SVM(Support Vector Machine)이란?
서포트 벡터 머신, SVM(Support Vector Machine)은 N차원 공간에서 각 클래스 간의 거리를 최대화하는 최적의 선 또는 초평면을 찾아 데이터를 분류하는 지도형 머신 러닝 알고리즘이다.
두 클래스 간의 경계(hyperplane)를 정의하고, 이 경계를 기준으로 새로운 데이터를 분류하는 모델이다. 이때 가장 넓은 margin(여유 공간) 을 가진 결정 경계를 찾는 것이 목표이다.
쉽게 말해 클래스(데이터 집합)를 케이크의 딸기 토핑이라고 생각하면 딸기 토핑이 정가운데에 오도록(가장 넓은 여유 공간을 가져서 데이터의 클래스를 손상시키지 않도록) 케이크를 조각내는 최적의 거리를 계산하는 머신 러닝 알고리즘이다.
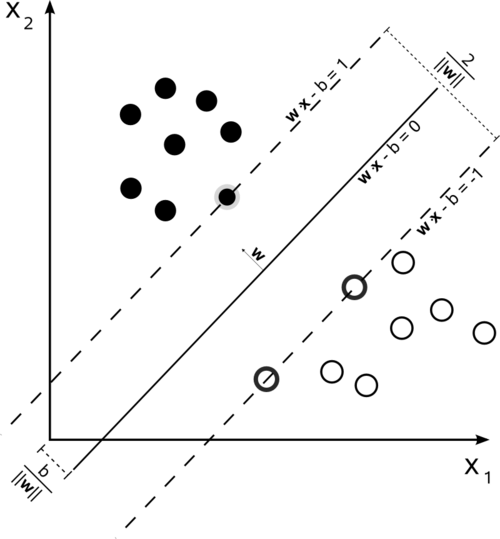
사진을 보면, 선형 SVM이 두 자료(흰색 원, 검은색 원)를 직선으로 분리하고 있다.
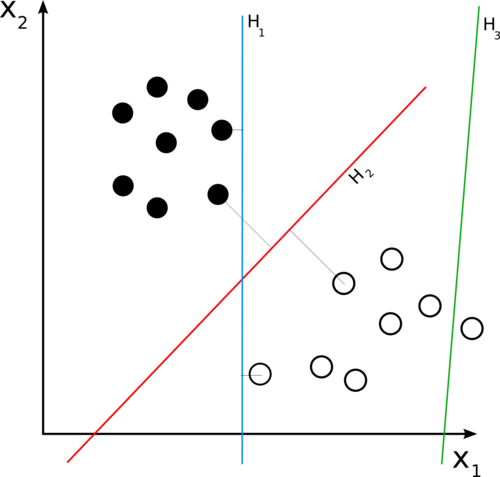
H3은 두 클래스의 점들을 제대로 분류하고 있지 않다. H1과 H2는 두 클래스의 점들을 분류하는데, H2가 H1보다 더 큰 마진을 갖고 분류한다.
유래
SVM은 1990년대에 블라디미르 바프닉(Vladimir N. Vapnik)과 그의 동료들이 개발했으며, 1995년 '함수 근사, 회귀 추정 및 신호 처리를 위한 서포트 벡터 방법 1'이라는 제목의 논문에서 발표되었다.
유형
1) 선형 SVM
분리 초평면 공식은 일반적으로 알고있는 일차 함수다.
w는 가중치 벡터, x는 입력 벡터, b는 편향 항이다.
2) 비선형 SVM
실제 시나리오의 많은 데이터는 선형적으로 구분할 수 없다.
따라서 비선형 SVM을 사용하게 된다.
비선형 SVM의 원리는 선형 SVM을 만들기 위해서 데이터를 전처리하여 높은 차원의 특성 공간으로 변형하는 것이다.
데이터를 효율적으로 분류하는 데 커널 트릭을 사용한다.
널리 사용되는 커널 트릭은 다음 세 가지이다.
- 다항식 커널
- 방사 기저 함수 커널(가우시안 커널 또는 RBF 커널이라고도 함)
- 시그모이드 커널
3) 서포트 벡터 회귀(SVR)
서포트 벡터 회귀(SVR)는 회귀 문제(즉, 결과가 연속적인 경우)에 적용되는 SVM의 확장이다. 선형 SVM과 마찬가지로 SVR은 데이터 포인트 사이의 마진이 최대인 초평면을 찾으며, 일반적으로 시계열 예측에 사용된다.
SVR은 독립 변수와 종속 변수 간에 이해하고자 하는 관계를 지정해야 한다는 점에서 선형 회귀와 다르다. 선형 회귀를 사용할 때는 변수 간의 관계와 그 방향에 대한 이해가 중요하다. SVR은 이러한 관계를 스스로 결정하기 때문에 이 과정이 필요하지 않다.
