강의 자료
Lecture 10
10번째 강의이다.
저번 시간에는 거대 언어 모델에 대해서 배웠다.
마지막 GPT-3에 대해서 배웠는데,
이번 시간에는 거대 생성 모델이 갖는
Prompting, Instruction Finetuning, and RLHF
과 같은 특징들에 대해서 알아보자.
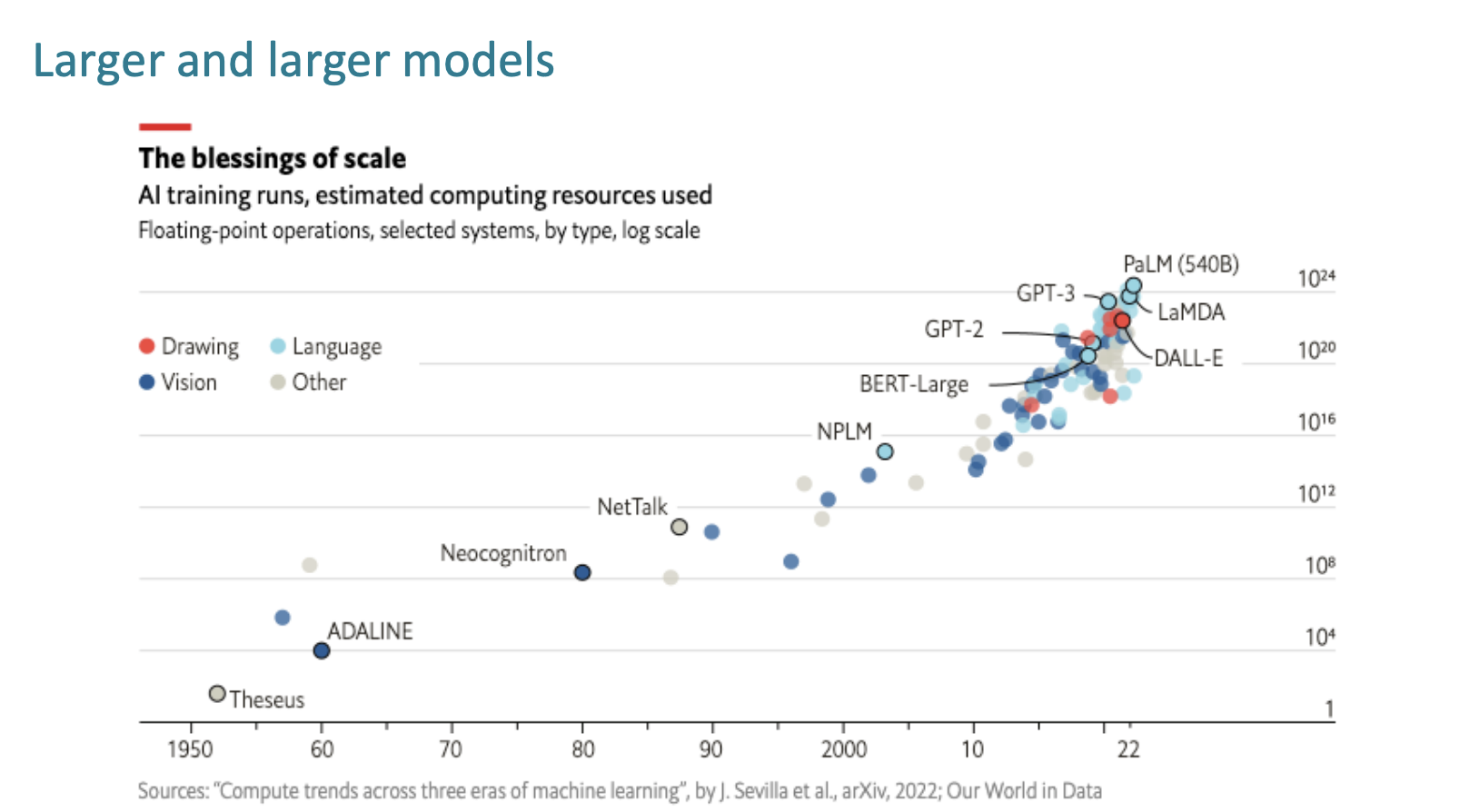
우리의 모델들은 크기가 점점 더 커져가고,
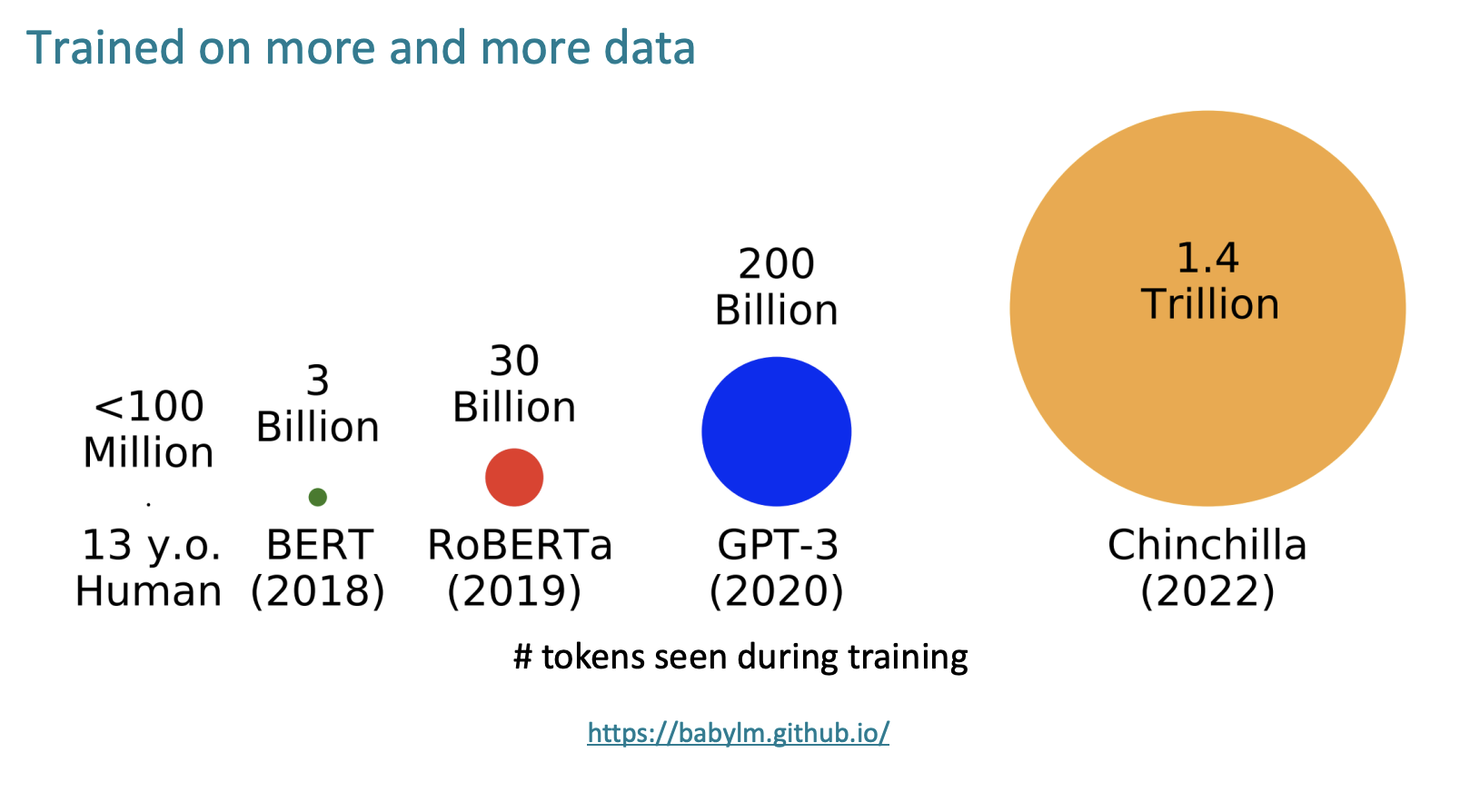
점점 더 많은 데이터에 훈련 받는다.
언어 모델은 어떤 것에 대해 훈련 받고 모델링 될까?
단순한 문장에 대해서 훈련을 받는 것일까?
아니다. 우리는 저번 9강에서 문장의 여러 빈칸을 만들어서 빈칸을 추론하는 방법으로도 언어 모델을 훈련 한다고 했다.
Stanford University is located in __, California. [Trivia]
• I put fork down on the table. [syntax]
• The woman walked across the street, checking for traffic over shoulder. [coreference]
• I went to the ocean to see the fish, turtles, seals, and _. [lexical semantics/topic]
• Overall, the value I got from the two hours watching it was the sum total of the popcorn
and the drink. The movie was _. [sentiment]
• Iroh went into the kitchen to make some tea. Standing next to Iroh, Zuko pondered his
destiny. Zuko left the ____. [some reasoning – this is harder]
• I was thinking about the sequence that goes 1, 1, 2, 3, 5, 8, 13, 21, ____ [some basic
arithmetic; they don’t learn the Fibonnaci sequence]
우리가 만든 언어 모델을 단순히 "언어"와 관련해서만 활용해야하는가?
수학, 코드 등에 대해서도 문제를 해결하는 생성 모델이 될 순 없는 것인가?
우리는 언어 모델을 모든 문제를 해결하는 Assistants로써 접근하려고 한다.
Zero-Shot and Few-Shot In-Context Learning
다시 GPT로 돌아가서,
일단 GPT-1은 대규모 언어 모델이 자연어추론과 같은 하위 작업들을 위한 효과적은 pretraining 기술이라는 것을 보여주었다.
그리고 GPT-2는 아키텍쳐가 훨씬 커졌고, 더 많은 데이터(4GB->40GB)에 대해 학습되었다. 이는 언어 모델이 비지도학습 Multitask Learners라는 논문으로도 게재되었다.
GPT-2에서 엄청난 능력이 밝혀졌는데, 바로 Zero-shot learning이다.
