강의자료
실라버스에서는 이전 강의랑 순서가 바뀌었는데, 이게 유투브에서는 11강 이라고 한다.
Lecture 11
오늘 배울 내용은 다음과 같다.
1. What is NLG?
2. A review: neural NLG model and training algorithm
3. Decoding from NLG models
4. Training NLG models
5. Evaluating NLG Systems
6. Ethical Considerations
What is NLG?
NLG는 natural language generation이다.
NLP = Natural Language Understanding + Natural Language Generation 으로 나뉘어 있다.
NLG는 좀 더 유창하고, 일관적이고 유용한 언어를 생산하는 것에 중점을 둔다.
NLG의 종류는 다양하다.

기계 번역의 output은 다양하지 않은 특징을 가지고 있다.

그에 반해, 대화나

스토리 생성과 같은 작업은 output이 정해져 있지 않다.
우리는 이를 entropy로 점수화할 것이다.
엔트로피는 불확실성을 의미한다. 엔트로피가 높다는 것은 작업의 내용이 오른쪽을 향하고 있고, 더 불확실하다는 것을 의미한다.
A review: neural NLG model and training algorithm
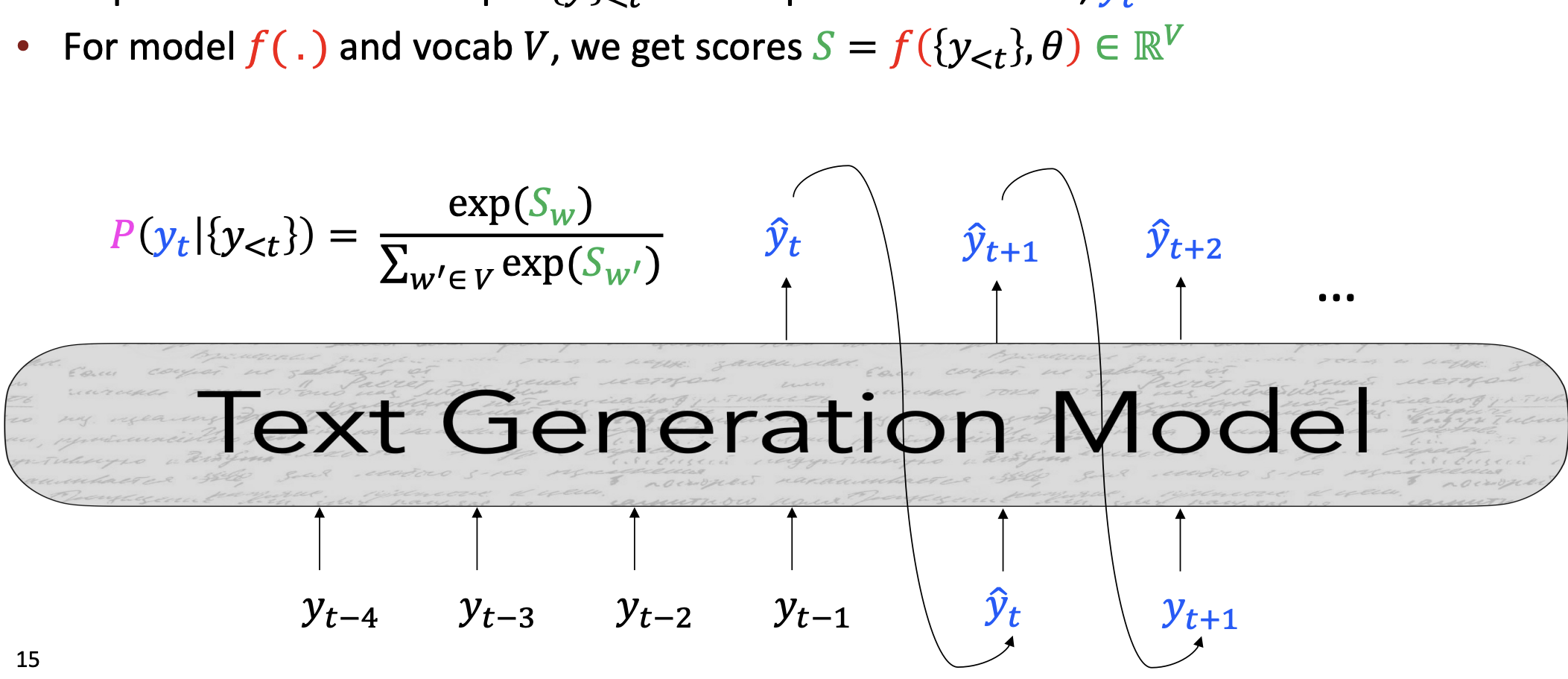
기계 번역과 같은 non-opened 한 task를 위해서, 우리는 encoder-decoder system을 사용한다.
스토리 생성과 같은 opened-ended tasks를 위해서는 autoregressive 한 generation model을 사용한다.
지금까지 배운 모델에서는 가장 가능성이 높은 단어를 선택해서 다음 input으로 넣었다. 이런 방식을 greedy 알고리즘이라 한다. 가장 확률이 높은 것을 하나 골라서 다음 선택의 input으로 넣는 것이다.
이런 방식 대신 우리는 더 성능을 좋게 하기 위해서 두가지 방식을 배울 것이다.
- Improve decoding
- Improve the training
Decoding from NLG models
디코딩, 다시 생각해보자.
우리는 두가지 방식으로 문장을 생성했다.
- Greedy Decoding
- Beam Search
이러한 최대 확률 디코딩은 low-entropy 에 해당하는 작업에는 적합하다.

하지만 Open-ended Generation에는 적합하지 않는다. 가장 잘 일어나는 현상은 바로 repetitive (반복)이다.
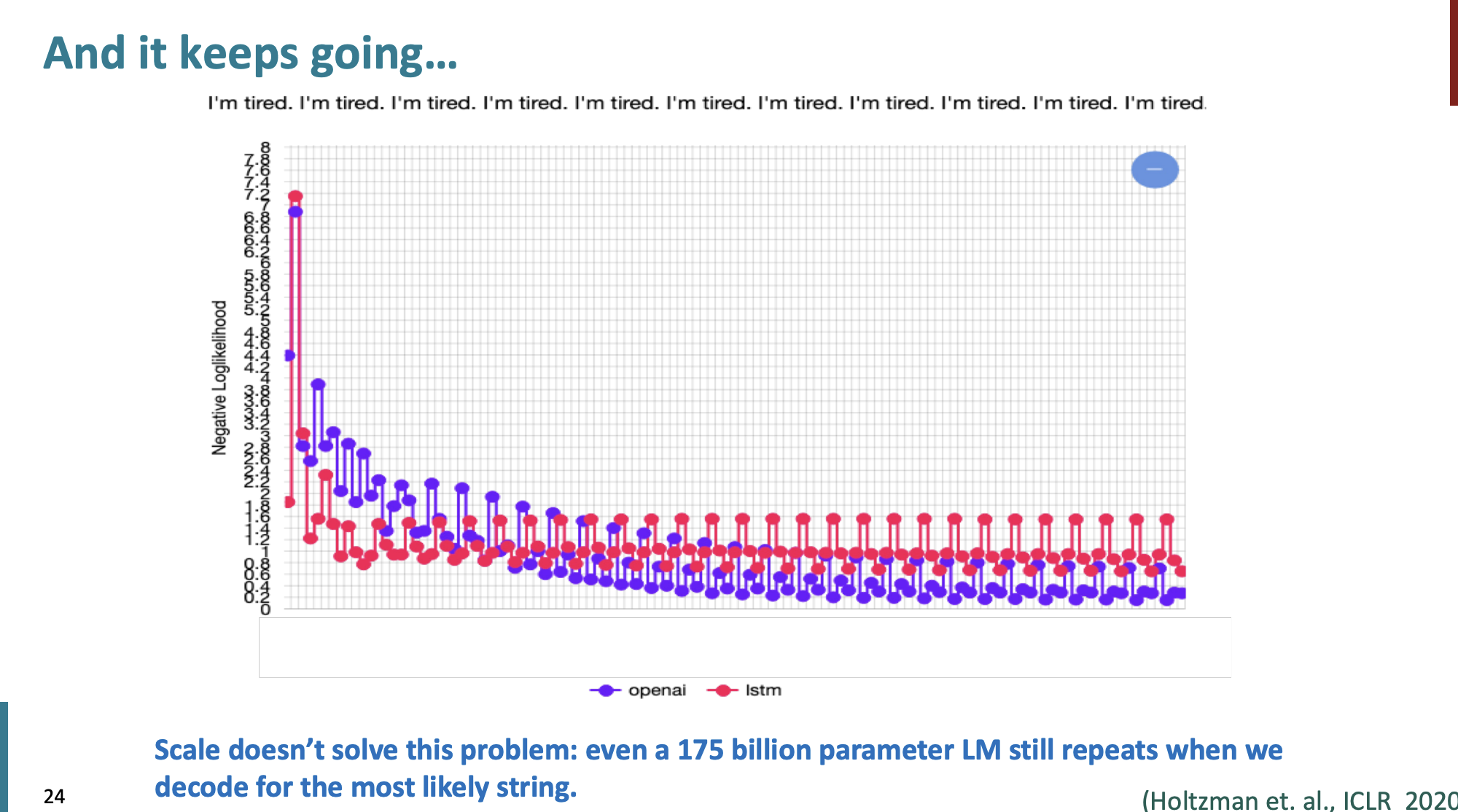
이러한 반복 현상은 매개변수를 아무리 크게 해도 해결되지 않았다.
