Lecture 13
이번 강의 내용이다!
Lecture Plan:
Lecture 16: Coreference Resolution
1. What is Coreference Resolution? (10 mins)
2. Applications of coreference resolution (5 mins)
3. Mention Detection (5 mins)
4. Some Linguistics: Types of Reference (5 mins)
Four Kinds of Coreference Resolution Models
5. Rule-based (Hobbs Algorithm) (10 mins)
6. Mention-pair and mention-ranking models (15 mins)
7. Interlude: ConvNets for language (sequences) (10 mins)
8. Current state-of-the-art neural coreference systems (10 mins)
9. Evaluation and current results (10 mins)
What is Coreference Resolution?
Corefernce Resolution은 동일한 항목을 지칭하는 것을 찾는 것이다.
아래 글을 보며 이해해보자.

빨간색 동그라미는 Vanaja를 가리킨다. 하지만 항상 이름을 적고 있지는 않다. her, she라는 다양한 대명사로도 Vanaja를 가리킨다. 우리는 쉽게 이해하고 찾을 수 있지만 기계는 문맥을 이해하여 무엇을 가리키고 있는지 찾아야한다.
Applications of coreference resolution
Corefernece resolution의 활용은 여러가지가 있다.
- 전체 텍스트 이해 : 문학 책에는 여러 대명사 표현이 있다. 이러한 대명사를 잘 이해해야 내용을 이해할 수 있다.
- 기계 번역
- 대화 시스템
“Book tickets to see James Bond”
“Spectre is playing near you at 2:00 and 3:00 today. How many tickets would you like?”
“Two tickets for the showing at three”
위 문장을 기계가 이해하려면
James Bond = Spectre
3:00 = three
How many tickets = Two
라는 것을 이해해야 한다.
이러한 Coreference Resolution을 해결하는 단계가 2가지 있다.
1. Detect the mentions
2. Cluster the mentions
Mention Detection
Mention detection은 언급되는 단어를 찾는 것이다. 비교적 의미를 해석해야하는 Cluster the mentions단계보다는 쉽다.
Mentions에는 3가지 종류가 있다.
- Pronouns(대명사)
- Named entities : 사람, 장소, 브랜드 이름 등 예) 나이키, 파리, 서울
- Noun phrases: ex) a dog, the big fluffy cat stuck in the tree
종류에 따라 다른 방법을 사용한다.
- Pronouns -> part of speech tagger
- Named entities -> Named Entity Recognition system
- Noun phrases -> parser (특히 constituency parser)
쉽게 언급되는 것들을 찾을 수 있다고 생각하겠지만, 사실은 그렇게 간단하지 않다. 다음 Mentions들에 대해서 생각해보자.
• It is sunny
• Every student
• No student
• The best donut in the world
• 100 miles
이러한 bad mentions들을 어떻게 피할 것인가?
간단한 방법은 우선 모든 mentions을 후보 멘션들로 지정해두고, 상호 연결되지 않은 것들을 모두 삭제하는 방법이 있다.
이 방법은 너무 ^구식^ 방법이니까 POS tagger, Ner system을 이용하는 방법도 있다. 또한 mention-dection과 coreference resolution을 동시에 해결하는 방법도 있다. 이건 좀이따 배울 것• Rule-based (pronominal anaphora resolution)
• Mention Pair
• Mention Ranking
• Clustering [skipping this year; see Clark and Manning (2016)]이다.
Some Linguistics: Types of Reference
Coreference를 배우기 전 언어학을 살짝 다뤄보자.
Coreference는 같은 entity를 부르는 두가지 멘션이 있을 때를 의미한다.
- Barach Obama traveled to ... Obama ...
그런데, Anaphora라는 것도 있다. 이는 문장이나 구절에서 연속적으로 반복되는 단어나 구절을 사용하는 수사학적 기법이라 한다.
여기서는 예시로 다음 문장을 들었다.
Barack Obama said he would sign the bill.
여기서 Barack Obama는 antecedent가 되고, he는 anaphor이다.
Anaphora
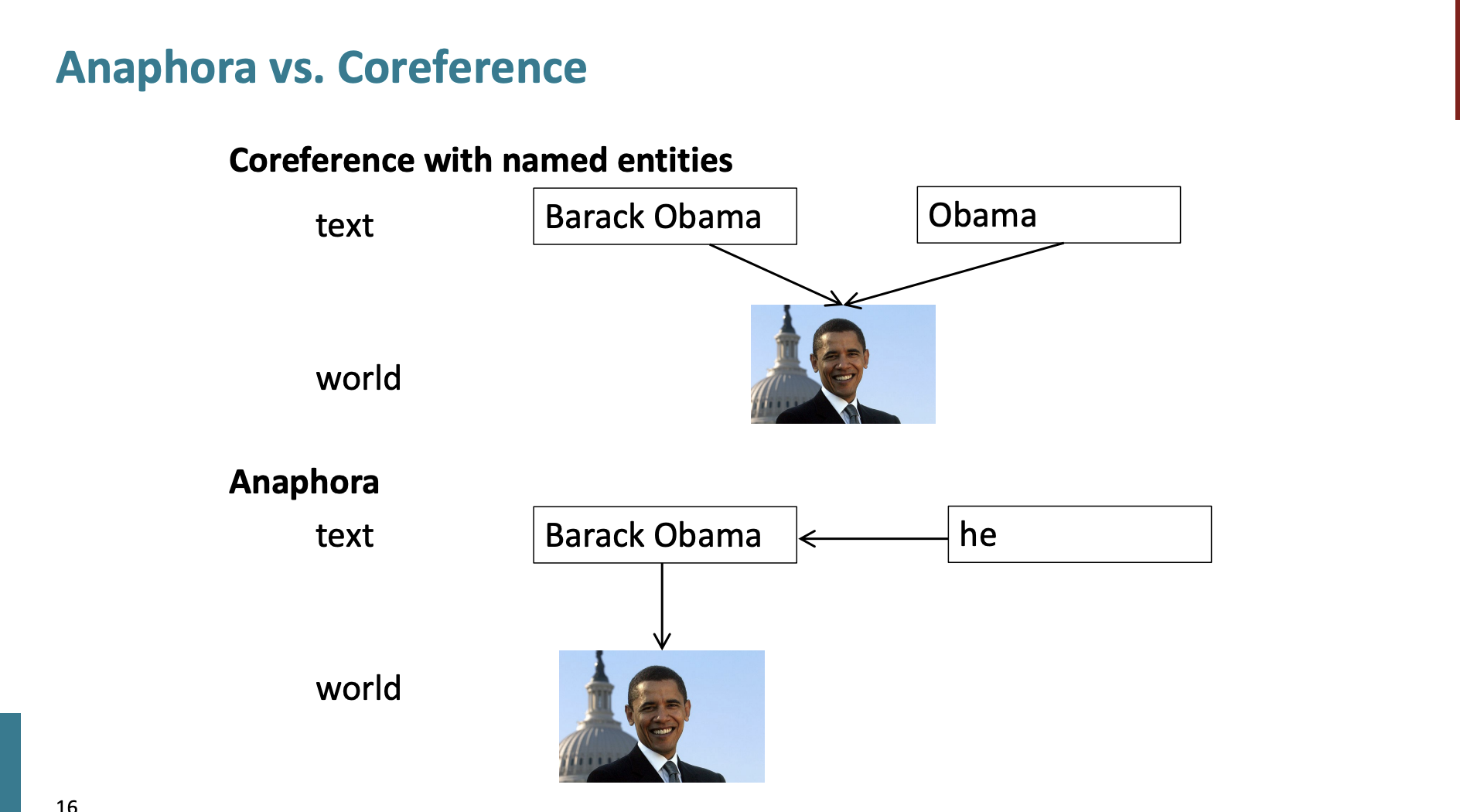
중요한 차이가 있다.
