
Chapter 9. Web Robots
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Extracting Links and Normalizing Relative Links
Cycle Avoidance
As a crawler moves through the Web, it is constantly retrieving HTML pages. It needs to parse out the URL links in each page it retrieves and add them to the list of pages that need to be crawled. While a crawl is progressing, this list often expands rapidly, as the crawler discovers new links that need to be explored. Crawlers need to do some simple HTML parsing to extract these links and to convert relative URLs into their absolute form. “Relative URLs” in Chapter 2 discusses how to do this conversion.
-
크롤러는 웹을 따라 이동하며 계속해서 HTML 페이지를 수집합니다.
-
수집한 페이지마다 URL 링크를 파싱하여 크롤링이 필요한 페이지 리스트에 추가해야 합니다.
-
크롤링을 진행하며 탐색이 필요한 새로운 링크를 발견할 때마다 리스트는 급속도로 확장합니다.
-
크롤러는 단순한 HTML 파싱 기법을 사용하여 링크를 추출하고 Relative URL을 Absolute Form으로 변환할 필요가 있습니다.
-
Chapter 2의 "Relative URLs"에서 이를 수행하는 방식에 대해 언급합니다.
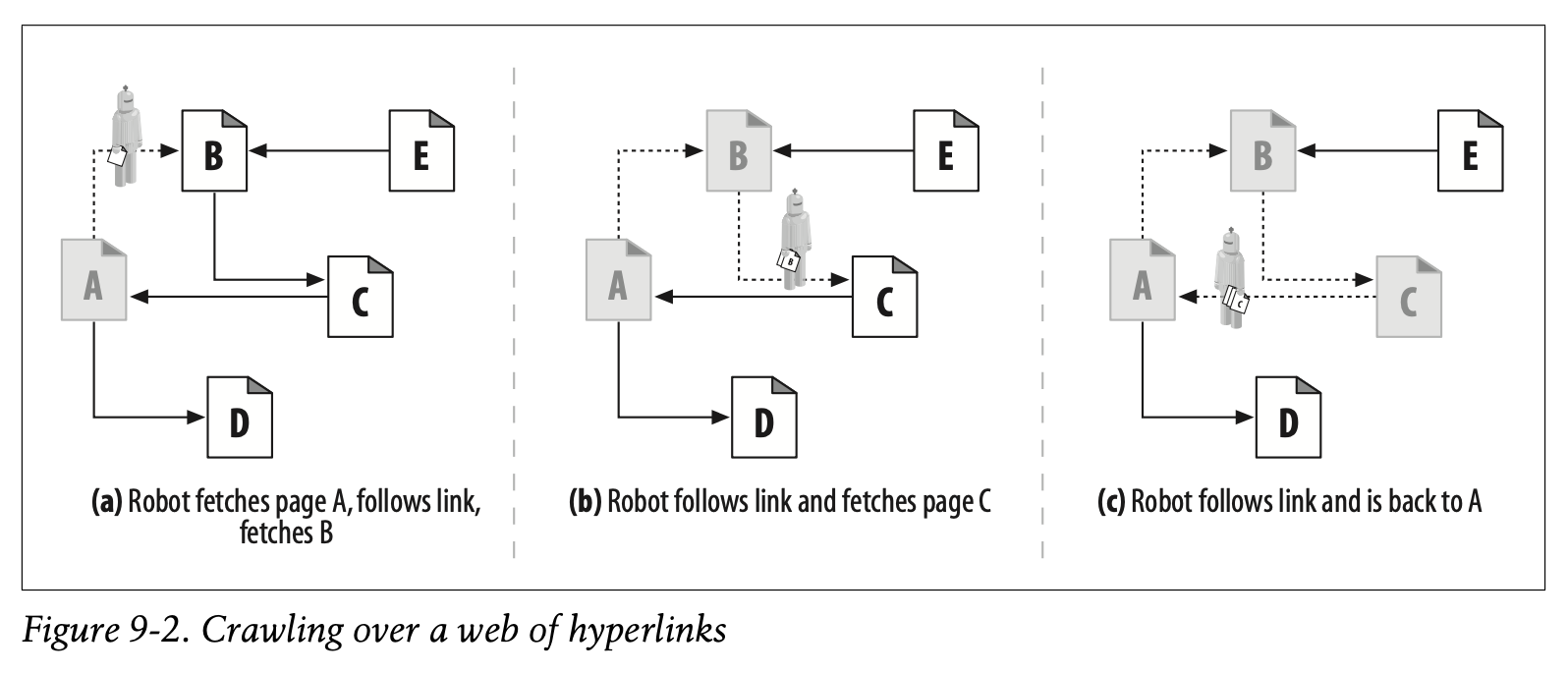
When a robot crawls a web, it must be very careful not to get stuck in a loop, or cycle. Look at the crawler in Figure9-2:
• In Figure9-2a, the robot fetches page A, sees that A links to B, and fetches page B.
