강의 자료
이번 강의 내용은 다음과 같다.
- What is question answering?
- Reading comprehension
✓ How to answer questions over a single passage of text - Open-domain (textual) question answering
✓ How to answer questions over a large collection of documents
강의 발표자는 프린스턴 대학 교수인 Danqi Chen이다.
Lecture 12
Question Answering
Question Answering이 뭘까?
시스템이 자동적으로 자연어 질문에 대해 응답하는 것이다. QA 시스템은 1960년대부터 연구되어졌다.
- 시스템을 만들기 위해서 어떠한 정보를 사용하는가?
- A text passage, all Web documents, knowledge bases, tables, images.. - 질문의 종류는 어떤 것들인가?
- Factoid vs non-factoid, open-domain vs closed-domain, simple vs compositional, - 답변의 종류는 어떤 것들인가?
- A short segment of text, a paragraph, a list, yes/no
QA시스템은 구글 검색기에서도 사용이 되고, Alexa같은 홈 스마트 기기에서도 활용되고 있다.
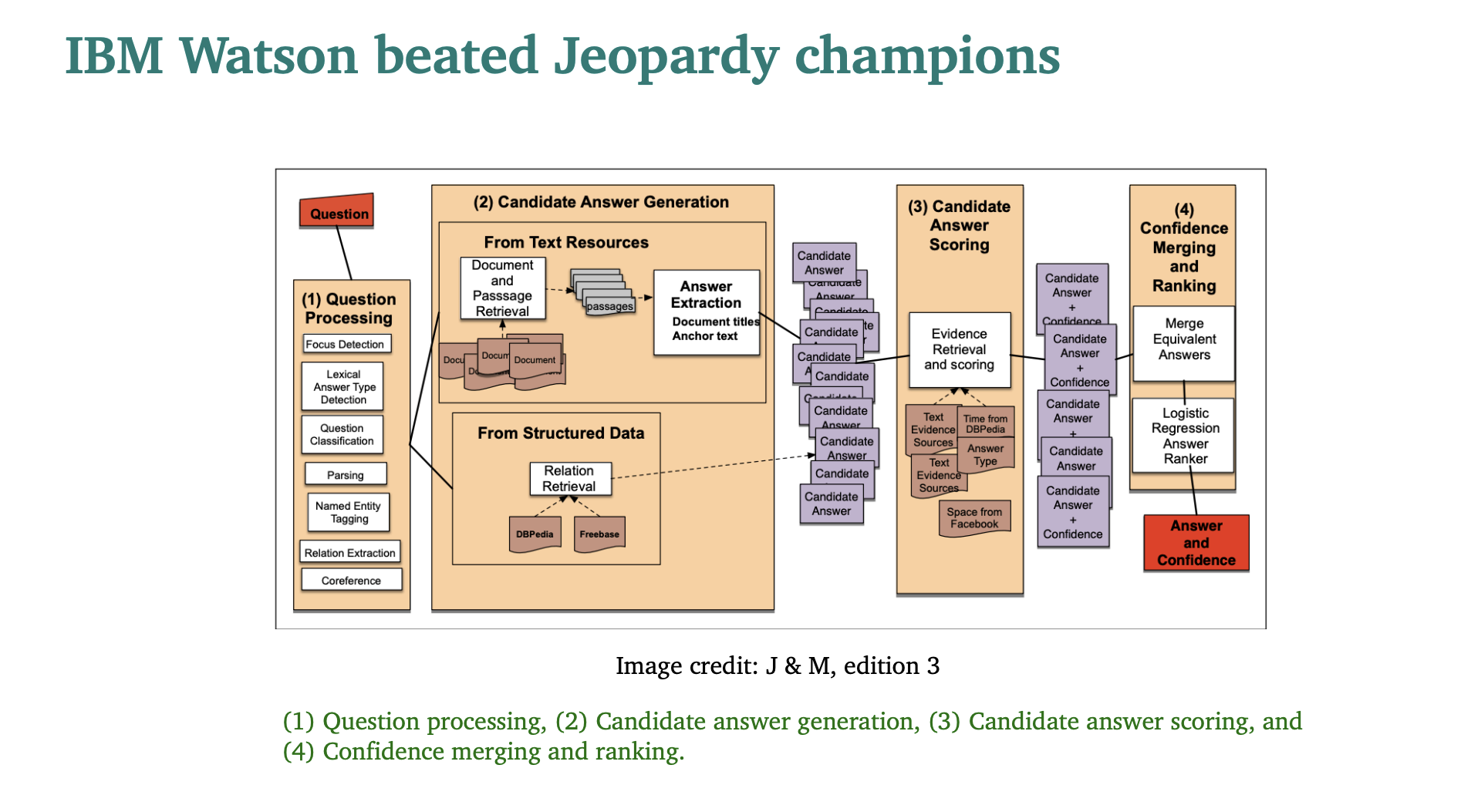
(1) 질문을 하면
(2) 여러 답변을 생성해내고
(3) 답변 후보들을 점수화해서
(4) 합치고 랭킹을 만들어서
(5) 답변을 하는 것이다.

최신 QA 시스템들은 end-to-end 훈련을 기반으로 하고 BERT와 같은 pre-trained 모델을 사용한다.
오늘은 Knowledge based QA, Visual QA 등, 구조화 되지 않은 텍스트를 기반으로 질문에 대해 답변을 어떻게 하는지 알아볼 것이다.
Reading comprehension
Reading comprehension은 독해력이다.
다음 단락을 읽고 문제를 풀어보자.

답은 German이다.
다른 문제도 풀어보자.

답은 Hindi이다.
인간은 이런 문제를 어렵지 않게 해결할 수 있지만, 기계는 이러한 작업을 어려워한다.
독해력에 대해서 우리는 왜 생각해야할까?
- 많은 실용적인 활용을 할 수 있기 때문이다.
- 또한 컴퓨터 시스템이 얼마나 인간의 언어를 이해하고 있는지 중요한 척도가 되기 때문이다. 한국인이 국어 시험을 보는 것과 비슷하다.
- QA는 자연어를 이해의 가장 강력한 설명이 된다.

단락을 읽고 정보를 추출하는 문제도 독해력에 속한다. 우리는 쉽게 ?에 해당하는 것이 Columbia University라는 것을 알 수 있다.

문장 구조에 따라 주어와 목적어등을 이해하는 것도 독해력이다.
그럼 당연히 QA 시스템을 개발하기 위해서는 필요한 것이 있다.
바로 Dataset이다.
Stanford question answering dataset
Stanford question answering dataset을 줄여서 SQuAD라고 한다.
- 10만개의 주석이 달린 글이다. -> 대규모 지도 데이터 세트는 독해를 위해 중요한 요소이다.
- 지문은 100~150 단어로 구성된 English 위키피디아에서 선택되었다.
