
Chapter 9. Web Robots
(해석 또는 이해가 잘못된 부분이 있다면 댓글로 편하게 알려주세요.)
✏️ 원문 번역
Aliases and Robot Cycles
Even with the right data structures, it is sometimes difficult to tell if you have visited a page before, because of URL “aliasing.” Two URLs are aliases if the URLs look different but really refer to the same resource.
- 적절한 자료구조를 사용하더라도 URL Aliasing으로 인해 이전에 페이지를 방문한 적이 있는지 확인하기 어렵습니다.
Table 9-1 illustrates a few simple ways that different URLs can point to the same resource.
- Table 9-1은 URL이 동일한 리소스를 가리키는 몇 가지 간단한 방식을 나타냅니다.
** Alias를 통해 표현한 URL과 원본 URL을 비교한 예시입니다.

Canonicalizing URLs
Most web robots try to eliminate the obvious aliases up front by “canonicalizing” URLs into a standard form. A robot might first convert every URL into a canonical form, by:
- Adding “:80” to the hostname, if the port isn’t specified
- Converting all %xx escaped characters into their character equivalents
- Removing # tags
-
대부분의 웹 로봇은 URL을 정해진 형태로 표준화하여 명백한 Alias를 제거하려고 시도합니다.
-
아마도 로봇은 모든 URL을 표준형으로 바꾸기 위해 가장 먼저 다음을 수행할 것입니다.
- 포트 번호가 명시되어 있지 않다면 호스트명에 :80을 붙입니다.
- 모든 %xx 탈출 문자를 대응하는 문자로 변환합니다.
- # 태그를 제거합니다.
These steps can eliminate the aliasing problems shown in Table 9-1a–c. But, without knowing information about the particular web server, the robot doesn’t have any good way of avoiding the duplicates from Table 9-1d–f:
-
이러한 과정은 Table 9-1의 a-c에 나타난 Aliasing 문제를 제거할 수 있습니다.
-
하지만 특정 웹 서버에 대한 정보가 없다면 로봇이 Table 9-1의 d-f에 해당하는 중복을 회피할 수 없습니다.
• The robot would need to know whether the web server was case-insensitive to avoid the alias in Table 9-1d.
- 로봇은 Table 9-1d에서 설명한 Alias를 회피하기 위해 웹 서버가 대소문자를 구분하는지 알아야 합니다.
• The robot would need to know the web server’s index-page configuration for this directory to know whether the URLs in Table 9-1e were aliases.
- 로봇은 Table 9-1e의 URL이 Alias인지 알기 위해 디렉토리에 대한 웹 서버의 인덱스 페이지 구성을 알아야 합니다.
• The robot would need to know if the web server was configured to do virtual hosting (covered in Chapter5) to know if the URLs in Table 9-1f were aliases, even if it knew the hostname and IP address referred to the same physical computer.
- 호스트명과 IP 주소가 동일한 물리적인 컴퓨터를 가리키고 있다는 것을알고 있더라도, 로봇은 Table 9-1f의 URL이 Alias인지 알기 위해 웹 서버가 가상 호스팅(Chapter 5에서 언급)을 수행하도록 구성되었는지 알아야 합니다.
URL canonicalization can eliminate the basic syntactic aliases, but robots will encounter other URL aliases that can’t be eliminated through converting URLs to standard forms.
-
URL 표준화를 통해 문법적인 Alias를 제거할 수 있습니다.
-
그러나 로봇은 URL을 표준형으로 변환하는 것만으로는 제거되지 않는 또다른 URL Alias를 마주하게 될 것입니다.
Filesystem Link Cycles
Symbolic links on a filesystem can cause a particularly insidious kind of cycle, because they can create an illusion of an infinitely deep directory hierarchy where none exists. Symbolic link cycles usually are the result of an unintentional error by the server administrator, but they also can be created by “evil web masters” as a malicious trap for robots.
-
파일 시스템의 Symbolic Link는 교묘한 종류의 사이클을 만들 수 있습니다.
-
존재하지 않는 무한히 깊은 디렉토리 계층이 있다고 착각을 불러일으킬 수 있기 때문입니다.
-
Symbolic Link 사이클은 보통 서버 관리자에 의한 의도치 않은 오류의 결과입니다.
-
하지만 이 사이클은 악의적인 웹 마스터가 로봇 트랩을 위해 생성한 것일 수 있습니다.
Figure9-3 shows two filesystems. In Figure9-3a, subdir is a normal directory. In Figure9-3b, subdir is a symbolic link pointing back to /. In both figures, assume the file /index.html contains a hyperlink to the file subdir/index.html.
