
By Microsoft Research Team
From arXiv, 2024
0. Abstract
- Transformer는 무관한 context에도 지나치게 attention 연산이 수행되는 경향이 있다.
- 우리가 제안하는 Diff Transformer는 ‘유’관한 context에 대한 attention을 극대화하면서도 노이즈를 줄인다.
- Differential attention은 두 개의 서로 다른 softmax 함수로 계산된 attention 가중치 행렬(map)의 차를 구해 attention score를 구한다.
- 모델이나 토큰 크기를 확장했을 떄 기존 transformer보다 성능이 우수하며, long-context modeling같은 실용적인 task에서 성능이 특히 좋았다.
- In-context learning에서는 robustness 도 좋았다.
1. Introduction
- Transformer의 중심에는 softmax를 통해 토큰의 중요성을 순서대로 평가하는 attention machanism이 있다.
- 그러나 최근 연구에 따르면 LLM은 context에서 key info를 찾는데 어려움을 겪고 있다.
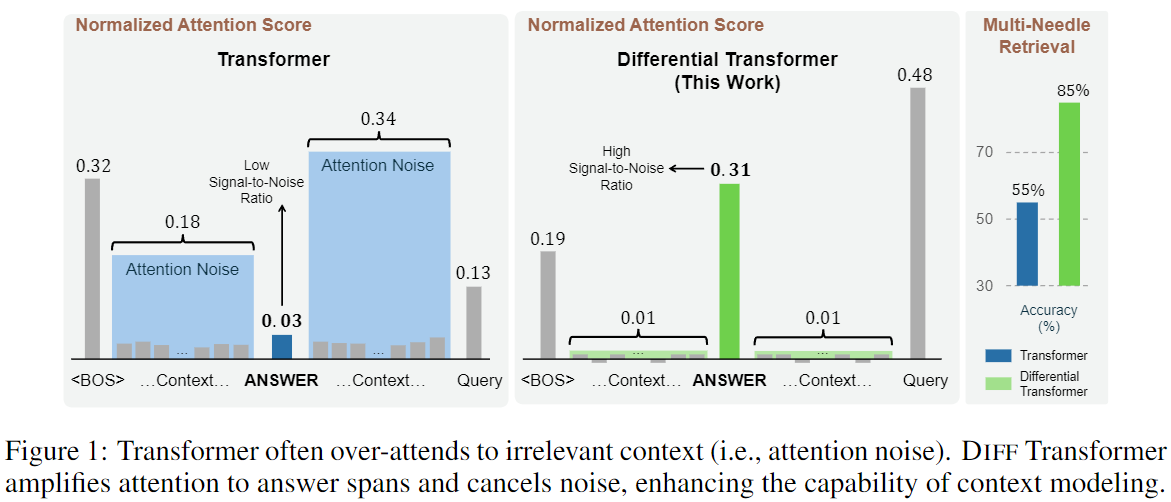
-
Figure 1의 왼쪽 그림을 보면, Transformer는 document 가운데에 있는 정답에 적은 비율의 attention score만을 할당했으며, 무관한 context에도 불균형하게 집중한 것을 알 수 있다.
-
이렇듯 Transformer는 정답이 아닌 context에 attention score를 할당해 올바른 정답을 놓치고 있으며, 이런 잘못된 score를 논문에서는 ‘attention noise’라고 한다.
-
Diff Transformer에서는 query와 key vector를 두 그룹으로 나누고, 두 개의 서로 다른 softmax attention map을 계산한다.
- 그리고 그 두 값의 차가 attention score로 사용된다.
- 노이즈 캔슬링 헤드폰이 두 신호의 차이를 사용하는 것과 비슷하다.
-
Figure 1의 가운데 그림을 보면, Diff Transformer의 attention score 점수가 transformer에 비해 정답에 휠씬 높은 점수를 할당하고 관련 없는 컨텍스트에는 낮은 점수를 할당하는 것을 알 수 있다.
-
Figure 1의 오른쪽 그림을 보면 Diff transformer는 Retreval 성능을 많이 향상시킨다.
-
Diff Transformer는 language modeling에서도 transformer의 65% 모델 사이즈와 training 토큰으로 유사한 language modeling 성능을 낸다.
-
또한 Diff transformer는 transformer의 여러 downstream task에서도 좋은 성능을 낸다.
