[논문 리뷰] PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization (2020)
Paper Review
목록 보기
7/15

From ICML, 2020
1. Introduction
- Text summarization은 입력 문서에서 정확하고 간결한 요약을 만드는 것을 목표로 하며, 추출 요약과 생성 요약으로 나뉜다.
- 생성 요약 분야에서는 RNN기반의 seq2seq 아키텍처가 주를 이뤘으며, 최근 Transformer가 등장했다.
- 더 최근에는, 넓은 분야와 고품질, 긴 길이, 많은 양의 문서, 다양한 도메인의 데이터셋을 지도학습으로 학습시켜 좋은 성능을 이끌어내는 연구가 늘어나고 있다.
- 그러나 이런 광범위한 설정의 모델들을 체계적으로 평가하는 작업은 거의 없었다.
- 본 연구(PEGASUS)는 생성 요약에 대한 pre-training 기법을 연구하고, 12가지 데이터셋에 대해 평가한다.
- PEGASUS는 문서에서 특정 문장 전체를 마스킹한 후 해당 문장(gap-sentences)들을 모델이 생성하게 하는 것이 요약 task에 효과적임을 발견함. → Gap-Sentences Generation (GSG)
- Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models → PEGASUS
- 12개 데이터셋에서 모두 SOTA와 비슷하거나 능가하는 성능을 보였다.
- 큰 규모의 데이터셋은 구하기 힘들고, 실험 결과와 실생활에서의 결과가 다른 경우가 많다.
- 그래서 적은 양의 데이터로도 쉽게 fine-tuning이 되는지 실험했다.
- 6개의 데이터셋에서는 1000개의 데이터셋만으로도 SOTA를 달성했다.
- 큰 규모의 데이터셋은 구하기 힘들고, 실험 결과와 실생활에서의 결과가 다른 경우가 많다.
2. Related work
- 생략(MASS, UniLM, T5, BART)
- PEGASUS는 위 모델들과 다르게 문장을 통으로 마스킹하며, 마스킹할 대상을 랜덤으로 고르지 않고 중요한 문장을 골랐다는 내용.