그럼 어떻게 이런 반복 현상을 줄일 수 있을까?
How can we reduce repetition?
첫번째 간단한 방법은 n-gram을 사용하는 것이다.
더 복잡한 방법은
다른 훈련 목표를 사용하는 것이다.
- 이미 생성된 토큰에 가능성이 없는 단어 생성
- Coverage loss를 준다.
또 다른 방법은 다른 decoding 목표를 만드는 것이다.
가장 가능성이 높은 문자열과 가장 가능성이 낮은 문자열의 차이를 극대화하는 것이다.
- logprob_largeLM (x) – logprob_smallLM (x).
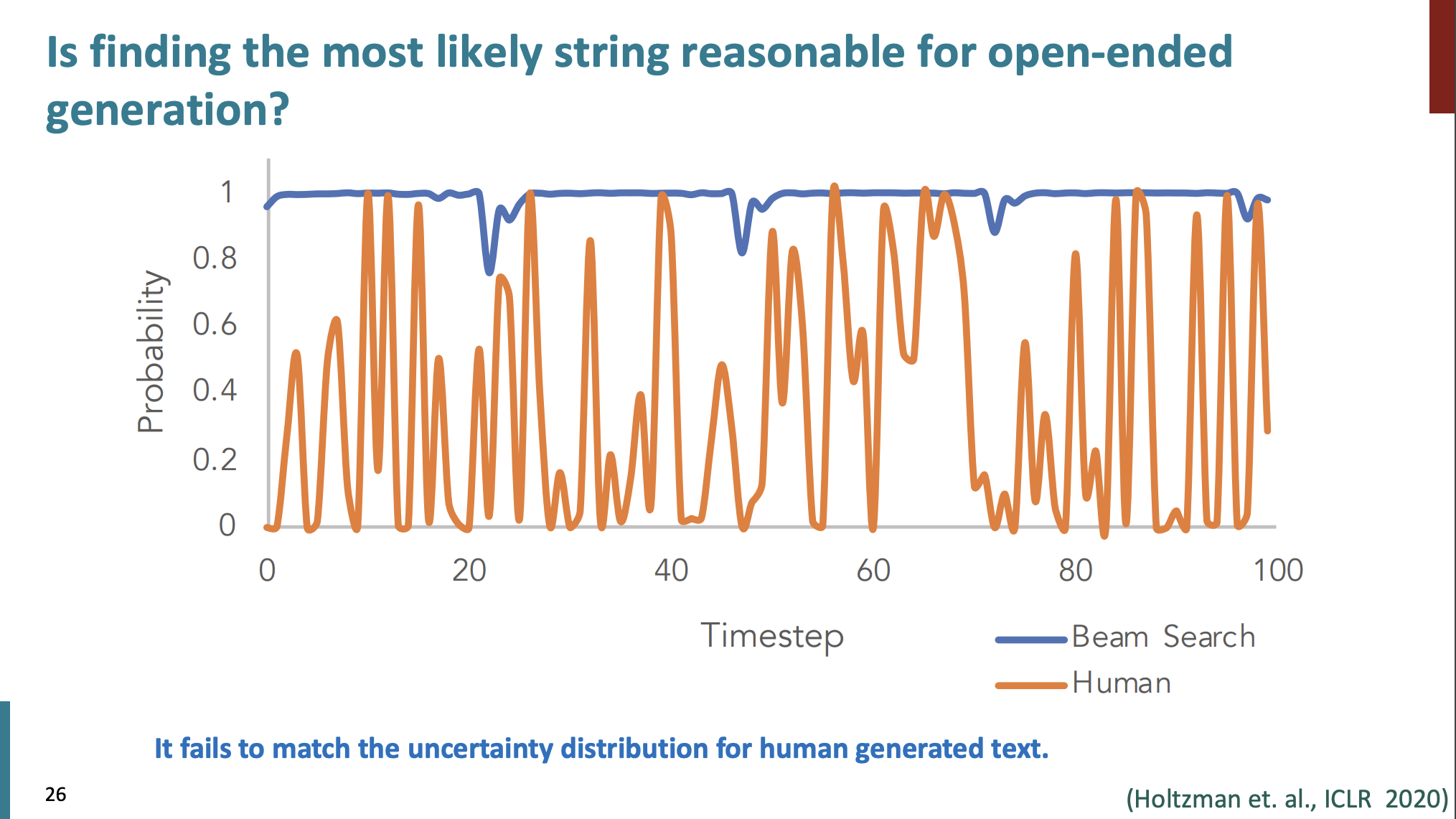
가장 가능성이 높은 문자열을 찾는것이 과연 open-ended 생성에 적합할까?
아니다.
인간과 기계의 문자열 생성 확률을 보자.
인간의 생성은 주황색인데, 주황색 선을 보면 항상 높은 확률만을 선택하지 않는다. 그게 반해 기계는 항상 가능성이 높은 것만 선택하는 것을 볼 수 있다.
그래서 가능성이 높은 단어만을 선택하는 것이 별로 좋지 않음을 알 수 있었다.
이를 해결하는 방법 중 하나는 바로 random 이다.