- Long-sequence evualuation을 통해 증가하는 context를 처리하는데 효율적임을 보인다.
- Key information retrieval, Hallucination mitigation, Incontext learning에서 기존 transformer보다 높은 성능을 보인다.
-
또한 Model activation을 위한 outlier를 줄여 quntization을 위한 여지를 제공한다.
2.1 Differential Transformer
- Attention은 query와 key vector를 사용해 attention score를 계산하고, 이후 value vector의 weighted sum을 구한다.
- Diff Transformer의 중요한 설계는 두 개의 softmax 함수를 사용해 attention score의 노이즈를 줄이는 것이다.
- 입력이 X ∈ R^(N x d_model)일 때 이를 q, k, v 값으로 projection하여 Q_1, Q_2, K_1, K_2 ∈ R^(N x d), V ∈ R^(N x 2d) 을 얻는다.
- Differential Attention 함수인 DiffAttn()은 아래와 같이 출력을 계산한다
- 3개의 W(가중치)는 parameter이며, λ는 학습가능한 스칼라값이다.
- λ는 아래와 같이 re-parameterize된다.
-
앞의 4개의 λ는 학습 가능한 벡터이며, λ_init ∈ (0,1)은 λ 초기화를 위한 상수이다.
-
Differential attention은 두 softmax attention 함수의 차를 통해 attention noise를 제거한다.
- 노이즈 캔슬링 헤드폰의 설계 원리와 유사
-
FlashAttention을 직접 재사용할 수도 있다.
2.1.1 Multi-Head Differential Attention
- Diff Transformer는 multi-head mechanism도 사용한다.
- 헤드 수 h에 대해 서로 다른 projection matrix W_i^Q,W_i^K,W_i^V(i∈[1,h])를 사용한다.
- 각 head는 아래와 같이 계산된다.
- 헤드의 출력은 정규화된 뒤 projection되어 아래와 같은 방식으로 multihead diff attention 연산을 수행한다.
- head의 수 h는 d_model / 2d로 잡았다(d는 transformer의 head 차원).
- 이 방식은 결과적으로 모델이 서로 다른 유형의 유효한 정보를 병렬로 집중할 수 있게 해서 중요한 문맥을 더 잘 잡을 수 있게 한 것이다.
2.1.2 Headwise Normalization
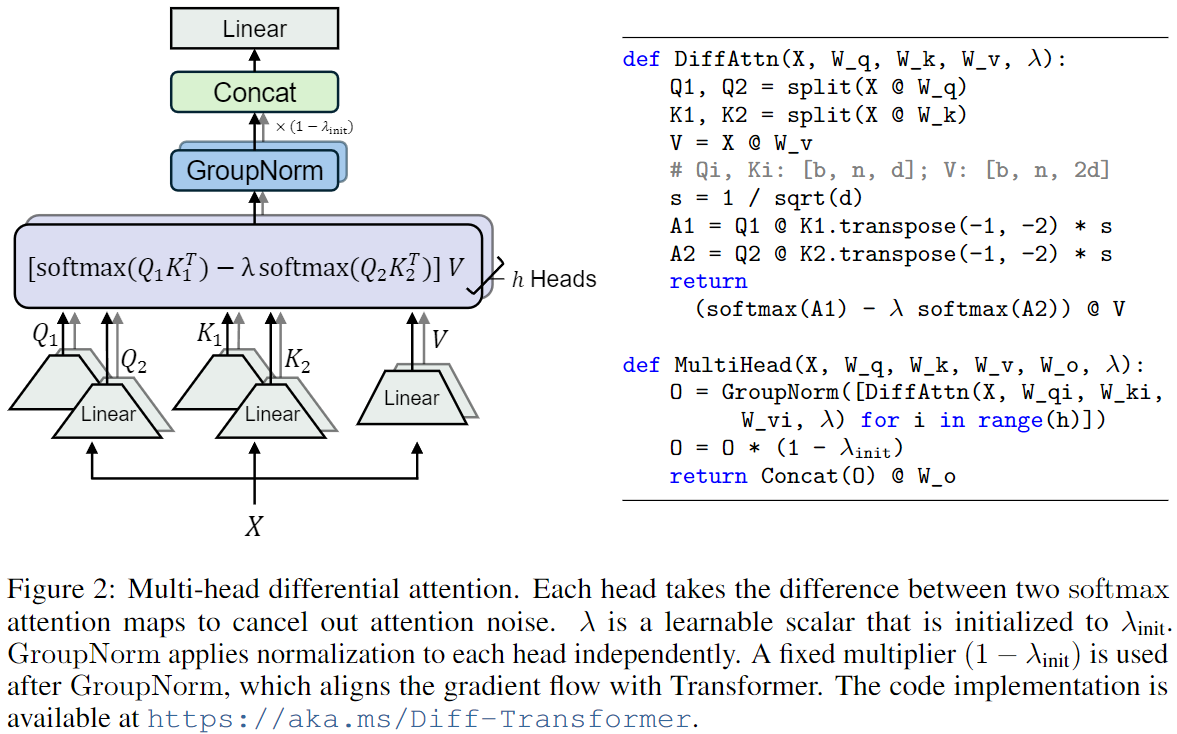
- Figure 2에서는 Layer Normalization이 각 head에 독립적으로 적용되었다는 것을 강조하기 위해 GroupNorm을 사용한다.