- PEGASUS의 output은 문서 전체가 아닌 masked sentences만.
3. Pre-training Objectives
3.1 Gap Sentences Generation (GSG)
- 우리는 Pre-training objective가 downstream task와 닮을수록 빠르고 좋은 fine-tuning 성능을 보인다고 가정한다.
- GSG 학습은 다음과 같이 진행된다.
- 문서에서 마스킹할 전체 문장을 선택하고,
- 선택한 문장을 concatenate하여 pseudo-summary를 만들고,
- gap sentence 위치에 [MASK1]을 치환한다.
- Gap Sentences 고르는 방식
- Random : 랜덤으로 m문장 선택
- Lead : 첫번째 m문장 선택
- Principal : ROUGE1-F1 점수가 가장 높은 m개의 문장 선택
- Ind (Independently): 각 문장을 독립적으로 점수 매김
- Seq (Sequentially): 문장을 순서대로 평가하여 점수 매김
- Uniq (Unique): n-gram을 세트로 간주하여 점수를 매김 (동일한 n-gram 중복 count X)
- Orig (Original): 동일한 n-gram 중복 count 하여 점수 매김

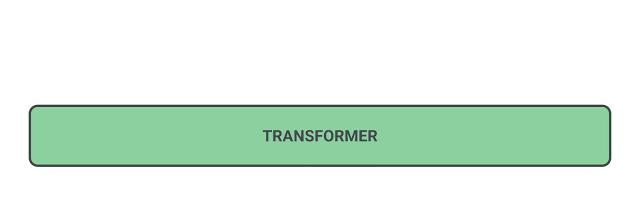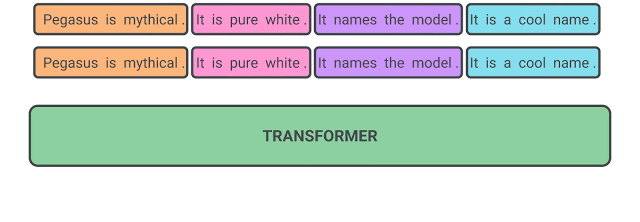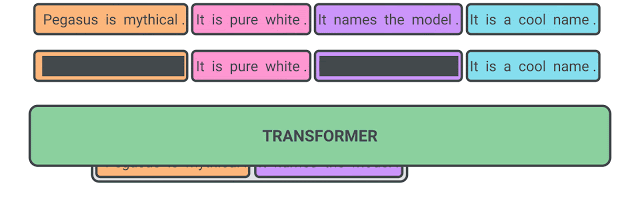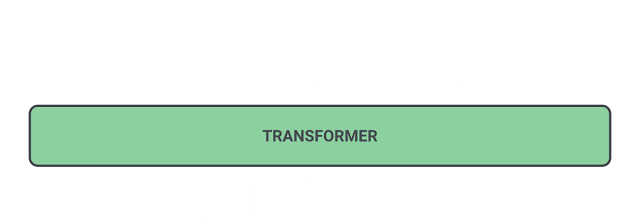
3.2 Masked Language Model (MLM)
-
BERT와 같이, 15%의 토큰을 input으로 사용하고, 그 중 80%는 [MASK2] 토큰으로, 10%는 random, 10%는 unchanged
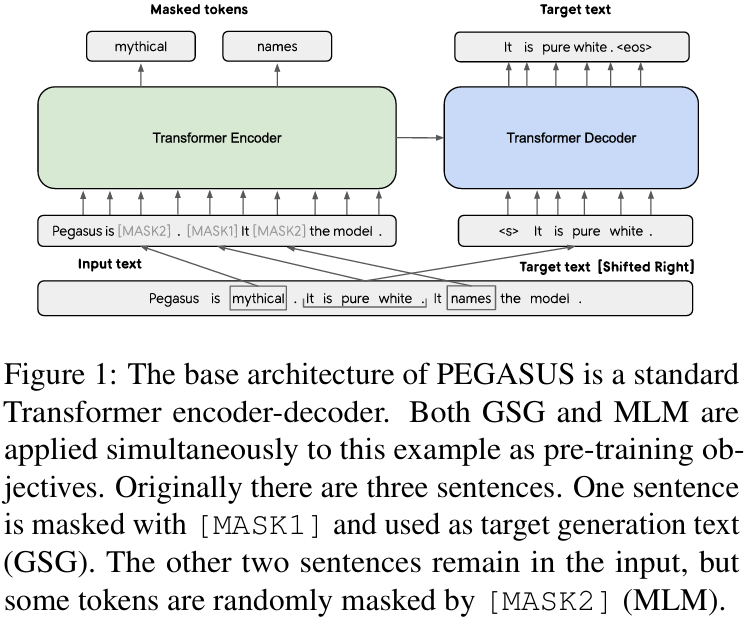
-
Fig. 1 은 GSG와 MLM이 둘다 적용된 예시를 보여준다.
- 그러나 MLM이 downstream tasks에서는 효과가 없었기 때문에 final model에는 포함하지 않았다.
