강의 자료
Lecture 9
9번째 수업이다.
이번 수업 시간에는
- A brief note on subword modeling
- Motivating model pretraining from word embeddings Model
- pretraining three ways
- Decoders
- Encoders
- Encoder-Decoders
- Interlude: what do we think pretraining is teaching?
- Very large models and in-context learning
에 대해 알아보자.
Subword modeling
단어의 구조와 하위 단어 모델에 대해 알아보자.
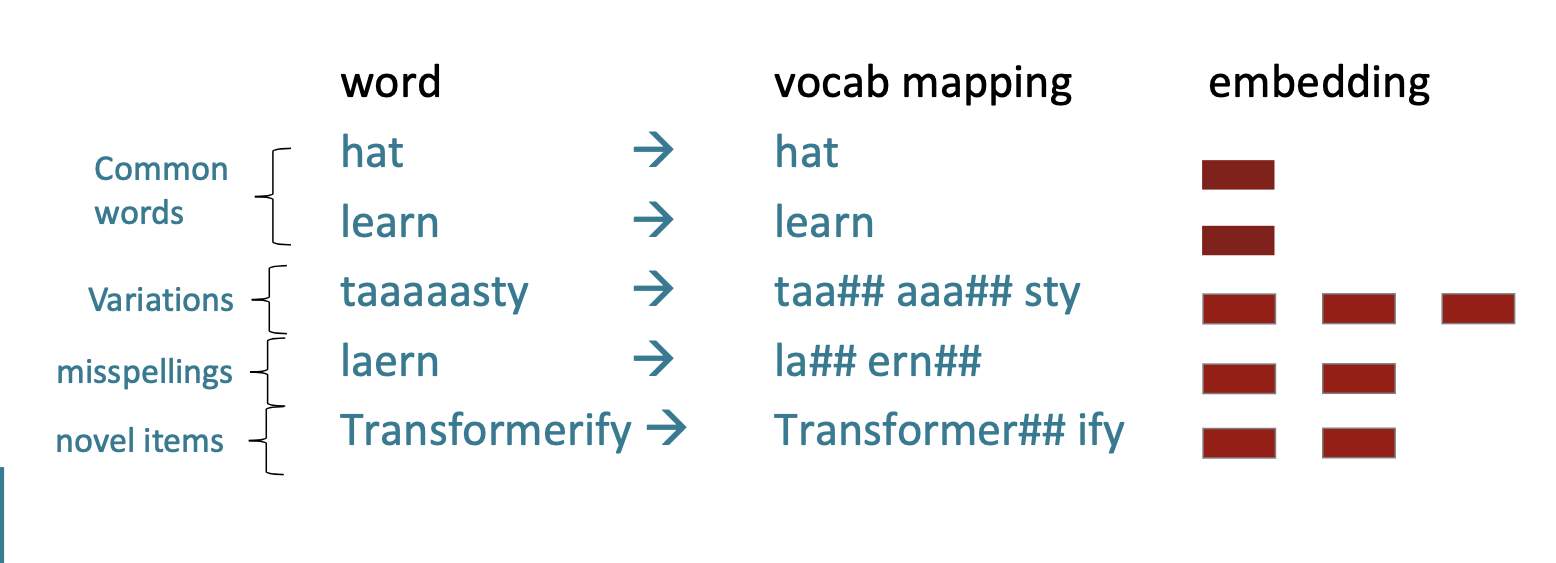
우리는 항상 유한한 단어장을 가질 수 밖에 없다.
따라서 우리의 단어장에 없는 단어가 있을 수 있다.
우리의 단어장에는 단어->벡터 이렇게 존재한다.
만약 단어장에 없는 단어가 있다면, 어떻게 벡터를 만들어내야 할까?
예를 들어서
taaaaasty 와 같은 변형된 단어,
laern 과 같은 오타가 있는 단어
Transformerify 같이 새로운 단어가 있다면 우리는 일단 UNK 라는 집합에 넣는다.
The byte-pair encoding algorithm
이를 해결하는 방법이 있다. 바로 Byte-pair encoding algorithm이다. 줄여서 BPE라고 한다.
4개의 단계로 진행된다.
- 초기 데이터 준비
- 빈도 수 계산
- 가장 빈번한 쌍 병합
- 반복
예를 들어서 'aaabdaaabac'라는 단어를 인코딩 해보자.
- 여기서는 모두 개별 단어로 취급한다. 즉 a,a,a,b,d,a,a,a,b,a,c 가 된다.
- 인접한 단어들을 묶어서 빈도수를 계산한다.
a,a : 4
a,b : 2
b,d: 1
d,a : 1
b,a : 1
a,c : 1 - 여기서는 a,a가 가장 많이 나타가기 때문에 a,a를 z로 대체한다.
변환하면
zabdzabac가 된다. - 위 과정을 반복한다. 그 다음 빈번한 단어 쌍은 a,b이므로 a,b를 x로 대체하는 등 한다.
이 과정을 통해서 문자열을 더 짧게 만들 수 있다.
단어장에 없는 단어를 위 방법을 통해서 단어장에 있는 단어들로 나눌 수 있다.
당연하게도 하위 단어가 없을 수록 더 좋다.
Pretraining whole models
지금까지 우리의 문제는 무엇이냐하면
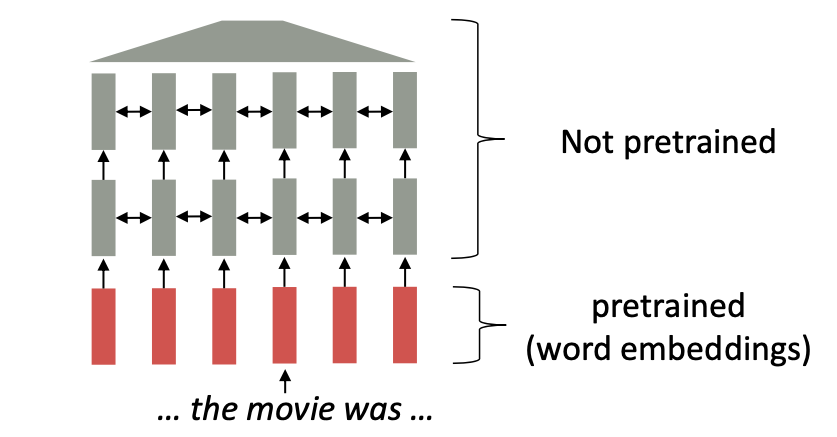
단어장의 단어에는 할당된 embedding이 이미 존재했다는 것이다. -> pretrained word embeddings
Word2Vec은 자연어 처리에서 단어를 벡터로 변환한다. 이 모델은 비슷한 의미를 가진 벡터끼리 가까운위치에 배치되도록한다. 하지만 한계가 있었다. 한 번 단어의 벡터(embedding)이 생성되면 그 단어의 문맥이 고려되지 않는 다는 점이다.