- Diff attention은 sparse한 pattern을 갖는 경향이 있으므로, 각 헤드의 통계적 정보가 다양할 수 있다.
- 따라서 헤드 별 정규화는 gradient statistics를 개선하고 학습 과정을 안정화하는데 도움이 된다.
2.2 Overall Architecture
- 전체 구조는 L개의 레이어를 쌓았으며, 각 레이어는 multi-head diff attention 모듈과 feed-forward network 모듈을 포함한다.
- 정리)
- Multi head diff attention은 유효한 context에 대한 attention은 amplify하고 noise는 제거하는 attention machanism이다.
- Feed foward network는 기존 transformer 아키텍처에서 사용되는 FFN과 유사한 것으로 보인다.
- Diff Transformer 레이어는 다음과 같이 표현 가능하다.
- LN(): RMSNorm Layer Normalization, SwiGLU(): SwiGLU Activation fuction
3. Experiments
3.1 Language Modeling Evaluation
- 3B 크기의 Diff Transformer를 1T 토큰에 학습시킨 모델의 언어 모델링 성능을 기존 Transformer-based 모델을 350B 토큰에 학습한 모델과 비교한다.
- SableLM, OpenLLaMA 등의 Transformer 기반 모델과 여러 다운스트림 작업에서 비교한다.
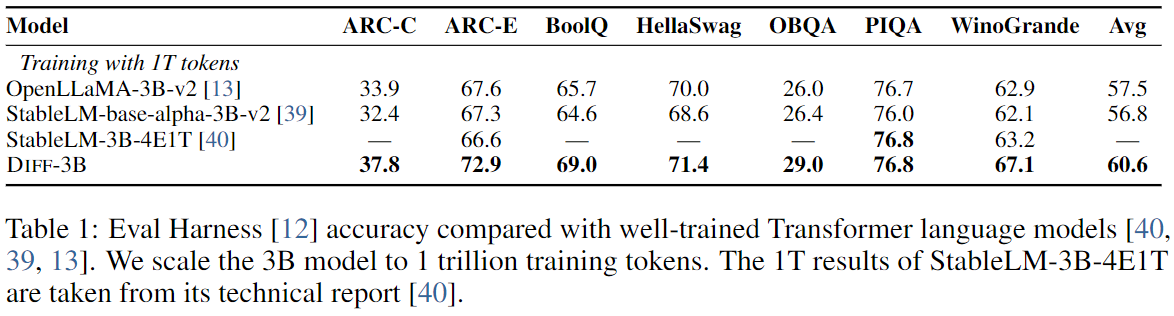
- Diff Transformer는 동일 사이즈의 Transformer보다 여러가지 task에서 우수한 성능을 보였다.
3.2 Scalability Compared with Transformer
- Diff Transformer와 Transformer의 모델 크기와 훈련 토큰 수에 따른 scalability를 평가했다.