4. Pre-training Corpus
- C4 (Colossal and Cleaned version of Common Crawl)
- 750GB의 웹 크롤링 데이터
- HugeNews
- 1.5B개의 기사 (3.8TB)
- only main article text
5. Downstream Tasks/Datasets
- XSum
- CNN/Dailymail
- NEWSROOM
- Multi-News
- Gigaword
- arXiv,PubMed
- BIGPATENT
- WikiHow
- Reddit TIFU
- AESLC
- BillSum
6. Experiments
- PEGASUS_base
- 인코더&디코더 Layer 수(L): 12
- Hidden Size(H): 768
- Feed-Forward Layer Size(F): 3072
- Self-attention Heads 수(A): 12
- PEGASUS_large
- 인코더&디코더 Layer 수(L): 16
- Hidden Size(H): 1024
- Feed-Forward Layer Size(F): 4096
- Self-attention Heads 수(A): 16
- Positional Encoding (Transformer의 그것과 같음)
- Optimizer: Adafactor (pre-training과 fine-tuning 모두)
- Square root learning rate decay
- Dropout rate: 0.1
- ##Pre-train되지 않은 PEGASUS_base를 Transformer_base와 동일하게 부른다.##
6.1 Ablations on PEGASUS_base
6.1.1 Pre-training Corpus
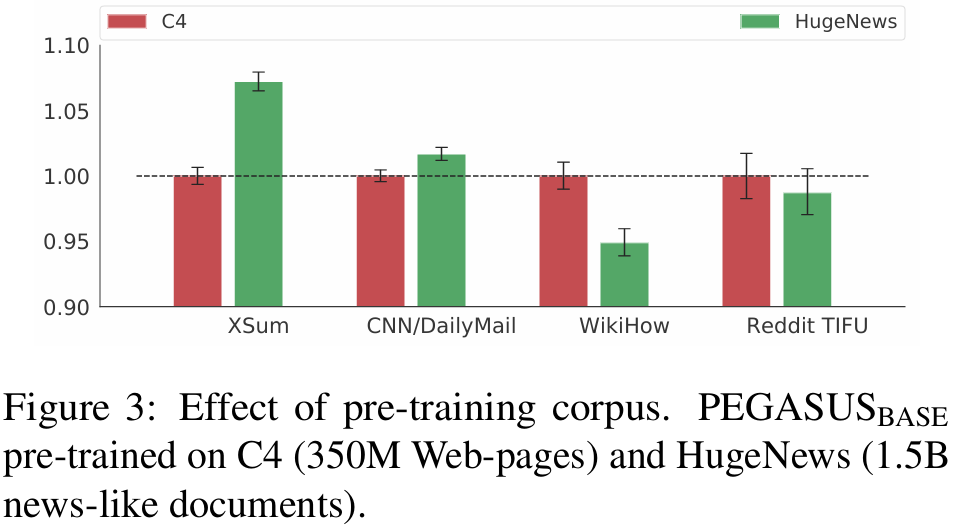
- Fig. 3 : C4를 1.00으로 기준으로 하여 각 데이터셋에 대해 HugeNews의 성능을 일반화한 결과
- HugeNews는 news 데이터셋에서 더 높은 성능, C4는 news가 아닌 informal 데이터셋에서 더 높은 성능
- → pre-train 모델은 domain이 aligned 되어 있을 때 transfer가 더 잘 수행된다.
6.1.2 Effect of Pre-training Objectives
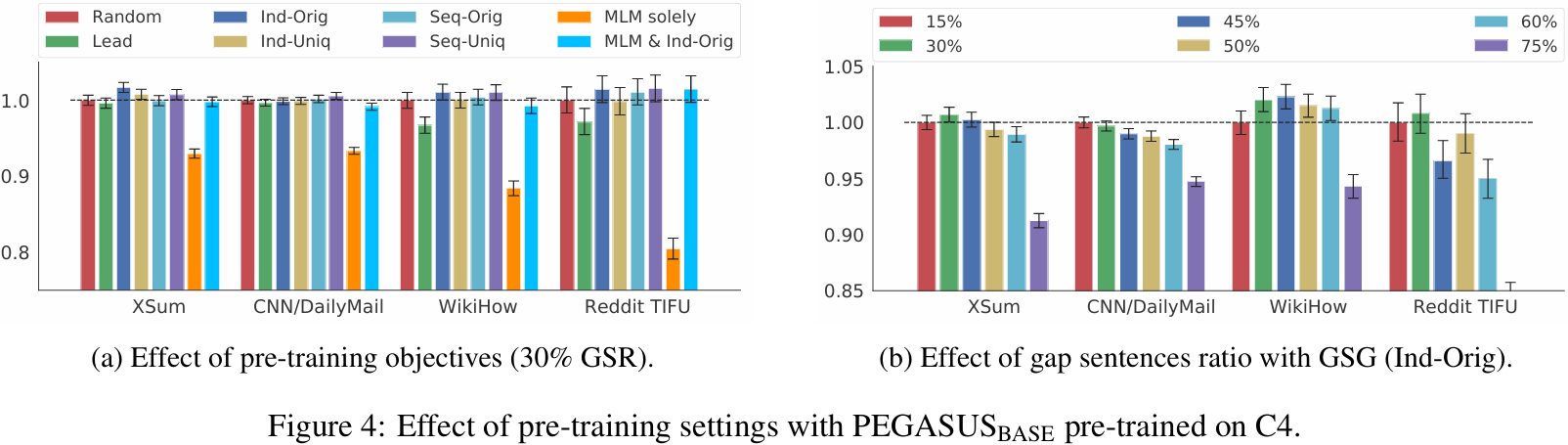
- 30%의 Gap sentences를 고르는데 사용되는 GSG의 6가지 기법(Lead, Random, Ind-Orig, Ind-Uniq, Seq-Orig, Seq-Uniq)의 성능을 비교했다.
