[논문 리뷰] Retrieval-Augmented Generation for Large Language Models: A Survey (2024)
Paper Review
목록 보기
8/15
From arXiv, 2024
Abstract
- RAG는 외부 DB의 지식을 통합함으로써 LLM의 문제들(환각, 최신 지식 부재, 불투명성, 추적 불가능)을 해결할 수 있는 해결책으로 떠오르고 있다.
- RAG는 생성물의 정확성과 신뢰성을 높여주고, 지식의 지속적인 업데이트와 특정 도메인의 정보 통합을 가능하게 한다.
Introduction
- LLM은 훈련 데이터를 벗어난 쿼리나 최신 정보에 대해 생성할 때 환각(hallucinations)을 일으키는 문제가 두드러진다.
- RAG는 외부 지식에서 의미적 유사성을 계산해 관련된 document chunks를 검색하여 LLM 성능을 향상시킨다. 이는 부정확한 콘텐츠를 생성하는 문제를 줄인다.
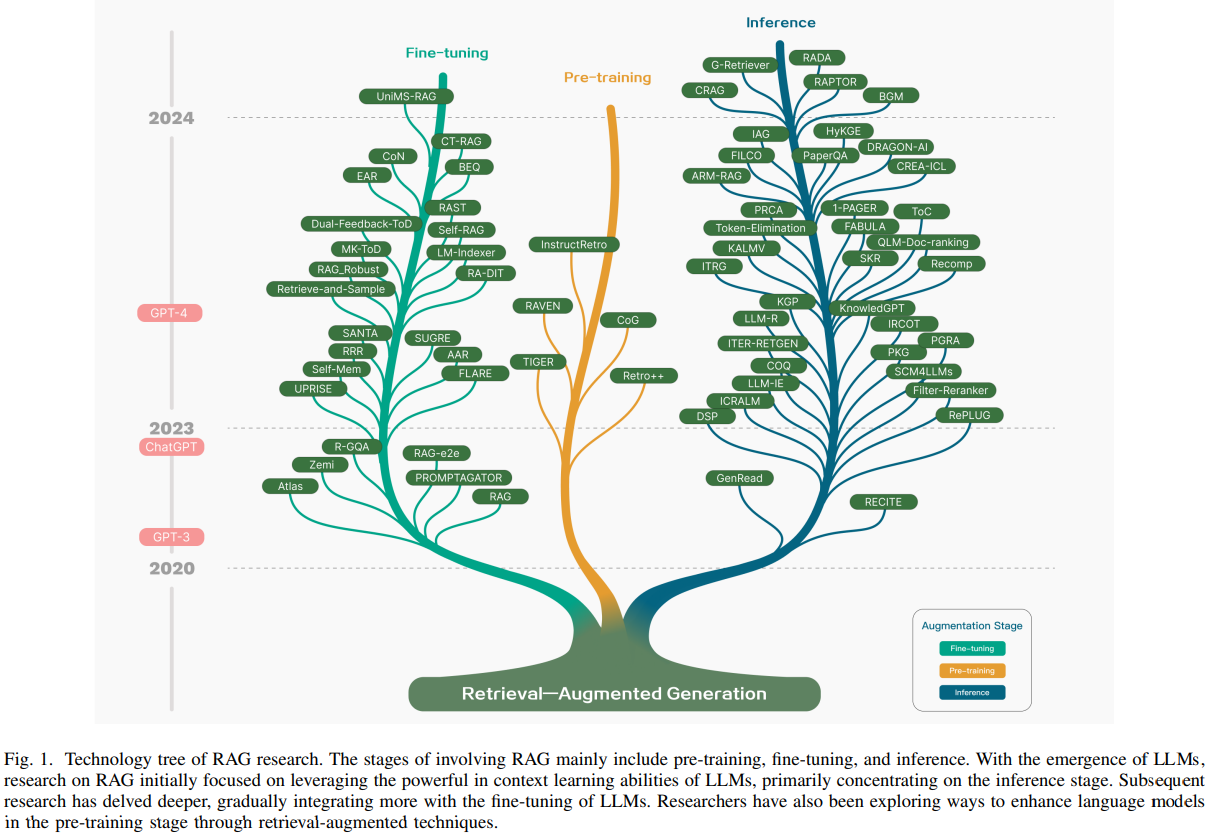
- RAG 기술은 최근 급격히 발전해왔으며, 관련 연구를 요약한 기술 트리는 Figure 1과 같다.
- 이 RAG 발전 방향은 단계적 특징을 갖는다.
- 초기 단계는 Tansformer 아키텍처의 부상과 함께 시작됐으며, 추가지식을 PreTraining Models(PTM)을 통해 성능을 향상시키는 데 중점을 두었다. 이 단계는 pretrain 기법을 개선하기 위한 작업이 특징이었다.
- 이후 ChatGPT의 등장으로 LLM의 In-Context Learning(ICL) 능력이 입증되면서 큰 전환점을 맞았다. RAG 연구는 추론 단계에서 더 복잡하고 지식 집약적인 작업을 해결하기 위해 LLM에 더 나은 정보를 제공하는 방향으로 전환되었고, RAG의 연구가 빠르게 진전되었다.
Overview of RAG
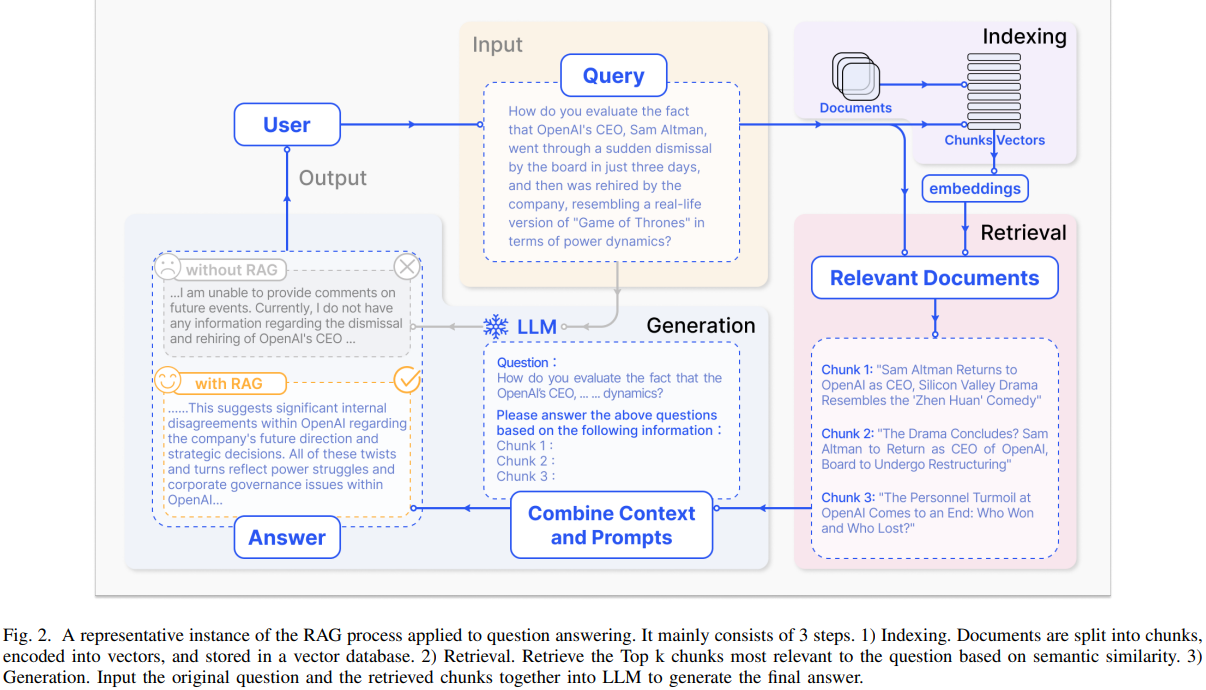
- RAG의 typical한 응용사례는 Figure 2와 같다.