-
Figure 9-3은 두 종류의 파일 시스템을 나타냅니다.
-
Figure 9-3a의 서브 디렉토리는 평범한 디렉토리입니다.
-
Figure 9-3b의 서브 디렉토리는 Root(/)로 돌아가도록 가리키는 Symbolic Link입니다.
-
두 가지 예시 모두 /index.html 파일이 subdir/index.html이라는 하이퍼링크를 포함하고 있다고 가정합니다.
Using Figure9-3a’s filesystem, a web crawler may take the following actions:
1. GET http://www.foo.com/index.html
Get /index.html, find link to subdir/index.html.2. GET http://www.foo.com/subdir/index.html
Get subdir/index.html, find link to subdir/logo.gif.3. GET http://www.foo.com/subdir/logo.gif
Get subdir/logo.gif, no more links, all done.
{kind=link}
- Figure 9-3a의 파일 시스템을 사용하여 웹 크롤러는 아래의 과정을 수행합니다.
- GET http://www.foo.com/index.html : /index.html을 불러와 subdir/index.html에 대한 링크를 찾습니다.
- GET http://www.foo.com/subdir/index.html : subdir/index.html을 불러와 subdir/logo.gif에 대한 링크를 찾습니다.
- GET http://www.foo.com/subdir/logo.gif : subdir/logo.gif를 불러오지만 더 이상 연결된 링크가 없으므로 모든 작업을 완료됩니다.
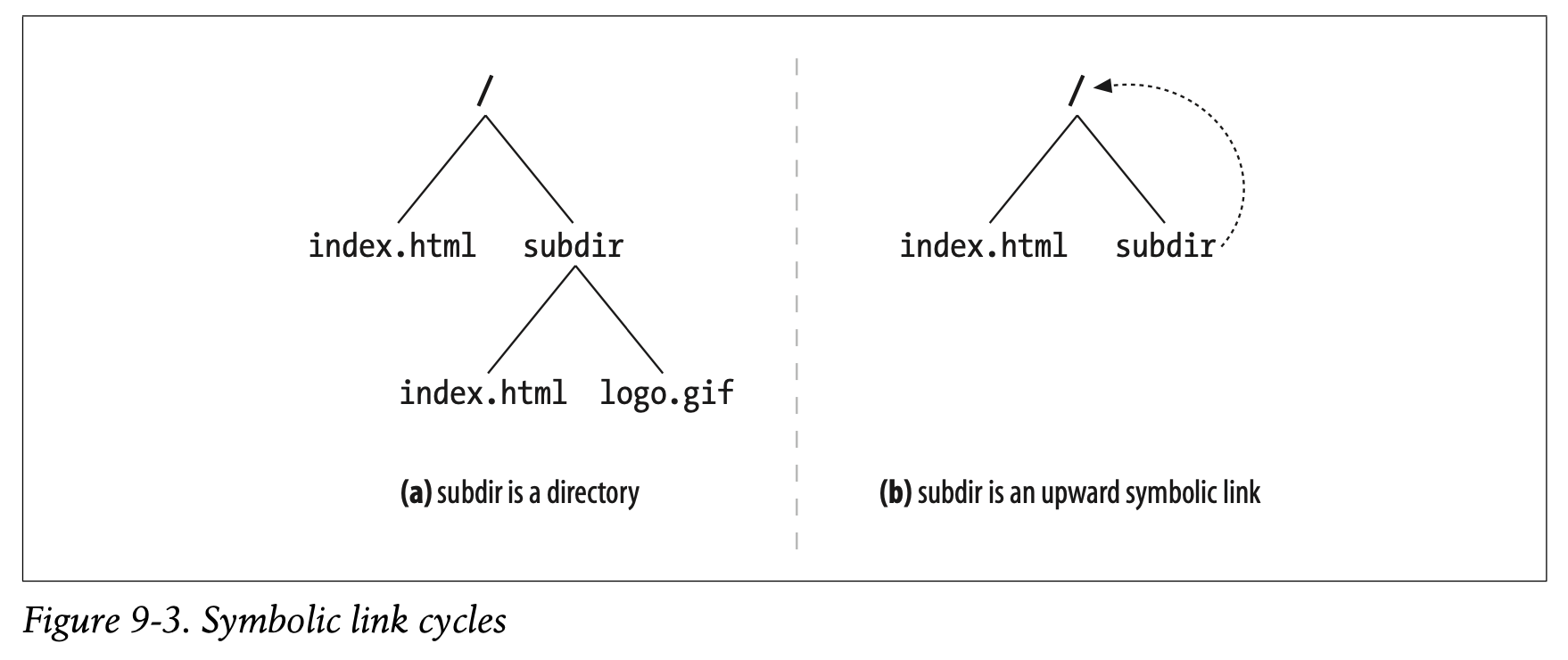
But in Figure 9-3b’s filesystem, the following might happen:
- GET http://www.foo.com/index.html
Get /index.html, find link to subdir/index.html.
