학습 내용 요약
- 머신러닝이란
- 선형 회귀
- 머신러닝 실습
1. 머신러닝이란
1) 정의
인공지능(AI)의 한 분야로 인간이 학습을 통해 정확도를 점진적으로 개선하는 방식을 모방하기 위한 데이터와 알고리즘의 사용에 초점을 맞춘다. 인간이 직접 하기 힘든 복잡한 계산 및 연산을 기계에게 데이터와 알고리즘을 학습시키고 풀도록 하는 것이 머신러닝이다.
2) 문제 푸는 방법
머신러닝을 통해 문제를 푸는 방법은 크게 두 가지로 나뉜다. 회귀, 분류인데, 두 가지 다 사용할 수 있는 문제도 있다. 좀 더 자세히 살펴보자.
(1) 회귀
지도학습 방법의 하나로 예측하고자 하는 결과값(출력값, 종속변수)이 연속적인 수치값(ex. 소수점, 정수 등)일 때 사용하는 방법
(2) 분류
지도학습 방법의 또다른 하나로 예측하고자 하는 결과가 특정 이름이나 문자, 판별에 쓰이는 숫자일 경우 사용하는 방법이다. 분류는 다시 두 가지로 나눌 수 있는데, 두 개로 나누는 이진 분류, 둘 이상으로 구분하는 다중 분류이다.
(3) 회귀, 분류 모두 가능
예를 들어 나이대를 범주로 나눠 특정 숫자로 나타낼 경우 나이를 예측하는 문제는 회귀와 분류 모두 사용할 수 있다.
(4) 양적/범주형 데이터
위에서 회귀와 분류로 문제 푸는 방법을 나눴는데, 그 과정에서 종속변수라는 말을 봤다. 예측하고자 하는 종속변수가 양적 데이터 즉, 대소비교가 가능하고 연속적인 수치의 데이터라면 회귀를 사용한다. 만약, 종속변수가 구분할 수 있는 이름이나 라벨용 수치인 범주형 데이터라면 분류를 사용한다.
2) 학습 방법
머신러닝이 학습하는 방법에는 크게 세 가지가 있다. 지도학습, 비지도학습, 강화학습이다. 각각에 대해 살펴보자.
(1) 지도학습
입력할 데이터와 정답인 결과값을 같이 알려주면서 학습시키는 방법. 그 종류로는 회귀와 분류가 있다.
(2) 비지도학습
결과값 없이 입력 데이터만 주고 학습시키는 방법으로 데이터는 많고 정답값은 없을 때 유용한 방법. 종류로는 군집화, 시각화와 차원 축소, 연관 규칙 학습이 있다.
(3) 강화학습
주어진 데이터 없이 실행과 오류를 반복하면서 학습시키는 방법. 특정 행동에 대한 보상을 받으면서 학습하는 방식이다. 알파고가 학습한 방법이 바로 강화학습이다.
각각의 학습 방법에 대한 세부사항은 다음에 좀 더 자세히 알아보자.
2. 선형 회귀
1) 정의
핵심만 말하자면, 모든 문제를 선형으로 풀 수 있다고 가정하는 것이다. 특정 데이터를 그래프로 나타낼 때, 그래프 상의 점들을 임의의 직선으로 그래프와 비슷하게 표현할 수 있다는 가설을 세운다. 이 임의의 직선(가설)이 선형 모델이고 수식은 다음과 같다.
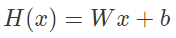
그래프 상의 원래 값들을 정확하게 예측하기 위해 임의의 직선과 그 값들의 거리를 좁혀야 하는데, 이를 구하기 위한 수식을 손실함수(비용함수)라 하고, 수식은 아래와 같다.
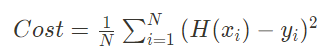
이 값이 최소가 되어야 모델 학습을 잘 시켰다고 할 수 있다.
2) 다중 선형 회귀
선형 회귀와 같은데, 입력 변수(값)가 둘 이상인 경우에 사용하는 방식이다. 이를 나타내는 가설과 손실함수의 수식은 다음과 같다.
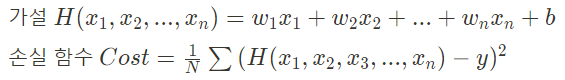
3) 손실함수 최적화
목표는 손실함수를 최소화 하는 것이다. 그런데 그 방법은 다양하다. 오늘은 그중에서 경사하강법(SGD)에 대해 살펴보자.