- Fig. 4(a)에 나타난 것처럼, Ind-Orig 가 가장 좋은 성능을 보인다.
- GSR(Gap Sentence Ratio)는 0.5 이하일 때 가장 높은 성능
- MLM 사용 시 초기 pre-training checkpoint(100k-200k steps)에서는 성능 이득을 보이지만, 500k 이후부터는 이득을 억제한다.
- 따라서 MLM 사용 x
- → PEGASUS_large는 GSG 기법은 Ind-Orig, GSR은 30%, MLM 적용 X
6.1. Effect of Vocabulary
- Byte-pair-encoding algorithm(BPE)과 SentencePiece Unigram algorithm(Unigram)의 두 tokenizer에 대해 성능을 비교함
- 비교 조건: PEGASUS_base 모델에 C4로 500k step으로 pre-train, 15% GSR + Ind-Orig
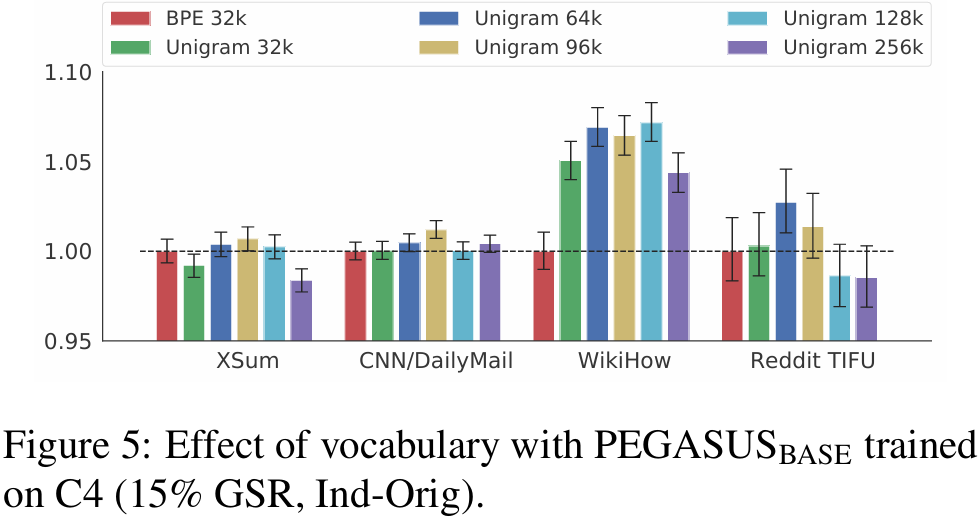
- News 데이터셋에서는 BPE와 Unigram 성능이 유사, Non-news에서는 Unigram이 더 좋은 성능 보임
- WikiHow는 Unigram 128k, Reddit TIFU는 64k일 때 가장 좋은 성능
- → PEGASUS_large에는 Unigram 96k 선택
6.2 Larger Model Results
- Abstractive dataset 뿐만 아니라 Extractive dataset을 타겟으로 한 성능 향상도 중요하므로, 20%의 선택된 문장은 [MASK1]으로 치환하던 것에서 unchanged로 방식을 변경했다.
