도를 전달할 단어를 선택한다.
-
더 formal 하게는, Θ를 latent concept space라 하고, θ ∈ Θ를 concept라 설정한다면,
- Xie ek al. [2021]에 따르면, task x와 관련 답변 y는 먼저 latent concept θ ∈ Θ에서 벡터를 선택하고, 이후 (x,y) ~ D(θ)를 샘플링하여 생성된다.
- 여기서 D는 concept에서 task-answer pair로 매핑하는 distribution을 나타낸다.
-
유사하게, 모델이 응답을 제공할 때, x를 관찰하고, 잠재 개념 θ 또는 더 일반적으로 잠재 개념 공간에 대한 분포를 추론한 후, 추론한 개념에 따라 응답을 생성한다.
- 즉, 위에서 주어진 모델 생성 확률 수식은 아래와 같이 표현될 수 있다.
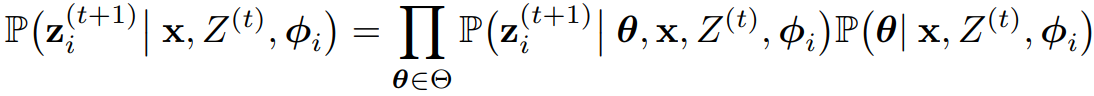
- 위 식은 잠재 개념 공간 Θ에 대해 항상 성립한다.
- 즉, 위에서 주어진 모델 생성 확률 수식은 아래와 같이 표현될 수 있다.
-
잠재 개념의 예시
- BoolQ 데이터셋에서의 QA task
- Q: “Abraham Lincoln이 영화 Saving Private Ryan에서 편지를 썼습니까?”
- A: “Yes”
- 이 경우, 잠재 개념은 영화의 한 장면, 즉 Lincoln이 쓴 Bixby letter가 병사들 앞에서 읽히는 장면과 관련있다.
- 본 연구 case와 마찬가지로, 먼저 concept θ가 선택되고, 이후 영화에서 문자열 x가 샘플링된다(즉 영화와 관련된 질문이 생성된다).
- 산술 계산, ex. 곱셈
- 언어로 곱셈은 “4 * 4” 와 같은 형식으로 작성 가능
- 이 문자열의 잠재 개념은 곱셈의 매커니즘을 나타낸다.
- 예를 들어, 곱셈은 덧셈의 반복이며, 덧셈은 숫자 값을 반복적으로 1씩 증가시키는 것
- 그러나 잠재 개념은 더 추상적일 수 있다
- 알려지지 않은 임베딩 공간의 벡터로 표현될 수 있다.
- BoolQ 데이터셋에서의 QA task
4. A Theoretical Fomulation of Multi-Agent Debate
- Multi-Agent Debate의 이론적 공식화를 제시한다.
- 토론의 내부 동작 방식을 이해하는데 중요한 통찰을 제공하며, 이를 통해 토론을 개선하려 한다.
- 프레임워크의 핵심은 잠재 개념의 아이디어와 각 모델의 생성 확률의 확장(두번째 수식)을 활용해 토론을 더 잘 이해하는 것이다.
- 그전에 중요한 가정이 있다.
Assumption 4.1
- 주어진 잠재 개념 공간 Θ에서, 응답 z_i^(t+1)을 생성할 확률은 concept θ ∈ Θ와 모델 파라미터 ϕ_i를 고려했을 때, 이전 응답 Z^(t)와 task x에 대해 조건적으로 독립적이다. 즉,
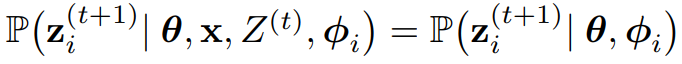
- 이는 모델의 generation z_i가 모델 파라미터 ϕ_i와 모델이 identify한 concept(θ)에 의해 고유하게 결정됨을 의미한다.
- 인코더-디코더 기반 모델의 경우 ϕ와 θ의 결합은 인코더가 생성한 임베딩이라고 할 수 있다.
- 이 임베딩을 사용하면 원래의 입력 (x, Z^(t))는 더이상 모델의 출력을 결정하지 않고, 대신 임베딩과 모델 매개변수 만이 모델 출력을 고유하게 결정한다.