Coreference는 world에서 같은 entity를 가리키지만, Anaphora에서는 일단 text의 다른 단어를 가리킨 다음, 그 단어가 world에서 하나의 entity를 가리킨다고 한다.
그럼 모든 anaphora가 coreferenctial 할 까?
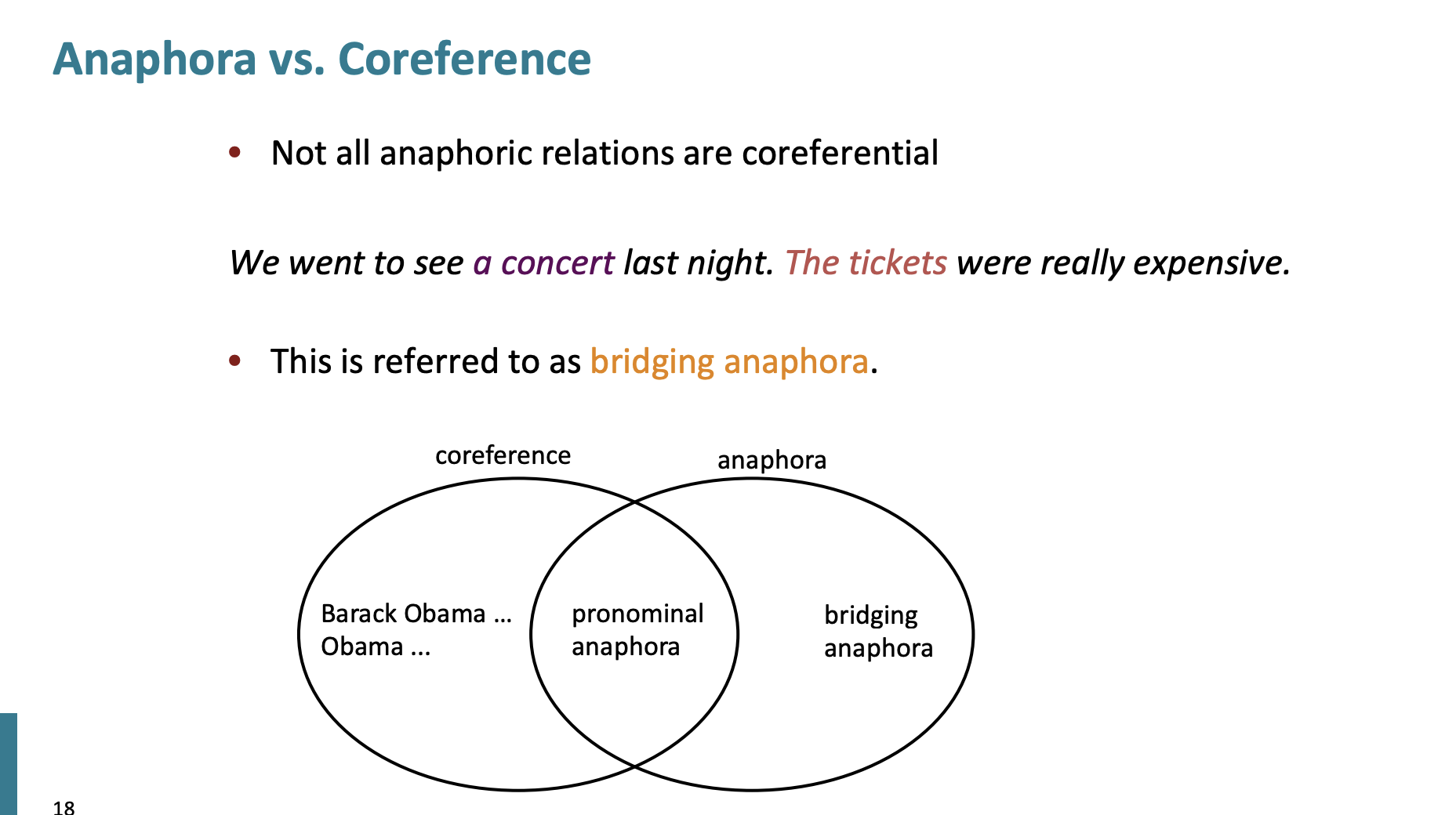
아니라고 한다.
We went to see a concert last night. The tickets were really expensive.
이 문장은 bridging anaphora라고 하며 coreference 가 아니라고 한다.
일단 Bridging Anaphora는 두번째 문장이 첫번째 문장의 일부 정보에 의존하는 경우를 말한다. 하지만 이 의존관계는 coreference보다 더 간접적이다. 예제에서 "The tickets were really expensive."라는 문장은 첫번째 문장 정보에 의존한다. '티켓'은 첫번째 문장에 직접적으로 언급되지는 않았지만 콘서트를 보러갔다는 맥락에서 자연스럽게 연결된다.
Coreference는 두 개 이상의 표현이 동일한 개체나 사건을 참조할 때 발생한다. '티켓'은 콘서트에 대한 간접적 참조일 뿐, 첫번째 문장에 있는 어떤 요소와도 정확히 일치하지 않는다.
Cataphora
Cataphora는 나중에 나오는 단어나 구절을 미리 참조하는 것이다.
한국어로 따지면,
그는 잘생겼다. 박지성은 무대에서 빛이 난다.
이렇게 작성할 수 있다. 여기서 '그'는 카타포라적 사용 예시이다.
정리
- 언어는 "문맥"상에서 해석되어야 한다.
- 우리는 "단어 의미 명확성"에서 몇가지 예시를 봤다. 예를 들면, "I took money out of the bank vs. The boat disembarked from the bank"
- Coreference의 예시는 다음과 같은 것이다.
Obama was the president of the U.S. from 2008 to 2016. He was born in Hawaii
그럼 Coreference Model에는 뭐가 있을까?
