도커/쿠버네티스를 활용한 컨테이너 개발 실전 입문 - 08. 컨테이너 운영

01. 로깅 운영
로깅 운영
도커와 같은 컨테이너 환경에서 로그 파일을 다루는 정석적인 방법은 컨테이너 내에서 애플리케이션이 발생시키는 표준출력들을 호스트에서 파일에다 수집하는 것이다.
보통 도커에서는 fluentd를 로그를 수집하는 로깅 드라이버로 많이 사용하고, 이는 elasticsearch와 함께 사용해 로그 수집 및 검색 기능을 구축할 수 있다.
fluentd와 elasticsearch를 이용한 로그 수집 및 검색 기능 구축
fluentd로 컨테이너에서 내뱉는 로그를 수집하고, elasticsearch에다 저장한 다음, kibana를 통해 시각화한다.
Elasticsearch와 Kibana 구축
docker-compose.yaml
version: "3"
services:
elasticsearch:
image: elasticsearch:5.6-alpine
ports:
- "9200:9200"
volumes:
- "./jvm.options:/usr/share/elasticsearch/config/jvm.options"
kibana:
image: kibana:5.6
ports:
- "5601:5601"
environment:
ELASTICSEARCH_URL: "http://elasticsearch:9200"
depends_on:
- elasticsearchelasticsearch 및 kibana는 docker hub의 표준 라이브러리에 있는 이미지를 사용하면 된다. 도커 컴포즈의 네임 레졸루션을 이용해 키바나에서 elasticsearch의 url을 추적할 수 있다.
이렇게 실행하면 해당 호스트의 5601번 포트에서 키바나 사이트가 뜨는 것을 확인할 수 있다.

fluentd 구축
fluentd의 설정 파일을 fluent.conf라는 이름으로 작성하고, 이를 COPY 인스트럭션으로 컨테이너 안에다 복사해 준다.
fluent.conf
<source>
@type forward
port 24224
bind 0.0.0.0
</source>
<match *.**>
@type copy
<store>
type elasticsearch
host elasticsearch
port 9200
logstash_format true
logstash_prefix docker
logstash_dateformat %Y%m%d
include_tag_key true
type_name app
tag_key @log_name
flush_interval 5s
</store>
<store>
type file
path /fluentd/log/docker_app
</store>
</match>Dockerfile
FROM fluent/fluentd:v0.12-debian
RUN gem install fluent-plugin-elasticsearch --no-rdoc --no-ri --version 1.9.2
COPY fluent.conf /fluentd/etc/fluent.conffluentd 로깅 드라이버로 컨테이너 로그 전송하기
fluentd 이미지도 빌드를 완료했으니, 이 이미지와 실행할 애플리케이션에 대한 내용을 docker-compose에 추가해준다.
docker-compose.yaml
version: "3"
services:
elasticsearch:
image: elasticsearch:5.6-alpine
ports:
- "9200:9200"
volumes:
- "./jvm.options:/usr/share/elasticsearch/config/jvm.options"
kibana:
image: kibana:5.6
ports:
- "5601:5601"
environment:
ELASTICSEARCH_URL: "http://elasticsearch:9200"
depends_on:
- elasticsearch
fluentd:
image: ch08/fluentd-elasticsearch:latest
ports:
- "24224:24224"
- "24220:24220"
depends_on:
- elasticsearch
echo:
image: gihyodocker/echo:latest
ports:
- "9000:8080" # 현재 8080번 포트가 사용중이어서 다른 포트에 바인딩함
logging:
driver: "fluentd"
options:
fluentd-address: "localhost:24224"
tag: "docker.{{.Name}}"
depends_on:
- fluentd도커 컴포즈를 통한 컨테이너 실행을 완료한 후, 몇 번 트래픽을 보내보고 키바나에 접속해보면 다음과 같이 로그를 확인할 수 있다.
