From NeurIPS, 2023
Abstract & Introduction
- 그동안의 자율적 의사결정 에이전트(autonomous decision-making agent)들은 주로 In-Context Learning 또는 강화 학습을 사용해 성능을 개선하고자 했다.
- 그러나 이는 거대 LLM의 파라미터에 의존하거나 강화 학습의 낮은 계산 효율성으로 인한 문제가 있었다.
- 이 논문에서는 모델을 fine-tuning 하지 않고 binary or scalar feedback을 언어적 피드백으로 변환해 text summary로 제공된다.
- 이런 self-reflective feedback은 다음 action에서 의미론적인 gradient signal로 사용되어 구체적인 개선 방향을 제공해 성능 개선에 도움을 준다.

- 이런 self-reflective feedback은 다음 action에서 의미론적인 gradient signal로 사용되어 구체적인 개선 방향을 제공해 성능 개선에 도움을 준다.
- Reflexion은 useful reflective feedback을 만들기 위해 세가지 방법을 사용한다.
- Simple Binary Environment Feedback(단순 binary 환경 피드백),
- Pre-defined Heuristics for common failure cases(실패 사례에 대한 휴리스틱),
- self-evaluation such as binary classification using LLMs (decision-making) or self-written unit tests (programming) (자체 평가 - decision making에서는 binary classification, 프로그래밍에서는 자체 제작된 unit test)
- Reflexion에는 장단점이 존재한다.
- Reflexion은 전통적인 RL보다 몇 가지 장점을 갖는다.
- 가볍고, LLM의 finetuning이 필요하지 않다.
- 스칼라/벡터 형태의 reward 보다 더 정교한 형태의 피드백을 가능하게 한다. ex) 행동에 대한 구체적 변경
- 이전 경험에 대한 명확하고 해석 가능한 episodic memory를 제공한다.
- 이후의 에피소드에서의 행동에 대한 명확한 hint를 제공한다.
- 하지만 단점도 있다.
- Reflexion은 LLM의 자체 self-evaluation capability or heuristic에 의존하며, success에 대한 formal guarantee가 없다.
- 다만 LLM의 성능이 향상될수록 이는 개선될 것으로 기대된다.
- Reflexion은 LLM의 자체 self-evaluation capability or heuristic에 의존하며, success에 대한 formal guarantee가 없다.
- Reflexion은 전통적인 RL보다 몇 가지 장점을 갖는다.
- Reflexion에 대해 1) Decision-making task, 2) Reasoning task, 3) Programming task 에서 실험을 수행했으며, 모두 성능 향상을 이루었다.
- Reflexion의 주요 기여점은 다음과 같다.
- Reflexion이라는 새로운 ‘언어적’ 강화학습 패러다임을 제안하며, 이는 agent의 메모리 인코딩과 LLM 파라미터 선택을 policy로 한다.
- LLM에서의 self-reflection이라는 속성을 탐구하며, 이를 통해 복잡한 작업을 적은 시도로 학습하는 데에 self-reflection이 매우 유용함을 실증적으로 보인다.
- LeetcodeHardGym이라는 code-generation RL gym envirionment를 소개한다. 이는 19개의 언어로 작성된 40개의 Hard Level의 Leetcode 문제를 담고 있다.
- Reflexion이 여러 task에서 strong baseline을 능가하고, 다양한 code generation 벤치마크에서 SOTA를 달성함을 보였다.
Related Work
Reasoning & Decision-making
- Self-Refine은 self-refinement를 통해 성능을 개선하는 iterative 프레임워크를 사용한다.
- 이러한 방식은 ‘이 generation을 어떻게 더 긍정적인 방식으로 쓸 수 있을까’ 와 같은 제약 조건에 따라 달라진다.
- 효과적이긴 하지만 단일 생성 추론 작업에만 제한된다.
- Semantic prompt-writing optimization을 수행한 연구도 있지만 역시 단일 생성 작업에 한정된다.
- 중간 피드백을 제공하기 위해 critic 모델을 파인튜닝해 reasoning 응답을 개선한 연구도 있다.