- 다음으로, 토론 라운드가 진행됨에 따라 모델 응답이 어떻게 진화하는지 조사하는데 유용한 아래 Lemma 4.2를 도출한다.
Lemma 4.2
- 시간 t+1에서 모델 i의 generation은 아래와 같이 표현 가능하다. (skew: 왜곡)
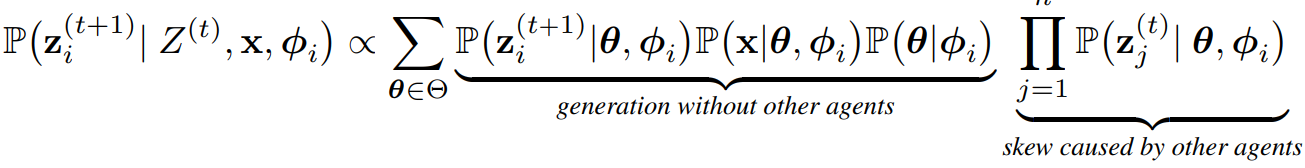
- 이 lemma의 중요성은 응답 z_i^(t+1)을 생성할 확률을 이전 응답 Z^(t)없이 생성하는 확률과, 이전 모델 응답에 의해 발생한 왜곡항(skew term)으로 표현할 수 있다는 것이다.
- (수식이 많아 캡처로 대체)
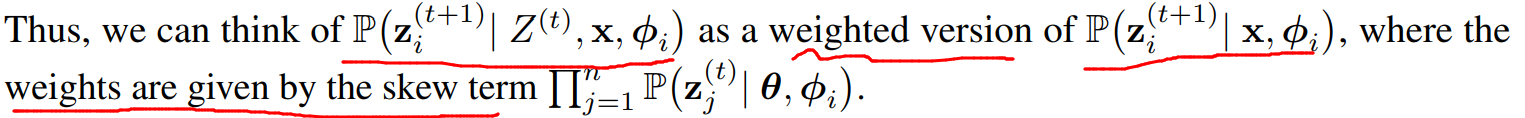
Debate and In-Context Learning
- Xie et al. [2021]의 연구를 통해 잠재 개념의 역할을 이해한다.
- 이 연구는 잠재 개념에 대한 베이지안 추론을 사용해 ICL을 이해한다.
- ICL과 Multi-agent debate는 자연스러운 연결점이 있다.
- ICL은 다음과 같이 동작한다.
- Task x와 모델 f에 대해, x와 유사한 task-anwer pair (x_1, y_1), … , (x_m, y_m)을 선택한다.
- 이후 모델 f에게 (x_j, y_j)를 예로 들어 task x에 대한 answer z= f(x|(x_1, y_1), … , (x_m, y_m))을 요청한다.
- Xie et al. [2021]의 핵심 결과는 예제 (x_j, y_j)에 포함된 잠재 개념, 특히 다수 예제 간에 공유된 개념이 답변 z에 영향을 준다는 것이다.
- ICL은 다음과 같이 동작한다.
- 이와 유사하게 이전 라운드의 모델 응답 Z^(t)는 ICL의 예제와 같은 역할을 한다.
- 다음 라운드 t+1에서 모델의 갱신된 응답 z_i^(t+1)은 Z^(t)에 공유된 개념에 영향을 받는다.
- Lemma 4.2에서 왜곡항(skew term)은 Z^(t)에 의해 전달된 잠재 개념이 z_i^(t+1)의 생성에 영향을 미치는 방식을 보여준다.
- 즉 (식에서)∏ ~~ 는 모델 생성 확률에 가중치를 부여한다.
4.1 Debate Objective
- 이런 관점에서 debate process를 설계하면 concept space Θ를 활용해 효과적으로 토론을 수행할 수 있다.
- 이를 위해 토론을 최적화 문제로 공식화하며, Lemma 4.2의 왜곡항이 최적화 변수가 된다.
- task x와 answer y에 대해 각 토론 라운드는 아래와 같은 최적화 문제로 공식화된다.
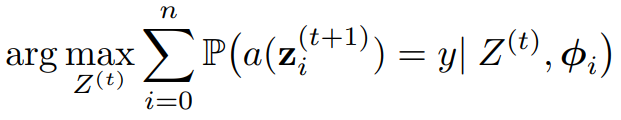
- 시간 t에서, 다음 단계에서 올바른 answer를 제공할 확률을 최대화하도록 Z^(t)를 작성하는 것을 목표로 하며, 이 objective를 잠재 개념 공간 Θ를 사용해 확장하면 아래와 같다.