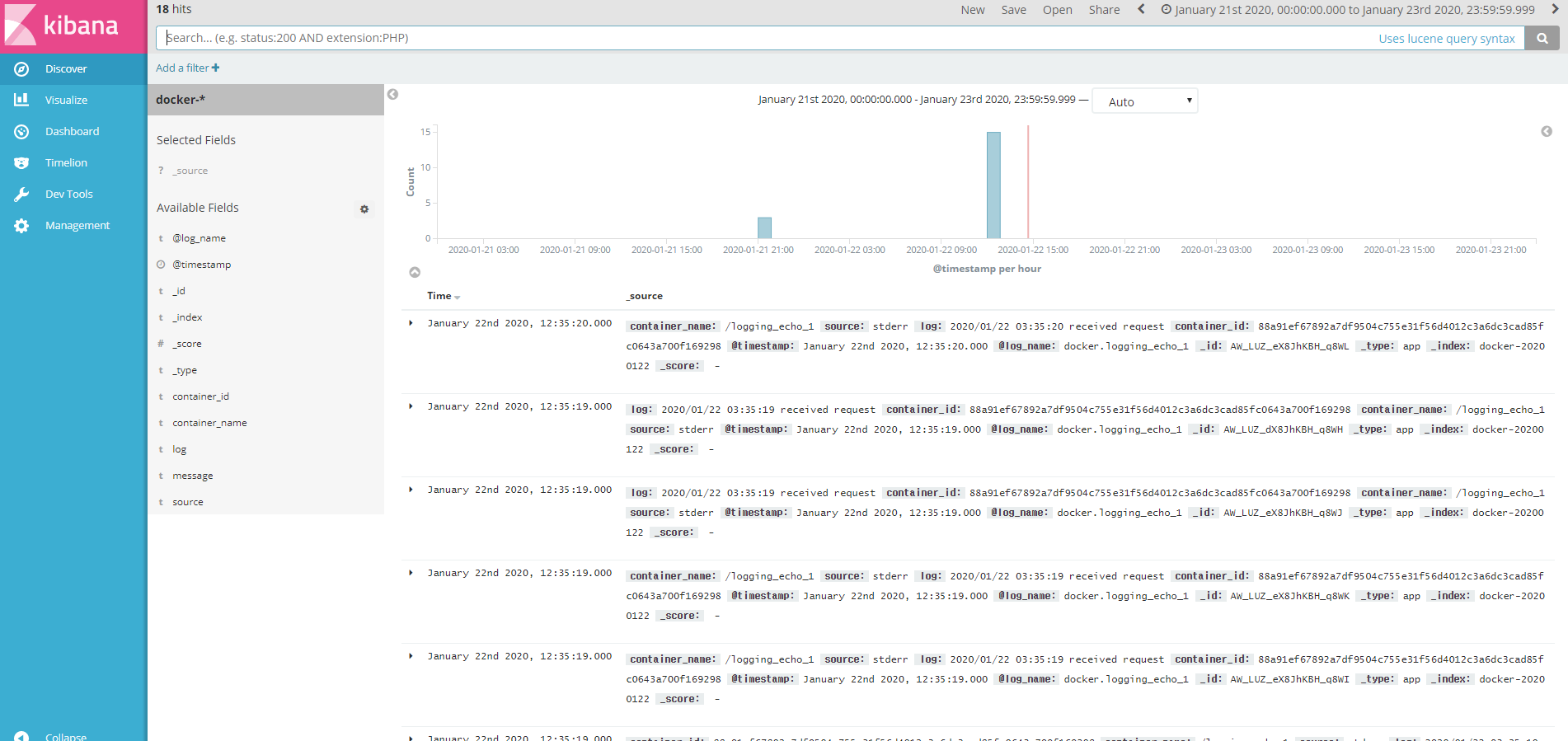
구글 스택드라이버를 통한 로깅 관리
스택드라이버는 GCP나 AWS에서 로깅 및 모니터링에 사용되는 매니지드 서비스이다. 이 스택드라이버를 통해 EKS나 GKE 등의 매니지드 환경에서는 개발자가 로깅에 대해 직접 관리할 필요가 없고, 애플리케이션 컨테이너에서 로그를 json 포맷으로 출력하기만 하면 스택드라이버로 로그를 열람할 수 있다.
06장에서 GKE로 만든 todolist에 대한 스택드라이버 페이지는 다음과 같다.