- 질문들은 Crowd-sourced (대중이 참여됨)
- 오늘날 거의 해결된 상태이고 최신 기술들은 인간의 성능을 뛰어 넘는다고 한다.
🧚 평가 방식
완전히 맞았는지(exact match) 확인하고 partial credit인 F1을 확인한다.
그럴듯한 답변이 여러개 있을 수도 있기 때문에 3개의 gold 답변이 수집된다.
-> 각 정답에 대해 예측된 답과 각 정답을(a,an,the,문장 부호는 제거) 비교해서 최대 점수를 구한다. 마지막으로, 모든 예제의 평균을 구한다.
Q: What did Tesla do in December 1878?
A: {left Graz, left Graz, left Graz and severed all relations with his family}
-> 그럴 듯한 답변 3가지를 작성한다.
Prediction: {left Graz and served} -> 실제 답
Exact match: max{0, 0, 0} = 0
-> 완전히 맞았는지 확인한다.
F1: max{0.67, 0.67, 0.61} = 0.67
-> 얼마나 부분적으로 맞았는지 확인한다.
🤔 그럼 SQuAD를 풀기 위해서 어떻게 모델을 수립해야 할까?
문제 형식은 다음과 같다.
- Input :
C = - Output : 1 <= start <= end <= N
크게 두가지 방식으로 해결한다.
✌️ LSTM-based vs BERT models
LSTM-based
우린 LSTM-based model을 중점적으로 살펴볼 예정이다.
🤩 seq2seq model with attention 를 다시 살펴보자.
이전에는 input source 문장을 통해 target sentences를 만들었다. 하지만 QA를 하는 우리는 passsage와 question이라는 시퀀스를 가지고 있다.
- passgage에서 question과 적합한 단어를 뽑아내야 한다. 이때 우리는 Attention을 통해서 어떤 단어가 질문과 관계있는지 알아낸다.
- 우리는 타깃 문장을 한 단어씩 만들어내는 autoregressive decoder가 필요하지 않다. 대신에 우리는 두가지 분류기를 훈련시켜서 answer의 시작과 끝지점을 예측시킬 것이다.
BiDAF
BiDAF는 the Bidirectional Attention Flow model의 줄임말이다.
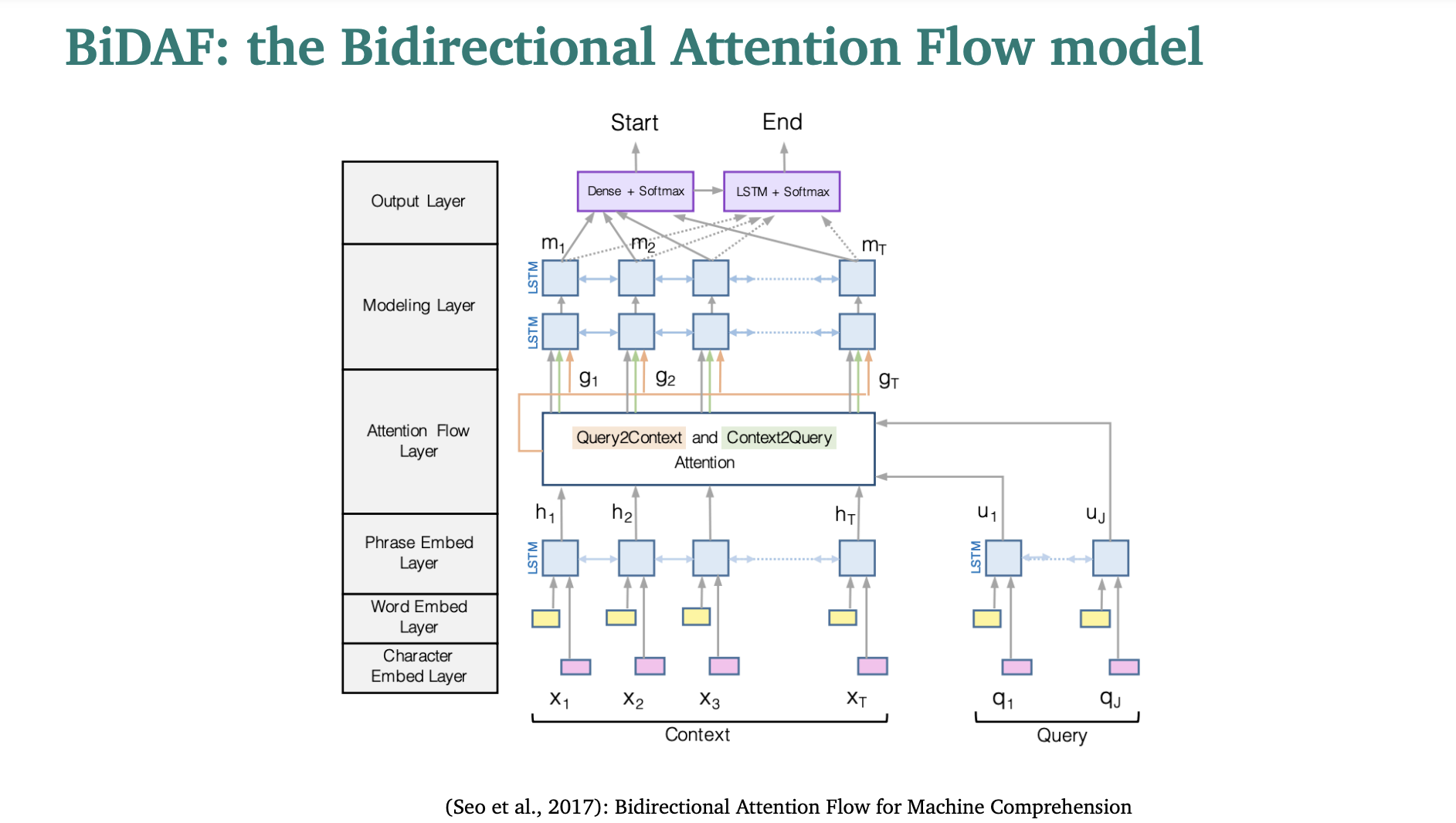
맨 아래 3 layer를 Encoding 영역이라 한다.
영역을 나누어서 BiDAF에 대해 자세히 알아보자.
1. Encoding
- 단어 임베딩 (GloVe)와 문자 임베딩 (CNNs over character embeddings)를 Concatenation한 것을 사용한다.
e(ci) = f([GloVe(ci); charEmb(ci)])
e(qi) = f([GloVe(qi); charEmb(qi)])
f: high-way networks omitted here - 그리고 두개의 bidirectional LSTM을 각각 사용해서 문맥과 query에 대한 contextual embeddings를 생산한다.

- 문맥 임베딩 과정에선는 문장 내의 각 단어가 주변 단어들과 어떻게 관련되는지 학습한다.
2. Attention
BiDAF는 문맥(context)와 질문(question)사이의 관계를 두 방향으로 탐색한다.
