나이브 베이즈란?
나이브 베이즈(Naive Bayes)는 확률 분류 모델로, 베이즈 정리를 기반으로 특성들 간의 독립성을 가정하여 사후 확률을 예측하여 분류 작업을 수행한다. 사후 확률이란, 최종적으로 예측하는 확률이다. 특히 텍스트 분류, 스팸 메일 필터링 등에 활용되며, 계산이 빠르고 간단한 특징으로 인해 널리 사용된다.
예를 들어, 비가 올 확률을 나이브 베이즈 모델로 예측할 수 있다.
여러 단서들을 하나씩 살펴보면서 "비가 올 확률"을 계속해서 업데이트하는는 방식이다.
여기서 중요한 건 "나이브"라는 표현이다. 이 말은 영어로 "순진하다" 또는 "단순하다"는 뜻인데, "각 확률 단서는 서로에게 영향을 주지 않는다"고 가정한다.
예를 들어, "하늘이 흐린 것"과 "일기예보에서 비가 온다고 하는 것"은 서로에게 영향을 주지 않고, 그냥 각각의 단서로만 생각하는 것이다. 실제로는 둘이 관련이 있을 수도 있지만, 그냥 따로따로 생각하고 합치는 것이다. 그래서 '나이브(순진한) 베이즈' 라고 부른다.
수학적 원리
=
-
(사후 확률, Posterior Probability): B라는 사건이 발생했을 때 A라는 사건이 발생할 확률. 우리가 알고 싶은 최종 확률. B라는 새로운 정보가 주어졌을 때 A에 대한 우리의 '업데이트된 믿음'이라고 할 수 있다.
-
(우도, Likelihood): A라는 사건이 발생했다는 가정 하에 B라는 사건이 발생할 확률. A가 사실일 때 우리가 관측한 B라는 증거가 나타날 가능성을 나타낸다.
-
(사전 확률, Prior Probability): B라는 정보가 주어지기 전에 A라는 사건이 발생할 확률. A에 대한 우리의 '초기 믿음'이다.
-
(증거, Evidence 또는 한계 우도, Marginal Likelihood): B라는 사건이 발생할 전체 확률. 이는 A가 발생하든 안 하든 B가 발생할 확률을 의미한다.
파이썬 실습 코드
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import seaborn as sns
# 1. 데이터 생성 (가상의 2차원 데이터)
# 두 개의 클래스를 가진 데이터를 만듭니다.
np.random.seed(42) # 재현성을 위해 시드 고정
# 클래스 0 데이터 (x, y)
X0 = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 1]], 100)
y0 = np.zeros(100)
# 클래스 1 데이터 (x, y)
X1 = np.random.multivariate_normal([3, 3], [[1, -0.5], [-0.5, 1]], 100)
y1 = np.ones(100)
X = np.vstack((X0, X1))
y = np.hstack((y0, y1))
# 2. 데이터 분할 (학습 및 테스트 세트)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3. 나이브 베이즈 분류기 학습
# 가우시안 나이브 베이즈 모델을 사용합니다.
# 이 모델은 특성들이 정규 분포를 따른다고 가정합니다.
model = GaussianNB()
model.fit(X_train, y_train)
# 4. 예측 수행
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test) # 각 클래스에 속할 확률
# 5. 모델 성능 평가
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
print(f"정확도 (Accuracy): {accuracy:.2f}")
print("\n혼동 행렬 (Confusion Matrix):\n", conf_matrix)
print("\n분류 보고서 (Classification Report):\n", class_report)
# 6. 시각화
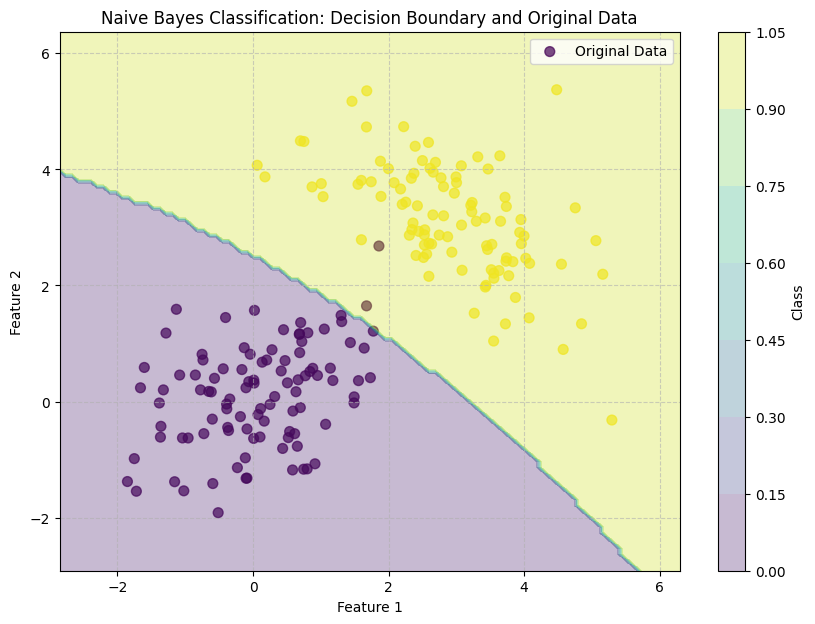
# 6.1. 원본 데이터 및 결정 경계 시각화
plt.figure(figsize=(10, 7))
# 원본 데이터 포인트
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='viridis', alpha=0.7, label='Original Data')
