ticket reservation app 완성 및 시뮬레이션
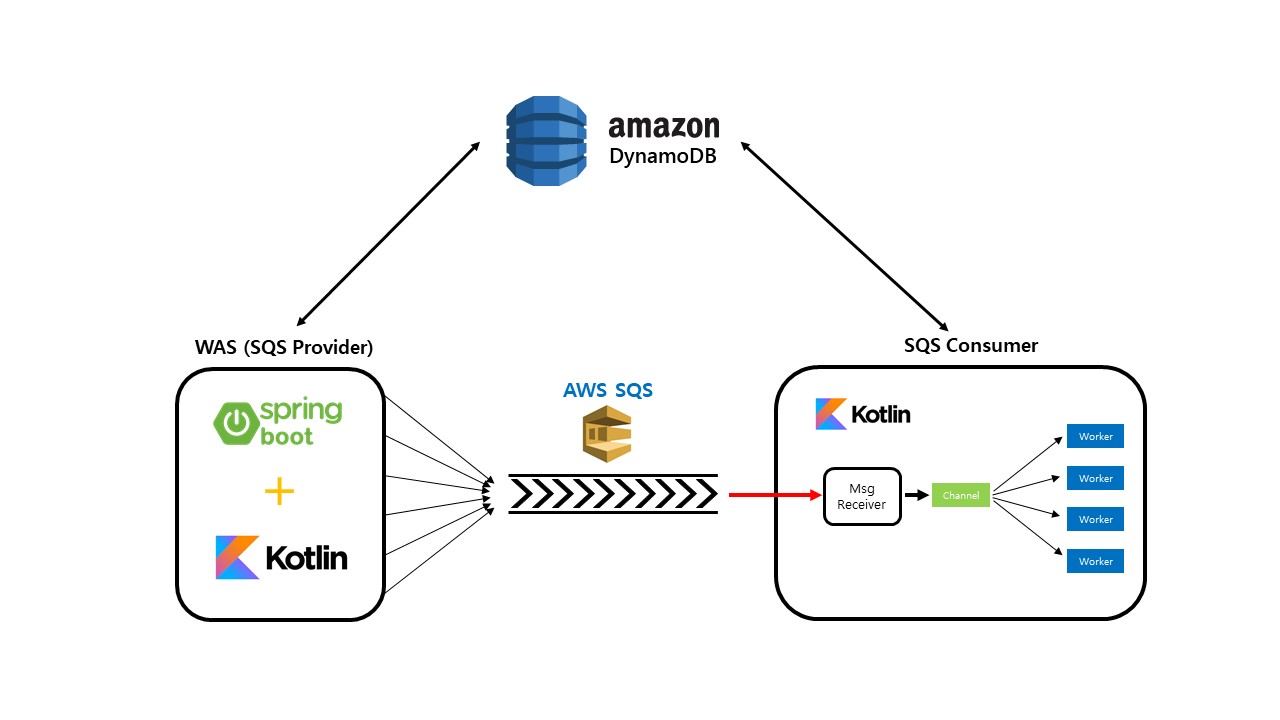
애플리케이션 구조
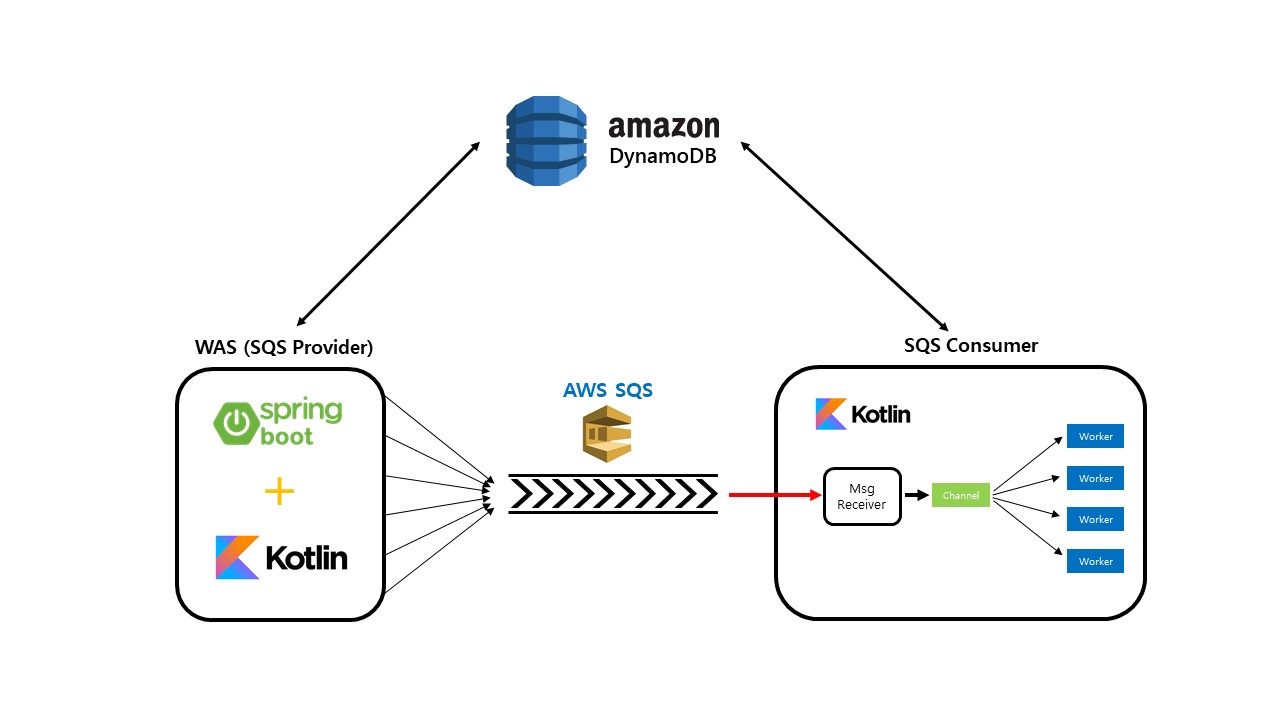
애플리케이션 작동 방식
이번 프로젝트의 목표는 순간적으로 몰리는 트래픽에 대응할 수 있는 서버를 구축하는 것이었기 때문에, 일반적인 웹 클라이언트는 만들지 않고 시뮬레이션을 위해 request 생성기(봇)을 만들었다.
이벤트 (event)
웹 클라이언트가 아닌 시뮬레이션용 클라이언트를 이용했기 때문에 로그인을 통한 인증이나 CORS policy 등 현실의 제약과 비슷한 상황을 재현하기 위해 이벤트라는 개념을 정의했다. 이벤트란 말 그대로 브라우저 상에서 사용자가 일으키는 사건들을 모사한 객체로, 아래와 같은 주요 이벤트를 설정했다.
login 이벤트
{
event_name: "login",
event_datetime: "2019:12:31 16:53:003",
event_common: {
event_id: "151489712313:1234-12123-asd13-134a"
},
event_dic: {
user_id: "ssh22"
}
}사용자가 티켓 예매 페이지에 로그인했음을 나타내는 이벤트이다.
page view 이벤트
{
event_name: "page_view",
event_datetime: "2019:12:31 16:51:003",
event_common: {
event_id: "151489712313:1234-12123-asd13-134a"
},
event_dic: {
user_id: "ssh22",
concert_id: 123
}
}page view 이벤트는 사용자가 특정 공연의 예매 페이지에 방문했는지를 표현하는 이벤트이다. 일반적인 웹 클라이언트/서버 간 통신에서 사용되는 CORS policy를 유사하게 구현한 이벤트라고 보면 된다. 다시 말해 WAS에서는 page_view 이벤트를 거치지 않고 들어온 예매 요청이라면 worker 단으로 넘기기 전에 필터링 하는 작업을 수행하도록 하였다.