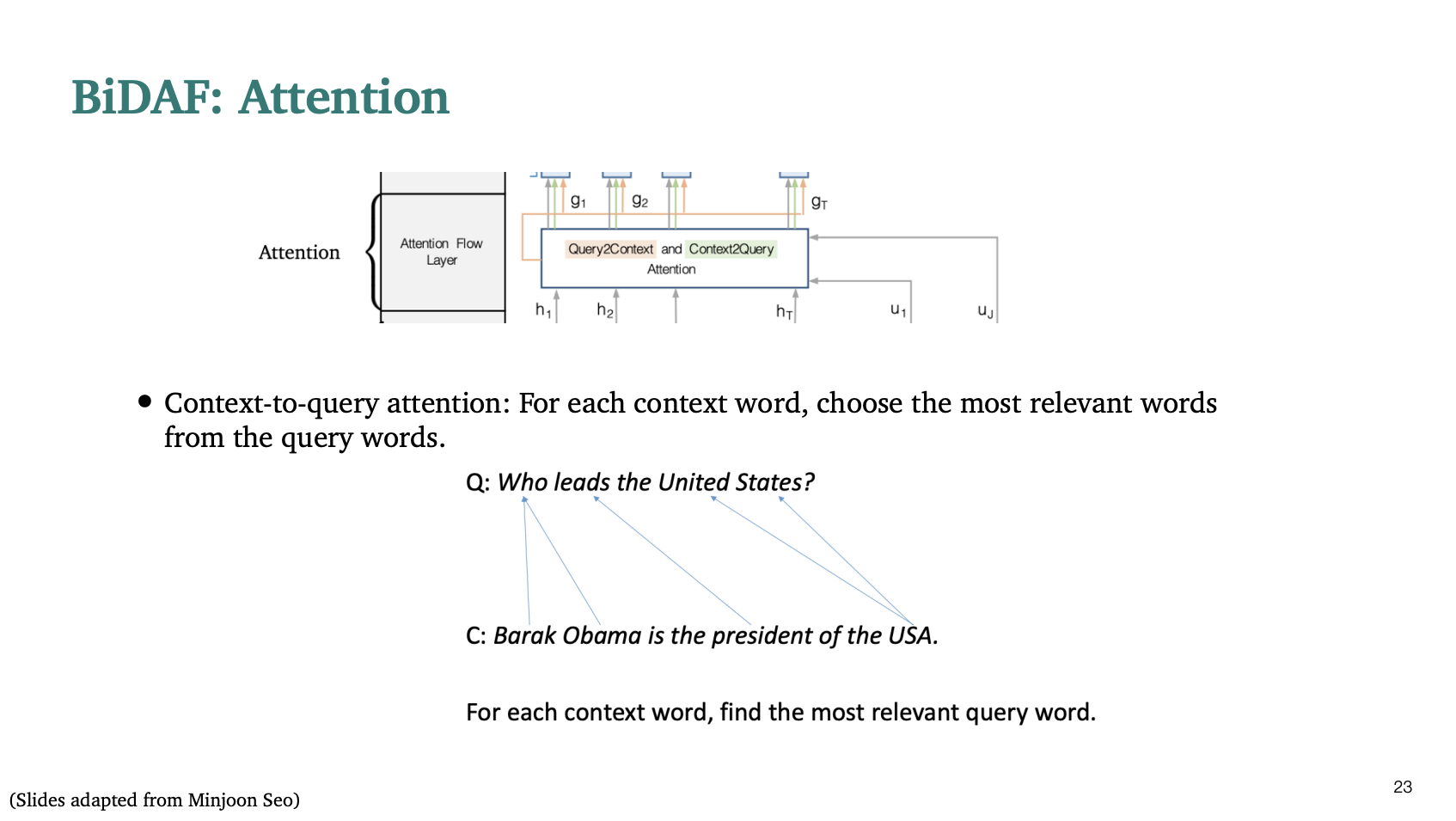
- 문맥 - 질문 어텐션: 각 문맥 단어가 질문 단어들과 얼마나 관련이 있는지 측정한다.

- 질문 - 문맥 어텐션 : 각 질문 단어가 문맥 단어들과 얼마나 관련이 있는지를 측정한다.

일단 첫번째로, 문맥과 질문 사이의 유사성 점수를 계산한다.
그 다음 각각 어텐션을 수행한다.
-
Context to query 어텐션은 어떤 질문 단어가 가장 문맥 단어인 에 관련이 있는지 알아보는 것이다.
그래서 softmax를 통해서 가장 관련이 있는 것을 라고 한다. 그리고 가중치 합계를 통해 a를 구한다.
💛 나는 문맥 단어 i와 질문 단어 j의 유사도를 구한 값 를 j에 대해 softmax를 취해서 확률 분포(가중치)로 만들고 이 가중 평균을 로 정의했다고 이해했다. -
Query to Context 어텐션은 어떤 문맥 단어가 몇개의 질문 단어들에 가장 관련이 있는지 알아보는 것이다. context-to-query와 다르게 MAX가 추가되었다.
💛 이 행렬의 각 행에 대해 최대값을 취해주면서 어떤 질문 단어가 어떤 문맥단어와 가장 관련이 있는지 확인하기 위함이다. 이 수치가 낮다면, 문맥 world와 일치할 수 있는 질문 단어가 없음을 의미한다. 그래서 최대값을 취한 후에도 가 여전히 매우 낮다면, 문맥단어와 그다지 관련성이 없는 것이다.
💛 나는 일단 어떠한 문맥 단어 i와 가장 유사도가 높은 질문 단어를 선택해서 i에 대해 softmax를 취하고, 확률 분포(가중치)로 만든 다음 가중치와 문맥 단어를 곱한 가중 평균을 b라고 정의한다고 이해했다. -> 순차적으로 문맥단어 i를 진행하지만, 질문 단어는 중복으로 뽑힐 수도 있는 것이다!
