
From ACL, 2004
- 사전 지식
ROUGE에서 Recall과 Precision
y : 모델이 만든 요약문 y’ : 사람이 만든 정답 요약Recall
-
정답 요약문의 단어 중 모델이 생성한 요약문에서 나타난 단어의 개수의 비율
Precision
-
모델이 생성한 요약문 중 정답 요약문과 얼마나 많은 단어가 겹치는지의 비율
-
0. Abstract
- ROUGE = Recall-Oriented Understudy for Gisting Evaluation
- 모델이 생성한 요약(후보 요약)과 인간이 만든 이상적인 요약(참조 요약)을 비교하는 자동화된 방법을 포함한다.
- (추출 요약, 생성 요약할 때 생성 요약 아님)
- (모델의 출력물로 나온 요약문이라는 뜻)
- 생성된 요약과 라벨 요약 사이에 중복되는 단위(n-gram, 단어 시퀀스, 단어 쌍 등)의 수를 세는 것
- 그래서 4가지 다른 지표인 ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S를 소개한다.
1. Introduction
- 요약문에 대한 evaluation을 수행하는 것은 ‘일관성, 간결성, 문법 정확성, 가독성, 내용’ 등 여러 지표를 평가해야 한다.
- 간단한 지표에 대한 수동 평가조차도 수 천 시간 이상의 human resource가 필요하므로 자주 수행되기 어렵다.
- 따라서 자동화된 요약 평가 방법이 필요하다.
- 코사인 유사도, n-gram, 최대 공통 부분열 등을 기반으로 한 평가 방법이 제시되었지만, 이러한 방식이 인간 판단과 어떤 상관 관계가 있는지는 보여주지 않았다.
- 우리는 2장부터 5장까지 n-gram과 최대 공통 부분열 등을 통한 여러가지 ROUGE 지표들을 제안하며, 6장에서는 이러한 지표들이 인간 판단과 어떤 상관 관계가 있는지를 보여준다.
2. ROUGE-N: N-gram Co-Occurrence Statistics
- ROUGE-N은 후보 요약과 참조 요약 사이의 n-gram Recall이며, 아래와 같이 계산된다.
- n은 n-gram의 길이를 나타내며, Count_match(gram_n)은 후보 요약과 참조 요약 집합에서 겹치는 n-gram의 최대 수이다.
- BLEU는 기계 번역의 자동 평가에서 사용되는 지표로, precision 기반의 척도이다.
- 분모에 있는 n-gram의 수는 더 많은 참조 요약을 사용함에 따라 증가한다.
- 여러 좋은 요약이 존재할 수 있으므로 직관적이고 합리적이다.
- 분자는 모든 참조 요약에 걸쳐 합산된다.
- 여러 참조 요약에서 일치하는 n-gram에는 더 많은 가중치가 부여된다.
2.1 Multiple References
- 한번에 여러 개의 참조 요약이 사용될 때, 후보 요약 s와 참조 집합의 각 참조 요약 r_i 간의 쌍 별로 ROUGE-N을 구한 뒤 최종적으로는 최대값을 사용한다:
- 위 방식의 구현을 위해서는 잭나이프 절차를 사용한다.
- M개의 참조 요약이 주어지면, M-1개의 참조 요약 집합에 대해 ROUGE-N 점수를 계산한다.
- 이를 모든 M개의 참조 요약마다 반복하여 총 M개의 ROUGE-N 점수를 얻는다.
- M개의 점수를 평균하여 최종 ROUGE-N 점수를 얻는다.
3. ROUGE-L: Longest Common Subsequence
- Longest Common Subsequence(LCS): 최장 공통 부분열, 두 문자열에서 최대 길이를 가진 공통 부분 수열
3.1 Sentence-Level LCS
→ 요약 문장 하나하나를 각각의 단위로 보고 ROUGE 점수를 계산
- 요약 문장을 단어의 연속으로 간주한다.
- 직관적으로, 두 요약문의 LCS가 길수록 두 요약은 더 유사하다.
- 참조 요약 X (길이 m)와 후보 요약 Y (길이 n) 사이의 유사성을 계산하기 위해 LCS 기반 F1 score를 사용하는 것을 제안한다.