Zero-shot
이 능력은 많은 업무와 작업들을 수행하지만 이에 대한 예시도, gradients도 없이 수행한다는 것이다.
학습 과정에서 배우지 않은 작업을 수행한다. 는 것인데 어떻게 가능할까?
음성 모델이 음성을 구성하는 성분 자체를 이해하고
자연어 모델은 자연어를 자체를 이해하고,
이미지 모델은 이미지 자체를 이해하도록 하는 것이다.
입력 데이터 자체에 대한 이해를 높이기 위한 학습 방식이 바로 비지도 학습(unsupervised learning)이다.
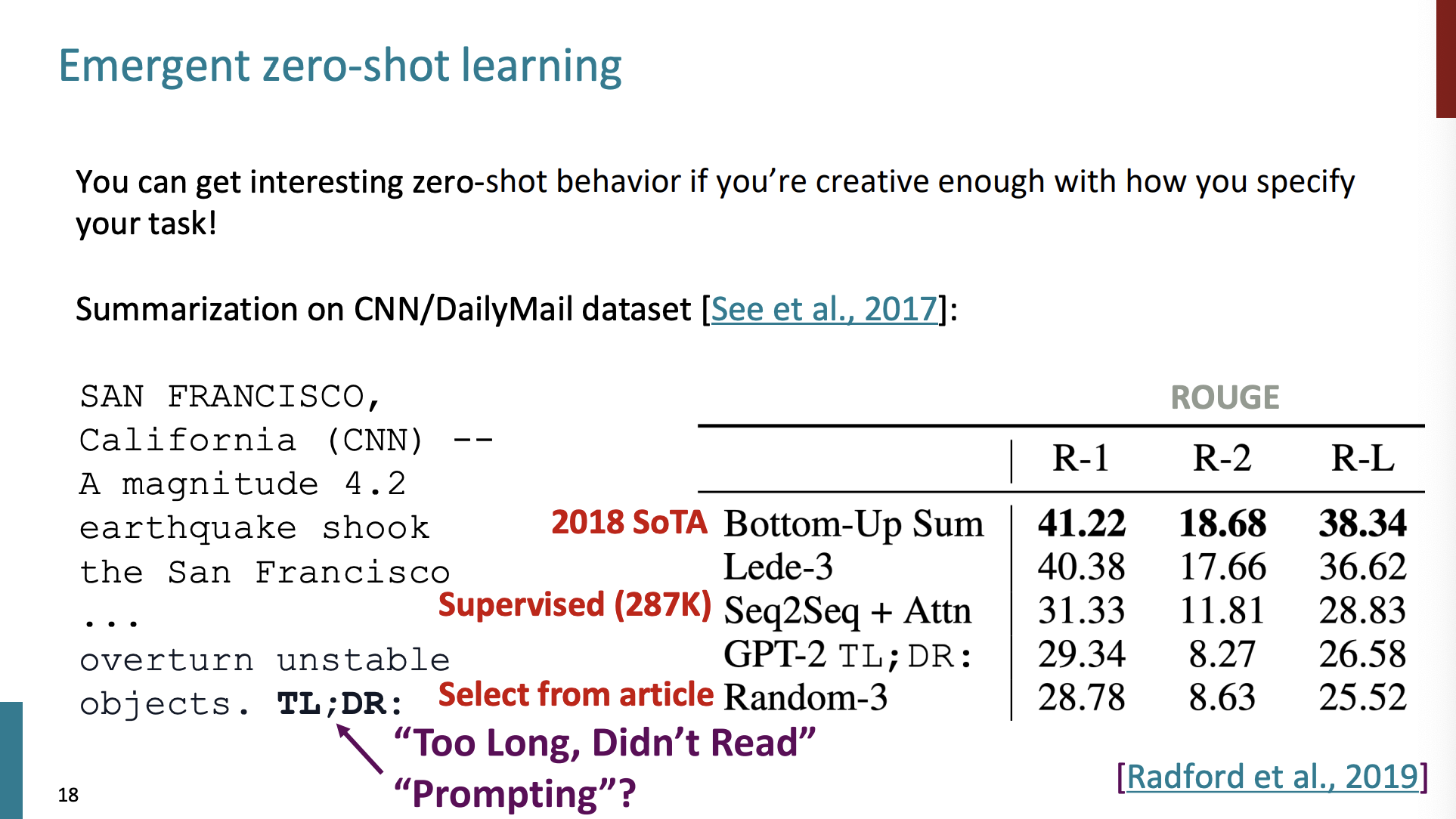
예를 들어서 모델이 "요약"을 수행하기를 원한다고 가정하자.
어떻게 모델이 요약을 수행하게끔 할 수 있을까?
일단 일부 뉴스 기사를 주고,
마지막에 TL;DR 을 추가한다.
이 의미는 '너무 길어서 읽지 않는다.'라는 의미이다.
이 문구 다음은 보통 요약하는 짧은 글이 주어진다고 한다.
그래서 모델이 이 문구 다음에 나타날 글을 예측하는 것을 바탕으로 실험을 해보았다.
일단 마지막 모델은 단순하게 기사에서 랜덤으로 3문장을 뽑은 것이다. GPT-2가 바로 위에 있다. 그리고 그 위의 지도 방식의 모델 두개가 더 좋은 점수를 보였지만, 이는 대규모 모델이 훈련 받지 않은 작업을 수행할 수 있다는 가능성을 보여준 것이다.
그리고 GPT-3가 등장했다.
Few-shot
GPT-3는 어마어마한 크기의 성장을 보여주었다.
1.5B->175B
그리고 데이터의 크기도 엄청 커졌다.
40GB -> over 600GB
그리고 여기서는 새로운 특징을 보여주었다.
바로 Few-shot 이다.
Few-shot이란, 작업 예시를 추가해서 작업을 지정하는 것이다.
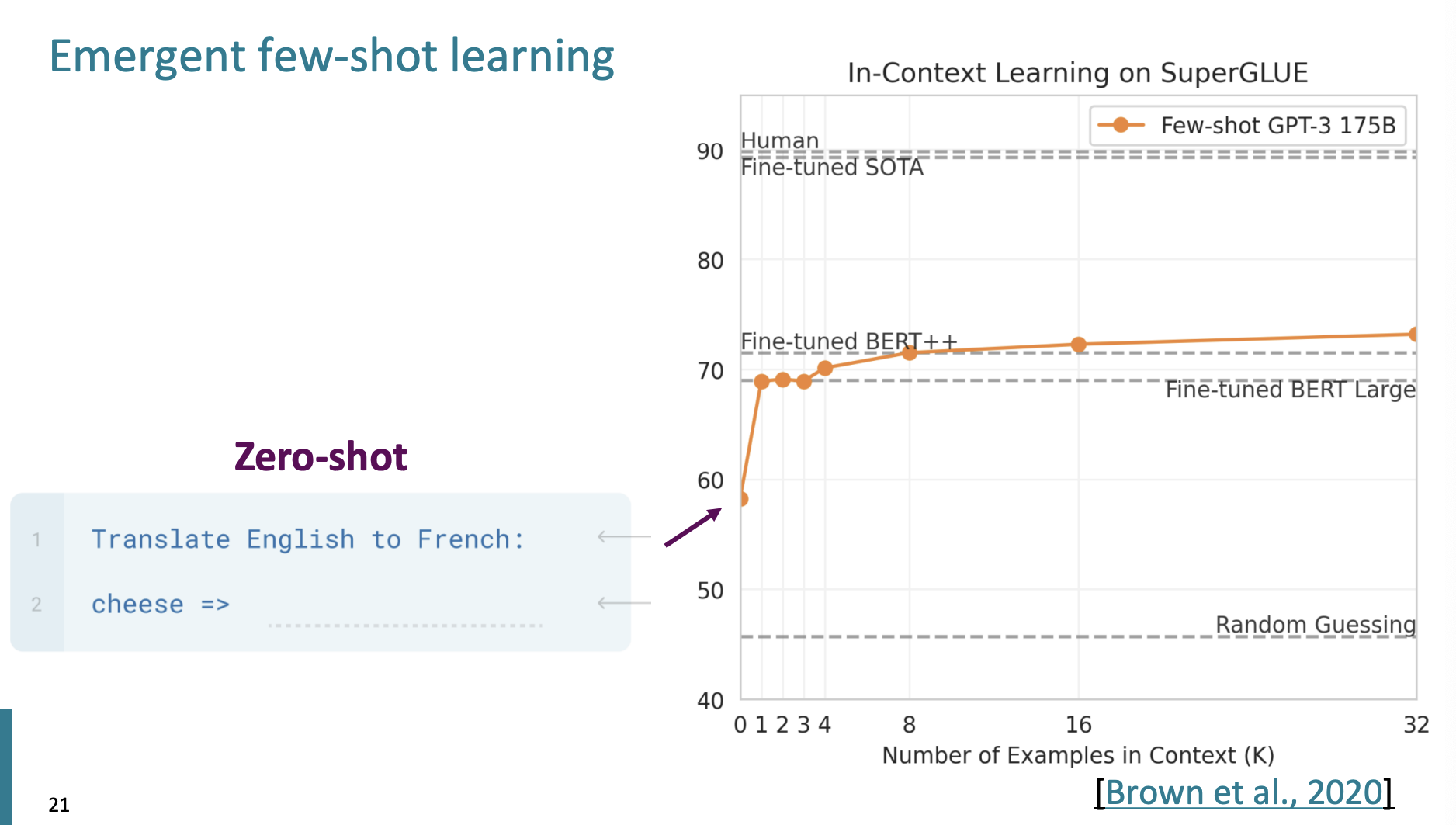
일단 맨 처음 BERT 모델에 번역을 요구하면, 정확도는 60정도 이다.