- User는 최신 정보에 대한 질문을 한다. LLM의 사전 학습 데이터만으로는 정보를 제공할 수 없다.
- RAG는 외부 데이버베이스에서 정보(기사)를 검색하고 통합함으로써 정보 격차를 메운다.
- 이러한 정보는 원래 질문과 결합되어 LLM이 well-informed된 답변을 생성할 수 있는 prompt를 만든다.
- 논문에서는 RAG 연구 패러다임을 세 단계로 분류한다. Advanced와 Modular RAG의 개발은 Naive RAG의 단점들을 해결하기 위한 대응으로 이루어졌다.
1. Naive RAG
2. Advanced RAG
3. Modular RAG
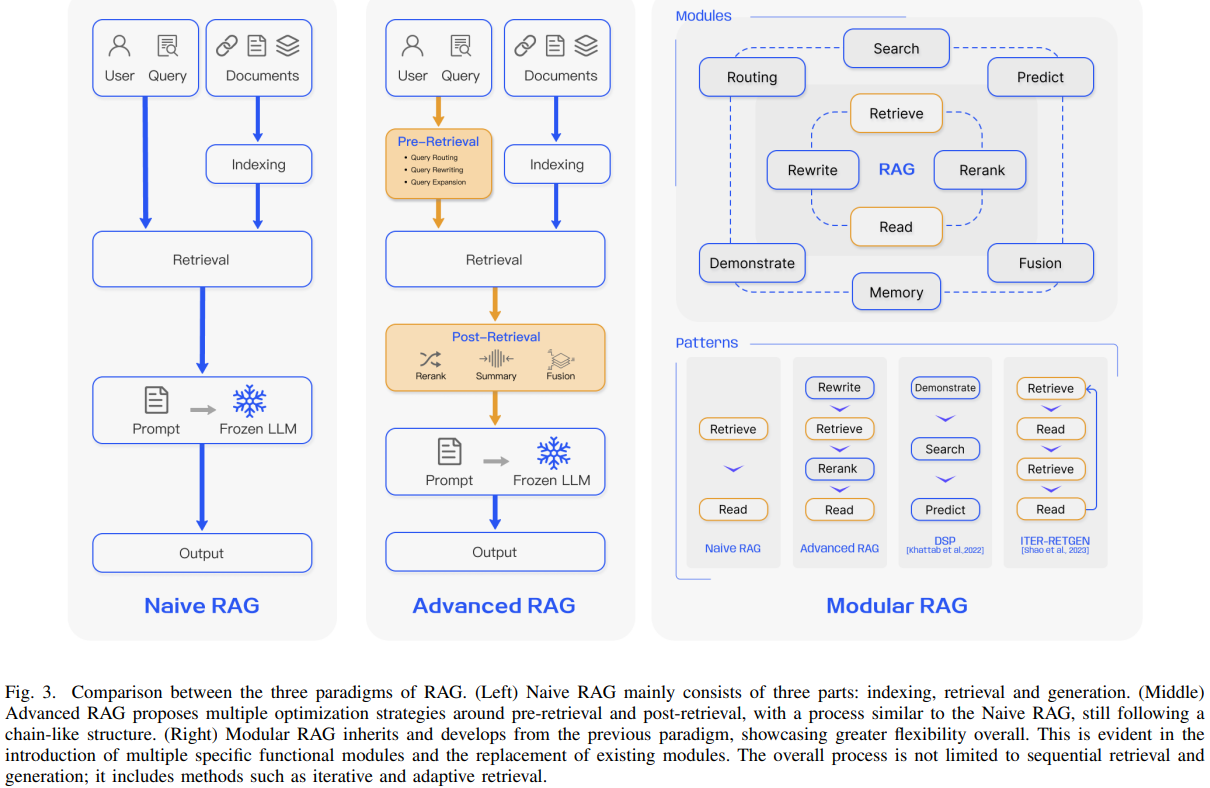
Naive RAG
- ChatGPT 도입 이후 주목받은 초기 RAG 방법론으로, indexing, retrieval, generation을 포함하는 전통적인 프로세스를 사용한다.
- Indexing
- PDF, HTML, Word, Markdown 등의 원시 데이터로부터 raw data를 추출해 uniform한 plain text format으로 변환한다.
- LM의 context 처리 한계를 고려해 텍스트는 더 작은 chunk 단위로 분할된다. 이후 임베딩 모델을 통해 벡터 표현으로 인코딩하고, 벡터 데이터베이스에 저장한다.
- 이 단계는 retrieval 단계에서 유사성 검색을 효율적으로 수행하게 하는 중요한 단계이다.
- Retrieval
- Indexing에서와 동일한 임베딩 모델로 User의 query도 vertor representation으로 변환한다.
- 이후 query vector와 indexed chunk vector 간에 유사성 점수를 계산한다.
- 유사성 점수 상위 k개의 chunk를 우선적으로 검색하며, 이후 이 chunk들은 expanded context로 prompt에 사용된다.
- Generation
- 쿼리와 검색된 문서들이 합쳐져 하나의 prompt가 되고, LLM은 response를 생성한다.
- 그러나 Naive RAG는 단점이 존재한다.
- Retrieval Challenges: retrieval 단계에서 precision과 recall의 어려움을 겪는 경우가 많아 잘못된 정보나 관련성이 낮은 chunk를 선택하거나 중요한 정보를 빠트리는 문제가 발생한다.