- LCS(X,Y) : X,Y의 LCS 길이
- ß : Precision / Recall , F1-score는 Recall과 Precision에 대해 동일한 민감도로 변함
- ß가 크면 Precision가 더 중요하게 고려되고, ß가 작으면 Recall이 더 중요하게 고려
- F_lcs 측정값을 ROUGE-L 지표로 사용
- X = Y 일 경우 1, LCS(X,Y) = 0 일 경우 0
- LCS를 사용하는 장점 중 하나는 단순히 연속적인 일치가 아니라 문장 수준의 어순을 n-gram으로 반영하는 시퀀스 단위의 일치를 요구한다는 것이다.
- 또 다른 장점은 가장 긴 순서대로 common n-gram을 포함한다는 것으로, 미리 정해진 n-gram의 길이가 필요하지 않다는 것이다.
- 예시) ROUGE-2와의 비교
S1. police killed the gunman → Reference Summary
**S2. police kill the gunman → Candidate Sentence 1
S3. the gunman kill police → Candidate Sentence 2
S4. the gunmanpolice killed→ Candidate Sentence 3

- S2와 S3는 같은 ROUGE-2 점수를 갖는다 (하나의 bi-gram(the gunman)만을 가지므로)
- 하지만 S2와 S3의 ROUGE-L은 다르다.
- S2=3/4=0.75, S3=2/4=0.5
- 이는 ROUGE-L이 문장 수준에서 신뢰 가능한 지표임을 보여준다.
- 하지만 S2와 S3의 ROUGE-L은 다르다.
- 하지만 LCS는 하나의 시퀀스 단위만을 센다. 따라서 다른 LCS들은 최종 점수에 반영되지 못한다.
- 예를 들어, S4에서는 “the gunman” 또는 “police killed”를 세지만 둘 다는 아니다. 따라서 S3와 S4는 동일한 ROUGE-L 점수를 갖는다.
3.2 Summary-Level LCS
→ 전체 요약문장을 하나의 단위로 보고 ROUGE 점수를 계산
- 총 m개의 단어를 포함하는 u개의 문장으로 구성된 참조 요약과, 총 n개의 단어를 포함하는 v개의 문장으로 구성된 후보 요약
- r_i = {w1 w2 w3 w4 w5}이고, C가 c1 = {w1 w2 w6 w7 w8}과 c2 = {w1 w3 w8 w9 w5}로 이루어지면?
- r_i와 c1의 LCS는 “w1 w2”이고 r_i와 c2의 LCS는 “w1 w3 w5”
- r_i, (c1+c2)의 LCS는 “w1 w2 w3 w5” → LCS(r_i, C)는 4/5
3.3 ROUGE-L vs. Normalized Pairwise LCS
- 2002년 제안된 Normalized Pairwise LCS와의 차이점
- Normalized Pairwise LCS는 각 후보 요약들의 LCS들을 모두 찾아서 LCS의 최대 길이를 사용한다. (최대값)
- 하지만 ROUGE-L은 후보 요약 전체를 결합한 단위에서의 LCS를 찾아서 사용한다. (결합값)
- 따라서 ROUGE-L은 요약 전체의 맥락을 고려해서 유사성을 평가할 수 있고, Normalized Pairwise LCS는 개별 문장 간의 유사성을 평가할 수 있다.
4. ROUGE-W: Weighted Longest Common Subsequence
- LCS는 좋은 특성을 갖지만, basic LCS는 서로 다른 공간적 관계를 갖는 시퀀스를 구분하지 못한다:
X: [A B C D E F G]
Y1: [A B C D H I K]
Y2: [A H B K C I D]
- Y1과 Y2는 같은 ROUGE-L 점수를 갖는다.
- 하지만 Y1은 연속적인 LCS를 갖는데, Y3보다 더 높은 점수를 가져야 하지 않겠는가?
- 지금까지 만난 연속적인 일치의 길이를 기억하도록 Dynamic Programming table을 만들 수 있다.