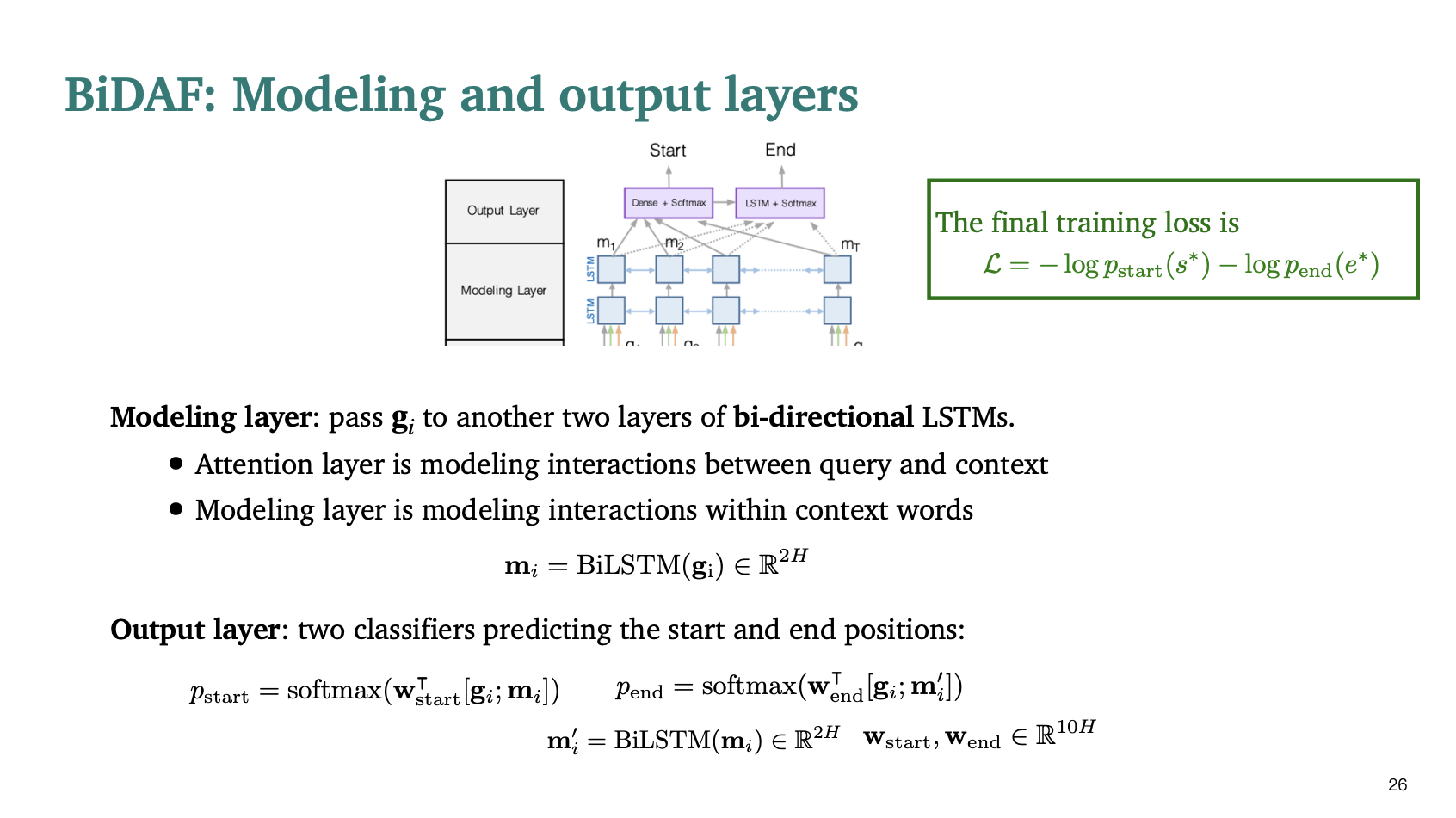
3. Modeling layer: 어텐션에서 수행한 정보들은 양방향 LSTM을 거쳐서 처리된다.(BiLSTM)
4. Output layer : 두개의 분류기는 시작점과 끝 지점을 예측한다.
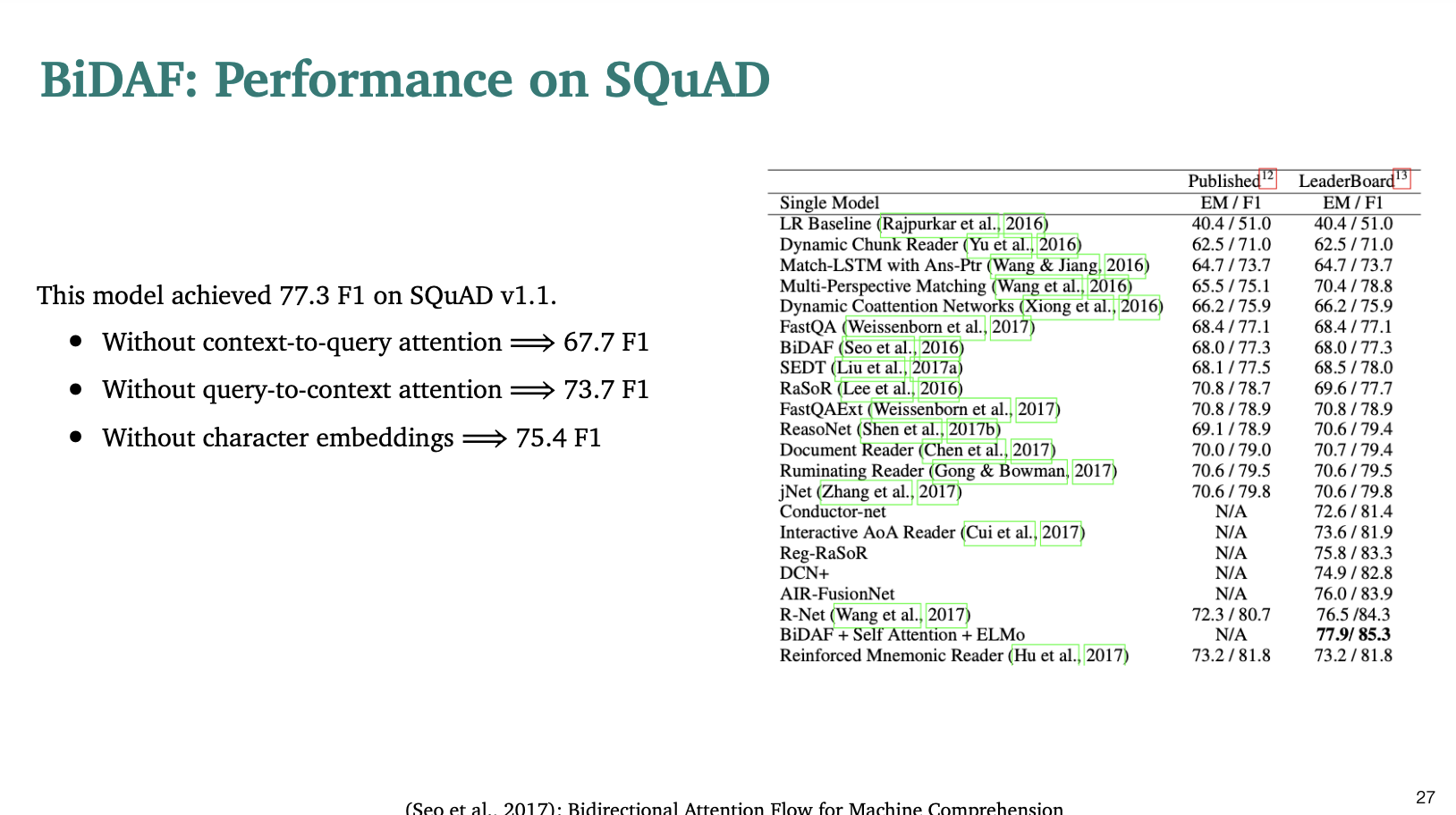
점수는 77.3점을 받았다.