# 결정 경계 (Decision Boundary) 시각화
# 격자점을 만들고 각 격자점에 대한 예측을 수행합니다.
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap='viridis')
plt.title('Naive Bayes Classification: Decision Boundary and Original Data')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.colorbar(label='Class')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()
# 6.2. 혼동 행렬 시각화
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', cbar=False,
xticklabels=['Predicted 0', 'Predicted 1'],
yticklabels=['Actual 0', 'Actual 1'])
plt.title('Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()
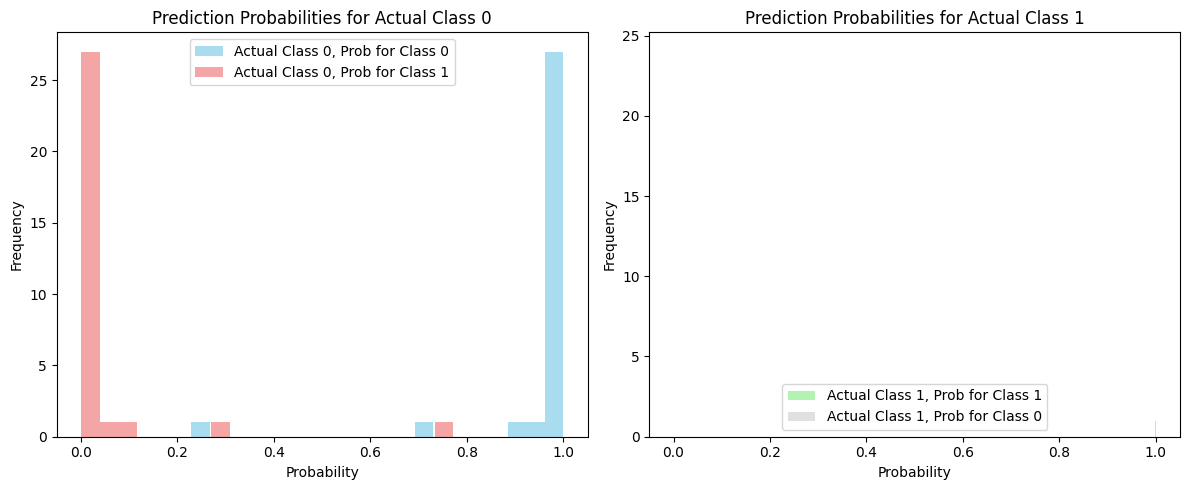
# 6.3. 예측 확률 분포 시각화 (선택 사항)
# 각 클래스에 대한 예측 확률을 히스토그램으로 시각화하여
# 모델이 얼마나 '확신'하는지 볼 수 있습니다.
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.hist(y_prob[y_test == 0, 0], bins=20, alpha=0.7, label='Actual Class 0, Prob for Class 0', color='skyblue')
plt.hist(y_prob[y_test == 0, 1], bins=20, alpha=0.7, label='Actual Class 0, Prob for Class 1', color='lightcoral')
plt.title('Prediction Probabilities for Actual Class 0')
plt.xlabel('Probability')
plt.ylabel('Frequency')
plt.legend()
plt.subplot(1, 2, 2)
plt.hist(y_prob[y_test == 1, 1], bins=20, alpha=0.7, label='Actual Class 1, Prob for Class 1', color='lightgreen')
plt.hist(y_prob[y_test == 1, 0], bins=20, alpha=0.7, label='Actual Class 1, Prob for Class 0', color='lightgray')
plt.title('Prediction Probabilities for Actual Class 1')
plt.xlabel('Probability')
plt.ylabel('Frequency')
plt.legend()
plt.tight_layout()
plt.show()
정확도 (Accuracy): 0.98
혼동 행렬 (Confusion Matrix):
[[30 1]
[ 0 29]]
분류 보고서 (Classification Report):
precision recall f1-score support
0.0 1.00 0.97 0.98 31
1.0 0.97 1.00 0.98 29
accuracy 0.98 60
macro avg 0.98 0.98 0.98 60
weighted avg 0.98 0.98 0.98 60
코드 설명:
데이터 생성 (numpy):
np.random.multivariate_normal을 사용하여 두 개의 다른 평균과 공분산 행렬을 가진 정규 분포에서 데이터를 생성.