- GSR의 20%는 unchanged, 80%는 GSG
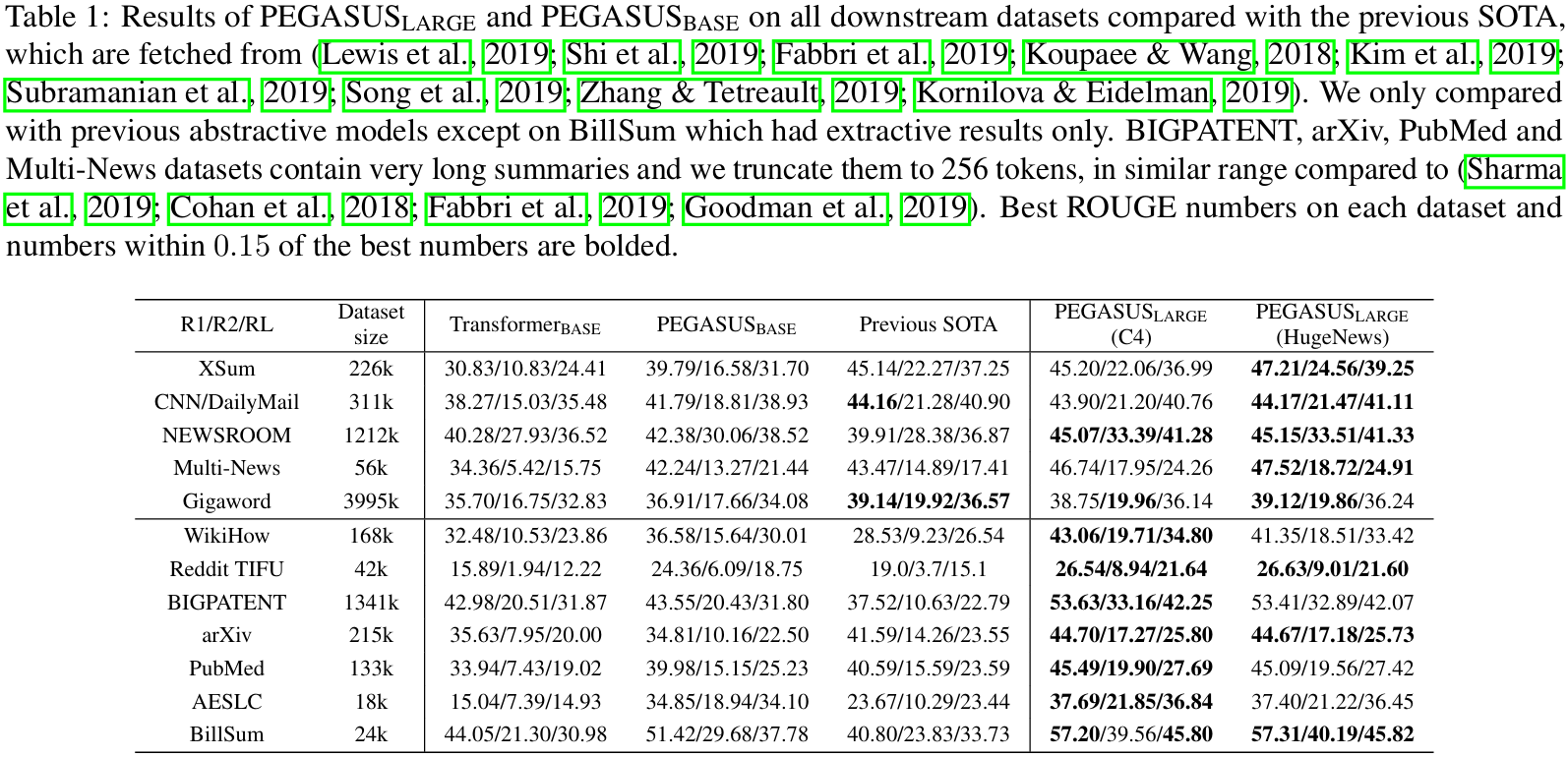
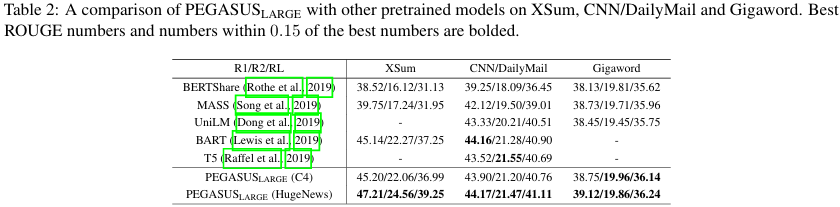
- PEGASUS_base는 많은 데이터셋에서 SOTA를 넘어섰으며, PEGASUS_large는 모든 데이터셋에서 SOTA를 넘어섰다.