Word2Vec 모델에서 단어의 벡터는 단어가 다양한 문맥에서 사용되어도 그 변화를 반영하지 못한다. record는 '기록'이라는 명사와 '기록하다', '녹음하다' 등의 동사도 있다. 이러한 의미를 구분짓는 것에 한계가 있다.
이러한 단점은
- 질문 답변과 같은 다운스트림 업무를 하기 위해서는 충분히 문맥적인 측면도 학습해야하는데 할 수 없다는 점.
- 초기의 파라미터는 대부분 랜덤하게 초기화된다는 점이다.
현대 NLP에서는 전체 모든 파라미터를 pretraining한다.
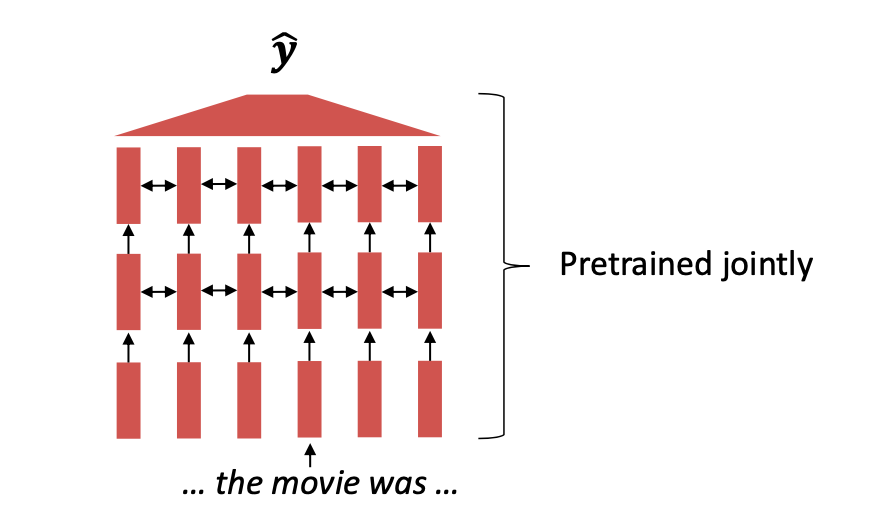
이는
- representations of language
- parameter initializations for strong NLP
models. - Probability distributions over language that we can sample from
들을 강력하게 구축하는데 매우 효과적이다.
Reconstructing input
아래는 우리가 input을 다시 만들어서 pretraining 을 하는 방법들이다.
• Stanford University is located in __, California. [Trivia]
• I put _ fork down on the table. [syntax]
• The woman walked across the street, checking for traffic over ___ shoulder. [coreference]
• I went to the ocean to see the fish, turtles, seals, and _. [lexical semantics/topic]
• Overall, the value I got from the two hours watching it was the sum total of the popcorn and the drink. The movie was _. [sentiment]
• Iroh went into the kitchen to make some tea. Standing next to Iroh, Zuko pondered his destiny. Zuko left the ____. [some reasoning – this is harder]
• I was thinking about the sequence that goes 1, 1, 2, 3, 5, 8, 13, 21, ____ [some basic arithmetic; they don’t learn the Fibonnaci sequence]
Pretraining through language modeling
언어 모델을 통해서 사전 학습을 해보자.
그 전에 일단 언어 모델이 하는 것이 뭐였을 까?
바로 다음 단어를 확률 분포를 통해 예측하는 것이다.
언어 모델을 통해서 사전학습 하는 것은 다음일을 하는 것이다.
- 엄청 많은 양의 텍스트를 통해 신경망을 언어모델로서 수행하도록 학습시키는 것이다.
- 네트워크 파라미터들을 저장한다.
우리는 사전 학습을 진행하면 이제 Finetune을 한다.
