이번 포스팅에서는 이전 포스팅의 내용을 이어서 최적의 를 찾는 Optimization에 대해 소개해보겠다. 비유를 통해 설명해보겠다. 아래처럼 산과 계곡을 걸어 내려가본다고 생각해보자.

여기서 산과 계곡이 이며, 인간이 있는 높이는 Loss이다. Loss는 에 따라 변하며, 우리는 최적의 를 찾아야한다. 우리의 임무는 골짜기의 밑바닥을 찾는 것이다.
전략 1 : Random Search
이 방법은 좋지 않은 해결책이다.
전략 2 : Follow the slope
전략 1보다 나은 전략은 기하학적 특성을 이용하는 것이다.(local geometry)
이 방법은 우리가 NN이나 Linear Classifier같은 것들을 훈련시킬 때 일반적으로 사용하는 방법이다. 여기서 slope은 어떤 함수에 대한 미분값이다.
1차원, 미분
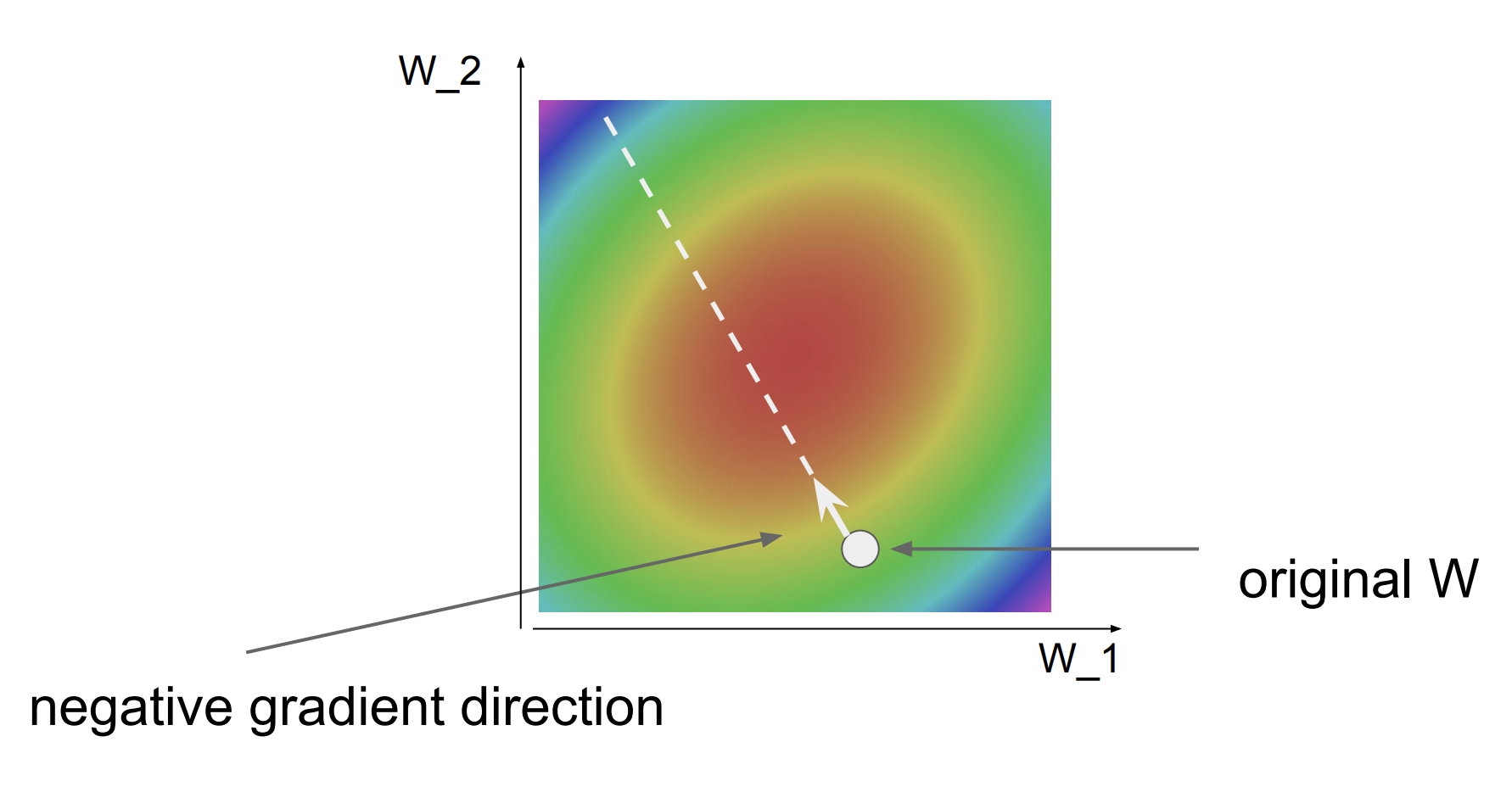
빨간 곳은 low loss이며, 초록과 파란색은 higher loss이며, 초록과 파란색이 우리가 피하고 싶어하는 부분이다.