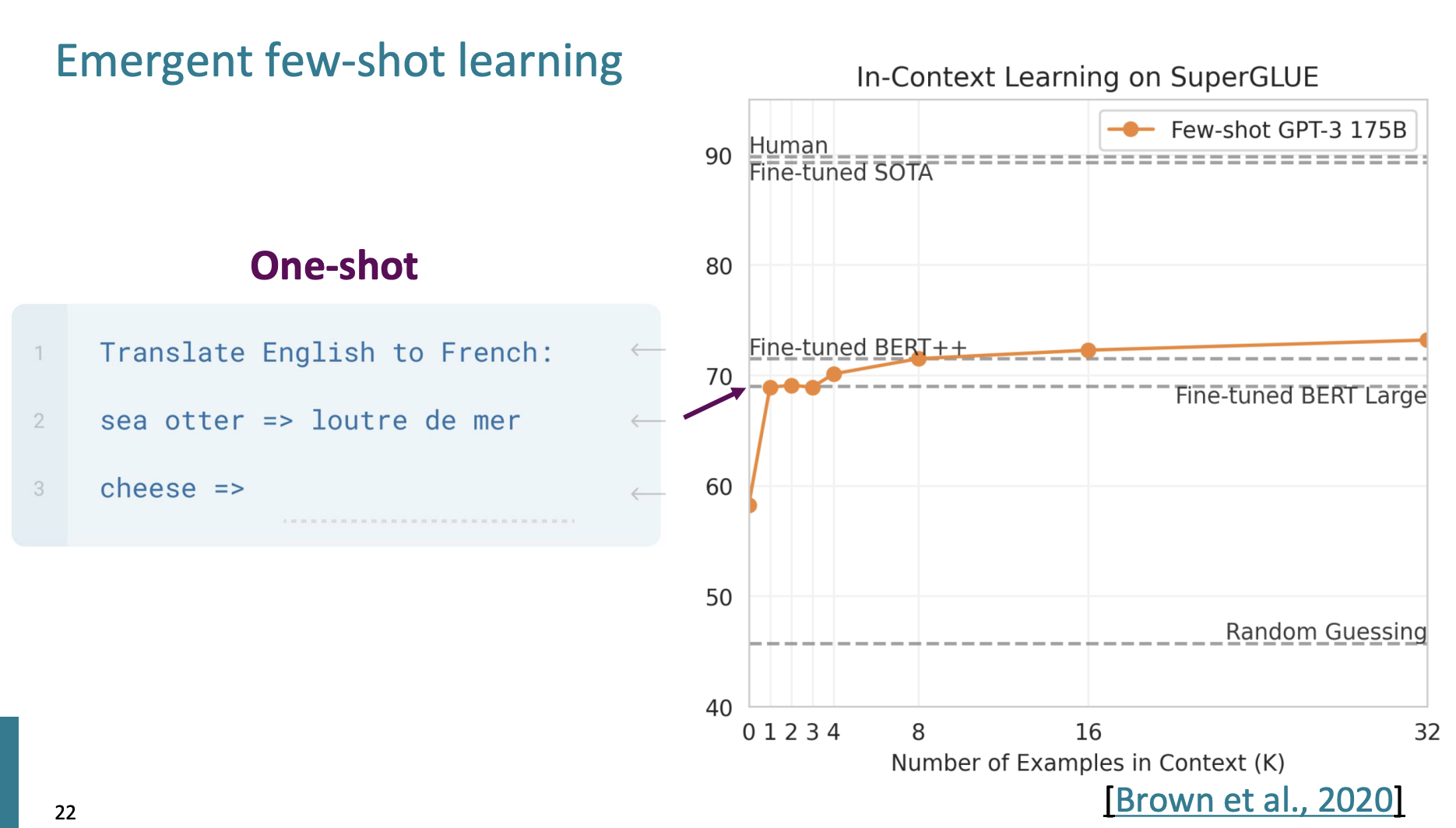
그리고 하나의 예시를 들면 정확도가 급격하게 상승한다.
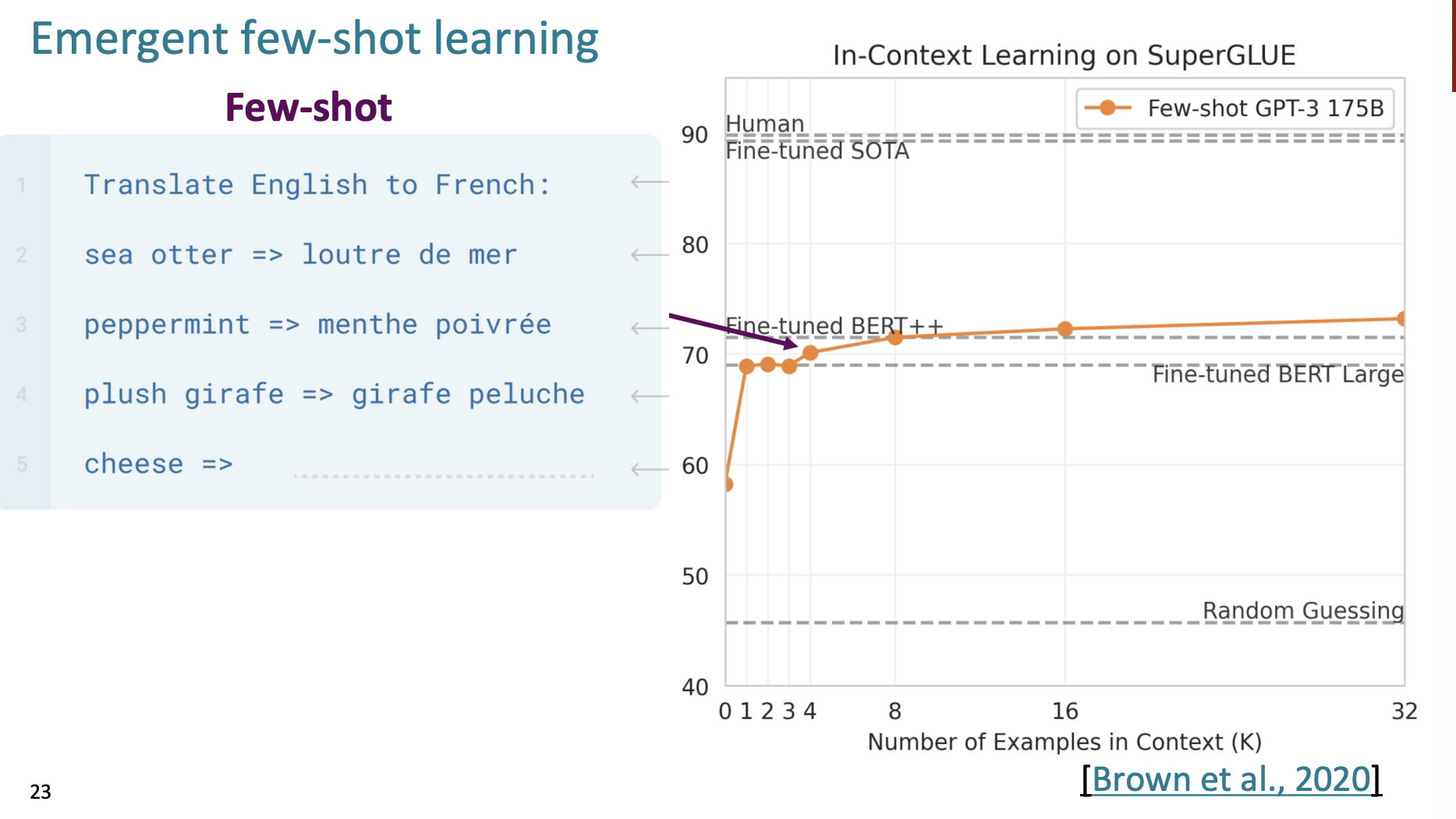
그리고 여러개의 예시를 추가하면 정확도가 높아지지만, 그렇게 많이는 높아지지 않는다.
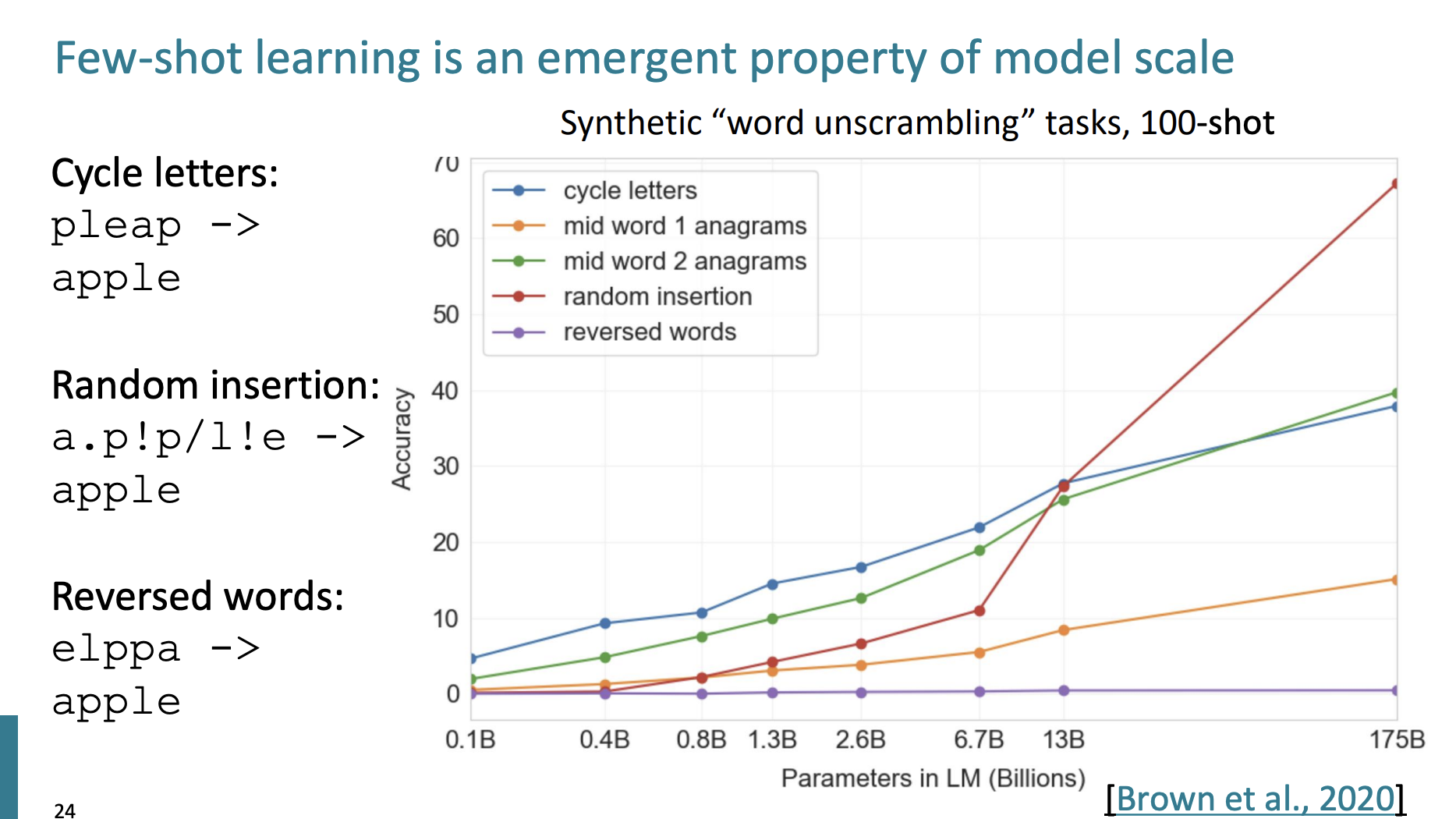
여기 다양한 예시에 대해서 모델이 어떤 정확도를 보이는지 그래프가 있다.