• In Figure9-2b, the robot fetches page B, sees that B links to C, and fetches page C.
• In Figure9-2c, the robot fetches page C and sees that C links to A. If the robot fetches page A again, it will end up in a cycle, fetching A, B, C, A, B, C, A...
-
로봇이 웹을 크롤링할 때는 루프나 사이클에 빠지지 않도록 유의해야 합니다.
-
Figure 9-2의 크롤러에 주목해봅시다.
-
Figure 9-2a에서 로봇은 A 페이지를 불러옵니다. 그리고 A와 연결되어 있는 B 페이지를 불러옵니다.
-
Figure 9-2b에서 로봇은 B 페이지를 불러옵니다. 그리고 B와 연결되어 있는 C 페이지를 불러옵니다.
-
Figure 9-2c에서 로봇은 C 페이지를 불러옵니다. 그러나 C 페이지는 A와 연결되어 있습니다. 만약 로봇이 A 페이지를 다시 불러온다면 A, B, C, A, B, C, A, ... 를 끊임없이 반복하는 사이클이 발생합니다.
Robots must know where they’ve been to avoid cycles. Cycles can lead to robot traps that can either halt or slow down a robot’s progress.
-
로봇은 사이클을 피하기 위해 자신이 어디에 있는지 알아야 합니다.
-
사이클이 로봇의 진행을 멈추거나 느리게 하는 트랩이 될 수 있습니다.
Loops and Dups
Cycles are bad for crawlers for at least three reasons:
- 사이클은 크게 세 가지 이유로 크롤러에 악영향을 미칩니다.
• They get the crawler into a loop where it can get stuck. A loop can cause a poorly designed crawler to spin round and round, spending all its time fetching the same pages over and over again. The crawler can burn up lots of network bandwidth and may be completely unable to fetch any other pages.
-
사이클은 크롤러가 루프에 빠져 멈추게 할 수 있습니다.
-
루프는 잘못 설계된 크롤러가 계속해서 똑같은 페이지를 반복해서 불러오며 모든 시간을 소모하게 합니다.
-
네트워크 대역폭을 소진하면서도 다른 페이지들은 전혀 불러오지 못하는 상황인 셈입니다.
• While the crawler is fetching the same pages repeatedly, the web server on the other side is getting pounded. If the crawler is well connected, it can overwhelm the web site and prevent any real users from accessing the site. Such denial of service can be grounds for legal claims.
-
크롤러가 똑같은 페이지를 반복해서 불러오는 동안 웹 서버는 부하를 받습니다.
-
만약 크롤러의 연결 상태가 양호하다면 웹 사이트가 과부하되어 실제 사용자가 사이트에 접근하지 못하게 만들 수 있습니다.
-
이러한 강제적 서비스 중단은 법적 소송의 근거가 될 수도 있습니다.
• Even if the looping isn’t a problem itself, the crawler is fetching a large number of duplicate pages (often called “dups,” which rhymes with “loops”). The crawler’s application will be flooded with duplicate content, which may make the application useless. An example of this is an Internet search engine that returns hundreds of matches of the exact same page.
-
루프 자체가 문제가 되지 않더라도 크롤러는 많은 수의 중복 페이지를 불러오고 있습니다. 이러한 페이지를 "dups"라고 부릅니다.
-
차고 넘치는 중복된 콘텐츠로 인해 넘쳐 크롤러 응용 프로그램이 쓸모가 없어지게 됩니다.
-
인터넷 검색 엔진이 정확히 동일한 페이지를 수백 개 반환한다고 생각하면 이해가 잘 될 것입니다.
Trails of Breadcrumbs
Unfortunately, keeping track of where you’ve been isn’t always so easy. At the time of this writing, there are billions of distinct web pages on the Internet, not counting content generated from dynamic gateways.
-
안타깝게도 방문한 위치를 추적하는 것이 항상 쉽지만은 않습니다.