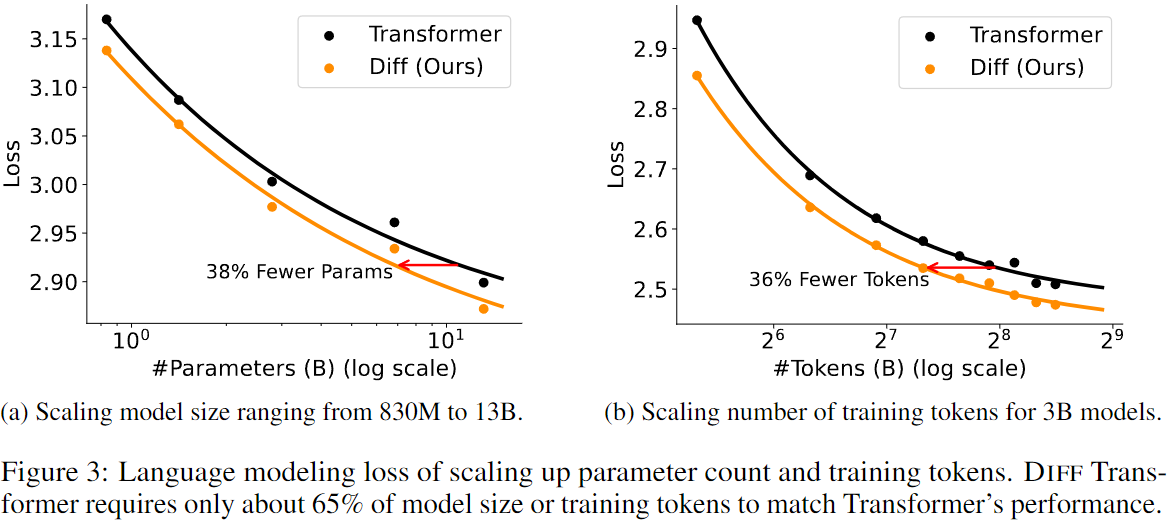
3.2.1 Scaling Model Size
- 830M부터 13B까지 모델 파라미터를 단계적으로 확장하여 비교했다.
- Figure 3(a)에 따르면, 6.8B Diff Transformer가 11B 크기의 기존 Transformer와 유사한 성능을 보였다.
3.2.2 Scaling Training Tokens
- 3B 크기 모델을 360B 토큰까지 학습해 평가했으며, Diff Transformer는 Transformer 대비 63.7%의 토큰만으로도 유사한 성능을 달성했다.
3.3 Long-Context Evaluation
- Diff Transformer는 context 길이를 64K까지 확장하여 long context에서의 성능을 평가했다.
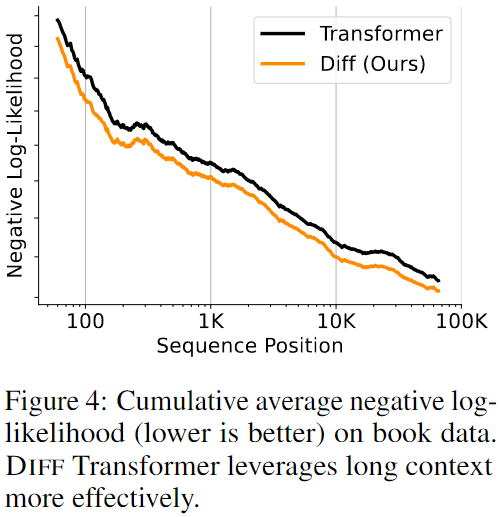
- 결과적으로 Diff Transformer는 Transformer보다 낮은 Negative Log Likelihood를 기록하며 long context에서 효과적임을 입증했다.
3.4 Key Information Retrieval
- Needle-In-A-Haystack test를 통해 Diff Transformer와 Transformer의 Information Extract 능력을 평가했다.