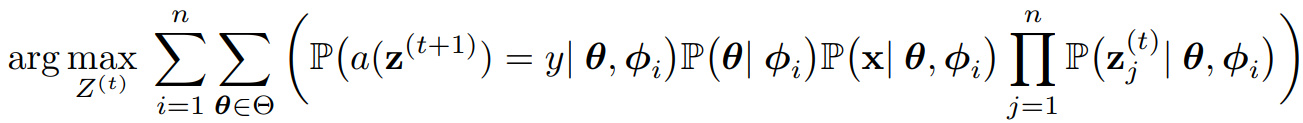
- 이 objective를 직접 최적화하는데 있어서 주요 challenge들은:
- task x와 answer y가 유래된(생성된) true concept θ*, 응답 z_j^(j)와 underlying concept 간의 관계가 알려져 있지 않다.
- Z^(t)의 응답은 자연어로 이루어져 있다.
- 그럼에도 concept space 안에서 여러 approach를 설계해 더 잘 최적화할 수 있으며, 그런 방식을 설계하기 위해 토론 절차 전체를 더 살펴볼 필요가 있다.
5. Debate Principals
- LLM debate의 효율성에 영향을 미치는 factor를 살펴본다.
- 특히 Z^(t)의 응답 다양성과 모델 능력의 다양성 측면에서 정보 다양성의 역할을 살펴본다.
- 어느 측면에서든 다양성이 부족하면 토론 과정에 부정적인 영향을 미침을 확인한다.
- 또한, 토론에서의 특정 유형의 homogeneity, 즉 모델 대다수가 동일한 잘못된 신념을 공유하는 경우를 연구한다.
- 특히 Z^(t)의 응답 다양성과 모델 능력의 다양성 측면에서 정보 다양성의 역할을 살펴본다.
5.1 Information Diversity
- 모델 능력과 모델 응답의 다양성이 토론 절차에 미치는 영향을 살펴본다.
- 능력이나 응답의 동질성은 토론 절차를 특정 잠재 개념으로 편향시킬 수 있다.
Similar Model Capabilities
- 토론 과정이 한 가지 타입의 모델로만 진행된다고 가정한다. 즉, n개의 동일한 모델 카피를 사용.
- 따라서 모든 i ∈ [n]에 대해 ϕ_i = ϕ인 경우이다.
- 이 경우 agent 수가 증가함에 따라 토론 절차는 에코 챔버 효과에 더 영향을 받게 된다.
- 즉, 에이전트들이 받아들이는 가장 유력한 개념이 변화할 확률은 0에 가까워진다.
- 그 말인즉, 더 많은 수의 similar agent는 static debate dynamics를 초래하며, 이는 debate의 본래 목적을 저해한다.
Theorem 5.1
(수식 생략)
- 내용: 동일한 모델의 copy나 매우 유사한 모델로 토론이 진행될 때, 모델의 수를 증가시키는 것은 하나의(변화하지 않는) 개념으로 토론을 수렴하게 만든다는 것을 의미한다.
- 이는 여러 개념의 균형있는 분포 대신 특정 개념으로 집중되는 결과를 초래한다.
Similar Model Opinions
- 모델의 유사한 응답이 collaboration process에 미치는 영향을 살펴본다.
- t 시점에 n개의 응답 Z^(t)가 존재하고, 이 중 최소 m개의 응답이 유사하다고 가정한다.
- 즉, θ’라는 특정 개념이 존재하며, 이는 모든 j ≤ m 에 대해 P(θ∣z_j^(t),ϕ_i)값을 최대화한다고 할 수 있다.
Theorem 5.2
(수식 생략)
- 내용: 다수의 모델이 task x에 대해 유사한 응답을 제공할 경우, 그 반복된 응답이 다른 모델의 응답 뿐만 아니라, task x 자체를 압도할 수 있음을 나타낸다. 실제로 Section 7에서 그 현상이 발생함을 보인다.
5.2 Shared Misconceptions
- 모델 능력과 응답의 homogeneity의 particular type인 ‘Shared Misconceptions’에 대해 살펴본다.