• Rule-based (pronominal anaphora resolution)
• Mention Pair
• Mention Ranking
• Clustering [skipping this year; see Clark and Manning (2016)]
Rule-based
아주 아주 구식적인 방법이다. 하지만 최근 7년을 제외하고 이 rule-based 방법을 잘 썼다고 한다. 이 알고리즘은 Hobbs’ naive algorithm 라고도 한다.
알고리즘 순서는 다음과 같다.
- Begin at the NP immediately dominating the pronoun
- Go up tree to first NP or S. Call this X, and the path p.
- Traverse all branches below X to the left of p, left-to-right, breadth-first. Propose as
antecedent any NP that has a NP or S between it and X - If X is the highest S in the sentence, traverse the parse trees of the previous sentences
in the order of recency. Traverse each tree left-to-right, breadth first. When an NP is
encountered, propose as antecedent. If X not the highest node, go to step 5. - From node X, go up the tree to the first NP or S. Call it X, and the path p.
- If X is an NP and the path p to X came from a non-head phrase of X (a specifier or adjunct,
such as a possessive, PP, apposition, or relative clause), propose X as antecedent
(The original said “did not pass through the N’ that X immediately dominates”, but
the Penn Treebank grammar lacks N’ nodes….) - Traverse all branches below X to the left of the path, in a left-to-right, breadth first
manner. Propose any NP encountered as the antecedent - If X is an S node, traverse all branches of X to the right of the path but do not go
below any NP or S encountered. Propose any NP as the antecedent. - Go to step 4
홉 알고리즘에 대한 자세한 설명은 넘길 것이다. 우리에겐 크게 중요한 내용은 아니다. 홉 알고리즘은 많은 오류가 있었고, 성능이 좋지 않다.
Mention-pair and mention-ranking models

이 예시를 보자.
일단 이진 분류기를 학습시킨다.
모든 멘션 쌍에 대한 확률을 계산한다.
=> 'she'의 경우 모든 후보 선행어를 살펴보고 어떤것이 핵심적인 것인지 결정한다.
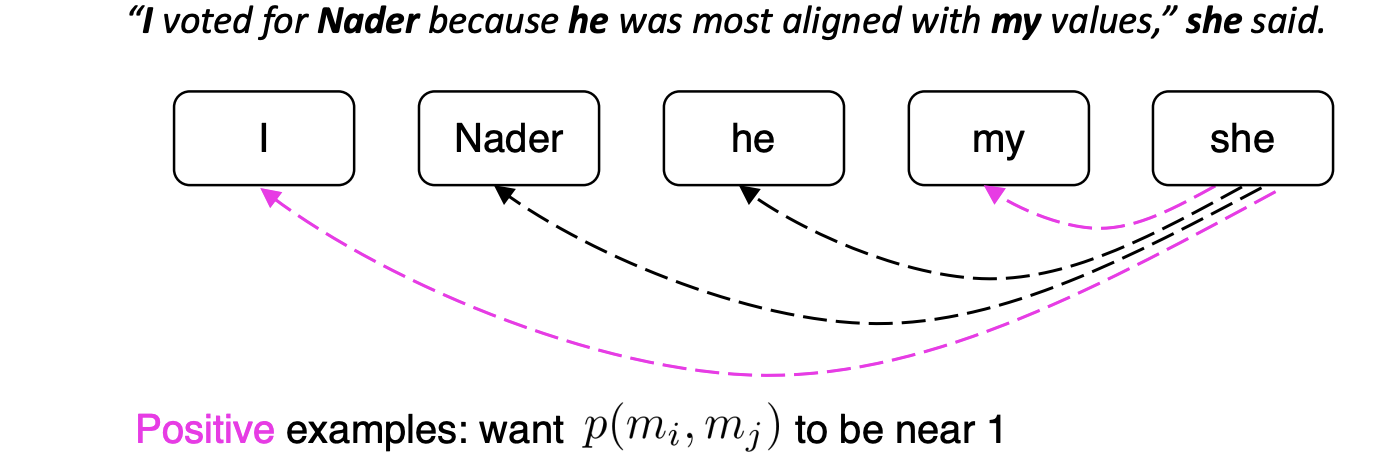
1과 가까운 확률 예시들은 I, my가 있다.
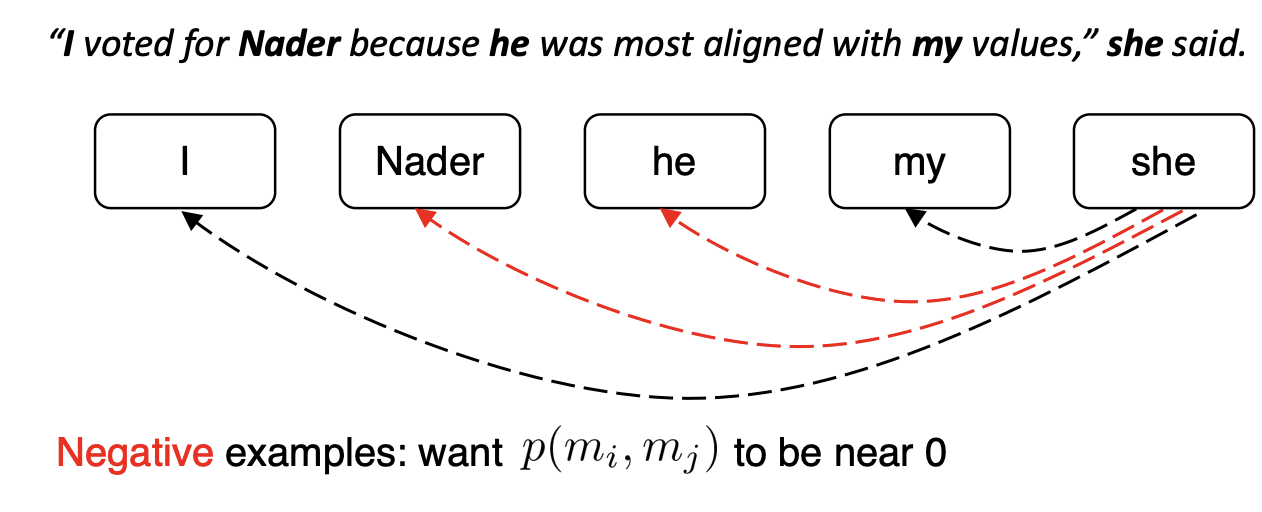
0과 가까운 확률 예시들은 Nader, he가 있다.
Training
- N 은 document 내의 mention 수이다.
- 가 1이면 coreferent, -1이면 그 반대를 의미한다.
- regular cross-entropy loss로 훈련한다.
Test Time
- Threshold 를 넘는 몇가지를 고른다음
- coreference links를 연결한다.