- Generation Difficulties: response 생성 과정에서 모델은 hallucination 문제에 빠질 수 있는데, 이는 retrieval된 context에 뒷받침되지 않는 내용을 생성하는 경우다. 또한 생성된 응답이 관련성이 없거나 편향된 내용을 포함하여 응답의 품질과 신뢰성을 떨어트릴 수 있다.
- Augmentation Hurdles: retrieval된 정보를 다른 task와 통합하는 것은 어려울 수 있으며, 때로는 관련없거나 일관성없는 output이 나올 수 있다. 또한 여러 source에서 비슷한 정보가 검색될 경우 반복적인 응답을 생성할 수도 있다. 복잡한 문제를 만났을 때에는 기존의 쿼리기반 단일 검색만으로는 충분한 context info를 얻기 어려울 수 있다.
- 또한 generation model이 augmented info에 과도하게 의존해 검색된 내용을 반복해 의미있는 정보를 제공하지 못할 수 있다.
Advanced RAG
- Advanced RAG는 Naive RAG의 한계를 극복하기 위해 pre-retrieval과 post-retrieval 기법을 도입한다. Indexing 성능을 개선하기 위해서 sliding window, fine-grained segmentation, 메타데이터 통합을 도입한다. 또한 retrieval process를 최적화하기 위해 여러가지 최적화 방법을 도입한다.
- Pre-retrieval process
- 이 단계에서는 indexing structure와 original query를 최적화하는데 중점을 둔다.
- 인덱싱 최적화의 goal은 인덱싱 콘텐츠의 품질 향상으로, 이를 위해 데이터 세분화 개선, 인덱스 구조 최적화, 메타데이터 추가, 정렬 최적화, mixed retrieval 등의 기법을 사용한다.
- 쿼리 최적화의 목표는 user의 원래 질문을 더욱 명확하고 검색 작업에 적합하게 만드는 것으로, 이를 위해 쿼리 재작성, 쿼리 변환, 쿼리 확장 등의 기법을 사용한다.
- Post-retrieval process
- 이 단계에서는 Chunk reranking과 Context compressing이 많이 사용된다.
- 검색된 정보를 재정렬하여 가장 관련성이 높은 내용을 프롬프트의 가장자리로 재배치하는 것이 핵심이다.
Modular RAG
- Modular RAG는 앞선 구조보다 더 발전을 이루며, 더 뛰어난 적응성과 유연성을 제공한다. 유사성 검색을 위한 검색 모듈을 추가하거나, fine tuning을 통해 retrieval을 개선하는 등 다양한 전략을 통합해 각 component를 향상시킨다. 특정한 문제를 해결하기 위해 RAG 모듈을 재구성하거나 RAG 파이프라인을 재배열하기도 한다.
- New Modules
- Search module: LLM이 생성한 코드와 query language를 통해 여러 data sources(search engines, DB, knowledge graphs)에 직접 접근해서 검색한다.
- 기존 RAG는 vector 기반 유사성 검사를 하는 것과 대비됨
- RAG Fusion: single query로는 찾기 어려운 정보를 parallel vector searches와 intelligent re-ranking을 통해 multi-query strategy를 도입하여 기존 검색의 한계를 해결한다.
- Memory Module: LLM의 메모리를 활용해 검색을 유도하며, 반복적인 self-enhancement를 통해 텍스트가 데이터 분포와 더 유사해지도록 한다.
- Routing: 다양한 data source를 탐색해 query가 어떤 data를 원하는지 그 최적의 경로를 찾는다.
- Predict module: LLM을 통해 직접 context를 생성함으로써 노이즈와 중복을 줄이고 정확성을 높인다.
- Task Adapter: RAG를 down stream에 맞게 조정한다.
- Search module: LLM이 생성한 코드와 query language를 통해 여러 data sources(search engines, DB, knowledge graphs)에 직접 접근해서 검색한다.
- New Patterns
- Modular RAG는 모듈을 교체하거나 reconfiguration하여 specific challenge를 해결할 수 있는 적응성이 있다.
- 이는 단순한 "Retrieval"과 "Read" 메커니즘에 의존하는 Naive RAG 및 Advanced RAG의 fixed structure를 넘어선 것이다.
- Rewrite-Retrieve-Read 모델, Generate-Read 방식, Recite-Read, Hybrid retrieval strategies, Hypothetical Document Embeddings(HyDE) 등의 기법은 Retrieval의 성능을 강화하는데 초첨을 맞춘다.
- 모듈의 배열이나 모듈 간의 interation을 조정하는 기법들도 존재한다. Demonstrate-Search-Predict(DSP) framework, ITERRETGEN은 각 모듈의 기능을 강화해 시너지를 높인다. FLARE와 Self-RAG은 RAG의 유연성을 높인다.
RAG vs. Fine-tuning
- RAG는 fine-tuning과 프롬프트 엔지니어링과 자주 비교된다. 각 방법들은 Figure 4와 같이 고유한 특성을 갖고 있다.
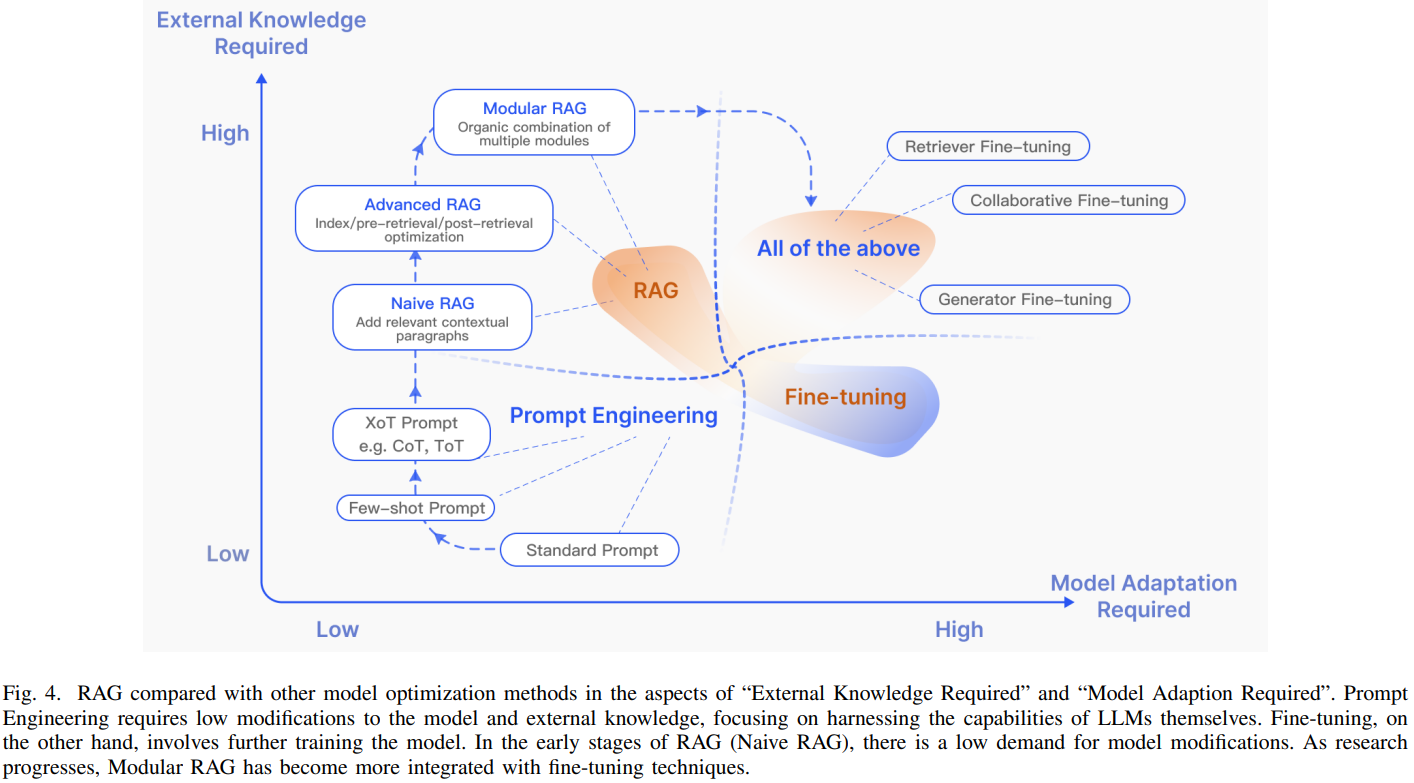
- Figure 4에서 각 축은 model adaptation이 필요한지, 외부 지식이 필요한지를 의미한다.