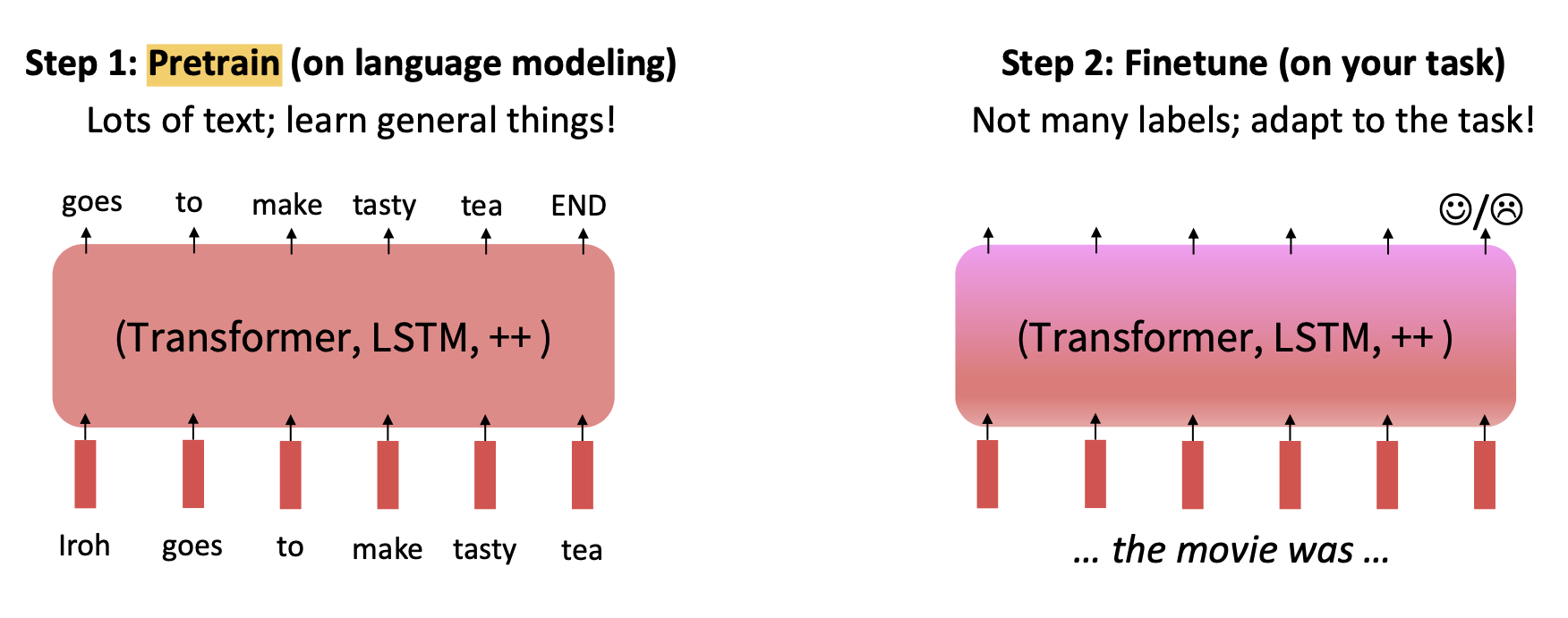
사전 학습은
- 엄청 많은 텍스트에 대해 학습
- 매우 general 한 것들을 학습
한다면
FineTune은
- 그렇게 많지 않은 라벨에 대한 학습
- task에 적합한 학습
을 진행한다.
왜 사전학습 -> 파인튜닝 방법으로 진행하는 것일까?
사전 학습 과정에서 모델은 매우 크고 다양한 데이터셋에서 학습된다. 사전 학습의 손실함수 은 일반적인 지식을 얻기 위해 계산된다.
파인 튜닝 단계에서 이미 사전 학습된 모델을 조금 더 특정한 작업이나 좁은 데이터 셋에 맞게 조정한다. 이때의 손실함수 은 이 특정 작업에 모델을 최적화하기 위해 계산한다.
이러한 방법은
- generalize well : 일반적인 지식을 바탕으로 쉽게 특정 작업에 적응할 수 있다. 사전 학습된 파라미터 에서 일반화가 잘 될 것이다.
- 효율적 : 이미 어느정도 최적화가 된 상태이기 때문에 더 빨리 그리고 효율적으로 학습이 가능하다.
Pretraining three ways - Encoders
모델을 사전학습시키는 방법 3가지가 있다.
- Encoder
- Encoder - Decoder
- Decoder
우선 첫번째로 Encoder 방법에 대해 알아보자.
Encoder는 양방향 문맥을 얻는다. 그래서 사실 언어 모델은 다음 단어를 예측하는 것인데, 양방향이기 때문에 우리는 이미 다음 단어를 안다.
그래서 단어의 input 중 몇개의 부분을 MASK 처리한다.
만약 가 x의 마스크된 버전이라면 우리는 를 학습하는 것이다.
이를 Masked LM이라 했다.
BERT
BERT: Bidirectional Encoder Representations from Transformers
위 방법으로 사전 학습된 트랜스 포머의 Encoder 아키텍쳐가 바로 BERT이다.
BERT의 사전학습 방법을 보자.
- 입력 단어의 80%를 MASK로 대체
- 입력 단어의 10%를 랜덤 단어로 대체
- 나머지 10%는 그대로 놔둔다.
왜 이렇게 학습했을 까?
바로 모델이 안주하지 않고 빈칸 단어를 강하게 잘 표현하기 위해 이렇게 학습시킨 것이다.
그리고 또 다른 학습 방법은 "두 문장이 연속하는 지" 이다.
BERT는 두 다른 문장이 연속하는지 학습했다.
-> 하지만 후속 논문에서는 이는 별로 필요하지 않다고 주장한다.
BERT는 두가지 모델이 있다.
- BERT-base : 12 layers, 768-dim hidden states, 12 attention heads, 110 million params.
- BERT-large : 24 layers, 1024-dim hidden states, 16 attention heads, 340 million params.
학습한 것은
- BooksCorpus(800 million words)
- English Wikipedia (2,500 million words)
이다.
사전 학습은 매우 비싸고 하나의 GPU에서 실행이 불가능한 반면, finetuning은 실용적이고 하나의 GPU에서 실행 가능하다.
그래서 보통 연구자들은 이미 개발된 BERT 모델을 사용하고 이를 특정 작업에 맞게 미세 조정하는 방법을 선호한다.
Limitations of BERT
BERT는 텍스트 생성에는 알맞지 않은 모델이다.
왜냐하면 일단 BERT는 양방향 문맥을 파악한다. 그래서 순차적인 텍스트를 생성하는데에 제약이 있다. 또한 BERT의 경우는 문장 내 단어를 이해하고 문장 간 관계를 파악하는 것에 중점을 둔다. 그래서 텍스트 생성을 목표로 한다면 gpt 같은 디코더 모델을 사용하는 것이 적절하다.
Parameter-Efficient Finetuning
Finetuning을 할 때도, 사실 전체 파라미터에 대해 Finetuning을 진행하는 것 보다 일부만 진행할 수 있다.
이 방법은
- 메모리 및 저장 공간을 절약
- 학습 시간 감소
- 오버 피팅 감소
- 유연성 및 적용성 증가
하다는 장점이 있다.
