본 글에서 사용한 코드는 모두 Google Colab에서 실행함
빅데이터 분석기사 실기 교재를 참고한 코드이며 실습 파일 또한 교재에 포함되어있음을 밝힘
(1) 데이터 불러오기
✍ 입력
import pandas as pd
import numpy as np
#데이터 로드
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
data=pd.read_csv('breast-cancer-wisconsin.csv', encoding='utf-8')
data.head()💻 출력

Class : target 변수, 0과 1로 이진 분리된 범주형 변수
10개의 feature 존재
(2) 변수 확인
✍ 입력
data.hist(figsize=(20,10))💻 출력

(3) X,y 변수 지정
✍ 입력
y = data[["Class"]]
X = data[data.columns[1:10]]
#행열 확인
print(X.shape,y.shape)💻 출력
(683, 9) (683, 1)- 데이터 프레임에서 독립변수와 종속변수를 추출
X : code와 class 제외한 column
y : target 변수 class - 683개의 데이터, feature 9개
(4) 훈련,테스트 데이터 분리
✍ 입력
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(X, y, stratify=y, random_state=42)
#학습 데이터와 테스트데이터 진단 여부(0,1) 비율 유사한지 확인
print(y_train.mean())
print(y_test.mean())💻 출력
Class 0.349609 dtype: float64 Class 0.350877 dtype: float64
평균 확인해보니 약 35% 수준으로 비슷함
(5) 정규화
✍ 입력
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
scaler.fit(X_train)
X_scaled_train=scaler.transform(X_train)
X_scaled_test=scaler.transform(X_test)(6) 모델 적용
✍ 입력
from sklearn.ensemble import RandomForestClassifier
rf=RandomForestClassifier()
rf.fit(X_scaled_train, y_train)
pred_train=rf.predict(X_scaled_train)
rf.score(X_scaled_train, y_train)💻 출력
1- 랜덤 포레스트 모델에 훈련 데이터셋을 학습시켜 y_train 데이터셋으로 예측값을 내 정확도를 확인하니 1.0 이라는 결과가 나왔다.
✍ 입력
#오차 행렬
from sklearn.metrics import confusion_matrix
confusion_train=confusion_matrix(y_train, pred_train)
print("훈련데이터 오차행렬:\n", confusion_train)💻 출력
훈련데이터 오차행렬:
[[333 0]
[ 0 179]] 훈련 데이터셋에 대한 오차행렬 또한 모두 맞춘 결과를 내보였다.
따라서 모델로 훈련이 잘 됐다는 것을 확인 할 수 있다.
(7) 예측 결과
훈련 데이터로 모델이 잘 학습되었다는 것을 확인했으니 이제 테스트 데이터로 예측 결과를 살펴보자.
✍ 입력
#테스트데이터 예측 결과
pred_test=rf.predict(X_scaled_test)
rf.score(X_scaled_test, y_test)
#테스트데이터의 오차행렬
confusion_test=confusion_matrix(y_test, pred_test)
print("테스트데이터 오차행렬:\n", confusion_test)
#테스트데이터의 분류 예측 레포트
from sklearn.metrics import classification_report
cfreport_test=classification_report(y_test, pred_test)
print("분류예측 레포트:\n", cfreport_test)💻 출력
0.9649122807017544- 예측 결과 96.5%의 정확도
테스트데이터 오차행렬:
[[106 5]
[ 1 59]]- 정상 5명 중 1명이 오분류 되는 결과를 반환
분류예측 레포트:
precision recall f1-score support
0 0.99 0.95 0.97 111
1 0.92 0.98 0.95 60
accuracy 0.96 171
macro avg 0.96 0.97 0.96 171
weighted avg 0.97 0.96 0.97 171- 랜덤 포레스트 모델은 96%의 정확도를 보여준다.
- 정밀도 (Precision) : 모델이 양성이라고 분류한 것 중 실제로 양성인 것은 92%
- 재현율 (Recall) : 실제 양성인 것 중에서 모델이 양성이라고 예측한 것은 98%로, 정밀도보다 높다.
- F1 Score : 0.95, 0.97로 분류기 성능이 좋다고 할 수 있다.
✅ F1-score

정밀도와 재현율의 조화 평균으로, 정밀도와 재현율이 비슷할수록 F1-score도 높아진다.
0~1 사이의 값을 가지머 f1 score가 높을수록 성능이 좋다고 말할 수 있다. 이 때, f1-score는 %로 나타내지 않는다.
✅ Precision - Recall Trade off
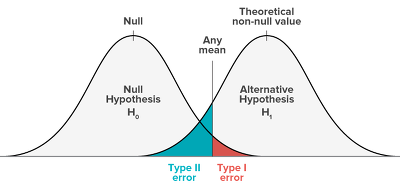
Any mean을 좌우로 조정하면 Type 1,2 error의 크기는 변화한다. 하지만 둘 다 커지거나 둘 다 작아지는 경우는 없다.
따라서 정밀도와 재현율 모두 높은 것은 불가능한 Trade-off 관계이다.
✅ 랜덤 포레스트가 의사 결정 나무보다 좋은 모델인가?
일반적으로 랜덤 포레스트가 의사결정나무보다 성능이 뛰어난 모델이다.
같은 데이터셋으로 의사결정나무 모델을 적용했을 때, 약 93.5%의 결과를 내보였으며 96%의 정확도를 내놓은 랜덤 포레스트보다 정확도가 떨어진 걸 확인했다.