- Action에 대한 stochastic beam search를 통해 더 효율적인 decision making을 하는 연구도 있다. 이는 agent가 self-evaluation component를 통해 예측 우위를 갖도록 하는 것이다.
- 여러 세대에 걸쳐서 reasoning을 하는 모델을 사용한 연구도 있다.
- Evaluation 없이 고정된 단계 수만큼 retry를 하는 패턴에 대한 연구도 있다.
- 이전 생성물에 대한 정성적 평가 단계를 통한 최적화를 수행하는 연구도 있다.
- 본 논문에서는 이런 여러 개념 중 몇 가지가 Self-refelction을 통해 향상되어 Self-refelction 경험에 대한 지속적인 메모리를 구축할 수 있음을 보인다.
- 이를 통해 agent는 자신의 오류를 스스로 식별하고 실수로부터 배울 교훈을 스스로 제안한 할 수 있다.
Programming
- 과거나 최근 연구들은 test-driven development 이나 code debugging 을 사용한다.
- AlphaCode는 hidden test cases에 대해 생성된 코드의 성능을 평가한다.
- CodeT는 자체 생성한 unit test를 통해 함수 구현 점수를 매긴다.
- Self-Debugging은 코드 실행 환경에서의 피드백을 바탕으로 기존 구현을 개선하는 debugging coomponent를 사용한다.
- CodeRL은 RL프레임워크를 사용해 코드 실행 환경으로부터 피드백을 받아 프로그램을 디버깅한다.
- a., c., d. 는 복잡도가 낮은 버그를 수정하는데 효과적이지만, 이는 ground-truth 케이스에 의존하며 pass@1 평가에 적합하지 않고, 오류 개선과 구현 개선 사이의 격차를 self-reflection을 사용하지 않는다.
- b. 는 hidden test case를 사용하지 않지만 코드 작성 개선을 위한 self-learning을 구현하지 않는다.
Reflexion: reinforcement via verbal reflection
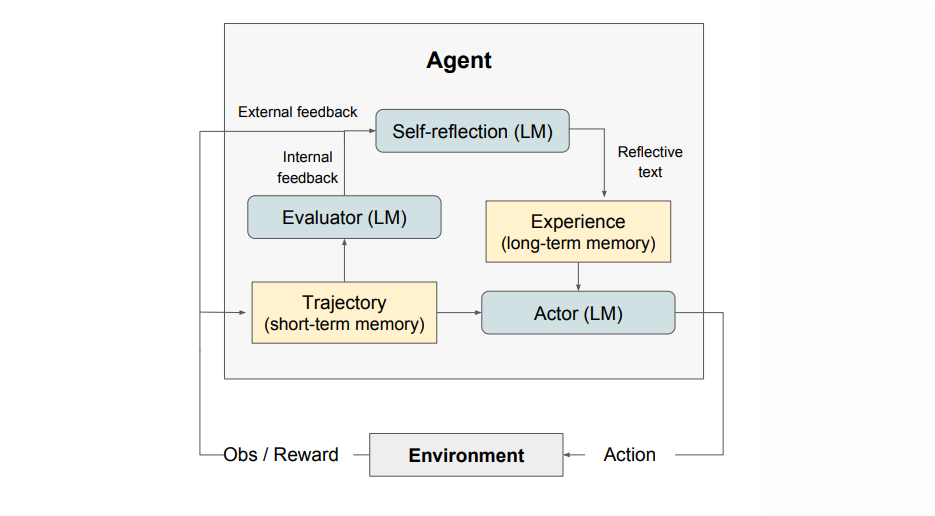
- Reflexion은 3개의 모델이 모듈화되어 구성되어 있다.
- Actor (M_a): 텍스트와 행동 생성
- Evaluator (M_e): 출력 결과 평가
- Self-Reflection (M_sr): Actor의 self-improvement을 위한 언어적 강화 피드백 생성 모델
Actor
- π_θ
- Actor는 LLM을 기반으로 구축되며, state observation에 맞는 텍스트와 action을 생성하도록 프롬프트된다.