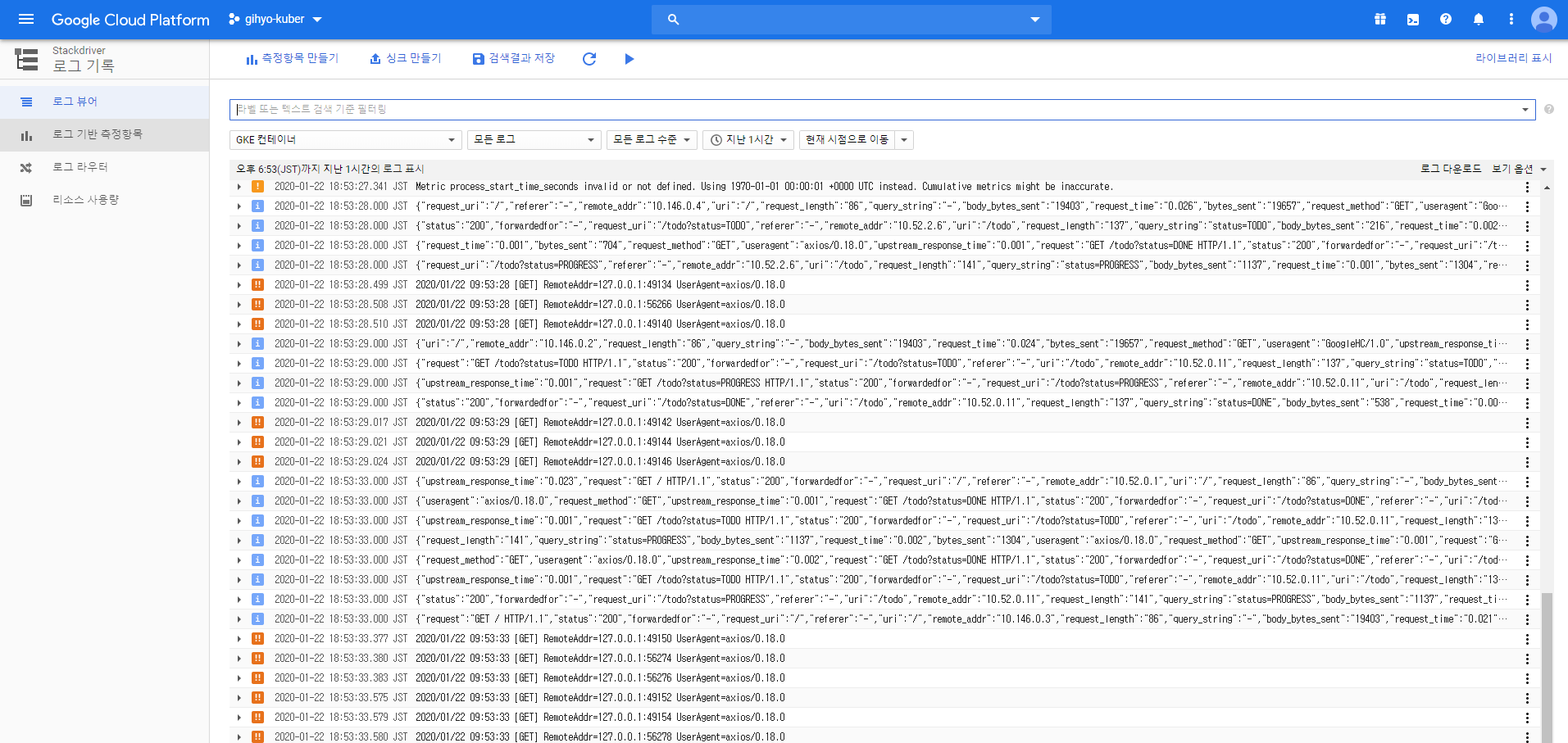
스택드라이버에서는 자동완성을 통한 편리한 검색 기능을 제공하며, 이 역시 내부적으로는 fluentd로 구성되어있다.
03. 장애 대책
도커 운영 시의 장애 대책
이미지 테스트
container-structure-test를 이용해 도커 이미지를 테스트할 수 있음.
예시)
test-tododb.yaml
schemaVersion: "2.0.0"
fileExistenceTests:
- name: "init-data.sh"
path: "/usr/local/bin/init-data.sh"
shouldExist: true
permissions: "-rwxr-xr-x"
fileContentTests:
- name: "mysqld.conf"
path: "/etc/mysql/mysql.conf.d/mysqld.conf"
expectedContents: ['log-bin=\/var\/log\/mysql\/.*\.log']fileExistenceTests는 해당 파일의 존재 여부를, fileContentTests는 파일의 내용을 확인하는 테스트이다. 이 테스트를 통해 이미지 구성이 잘못되어 발생하는 오류는
상당부분 억제할 수 있다.
디스크 용량 부족에 주의할 것
docker system prune -a 명령어를 이용해 사용하지 않는 이미지나 컨테이너를 일괄 삭제할 수 있다. 야간에 이 명령을 자동으로 수행하게끔 cron 설정으로 스케줄링하면 편하다.
쿠버네티스 운영 시의 장애 대책
노드가 장애를 일으켰을 때 쿠버네티스는?