단어가 cycle되거나 random한 문자 삽입이 주어지면 100개의 예시가 주어지고, 모델의 parameter의 수가 많아질수록 정확도가 높아지는 것을 확인할 수 있었다.
하지만 reversed words에 대해서는 정확도가 그대로인데, 이는 최신 모델에 대해서 실행해보면 결과가 달라질수도 있을 거라 말한다. 하지만 여전히 연구중인 분야라고 한다.
더 고난이도의 작업을 하도록 하기위해서는 우리는 언어 모델에게 묻는 방식을 바꿔야 한다.
Chain-of-thought
richer, multi-step resoning을 포함하는 방법을 바로 chain-of-thought이라 한다.
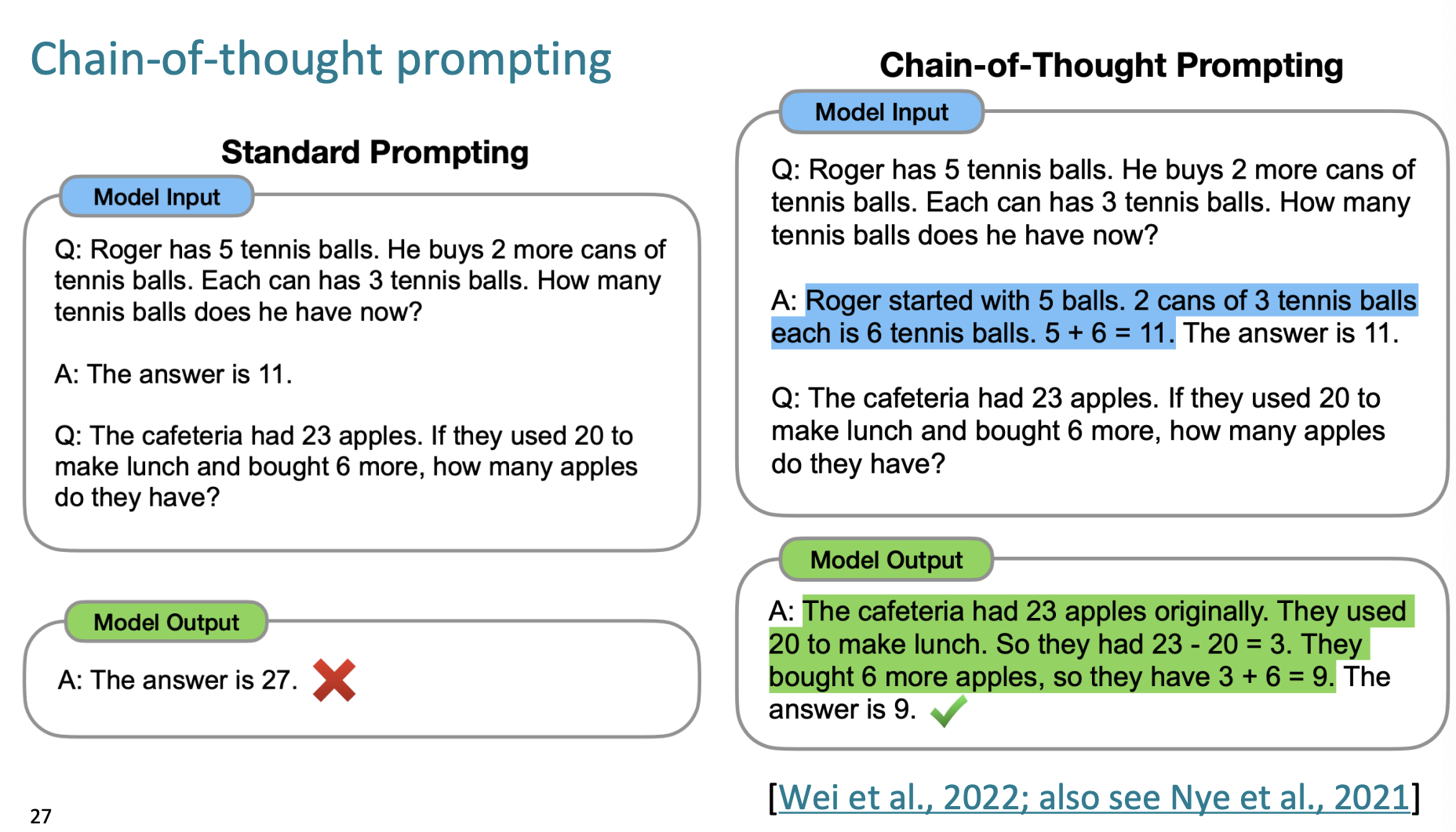
모델의 input 에서 문제를 푸는 예시를 주는 것이다. 다만 문제를 해결할 때, 단계적으로 (step-by-step)으로 문제를 해결하는 방법을 알려주고, 다른 문제를 알려주고 output 을 받았더니 문제를 푸는 정확도가 더 높아졌다는 것이다.
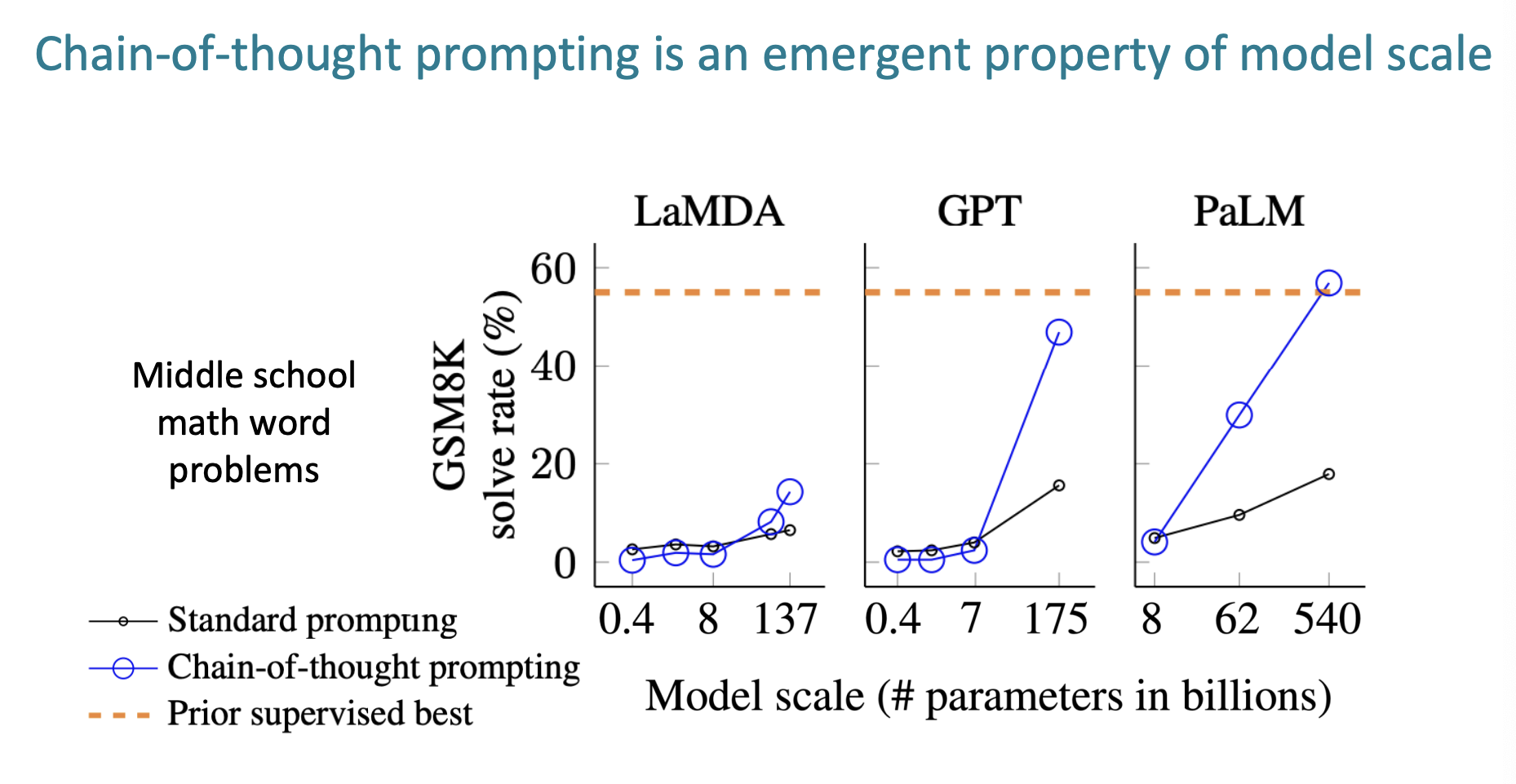
이는 어느정도 규모 이상의 모델에서 문제를 해결하는 비율이 높았다.