- 전통적인 policy-based RL 처럼, 시점 t에서의 현재 정책 π_θ으로부터 action이나 generation a_t를 샘플링하고, 환경으로부터 observation o_t를 받는다.
- Actor 모델로는 Cot나 ReAct를 포함한 다양한 모델을 사용해 Reflexion의 다양한 요소의 성능이나 효율성을 살펴본다.
- 추가적으로, 메모리 component인 mem을 추가해 agent에게 추가적인 context를 제공한다.
Evaluator
- Actor가 생성한 출력의 품질을 평가하는 중요 역할
- task context 내에서의 성능을 반영한 reward score 계산
- Semantic space에 적용할 수 있는 효과적인 value/reward function을 정의하는 것은 어렵기 때문에, 여러 evaluator 모델의 변형을 조사한다.
- Reasoning task에서는 Exact Match(EM) 계산에 기반한 reward function을 실험해 생성된 출력이 예상 솔루션과 얼마나 일치하는지 확인한다.
- Decision-making task에서는 특정 기준에 맞게 설계된 사전 정의된 휴리스틱 함수를 사용한다.
- 또한 decision-making과 programming 작업에서는 evaluator로서 LLM의 다른 instance를 사용하여 reward를 생성하는 방법도 실험한다.
Self-Reflection
- Self-Reflection은 LLM으로 구현되며, 언어적인 self-reflection을 생성하여 추후의 trial을 위한 귀중한 피드백을 제공하기 때문에 reflexion에서 중요한 역할을 한다.
- binary reward signal(성공/실패)같은 sparse reward signal과, 현재 경로, 그리고 지속적인 메모리인 mem을 기반으로 구체적인 피드백을 생성한다.
- 이 informative한 피드백은 agent의 memory인 mem에 저장된다.
- 예를 들어, multi-step decision-making task에서 agent가 실패 신호를 받으면, 특정 행동 ai가 그 이후의 잘못된 행동 a(i+1)과 a_(i+2)로 이어졌다는 것을 추론할 수 있다.
- agent는 이를 언어적(verbal)으로 표현하여 다른 행동 a’_i를 취했어야 했음을 기록해둔다.
- 이를 토대로 agent는 과거 경험을 활용해 더 나은 decision-making approach를 할 수 있다.
- Trial, error, Self-reflection, persisting memory 의 프로세스는 agent가 빠르게 decision making성능을 향상시킬 수 있도록 돕는다.
Memory
- Reflexion 과정에서의 핵심 요소는 단기 메모리와 장기 메모리 개념이다.
- Inference를 할 때, Actor는 단기 및 장기 메모리를 바탕으로 자신의 결정을 내리며, 이는 사람이 세세한 최근 정보를 기억하면서도 중요한 과거 경험을 장기 메모리에서 떠올리는 방식과 유사하다.
- RL setup에서 경로 history는 단기 메모리로 작용하고, self-reflection 모델의 출력은 장기 메모리에 저장된다.
- 이러한 메모리 세팅은 Reflexion이 갖는 주요 장점이다.
The Reflexion process

- Reflexion은 1장에서 언급한 것처럼 반복적인 최적화 과정으로 공식화된다.
- 첫번째 trial에서 Actor는 환경과 상호작용하여 경로(trajectory) τ_0를 생성한다.
- 이후 Evaluator는 τ_0를 입력으로 받아 점수 r_0를 계산하고, 이는 r_0=M_e(τ_0)로 표현된다.
- r_t는 시행 t에서의 스칼라 보상값으로 작업 별 성능이 증가함에 따라 개선된다.
- 첫 trial 이후에 r_0을 LLM 개선에 사용할 수 있는 피드백 형태로 바꿔야 한다.
- 그러기 위해 Self-reflection 모델은 {τ_0, r_0} set를 분석해 summrary sr_0을 생성하고 이를 mem에 저장한다.
- sr_t는 trial t에 대한 언어적 경험 피드백을 의미하며, mem에 추가된다.
- 실제로 mem에는 저장되는 경험에 수를 최대 Ω로 제한해(보통 1~3) LLM의 max context length를 초과하지 않도록 한다.