- 프롬프트 엔지니어링은 외부지식과 model adaptation이 거의 필요하지 않은 상태에서 모델의 내재된 기능을 사용한다.
- RAG는 정보 검색을 위해 딱 맞는 교과서를 제공하는 것과 비슷하며, 정확한 정보를 검색하는 것에 이상적이다.
- Fine-tuning은 학생이 지식을 습득하는 것에 비유되며, 특정한 구조나 형식을 copy해야 하는 시나리오에 적합하다.
- RAG는 latency가 길고, 데이터 검색에서 윤리적 고려사항이 동반된다.
- Fine tuning은 정적이며 업데이트를 위해서는 재학습이 필요하지만, 모델의 action과 style을 커스터마이징할 수 있다. 데이터셋 준비 및 학습에 상당한 resource를 요구하며, 환각을 줄일 수 있지만 익숙하지 않은 데이터에 대해서는 어려움을 겪을 수 있다.
- RAG와 FT를 평가한 결과, RAG는 훈련 중의 기존 지식과 새로운 지식 모두에서 우수한 성능을 보인다. RAG와 FT는 상호 보완적인 관계에 있으며 서로를 보완해 모델의 역량을 다양한 수준에서 향상시킬 수 있다. 일부의 경우에는 둘을 결합해 사용할 때 최적의 성능을 발휘한다.
Retrieval
Retrieval Source
- retrieval source의 유형과 retrieval unit의 세분화는 최종적인 생성 결과에 영향을 미친다.
- Data Structure
- 초기에는, text가 주된 검색 source였다. 이후에는 PDF같은 semi-structured data와 knowledge graph같은 structured data를 포함하도록 확장되었다. 최근 연구에서는 LLM이 자체 생성한 콘텐츠를 retrieval이나 enhancement 목적으로 사용하는 경향도 커지고 있다.
- Unstructured Data
- Text와 같은 비구조화 데이터는 주로 corpus에서 수집된다. 주로 특정 도메인 데이터가 포함된다.
- Semi-structured data
- 반구조화 데이터는 주로 텍스트와 표를 결합한 데이터를 의미하며, PDF가 대표적이다. 이를 처리하는 것은 RAG시스템에 두 가지 이유로 challenge를 준다.
- 텍스트 분할 과정에서 표가 분리되어 데이터가 손상될 수 있다.
- 표가 포함된 데이터는 semantic similarity 검색을 복잡하게 한다.
- 이 분야에는 많은 연구 기회가 있다.
- 반구조화 데이터는 주로 텍스트와 표를 결합한 데이터를 의미하며, PDF가 대표적이다. 이를 처리하는 것은 RAG시스템에 두 가지 이유로 challenge를 준다.
- Structured data
- Knowledge data와 같은 구조화 데이터는 보통 검증된 데이터로, 더 정확한 정보를 제공할 수 있다.
- KnowledGPT, G-Retriever 모델, Prize-Collecting Steiner Tree(PCST) 최적화 문제 등 사용
- structured db를 구축, 검증, 유지보수 하는 것은 추가적인 노력 필요
- LLMs-Generated Content
- RAG의 외부 정보 한계를 해결하기 위해, 일부 연구에서는 LLM 내부 지식을 활용한다.
- Retrieval Granularity(검색단위 세분화)
- 데이터의 세분화 정도는 중요한 요소다. 큰 단위의 검색은 이론적으로 더 관련있는 정보를 제공할 수 있지만, 불필요한 내용도 포함되어 이후 작업에서 혼란을 겪을 수 있다. 너무 작은 단위는 검색의 부담을 증가시키며 의미적 완전성을 보장하지 못할 수 있다. 이 단위는 token-phrase-sentence-proposition(명제)-chunk-document 까지 다양하다.
Indexing Optimization
- Chunking Strategy
- 문장을 일정한 수의 토큰으로 분할한다. 큰 청크는 더 많은 context를 캡처할 수 있지만, 많은 노이즈를 생성하고 시간과 비용이 늘어난다. 작은 청크는 그 반대이다.
- 청크 분할은 문장이 잘리는 문제를 야기할 수 있어 recursive split이나 sliding window 방법을 최적화하여 여러 검색에서 정보를 병합하는 계층적 검색을 가능하게 한다.
- Metadata Attachments
- 청크에 메타데이터 정보를 추가하여 문서의 범위를 좁힌 뒤 검색한다. 메타데이터를 인위적으로 구성할 수도 있다.
- Structural Index
- Hierarchical Index
- 문서에 hierarchical structure을 구축함으로써 RAG의 검색 효율을 높인다.
- Knowledge Graph Index
- 문서 계층 구조 구축을 위해 Knowledge Graph(KG)를 사용하면 일관성을 유지할 수 있으며, 정보 검색 프로세스를 LLM이 이해할 수 있는 명령으로 바꾸어 정확성을 높일 수 있으며, LLM이 context에 맞는 응답을 생성하도록 해 RAG의 전반적인 효율성을 높일 수 있다.