근데 그러면 항상 우리는 추론을 보여주어야 하는가?
단지 문구 하나를 추가해서 Zero-shot에 대한 chain of thought을 수행할 수 있다.
바로
Let's think step by step
이다.

문제를 주고, Let's think step by step을 추가하면 알아서 문제를 단계별로 해결한다는 것이다.

(출처:https://learnprompting.org/docs/intermediate/zero_shot_cot)
그리고 어떤 문구가 가장 정확도가 높았을까?
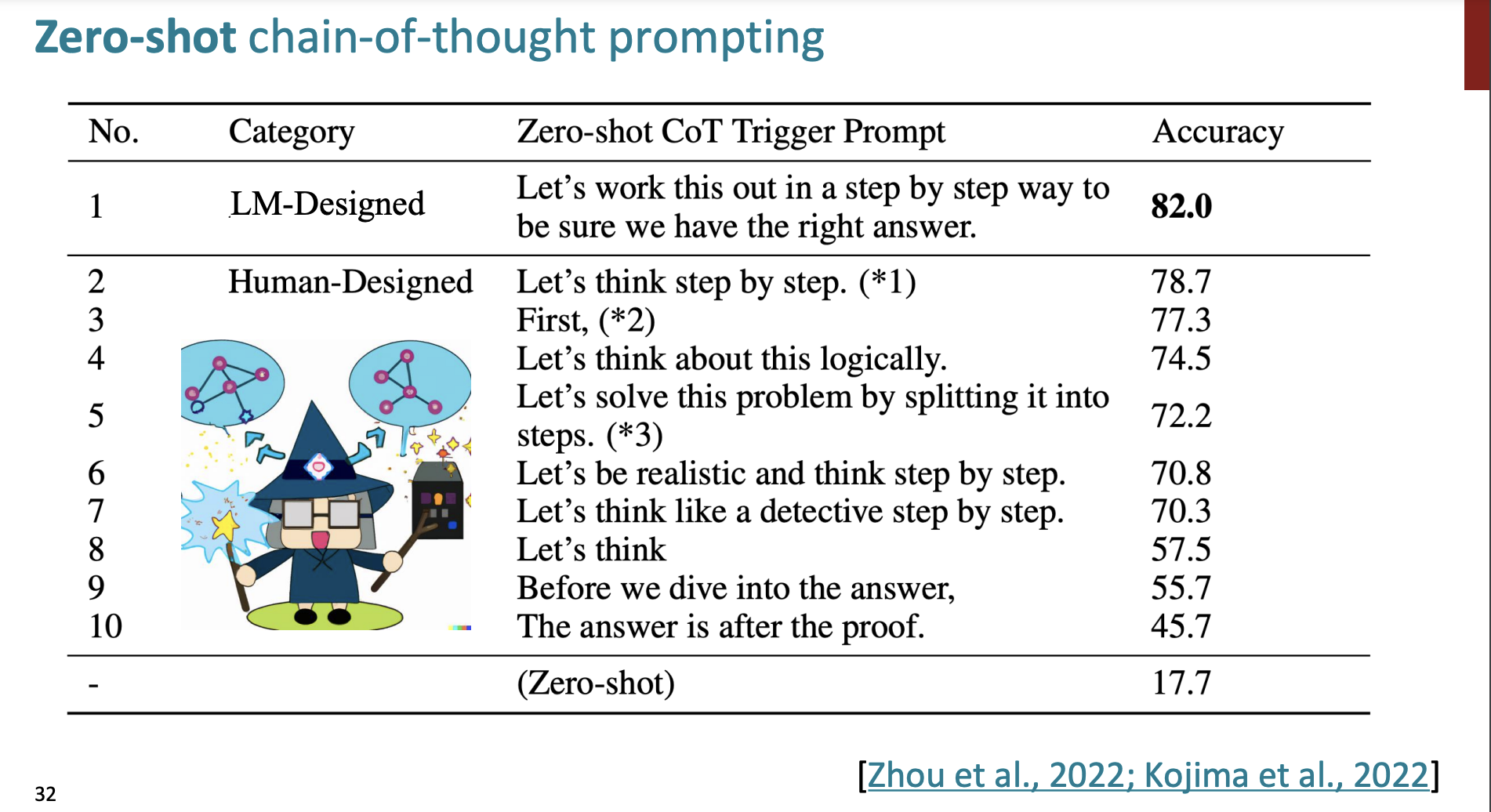
Let's work this out in a step by step way to be sure we have the right answer.
를 추가하면 더 정확도가 높아진다고 한다.
그래서 프롬프트에 어떤 문구, 어떤 말을 넣는가에 따라 언어 모델은 다른 성능을 보여준다는 것을 알게 되었다.
그래서 회사들은 "Prompt engineering"이라는 일을 수행하는 사람을 기용한다고 한다.
그럼 지금까지 우리가 배운 것의 장점과 단점을 정리해보자.
- 미세조정(finetuning)이 더이상 필요하지 않고 프롬프트 엔지니어링으로 성능을 향상시킬 수 있다.
- 하지만 문맥에서 고치는 것엔 한계가 있고
- 복잡한 일을 수행하기 위해서는 gradient 수정이 필요하다.
그럼 이러한 단점을 수정하기 위해서 그 다음을 배워보자.
Instruction finetuning
사용자 의도에 맞게 모델을 구축하기 위해서는 Finetuning이 필요하다.
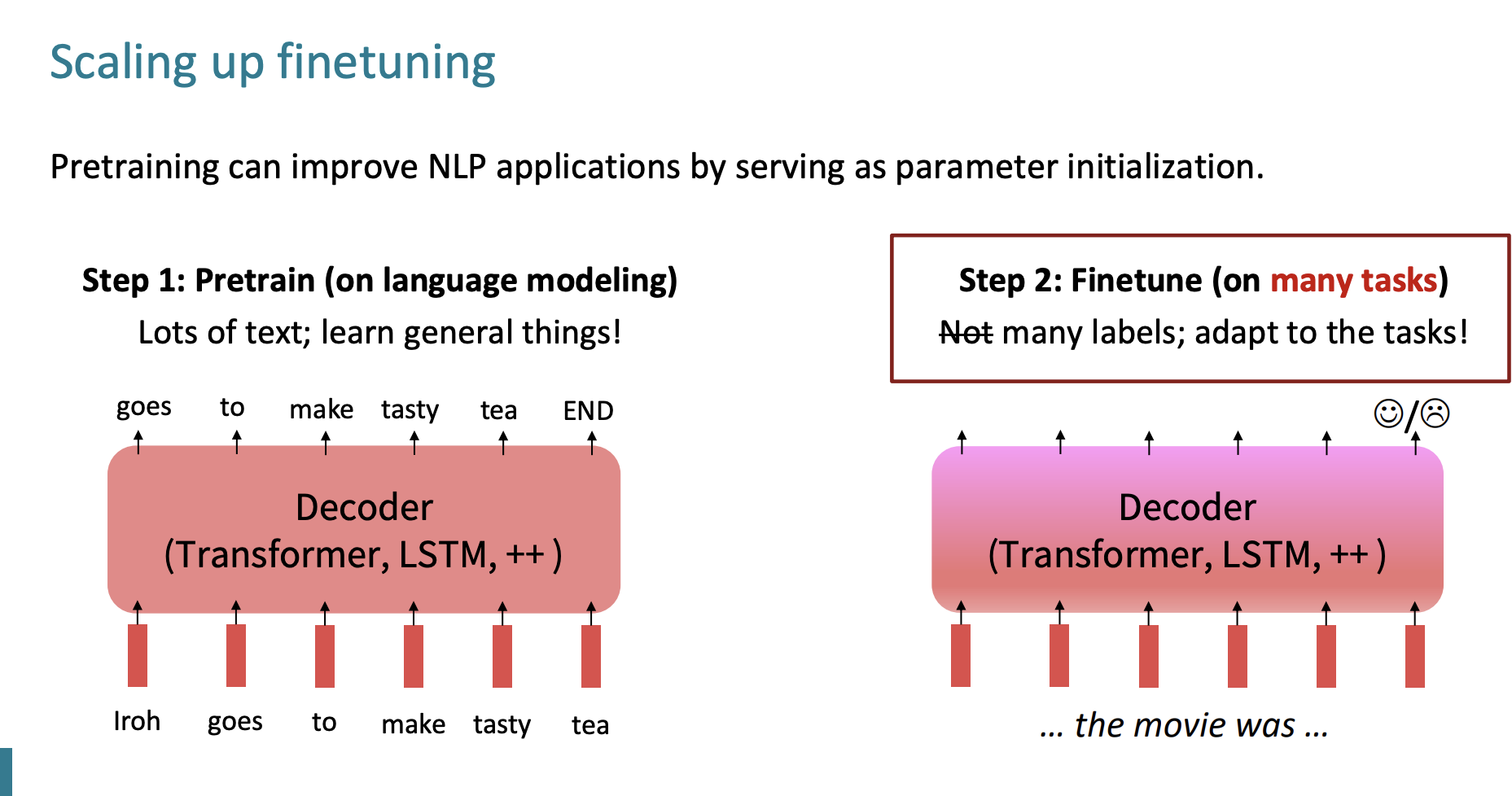
이전에 Finetuning에 대해서 알아봤는데, 그때는 적은 labels에 대해 미세조정을 했다면 이번엔 many labels에 대해 미세 조정을 하는 것이 다른 점이다.
그럼 어떤 labels을 모으는 것일까?