- 만약 context-to-query 어텐션이 없다면 67.7점으로 떨어진다.
- 만약 query-to-context 어텐션이 없다면 73.3점으로 떨어진다.
- 만약 문자 임베딩을 제거한다면 75.4로 떨어진다.
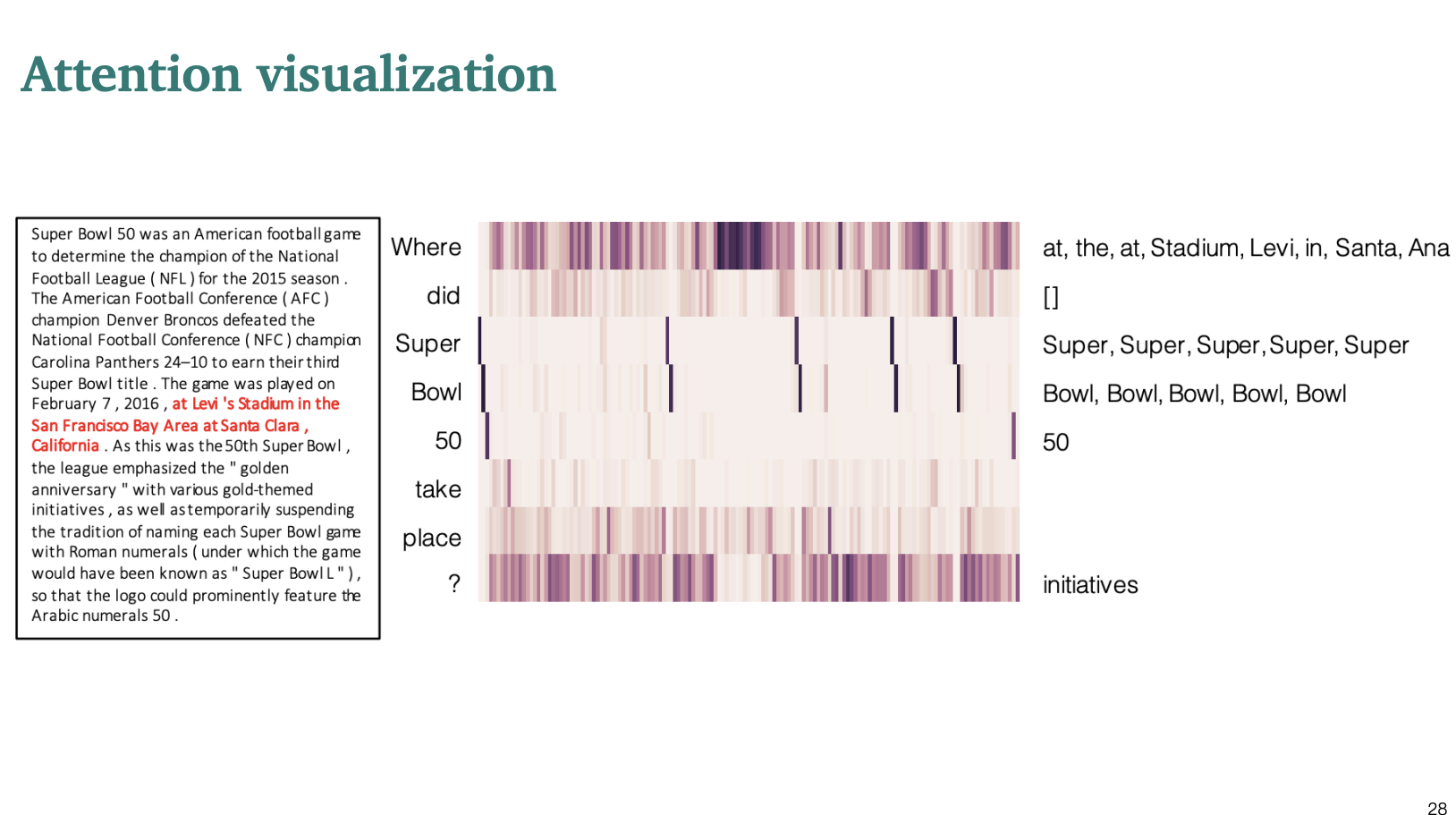
어텐션을 비주얼화해서 살펴보면 중요한 문장에서 진한 색으로 나타나는 것을 알 수 있었다.
BERT for reading comprehension
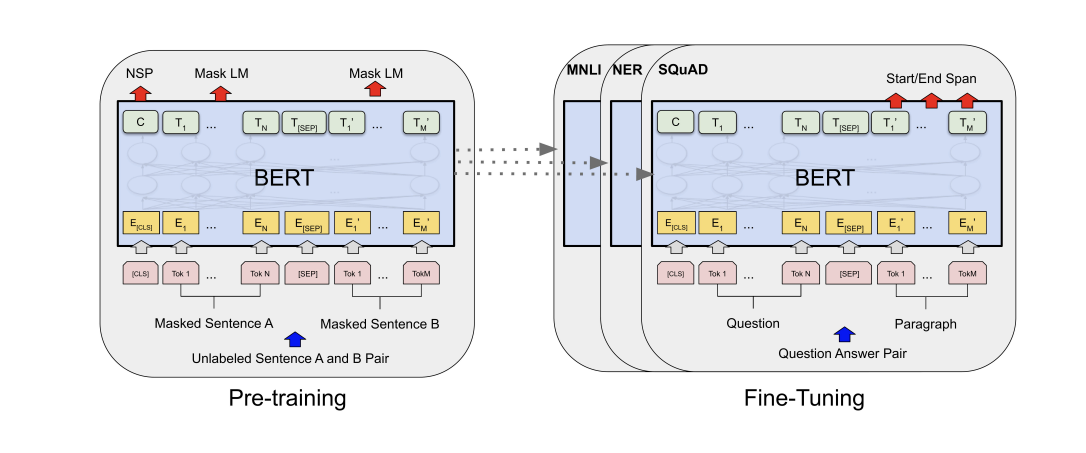
우린 이미 BERT에 대해서 배웠다. 그러니 기초 BERT개념은 생략하자~
- BERT는 대량의 텍스트에 대해 사전 학습된 양방향 트랜스포머 인코더이다.
- BERT는
• Masked language model (MLM)
• Next sentence prediction (NSP)
에 대해 사전 학습되었다. - BERTbase는 12개의 layers 와 1억 1천만개의 파라미터를 가지고 있고, BERTlarge는 24개의 layer와 3억 3천만개의 파라미터를 가지고 있다.
BERT에 대해서는 간략히만 알아보자.