- 이를 가중치가 있는 LCS(WLCS)라고 하고, k를 연속적인 길이로 사용한다.
- 두 문장 X, Y에 대한 WLCS 점수는 아래와 같은 Dynamic Programming 수도 코드로 나타낼 수 있다.
(1) For (i = 0; i <=m; i++)
c(i,j) = 0 // initialize c-table
w(i,j) = 0 // initialize w-table
(2) For (i = 1; i <= m; i++)
For (j = 1; j <= n; j++)
If xi = yj Then
// the length of consecutive matches at
// position i-1 and j-1
k = w(i-1,j-1)
c(i,j) = c(i-1,j-1) + f(k+1) – f(k)
// remember the length of consecutive
// matches at position i, j
w(i,j) = k+1
Otherwise
If c(i-1,j) > c(i,j-1) Then
c(i,j) = c(i-1,j)
w(i,j) = 0 // no match at i, j
Else c(i,j) = c(i,j-1)
w(i,j) = 0 // no match at i, j
(3) WLCS(X,Y) = c(m,n)- w 테이블 안에 연속적인 일치의 길이를 저장하고, 가중치 함수인 f 함수를 통해 c 테이블 안에 가중치 값(WLCS 점수)을 저장한다.
- 가중치 함수 f는 연속적인 일치에 더 많은 점수를 부여하도록 설계
- ex) n-gram 시퀀스가 끊길 때마다 페널티 부여하는 함수
- WLCS를 기반으로 한 Recall, Precision, F1 score는 아래와 같이 계산된다.
- (f(가중치 함수)의 역함수 사용 이유)
- 가중치가 적용되어 있는 LCS 점수를 기존 길이 비율로 정규화하기 위함
- (f(가중치 함수)의 역함수 사용 이유)
5. ROUGE-S: Skip-Bigram Co-Occurrence Statistics
- Skip-Bigram은 문장 내에 단어 쌍을 간격을 허용하면서 순서대로 나타내는 것이다.
- Skip-Bigram Co-Occurrence Statistics은 후보 번역과 참조 번역 사이의 skip-bigram 중복도를 측정한다.
S1. police killed the gunman → Reference Summary
**S2. police kill the gunman → Candidate Sentence 1
S3. the gunman kill police → Candidate Sentence 2
S4. the gunmanpolice killed→ Candidate Sentence 3
- 각 문장은 4C2 = 6개의 skip-bigram을 갖는다.
- ex) S1 = (“police killed”, “police the”, “police gunman”, “killed the”, “killed gunman”, “the gunman”)
- S2와 S1은 3개가 일치하며, S3는 1개의 일치, S4는 2개가 일치한다.
- 길이가 m인 문장 X와 길이가 n인 문장 Y가 주어질 때, skip-bigram 기반의 F1-score는 아래와 같이 계산한다.
- SKIP2(X,Y)는 X와 Y 사이의 skip-bigram 일치 수를 의미한다.
- S1을 참조 요약으로 할 때, ROUGE-S 점수는
- S2: 0.5, S3: 0.167, S4: 0.333
- ROUGE-L 보다 더 직관적이다.
- 단어 사이의 거리를 두는 skip-bigram의 장점
- 연속적인 일치를 요구하지 않으면서도 단어 순서에 민감하다는 것
- 단어 사이 거리 제한을 두지 않는다면?
- ‘the the’나 ‘of in’ 같은 부적절한 일치도 유효하게 계산될 수 있다.
- d_skip 파라미터로 스킵 거리 조절
5.1 ROUGE-SU: Extension of ROUGE-S
- ROUGE-S의 잠재적인 문제는, 후보 문장이 참조 문장과 일치하는 단어 쌍이 없을 경우에는 점수를 주지 않는다는 것이다.
- 예를 들어, 아래 S5는 ROUGE-S 점수가 0이다:
S5. gunman the killed police
- S5는 S1의 정확한 역순이며, 이들 사이에는 skip-bigram 일치가 없다.
- 하지만 이들을 구분할 필요가 있다.
- 따라서 bigram 단위가 아닌 unigram 단위로 세는 ROUGE-SU를 추가했다.