방법에는
1. Lightweight Finetuning
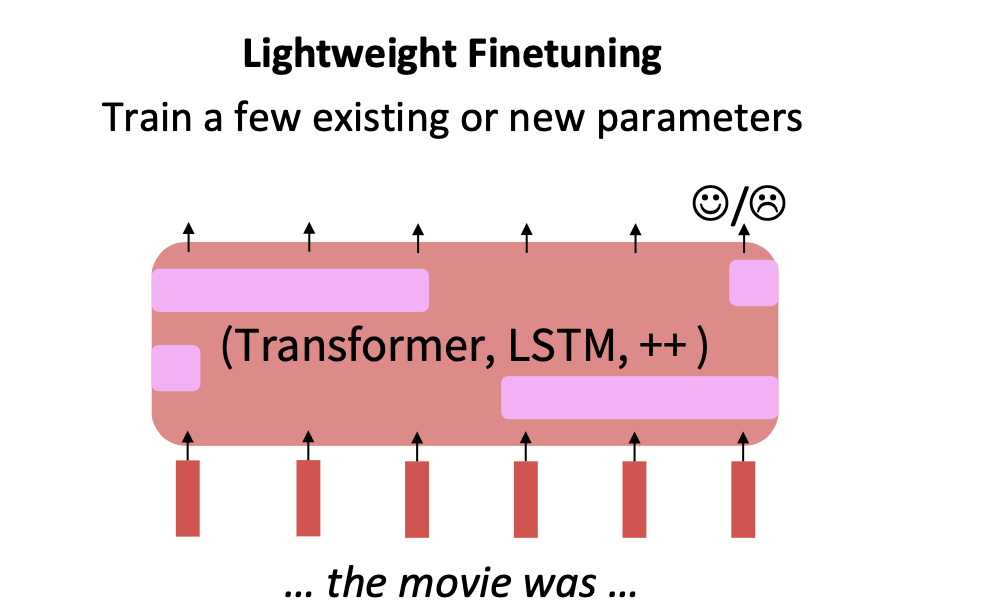
일부의 파라미터 또는 새로운 파라미터만 튜닝한다.
2. Prefix-Tuning
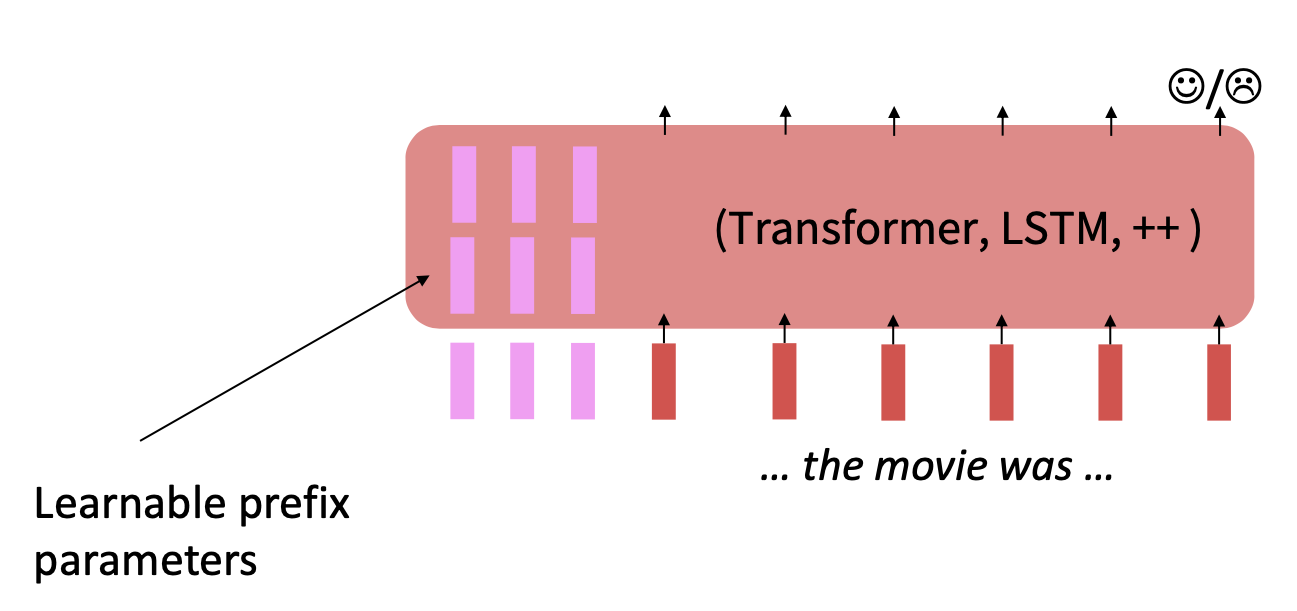
학습가능한 전치 파라미터를 추가한다.