활용
SVM은 일반적으로 분류 문제에서 사용된다. 서로 반대되는 두 클래스의 가장 가까운 데이터 포인트 사이의 마진을 최대화하는 최적의 초평면을 찾아 두 클래스를 구분한다.
입력 데이터의 특성 수에 따라 초평면이 2차원 공간의 선인지, 아니면 n차원 공간의 면인지가 결정된다. 클래스를 구분하기 위해 여러 초평면을 찾을 수 있으므로, 포인트 사이의 마진을 최대화하면 알고리즘이 클래스 간 최적의 결정 경계를 찾을 수 있다.
이를 통해 새로운 데이터에도 잘 일반화하여 정확한 분류 예측을 할 수 있다. 최적의 초평면에 인접한 선들을 서포트 벡터라고 하는데, 이 벡터는 최대 마진을 결정하는 데이터 포인트를 통과한다.
SVM 알고리즘은 선형 및 비선형 분류 작업을 모두 처리할 수 있기 때문에 머신 러닝에서 널리 사용된다.
앞서 말했듯 데이터를 선형적으로 분리할 수 없는 경우, 데이터를 고차원 공간으로 변환하여 선형 분리가 가능하도록 하기 위해 커널 함수를 사용한다. 이러한 커널 함수의 적용을 '커널 트릭'이라고 하며 데이터 특성 및 특정 사용 사례에 따라 선형 커널, 다항식 커널, 방사 기저 함수(RBF) 커널 또는 시그모이드 커널 등 선택할 수 있는 커널 함수가 달라진다.
파이썬 라이브러리 소개
파이썬 언어로는 대표적으로 아래 세 가지의 라이브러리를 이용해 SVM을 활용한 알고리즘을 구현할 수 있다. 세 가지 모두 무료로 사용 가능하다.
(1) Scikit-learn
scikit-learn은 NumPy, SciPy, 그리고 matplotlib 라이브러리들을 기반으로 구현되었고 오픈 소스이며 상업적으로도 이용 가능하다.
(2) PyML
PyML은 scikit-learn이 전반적인 머신 러닝 기법들을 제공해주는데 비해, PyML은 서포트 벡터 머신 기능에 초점을 맞추고 있다. 무료로 다운받아서 사용할 수 있으며, Linux와 Mac OS X에서 사용 가능하다.
(3) LIBSVM
서포트 벡터 머신만을 위한 라이브러리로 파이썬 뿐만 아니라 C/C++, Java, Matlab, R, Perl 등의 다양한 언어를 지원한다. 무료로 다운받아서 사용할 수 있으며, Windows, Mac OS X, 그리고 Linux에서 사용 가능하다.
파이썬 실습 코드
gemini에게 코드를 받아 colab에서 구현해보았다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC, SVR
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, mean_squared_error
from sklearn.preprocessing import StandardScaler
# 1. 선형 SVM (Linear Support Vector Machine)
# 간단한 이진 분류 데이터 생성
X_linear = np.array([[1, 1], [2, 2], [1, 2], [2, 1], [4, 4], [5, 5]])
y_linear = np.array([0, 0, 0, 0, 1, 1])
# 데이터 분할
X_train_linear, X_test_linear, y_train_linear, y_test_linear = train_test_split(X_linear, y_linear, test_size=0.3, random_state=42)
# 모델 학습
linear_svm = SVC(kernel='linear')
linear_svm.fit(X_train_linear, y_train_linear)
# 예측 및 평가
y_pred_linear = linear_svm.predict(X_test_linear)
accuracy_linear = accuracy_score(y_test_linear, y_pred_linear)
print(f"선형 SVM 정확도: {accuracy_linear:.2f}")
# 결정 경계 시각화 (2차원 데이터에 한정)
if X_linear.shape[1] == 2:
plt.figure(figsize=(6, 4))
h = .02 # 메시 간격
x_min, x_max = X_linear[:, 0].min() - 1, X_linear[:, 0].max() + 1
y_min, y_max = X_linear[:, 1].min() - 1, X_linear[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = linear_svm.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X_linear[:, 0], X_linear[:, 1], c=y_linear, cmap=plt.cm.coolwarm, edgecolors='k')
plt.title('선형 SVM 결정 경계')
plt.xlabel('특성 1')
plt.ylabel('특성 2')
plt.show()
# 2. 비선형 SVM (Non-linear Support Vector Machine)
# 간단한 비선형 분류 데이터 생성
X_nonlinear = np.array([[1, 1], [2, 2], [1, 2], [2, 1], [4, 1], [5, 2], [4, 2], [5, 1]])