Stochastic Gradient Descent (SGD)
매번 N개의 데이터를 전부 미분하는 것은 자원이 많이 낭비된다. 그래서 근사치만 연산하기 위해 minibatch 개념을 이용한다.
연관링크1
연관링크2
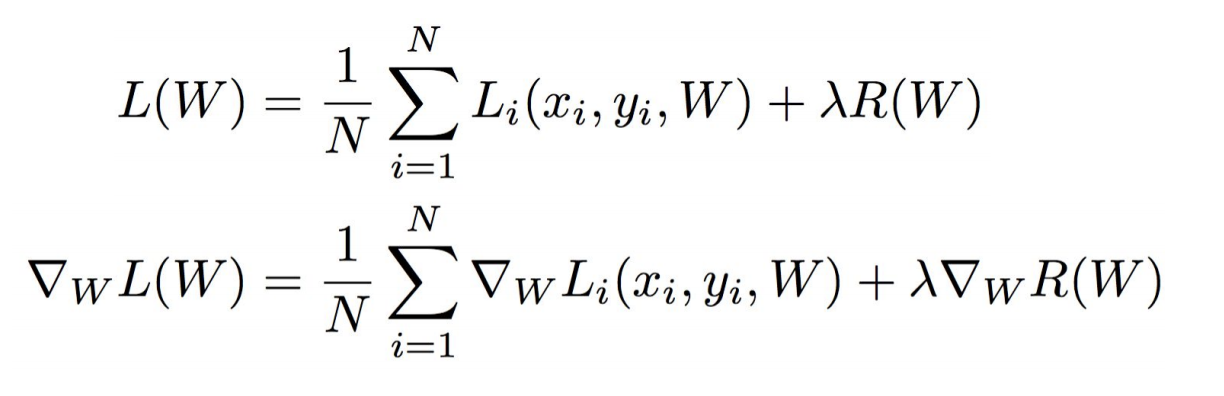

특징 변환
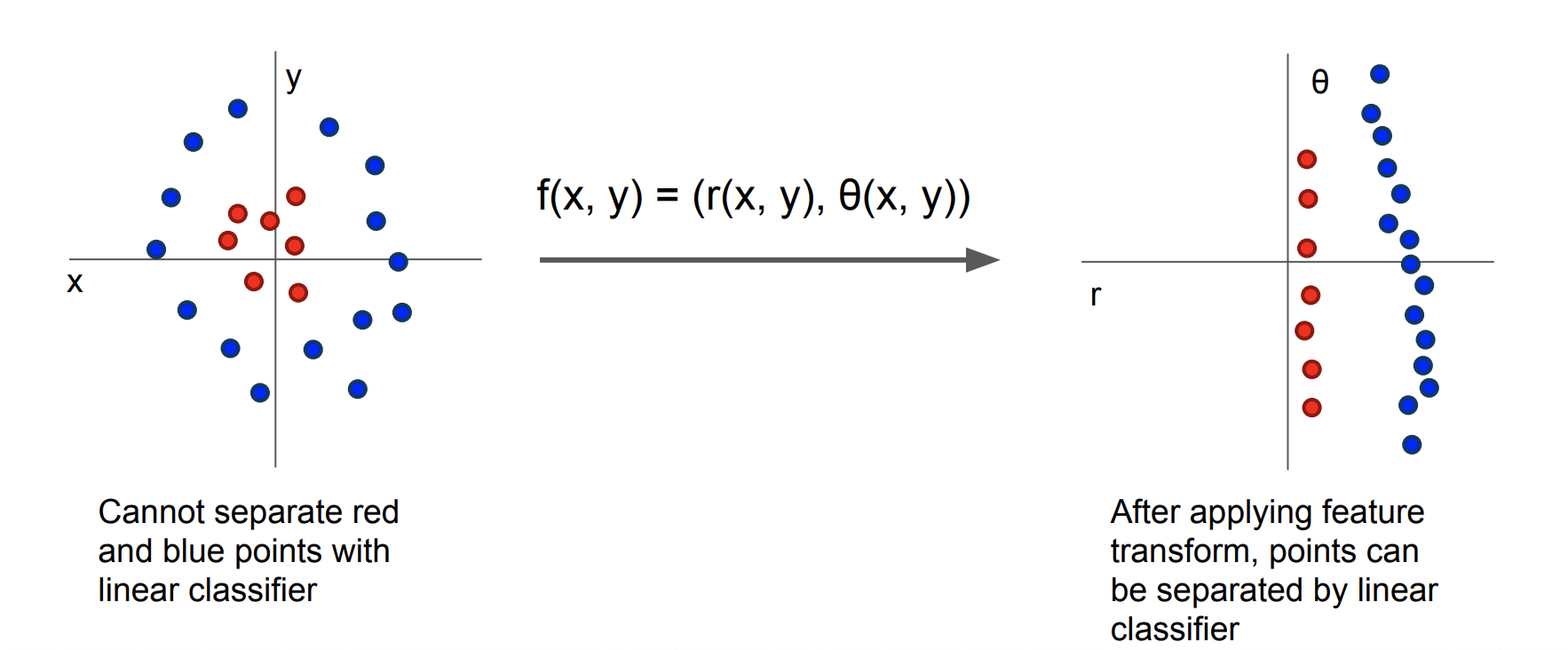