- Hierarchical Index
Query Optimization
- Naive RAG의 주요 challenge 중 하나는 사용자의 원래 쿼리의 직접 의존해 검색을 수행한다는 것이다. 명확한 질문을 구성하는 것은 어려운 일이며, 부적절한 쿼리는 검색 효율성을 떨어뜨린다.
- 또 다른 어려움은 언어의 복잡성에 따른 모호성으로, 전문 용어나 다의어를 처리하는 데 어려움을 겪는다.
- Query Expansion
- single query를 multiple query로 확장하면 쿼리의 내용을 풍부하게 하여 특정 뉘앙스 부족을 해결하고 답변과의 관련성을 최적화할 수 있다.
- Multi-query
- LLM을 활용한 프롬프트 엔지니어링으로 쿼리를 확장하고, 이 여러 쿼리를 병렬로 실행할 수 있다. 이 확장은 무작위가 아닌 철저히 설계되어 이루어진다.
- Sub-query
- sub-question을 계획하는 과정은 원래 질문에 context를 추가하고 이를 답할 수 있도록 필요한 하위 질문을 생성하는 것을 의미한다. 복잡한 질문은 least-to-most 프롬프트 방식으로 더 단순한 하위 질문으로 분해 가능하다.
- Chain-of-Verification(CoVe)
- 확장된 쿼리는 LLM을 통해 검증과정을 거치며, hallucination을 줄이는 효과를 얻을 수 있다.
- Query Transformation
- original query가 아닌 변환된 쿼리를 기반으로 검색을 수행한다.
- Query Rewrite
- original query는 llm 검색에 항상 최적화되어 있지 않으며, 따라서 LLM을 프롬프트하여 쿼리를 재작성할수 있다. 또는 특화된 sLM을 사용할 수 있다.
- Query Rewrite
- Query Routing
- 쿼리의 특성에 따라 적합한 RAG 파이프라인으로 라우팅하여 다양한 시나리오에 적용가능한 다목적 RAG 시스템을 설계할 수 있다.
- Metadata Router/Filter
- 퀴리에서 키워드를 추출한 후, 키워드 내 메타데이터를 기반으로 필터링하여 검색 범위를 좁힌다.
- Semantic Router
- 쿼리의 시맨틱 정보를 활용한다. 시맨틱과 메타데이터 정보를 결합한 하이브리드 방식도 있다.
Embedding
- RAG에서는 질문 임베딩과 청크 임베딩의 유사성(ex: 코사인)을 계산해 검색을 수행하는데, 이때 임베딩 모델의 semantic representation 능력이 중요하다. 여기에는 주로 BM25 같은 sparse encoder와 BERT 아키텍처 PTM 같은 dense retriever가 포함된다. 어떤 임베딩 모델을 사용해야하는가에 대한 일관된 답은 없지만, 특정 모델들이 특정 task에 더 적합한 경향은 있다.
- Mix/Hybrid Retrieval
- Sparse embedding과 dense embedding 방식은 서로 다른 relevance feature를 포착하며, 상호보완적인 관계가 될 수 있다. 예를 들어, sparse 모델을 dense 모델을 학습하기 위한 초기 검색 모델을 제공할 수 있다.
- Fine-tuning Embedding Model
- 특수한 도메인을 사용할 경우 자체 데이터셋을 사용해 임베딩 모델을 fine-tuning 하는 것이 필수적이다.
- fine-tuning의 또다른 목적은 Retriever와 Generator를 align하는 것이다. 예를 들어 LLM의 결과를 fine-tuning의 supervision signal로 사용하는 방법을 LSM(LM-supervised Retriever)이라고 한다.
- Retriever는 1) 데이터셋의 hard label과 2) LLM의 soft reward라는 두 가지 종류의 supervised signal을 통해 학습된다.
- 이러한 이중 signal 접근 방식은 다양한 다운스트림 task에 맞게 조정하는데 효과적이다.
- RLHF에서 영감을 받아 LM 기반 피드백을 사용해 Retriever를 강화학습을 통해 강화하는 방법도 있다.
- Retriever는 1) 데이터셋의 hard label과 2) LLM의 soft reward라는 두 가지 종류의 supervised signal을 통해 학습된다.
Adapter
- 일부 방식에서는 외부 어댑터를 사용해 모델을 align 한다.
Generation
- Retrieval 후 검색된 모든 정보를 LLM에 직접 입력하는 것은 좋은 방법이 아니다.
Context Curation
- 중복된 정보는 generation에 방해가 될 수 있으며, 긴 context는 ‘Lost in the middle’ 문제를 초래할 수 있다. 따라서 RAG에는 검색된 내용을 post-process해야 한다.
- Reranking
- Reranking은 chunk를 reorder해 가장 관련성이 높은 것을 먼저 강조하는 방식으로, 전체 문서 pool을 줄이고, IR에서 enhancer와 filtering을 동시에 수행하여 LLM이 더 정확하게 처리할 수 있는 정제된 입력을 제공한다.
- Context Selection/Compression
- RAG에서 가능한 많은 관련 문서를 검색하고 긴 검색 프롬프트를 만드는 것이 유리하다는 것은 오해이다. 긴 context는 noise로 인해 LLM의 정보 인식 능력을 저하시킬 수 있다.
- 여러 모델에서는 sLM이나 information retriever, information condenser 등을 사용해 중요하지 않은 토큰을 감지하고 제거하는 방법을 사용했다.
- context 압축 외에도 문서 수를 줄이는 것도 유용하다.
- Reranking
LLM Fine-Tuning
- 특정 task나 데이터에 타겟팅된 fine-tuning은 LLM에게 더 좋은 성능을 이끌어낸다. 이는 on-premise LLM을 사용하는 가장 큰 장점 중 하나이기도 하다.
- Fine-tuning의 또 다른 장점은 모델의 입력과 출력을 조정할 수 있다는 점이다.
- LLM의 출력을 인간이나 retriever의 선호에 맞추기 위해 강화학습을 사용하는 것도 가능한 방식이다.
- 거대한 오픈소스 모델에 접근할 수 없는 상황에서는 강력한 모델(ex: GPT-4)을 distillation하는 간단하면서도 효과적인 방법이 있다.
- LLM의 fine-tuning은 reiriever의 fine-tuning과 함께 진행될 수 있으며, 이를 통해 preference를 align할 수 있다.
Augmentation Process in RAG
- RAG에서는 일반적으로 한 번의 검색 단계를 거치고 답변을 생성한다. 그러나 이는 다단계의 추론을 요구하는 복잡한 문제에서는 제한된 정보만을 제공하므로 충분하지 않을 때가 많다. 이러한 문제를 해결하기 위해 많은 연구에서 검색 과정을 최적화하였으며, 아래 Figure 5에 나타낸다.