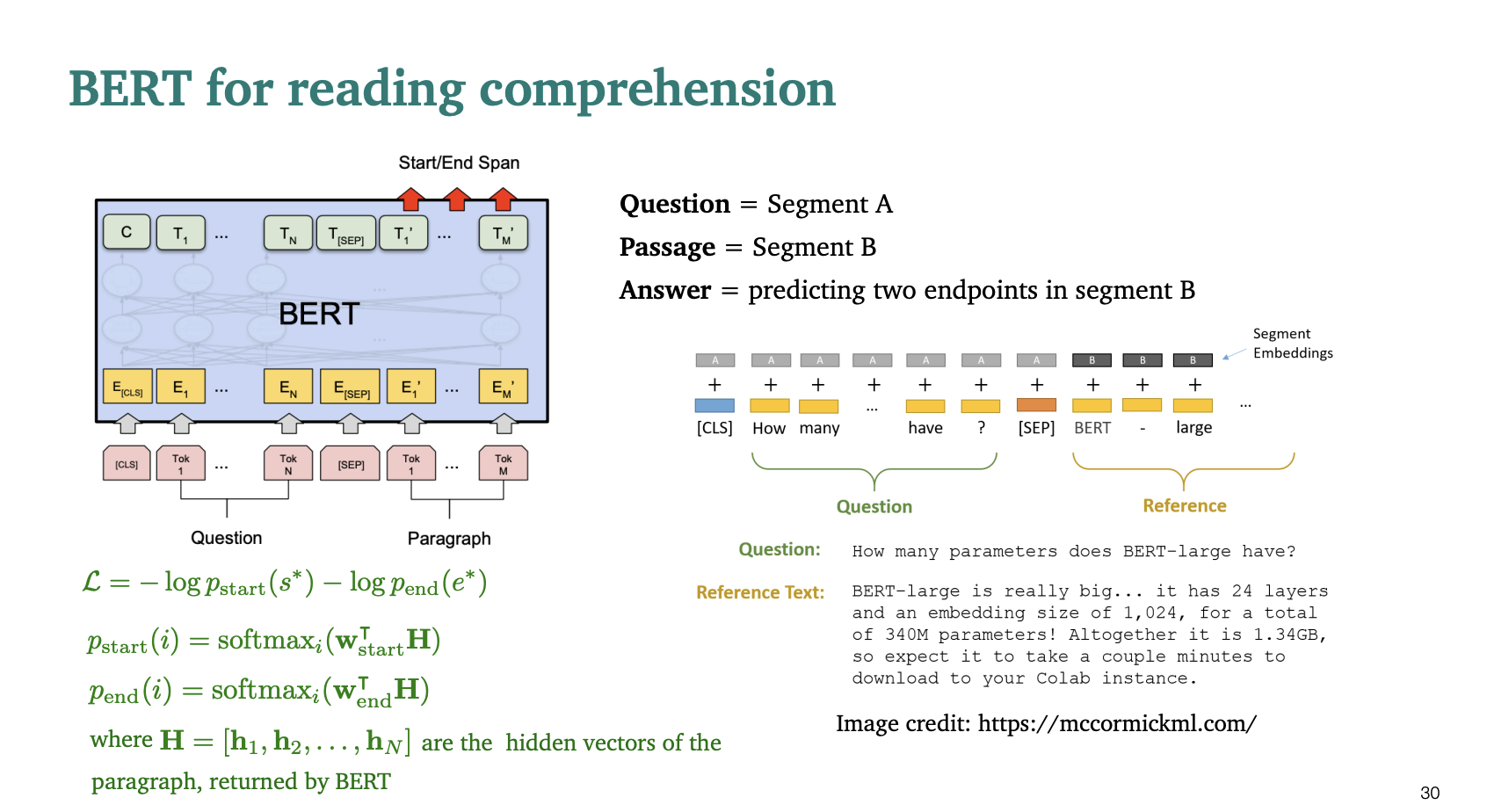
우리가 BERT에 넣는 문자열은 다음과 같다.
Question = Segment A
Passage = Segment B
Answer = Segment B에서 두개의 end point를 예측하는 것.
그러니까 질문과 질문에 필요한 글을 같이 입력으로 넣고, 질문에 답하기 위한 문장을 글에서 뽑아내는 것이다.

손실함수를
라고 정의하자.
모든 BERT의 파라미터들을 L에 최적화해서 정의했다고 하자.
BiDAF와 비교해서 점수를 보면 BERT의 점수가 훨씬 큰것을 확인할 수 있었다.
RoBERTa, ALBERT와 같은 사전 훈련된 최신 언어모델은 더 좋은 결과를 보여주었다.
BiDAF vs BERT
BiDAF와 BERT는 완전히 다른 모델인가?
아니다!
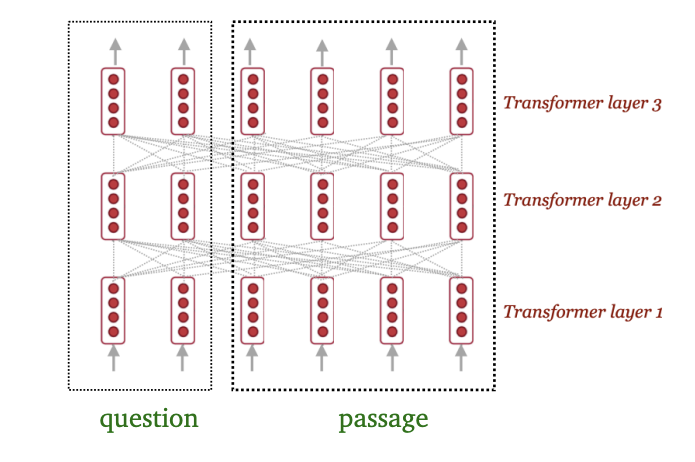
- BiDAF는 질문과 passage 사이에서의 상호작용에 초점을 둔다.
- BERT는 질문과 passage 사이에서의 self-attention을 사용한다. -> attention(P, P) + attention(P, Q) + attention(Q, P) + attention(Q, Q)
- 한 논문((Clark and Gardner, 2018))에 의하면 passage 사이에서의 self-attention이 성능을 좋게 한다고 한다.
SpanBERT
그럼 BERT를 더 나은 성능을 갖게 할 수 있을까? YES
두가지 idea를 가진다.
1) 연속된 단어를 MASK한다. (가린다)
2) MASK된 범위의 끝점을 사용해서 MASK된 부분을 예측한다. 범위의 정보를 두 끝점으로 압축하는 것이다.