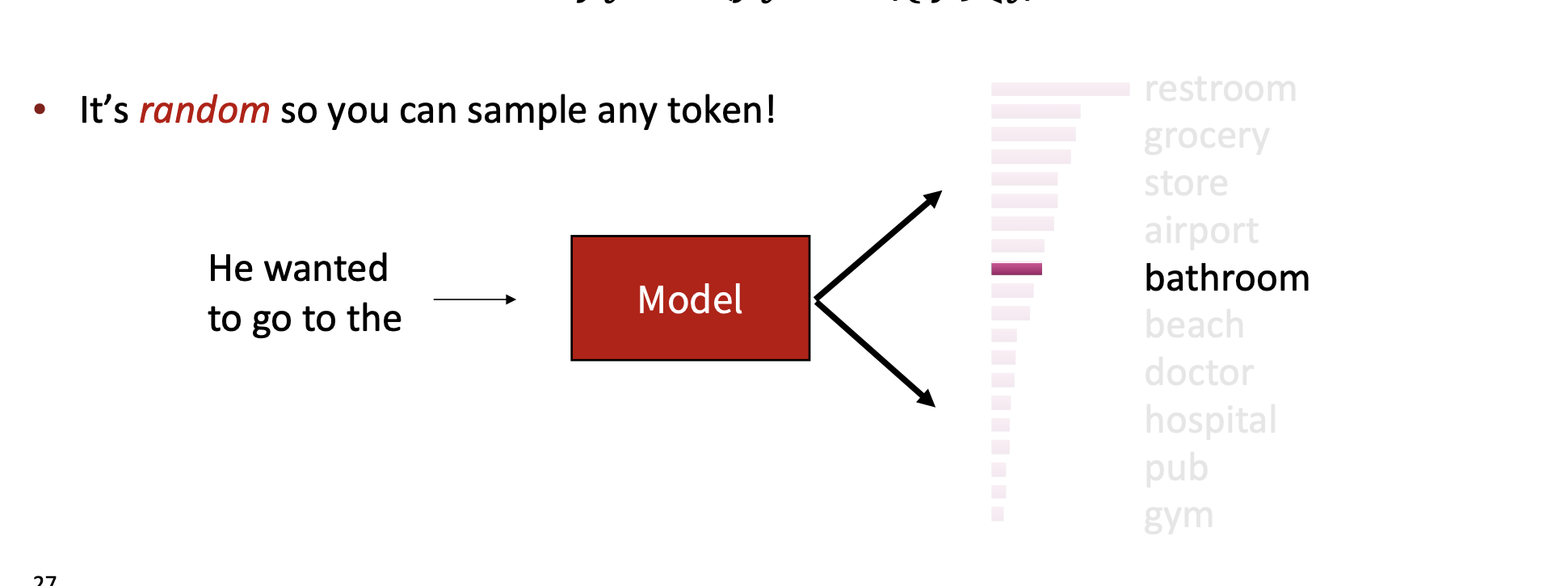
근데 이렇게 random으로 단어 선택을 하면 문제점이 뭘까?
- 많은 토큰들은 현재 문맥에서 많이 벗어날 수 있다.
- 이러한 wrong 토큰들에 대해서 우리는 각각 독립적으로 선택될 아주 작은 기회를 부여할 것이다.
- 하지만 이러한 것들은 매우 많기 때문에 우리는 그룹화를 할 것이다.
Top-k sampling
그래서 상위 k개를 선택하는 것이다.
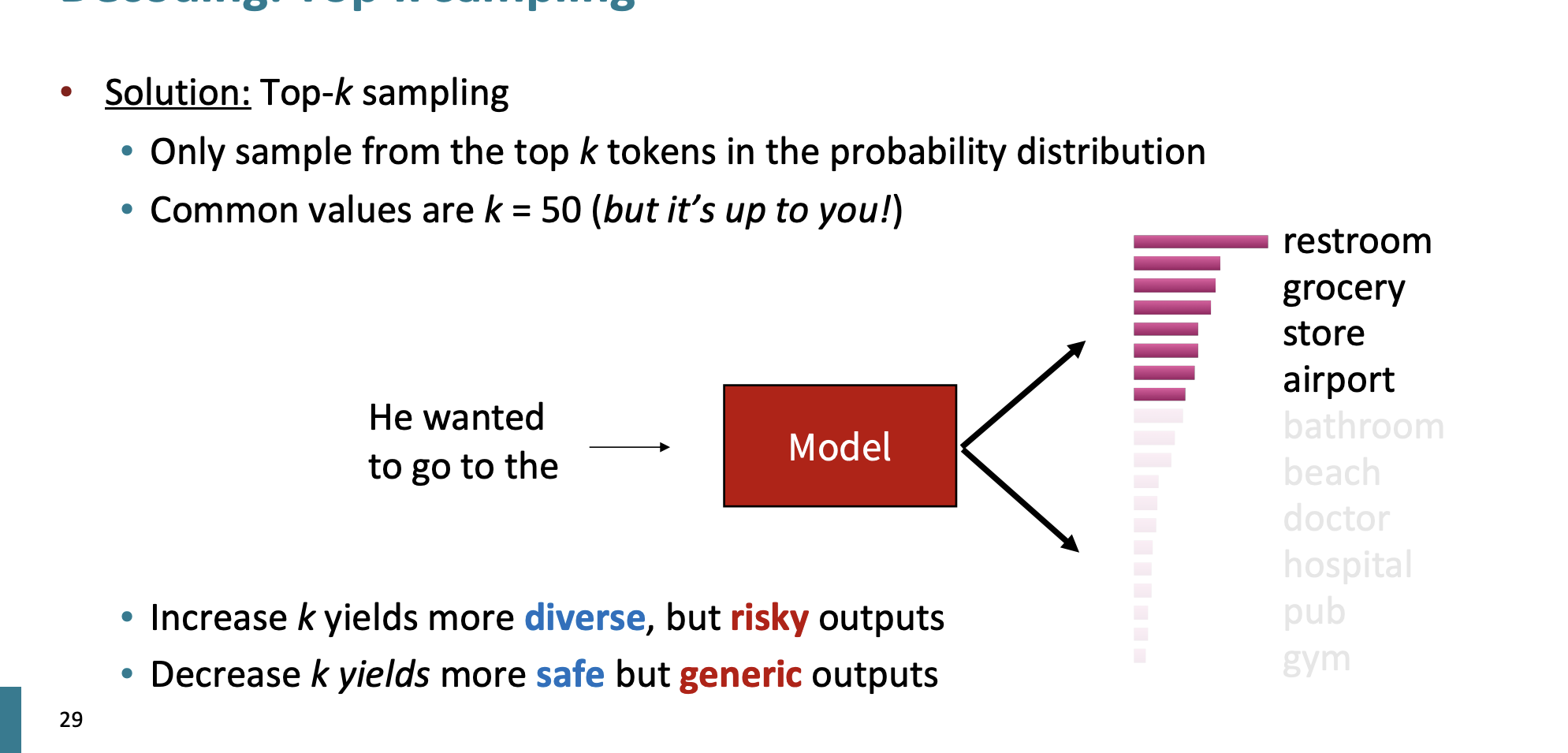
보통 k값은 50으로 한다. 하지만 언제든지 조정할 수 있다.
만약 k값이 증가하면 output은 좀 더 risky하다.
k값이 감소할 수록 안전하지만 output은 일반적인 특성을 가지고 있다.
보통 non-opened된 작업에서는 k값을 작게, opend-ended한 작업에서는 k값을 크게 잡고 있다.
그럼 Top-k sampling의 단점은 무엇일까?
- 만약 분포 p가 flatter 하면, 제한된 k는 많은 옵션들을 지우게 된다.
- 만약 분포 p가 peakier 하면, 높은 k는 너무 많은 옵션들을 선택하게 하는 문제가 있다.
그러면 해결 방법은 무엇일까?
분포도에 맞는 sampling을 진행하는 것이다.
Top-p sampling
분포도 그림에 맞춰서 선택하는 옵션의 수를 정하는 것이다.