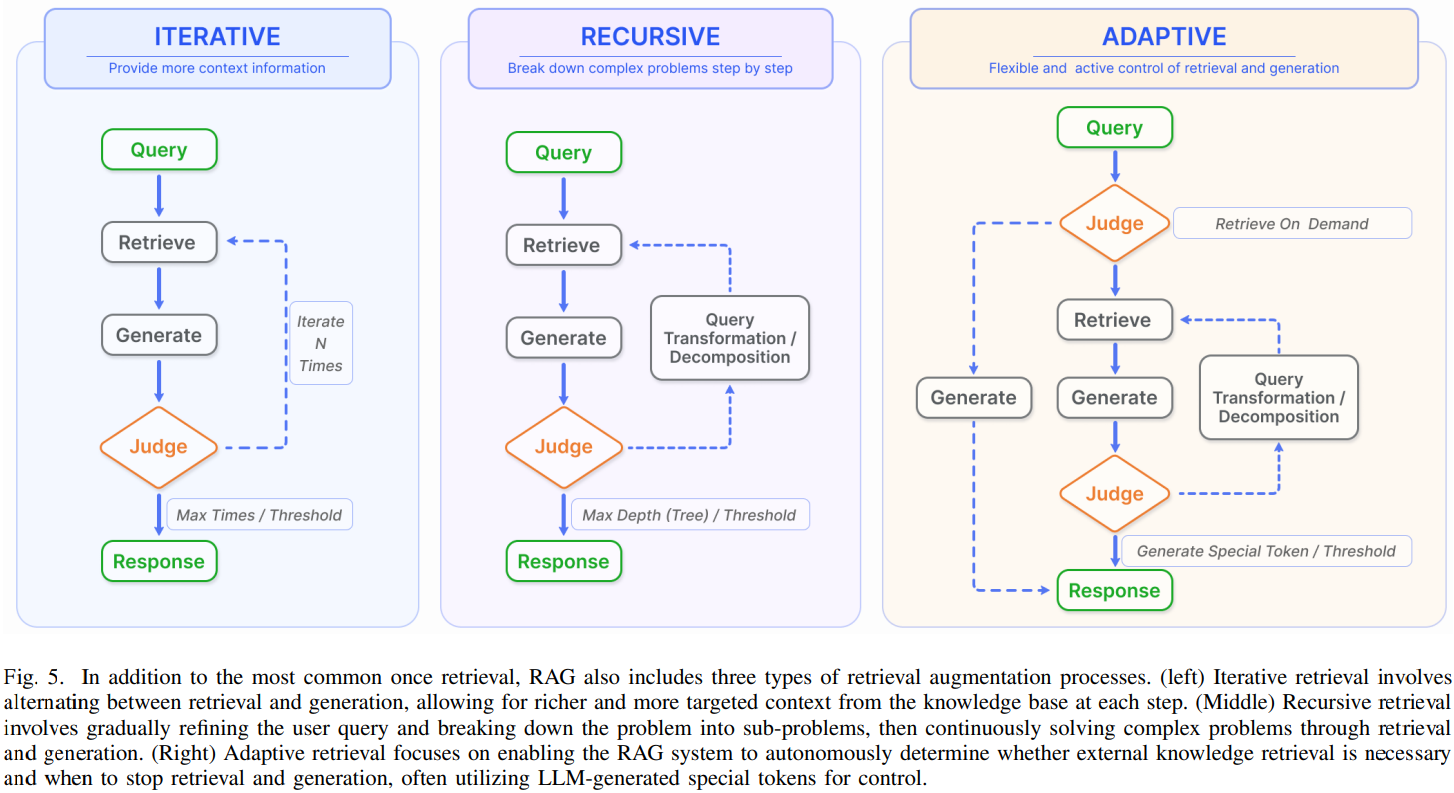
Iterative Search
- Iterative search는 초기 쿼리와, 지금까지 생성된 텍스트를 바탕으로 knowledge base에서 반복적으로 검색이 수행되는 과정이다. 이를 통해 답변 생성의 robustness를 향상시키는 것으로 나타났다.
- 하지만 이 방식은 의미적 불연속성이나 불필요한 정보의 축적으로 인해 영향을 받을 수 있다.
Recursive Search
- Recursive search는 이전 검색에서 얻은 결과를 바탕으로 검색 쿼리를 반복적으로 수정하는 방식으로 진행된다.
- Recursive search의 목표는 feedback loop를 통해 점진적으로 가장 관련성 높은 정보에 수렴하는 식으로 검색 경험을 개선하는 것이다.
Task and Evaluation
Downstram Task
- RAG의 core task는 QA로, 전통적인 single-hop/multi-hop(질문에 대한 답을 하나의 문단/여러문단에서만 정답을 찾을 수 있는 것) QA, multiple chioce QA, domain-specific QA, long-form scenarios suitable QA 를 포함한다. 또한 RAG는 IR, IE(Information Extration), Dialogue Generation, Code Search 등 다양한 다운스트림 작업으로 확장되고 있다.
Evaluation Target
- 그동안 RAG 모델의 평가는 특정 다운스트림 작업에서의 성능으로 초점이 맞춰져왔으므로 해당 작업에 적합한 평가 지표가 사용되어 왔다. RAG의 자동평가를 위해 설계된 RALLE와 같은 도구도 이러한 task별 지표를 기반으로 평가를 수행한다.
- 그럼에도 RAG 모델의 고유한 특성을 평가하는 연구는 여전히 부족하다. 주요한 evaluation objectives는 Retrieval Quality와 Generation Quality를 평가하는 것이다.
- Retrieval Quality: Hit Rate, MRR(Mean Reciprocal Rank), NDCG(Normalized Disconted Cunulative Gain) 등의 지표가 일반적으로 활용
- Generation Qulaity: 레이블의 유무에 따라 평가는 두가지로 나뉜다.
- 레이블이 없는 콘텐츠는 생성된 답변의 충실성(faithfulness), 관련성(relevance), 무해성(non-harmfulness)을 평가하며, 레이블이 있는 콘텐츠는 정보의 정확성(accuracy)에 초점을 맞춘다. 이 평가는 수동/자동 평가를 통해 수행될 수 있다.
Evaluation Aspects
- 현대의 RAG 평가는 3개의 quality score와 4개의 essential ablilty에 중점을 두며, 이는 RAG의 주 목표인 검색과 생성 평가에 대한 종합적인 정보를 제공한다.
- Quality Scores: Quality scores는 RAG의 효율성을 다양한 관점에서 평가한다.
- 1) Context Relevance: retrieved된 context의 precision(정확도)과 specificity(특이도)를 평가하여, 불필요한 콘텐츠로 인한 cost를 최소화하고 관련성은 보장한다.