-
동적 게이트웨이로부터 생성되는 콘텐츠의 개수를 포함하지 않고도 수십억 개의 웹 페이지가 지금도 인터넷상에 존재하고 있습니다.
If you are going to crawl a big chunk of the world’s web content, you need to be prepared to visit billions of URLs. Keeping track of which URLs have been visited can be quite challenging. Because of the huge number of URLs, you need to use sophisticated data structures to quickly determine which URLs you’ve visited. The data structures need to be efficient in speed and memory use.
-
만약 사용자가 전 세계의 방대한 웹 콘텐츠를 크롤링하고자 한다면, 수십억 개가 넘는 URL을 방문할 준비가 되어있어야 합니다.
-
어떤 URL을 방문했는지 추적하는 것은 상당히 어렵습니다.
-
URL이 너무 많기 때문에 어떤 URL에 방문했는지 빠르게 알기 위해서 정교한 자료구조를 사용할 필요가 있습니다.
-
이때 자료구조는 속도와 메모리 사용량이 효율적이어야 합니다.
Speed is important because hundreds of millions of URLs require fast search structures. Exhaustive searching of URL lists is out of the question. At the very least, a robot will need to use a search tree or hash table to be able to quickly determine whether a URL has been visited.
-
수억 개의 URL은 빠른 탐색 구조를 필요로 합니다. 때문에 속도가 중요합니다.
-
URL 리스트를 무작정 탐색하는 것은 절대 불가능합니다.
-
최소한 로봇이 탐색 트리나 해시 테이블을 사용하여 자신이 방문한 URL을 빠르게 파악할 수 있어야 합니다.
Hundreds of millions of URLs take up a lot of space, too. If the average URL is 40 characters long, and a web robot crawls 500 million URLs (just a small portion of the Web), a search data structure could require 20 GB or more of memory just to hold the URLs (40 bytes per URL × 500 million URLs = 20 GB)!
-
또한 수억 개의 URL은 많은 공간을 차지합니다.
-
만약 웹 로봇이 평균적으로 40글자 정도인 URL을 5억 개 크롤링한다면(5억 개도 웹의 아주 일부분일 뿐입니다), 탐색 자료구조는 URL을 저장하기 위해 20GB 이상의 메모리를 필요로 하게 됩니다.
Here are some useful techniques that large-scale web crawlers use to manage where they visit:
- 거대한 웹 크롤러가 방문 정보를 관리하기 위해 사용하는 몇 가지 유용한 기술들이 있습니다.
Trees and hash tables
Sophisticated robots might use a search tree or a hash table to keep track of visited URLs. These are software data structures that make URL lookup much faster.
트리 및 해시 테이블
- 정교한 로봇은 탐색 트리나 해시 테이블을 사용하여 방문한 URL을 추적합니다. 이는 URL 탐색을 훨씬 빠르게 하는 소프트웨어 자료구조입니다.
Lossy presence bit maps
To minimize space, some large-scale crawlers use lossy data structures such as presence bit arrays. Each URL is converted into a fixed size number by a hash function, and this number has an associated “presence bit” in an array. When a URL is crawled, the corresponding presence bit is set. If the presence bit is already set, the crawler assumes the URL has already been crawled.
Lossy Presence 비트맵
-
공간을 최소화하기 위해 거대한 크롤러는 Presence 비트 배열처럼 손실이 존재하는 자료구조를 사용합니다.
-
각 URL은 해시함수에 의해 고정된 사이즈의 숫자로 변환되는데, 이 숫자를 배열에 관한 "Presence Bit"라고 합니다.
-
URL이 크롤링되면 일치하는 Presence Bit가 설정됩니다.
-
만약 Presence Bit가 이미 설정되어 있다면, 크롤러는 URL이 이미 크롤링되었다고 가정합니다.
** Loss는 Hash Collision에 의한 것이라고 보면 됩니다. 서로 다른 URL이 같은 Presence Bit를 공유할 수 있어 일부 URL이 이미 크롤링된 것으로 잘못 판단될 여지가 있습니다.
Checkpoints
Be sure to save the list of visited URLs to disk, in case the robot program crashes.
체크포인트
- 로봇 프로그램이 충돌할 경우를 대비하여 방문 URL을 디스크에 저장하기를 권장합니다.