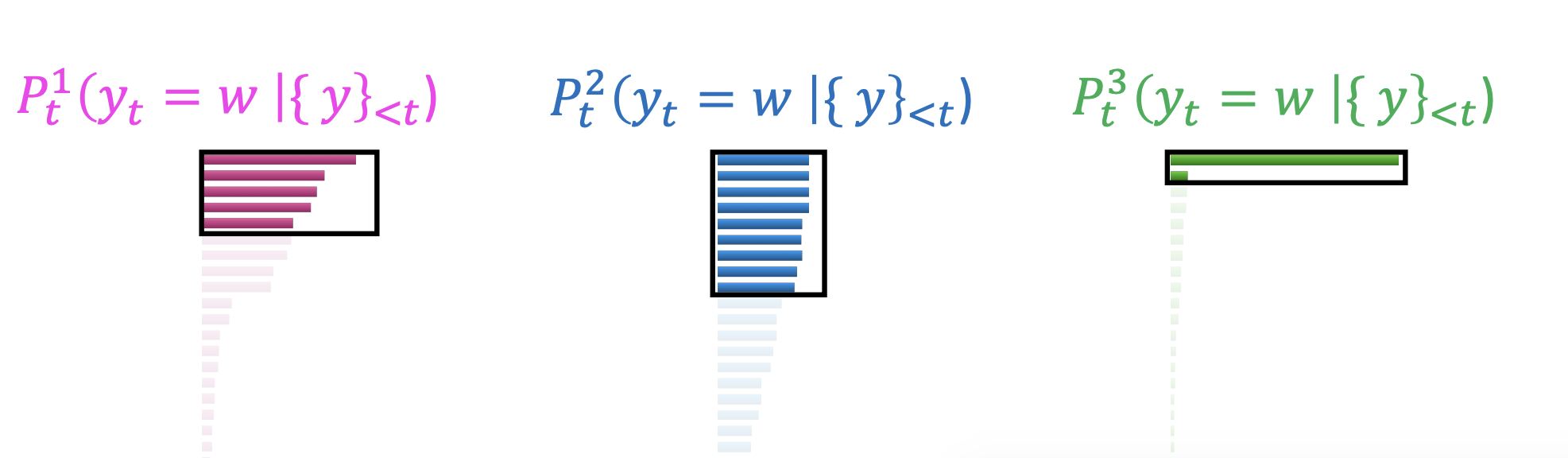
- Typical Sampling : 분포의 엔트로피에 기초해서 점수를 연관시키는 것이다.
- Epsilon Sampling : 가장자리를 낮은 경계 확률로 설정하는 것이다. 예를들어, 확률이 0.03보다 낮다면 아예 선택되지 않도록 나타내지 않는 것이다.
그럼 엔트로피를 어떻게 계산할까?
로 계산하는데, 만약 분포가 평평하다면 엔트로피는 클 것이고, 분포가 어느곳에 집중되어 있다면 엔트로피는 작을 것이다.
Scaling randomness : Temperature
또는 우리는 온도 (temperature) 하이파라미터를 사용할 수도 있다. 를 사용한다.
기존 softmax 함수를 변형한다.
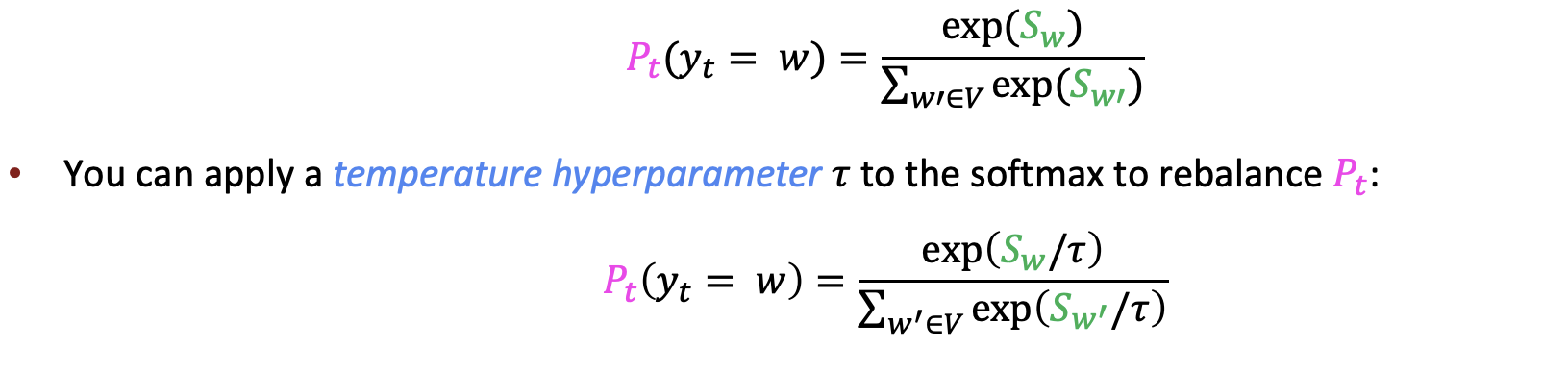
만약 를 1보다 크게하면, 는 균일해진다 그래서 output은 더 diverse해진다. 만약 를 1보다 작게 한다면 는 spiky해진다. output은 덜 다양해진다.
Re-ranking
만약 나의 모델에서 bad sequence를 decode했다면?
그렇다면 여러 시퀀스들을 decode하자.
후보자의 개수는 10이 적당하다. (하지만 it's up to you)
시퀀스의 품질을 대략적으로 평가하기 위해서 점수를 정의하고 이 점수를 통해 다시 re-rank한다.
- perplexity를 사용한다. repetitve 한 발화는 낮은 perplexity를 가지고 있다.
- re-rankers은 다양한 특성을 점수를 매길 수 있다. style, discourse, entailment/factuality ..
- 다양한 re-rankers를 함께 compose할 수 있다.
디코딩은 아직도 NLG에서 해결해야할 문제들이 많다.
다양한 디코딩 알고리즘을 통해서 편향을 주입하면 일관된 자연어 생성의 다양한 특성을 encourage할 수 있다.
지난 몇 년동안 NLG에서 가장 영향력 있는 발전은 디코딩 알고리즘을 간단하지만 효과적으로 수정한 데 있어서 비롯되었다. 그만큼 디코딩 알고리즘은 중요하다!
Training NLG Models
아까 이 문제를 우리는 확인했다.
흔하게 해결하는 방법인 MLE model은 잘못된 텍스트 분포를 학습할 수 있다.
Exposure Bias

Exposure Bias는 훈련시 모델이 실제 데이터 분포에서만 학습되고, 자신이 생성한 데이터(예측 데이터)로는 학습되지 않는 문제이다. 모델은 훈련 데이터에만 노출되고 이로 인해 학습 과정에서 생성된 자체 출력에 대한 노출이 제한되는 것이다.
발생 원인
이러한 편향은 순차적 모델에서 두드러진다. 모델은 각 시퀀스 단계에서 정답을 보고 다음 단어를 예측하는 방식으로 훈련된다. 하지만 실제 사용할 때에는 이전에 모델이 생성한 출력을 기반으로 다음 단어를 예측해야한다.
문제점
Exposure Bias로 인해서 모델이 실제 세계 데이터를 처리할 때 예측 오류가 누적된다. 잘못된 예측을 기반으로 다음 단어를 계속 예측하면 오류가 눈덩이처럼 커지게 된다.
해결방안
- Scheduled sampling : p의 확률로 진짜 gold token대신 토큰을 decode한다. 그리고 다음 input으로 넘긴다. 훈련 동안 p를 증가시킨다. 이 방법은 해결 방안이지만, 엉뚱한 다른 훈련 목표를 가질 수도 있다는 단점이 있다.
- Dataset Aggregation(DAgger): 훈련 중에 다양한 간격에서 현재 모델에 대한 시퀀스를 생성하는 것이다. 그리고 시퀀스를 훈련 데이터 셋이 추가한다.
작동 방식
단계 1: 초기 학습 단계에서, 전문가(예: 사람 운전자)의 행동을 모방하여 데이터를 수집한다.