- 2) Answer Faithfulness: 생성된 답변이 retrieved된 context에 충실하게 유지되도록 하여 일관성을 유지하고 모순을 피하도록 한다.
- 3) Answer Relevance: 생성된 답변이 제시된 질문과 직접적으로 관련되며 핵심적인 질문을 효율적으로 다루는지 평가한다.
- Required Abilities: 모델의 적응성과 효율성을 평가하는 4가지 ablility도 포함된다.
- 1) Noise Robustness: 질문과 관련은 있지만 실질적인 정보가 부족한 noise document를 처리하는 모델의 능력을 평가한다.
- 2) Negative Rejection: retrieved된 문서에 질문이 답하기 위해 필수 지식이 없을 때, response를 자제하는 모델의 자제력(분별력)을 평가한다.
- 3) Information Integration: 모델이 복잡한 질문에 답하기 위해 여러 문서에서 정보를 통합하는 능력을 평가한다.
- 4) Conterfactual Robustness: 모델이 문서 내에서 잘못된 정보를 인식하고, 잠재적인 오정보에 대해 지시를 받았을 때 이를 무시하는 능력을 평가한다.
- 1-1), 2-1)은 Retrieval quality를 평가하는 데 중요하며, 나머지는 Generation Quality를 평가하는 데 중요하다.
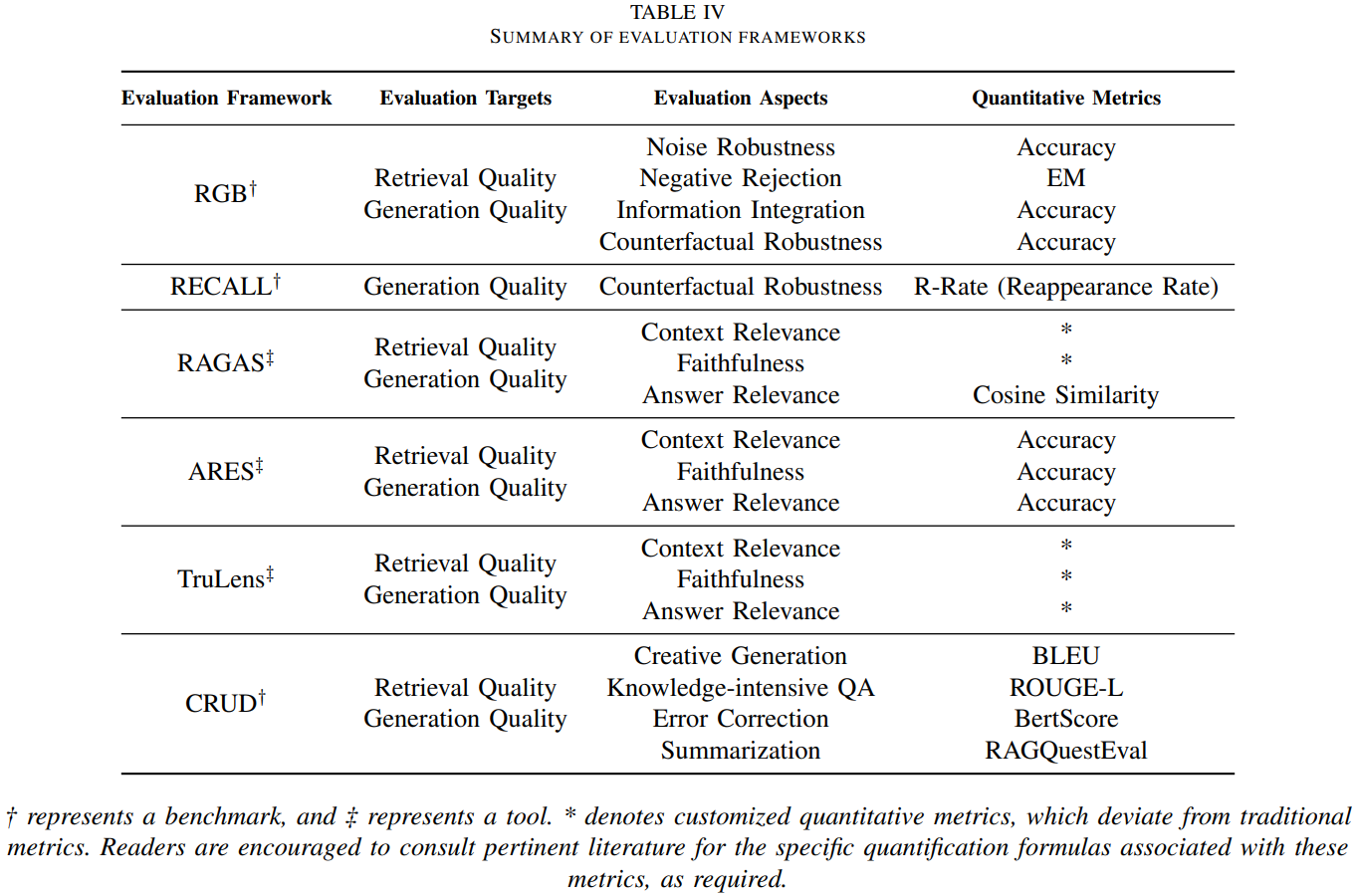
Evaluation Bencmarks and Tools
- RGB, RECALL, CRUD 등의 주요 벤치마크는 RAG의 essential ablility를 평가하는 데 중점을 준다.
- RAGAS, ARES, TruLens같은 최신 automated 도구들은 LLM을 통해 quality score를 측정한다.
Discussion and Future Prospects
RAG vs. Long Context
- LLM의 context 처리 능력은 지속적으로 확장되고 있다(최근엔 20만 토큰). 이는 RAG에 의존하던 긴 문서 QA를 이제 문서 전체를 프롬프트에 직접 포함해 처리할 수 있음을 의미한다. 이러한 발전은 LLM이 컨텍스트에 제한받지 않을 때 RAG가 필요한가?에 대한 논의를 불러일으켰다.
- 사실 RAG는 여전히 대체할 수 없는 역할을 한다.
- LLM에 한 번에 많은 양의 context를 제공하면 추론 속도에 큰 영향을 미치지만, 반면 RAG의 retrieved chunk와 on-demand input은 효율성을 크게 향상시킬 수 있다.
- RAG 기반 generation은 LLM이 원본 참조 자료를 빠르게 찾아서 generated response를 검증하는 데 도움을 줄 수 있다.
- RAG와 다르게 LLM은 여전히 블랙박스다.
- 그러나 context expansion은 RAG 발전에 새로운 기회를 제공해 더 복잡한 task를 다룰 수 있게 한다. 초장기 context를 처리하는 것은 RAG의 future research trend 중 하나다.