Experiments
- Agent의 여러 RL환경에서 Decision-making, reasoning, code-generation을 평가한다.
- HotPotQA를 사용한 search-based qa
- AlfWorld의 일반 가정환경에서의 multi-step tasks
- HumanEval, MBPP, LeetcodeHard 에서 interpreter와 compiler를 사용하는 code writing task
Sequential decision making: ALFWorld
- AlfWorld는 TextWorld를 기반으로 한 상호작용 환경에서 에이전트가 multi-step task를 해결하도록 하는 텍스트 기반 환경들의 모음이다.
- 숨겨진 객체 찾기(서랍에서 주걱찾기), 객체 이동(칼을 도마로 옮기기) 등과 같은 6가지 작업을 134개의 AlfWorld 환경에서 agent를 실행하며 Action generator로는 ReAct를 사용한다.
- AlfWorld task는 작업이 완료되었을 때만 signal을 보내기 때문에 자연스럽게 self-evaluation step이 요구된다.
- Fully autonomous behavior를 위해 두가지 self-evaluation 기법을 도입한다
- LLM을 사용한 자연어 분류
- 수기로 작성된 휴리스틱
- 휴리스틱은 에이전트가 동일한 행동에 대해 동일한 response를 받는 cycle이 3번 이상 반복되거나, 현재 환경에서 action을 30번 이상 수행하는 비효율적인 plan이라면 self-reflection을 수행하는 것이다.
- Fully autonomous behavior를 위해 두가지 self-evaluation 기법을 도입한다
- Baseline 실행에서는 self-reflection이 제안되면 이를 스킵하고 환경을 초기화한 후 새로운 trial을 시작한다.
- Reflexion 실행에서는 agent가 self-reflection을 통해 실수를 찾아내고 메모리를 업데이트한 뒤 환경을 초기화하여 새로운 trial을 시작한다.
- Max context length를 초과할 수 있는 매우 긴 prompt window를 방지하기 위해, agent의 memory는 last 3 self-reflections(experiences)로 제한한다.
- 의미론적 오류를 막기 위해 도메인 별로 few-shot 경로를 주는데, 아래 예시(Figure 5)와 같다.(appendix에 있음)

Result
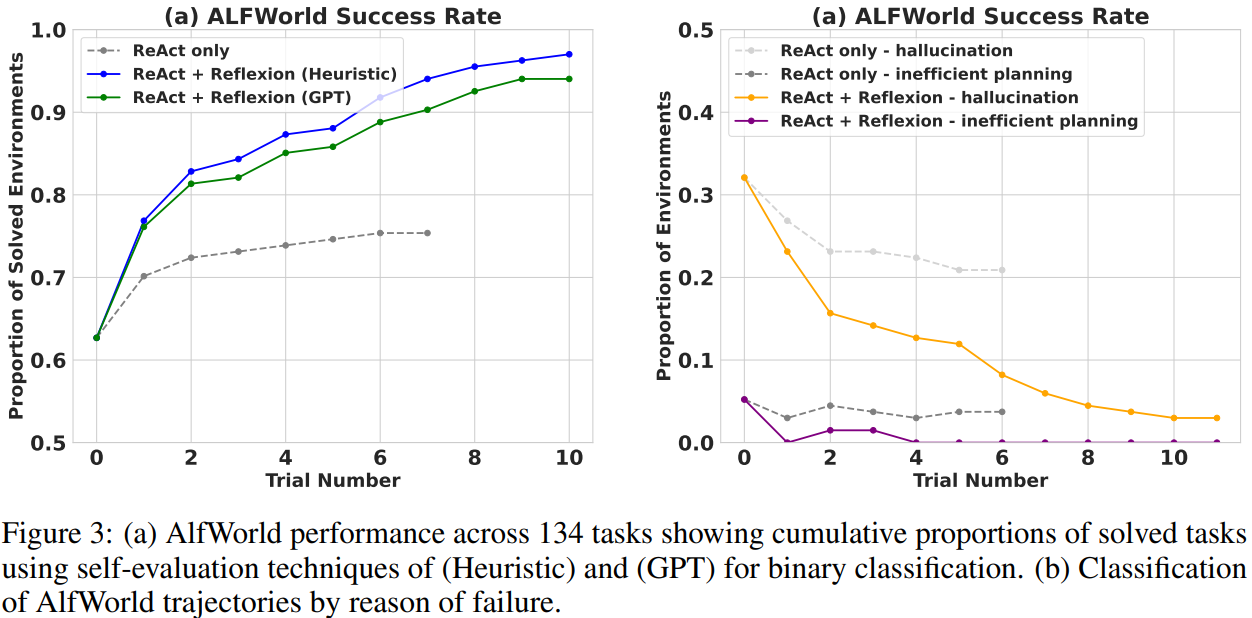
- ReAct + Reflexion은 simple heuristic을 사용해 hallucination을 탐지하고 비효율적 planning을 탐지하면서 134개 task 중 130개를 완료하면서 ReAct를 크게 능가한다.