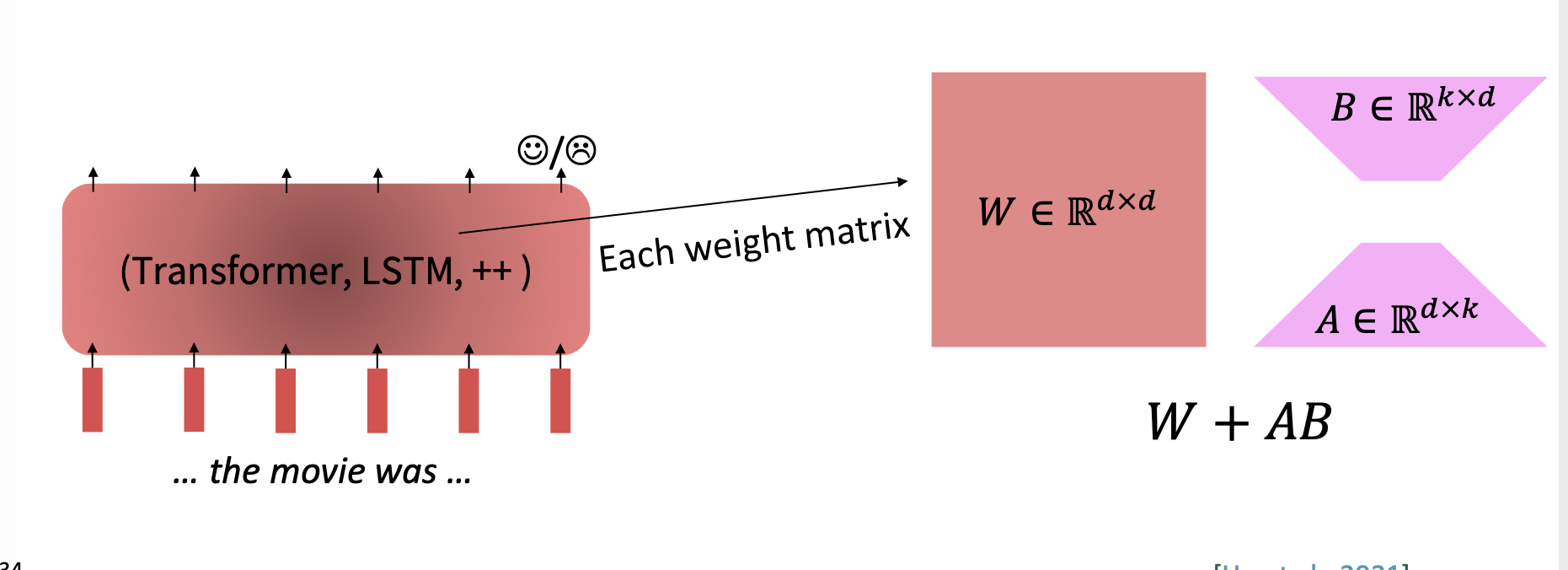
3. Low-Pank Adaptation
저차원으로 근사하고, 특이값 분해를 통해 파라미터의 수를 줄일 수 있는 방법이다.
Pretraining three ways - Encoder-decoders
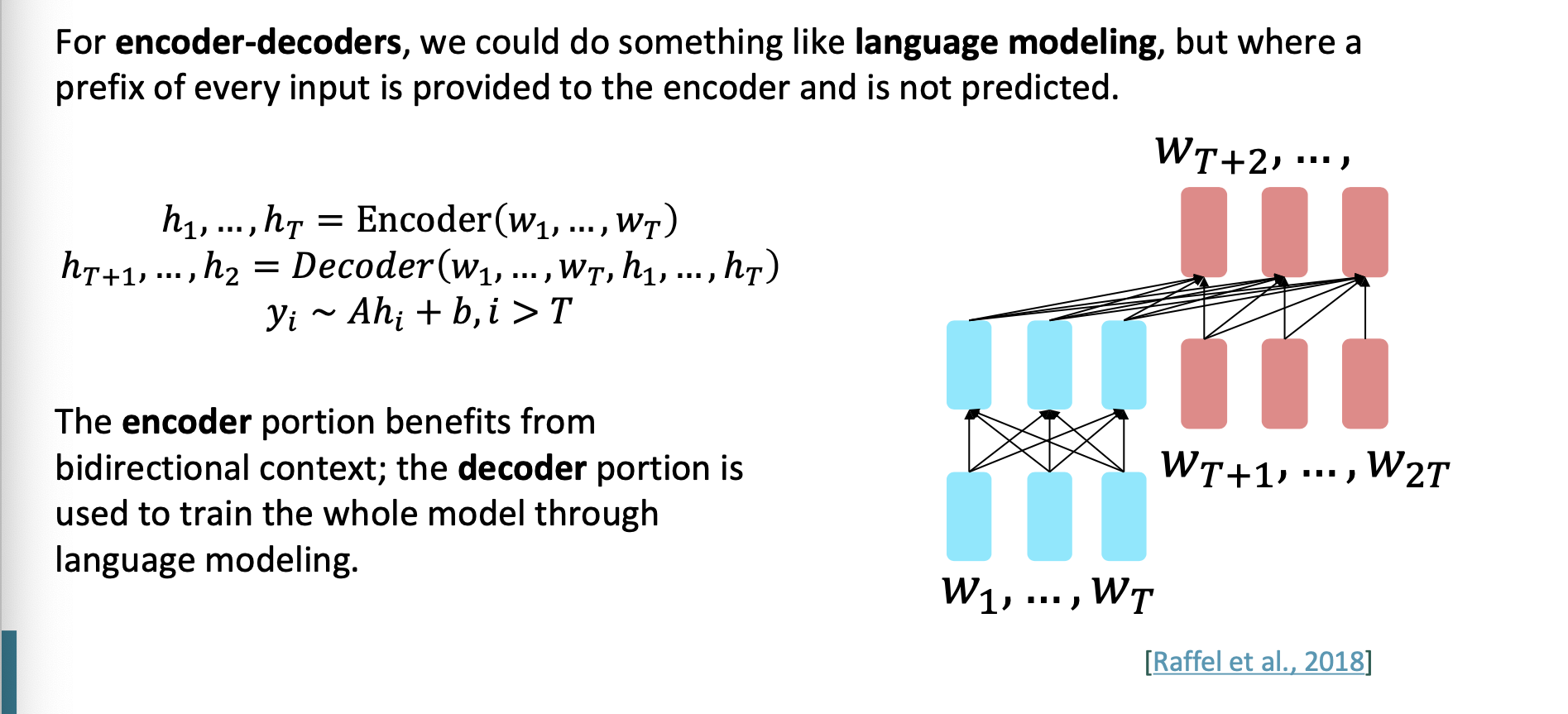
이제 인코더-디코더 구조를 보자.
입력의 일부는 encoder에 주어지고 이는 예측되기 위함이 아니다.
encoder의 부분은 양방향 문맥의 이점을 가지고 decoder의 부분은 언어모델링을 통해서 전체 모델을 학습시키는데 사용된다.
Span Corruption
Span Corruption을 하면 유용하다는 것을 알아냈다. 모델 이름은 T5이다.