- 모델들 사이에 공통적으로 잘못된 신념이 공유될 경우, 토론은 덜 효과적이며, 그 잘못된 신념과 관련된 잘못된 개념으로 수렴할 가능성이 높다.
Definition 5.3 (Misconception)
- 특정 개념 θ에 대해, 모델 i가 θ에 대한 오해를 갖고 있다고 하자.
- 이는 다른 개념 θ’가 존재하여, 아래를 만족할 때 성립한다.
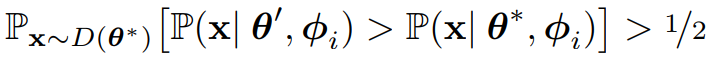
- 즉, θ* 개념에서 생성된 task에 대해, 모델이 잘못된 개념 θ’이 task를 더 잘 설명한다고 믿는 경우이다.
- m개의 agent가 동일한 잘못된 개념 θ’을 공유하는 경우, 이를 ‘shared misconception’이라 한다.
- 이런 경우 모델이 생성한 응답은 잘못된 개념 θ’에 biased 된다.
Theorem 5.4
- 참인 개념 θ*가 주어지고, n개의 agent 중 m개가 잘못된 개념 θ’에 대한 shared misconception을 갖고 있다고 가정한다.
- 그러면 task-answer pair (x,y) ∼ D(θ*)에서, 마지막 라운드 T의 토론 절차의 평균 정확성은 m에 따라 단조(monotonically) 감소한다. 즉,
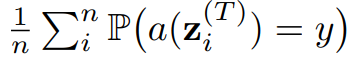
- 위 식은 m이 증가함에 따라 감소한다.
- 그러면 task-answer pair (x,y) ∼ D(θ*)에서, 마지막 라운드 T의 토론 절차의 평균 정확성은 m에 따라 단조(monotonically) 감소한다. 즉,
- 잘못된 개념으로 수렴하는 현상은 더 많은 모델을 추가한다고 해서 쉽게 완화되지 않을 가능성이 있다.
- 한 모델의 misconception이 훈련 데이터에 의해 형성된 경우, 다른 모델들도 비슷한 훈련 데이터 간 높은 상관관계로 인해 동일한 misconception을 가질 가능성이 높기 때문
6. Interventions
- 토론 절차에 대한 interventions(수정, 개입)을 논의한다.
- Intervention은 두 범주로 나눈다.
- 가지치기(Pruning): 전체 응답 Z^(t)에서 어떤 응답을 유지할지 선택하는 데 초점을 맞춤
- 수정(Modifying): Z^(t)의 응답을 변경하거나 편집하는 데 초점
6.1 Pruning Interventions
- debate의 t 라운드에서, intervention은 t+1 라운드를 시작하기 전에 Z^(t)에서 하위집합 응답인 Z’^(t)을 선택하여 동작한다.
- Pruning intervention을 사용할 때는, t+1라운드에서 모델은 pruned된 응답 집합인 Z’^(t)만을 보게 된다.(전체 응답인 Z^(t)가 아닌)
Diversity Pruning
- KL divergence를 KL로 나타내면, diversity pruning intervention은 information entropy를 최대화하는 방향으로 Z^(t)의 n개의 응답에서 k개를 선택한다. (선택된 k개는 Z’^(t))
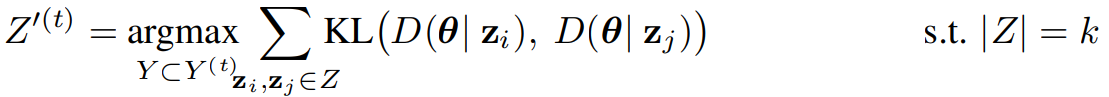
Quality Pruning
- Quality Pruning은 Z^(t)에서 task x와 highest similarity를 갖는 k개의 응답을 선택하는 것을 목표로 한다.
- Diversity Pruning과 유사하지만, quality pruning은 time t에서 n개 중 k개의 응답을 고른다.
- Quality pruning은 diversity에 대해 선택하는 대신, 질문에 대한 k개의 제일 유사한 응답을 고른다. 이는 아래와 같이 수행된다.