단계 2: 이 데이터를 사용하여 초기 모델을 훈련시킨다.
단계 3: 훈련된 모델을 실제 환경에서 실행시키고, 이 과정에서 발생하는 의사결정을 기록한다.
단계 4: 전문가가 이 기록된 의사결정을 검토하고, 올바른 행동을 알려준다.
단계 5: 이렇게 얻은 새로운 데이터를 기존 데이터셋에 추가하여 모델을 다시 훈련시킨다. - Retrieval Augmentation : 과거 훈련 데이터에서 배운 정보에만 의존하는 것이 아니라 관련 있는 외부 데이터를 검색해서 현재 예측에 활용한다.
- Reinforcement learning : 몬테 카를로 결정 방법으로 텍스트 생성 모델을 캐스팅한다. 그리고 모델을 보상함으로서 행동을 학습한다.
보상은 어떻게 할까?
일단 Evalutaion metric을 사용해서 점수를 만든다.
- BLEU, ROUGE
어떤 작업에 대해 최적화를 시키는 것은 게임 보상처럼 단순하게 생각하면 안된다. 비록 RL(강화학습)은 BLEU점수를 더 낫게 하지만 이것이 인간의 번역 퀄리티에 영감을 주진 못한다. 즉 인간에게 효과가 없을 수도 있다.
무엇을 목적으로 보상을 주어야 할까?
• Cross-modality consistency in image captioning (Ren et al., CVPR 2017)
• Sentence simplicity (Zhang and Lapata, EMNLP 2017)
• Temporal Consistency (Bosselut et al., NAACL 2018)
• Utterance Politeness (Tan et al., TACL 2018)
• Formality (Gong et al., NAACL 2019)
이러한 것들이 있다.
Teacher forcing이 아직도 다음 생성 모델을 훈련하기 위한 주요 알고리즘이다.
Exposure bias는 텍스트 생성 모델이 쉽게 일관성을 잃도록 만든다. 그래서 모델은 그들의 bad samples에 대해서 회복성을 학습해야 하고 (scheduled sampling, DAgger)또는 아예 bad text를 만들지 않도록 해야한다.(retrieval + generation)
Evaluating NLG Systems
NLG 시스템을 평가하는데는 3가지 방법이 있다.

Content overlap metrics
생성된 텍스트와 사람이 작성한 텍스트 사이의 유사성을 비교해서 점수를 내는 방법이다.
이 방법은 매우 빠르고 효율적이고 널리 사용된다.
이 방법은 N-gram overlap metrics를 사용해서 유사성을 확인한다.
하지만 n-gram을 사용하면 문제점이 있다.
- 문장이 길어지면 길어질수록 유사성이 떨어지기 때문에 open-ended 작업에서는 worse한 결과를 얻기 때문이다.
- 요약, 대화, 스토리 생성 등 점점 갈수록 유사성은 낮아진다!
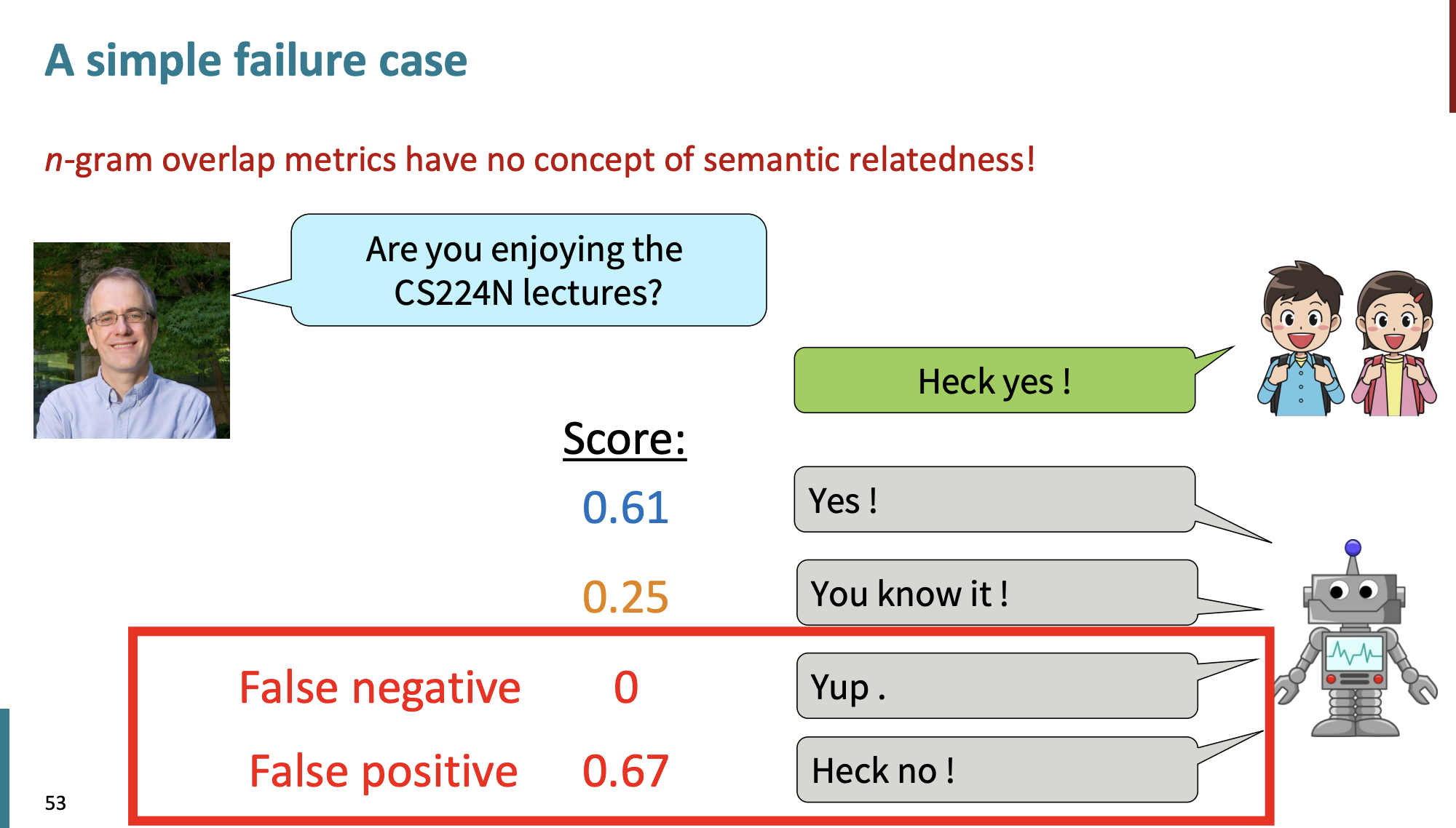
그리고 또 문제점은 의미가 같아도 유사도는 낮아서 점수는 낮을 수 있고, 의미가 완전히 반대여도 형식은 비슷해서 점수는 높을 수 있다.
Model-based metrics
그래서 이제 문장의 의미적 유사성을 찾아보자.
n-gram은 병목현상이 있으니까 이제 단어 임베딩을 사용한다.
임베딩들은 이미 pretrained되어 있다. 그리고 거리 metrics은 유사성을 측정하기 위해 수정될 수 있다.
다양한 word distance functions이 있다.