위 그림과 같이 똑! 떨어지게 분류할 수 없는 왼쪽 경우를 오른쪽과 같이 분류 가능한 상황으로 만들려면 어떤 변환이 필요할까?
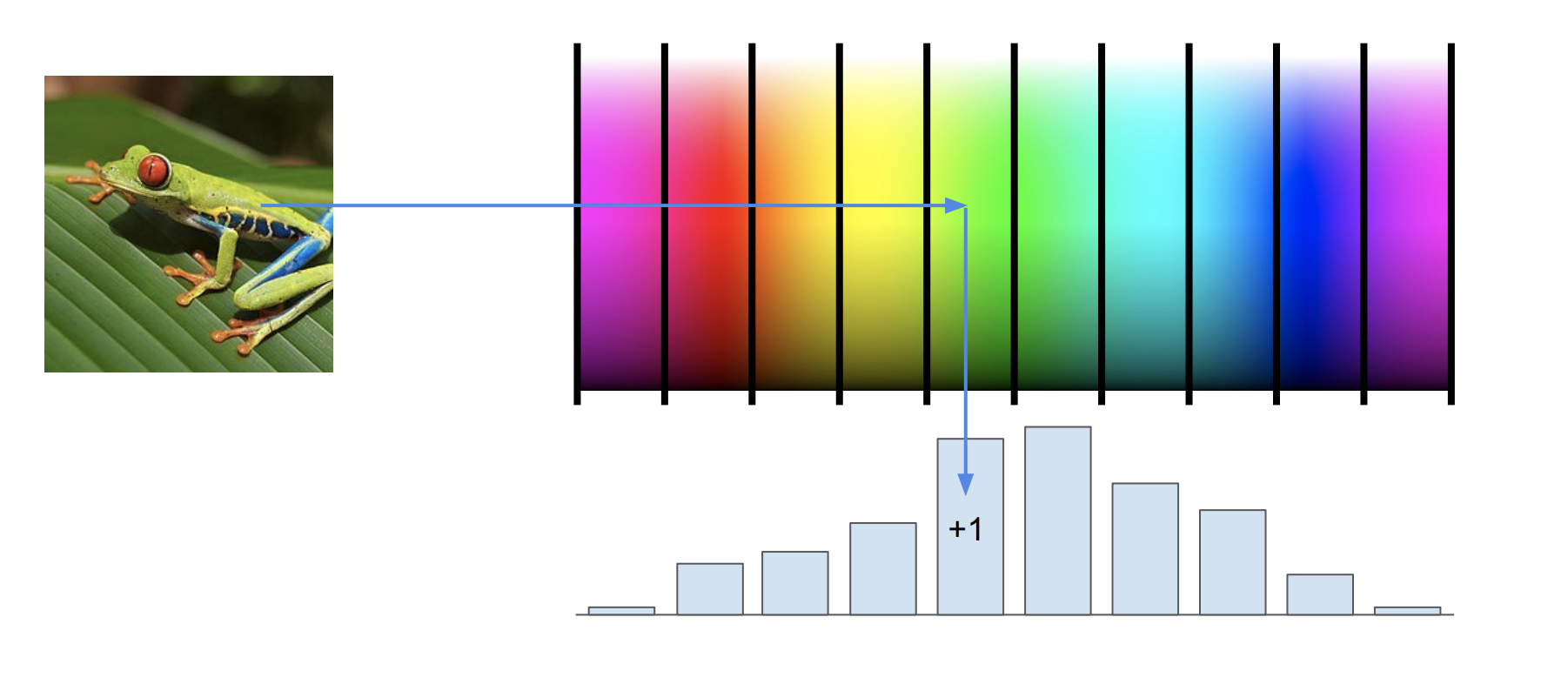
특징 변환의 예1 : color histogram
이미지 전체적으로 어떤 색으로 있는지를 나타낸다.