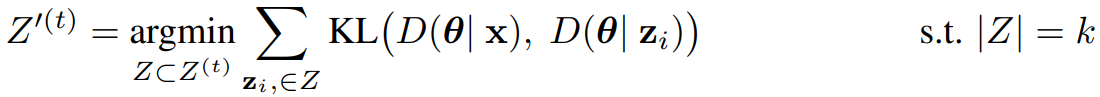
- Quality pruning은 diversity에 대해 선택하는 대신, 질문에 대한 k개의 제일 유사한 응답을 고른다. 이는 아래와 같이 수행된다.
- 실제로 Diversity pruning과 Quality pruning의 수식에서, KL divergence 식을 계산하는 것은 비현실적이다.
- 그러나 sentence embedding을 해당 값을 대체하는 근사치로 사용할 수 있다.(Section C 참고)
- 다음은 모델이 shared misconception을 갖고 있는 경우, diversity pruning이 토론 절차가 해당 잘못된 개념으로 수렴될 가능성을 줄인다는 것을 보여준다.
Theorem 6.1
- 참인 concept이 θ∗이며, n/2 이상의 에이전트가 잘못된 개념 θ′에 대한 shared misconception을 가지고 있다고 가정한다. 이 경우, diversity pruning은 토론이 잘못된 개념 θ′에서 비롯된 답변 y′로 수렴할 확률을 줄인다. 즉, y′ ∼ D(θ′)이다.
Theorem 6.2
- task-answer pair (x,y)에 대해, quality pruning은 토론이 올바른 answer로 수렴할 확률을 증가시킨다.
- 즉, Z^(t)를 시간 t에서 모든 응답 집합이라고 하고, Z’(t)를 quality pruning의 결과라고 한다면, 아래가 성립한다.
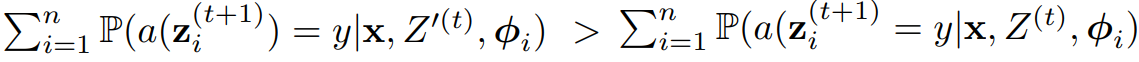
- 즉, Z^(t)를 시간 t에서 모든 응답 집합이라고 하고, Z’(t)를 quality pruning의 결과라고 한다면, 아래가 성립한다.
Remark 6.3
- Theorem 6.1과 6.2에서 보여지듯, diversity pruning은 특정 concept에서 비롯된 잘못된 답변으로 토론이 수렴할 확률을 감소시키며, quality pruning은 옳은 concept에서 비롯된 올바른 답변으로 토론이 수렴할 확률을 증가시킨다.
- 두 intervention은 동시에 사용 가능하며, 이를 통해 잘못된 답변은 멀리하고 올바른 답변으로 토론 절차를 유도할 수 있다.
6.2 Modification Interventions
Misconception Refutation(오해 반박?)
- Z^(t)의 응답 중 어떤 것을 다음 라운드에 사용할지 선택하는 것 외에도, Z^(t)의 응답을 수정할 수도 있다.
- Misconception Refutation은 이 작업을 하며, z_j^(t) 응답을 task x와 더 관련있게 업데이트 하는 것을 목표로 한다.
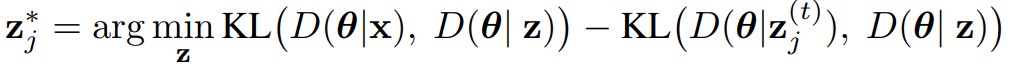
- 앞선 두 개의 pruning과 마찬가지로, 위 식에서 KL divergence를 직접 구하는 것은 불가능하다.
- 따라서 업데이트를 위해 proxy를 사용한다.
- 특히 LLM이 주어진 응답 z_j^(t)를 최소로 수정해 z_j^*를 생성한다.
- 모델은 먼저 응답에서 식별된 misconception과 오류의 목록을 요청받는다
- 이후 misconception의 refutation과 수정된 응답을 모델에게 요청한다.
Theorem 6.4
- task-answer pair (x,y)에 대해, Misconception Refutation은 토론이 올바른 답변으로 수렴할 확률을 증가시킨다.
- 즉, Z^(t), Z*^(t)가 각각 Misconception Refutation 전과 후의 응답이라면 아래가 성립한다.