- ReAct + Reflexion은 12번의 연속적 trial을 통해 additional task를 해결하는 방법을 학습한다.
- ReAct only에서는 6~7의 trial에서 성능 향상이 멈추는 것을 확인했다.
- (아래 Figure 3 그래프 참고)
Analysis
- AlfWorld에서 실패 경로의 일반적인 오류는 agent가 item을 소유하고 있다고 생각하고 있지만, 실제로는 소유하지 않은 경우이다.
- Agent는 긴 경로에서 여러 행동을 하며 실수를 되돌릴 수 없다
- Reflexion은 self-reflection을 통해 긴 실패 경로를 관련된 경험으로 요약하고, 이를 미래의 self-hint로 사용할 수 있도록 해 이와 비슷한 대부분의 사례를 없앤다.
- AlfWorld에서 장기 메모리가 agent를 돕는 2가지 주요 사례는 다음과 같다.
- 긴 경로의 초기 실수를 쉽게 찾을 수 있다. 따라서 Agent는 새로운 action 선택이나 장기 plan 까지도 제안할 수 있다.
- 객체를 찾기 위해 너무 많은 surface/container를 체크해야 할 때에도 좋다. Agent는 여러 trial에 걸쳐 쌓인 경험 메모리를 활용해 방을 철저하게 search할 수 있다.
Reasoning: HotpotQA
- HotpotQA는 113k의 QA 쌍으로 구성된 Wikipedia 기반 데이터셋으로, agent가 여러 supporting documents를 파싱하고 reasoning하도록 한다.
- 추론 능력만의 개선을 테스트하기 위해 Reflexion + CoT를 구현한다.
- 이는 Q → A와 Q, C_{gt} → A가 step by step으로 구현된다.
- C_{gt}는 데이터셋에 있는 ground truth context, A는 최종 정답이다.
- CoT가 multi-step decision-making techinique가 아니므로, C_{gt}를 제공하여 문서를 왔다갔다하는 reasoning은 따로 테스트한다.
- 전체적인 QA능력, 즉 reasoning과 action choice가 모두 요구되는 능력을 테스트하기 뒤해 Reflexion + ReAct agent를 구현한다.
- 이는 Wikipedia API를 사용해 relevant context를 검색하고, step-by-step explicit thinking을 통해 답변을 유추한다.
- CoT 구현에는 6-shot, ReAct에는 2-shot, Self-Reflection에는 2-shot 프롬프팅을 사용한다. 예시 전체는 Appendix에 있으며 일부는 아래와 같다.
- CoT+Reflexion

- HotPotQA CoT + Reflexion

- CoT+Reflexion
- Answer들을 robust하게 평가하기 위해, trial 간에 environment를 사용해 Exact Match grading을 수행해 agent에게 binary success signal을 준다.
- 이후 self-reflection loop를 통해 이 신호를 amplify하며 이는 AlfWorfd 처럼 memory size를 3 experiences로 한다.