3.4.1, 3.4.2 Retrieve from 4K & 64K Context Length
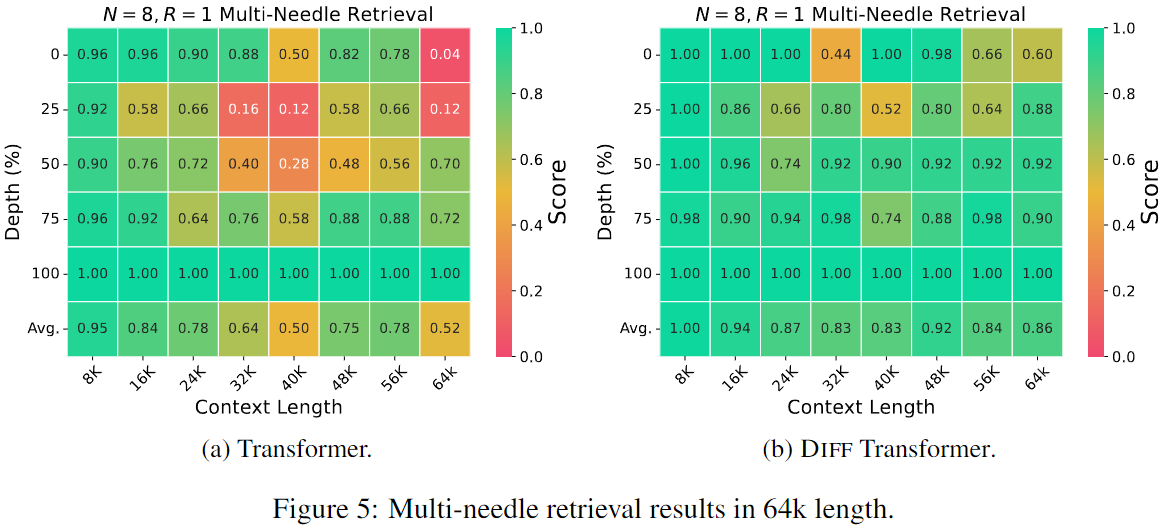
- 4K와 64K 길이의 문맥에서 Multi-needle retrieval test에서 Diff Transformer는 Transformer보다 높은 accuracy를 유지했으며, 중요한 정보가 context의 첫 절반에 위치할 때에는 Transformer보다 76% 이상 개선된 성능을 보였다.
3.4.3 Attention Score Analysis
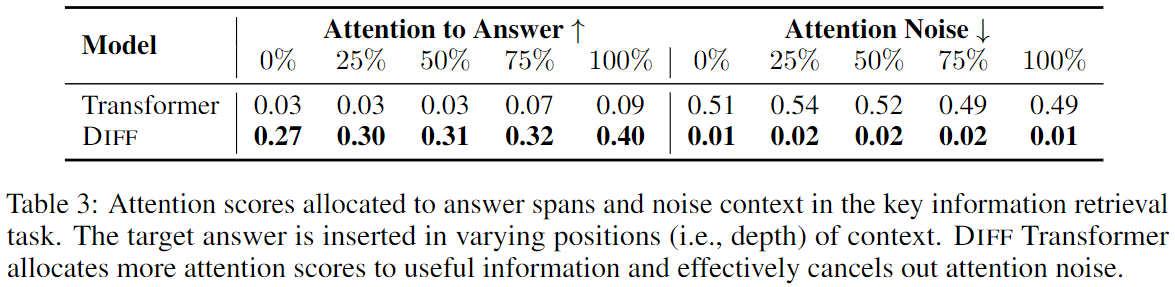
- Diff Transformer는 정답 구간에 더 높은 attention score를 할당하고, noise에 대한 attention은 낮추는 것으로 나타났다.