- GET http://www.foo.com/subdir/index.html
Get subdir/index.html, but get back same index.html.
- GET http://www.foo.com/subdir/subdir/index.html
Get subdir/subdir/index.html.
- GET http://www.foo.com/subdir/subdir/subdir/index.html
Get subdir/subdir/subdir/index.html.
- 그러나 Figure 9-3b의 파일 시스템에서는 다음과 같은 일이 발생합니다.
- GET http://www.foo.com/index.html : /index.html을 불러와 subdir/index.html에 대한 링크를 찾습니다.
- GET http://www.foo.com/subdir/index.html : subdir/index.html을 불러오지만 동일한 index.html 페이지로 돌아갑니다.
- GET http://www.foo.com/subdir/subdir/index.html : subdir/subdir/index.html을 불러옵니다.
- GET http://www.foo.com/subdir/subdir/index.html : subdir/subdir/subdir/index.html을 불러옵니다.
The problem with Figure9-3b is that subdir/ is a cycle back to /, but because the URLs look different, the robot doesn’t know from the URL alone that the documents are identical. The unsuspecting robot runs the risk of getting into a loop. Without some kind of loop detection, this cycle will continue, often until the length of the URL exceeds the robot’s or the server’s limits.
-
Figure 9-3b에 나타난 문제는 subdir/이 /로 돌아가는 사이클이라는 점입니다.
-
하지만 URL이 다르기 때문에 로봇은 URL만으로 그 문서가 동일한 것인지 알 수 없습니다.
-
의심하지 않는 로봇은 루프에 빠질 위험이 있습니다.
-
별도의 루프 감지가 없다면 URL의 길이가 로봇이나 서버의 한계를 초과할 때까지 사이클이 계속될 것입니다.
✏️ 요약
URL Aliases and Robot Cycles
: URL Alias에 의한 로봇 사이클을 방지하는 방법
[1] Default Port Number
- Alias : 포트번호를 생략한 경우 디폴트 포트번호인 80번으로 간주
- Solution : 포트번호가 명시되어 있지 않다면 :80을 붙인다
[2] %xx Escaped Characters
- Alias : URL을 %xx 탈출 문자로 표기한 경우
- Solution : 모든 %xx 탈출 문자를 대응하는 문자로 변환한다
[3] Tags
http://www.foo.com/x.html#early
http://www.foo.com/x.html#middle
- Alias : # 태그가 존재하는 경우 (태그로는 페이지 변화 X)
- Solution : # 태그를 제거한다
[4] Case-insensitivity
http://www.foo.com/readme.html
http://www.foo.com/README.html
- Alias : URL이 대소문자를 구분하지 않는 경우
- Solution : 웹 서버가 URL의 대소문자를 구분하는지 확인한다
[5] Index-page Configuration
- Alias : index.html을 인덱스 페이지로 간주하여 생략
- Solution : 디렉토리에 대한 웹 서버의 인덱스 페이지 구성을 확인한 후 index.html이 Alias인지 확인한다
[6] Virtual Hosting
http://www.foo.com/index.html
http://209.231.87.45/index.html
- Alias : IP 주소를 호스트명으로 작성한 경우
- Solution : 웹 서버가 가상 호스팅을 수행하도록 구성되었는지 확인한다
Filesystem Link Cycles
: Symbolic Link를 통해 존재하지 않는 깊은 디렉토리 계층을 만드는 사이클
- 서버 관리자에 의한 의도치 않은 오류로 생성되기도 하지만, 악의적인 웹 마스터가 로봇 트랩을 위해 생성하는 경우가 있음
- 서브 디렉토리가 상위 디렉토리와 연결되는 경우 사이클 생성
- URL의 길이가 로봇이나 서버의 한계를 초과하지 않는 한 계속 반복
- 루프를 탐지하는 기법이 필요함
✏️ 감상
Virtual Hosting에 대해 알아보자
Virtual Hosting에 대해서는 Chapter 18에서 자세히 나온다. Chapter 5에서 언급했다고는 이야기하는데 음.. 되돌아가서 읽어봤지만 별로 도움이 안 됐다. 그래도 글을 읽다 짧게라도 언급이 되었으니 한 번 찾아보았다.