Result
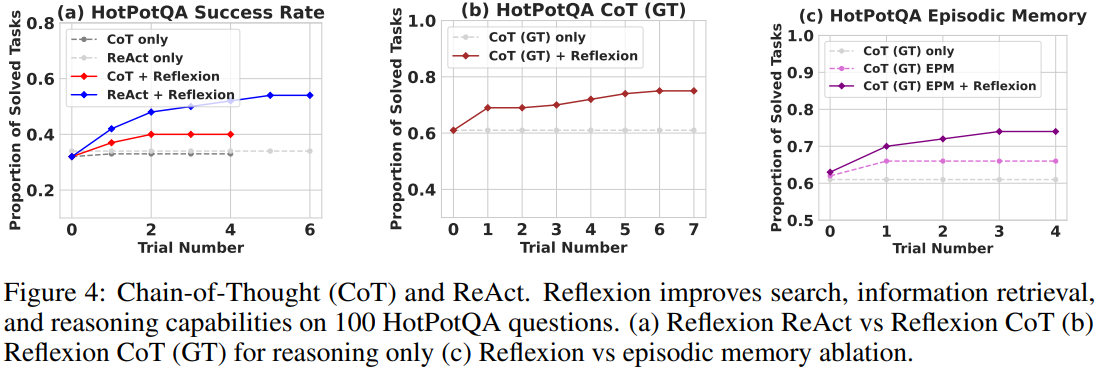
- Reflexion은 여러 learning step을 거치면서 베이스라인의 성능을 능가한다.
- 더군다나, ReAct-only, CoT-only, CoT(GT)-only는 어떤 작업에서도 확률적으로 개선되지 않았다.
- 즉 첫번째 시행에서 실패한 걸 나중에 해결하지 못했다는 것
- Reflexion은 에이전트가 동일한 작업에서 3번까지는 실패한 후에도 자신의 경험을 통해 재시도할 수 있도록 했다.
- CoT(GT)는 자연스럽게 질문의 정답 context에 접근할 수 있기 때문에 더 높은 정확도를 달성했다.
- 그러나 여전히 질문의 39%에서 올바른 답변을 하지 못했다.
- 그러나 Reflexion은 정답 context에 접근하지 않고도 agent가 본인의 실수를 수정해가면서 정확도를 14% 향상시켰다.
Analysis
- CoT(GT)를 baseline으로 사용해 self-reflection에 대한 ablation study를 수행했다.
- CoT(GT)는 GT context가 제공된 상태에서 CoT reasoning을 사용하는 접근법으로, 긴 context를 통해 reasoning을 하는 능력을 테스트한다.
- 또한 최근 경로(trajectory)를 포함하는 에피소드 메모리(EPM)을 추가한다.
- Reflexion agent는, 마지막으로 standard self-reflection step을 구현한다.
- 직관적으로는 agent가 1인칭 언어적 설명을 사용해 반복적으로 효과적으로 학습할 수 있는지 테스트한다.
- Figure 4의 실험 결과를 보면, Self-Reflection은 EPM을 통한 학습보다 8%의 성능향상을 보인다.
- 단순 refinement 접근법보다 self-reflection 기반 refinement 접근법이 더 효과적이라는 주장을 뒷받침한다.
Programming
(Dataset)
- MBPP, HumanEval, LeetcodeHardGym에서 Python/Rust code generation에 대해 평가한다.
- MBPP, HumanEval: 자연어 설명이 주어졌을 때 함수 본문 생성 정확도 측정
- MultiPL-E 사용해 데이터셋 일부 Rust로 변환
- MultiPL-E: Python 벤치마크 문제를 18개 언어로 변환할 수 있는 작은 컴파일러 모음
- Rust 코드 생성을 포함한 실험을 통해 Reflextion이 언어에 구애받지 않고, interpreted/complied language 모두에 적용될 수 있음을 보인다.
- MultiPL-E 사용해 데이터셋 일부 Rust로 변환
- LeetcodeHardGym: 40개의 Leetcode hard-rated question을 포함하는 interactive programming gym
- MBPP, HumanEval: 자연어 설명이 주어졌을 때 함수 본문 생성 정확도 측정
(Experiment Setting)
- 프로그래밍 task는 self-generated unit test suite와 같은 더 구체적인 self-evaluation 방식을 사용할 수 있다.
- 따라서 Reflexion 프로그래밍 task는 pass@1 accuracy를 사용하기 적합하다.