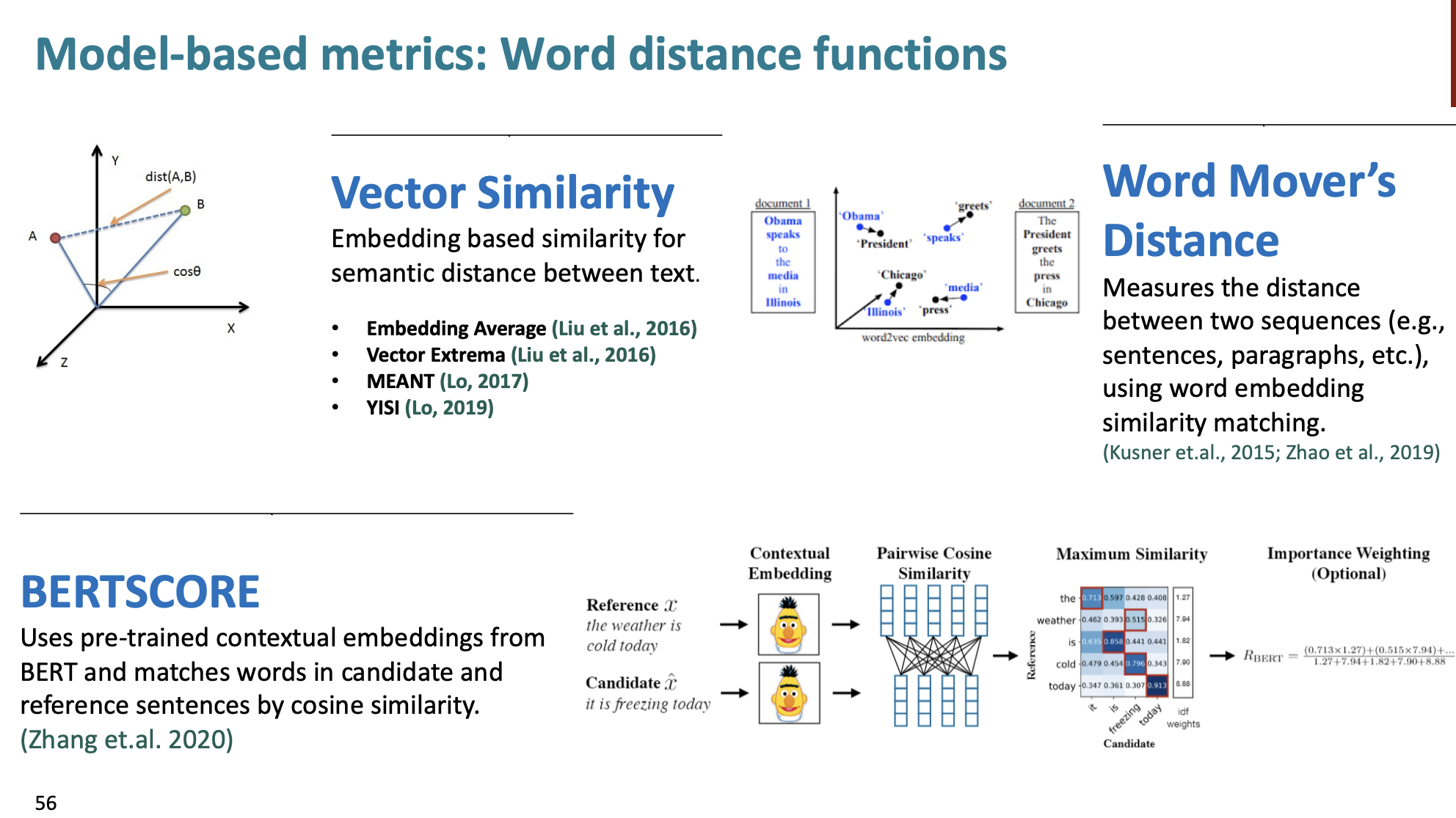
- Vector Similarity: 벡터 유사성을 계산한다. (문장들 사이 유사성)
- Word Mover’s Distance: 단어 임베딩을 사용해서 두 문장 사이의 거리를 계산한다.
- BERTSCORE: 코사인 유사도를 이용해서 문장 사이의 BERT 점수를 계산한다.

-
Sentence Movers' Similarity는 Word Movers' Distance 개념을 확장한 것이다. WMD는 문서 내 개별 단어 간의 거리를 기반으로 문서 간 유사성을 측정했다면, SMS는 문장수준으로 확장한 것이다.
-
작동방식: 여러 단어의 임베딩을 결합해서 문장이나 문서 전체의 임베딩을 생성한다. 생성된 임베딩을 기반으로 두 문장 또는 문서 간의 거리를 측정한다.
-
BLEURT는 BERT모델을 기반으로 한다. 후보 텍스트가 문법적인 의미를 나타내고, 참조 텍스트의 의미를 전달하는 점수를 반환한다.
Evaluating Open-ended Text Generation
개방된 텍스트 생성은 어떻게 평가할까?
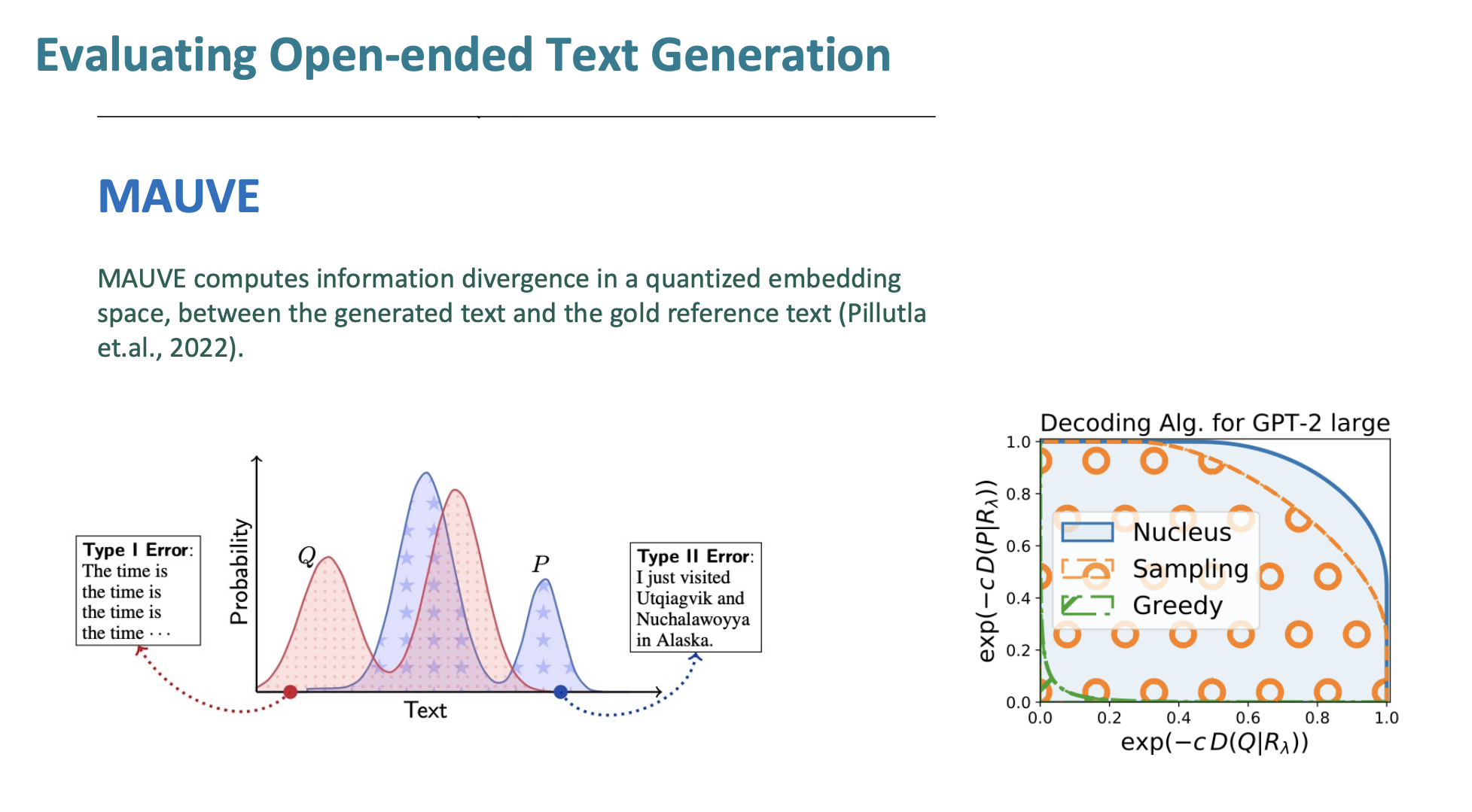
MAUVE의 기본원리는 인간이 작성한 텍스트와 기계가 생성한 텍스트 사이의 유사성을 측정하는 척도이다.