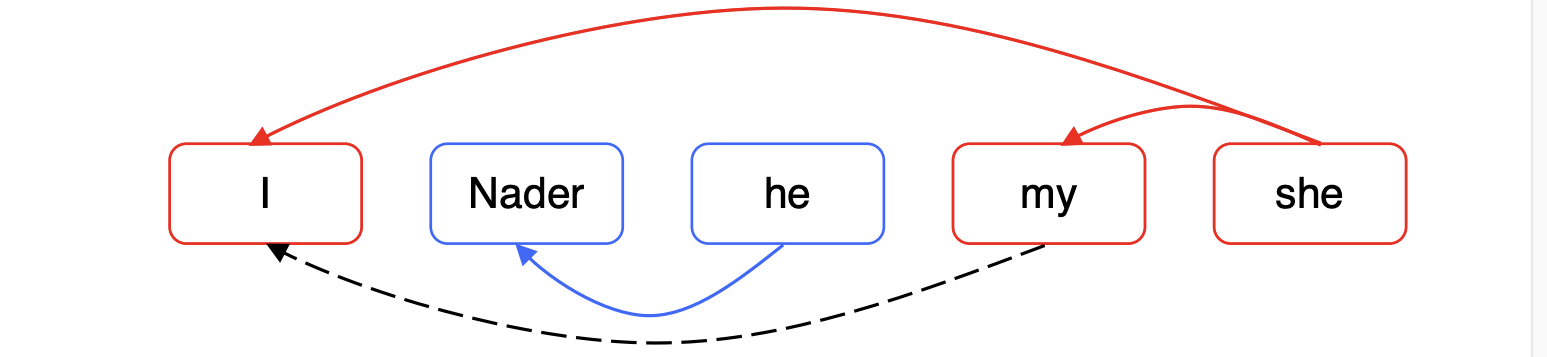
만약 coreference link를 연결하지 못했어도, I와 my는 transitivity(전이성) 때문에 coreferent된다.
하지만 전이성 때문에 잘못된 연결 하나만 되어도 전체 클러스터에 영향을 주는 단점이 있다.
Disadvantage
다음과 같은 내용이 포함된 document가 있다고 하자.
Ralph Nader … he … his … him … voted for Nader because he …
- 많은 mentions은 오직 하나의 clear한 전례(antecedent)를 가지고 있다. 하지만 우리는 모델에게 그들 모두에 대해 예측하도록 해야한다.
- 이 해결방법은 각 멘션에 대해서 하나의 전례만을 찾도록 훈련하는 대신 다양하고 그럴듯한 전례를 찾도록 하는 방법이다.
Mention Ranking
NA I Nader he my she
라는 mention 더미들을 보자.
NA는 이전에는 없던 mention 더미이다.
'she'와 가장 잘 맞는 전례는 무엇인가? 우리는 각 mentions에 대해서 예/아니오라는 이진 분류기를 사용하는 대신에 하나의 분류를 선택하는 것이다. 우리는 소프트맥스 분류기를 사용할 수 있다.
NA 더미 멘션을 통해서 현재 멘션과 아무것도 연결하지 않을 수 있다.
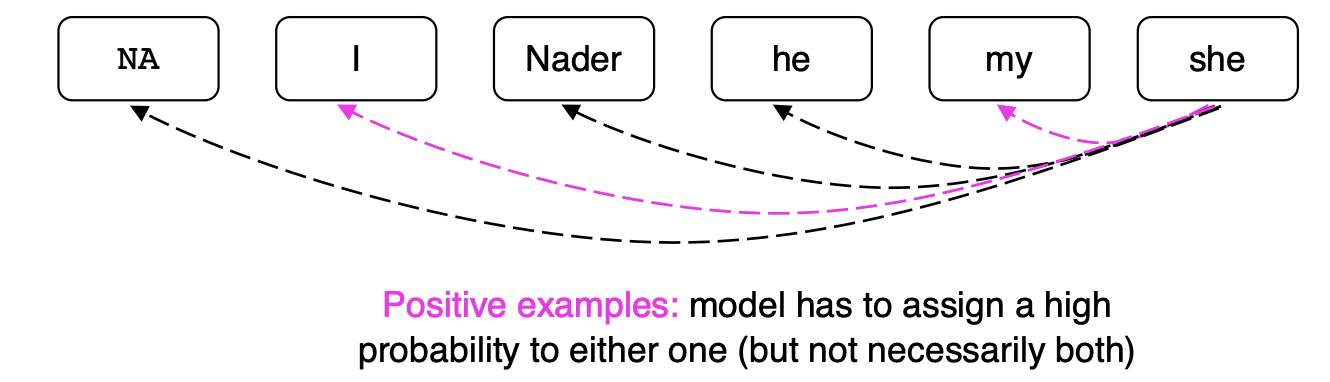
모델은 둘 중에 높은 확률에 대한 더미 하나만 선택할 수 있다.
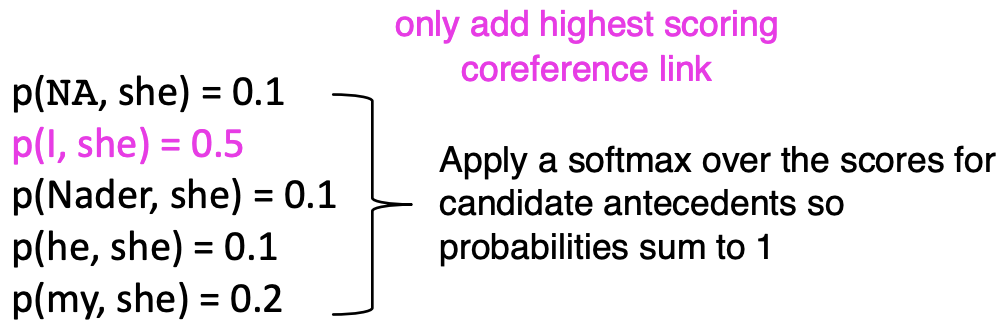
softmax를 통해서 가장 높은 확률 하나를 선택해서 coreference link를 연결한다.
식은 다음과 같다.
는 현재 mention을 의미한다.
그럼 어떻게 확률을 계산할까?
Probabilities
A. Non-neural statistical classifier
B. Simple neural network
C. More advanced model using LSTMs, attention, transformers
Neural Coref Model
Neural Coref Model는 신경망 구조를 가지고 있다.
Input layer에는 단어 임베딩과 몇개의 종류 feature들이 들어간다.