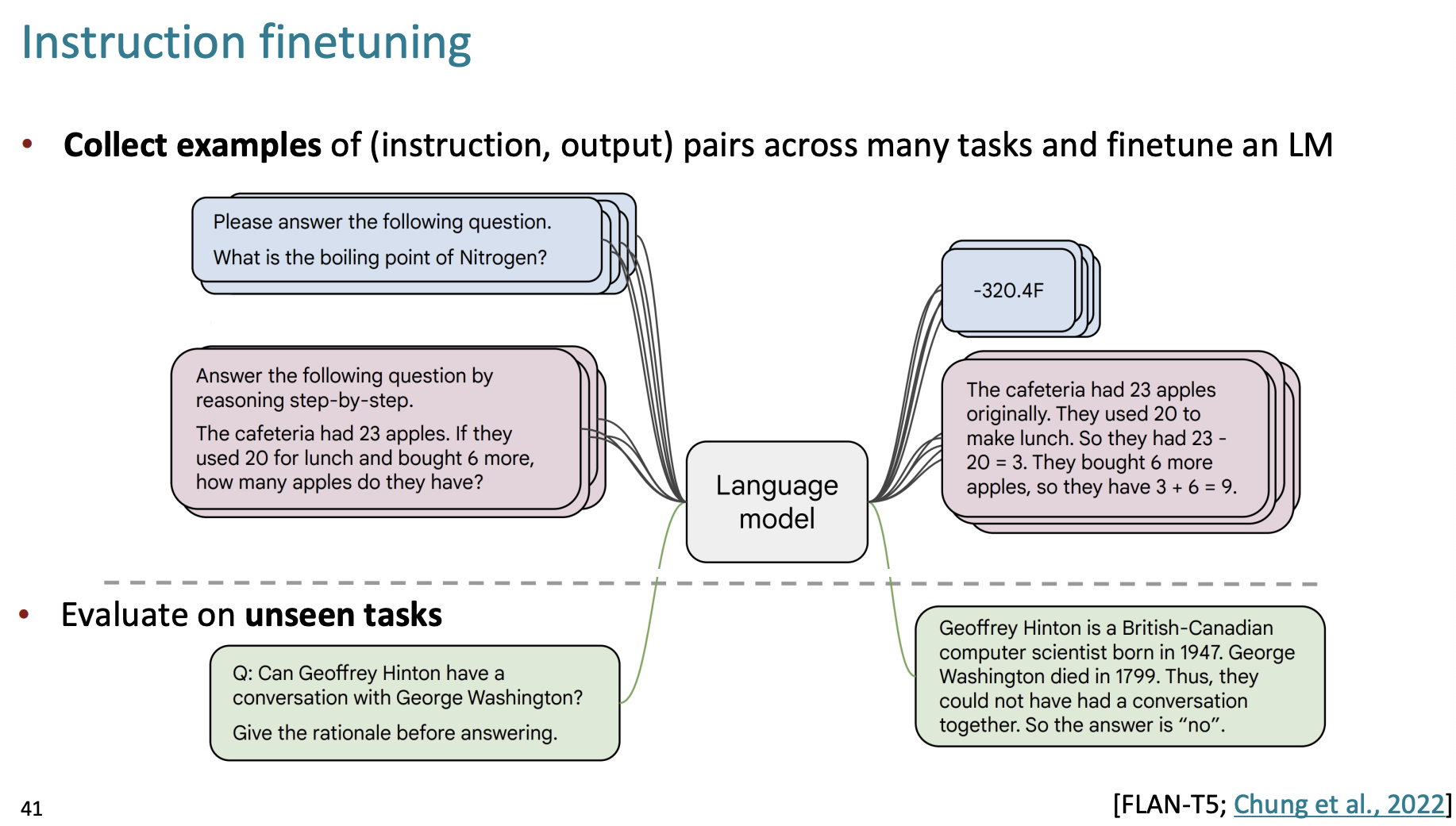
정말 많은 도메인에 대해서 질문-답변 pair 들을 모아서 LM에 파인튜닝을 하는 것이다.
그리고 보이지 않은 작업들에 대해서 평가하는 것이다.
Asid
LM을 측정하는데 새로운 벤치마크가 생겼다.
바로 "Massive Multitask Language Understanding (MMLU)"이다.
MMLU는 인공지능이 다양한 종류의 언어 이해 작업을 수행할 수 있도록 하는데 중점을 둔다.
또 다른 것은 BIG-Bench이다.
"Beyond the Imitation Game: A Benchmark for Natural Language Understanding"의 약자로, 대규모 언어 모델의 능력을 평가하기 위해 만들어졌다.
BIG-Bench는 10억명의 작성자가 만들었다. 그만큼 엄청 큰 벤치마크이며 다양한 종류의 작업과 도메인을 포함한다. 또한 연구자들이 계속 새로운 작업이나 데이터셋을 추가해서 확장할 수 있도록 개방적으로 설계했다.
한계
그럼 사람의 작업에 맞게 대규모의 정보로 Finetuning을 하는 것의 한계점은 무엇일까?
우선 정보가 정확하지 않을 수 있다는 점이다. 다양한 사람들은 다양한 생각을 하기 때문에 질문에 대한 정답이 모두 다를 수 있다.
그리고 인간의 라벨을 얻는 것은 매우 어렵고 annoying한 일이다. 그리고 매우 많은 비용이 든다.
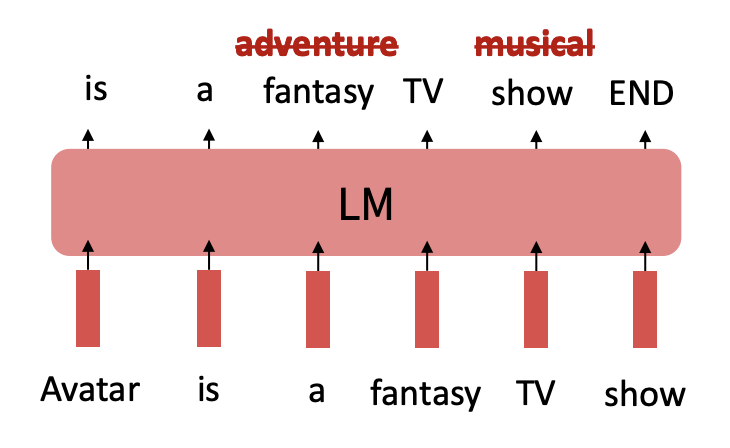
그리고 task는 창의적이고, 열린 결말의 창작 활동에 대해 정다이 없는데 이러한 일에 대해서는 잘 수행을 할 수 없다는 점.
또 다른 문제는 아바다가 fantasy가 아니라 adventure라고 해서 크게 문제될 것은 없지만, show를 musical로 바꾸면 완전히 거짓이 되는데 이 둘의 손실에 대해서 동등하게 처리한다는 점이 바로 단점이다.
Reinforcement Learning from Human Feedback(RLHF)
강화학습은 인간의 피드백을 바탕으로 LM을 강화시키는 것이다.
일단 우리는 어떤 언어 모델이 "요약"을 수행하도록 하자.

만약 모델이 잘 수행했다면, 인간은 점수를 높게 주고, 잘 수행하지 않았다면 점수를 낮게 주는 것이다.
Reinforcement learning(RL)은 최근 들어 많이 연구되는 분야이다.
그럼 인간의 선호도를 어떻게 최적화할까? (인간의 선호도가 높을 수록 좋은 것)
gradient ascent를 수행해보자.
아주 간단하게 Policy gradient에 대해 배워보자. 여기서는 겉핥기식으로만 다룰 것이며 더 깊은 내용은 cs234을 참고하자.
일단 우리는 인간의 선호도를 최적화하기 위해서 LM의 파라미터인 를 조정한다.
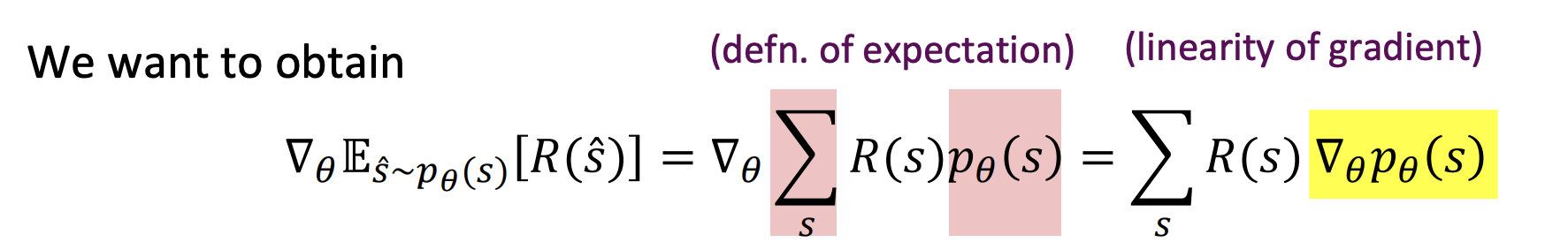
그리고 gradient는 chain rule에 따라 구한다.
