Lecture 7
강의 내용
- Machine Translation
- seq2seq
- attention
Pre-Neural Machine Translation
기계번역의 역사부터 알아보자.
이전 최초의 기계번역의 시도는 냉전시기 러시아어을 영어로 번역하여 우위를 점하기 위해서 영국에서 시작되었다. 단순한 규칙 기반 방법으로 러시아-영어 사전을 구축해서 영어단어를 찾는 방식이지만, 너무나 원시적인 방법이라 그닥 성능은 좋지 않았다.
Statistical Machine Translation
1990년~2010년까지 확률적 통계 기반 모델로 번역을 시도했다.
- 만약 우리가 프랑스어를 영어로 번역한다고 하자.
- 프랑스 문장 x가 주어졌을 때, 가장 좋은 영어 문장 y를 찾는다고 하자.
- 로 찾을 수 있고 이는 베이지안 방법으로 풀어내면
- 로 풀어낼 수 있다.
- 위 식은 두항으로 나눠져 있다.
- P(x|y): 영어->프랑스어 문장으로 translation model로 병렬적 데이터 통해 학습시키는 번역 모델이다.-
P(y) : 기존 언어 모델이다. 현재 y의 문장이 얼마나 자연스러운지 확률 분포를 통해 알 수 있다.
P(y)는 기존 언어모델을 사용하면 되는데, P(x|y)는 어떻게 학습시킬까?
-
Learning alignment
a 라는 추가 변수를 만들어서 모델에 학습을 시킨다.
a는 alignment이다. "정렬"인데 정렬은 단어 단위 동치 관계를 의미한다.
마치 I <=> 나 와 같은 관계이다.
Alignment
프랑스어 -> 영어로 번역을 할 때 단어와 단어는 1:1 대응을 할 수 있다.
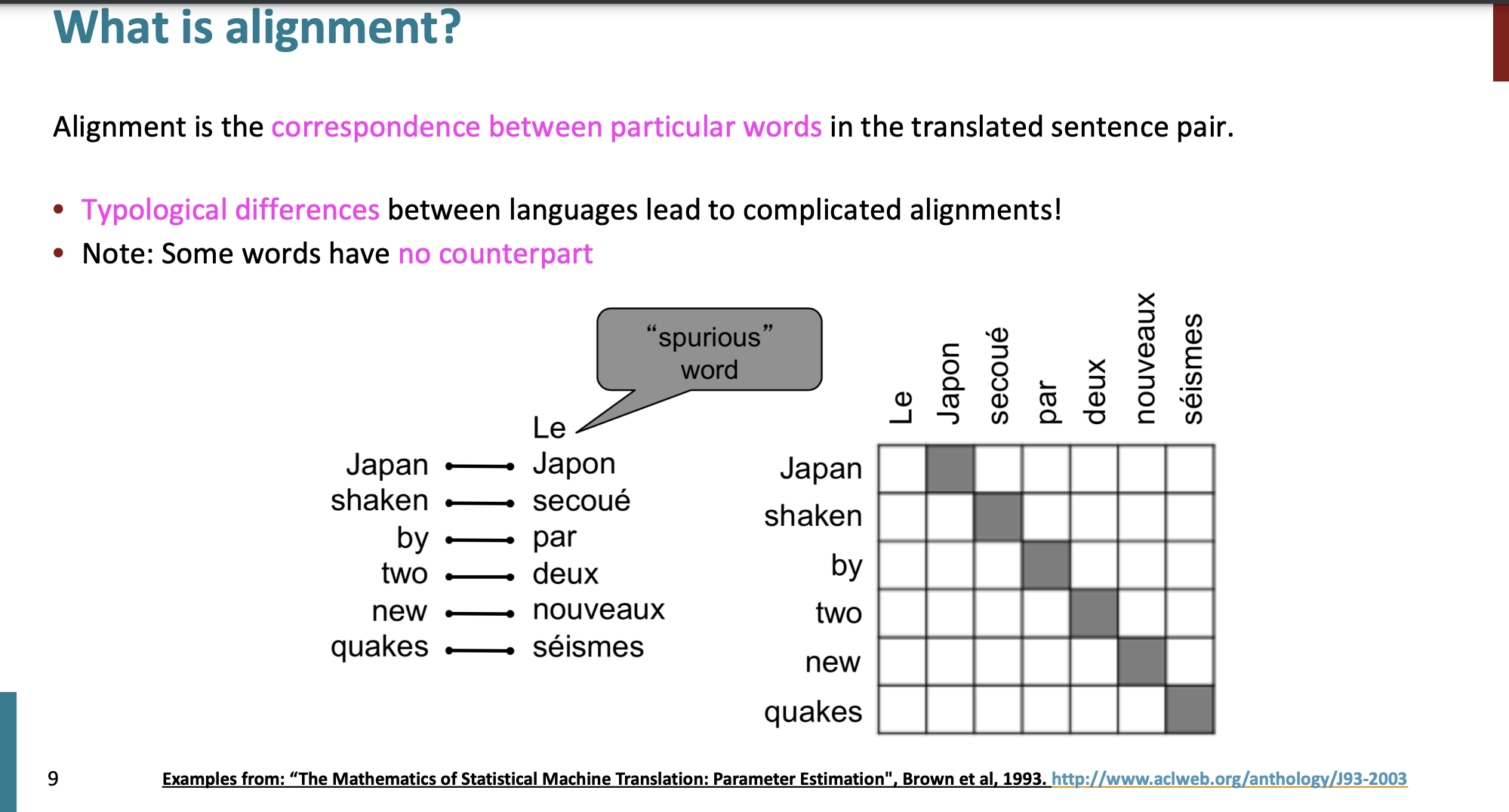
하지만 다 1:1 번역이 되는건 아니다.
Many to one