6. Evaluations of ROUGE
- 인간 요약과의 비교를 위해 DUC 2001, 2002, 2003 데이터를 사용했으며, 이 데이터에는 다음과 같은 인간 판단이 포함되어 있다.
- 약 100 단어에 대한 단일 문서 요약
- 약 10 단어에 대한 매우 짧은 단일 문서 요약
- 약 10 단어에 대한 다중 문서 요약
- ROUGE score와 인간 요약 사이의 상관 관계를 분석하기 위해, 즉 ROUGE가 인간의 판단을 얼마나 잘 반영하는지 보기 위해서
- 피어슨 상관계수, 스피어만 상관계수, 켄달 상관계수를 계산했다.
- 공간의 한계로 논문에는 피어슨 상관계수 결과만 싣는데, 나머지도 피어슨과 밀접하다.
- 요약문을 기존 버전(CASE 세트), 어간 추출 버전(STEM 세트), 불용어 제거 버전(STOP 세트)로 나누어 준비해 각각의 영향을 관찰했다.
- 피어슨 상관계수, 스피어만 상관계수, 켄달 상관계수를 계산했다.

- 표1 은 DUC 2001, 2003의 100단어 단일 문서 요약에 대한 17 종류의 ROUGE 지표와 인간 판단과의 피어슨 상관계수를 나타낸다.
- 녹색은 최고값을 나타내며, 통계적으로 유사한 값들은 회색으로 표시되었다.
- 어간 제거나 불용어 제거가 상관관계에 영향을 미치지 않았으며,
- ROUGE-2가 ROUGE-N 변형 중에서는 가장 성능이 좋으며,