RAG Robustness
- Retrieval 과정에서 발생하는 noise나 모순된 정보는 RAG response quality에 악영향을 준다.
- 이는 ‘잘못된 정보는 정보가 없는 것보다 더 해로울 수 있다’라는 비유로 설명된다.
- 그러나 연구 결과에서는 관련없는 문서를 일부 포함했을 때 정확도가 30%이상 향상되는 경우가 있으며, 초기 가정과 상반된다.
- RAG 연구에서 Retrieval과 generation 모델을 통합하는 특화된 전략을 개발할 필요성을 강조하며, RAG robustness에 대한 추가적인 연구의 중요성을 보여준다.
Hybrid Approaches
- RAG와 fine-tuning을 결합하는 방식이 주요 방식으로 떠오르고 있다.
- 특정 기능의 sLM을 RAG에 도입하고 RAG의 결과로 이를 미세소정하는 방식도 있다.
Scaling laws of RAG
- End-to-end RAG와 RAG기반의 PTM에서 parameter는 중요한 요소이다.
- LLM에서는 scaling laws가 성립되어 있지만, RAG에도 적용가능한지는 불확실하다.
Production-Ready RAG
- RAG 생태계의 발전은 기술 스택의 발전에 큰 영향을 받는다.
- LangChain과 LLamaIndex와 같은 기술 스택은 RAG관련 API를 제고하고 LLM 분야에서 필수적인 역할을 하고 있다.
- RAG 기술 발전에는 몇 가지 특화된 방향이 나타난다.
- Customization: 특정 요구를 충족하도록 RAG를 조정하는 것
- Simplication: 초기 learning curve를 줄이기 위해 RAG를 더 쉽게 만드는 것
- Specification: RAG를 최적화하여 실제 환경에서 더 잘 작동하도록 만드는 것
- RAG는 기술 스택의 성장으로 인한 상호작용으로, RAG tool은 foundational technology stack이 되어가고 있으며 고급 application을 위한 기초를 마련하고 있다.
Multi-Modal RAG
- 이미지
- RA-CM3는 텍스트와 이미지를 검색하고 생성하는 pioneering 멀티모달 모델이다.
- BLIP-2는 고정된 이미지 인코더와 LLM을 결합해 visual 언어 사전학습을 효율적으로 수행하며, zeroshot image-to-text 변환을 가능하게 한다.
- Visual Before You Write 방식은 이미지 생성을 통해 언어 모델의 텍스트 생성을 유도한다.
- 오디오와 비디오
- GSS는 오디오 클립을 검색하고 이를 결합해 기계 번역된 데이터를 음성 번역 데이터로 변환한다.
- 코드
- RBPS는 코드 예시를 검색해 개발자의 목표에 맞게 인코딩 및 빈도 분석을 통해 작은 규모의 학습 작업에서 뛰어난 성능을 발휘한다.
Conclusion
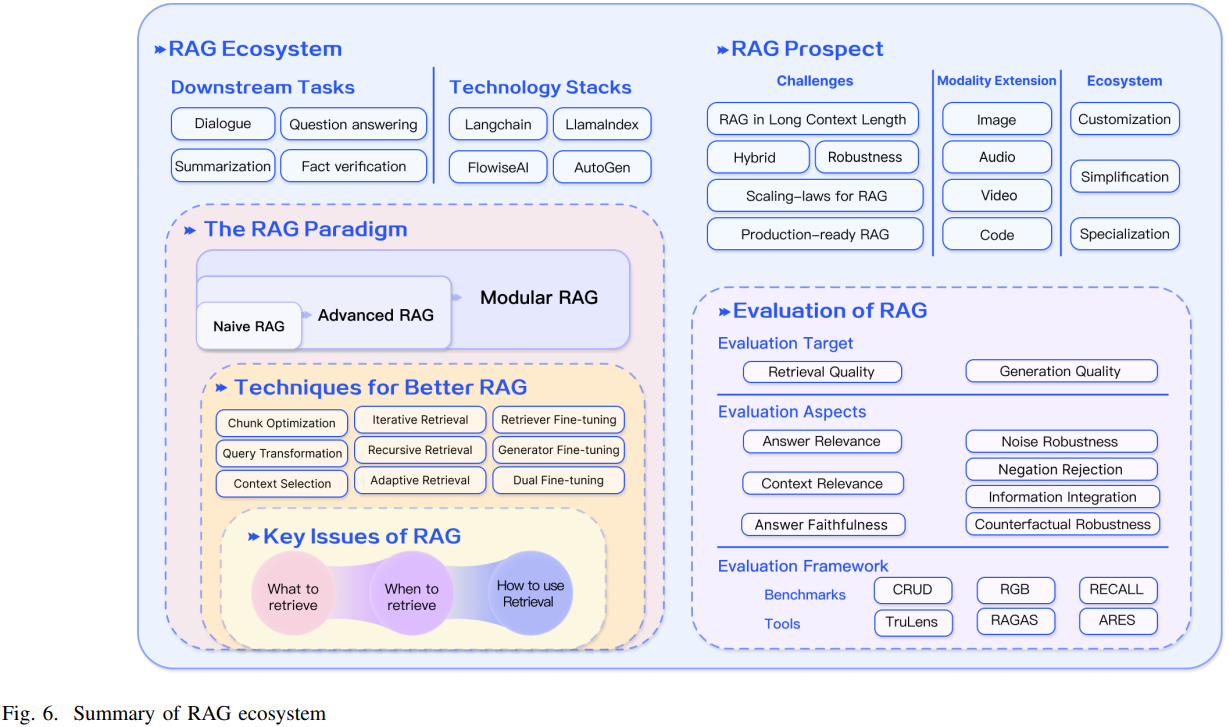
- Figure 6에 나타난 것처럼, LLM의 매개변수화된 지식과 외부 지식 기반의 비매개변수화된 데이터를 통합하여 RAG가 LLM의 기능을 크게 발전 시켰음을 강조한다.
- RAG는 fine-tuning과 강화학습과 같은 다른 기술과의 통합을 통해 그 기능을 확장해왔다.
- 여전히 RAG의 robustness와 long context 처리 능력을 개선하기 위한 연구 기회는 존재한다.
- RAG의 응용범위는 멀티모달 도메인으로 확장되어 이미지, 비디오, 코드와 같은 다양한 데이터 형식을 해석하고 처리하는데 사용되고 있다.
- RAG 생태계가 확장하는 것은 RAG application과 이를 지원하는 tool의 지속적 개발로 입증된다.
- RAG가 꾸준히 성장하기 위해서는 정확하고 대표적인 성능평가를 보장하는 것이 매우 중요하다.

Anyone can be anything ... with agent!