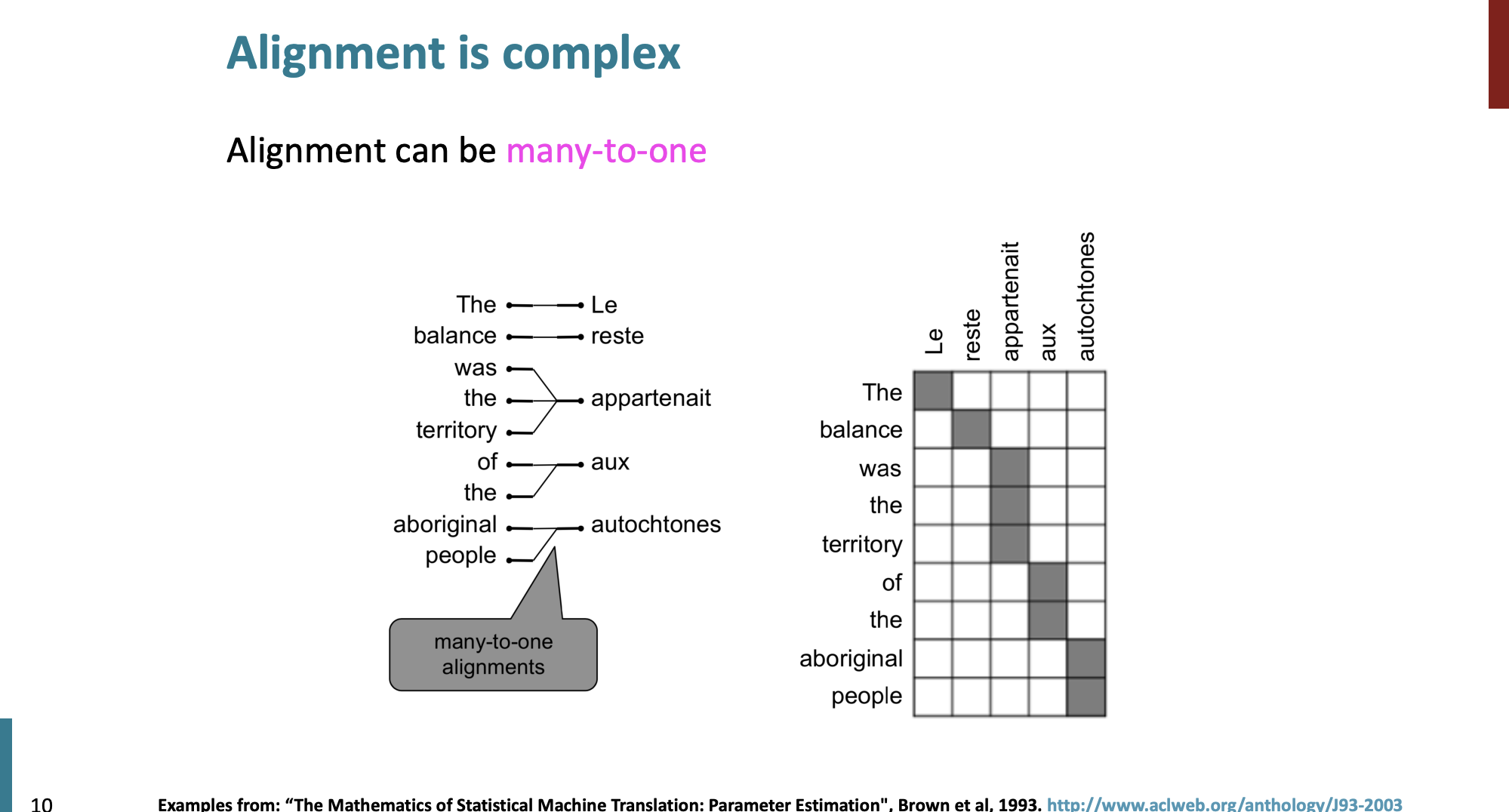
여러 단어가 하나의 프랑스어 단어에 대응될 수 있고,
One to Many
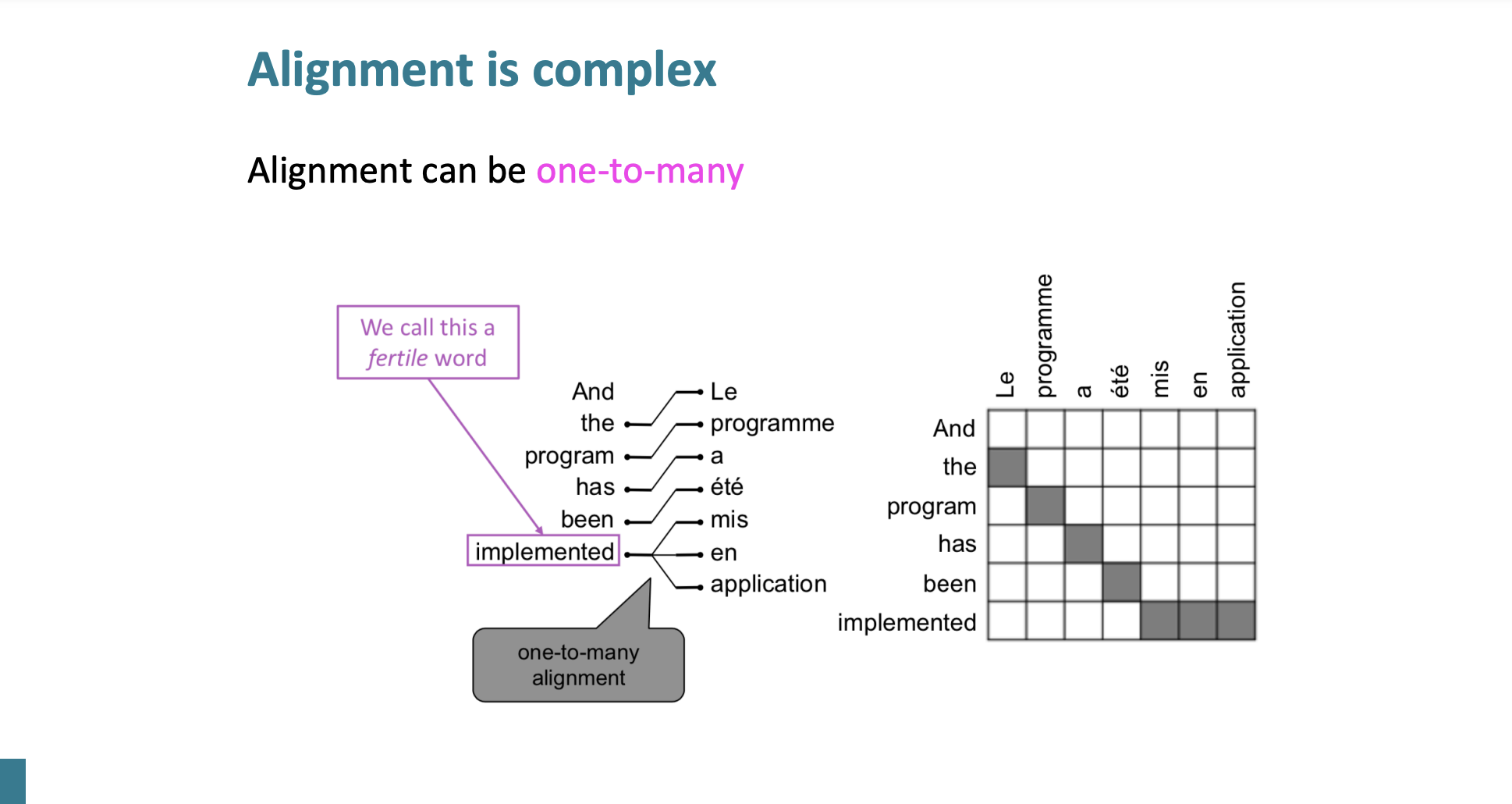
하나의 단어가 여러 프랑스어 단어에 대응될 수 있다.
Many to many
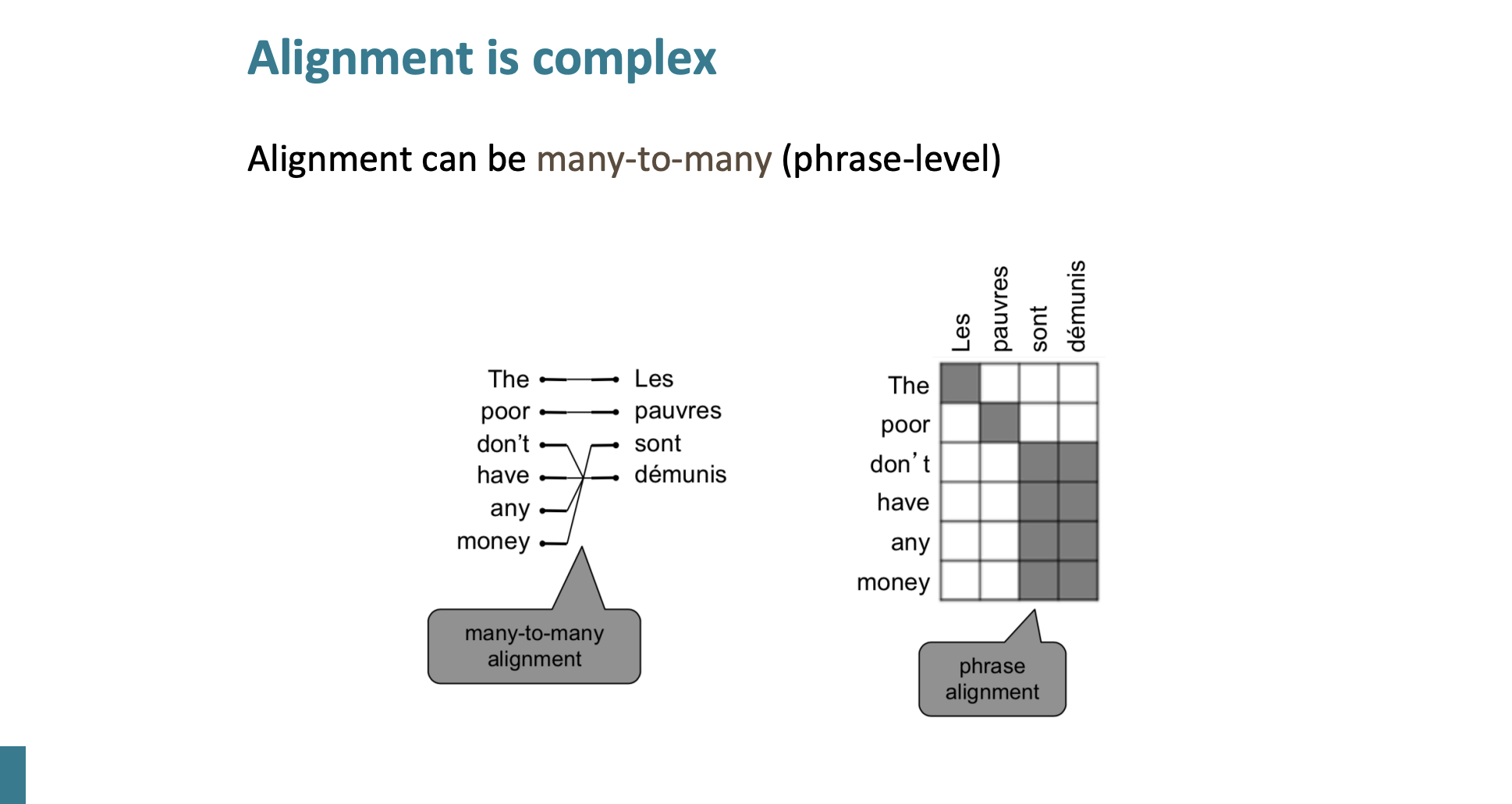
또는 단어 여러개가 여러 프랑스어 단어에 대응될 수 있다.
이처럼 번역은 단순 단어끼리 매칭으로 할 수 없다.
그래서 가장 좋은 방법은 사실 모든 영어 단어를 조합해서 가장 좋은 확률을 찾아내는 것이다. 그런데 이렇게 계산하면 너무 Expensive 하고 비효율적이다.
또 다른 해결방법이 있다. 바로 Decoding이다.
Decoding
지금 자세하게 설명을 하진 않겠다. 하지만 가장 높은 확률의 단어를 선택했을 때, 나머지의 경우의 수를 모두 잘라내는 방식이다.