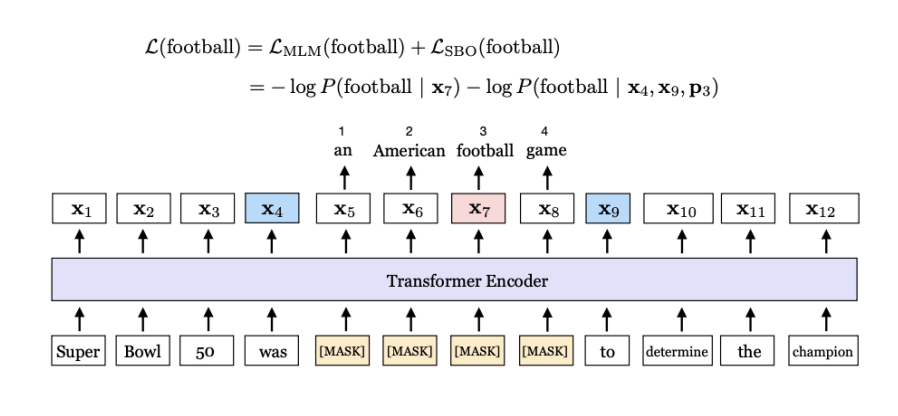
사실 이해가 잘 안되긴한다.
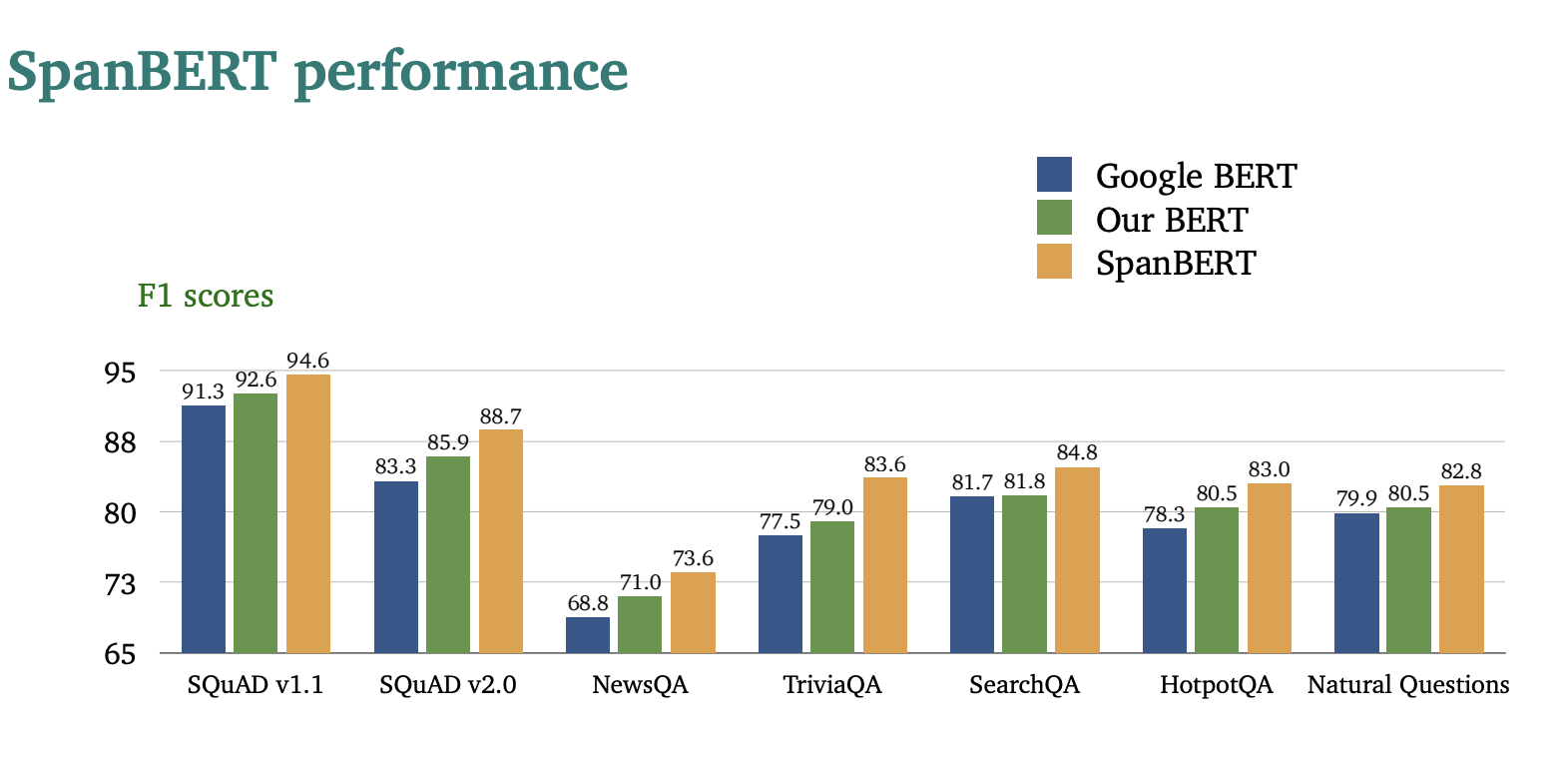
아무튼 기존 BERT보다 더 성능이 좋다고 한다.
한계점
그럼 독해력이 완전히 해결되었을까?
아니다!
-
우리의 현재 시스템은 공격적인 예제나 외부 도메인에 대해서는 잘 작동하지 않는다.
-
하나의 dataset에서 훈련된 것은 다른 dataset에서 잘 실행되지 않는다. -> SQuAD에서 학습된 모델은 TriviaQA에서 정확도가 낮은편.

-
그래서 (Ribeiro et al., 2020): Beyond Accuracy: Behavioral Testing of NLP Models with CheckList라는 논문이 있는데, 이는 NLP model을 테스트하기위한 여러 체크리스트를 작성한 글이다.
Open-domain quesion answering
Open domain에서는 더이상 주어진 passage만 고려하는 것이 아니다.
대신 우리는 대규모 문서 모음(위키피디아 같은)에만 접근할 수 있고, 우리가 찾는 답이 어디 있는지 모른다. 그래서 더 어렵지만 더 실용적인 문제이다!
Retriever-reader framework
정보 검색 및 질의 응답 시스템에서 사용되는 주요 구조 중 하나이다.
-
'Retriever'
역할 : 대규모 문서 집합에서 관련 문서나 정보를 빠르게 검색한다.
방법 : 키워드나 문장을 기반으로 문서를 검색한다. TF-IDF 같은 방법이나 BERT와 같은 검색 방법을 사용할 수 있다.
-> 가장 관련성이 높은 정보를 포함하고 있는 문서를 식별한다. -
'Reader'
역할 : Retriever가 선택한 문서를 분석해서 구체적인 답변을 찾아낸다.
방법 : 문서의 텍스트를 깊이 있게 분석해서 특정 질문에 대한 답변을 추출하거나 생성한다. GPT, BERT와 같은 모델이 사용된다.
-> 정확하고 구체적인 답변을 제공한다. 'Reading comprehension'에서 배운 내용과 같은 작업을 수행하는 것이다.
Train retriever
Retriever를 훈련하기 위해서 노력한 논문 두가지가 있다.