ticket_reserve 이벤트
{
event_name: "reserve_ticket",
event_datetime: "2019:12:31 16:52:003",
event_common: {
event_id: "151489712313:1234-12123-asd13-134a"
},
event_dic: {
user_id: "ssh22",
concert_id: 123,
ticket_num: 1
}
}ticket_reserve 이벤트는 말 그대로 티켓 예매 이벤트이다. WAS는 ticket_reserve 이벤트를 제외한 다른 모든 이벤트는 자신이 처리하고, disk IO 작업이 많이 필요한 ticket_reserve 이벤트만을 worker에 넘겨 latency를 최소화한다.
이벤트 간 의존관계
적절한 예매 요청이란 무엇인가?에 대한 답을 각 이벤트가 서로 어떤 의존관계를 가지고 있는지로 정의할 수 있다. 한 사용자가 일으키는 일련의 이벤트들은 서로 같은 이벤트 id를 공유하도록 설정하고, 그 사용자가 예매 요청을 보내왔을 때 그 이전에 어떤 이벤트들을 거쳤는지 확인한다.
(로그아웃 이벤트 이후에 발생한 로그인 이벤트) -> (page view 이벤트) -> (ticket_reserve 이벤트)
의 순서로 이벤트가 발생했을 때 이 ticket_reserve 이벤트는 유효한 예매 요청이라고 취급하고 worker가 작업을 시도하도록 결정했다. 예를 들어, 아래 그림에서 위 두 예시는 유효한 예매 요청이고, 아래 한 개는 유효하지 않은 예매 요청이다.
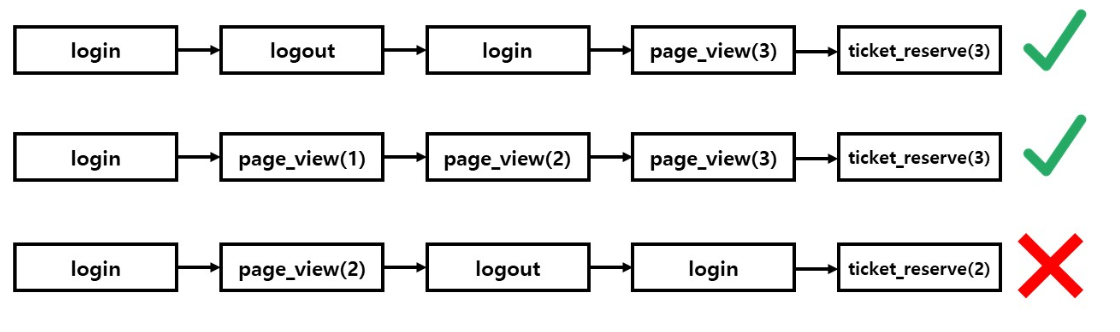
(** page_view와 ticket_reserve 이벤트에서 괄호 안의 숫자는 concert의 id를 의미)
DB 스키마 설계
1. user - 사용자 테이블
primary key
user_id (partition key)
attributes
name, gender, age 등 (협의 후 확정 필요)
2. concert - 공연 테이블
primary key
concert_id (partition key)
attributes
name, reservation_start_time(예약 가능 시작 시간), reservation_end_time(예약 가능 마감 시간)
3. event - 이벤트 테이블
primary key
event_id (partition key) + event_name (sort key)
attributes
login_datetime (event_name 이 LOGIN일 경우)
pageview_datetime, pageview_concert_id (event_name 이 PAGE_VIEW일 경우)
reservation_datetime (event_name 이 TICKET_RESERVE일 경우)
( 이벤트의 경우 한 사용자가 일으키는 일련의 이벤트가 모두 같은 id를 공유하기 때문에 event_id를 기준으로 partition을 구성할 수 있고, sort key를 event_name으로 설정함으로써 이 필드를 통한 search 작업이 용이하도록 했다.)