3.5 In-context Learning
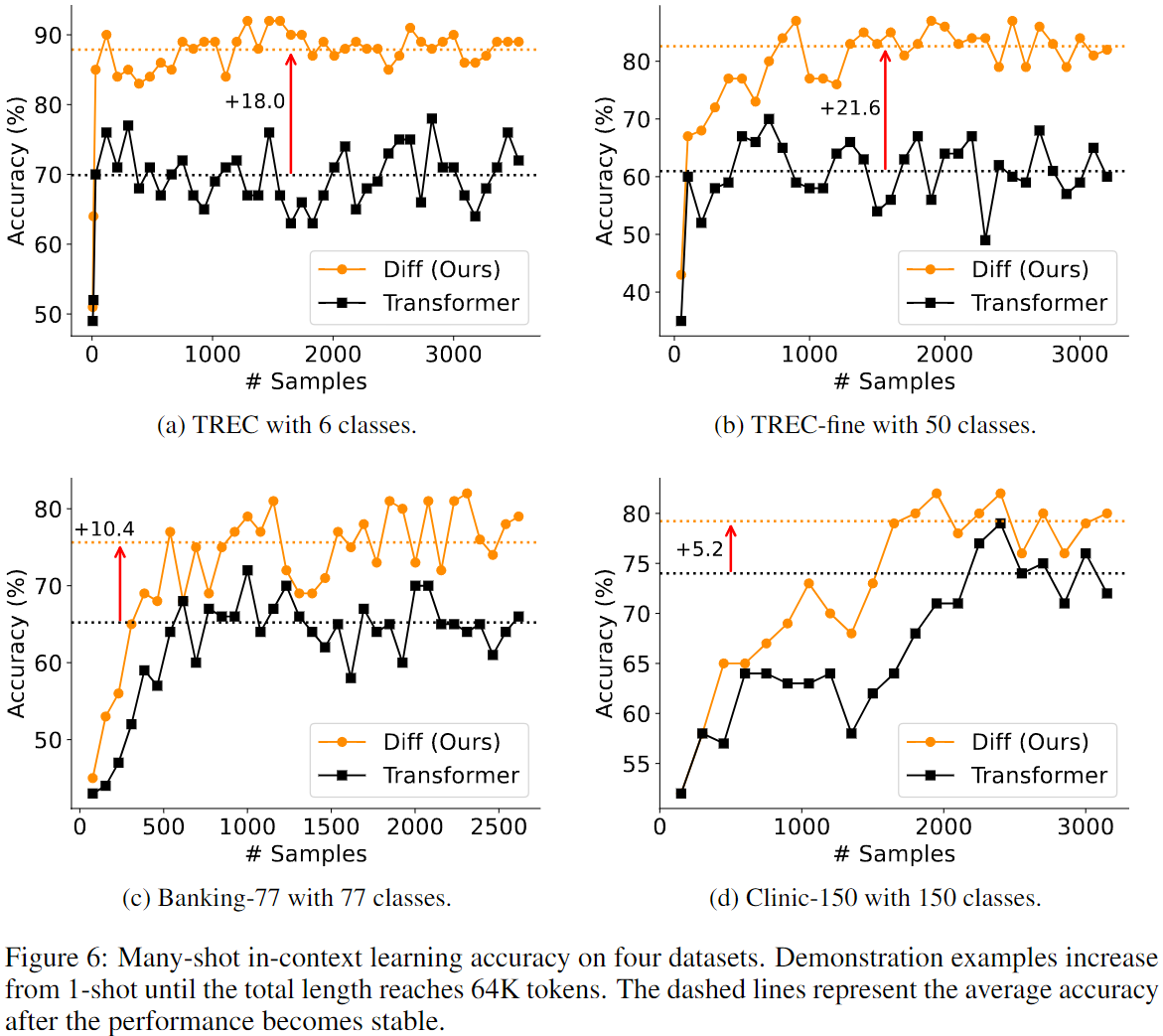
- Diff Transformer는 few shot classification 작업에서 Transformer보다 더 높은 accuracy를 기록했으며,
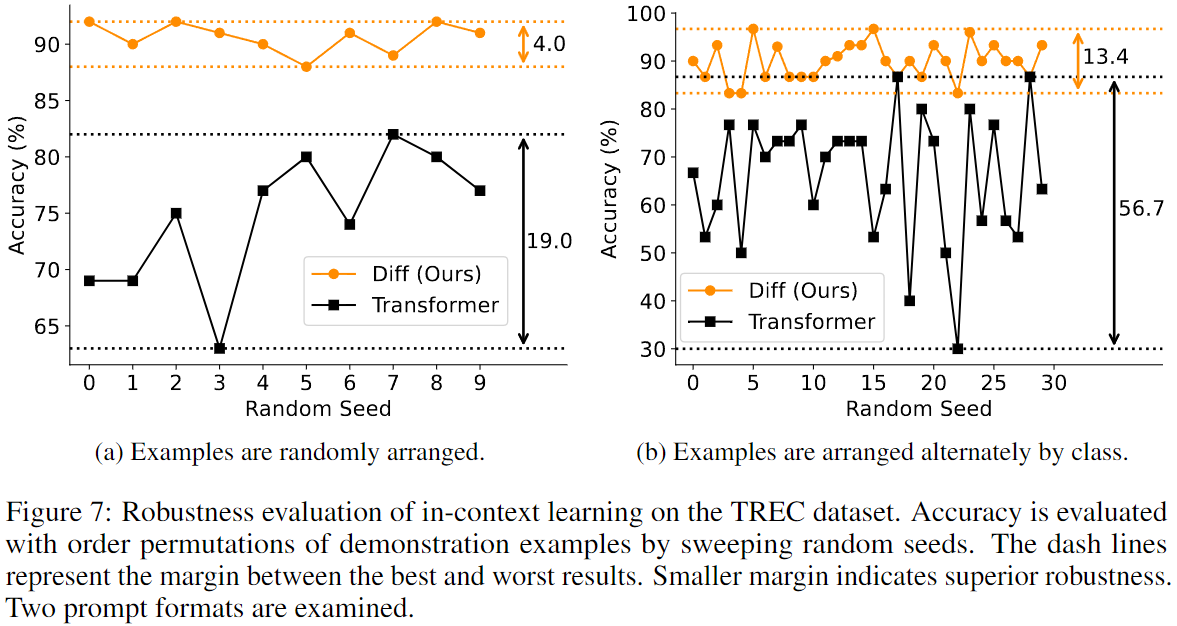
- 컨텍스트 내의 example 순서의 변동에 덜 민감한 robust한 성능을 보였다.