- pass@1 accuracy: 모델이 첫 번째 시도에서 정확한 답변을 내는 비율
- test suite를 생성하기 위해 CoT를 사용해 여러 test와 대응하는 자연어 설명을 생성한다.
- 이후 그 테스트가 유효한 추상 구문 트리(AST)를 생성할 수 있는지 확인해 문법적으로 유효한 테스트만 필터링한다.
- 이후 생성된 unit test들에서 n개의 test를 샘플링 해 test suite T={t_0, t_1, …, t_n}을 생성한다. n은 최대 6이다.
- 나머지 학습 설정은 Reasoning과 Decisio making에서와 동일하며, memory limit은 1 experience로 한다.
- 따라서 Reflexion 프로그래밍 task는 pass@1 accuracy를 사용하기 적합하다.
Result

- Reflexion은 모든 baseline을 넘어서는 성능을 보이며 SOTA 성능을 달성한다.
- 하지만 MBPP python에서는 GPT-4를 넘어서지 못했다.
- 그래서 이 낮은 성능의 원인을 조사한다.
Analysis
- Self-reflection을 사용하는 code generation agent는 diverse & comprehensive 한 test 작성 능력에 따라 성능이 좌우된다.
- 1) Test suite를 잘못 만들 경우, 모든 테스트를 통과했을지라도 이는 False Positive로 이어진다.
- 2) 반면 잘못된 test suite가 올바른 solution에서 실패를 유발한다면 이는 False Negative로 이어진다.
- Reflexion은 1) 보다는 2)을, 즉 False Negative(올바른 솔루션을 잘못된 성공으로 분류)를 선호한다.
- False Negative는 agent가 self-reflection을 통해 잘못된 테스트를 식별하고, 원래 코드 구현을 유지하도록 스스로 유도할 수 있기 때문
- 그러나 False Positive는 agent로 하여금 잘못된 결과를 조기에 제출하게 할 수 있다.
- Table 2는 다양한 성능 지표를 나타낸다.
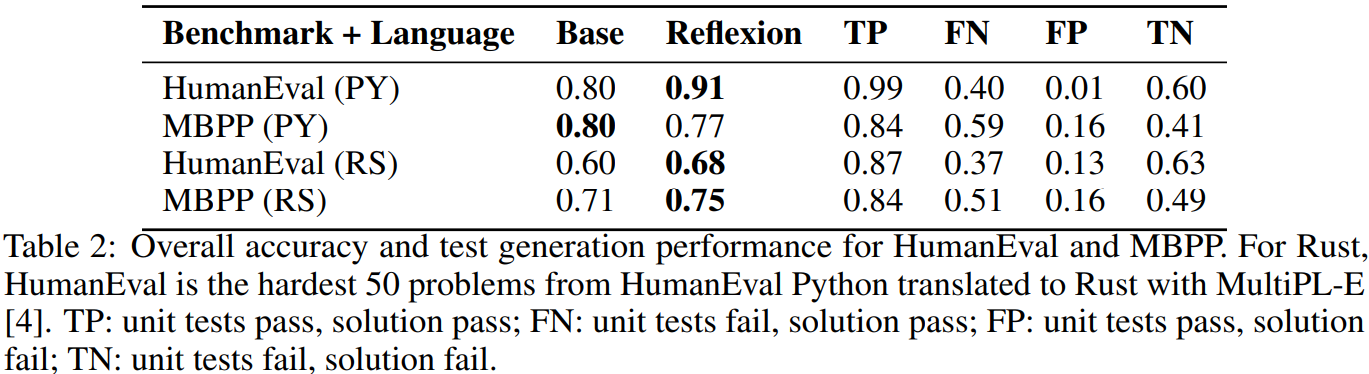
- 앞서서 MBPP Python이 baseline인 GPT-4보다 낮은 성능이 보인다는 것을 확인했다.
- 그리고 Table 2에서는 False Positive 수치들의 불일치를 확인했다.
- 이는, P(not pass@1 generation correct | tests pass), 즉, ‘모든 unit test를 통과했지만 실제로는 올바르지 않은 result가 있을 확률’을 나타낸다.