인간이 작성한 텍스트와 얼마나 유사한지, 얼마나 다양한지를 동시에 고려한다.
작동 방식
- 임베딩을 사용한다. 임베딩하는 데 사전 훈련된 (GPT-2, BERT)등을 사용한다.
- 인간 텍스트와 기계 텍스트의 임베딩 분포를 비교한다.
- 텍스트의 다양성(텍스트가 얼마나 다양한 주제, 스타일을 나타내는지)와 유사성(인간의 텍스트와 얼마나 유사한지)를 동시에 측정한다.
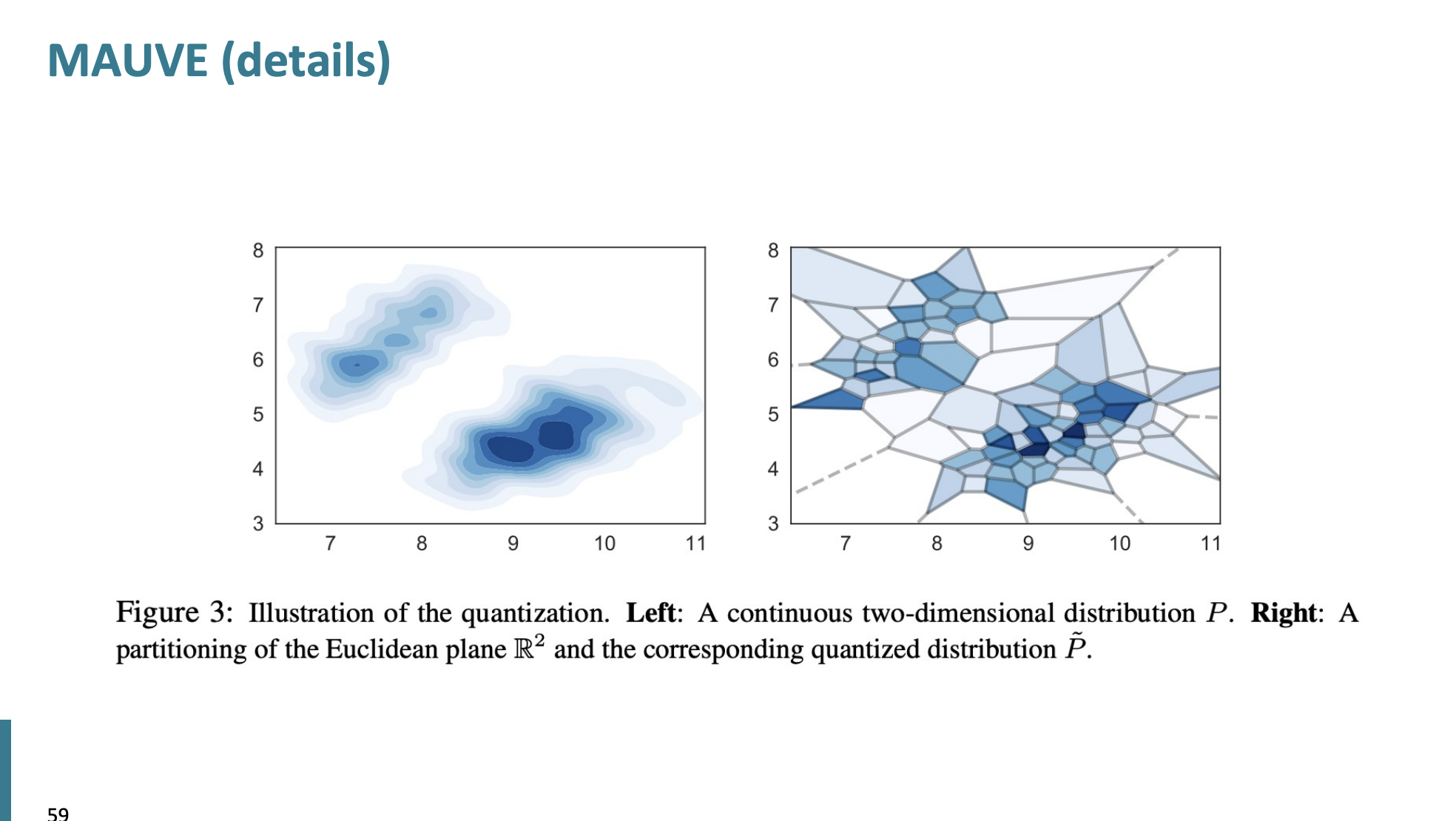
MAUVE는 고차원 임베딩 분포를 분석하는데, 개별 텍스트 조각의 유사성을 넘어서, 전체 텍스트 생성의 임베딩 분포를 분석한다.
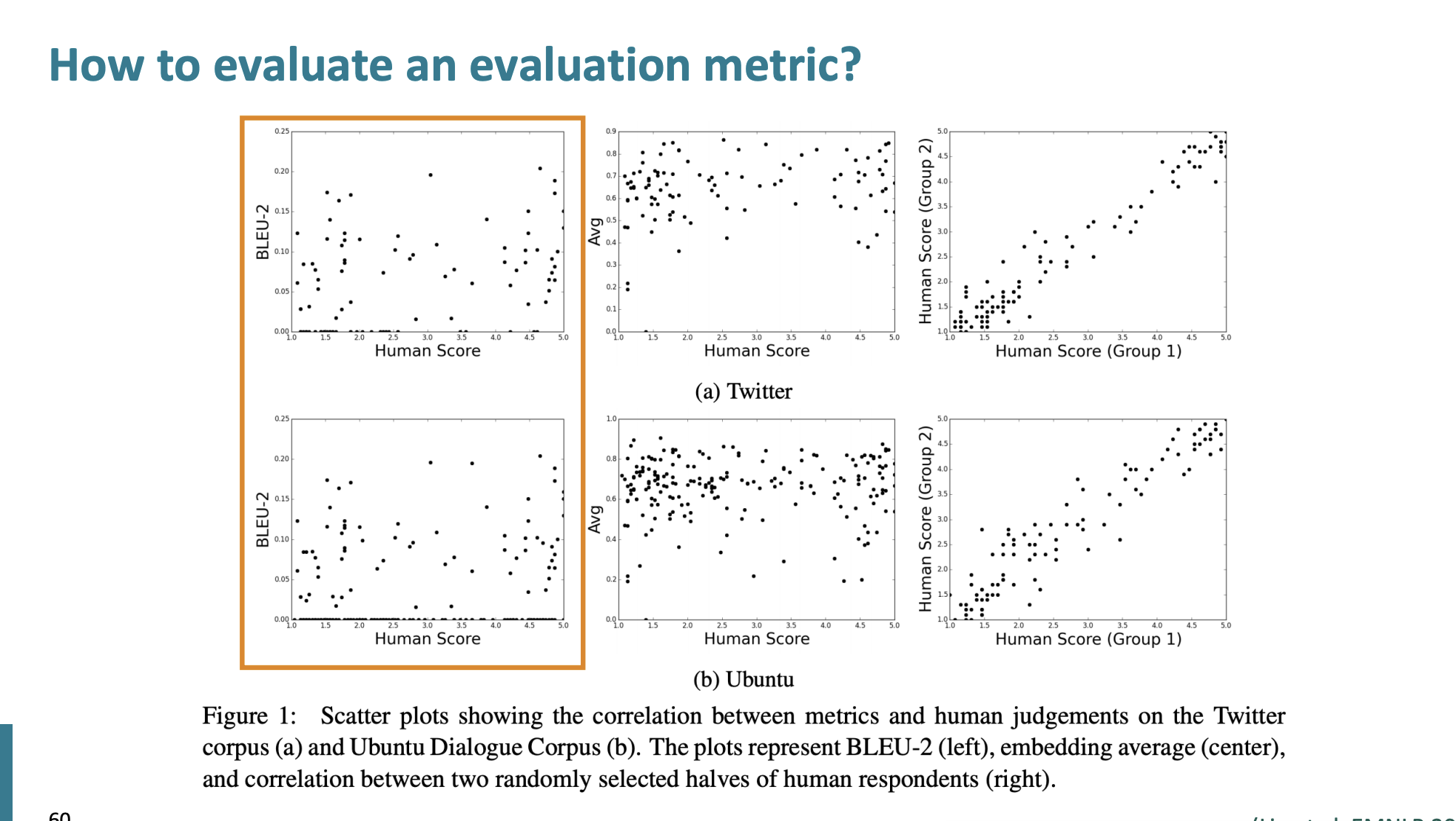
y축은 BLEU, x축은 인간 점수이다. 여기서는 어떤 상관관계도 보이지 못했기 때문에 BLEU점수는 그다지 좋은 지표가 아니라는 것을 암시한다.