- ROUGE-L,W,S 모두 잘 수행되며,
- 다중 참조를 수행하면 성능이 향상되지만 큰 향상은 아니다.
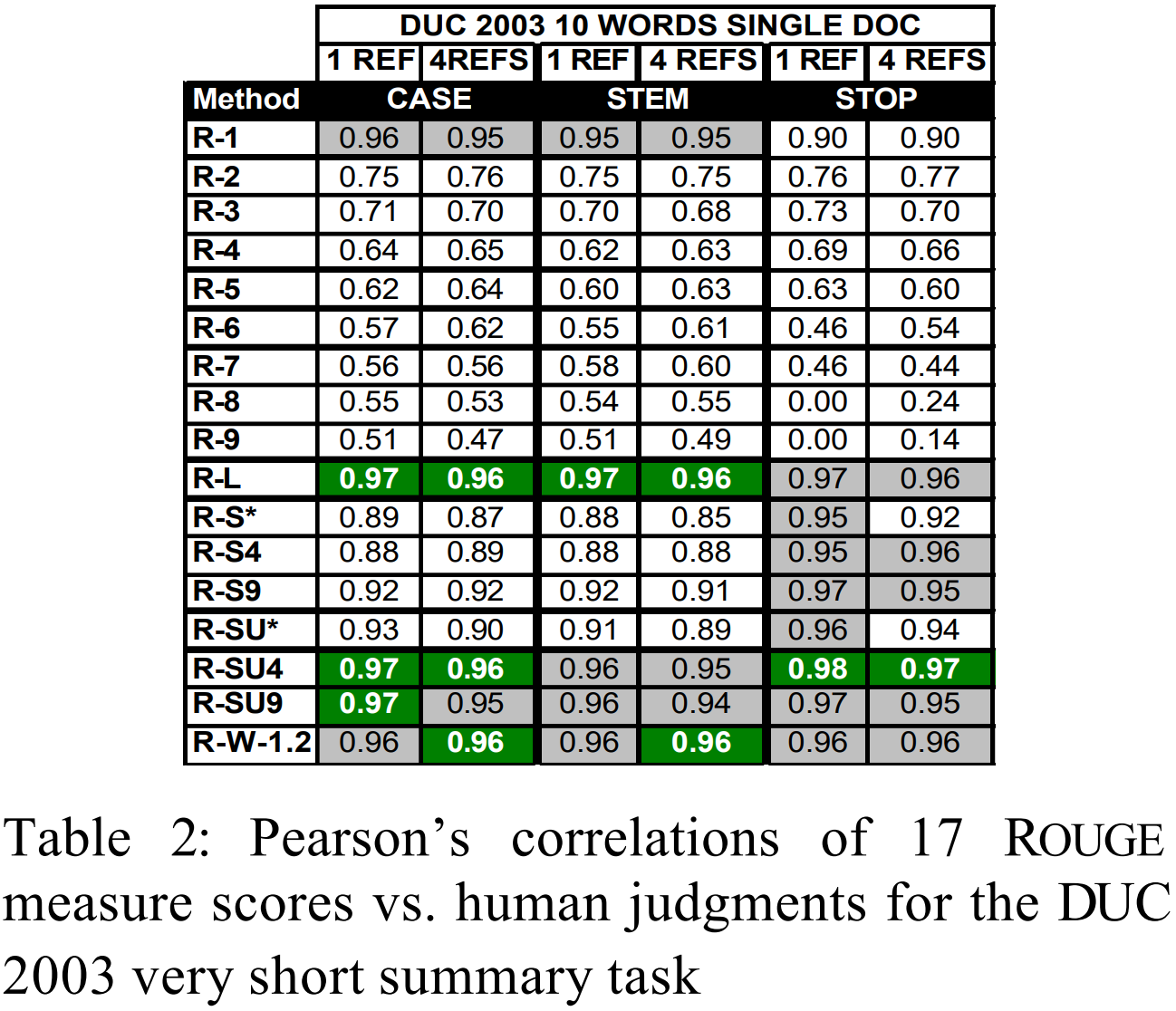
- 표2 는 DUC 2003의 단일 문서의 매우 짧은 요약에 대한 상관관계 분석 결과이다.
- N > 1인 ROUGE-N은 결과가 현저히 떨어진다.
- 불용어 제거는 일반적으로는 성능을 향상시키지만 ROUGE-1은 아니다.
- 이 데이터는 샘플이 많기 때문에 다중 참조가 상관관계를 향상시키지 않았다.
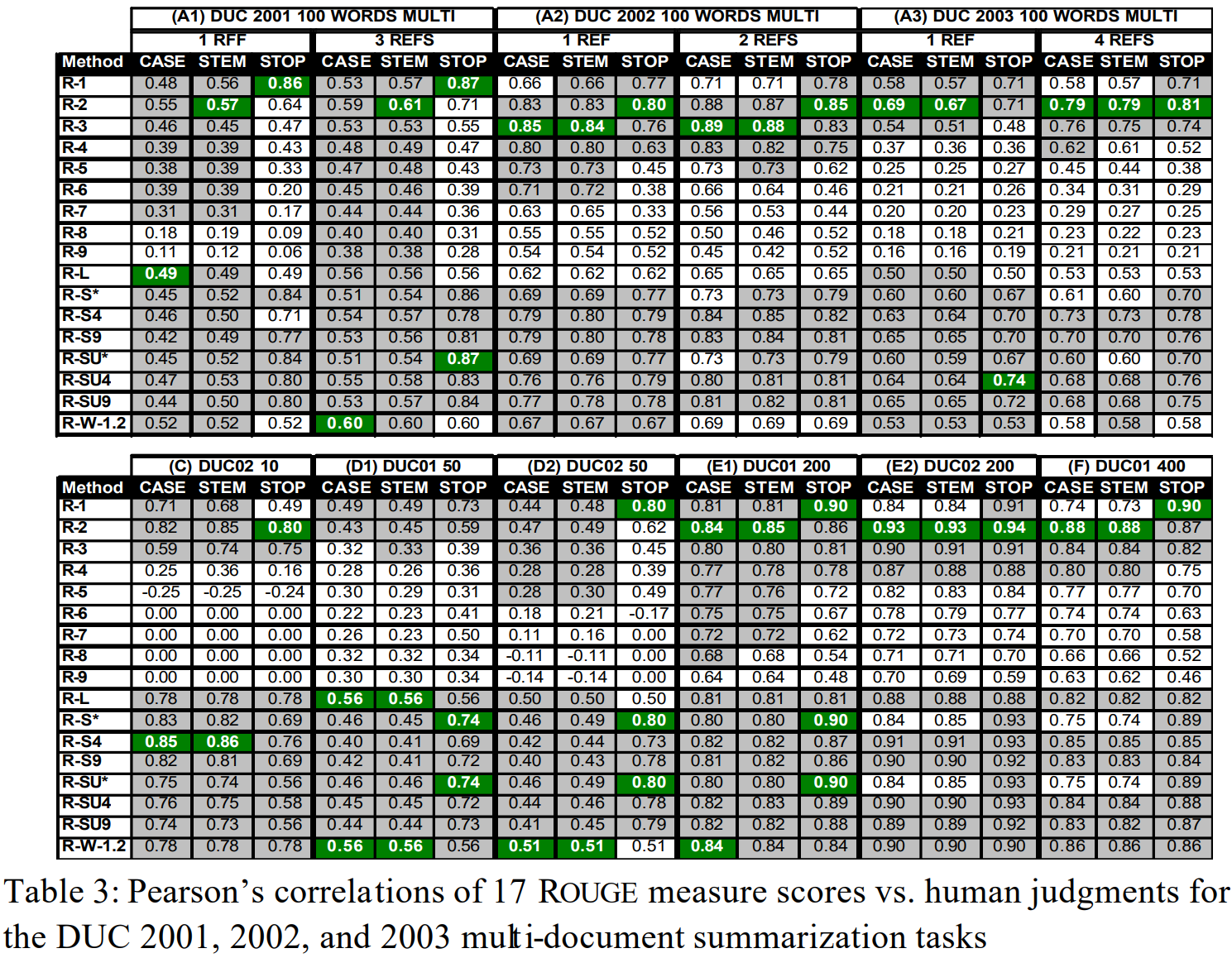
- 표3 A1,A2,A3은 DUC 2001, 2002, 2003의 100단어 다중 문서 요약에 대한 상관관계 분석 결과이다.
- 요약하면, 다중 참조를 사용하고, 불용어를 제거하는 것이 일반적으로 성능을 향상시킨다.
- 표3 C, D1,D2,E1,E2,F는 나머지 DUC 데이터에 대해 다중 참조를 사용한 것에 대한 상관관계 분석 결과이다.
- 불용어 제거가 특히 50단어 이상의 다중 문서 요약에서 성능을 향상시킨다는 것 보임.
- 200단어, 400단어 요약에서는 더 나은 상관 관계(>0.70)
- 불용어 제거가 특히 50단어 이상의 다중 문서 요약에서 성능을 향상시킨다는 것 보임.