- Transformer_base에서 PEGASUS_large로 발전할 때 소규모 데이터셋에서의 성능 향상은 특히 큰 편이다.
- ROUGE2-F1 score가 AESLC은 거의 3배, Reddit TIFU는 5배가 됨.
- → 소규모 텍스트 요약이 pre-training에 가장 이득을 본다.
6.3 Zero and Low-Resource Summarization
- 적은 양의 데이터셋에 대한 fine-tuning 성능을 확인하기 위해 0, 1k, 10k, 100k 개에 대한 Rouge1,2,L-F1 score를 측정한다.
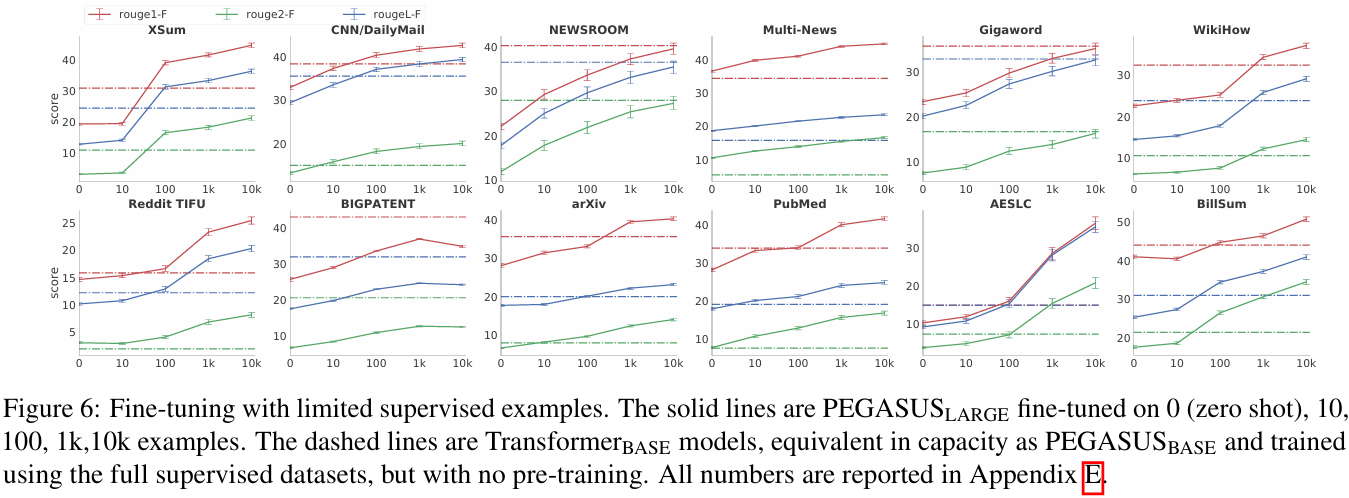
- 12개 중 8개의 데이터셋에서, 단 100개의 example만으로도 PEGASUS_large는 Transformer_base의 성능을 앞질렀다.