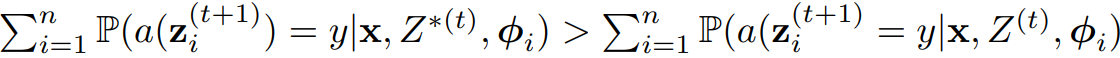
- 즉, Z^(t), Z*^(t)가 각각 Misconception Refutation 전과 후의 응답이라면 아래가 성립한다.
7. Experiments
- 4개의 언어모델 벤치마크로 실험(BoolQ, MMLU, TruthfulQA, MathQ)
- 4개의 LLM 사용(GPT-3.5 Turbo, Llama-2 7B Chat, Llama-3 8B Instruct, Mistral 7B Instruct v0.2)
- 잠재 개념(Θ)의 프록시로 동작하는 sentence embedding은 OpenAI의 ADA-2
- 제안하는 3개의 intervention 조합을 Du et al.[2023]의 SoM(Society of Minds)와 비교
Tyranny of the Majority (다수 의견의 독재)
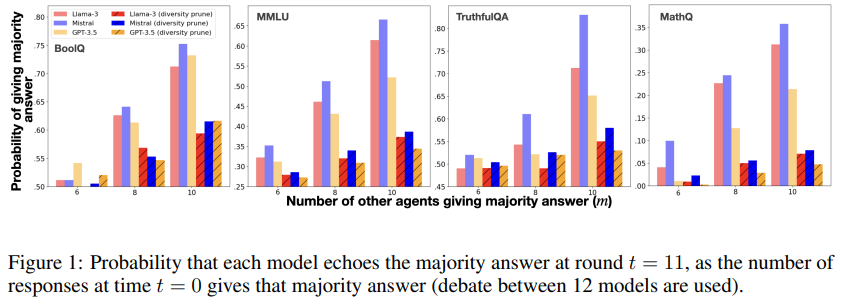
- 모델이 다수 의견을 따를 가능성 조사
- 모델은 echo chamer effect에 민감함이 보여졌다.
- Z^(t)에 majority answer가 포함된 정도가 늘어나면(m이 증가하면) model이 majority answer를 제공할 가능성이 증가한다.
- Figure 1은 k=5의 diversity pruning이 에코 챔버 효과를 감소시킴을 보여준다.
Diversity of Opinions
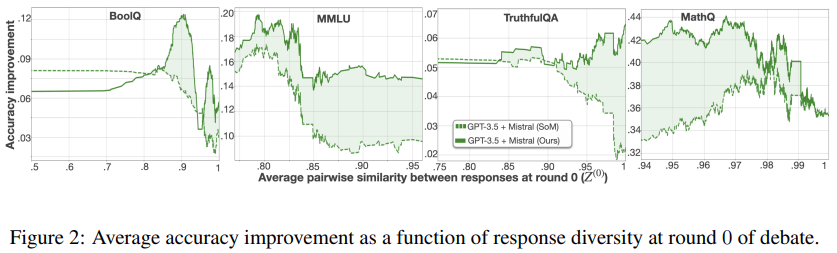
- 제안하는 방법과 SoM이 opinion diversity에 따라 얼마나 효과적인지 조사
- Figure 2: 4개 데이터셋에서 첫 라운드(t=0)의 응답 간 유사성(pairwise 코사인 유사도)에 따른 SoM(점선) 및 제안하는 방법(실선)의 Accuracy Improvement 향상 정도를 나타낸다.
- 첫 라운드에서 응답 간 유사성이 증가할수록 SoM의 효율성이 감소함이 나타난다.
- 이는 Theorem 5.1, 5.2와 같이 intervention 없는 토론에서 응답이 너무 유사하면 덜 효과적이라는 것과 일치한다.