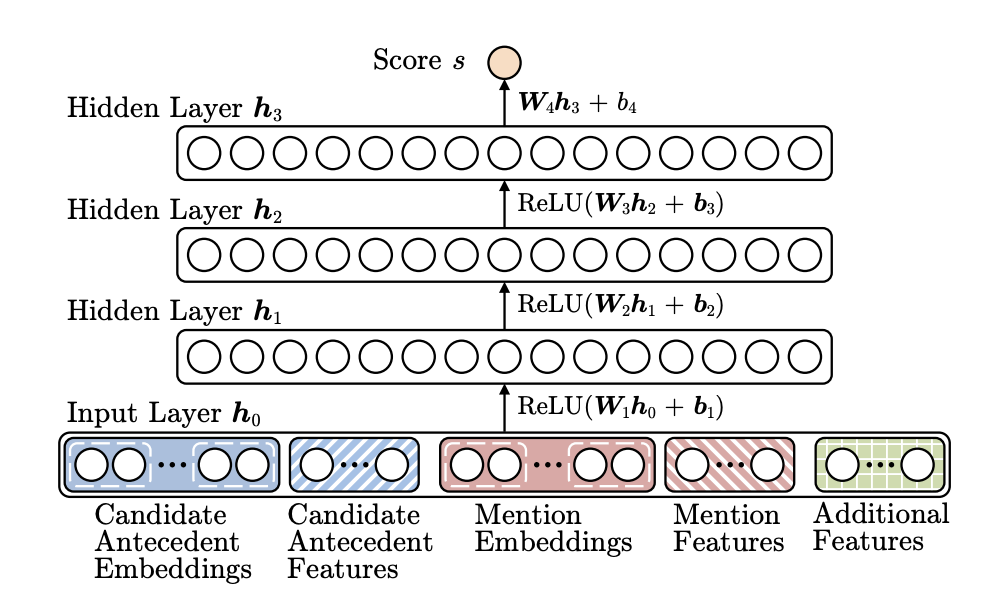
feature에는 다음 것들이 있다. 이들은 모델 성능을 더욱 강화시킨다.
- Distance
- Document genre
- Speaker information
Convolutional Neural Nets
여기서는 아주 간단하게만 CNN에 대해 살펴보자. 더 자세한 내용은 231N을 참조하길 바란다.
예를 들어 텍스트에 대해서 1D convolution 을 수행해보자.
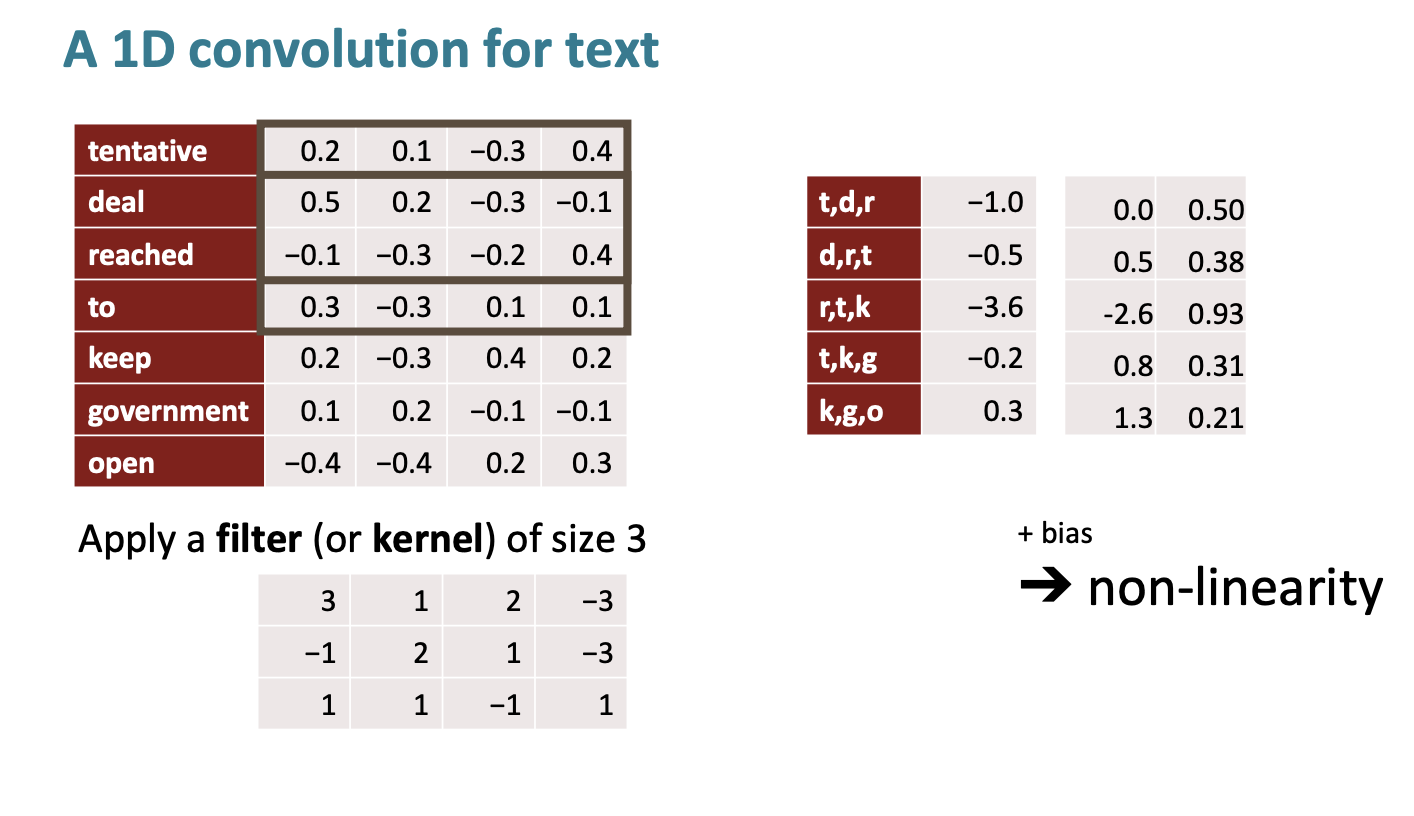
0.2 3 + 0.1 1 + -0.3 * 2 + ... 를 수행해서 t,d,r을 수행한 결과는 -1.0이다. 이렇게 cnn을 수행하면 크기가 줄어드는 것을 확인할 수 있다.