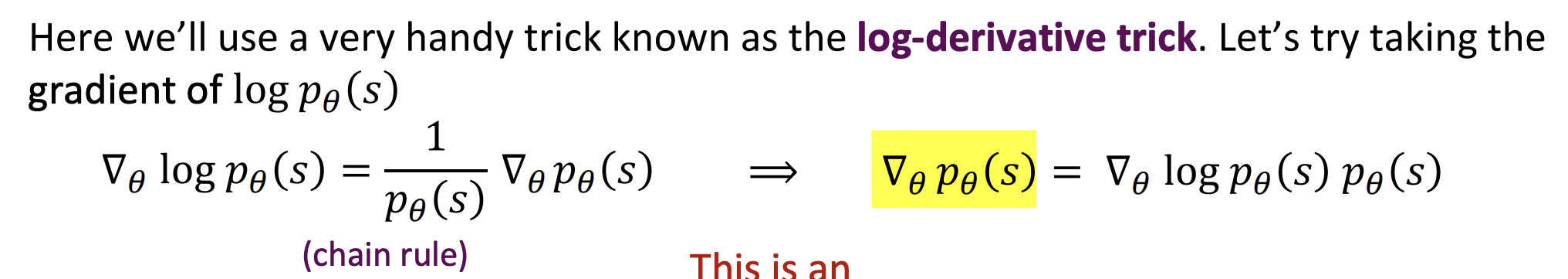
이것을 정리하면,
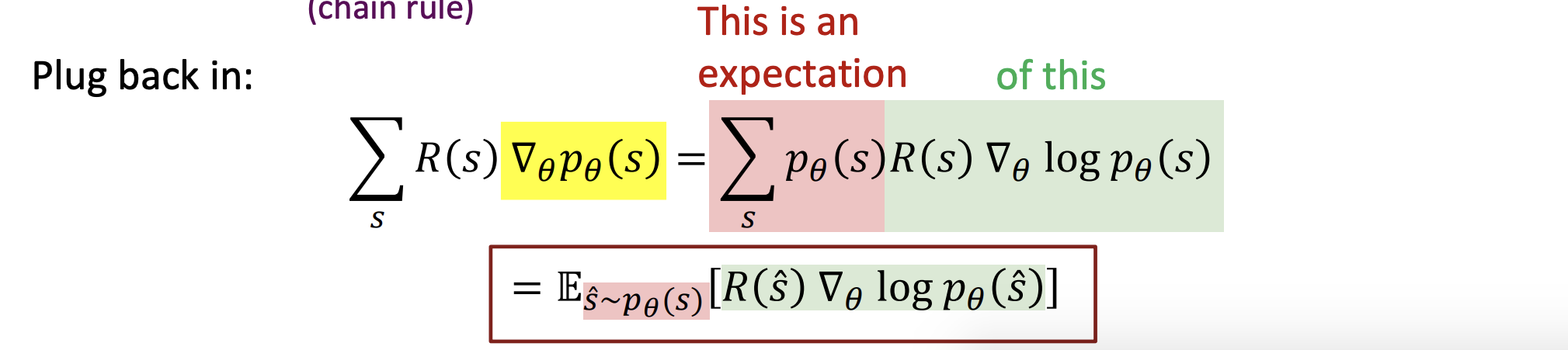
그리고 몬테 카를로 샘플로 어쩌구 이거를 이렇게 정리할 수 있다.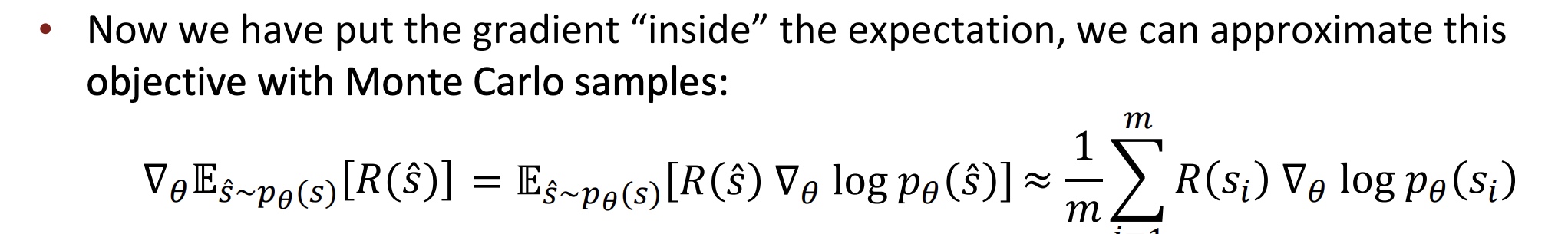
(사실 이건 이해 안됨)
결과적으로 update rule이 만들어진다.

만약 R이 +++ 라면 기울기는 를 늘리는 방향으로,
R이 ---라면 기울기는 를 줄이는 방향을 가리킬 것이다.
이는 강화학습이 좋은 행동은 강화사키고 더 많이 일어나게끔 학습시키는 직관과 일치한다.
이러한 학습 방법에는 무슨 문제점이 있을까?
첫번째, 사람이 판단하는 것은 비용이 비싸다.
solution은 모델이 사람의 선호도를 측정하는 대신 그들의 선호도를 측정하는 것이다.
두번째, 사람의 판단은 noisy하고 miscalibrated하다. 그러니까 사람마다 판단이 다르고, 어떤 선호도를 가지는지 다르지 때문에 여러 사람들의 선호도를 조사해서 신뢰가능한 것을 선택해야 한다.
Reward Model
새로운 개념이 등장하는데, 바로 보상 모델이다.
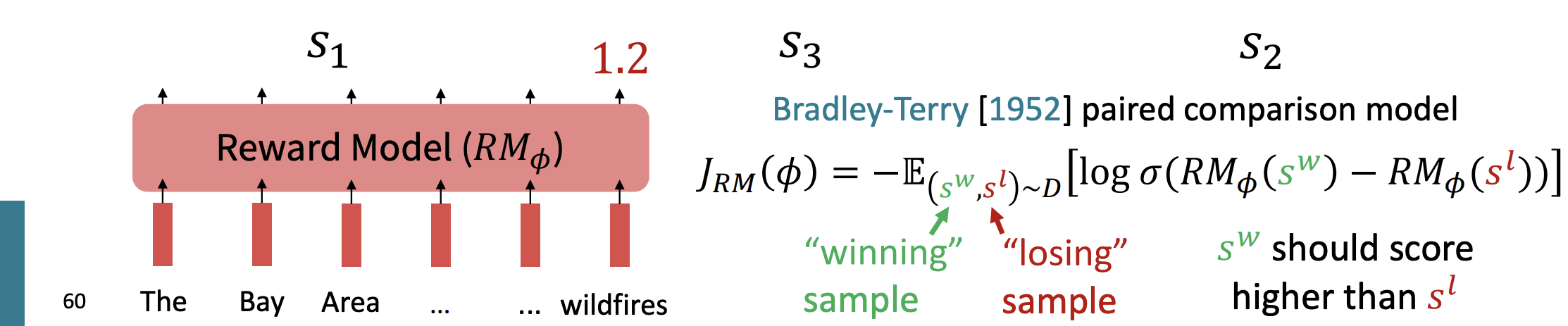
아까 여러 사람들의 선호도를 조사해야 한다는 것처럼, 우리도 언어 모델들의 여러 샘플들을 비교해야한다.
이때 가장 우수한 샘플과 가장 안좋은 샘플을 빼고 로그를 취한 것을 손실함수라고 하자. 보상 모델의 손실함수가 바로 위 공식이다.
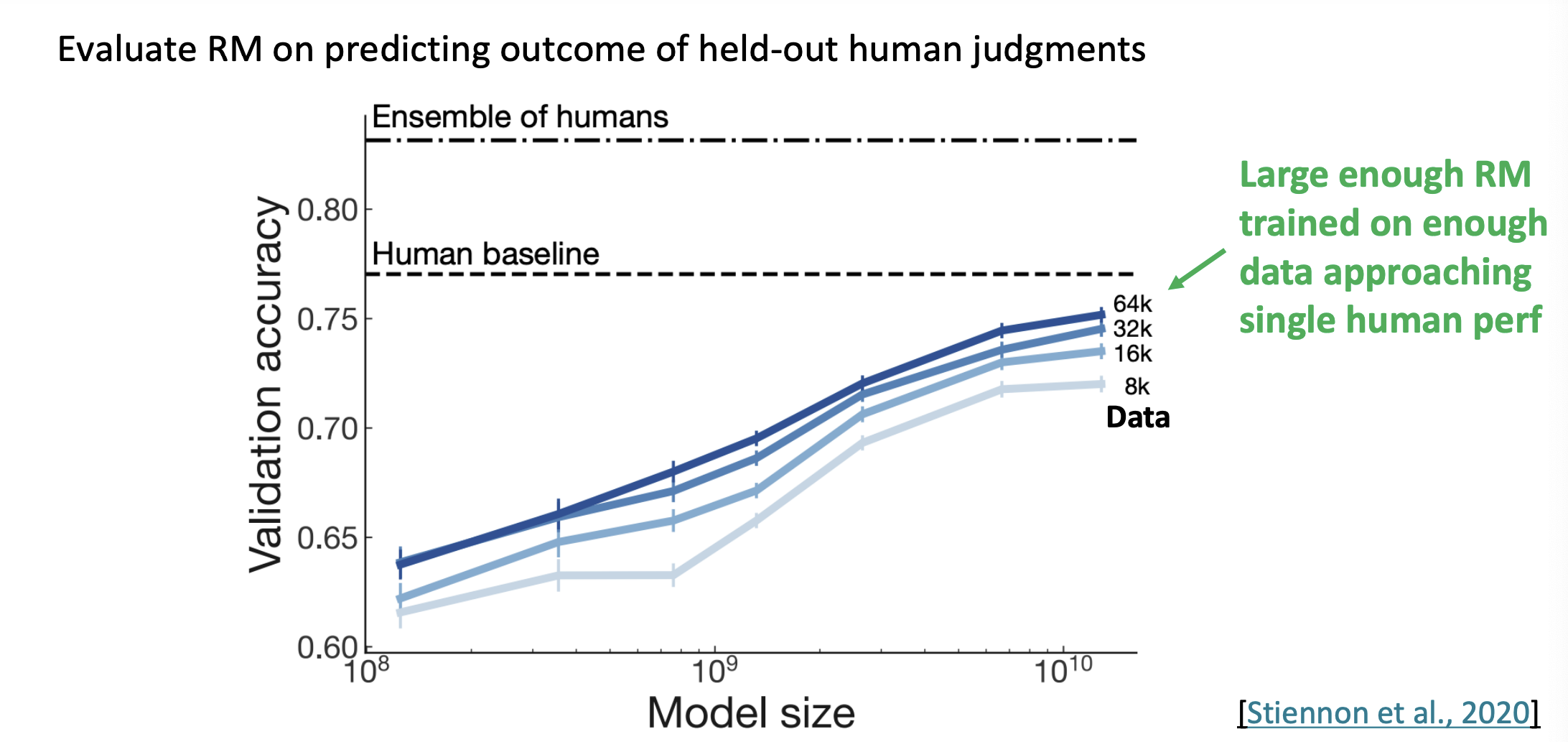
그래서 RM을 평가해보면 많은 데이터를 가진 RM일수록 한 사람의 선호도에 접근한다.(사람과 비슷한 성능을 가진다.)