7. Conclusions
- ROUGE 지표를 제안했으며, 3개년의 DUC 데이터를 사용해 ROUGE에 대한 평가를 수행했다.
- 우리는 이러한 사실들을 알아냈다.
- (1) ROUGE-2, ROUGE-L, ROUGE-W, ROUGE-S가 단일 문서 요약 작업에서 잘 동작하며,
- (2) ROUGE-1, ROUGE-L, ROUGE-W, ROUGE-SU4, ROUGE-SU9가 매우 짧은 요약(또는 헤드라인 같은 요약)을 평가하는 데 효과적이고,
- (3) 다중 문서 요약 작업에서 높은 상관 관계를 달성하기는 어려웠지만, 불용어를 제거하면, ROUGE-1, ROUGE-2, ROUGE-S4, ROUGE-S9, ROUGE-SU4, ROUGE-SU9가 효과적으로 동작했다.
- (4) 불용어를 제외하는 것은 일반적으로 상관관계를 향상시켰으며,
- (5) 다중 참조를 사용함으로써 인간 판단과의 상관관계가 증가했다.
- 요약하면, ROUGE는 요약의 자동 평가에 효과적으로 사용될 수 있음을 보여준다.
- 그러나 ROUGE가 단일 문서 요약 작업에서 효과적인 것처럼 다중 문서 요약 작업에서도 인간의 판단과 높은 상관 관계를 달성하도록 하는 것은 향후 연구로 진행되어야 하는 주제다.

Anyone can be anything ... with agent!