- HumanEval과 MBPP Python에서 baseline의 pass@1 accuracy는 82%, 80%로 비교적 유사하다.
- 그러나 MBPP Python의 FP rate는 16.3%로, HumanEval python의 1.4%에 비해 휠씬 높다.
- 이는 MBPP Python의 낮은 신뢰성을 의미한다.
Ablation study
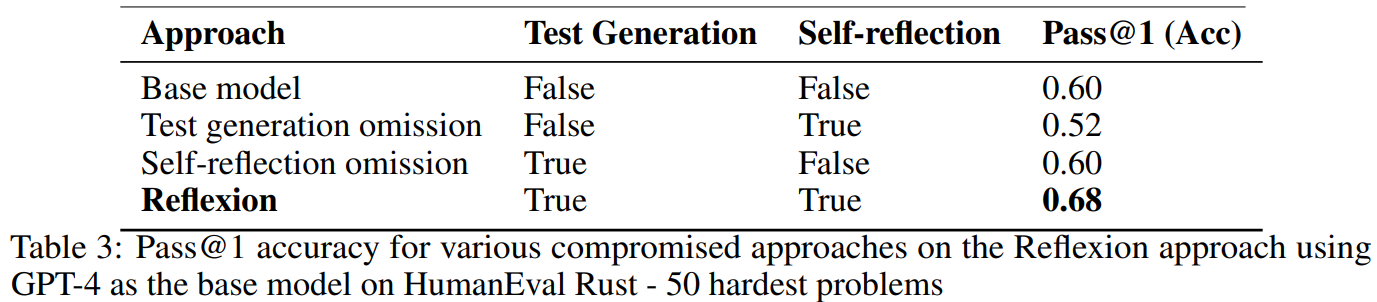
- Reflexion의 test generation과 self-reflection cooperation 요소를 HumanEval Rust의 가장 어려운 50개 집합에서 실험했다.
- 1) internal test generation & execution step 생략
- Agent의 현재 구현이 맞는지 확인할 때, unit test 없이 self-reflection을 수행하도록 테스트했다.
- 이는 accuracy가 52%로 떨어지며, baseline의 60%보다 낮고, unit test 없이는 agent가 조기 종료없이 잘못된 수정작업을 진행함을 보여준다.
- Agent의 현재 구현이 맞는지 확인할 때, unit test 없이 self-reflection을 수행하도록 테스트했다.
- 2) Self-reflection 생략
- Unit test 실패 이후에 자연어 설명 단계를 제거해, agent가 모든 unit test에 대한 오류 식별 및 구현 개선 작업을 통합하도록 강제했다.
- 이 경우 baseline보다 성능이 향상되지 않았다.(동일)
- 오류는 잘 찾지만, 수정작업에서 오류를 반영하지 못했다.
- 1) internal test generation & execution step 생략
Limitations
- Reflexion은 본질적으로 자연어를 통해 policy optimization을 수행하는 최적화 기법이다.
- Policy optimization은 experience를 통해 action choice를 개선하는 강력한 접근법이지만, 여전히 local minima에 수렴할 가능성이 있다.
- 이 연구에서는 long-term memory를 maximum capacity를 갖는 sliding window로 제한했지만, 향후 연구에서는 이 메모리 구조를 더 발전된 구조로 확장할 것을 권장한다.
- Code generation과 관련해서는, 정확한 input-output mapping을 지정하는 test-driven development에 여러 한계가 있다. 즉, 여러 함수들은 입력에 대해 출력을 예측하기 현실적으로 어려워 (결과가 비결정적, 환경의존적 등) 평가하는 것에 제한이 있다.
Conclusion
- Verbal enhancement를 통해 agent가 과거의 실수로부터 학습하도록 돕는 Reflexion 제안. 성능 우수.
- 향후 연구에서는 Reflexion이 자연어에서의 value learning이나 off-policy exploration 기법 같은 전통적 강화학습 설정에서 연구된 더 발전된 기술을 활용할 수 있을 것이다.

Anyone can be anything ... with agent!