y_nonlinear = np.array([0, 0, 0, 0, 1, 1, 1, 1])
# 데이터 분할
X_train_nonlinear, X_test_nonlinear, y_train_nonlinear, y_test_nonlinear = train_test_split(X_nonlinear, y_nonlinear, test_size=0.3, random_state=42)
# 모델 학습 (RBF 커널 사용)
nonlinear_svm = SVC(kernel='rbf', gamma='scale') # 'poly', 'sigmoid' 등 다른 커널도 사용 가능
nonlinear_svm.fit(X_train_nonlinear, y_train_nonlinear)
# 예측 및 평가
y_pred_nonlinear = nonlinear_svm.predict(X_test_nonlinear)
accuracy_nonlinear = accuracy_score(y_test_nonlinear, y_pred_nonlinear)
print(f"비선형 SVM (RBF 커널) 정확도: {accuracy_nonlinear:.2f}")
# 결정 경계 시각화 (2차원 데이터에 한정)
if X_nonlinear.shape[1] == 2:
plt.figure(figsize=(6, 4))
h = .02
x_min, x_max = X_nonlinear[:, 0].min() - 1, X_nonlinear[:, 0].max() + 1
y_min, y_max = X_nonlinear[:, 1].min() - 1, X_nonlinear[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = nonlinear_svm.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.8)
plt.scatter(X_nonlinear[:, 0], X_nonlinear[:, 1], c=y_nonlinear, cmap=plt.cm.coolwarm, edgecolors='k')
plt.title('비선형 SVM (RBF 커널) 결정 경계')
plt.xlabel('특성 1')
plt.ylabel('특성 2')
plt.show()
# 3. SVR (Support Vector Regression)
# 간단한 회귀 데이터 생성
X_svr = np.sort(5 * np.random.rand(40, 1), axis=0)
y_svr = np.sin(X_svr).ravel() + 0.5 * np.random.randn(len(X_svr))
# 데이터 분할
X_train_svr, X_test_svr, y_train_svr, y_test_svr = train_test_split(X_svr, y_svr, test_size=0.3, random_state=42)
# 특성 스케일링 (SVR은 스케일링에 민감할 수 있습니다.)
scaler_svr = StandardScaler()
X_train_scaled_svr = scaler_svr.fit_transform(X_train_svr)
X_test_scaled_svr = scaler_svr.transform(X_test_svr)
# 모델 학습
svr = SVR(kernel='rbf', C=1.0, epsilon=0.1, gamma='scale') # 'linear', 'poly', 'sigmoid' 등 다른 커널도 사용 가능
svr.fit(X_train_scaled_svr, y_train_svr)
# 예측 및 평가
y_pred_svr = svr.predict(X_test_scaled_svr)
mse_svr = mean_squared_error(y_test_svr, y_pred_svr)
print(f"SVR 평균 제곱 오차: {mse_svr:.2f}")
# 결과 시각화
plt.figure(figsize=(8, 6))
plt.scatter(X_test_svr, y_test_svr, color='red', label='실제 값')
plt.plot(X_test_svr, y_pred_svr, color='blue', label='예측 값')
plt.xlabel('데이터')
plt.ylabel('타겟')
plt.title('SVR 결과')
plt.legend()
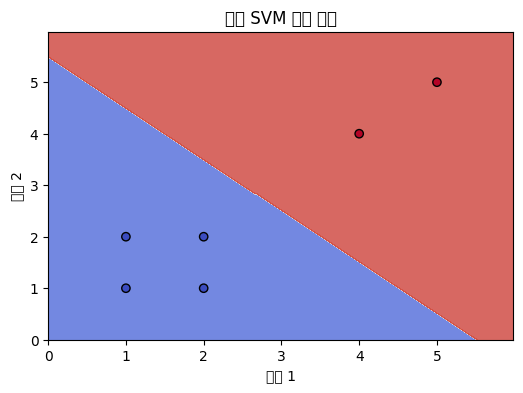
plt.show()결과 1 : 선형 SVM
선형 SVM 정확도: 1.00
결과 2 : 비선형 SVM
비선형 SVM (RBF 커널) 정확도: 1.00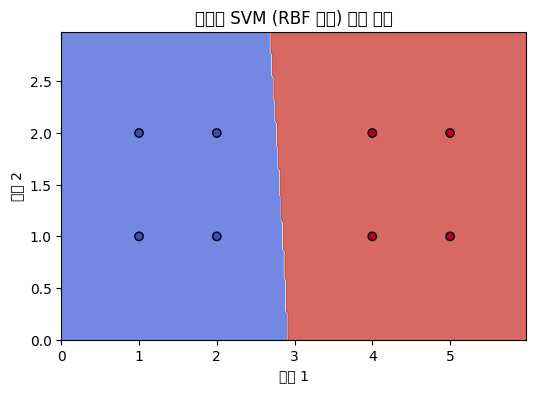
결과 3 : SVR
SVR 평균 제곱 오차: 0.48
레퍼런스
https://www.ibm.com/kr-ko/think/topics/support-vector-machine
https://ko.wikipedia.org/wiki/%EC%84%9C%ED%8F%AC%ED%8A%B8_%EB%B2%A1%ED%84%B0_%EB%A8%B8%EC%8B%A0