( 이 테이블의 데이터는 영구적으로 저장될 필요가 없으므로, TTL을 설정해 일정시간이 지나면 자동으로 지워지도록 설정해주었다.)
4. reservation - 공연 예약 내역 테이블
primary key
reservation_id (partition key)
attributes
user_id, concert_id, reservation_datetime
5. failed_reservation - 실패한 공연 예약 내역 테이블
4와 같음
기능
WAS (Web Application Server)
WAS는 클라이언트와 소통하는 api 서버로, 본 프로젝트는 시뮬레이션 프로젝트이기 때문에 restful API 원칙을 따르지 않고 /event라는 단일 엔드포인트를 사용했다. WAS의 주 기능은 아래와 같다.
1.유효하지 않은 요청 1차 필터링
백엔드 애플리케이션을 WAS와 worker로 분리하여 구성하면서 중요하게 생각했던 점은 각 레이어의 맡는 기능을 확실히 정하고 엄격하게 분리하자는 것이었다. 유효하지 않은 예매 요청을 반려시키는 것도 필터링 과정을 1차와 2차로 나누어 비교적 간단히 수행할 수 있는 1차 필터링을 WAS가 담당하도록 했다. 우리의 시뮬레이션에서 1차 필터링에 해당하는 내용은 다음과 같다.
- 사용자가 블랙 리스트에 포함된 사용자일 때 예매 요청을 반려
- 예매 요청이 들어온 시간이 해당 공연의 예매 기간이 아닐 때 예매 요청을 반려
- 한 번에 너무 많은 매수의 티켓을 예매하려고 할 때 예매 요청을 반려
2. 모든 이벤트를 dynamoDB에 저장
티켓 예매 요청이 들어왔을 때 뒷단 worker는 이벤트 간의 의존관계를 파악해 본 요청이 유효한 요청인지를 판단해야한다. 그러기 위해 WAS에서는 클라이언트로부터 들어오는 이벤트에 대한 내용을 DB에 저장해야한다.
3. 들어오는 이벤트가 ticket_reserve일 시, queue message를 생성하여 SQS에 전달
티켓 예매 요청이 들어왔을 때 1차 필터링을 통과했다면 이 요청을 그대로 queue message로 만들어 SQS에 공급한다.
Worker
worker는 기본적으로 '티켓 예매 요청'에 대한 처리만을 담당한다. 요청을 빠르게 처리해야 하므로 코루틴을 통해 멀티스레딩을 이용하고, mutual exclusion 기법으로 공유자원에 대한 동기화 문제를 처리한다.
1. 유효하지 않은 요청 2차 필터링
1차 필터링을 거쳐 넘어온 예매 요청이 정말로 유효한지 최종 검증한다. 구체적인 검증 방법은 위의 '이벤트간 의존 관계' 부분에서 설명한 것을 로직으로 구현하였다. 아래 과정을 모두 통과한 예매 요청은 유효한 요청으로 취급했다.
- 최후에 발생한 로그인 이벤트 이후에 로그아웃 이벤트가 없다.
- 최후에 발생한 로그인 이벤트 이후에 해당 공연에 대한 page_view 이벤트가 존재한다.
- 로그인 이벤트와 page_view 이벤트는 예매 요청 시각으로부터 10분 이내로 발생한 이벤트이다.
그리고 예매 가능한 최대 좌석 수를 1000개로 설정해 이 이상의 예매 요청은 모두 반려하도록 했다. 최대 좌석 수에 해당하는 변수는 여러 스레드가 동시에 접근 가능한 공유자원이므로 동기화 제어가 필요했다. 이전에 학습했던 mutex 라이브러리를 사용해 공유자원으로의 안전한 접근을 보장하였다.