예를 들어, 손실함수가 이차 함수 그래프의 형태라고 가정하면,
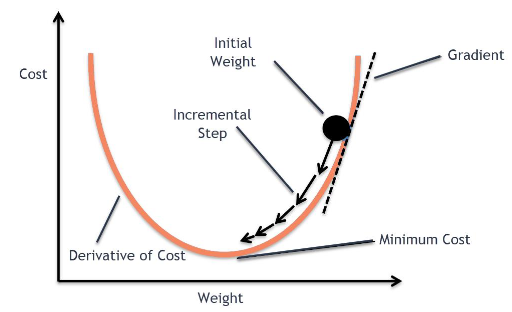
그래프를 따라 내려가면서 minimum cost인 지점을 찾아야 하는 것이다. 여기서 gradient가 점점 내려가면서 그 지점을 찾는데, 이 방법을 경사하강법이라고 한다.
이때, 움직이는 단위를 learning rate라 하는데 적당한 값을 설정하는 것이 관건이다. 만약, 너무 크면 최소 지점을 못찾고 그 부근을 왔다갔다 하고 최악의 경우 무한대로 발산(overshooting)해버린다. 반대로 너무 작으면 시간이 오래걸려 비효율적이다.
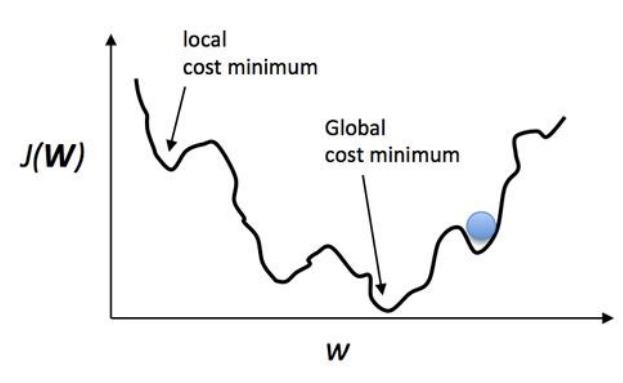
위 그림처럼 현실의 문제는 매우 복잡해서 2차 함수가 아니라 다차 함수 그래프 형태일 것이다. 여기서 목표는 global cost minimum을 찾는 것인데, 조심해야 할 부분이 local cost minimum에 빠져서 탐색을 종료하지 않는 것이다.
3. 머신러닝 실습
1) 데이터셋
모델을 학습시킬 때 필요한 데이터는 크게 세 개로 분류한다.
(1) 학습 데이터셋
Traing dataset이라고 하는데, 보통 전체 데이터셋의 80% 정도를 할당한다. 머신러닝 모델을 학습시킬 때 입력하는 데이터셋이다.
(2) 검증 데이터셋
Validation dataset이라고 하고, 전체 데이터의 20%를 차지한다. 모델의 성능을 검증하고 최적화 기법이나 손실함수 등을 바꾸면서 검증한다. 이 데이터셋은 모델에게 데이터를 직접 보여주지 않고 평가 용도로만 사용해서 모델의 성능에 직접적으로 영향을 미치지 않도록 한다.
(3) 테스트 데이터셋
Test dataset이고 학습한 모델의 최종 평가를 위해 사용된다. 실제 환경에서의 데이터셋을 제공해서 제대로 작동하는지를 보는 것이다.
(4) 데이터셋 비율
보통 학습에 80%, 검증에 20%를 할당하지만, 나누는 과정에서 중요하게 고려할 조건이 다음과 같은 두 가지가 있다.
- 보유한 데이터 전체 샘플 수
- 훈련을 하는 실제 모델에 사용되는 샘플 수
다양하게 변형해서 실험해보고 결정해야 최적의 비율을 찾을 것이다.
2) 선형 회귀 실습
keras를 이용해서 간단하게 선형 회귀 모델을 만들어 볼 수 있다.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD넘파이, 순차 모델(sequential), 덴스(dense) 레이어, 최적화 기법(adam,sgd)를 불러온다.
x_data = np.array([[1], [2], [3]])
y_data = np.array([[10], [20], [30]])입력값과 출력값을 만든다.
model = Sequential([
Dense(1)
])덴스 레이어를 가진 순차 모델을 만들고 정의한다.
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1))
model.fit(x_data, y_data, epochs=100)손실함수와 최적화 기법을 요소로 모델을 구성하고, 데이터를 모델에 학습시킨다. 이때 epochs는 학습하는 횟수로 항상 복수형으로 적는다.
y_pred = model.predict([[4]])
print(y_pred)모델의 예측값을 출력한다.
앞으로 더 공부해서 구체적인 요소들과 상세한 내용은 차근차근 정리해 보자.
어렵거나 완전히 이해 못한 내용
아직 머신러닝에 관한 용어들이 생소하고, 모델을 만들고 학습시키는 과정이 완전히 이해가 되진 않았다. 단지 흐름이 어떻게 흘러가는지만 알 뿐이다. 손실함수에는 어떤 것들이 있는지, 최적화 기법에는 뭐가 있는지, 적절한 학습 횟수는 무엇일지 많은 것들이 궁금하고 어렵다. 급하지 않게 천천히 알아보고 잘 정리해 보자.