- 12개 중 6개의 데이터셋에서, 1000개의 example로 기존 SOTA 성능을 추월했다.
6.4 Qualitative Observations and Human Evaluation
- PEGASUS가 생성한 요약문이 Human evaluation과 얼마나 차이나는지 비교한다.
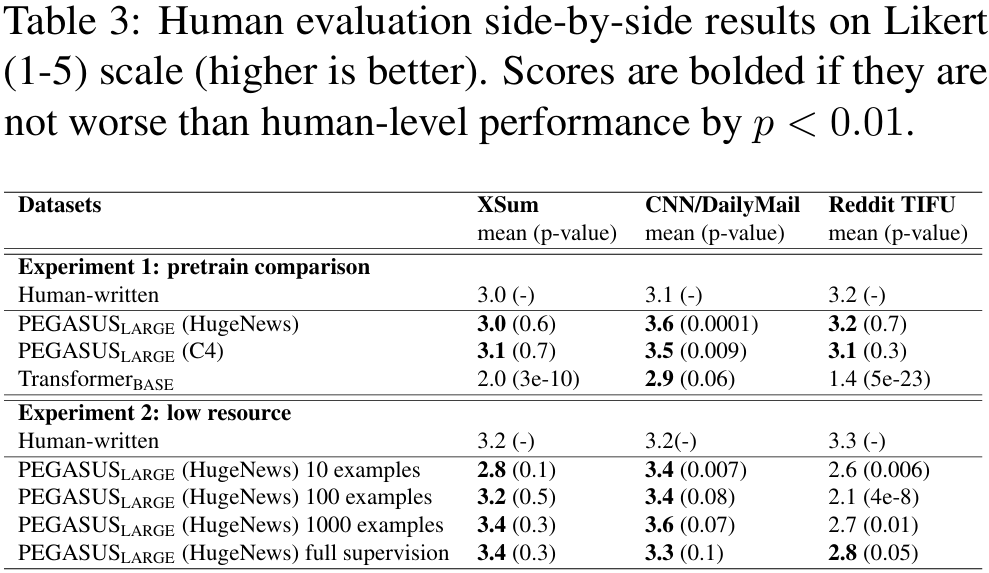
- 이를 위해 Amazon Mechanical Turk에 돈을 주고 요약문(model summaries, reference summaries)에 대한 evaluation을 의뢰했다.
- 3가지 데이터셋에 대한 평가이며, 1~5점으로 이루어져있다.
- Table 3를 보면, Reddit TIFU를 제외한 데이터셋에서는 PEGASUS 모델이 만든 summary가 인간이 만든 summary보다 나쁘지 않은 편임을 알 수 있다.
6.5 Test-set Overlap with Pre-training Corpus
- Pre-training에 사용된 corpus 데이터와, downstream 데이터셋들 간에 데이터 중복 정도를 측정하고, pre-trained 모델이 중복 정보에 대한 기억력을 활용할 수 있는지 연구했다.
- (생략)
- XSum에서만 15%~20% 사이의 상당한 중복이 있었고, 이러한 example을 필터링해도 ROUGE score가 1%이상 변하지 않음
- 모델은 중복 정보에 대한 기억 사용은 없는 것으로 나타났다.
6.6 Additional PEGASUS_large Improvements
- (생략)
7. Conclusion
- PEGASUS는 abstractive summarization을 위해 최적화된 pre-training objective인 Gap-Sentences Generation을 제안했다.
- GSG를 위한 여러 방안을 제안했고, 최적의 방식을 선택했다.
- 이를 통해 12개의 데이터셋에서 SOTA를 달성했다.
- 또한 unseen data에도 빠르게 적응하여, 1000개의 example만으로도 강력한 성능을 보임을 확인했다.
- 마지막으로 human evaluation을 통해 여러 데이터셋에서 인간 성능에 준하는 성능을 달성했음을 보였다.

Anyone can be anything ... with agent!