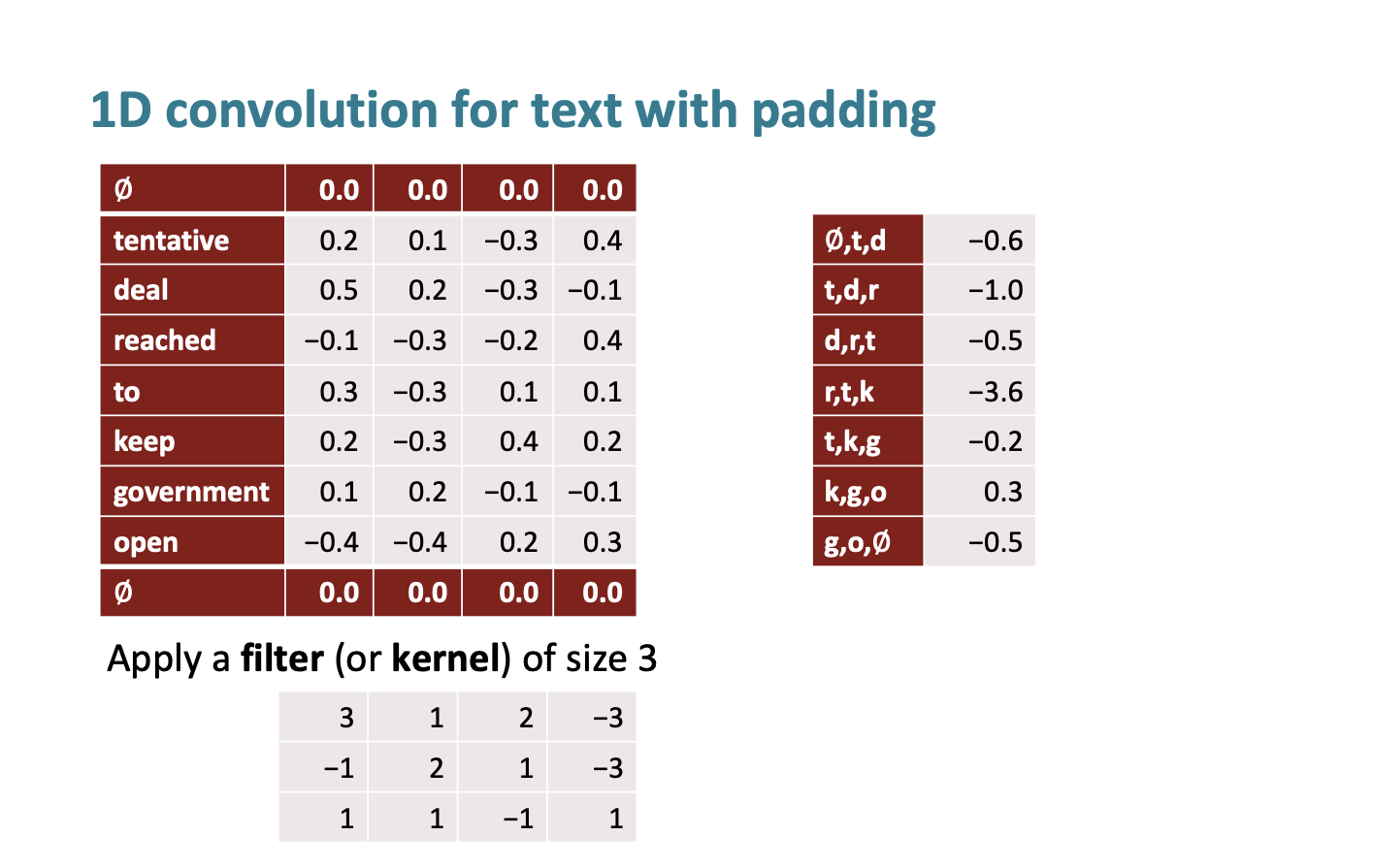
그래서 위 아래에 zero padding을 추가해서 크기가 줄어드는 것을 방지할 수 있다.
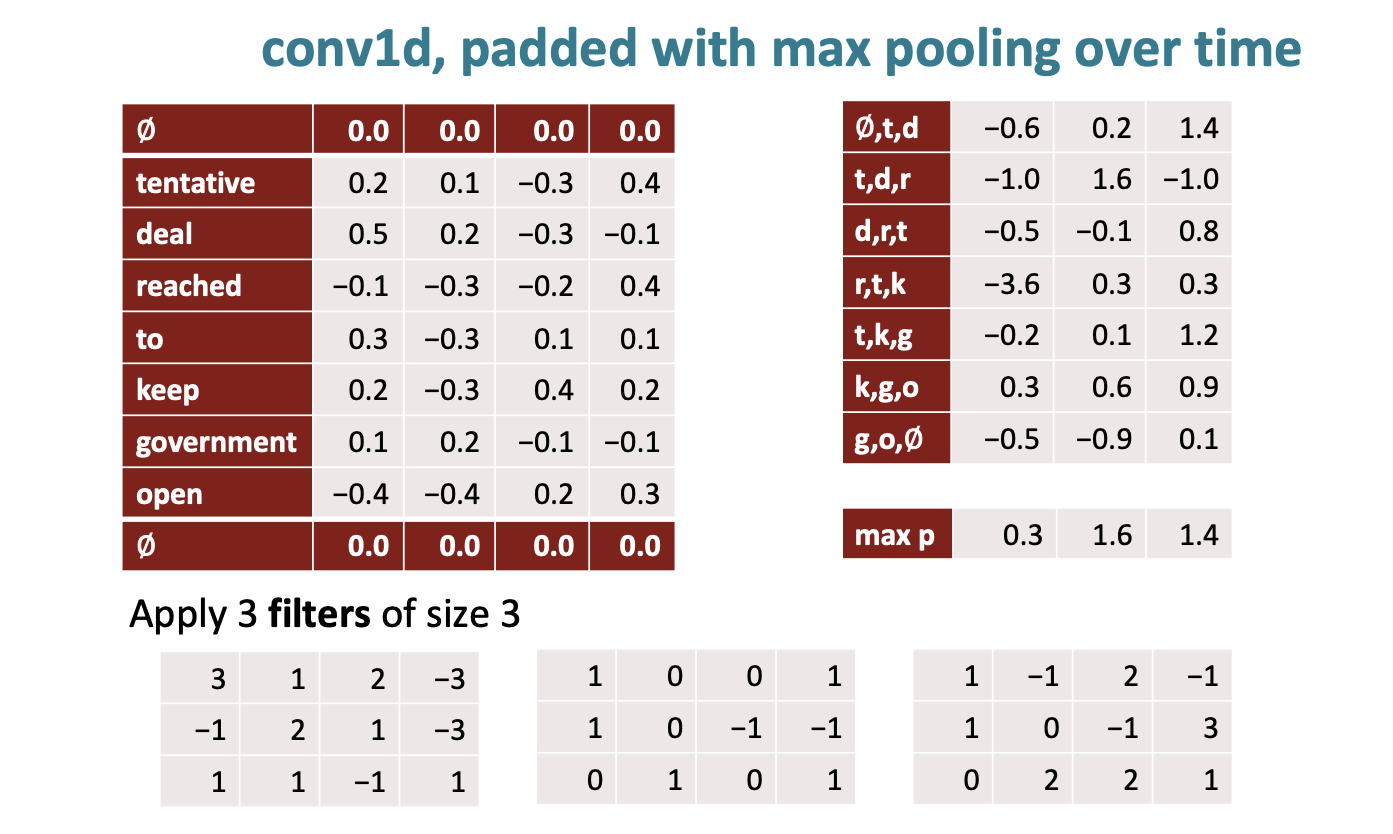
Pooling을 통해서 크기를 완전히 줄일 수도 있다. 가장 큰 숫자를 선택하는 max pooling 을 수행하는 것이 일반적이다.