Partitioning
As the Web grows, it may become impractical to complete a crawl with a single robot on a single computer. That computer may not have enough memory, disk space, computing power, or network bandwidth to complete a crawl. Some large-scale web robots use “farms” of robots, each a separate computer, working in tandem. Each robot is assigned a particular “slice” of URLs, for which it is responsible. Together, the robots work to crawl the Web. The individual robots may need to communicate to pass URLs back and forth, to cover for malfunctioning peers, or to otherwise coordinate their efforts.
파티셔닝
-
웹이 성장함에 따라 한 개의 컴퓨터에서 한 개의 로봇이 완벽하게 크롤링을 수행하는 것이 불가능해졌습니다.
-
한 컴퓨터만으로는 크롤링을 완료할 만큼 충분한 메모리와 디스크 공간, 컴퓨팅 파워, 네트워크 대역폭을 확보하기 어렵습니다.
-
대규모 웹 로봇은 별도의 컴퓨터로 구성된 로봇 "팜"을 사용하여 함께 동작합니다.
-
각각의 로봇은 특정 URL의 "슬라이스"를 할당받습니다.
-
그리고 함께 웹을 크롤링합니다.
-
개별 로봇은 URL을 주고받거나 오작동하는 다른 컴퓨터를 커버하거나 조정하기 위해 통신할 필요가 있습니다.
A good reference book for implementing huge data structures is Managing Gigabytes: Compressing and Indexing Documents and Images, by Witten, et. al (Morgan Kaufmann). This book is full of tricks and techniques for managing large amounts of data.
-
(Witten, 외, Morgan Kaufmann 저)의 Managing Gigabytes: Compressing and Indexing Documents and Images는 대규모 자료구조 구현에 관한 좋은 참고자료입니다.
-
이 책은 방대한 양의 데이터를 처리하는 많은 요령과 기술로 가득차 있습니다.
✏️ 요약
Loops and Dups
- Loops : 로봇이 똑같은 페이지를 끊임없이 반복해서 불러오는 것
- Dups : 중복된 페이지
[1] Problems
- 크롤러가 네트워크 대역폭을 소진하면서 다른 페이지를 불러오지 못하고 중단될 수 있다
- 크롤러가 똑같은 페이지를 반복해서 불러오는 동안 웹 서버에 부하가 가해진다 (웹 서버 부하로 인한 서비스 방해는 법적 소송으로 이어질 수 있다)
- Dups로 인하여 응용 프로그램이 제대로 동작하지 모한다
[2] Tricks for Cycle Avoidance
: 로봇은 사이클을 회피하기 위해 자신의 위치를 알 수 있어야 한다
- Trees and Hashtables : URL 탐색을 빠르게 하는 자료구조
- Lossy Presence Bit Maps : 해시함수를 사용함으로써 약간의 손실이 발생하더라도 공간을 최소화하는 방식
- Partitioning : 여러 개의 컴퓨터가 서로 통신하며 URL을 주고받는 방식
✏️ 감상
왜 트리와 해시 테이블이어야 하는가
기차 타고 가는 길에 심심해서 알고리즘 문제를 풀다 보니 갑자기 자료구조에 대한 얘기를 쓰고 싶어져서 복습 겸 다시 정리해보려고 한다.
로봇이 자신이 방문한 URL을 추적하기 위해 트리와 해시테이블을 사용하는 이유는 상대적으로 탐색에 대한 시간복잡도가 낮기 때문이다. 로봇이 자신의 위치를 빠르게 파악하고 사용하려면 URL을 불러올 때 시간복잡도가 낮은 것이 유리하다. 수집이 조금 오래 걸리더라도 루프에 걸리는 것보다는 낫지 않겠는가(...)
비정렬 배열의 탐색 시간복잡도는 O(N)이다. 정렬을 하면 이진 탐색으로 O(logN)까지 당겨볼 수 있겠지만 정렬된 상태를 유지하는 것에도 비용이 든다. 대신 탐색 평균 시간 복잡도가 O(logN)인 BST를 고려해볼 수 있겠다. 그런데 이건 나의 개인적인 생각이지만..ㅎㅎ URL 관리에 있어 해시 테이블만큼 적합한 것이 없어 보인다. 약간의 손실이 발생하는 것을 허용한다면 O(1)에 가까운 복잡도에 값을 넣고 빼고가 가능하다. 어차피 모든 웹 페이지를 크롤링하는 것이 불가능하다면 손실을 감안하고 빠른 속도로 Loop 없이 수집하는 것이 더 현명한 선택이지 않을까?! 하는 생각이 들었다. 전문가가 아니라서 잘은 모르겠지만 나라면 그렇게 했을 것 같다.