- 제안하는 방법의 SoM대비 개선은 모델 의견이 유사할 수록 더 커진다.(MathQ는 반례)
Debate Interventions
- 3가지의 Intervention의 조합이 얼마나 효과적인지 조사
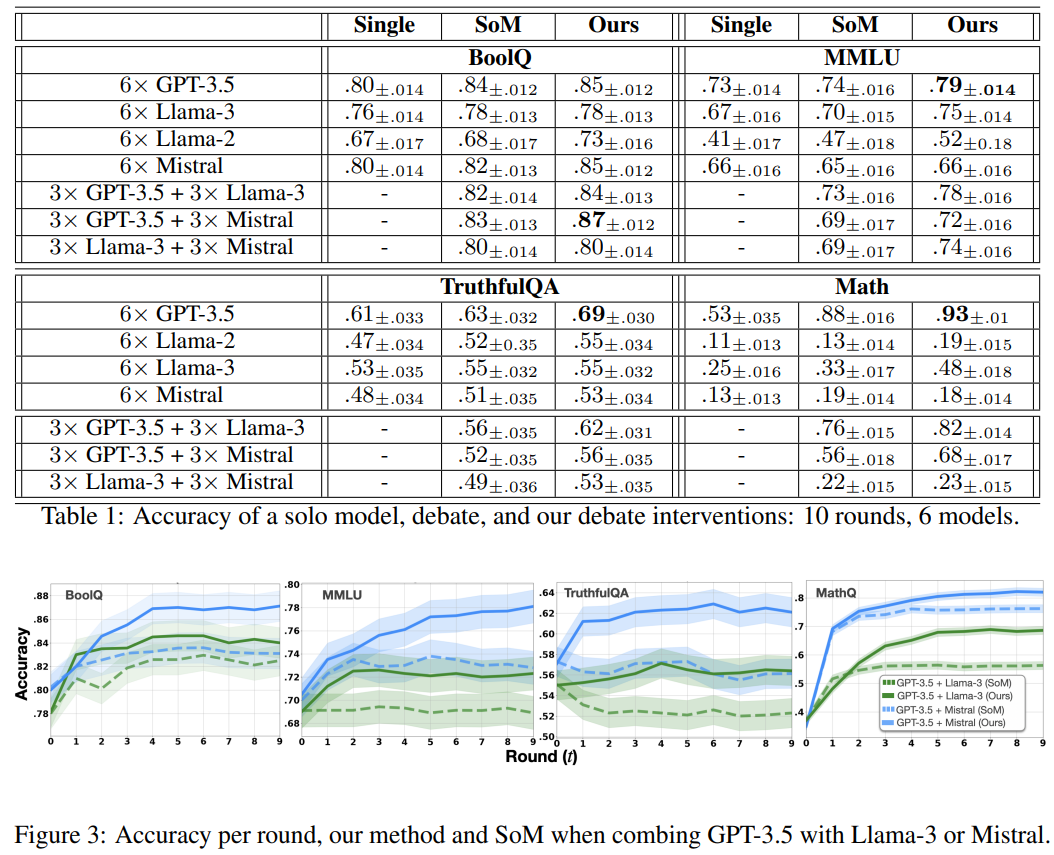
- Figure 3: 제안하는 방법과 SoM의 각 라운드별 성능
- 제안하는 방법의 우위는 토론 후반 라운드에서 두드러짐
- Table 1: 단일 모델, SoM, 제안하는 방법의 조합에 대한 결과
- 모든 경우에서 제안하는 방법은 SoM과 비교해 Competitive or superior
- Supplement의 Table 3을 보면 각 intervention을 개별적으로 적용했을 때보다 세 가지를 동시에 적용할 때 가장 효과가 좋음을 보인다.
- 실제로 일부 intervention은 단독으로 사용되면 토론에 부정적인 영향을 줄 수 있으며, 이는 각 intervention이 상호 보완적으로 설계되었기 때문에 예상되는 결과이다.
8. Limitations
- 제안하는 이론적 결과는 latent concept space를 활용하지만, 실제로는 이런 공간에 접근할 수 없는 경우가 많아 sentence embedding과 같은 대체 proxy를 사용해야 한다.
- 수학적 질문 같이 sentence embedding이 덜 의미있는 도메인에서는 제안하는 방법의 효과가 떨어진다.
- 제안하는 intervention들은 토론 절차의 추론 시간을 증가시킬 수 있다.
- 주요 원인은 misconception refutation으로, 이는 각 참여자에게 여러번의 re-prompting을 요구하기 때문이다.
9. Conclusion
- Multi-agent debate는 LLM response의 효율성을 향상시키는데 효과적이다.
- 그러나 토론은 본질적으로 tryanny of the majority나 shared misconception같은 문제에 취약하다.
- 본 연구에서는 이론적 토론 프레임워크를 활용해 이러한 문제를 완화하고 토론의 성능을 향상시키는 interventions를 확립했다.

Anyone can be anything ... with agent!