- Lee et al., 2019. Latent Retrieval for Weakly Supervised Open Domain Question Answering
: 각 텍스트 구절을 BERT룰 사용해 벡터로 인코딩.
retriever 점수는 문제 표현과 구절 표현사이의 내적으로 측정.
하지만 구절의 수가 매우 방대해서 모델링이 쉽지 않음
(위키피디아의 경우 2100만개)
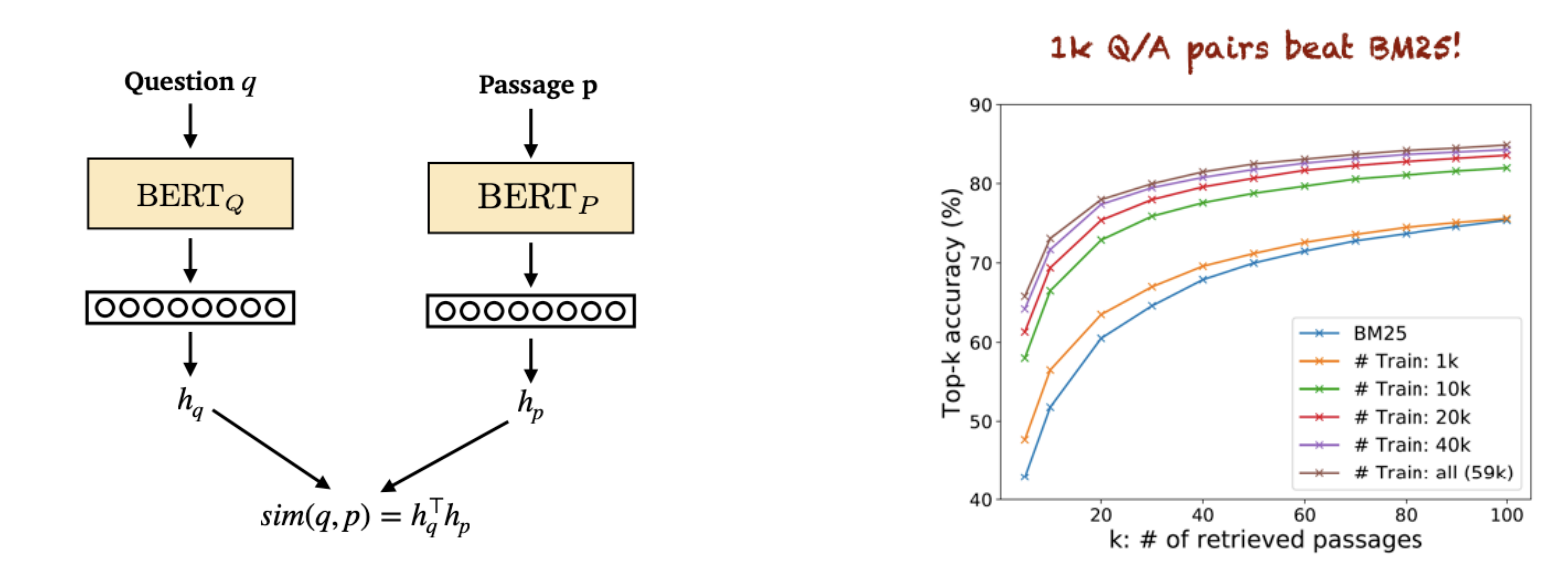
- Karpukhin et al., 2020. Dense Passage Retrieval for Open-Domain Question Answering
: 질문 답변 쌍만을 이용. 기존 IR보다 훨씬 더 잘 작동한다.
Without an explicit retriever stage
Retriever 구조가 항상 필요한 것은 아니다.
매우 큰 언어모델을 사용하는 경우, 공개 도메인을 통해 답변을 생산해낼 수 있다.
- Roberts et al., 2020. How Much Knowledge Can You Pack Into the Parameters of a Language Model?
Without an explicit reader stage
reader모델이 필요하지 않을 수 있다.
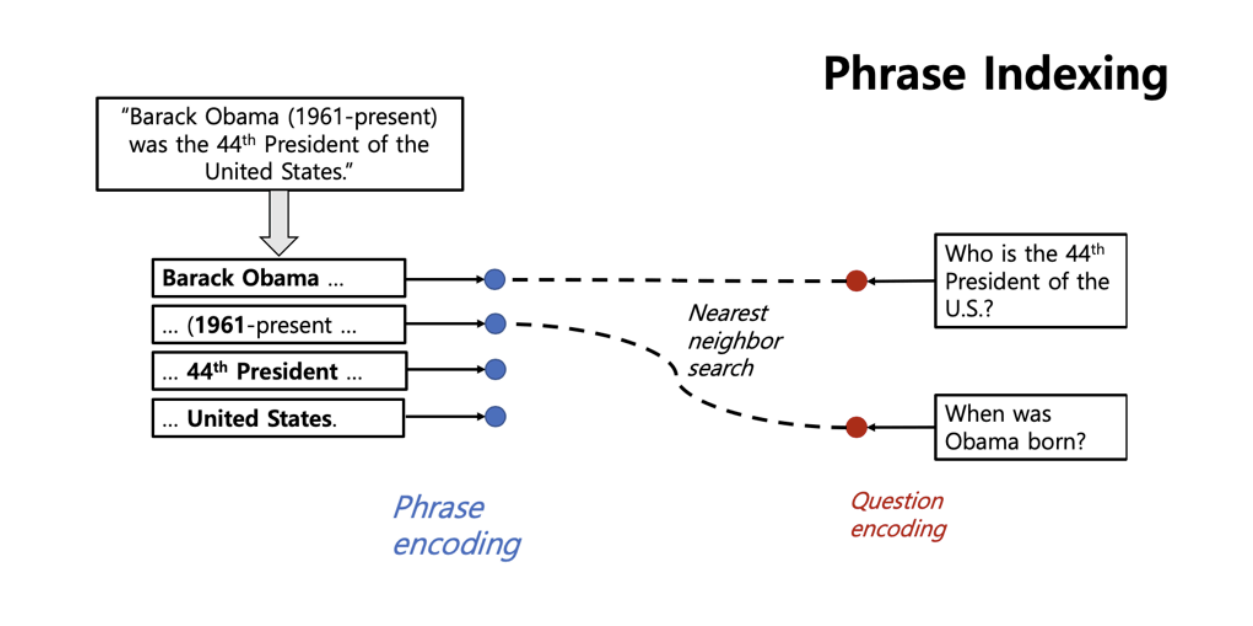
모든 위키피디아 글을 인코딩하고 질문을 선택하면 질문을 단일 벡터로 인코딩할 수 있다. 단일 벡터에서 가장 가까운 최근접이웃 알고리즘을 통해 임베딩 벡터를 구할 수 있다.
- Seo et al., 2019. Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
- Lee et al., 2020. Learning Dense Representations of Phrases at Scale
❤️끝❤️