특징 변환의 예2 : Histogram of Oriented Gradients (HoG)
이미지 내에 전반적으로 어떤 종류의 edge 정보가 있는지를 나타낸다.

이미지를 지역화해서, 지역적으로 어떤 edge가 존재하는지도 알 수 있다.
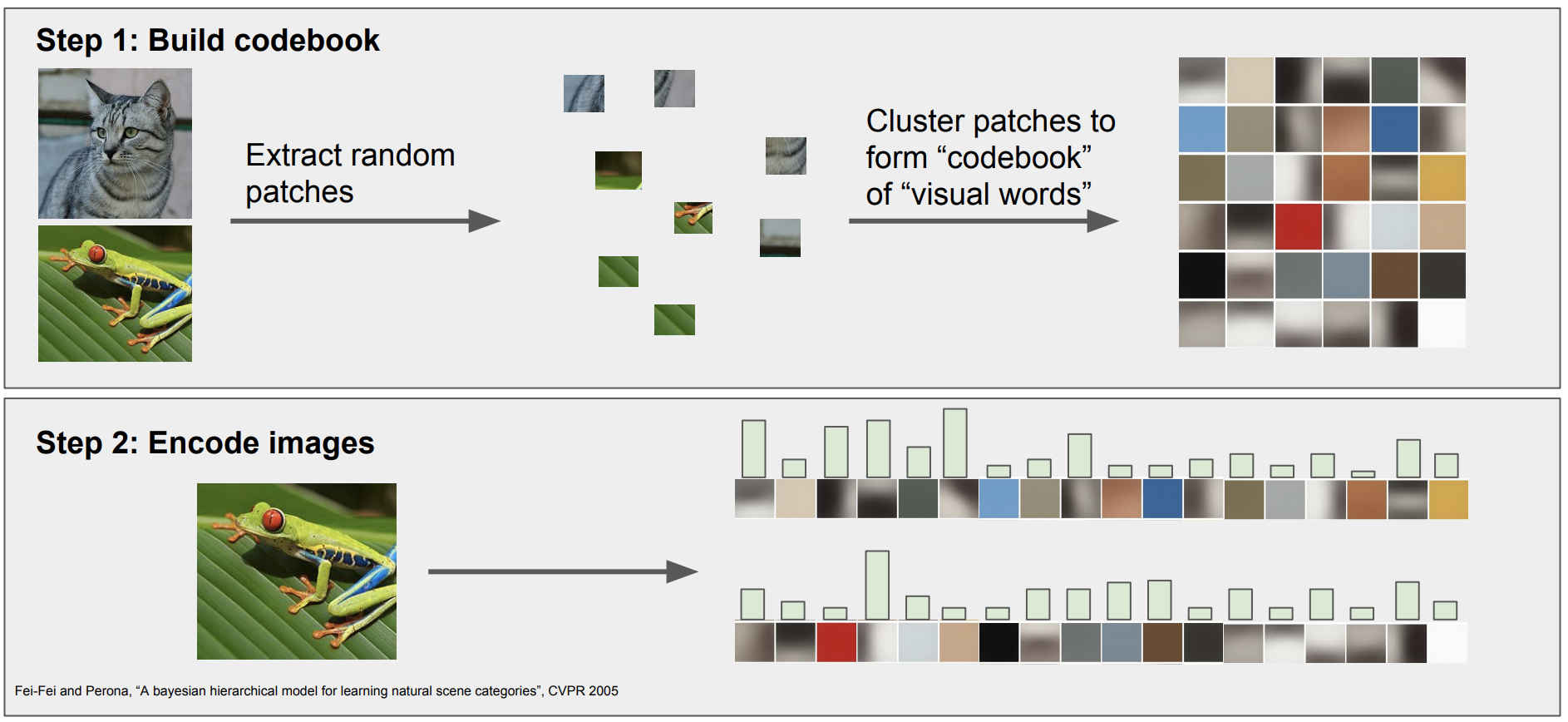
특징 변환의 예3 : Bag of Words
자연의 처리(NLP)에서 영감을 얻은 방법이다.