우리는 강화학습하기 전에 필요한 것들을 모두 계산했다.
RLHF
우리가 사전에 훈련한 모델을 pretrained LM 즉 이라 하자. 그리고 보상 모델을 이라하자. 이는 LM의 결과에 대한 스칼라 보상을 출력한다. 인간의 비교들을 데이터셋으로 해서 훈련한 것이다.
강화학습 모델을 이라 하고 파라미터 를 우리가 최적화하고 싶은 것이라 하자.
다음의 식을 최적화하자.
만약 의 값이 보다 크다면 패널티가 되는 것이다.
pretrained 된 model(instruction-finetuned)에 대해서 너무 멀리 떨어지면 패널티를 주어서 방지하는 것이다. 이는 와 의 쿨백-라이플러 발산이라 한다.
이 식을 자세히 보면,
- R(s)는 주어진 s에 대한 최종 리워드를 나타낸다. 얼마나 바람직한 결과를 얻었는지 수치로 나타낸다.
- 는 학습된 리워드 모델을 나타낸다. 상태 s에 대한 기대 리워드를 계산한다.
- 는 정규화항의 가중치를 조절해서 얼마나 많이 정규화를 할지 정한다. 여기서는 얼마나 많이 패널티를 줄 것인가를 정한다.
- 는 강화학습과정에서 사전훈련된 행동 경향에서 벗어나는 정도를 측정한다. 로그의 내부값이 1미만이면 음수가 되고 앞의 음수를 통해서 R(s)값은 더 커지게된다.
- 결과적으로 2개의 항으로 이루어진 것이고, 첫번째 항은 리워드 모델을 통해서 (잘했다~잘했다~하면 더 잘하게 하는 모델) 강화학습이 되도록 하지만 두번째 항을 통해서 너무 강화학습 자체가 과적합되도록 하는 것을 막는다. 일종의 두항은 서로 트레이드 오프 관계이다.
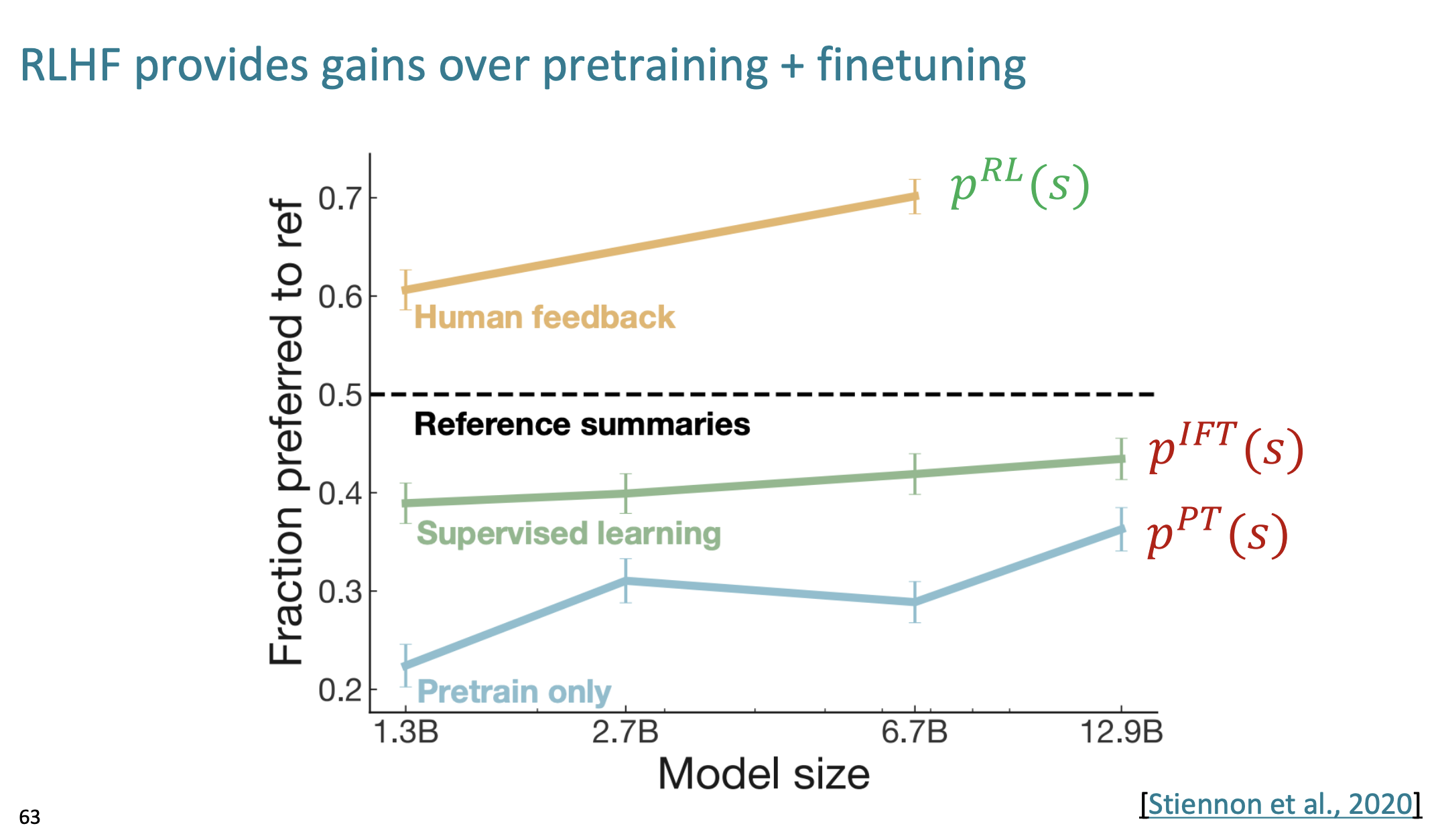
그럼 강화학습의 효과는 어느정도일까?
오직 pretrained된 모델과 지도학스된 모델과 비교해서 좋은 성능을 보여준다.
InstructGPT
OpenAI가 개발한 GPT-3 모델의 변형이다.
사용자의 지시(Instruction)에 더 잘 응답하도록 훈련된 버전이다.
어떻게 train을 했을까?
우선 첫번째, Supervised Fine-Tuning(SFT)을 진행했다. 인간이 의도하는 policy를 학습시키기 위해서 인간 Labeler가 30k정도 되는 데이터를 선별해서 Pre-trained LM을 Finetuning했다.
두번째, Reward Model.
인간 Labeler는 첫번째 단계에서 Finetuning된 모델이 생성한 답변 중 인간 Labeler들은 뭐가 더 좋은 답변인지 점수를 매겨서 데이터를 수집한다. 이러한 데이터는 다시 reward model을 학습한다.
세번째, PPO를 이용해서 SFT 모델을 강화학습한다.
PPO는 Proximal Policy Optimization이다. SFT 모델에 여러 사용자 입력을 주고 PPO는 output을 만든다. 그리고 reward model은 해당 output에 대한 점수를 계산한다. 그 reward는 다시 PPO를 발전시키기 위해 사용된다.
2,3 단계는 반복적으로 시행된다고 한다.
ChatGPT
ChatGPT는 어떤 훈련 방식을 사용하는지, 모델 사이즈는 무엇을 사용하는지, 데이터는 무슨 데이터를 사용하는지 모두 비밀이다. 공개한 것은 "Instruction finetuning을 사용했고, RLHF을 사용했다."라는 것이다. 하하
한계점
그럼 강화학습의 장단점은 무엇일까?
- 라벨링된 데이터를 통해서 일반화할 수 있다는 점이다.
- 하지만 라벨링된 데이터를 얻기는 참 쉽지 않다.
또한 "인간의 선호도"라는 것은 Unreliable! 하다.
예를 들어서 어떤 자동차 게임을 한다고 하자.
자동차 트랙을 빨리 통과할 수록 더 좋은 점수를 얻는다.
동시에 자동차 드리프트를 많이 할수록 더 좋은 점수를 얻는다.
강화학습된 모델한테 게임을 시켜봤더니,
트랙을 운전해서 가기는 커녕 드리프트만 주구장창한다는 것이다.
이는 "Reward hacking"이라 한다. 보상을 사용자의 의도에 따라 맞게 얻는 것이 아니라 다른 방식으로 얻어 생기는 문제이다. 이는 RL에서 매우 흔한 문제이며, 사용자의 선호도를 단순히 숫자화한다는 점에 문제가 생긴 것이다.
또한 챗봇은 그럴듯한 느낌의 답변을 하면 사용자의 선호도가 높기 때문에 도움이 되지 않아도 그럴듯한~ 답변을 하는 경우가 많다고 하고, 이는 Hallucinations(환각) 증세를 만들게한다.
마지막으로, 인간의 선호도 또한 확실하게 신뢰할 수 없는데, 모델의 선호도는 얼마나 더 unreliable할까?
What's next?
강화학습 분야는 정말 매우 빠르게 발전하고 있어서 내년에 10강에서는 전혀 새로운 것을 배울 수 있다.
아직 강화학습의 분명한 한계는 사람의 힘이 필요하기 때문에 매우 Expensive 하다는 점이다.
최근 연구는 그래서 데이터를 수집하는데 너무 비싼 비용이 드니까 AI를 통해 data를 수집하거나 Feedback하려는 연구도 진행이 되고 있다.
아직도 size, hallucination과 같은 많은 한계점이 존재해서 풀어야할 숙제가 아주 많다!