3.6 Contextual Hallucination Evaluation
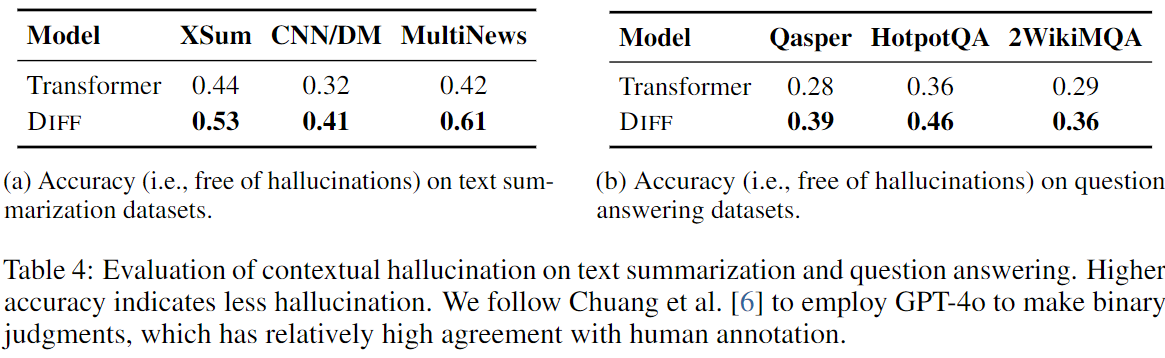
- Diff Transformer는 Summarization과 QA task에서 Transformer보다 contextual hallucination을 더 많이 줄였다. (Table 4)
- 이는 Diff Transformer가 불필요한 context에 덜 분산되고 중요한 정보에 더 집중할 수 있기 때문으로 분석된다.
3.7 Activation Outliers Anlaysis
- 참고) Activation Outliers(활성화 이상치): 신경망에서 뉴런이 비정상적으로 큰 값이나 작은 값을 출력하는 현상
- 뉴런이 지나치게 활성화되거나, 가중치나 편향이 비정상적으로 커지거나 작아지거나, 데이터 자체가 이상치거나, 활성화 함수 자체의 문제(ReLU는 음수 0으로 보내니까) 등등..
- 일반화 성능 저하되고 훈련이 불안정적으로 변하는 등의 문제가 생긴다!

- Diff Transformer는 Transformer에 비해 Activation Outliers의 크기를 줄였으며, 이로 인해 양자화가 더 효율적으로 가능함을 확인 했다.