2. 예매 내역을 db에 저장
위의 2차 필터링을 최종적으로 통과한 예매 요청은 정상적으로 db에 저장한다. 그리고 실패한 예매 요청 또한 사용자가 확인할 수 있어야 하기 때문에 failed_reservation 테이블을 두어 내역을 저장하도록 했다.
시뮬레이션
예약할 공연을 우선 무조건 1개로 고정하고, 클라이언트 봇 + WAS + worker를 함께 돌려 시뮬레이션해본 결과 아래와 같이 정확히 1000개의 예매 요청만 성공하는 것을 잘 확인할 수 있었다.

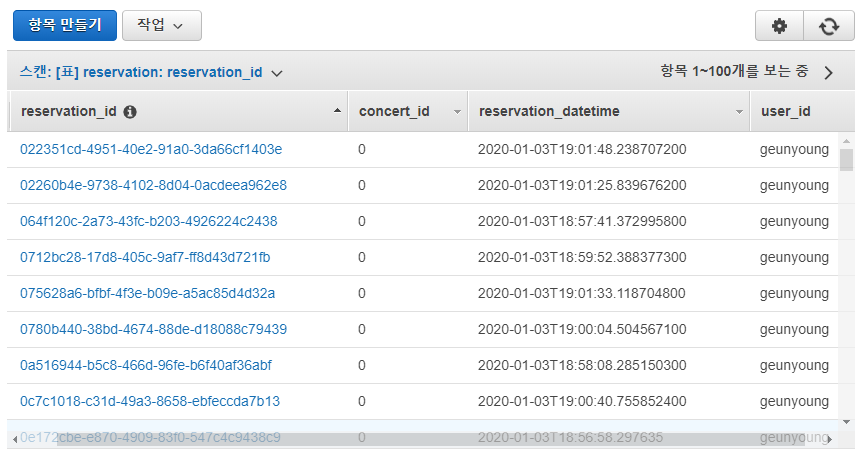
reservation_id 같은 경우 @DynamoDBAutoGenerated annotation을 이용해 random uuid를 할당받도록 하였다.
하지만...?
애플리케이션의 기능 자체는 정상적으로 작동하는 것을 확인했지만, 문제는 성능이었다. 약 1500개의 예매 요청을 처리하는 속도가 너무나도 느렸다... 성능이 안나오는 데에는 SQS 통신, 동기화 관리 등 여러 요소가 있겠지만 그 중에서도 dynamoDB에 의한 요인이 가장 주요해보였다.
DynamoDB의 WCU(Write Capacity Unit)
dynamoDB에는 RCU(Read Capacity Unit)과 WCU(Write Capacity Unit)라는 개념이 존재하는데, provisioned 방식으로 테이블을 생성할 경우 테이블에 RCU와 WCU를 몇개씩 할당할 지를 정해야 한다. 1WCU는 초당 1KB의 쓰기 작업을 감당할 수 있는데, 쓸 아이템의 크기가 1KB보다 작을 경우 무조건 올림하여 계산하기 때문에 우리 프로젝트에서는 성능이 고작 초당 아이템 20개 쓰는게 전부라는 거다.. 오토 스케일링을 통해 급증하는 트래픽에 어느정도 대응은 할 수 있겠지만, 애초에 본 프로젝트에서 설정한 상황은 트래픽이 특정 순간에 몰리는 상황이기 때문에 provisioned 방식은 어울리지 않고, on-demand 방식으로 테이블을 생성하는게 더 적절할 것 같다.
프로젝트를 통해 배운 점
- 멀티스레딩 서버 구축하기
- 서버 구조의 기능별 분리
- AWS SQS를 통한 MSA간 통신
- SQS + kotlin + coroutine을 이용한 멀티스레딩 SQS consumer 만들기
- AWS DynamoDB 개념 학습 및 적용
- kotlin에서 dynamoDB 조작하기
- mutual exclusion 기법을 이용한 동기화 제어

저 봇을 어떻게 구성했는지 궁금해요!
그냥 요청만 가게 한건가요?