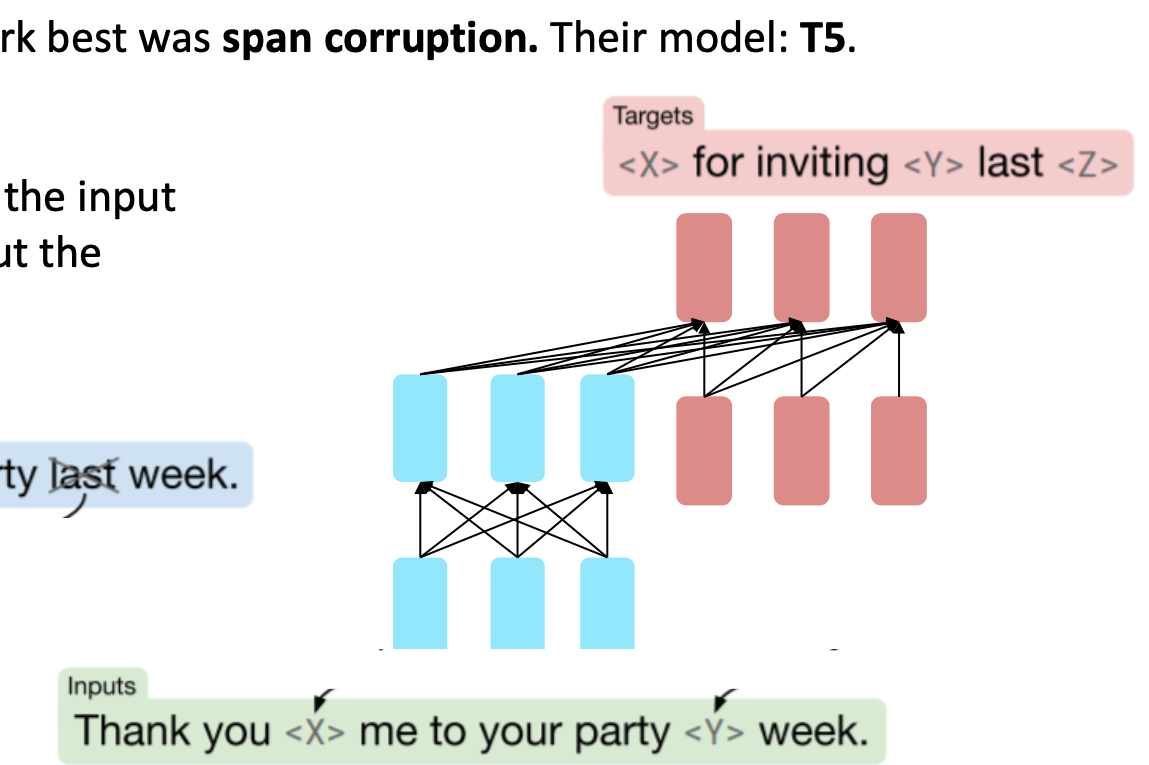
데이터 전처리 기법 중 하나이고 기본 아이디어는 텍스트에서 무작위로 선택된 연속된 단어들의 "span"을 마스킹하거나 변형 한다.
과정은 다음과 같다.
- 무작위 span 선택->길이는 얼마나 길지 모른다.
- 선택한 span을 마스킹, 또는 다른 방식으로 변형
- 이렇게 변형된 텍스트를 사용해 모델을 학습. 목적은 마스킹된 span을 예측하거나 텍스트의 의미를 파악하는 것.
-> 이렇게 학습한 모델 T5는 광범위한 질문에 대한 미세조정으로 답할 수 있게 됨.
Pretraining three ways - Decoders
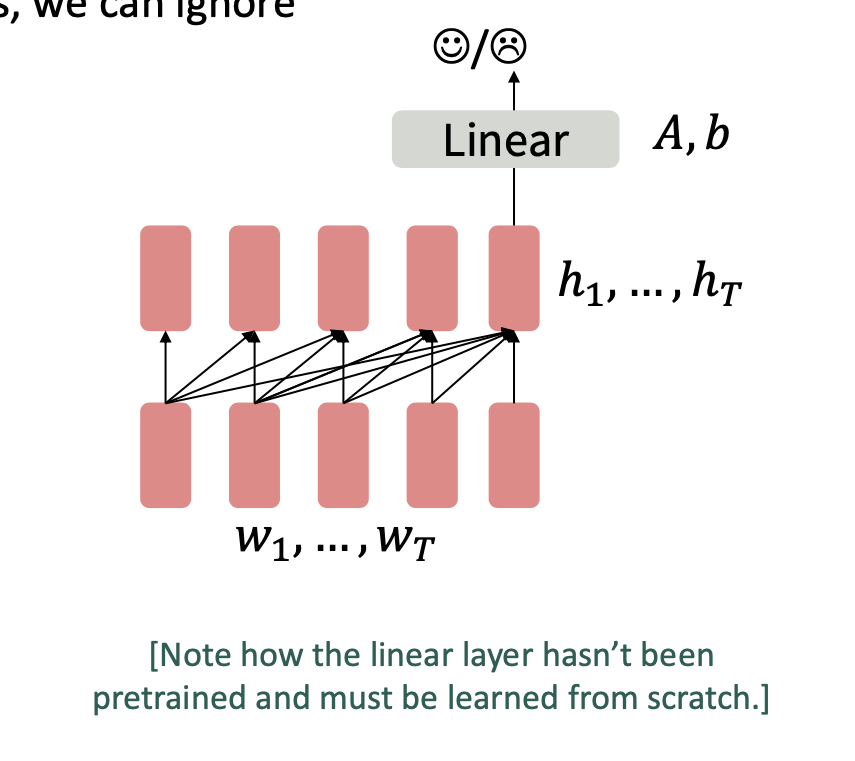
드디어 디코더 모델이다.
우리는 p(로 학습된 모델을 사용해 마지막 단어의 hidden state에 분류기를 학습시켜서 finetune 한다.
h1, ... hT = Decoder (w1,...,wT)
y ~ + b
A,b 는 모두 random 하게 초기화하고 다운스트림 작업으로 specified 된 것이다.
이러한 디코더 구조의 언어 모델은 대화, 요약 같은 일을 작업할 때 도움이 된다. 즉 output이 sequece 인 경우이다.
GPT
순서대로 GPT-1, GPT-2, GPT-3 간단 비교 해보자.