Virtual Hosting(가상 호스팅)은 여러 명의 고객이 하나의 컴퓨터를 공유하는 방식으로 제공되는 웹 호스팅 서비스를 의미한다. 고객의 관점에서는 각각의 웹사이트가 별도의 컴퓨터에서 제공되는 것처럼 보이지만 실제로는 동일한 물리적 컴퓨터(서버)에서 제공이 되고 있는 것이다.
Table 9-1f에서 Virtual Hosting 여부를 확인해야 한다고 한 까닭은 Virtual Hosting을 사용하는 경우 동일한 IP를 여러 개의 도메인이 공유하게 되기 때문이다. 호스트명을 IP 주소로 치환했을 때 이 IP 주소가 어떤 도메인을 가리키는지 구분할 수 없으므로 "호스트명 = IP 주소" 관계가 성립하지 않는다.
일반적으로 가상 호스트는 virtual_host.conf 파일을 별도로 만들어 정의하는 경우가 많다. 관리가 편하기 때문이다. <VitrualHost> 태그와 함께 서버의 이름, 별칭, 루트 파일, 로그 파일 등을 개발자가 원하는대로 구성할 수 있다. 이 설명은 Apache에 기준이므로 Nginx와는 조금 다를 수 있다.
Symbolic Link vs Hard Link
Symbolic Link와 Hard Link를 설명하기 위해서는 우선 리눅스의 파일 시스템에 대한 이해가 필요하다.
리눅스에는 i-node라는 FCB(File Control Block)가 있다. 파일과 디렉토리에 대한 메타데이터를 저장하는 블록이라고 생각하면 된다. 여기서 메타데이터라고 하면 파일이나 디렉토리의 이름, owner, 크기, 생성일시, 수정일시와 같은 정보를 말한다. 그 중 가장 중요한 메타데이터가 바로 디렉토리와 파일을 디스크 블록에 어떻게 할당할지에 대한 것이다. 구체적인 할당 방법은 차치하더라도 일단 i-node가 데이터 블록을 포인팅하고 있다는 점에 주목해보자.
우리는 종종 동일한 파일에 대해 "바로가기"를 생성하는 경우가 있다. 만약 이 바로가기 파일이 Hard Link로 생성되었다면, 새로운 파일의 i-node는 기존 파일의 i-node와 동일하며 각각의 데이터 블록에 대한 링크가 하나 증가하게 된다. 두 파일 중 하나를 삭제하면 데이터 블록에 대한 링크가 감소하기만 할 뿐 다른 Hard Link로 접근이 가능하다.
반면 Symbolic Link로 생성된 파일의 i-node는 기존 파일의 경로를 가지고 있다. 따라서 데이터 블록에는 새로운 링크가 형성되지 않으며, 기존 파일을 삭제하는 경우 Broken Link가 발생한다.
리눅스를 비롯하여 대부분의 파일 시스템에서는 디렉토리에 대한 Hard Link 생성을 금지하고 있다. 같은 디렉토리를 여러 곳에서 참조하도록 허용하는 경우 부모 디렉토리가 여러 개가 되는 사이클이 발생할 수 있다. 파일 시스템의 트리 구조가 깨질 위험이 있는 것이다. 하지만 Symbolic Link는 새로운 i-node가 단순히 원본 파일의 경로 문자열을 가지고 있는 것뿐이므로 트리 구조를 깨뜨릴 염려가 없다. 따라서 디렉토리에 대한 Symbolic Link는 막지 않고 있다.
즉 파일 시스템 자체에서는 Symbolic Link로 상위 디렉토리를 가리켜도 문제가 생기지 않는다. 하지만 URL은 /subdir을 단순히 문자열로 해석한다. root에 subdir가 있고 subdir가 root를 Symbolic Link하고 있다고 하면, /subdir/subdir/subdir... 순으로 경로가 계속해서 덧붙여지게 된다. 크롤러 입장에서는 아주 고통스러운 루프가 되는 것이다.
재미없어 병에 걸렸습니다
Chapter 9 들어온 이후로 갑자기 재미가 없어졌다. 의욕이 많이 떨어졌지만 그래도 틈틈이 읽어서 글을 ㅆ..써야겠지... 쓸게요 ㅠㅠ