노드가 장애를 일으켰을 때 쿠버네티스는 그 노드에서 실행되고 있는 파드를 즉시 종료하고, 정상적으로 작동하는 노드에 파드를 다시 배치한다. 이러한 기능을 autohealing이라고 하는데,ㅡ
레플리카 수를 정의해 파드의 개수를 관리하는 디플로이먼트/스테이트풀세트/데몬세트 등의 리소스는 오토힐링 기능을 제공하므로, 이 리소스들을 단위로 배포하는 것이 권장되는 사항이다.
파드 안티 어피니티
오토힐링 기능이 있다고 하더라도, 같은 파드가 모두 하나의 노드에 배치되어 있다면 오토힐링 과정에서 다운타임이 발생하기 때문에 같은 파드는 최대한 겹치지 않게 분산 배치하는 것이
효율적이다. 파드 간의 상성을 고려해 파드 배치 전략을 규칙으로 정의할 수 있도록 하는 것이 pod antiaffinity이다. 디플로이먼트 정의 파일의 예시를 살펴보자.
# 중간중간 중요하지 않은 부분은 생략하였음.
apiVersion: apps/v1
kind: Deployment
spec:
template:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- echo
topologyKey: "kubernetes.io/hostname"labelSelector는 'app=echo인 파드'라는 조건을 나타내며, topologyKey는 이 조건을 적용할 대상, kubernetes,io/hostname은 노드가 가져야할 레이블을 의미한다.
이 내용을 합치면 '레이블이 app=echo인 파드가 배포된 노드'가 되는데, 그러므로 이 정의 파일은 같은 파드를 한 노드에 배치하지 말라는 파드 배치 규칙을 가진
정의 파일이 된다.
위와 같은 파드 배치 규칙으로 인해 파드를 어떤 노드에도 배치할 수 없는 경우 그 파드는 pending 상태로 남아있게 된다. 클러스터에 새 노드가 추가되면 그 순간에 배치될 것이다.
CPU 부하가 큰 파드를 노드 어피니티로 격리하기
CPU 자원을 많이 사용하는 파드의 경우, 같은 노드에 배치된 다른 파드의 성능을 떨어뜨리므로 전용 노드를 두어 다른 파드에 대한 영향을 차단해야 한다.
이를 위해서는 노드에 레이블을 부여하고, 파드 배치 규칙을 적절히 정의해주면 된다. kubectl을 통해 원하는 노드에 특정 라벨을 붙여줄 수 있다.
$ kubectl label nodes <node-name> <label-key>=<label-value>그리고 매니페스트 정의 파일에서 spec.affinity.nodeAffinity 속성 값을 적절히 정의하면 된다.
apiVersion: apps/v1
kind: Deployment
spec:
template:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: instancegroup
operator: In
values:
- "batch"위와같이 정의하면 instancegroup=batch 라벨이 부여된 노드에만 해당 파드가 배치된다.
HPA를 이용한 오토스케일링
HPA(horizontal pod autoscaler)는 시스템 리소스 사용률에 따라 파드 수를 자동으로 조정하는 쿠버네티스 리소스다. HPA는 파드의 오토 스케일링 조건을
디플로이먼트나 레플리카세트에 부여할 수 있다.
예시)
apiVersion: autoscaling:v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: echo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: echo
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 40위 예시는 노드에 대한 파드의 CPU 사용률이 40퍼센트가 넘었을 때 파드 오토스케일링을 통해 파드의 레플리카 수를 늘리도록 하는 HPA 설정 파일이다.
scaleTargetRef 부분에서 오토 스케일링 조건을 부여할 대상 리소스를 결정할 수 있다.
Cluster Autoscaler를 이용한 노드 오토 스케일링
위 HPA를 통해 파드의 오토 스케일링이 가능해졌다고 해도 파드를 배치할 노드 리소스가 충분하지 못하면 말짱 꽝이다. 그렇기 때문에 cluster autoscaler를 통한
노드 오토 스케일링이 필요하다. cluster autoscaler는 GCP, AWS, Azure등의 플랫폼을 지원하고, GKE에서는 매니지드 서비스로 제공되므로 gcloud 명령만으로
cluster autoscaler가 적용된 클러스터를 만들 수 있다. (GKE 이외의 플랫폼에서는 cluster autoscaler를 별도 설치해야 한다.)
예시)
$ gcluod container clusters create example --cluster-version=1.9.7-gke.1 \
--machine-type=n1-standard-1 \
--num-nodes=5 \
--enable-autoscaling \
--min-nodes 3 \
--max-nodes 10HPA와 cluster autoscaler는 함께 사용할 때 그 효과가 극대화되므로, 배포 환경에서 유용하게 쓰일 것 같다.