GPT-1
출시 : 2018년
파라미터 수 : 1억 1천만 개
특징 : 가장 초기 버전이다. 문장을 생성하는데 성능이 좋았지만 일관성이 부족하다는 면에서 아쉬웠다.
GPT-2
출시 : 2019년
파라미터 수 : 최대 15억개
특징 : GPT-1에 비해 큰 모델 크기를 가졌다. 더욱 정교하고 일관적이고 연속적인 문장을 생성했다.
GPT-3
출시 : 2020년
파라미터 수 : 1750억개
특징 : 이전 버전에 비해서 매우 큰 규모의 언어 모델이다. 특별한 미세 조정 없이도 특정 작업에 적응할 수 있는 능력을 지니게 되었다. 특정 작업에 높은 상호작용을 보여주었다. 하지만 매우 크기가 거져서 계산 비용이 매우 높아졌다.
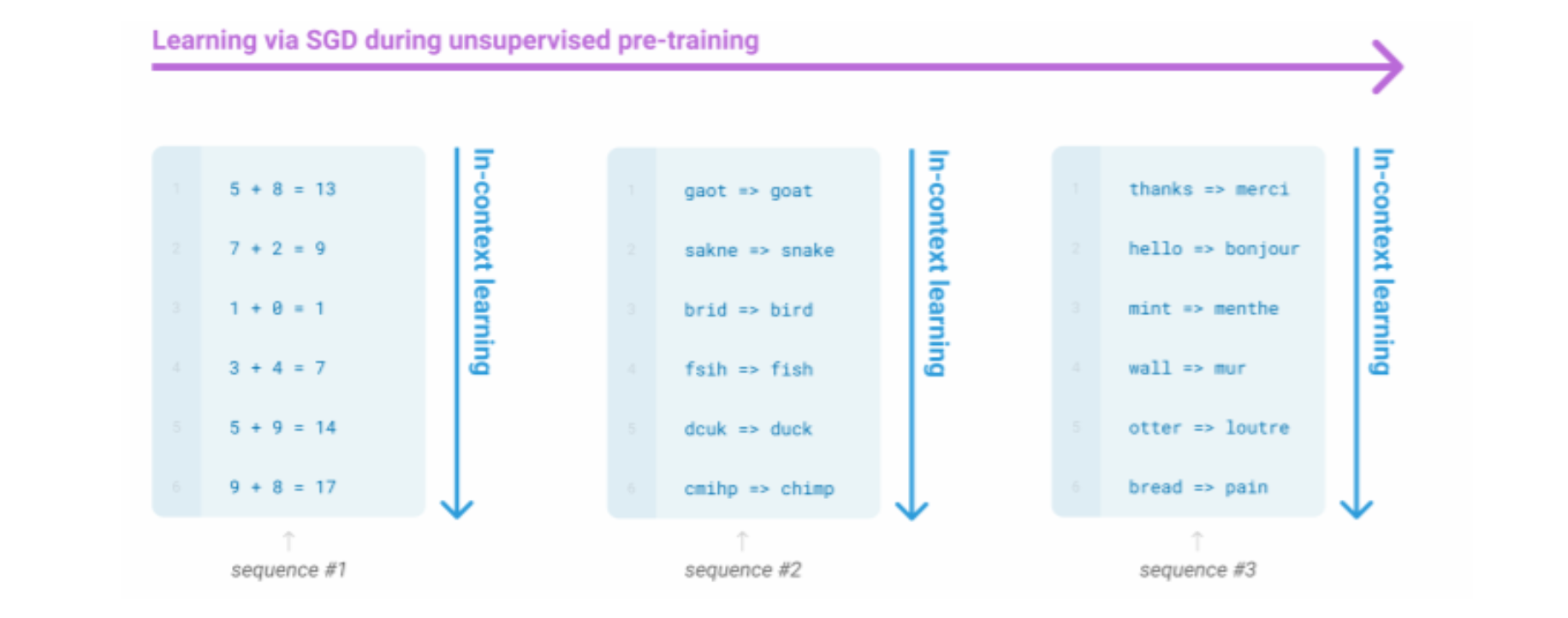
이처럼 아주아주아주 큰 언어 모델은 디코더 문맥안에서 제공하는 예시로부터 gradient step 없이 어떤 종류의 학습을 진행하는 것 처럼 보인다.
In-context learning은 Finetuning 없이 그저 조금의 예시를 알려주는 것이다. 작업에 대한 힌트를 제공하는 것이다. 이러한 힌트를 기반으로 모델은 학습을 하고 즉각적인 적응을 하여 사용자가 원하는 작업을 수행할 수 있다.
Scaling Efficiency
GPT-3의 파라미터 수가 1750억개로 매우 많다. 이것이 바로 가장 효율적인 파라미터의 수 일까?