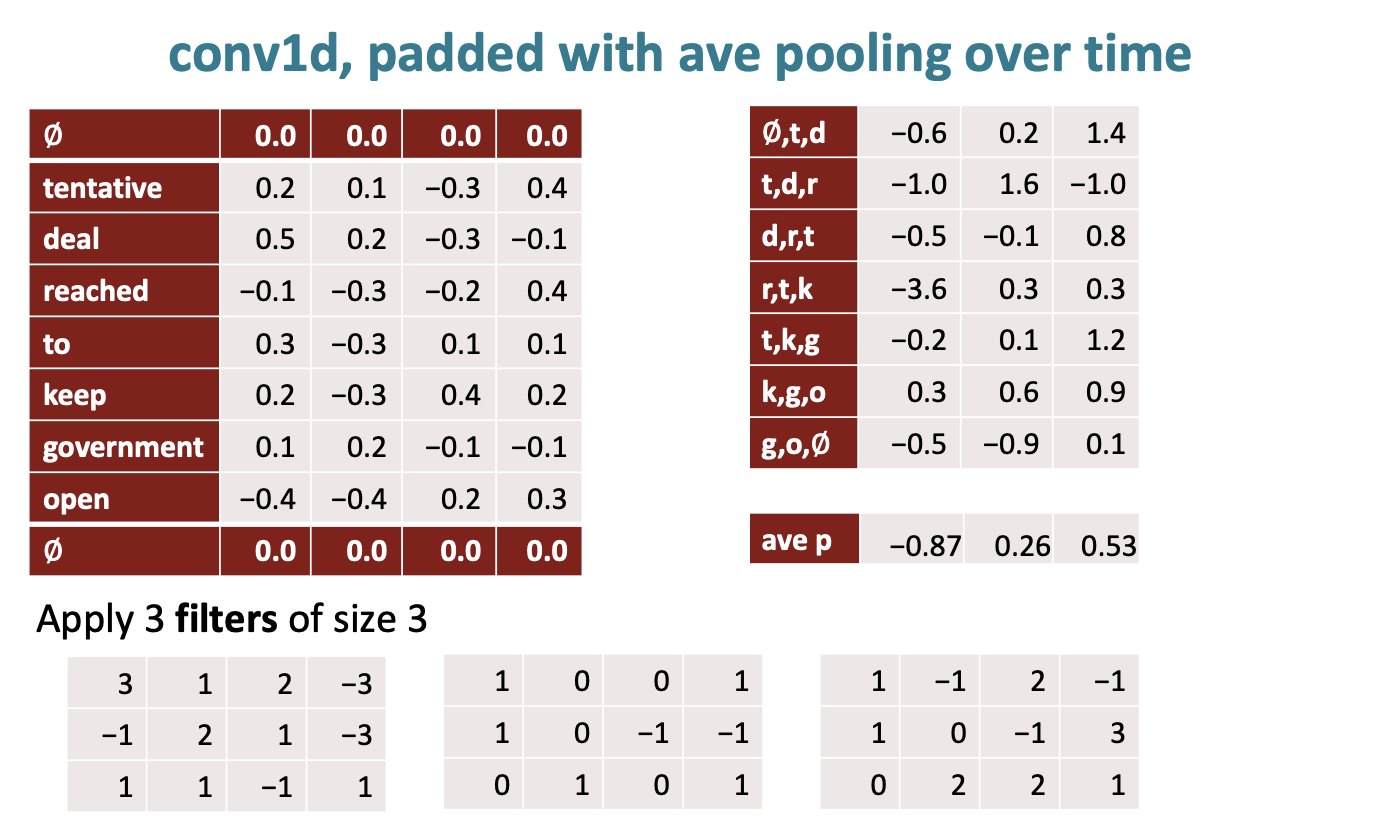
하지만 평균을 계산한는 방법인 average pooling을 수행할 수도 있다. 그치만 max pooling이 좀 더 효과적이라 한다.
End-to-end Neural Coref Model
완전 최신 기술은 아니지만, coreference resolution으로 mention detection과 coreference 를 end-to-end로 수행하는 방법이 있다.
Kenten Lee가 2017년에 발표했다.
이 모델은
- Mention ranking model이고
- LSTM을 사용한다.
- Attention을 사용한다.
이 방법은
1. 단어 임베딩 행렬과 문자 수준의 CNN을 사용하여 문서의 단어를 포함한다.
2. 전체 document에서 양방향 LSTM을 수행한다.
3. START(i) 에서 END(i)로 가는 텍스트 i를 벡터로 표현한다.
4. General, General Electric, General Electric said, …, Electric, Electric said 는 모두 각각의 벡터 표현을 가지게 된다.
5. 그리고 span representation을 구한다. 예를 들어서 "the postal serviece" 를 보자.
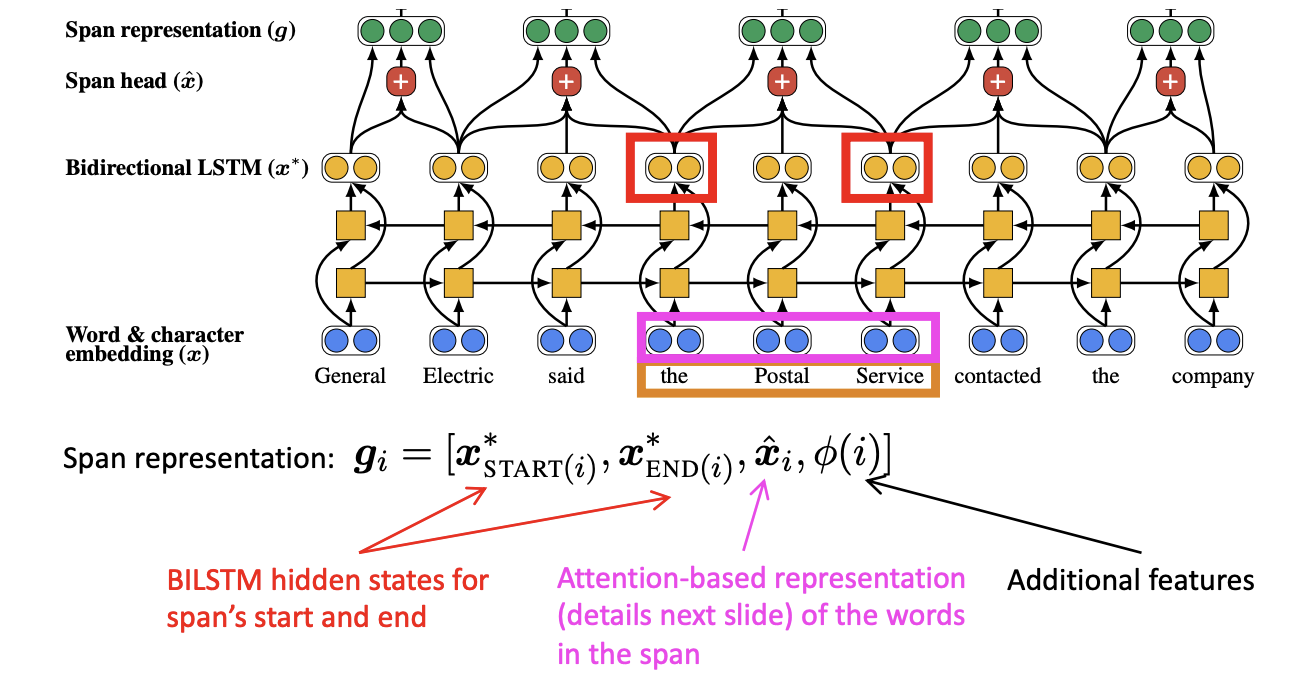
span representation 를 보자. 첫번째는 span의 시작과 끝에 대한 양방향 LSTM의 히든 state이다. -> span의 왼쪽 오른쪽 문맥을 표현한다.