Human evaluations
인간의 평가는 아직도 텍스트 생성 시스템의 평가에 가장 중요한 요소이다.
그럼 인간이 텍스트 생성에 대해서 평가하는 요소들은 무엇일까?
• fluency
• coherence / consistency
• factuality and correctness
• commonsense
• style / formality
• grammaticality
• typicality
• redundancy
인간의 판단은 gold standard로 여겨진다. 하지만 인간의 판단은 느리고 비싸다
인간의 feedback으로 부터 배우는 방법 두가지가 있다.
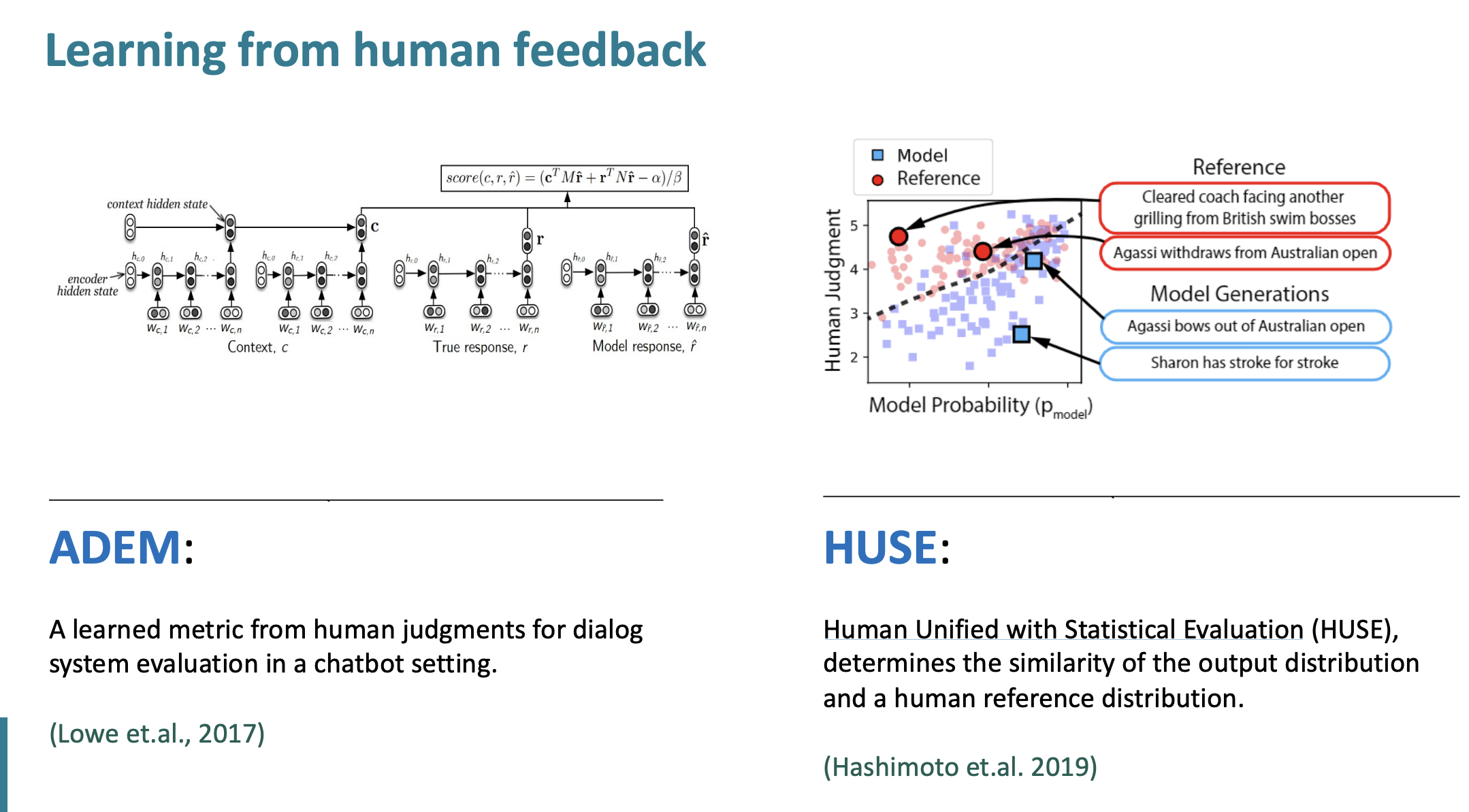
ADEM은 챗봇세팅에서 대화 시스템 평가를 위해서 인간의 판단으로부터 metric을 배운다.
HUSE는 Human Unified with Statistical Evaluation의 줄임말이며 인간의 분포도와 output 분포도의 비슷함(유사도)를 결정한다.
결과적으로
Content overlap metrics는 생성된 텍스트의 품질을 평가하는 좋은 시작점이였지만, 충분하지 않았다.
Model-based metrics는 더 인간의 판단과 일치했지만 그들의 behavior는 해석할 수 없었다.(방식이 어렵다는 의미같다.)
Human judgment는 중요하지만 인간조차도 완전하지 않다.
더 나아가서
우리가 인공지능 공학도로써 갖춰야할 인공지능 윤리에 대해서 말한다.
인공지능에게 유해한 질문을 통해 유해한 정보를 얻을려고 한다. 이를 보통 개발자들은 막아놓지만, 질문을 우회해서 하면 방화벽(jailbreak)을 넘어서 인공지능이 답을 해준다고 한다.
이러한 문제점이 아직도 존재하고
거짓인 사실을 사실인 양 말하는 등의 문제점도 있다.
그리고 생성 모델에서도 Bias가 존재했다.
성별, 인종, 양성애자 등등에 대해서 편견이 존재했다.
인공지능 개발자들은 모델을 공개하기전 유해한 정보를 생성하는 지에 대해서 이전에 꼭 확인을 해야한다.
- 모델의 출력이 harmful한지
- 모델이 trigger words에 대해서 robust한지 확인해야 한다.
끝!