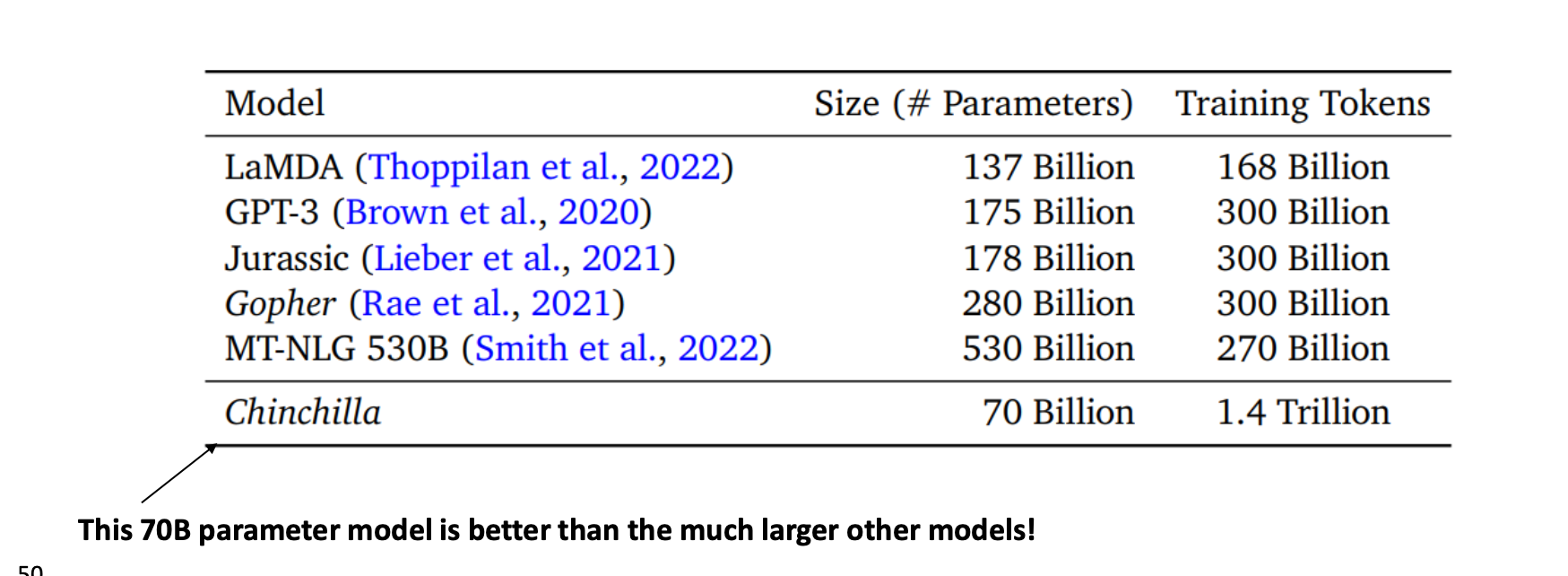
표를 보면, Chinchilla 라는 모델은 700억개이지만 다른 모델보다 더 좋은 성능을 보였다고 한다. 하지만 Training Tokens를 보면 훨씬 많은 토큰을 학습시켰다는 점이 존재했다.
Chain-of-thought
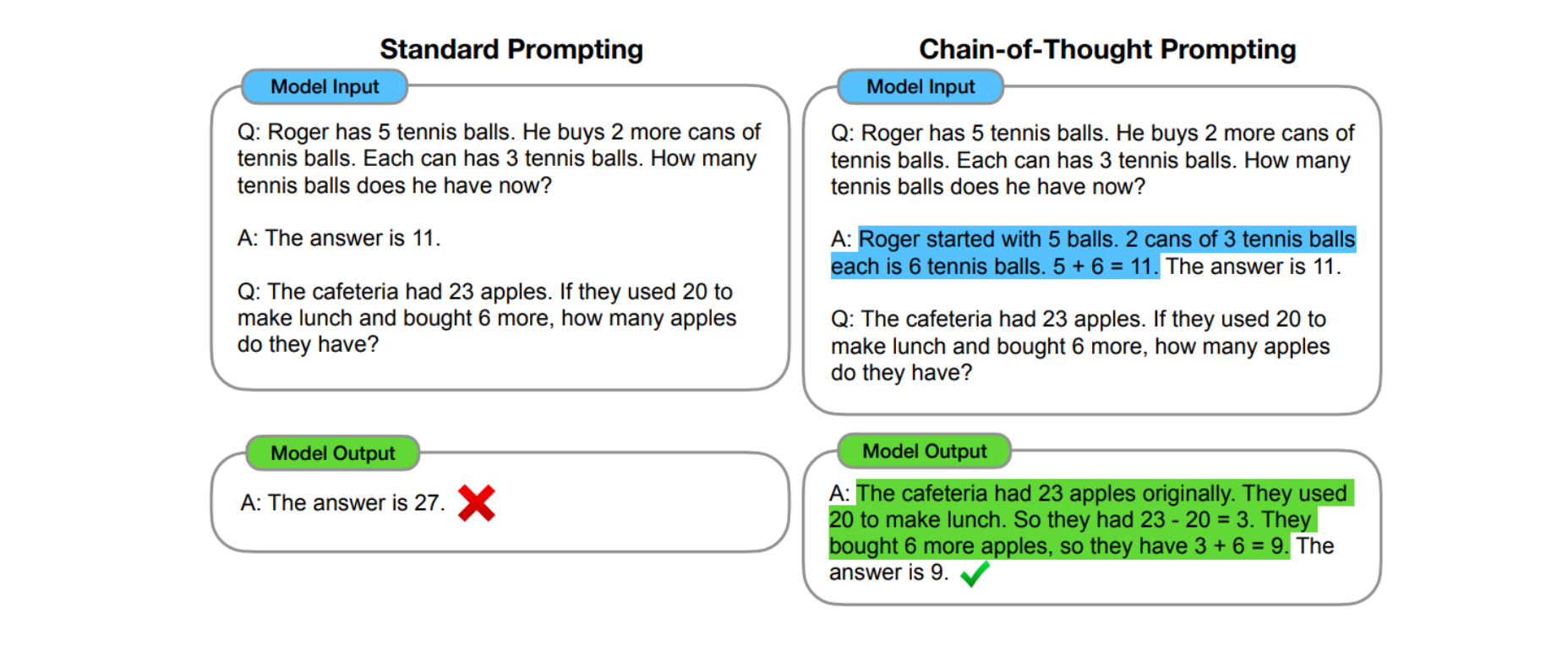
문제를 단계별로 분해하고 각 단계를 명시적으로 표현함으로써 모델이 최종 결론에 잘 도달하는 과정이다.
왼쪽 프롬프트를 보면 이전 A에 해당하는 답변은 어떻게 문제를 풀었는지에 대한 답이 없다.
그래서 output 또한 틀렸다.
하지만 오른쪽 프롬프트를 보면 이전 A에 해당하는 답변은 문제를 어떻게 풀었는지, 해결 방법을 제시했다. 이러한 올바른 해결방법을 통해 output 또한 올바르게 생성된 것을 확인할 수 있다.
이러한 방법은
- 모델이 잘못된 중간 단계를 거치거나 학습할 경우 최종 단계도 잘못될 수 있다.
- 또한 이러한 방법은 GPT-3와 같은 큰 언어 모델에서 가능하다.
끝!