두번째는 span내부의 단어들에 대한 Attention기반 표현이다. -> span자체를 표현한다.
마지막 세번째는 추가적인 특징들이다. -> text에 표현되지 않는 다른 정보를 표현한다.
는 span내에서의 단어 임베딩의 어텐션 가중치 평균이다.

- 마지막으로 그들이 coreferent mention인지 아닌지 결정하기 위해서 모든 쌍의 span들을 계삲나다.
의 의미는 i가 mention인가? 물어보는 것이다.
의 의미는 그들이 coreferent로 보이는가? 물어보는 것이다.

하지만 모든 쌍의 span에 대해서 계산하기 힘들다는 단점이 있다. 그래서 Attention을 통해서 어떤 단어가 mention 중 중요한 단어인지 배우고 그들을 중심으로 계산한다고 한다.
위 end-to-end model은 이전에 말했듯, 완전 최신 모델은 아니라 했다.
요즘은 BERT 기술을 사용한다고 한다.
BERT
Idea 1 : SpanBERT 처럼 사전 훈련된 BERT 모델은 coref 와 QA같은 span-based된 예측 task를 잘 수행한다.
Idea 2 : 이전에 우린 QA에 대해 배웠다. QA 또한 BERT를 활용하는데, 질문을 통해 어떤 mention이 어떤 entity를 가리키는지 물어볼 수 있고 그에 대한 답으로 해결할 수도 있다.
“what is its antecedent?”
Answer span이 coreference link가 되는 것이다.
평가는 넘어간다(수업에서 다루지 않음)
System Performance
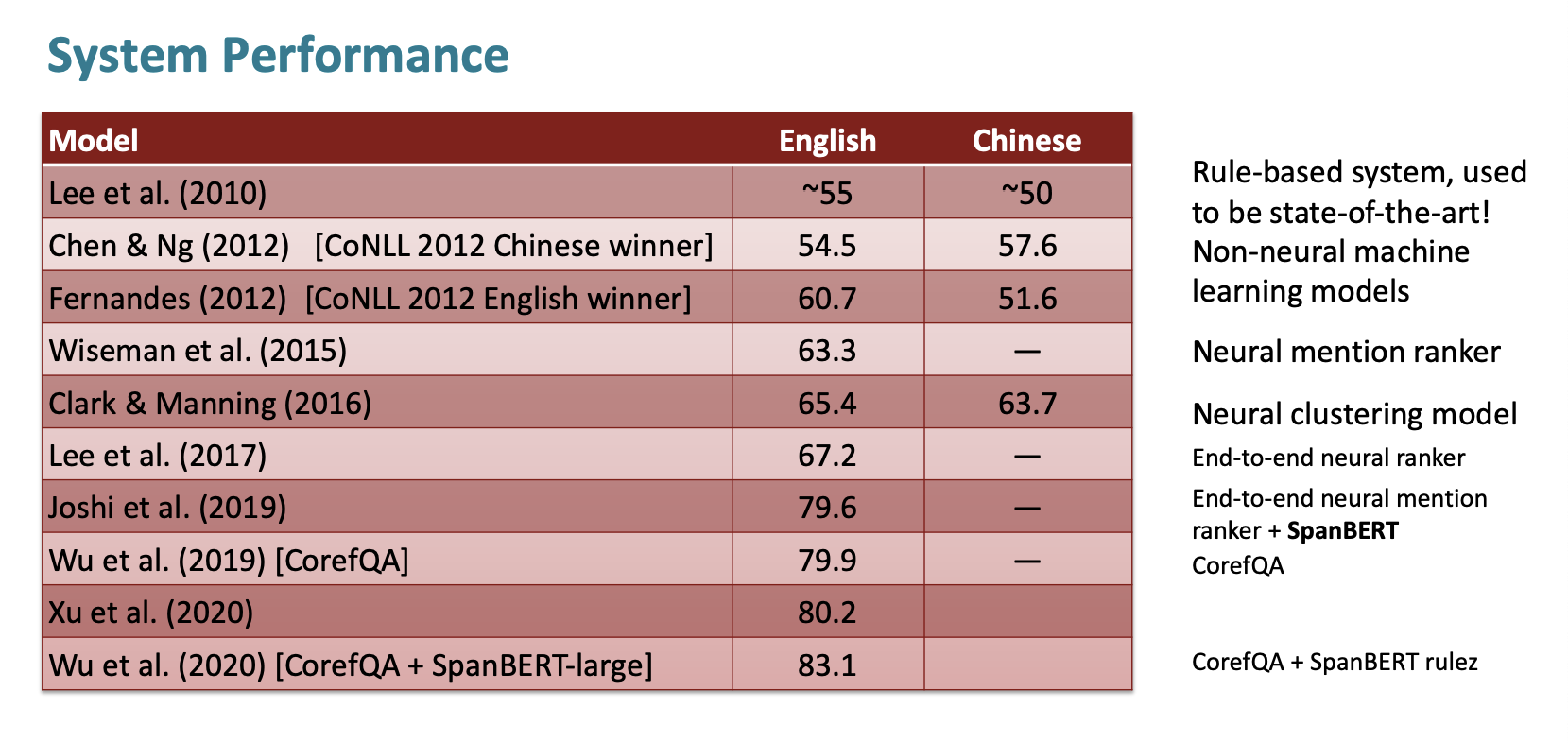
맨처음 Lee et a.(2010)은 Rule-based system이다. 얼마나 규칙 기반 시스템이 잘 작동하는지 알기위해 수행했다고 한다.
그 다음 Clark & Manning이 2016년에 수행한 것은 Neural clustering model이다.
그 다음 Lee et al.(2017)은 아까 전에 살펴본 end-to-end neural ranker이다.
그리고 갑자기 Joshi et al(2019)에서 정확도가 10% 높게 상승했는데 이때 SpanBERT를 활용했다고 한다.
제일 정확도가 높은 Wu et a.(2020)은 CoreQA와 SpanBERT-large를 모두 활용해서 83.1%의 정확도를 기록했다.
오늘은 2024년 1월1일!
모두 새해 복 많이 받으시고 올해 좋은 일만 가득가득가득하길 바랍니다!