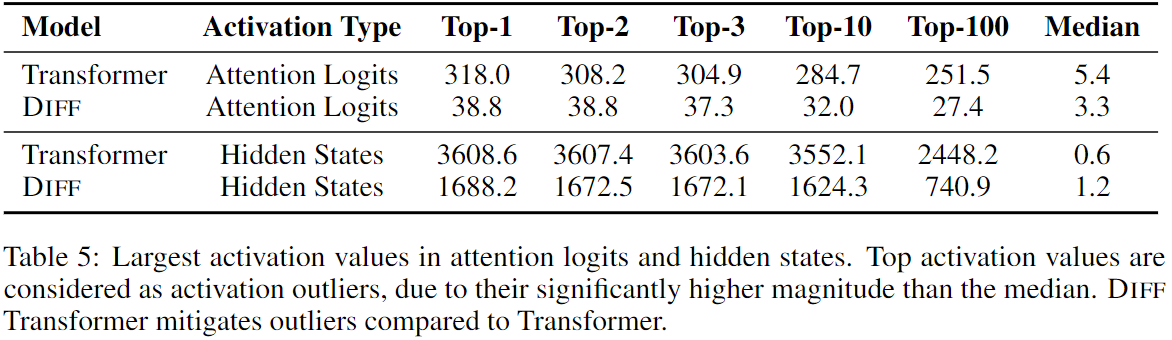
- Activation Outliers 통계에서 Diff Transformer는 Attention Logits과 Hidden States에서 Largest Activation Values가 낮아졌으며, 4Bit 양자화에서도 Transformer보다 25% 높은 정확도를 기록했다.
3.8 Ablation Studies
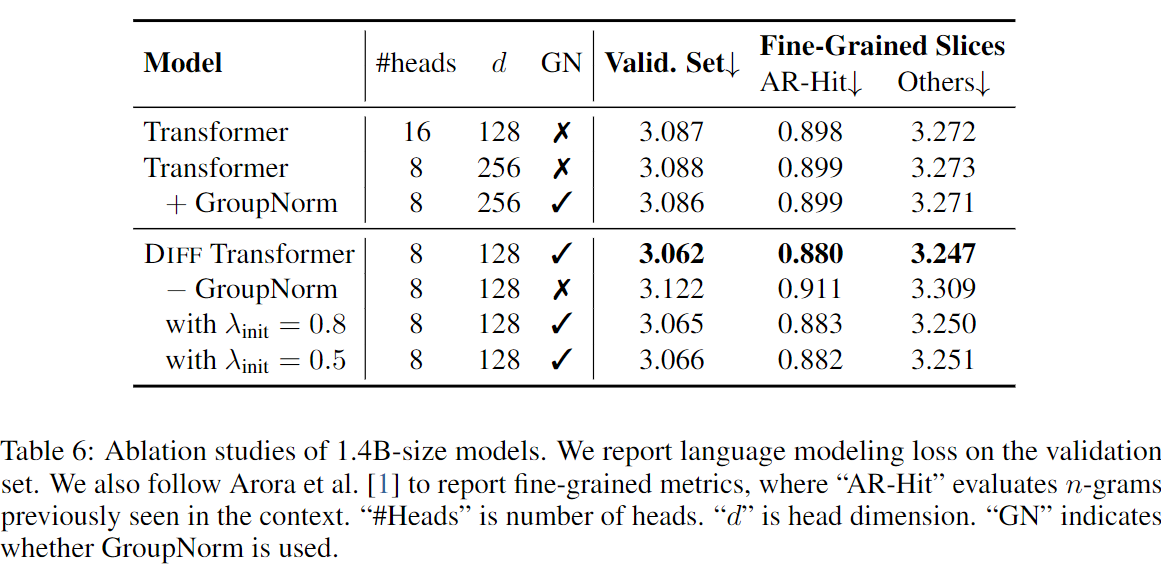
- Diff Transformer의 설계 요소를 분석하기 위해 다양한 소거 연구를 진행했다.
- GroupNorm은 MultiHead의 다양한 값들을 normalizing 하는데 중요한 역할을 했으며, λ 초기화 에서 값의 변화에도 모델 성능이 robust함을 확인했다.
- 모델 성능의 개선은 주로 differential attention mechanism에서 기인하며, configuration이나 normalization 보다는 differential attention mechanism 자체가 중요하다고 분석되었다.
4. Conclusion
- DIFF Transformer는 관련 context에 대한 attention을 amplify하고 noise를 줄이는 differential attention mechanism을 통해 Transformer보다 뛰어난 성능을 보인다.
- 이는 scalability, long context modeling, key information retrieval, hallucination mitigation, in-context learning, reduction of activation outliers과 같은 여러 측면에서 성능 향상을 보인다
- 이러한 결과를 바탕으로, DIFF Transformer는 대규모 언어 모델 아키텍처로서 유망하며, 향후 low-bit attention kernel 개발과 캐시 압축에도 활용 가능성이 높아 보인다.