이는 두 개의 클래스(0과 1)가 특징 공간에서 서로 다른 영역에 분포하도록 만든다.
X는 특징(feature) 데이터, y는 레이블(target) 데이터이다.
데이터 분할 (sklearn.model_selection.train_test_split):
모델 학습에 사용할 X_train, y_train과 모델 성능 평가에 사용할 X_test, y_test로 데이터를 나눕니다. test_size=0.3은 전체 데이터의 30%를 테스트 세트로 사용한다는 의미입니다.
나이브 베이즈 분류기 학습 (sklearn.naive_bayes.GaussianNB):
GaussianNB는 특성들이 가우시안(정규) 분포를 따른다고 가정하는 나이브 베이즈 모델입니다. 이는 연속형 데이터에 적합하다.
model.fit(X_train, y_train)으로 학습 데이터에 모델을 적합시킨다.
예측 수행 (model.predict, model.predict_proba):
model.predict(X_test)는 테스트 데이터에 대한 예측 레이블을 반환합니다.
model.predict_proba(X_test)는 각 샘플이 각 클래스에 속할 확률을 반환합니다.
모델 성능 평가 (sklearn.metrics):
정확도 (Accuracy): 올바르게 분류된 샘플의 비율.
혼동 행렬 (Confusion Matrix): 실제 클래스와 예측 클래스 간의 관계를 보여주는 표.
True Positive (TP): 실제 양성, 예측 양성
True Negative (TN): 실제 음성, 예측 음성
False Positive (FP): 실제 음성, 예측 양성 (Type I error)
False Negative (FN): 실제 양성, 예측 음성 (Type II error)
분류 보고서 (Classification Report):
정밀도(Precision), 재현율(Recall), F1-점수(F1-score), 지지도(Support)를 포함하여 각 클래스별 성능을 자세히 보여준다.
시각화 (matplotlib.pyplot, seaborn):
원본 데이터 및 결정 경계 시각화:
plt.scatter를 사용하여 원본 데이터 포인트들을 클래스별로 색상을 다르게 표시한다.
np.meshgrid와 plt.contourf를 사용하여 분류기가 데이터를 어떻게 나누는지를 보여주는 결정 경계(Decision Boundary)를 시각화한다. 이 경계는 각 지점에서 모델이 예측하는 클래스가 바뀌는 지점이다. 나이브 베이즈는 선형 또는 비선형 경계를 가질 수 있지만, 가우시안 나이브 베이즈는 일반적으로 타원형/곡선형 경계를 생성한다.
혼동 행렬 시각화:
seaborn.heatmap을 사용하여 혼동 행렬을 시각적으로 더 쉽게 이해할 수 있도록 표시한다.
예측 확률 분포 시각화:
모델이 예측한 각 클래스의 확률 분포를 히스토그램으로 보여준다. 이를 통해 모델이 특정 예측에 대해 얼마나 "확신"하는지, 그리고 잘못 분류된 샘플의 경우 확률 분포가 어떻게 되는지 파악할 수 있다.
-
나이브 베이즈의 개념 검증:
이 코드를 실행하면 다음과 같은 방식으로 나이브 베이즈의 개념을 검증할 수 있다: -
결정 경계: 시각화된 결정 경계를 통해 나이브 베이즈가 각 클래스의 확률 분포를 기반으로 어떻게 데이터를 분리하는지 직관적으로 이해할 수 있다. 특히 가우시안 나이브 베이즈의 경우, 각 클래스의 평균과 분산을 바탕으로 타원형 또는 곡선형의 경계가 나타나는 것을 볼 수 있다.
-
성능 지표: 정확도, 정밀도, 재현율, F1-점수 등을 통해 모델이 얼마나 잘 분류하는지 정량적으로 확인할 수 있다.
-
혼동 행렬: 모델이 어떤 종류의 오류(오분류)를 범하는지 (예: 클래스 0을 1로 잘못 예측하는 경우) 명확하게 보여준다.
-
확률 분포: predict_proba를 통해 모델이 단순히 레이블을 반환하는 것이 아니라, 각 클래스에 속할 확률을 계산하며, 이 확률을 기반으로 최종 결정을 내린다는 것을 알 수 있다.