Summary
- 2010년 까지 주류를 이끈 연구분야이다.
- 많이 세분화된 디자인의 서브컴포넌트들이 많았다.
- 유지하는데 너무 많은 사람의 인력이 투입된다.
Neural Machine Translation
신경망 기계 번역이 2014년에 등장하면서 엄청난 발전이 일어났다.
이때 사용했던 모델을 seq2seq라 하는데 말 그대로 문장->문장 이다.
당시 사용된 구조는 Encoder의 RNN, Decoder에 RNN이다.
모델 구조
모델 구조는 위처럼 Encoder, Decoder에 RNN 구조로 되어있다.
Encoder RNN은 소스 문장의 인코딩을 만들고
Decoder RNN은 ecoding에 기반해서 타겟문장을 만들어낸다.
마지막 hidden state는 프랑스어 문장의 정보를 담고 있는 벡터가 되어서 Decoder RNN에 보내진다.
많은 NLP tasks 들이 seq2seq를 기반하여 활용한다.
- 요약 : 긴 텍스트를 입력받아 정리하여 짧은 텍스트로 바꾼다.
- 대화 : 입력받은 말과 자연스러운 답을 생성한다.
- 파싱 : 입력받은 텍스트를 하나의 시퀀스로 생성한다.
- 코드 생성 : 자연어 언어를 파이썬 코드로 바꿔준다.
Conditional Language Model
디코더 RNN 부분은 인코딩을 조건으로 단어를 생성하는 조건부 모델이다.
- 이전에 생성한 단어를 기반해서 다음 단어 분포를 생성하는 모델이다.
NMT는 직접적으로 P(y|x)를 계산한다.
그럼 학습은 어떻게 할까? 일단 큰 병렬 코퍼스를 얻는다.
Training a Neural Machine Translation system
소스언어 문장이 주어졌을 때, 목표 언어 문장의 조건부 모델 확률을 직접 계산하는 것이다.
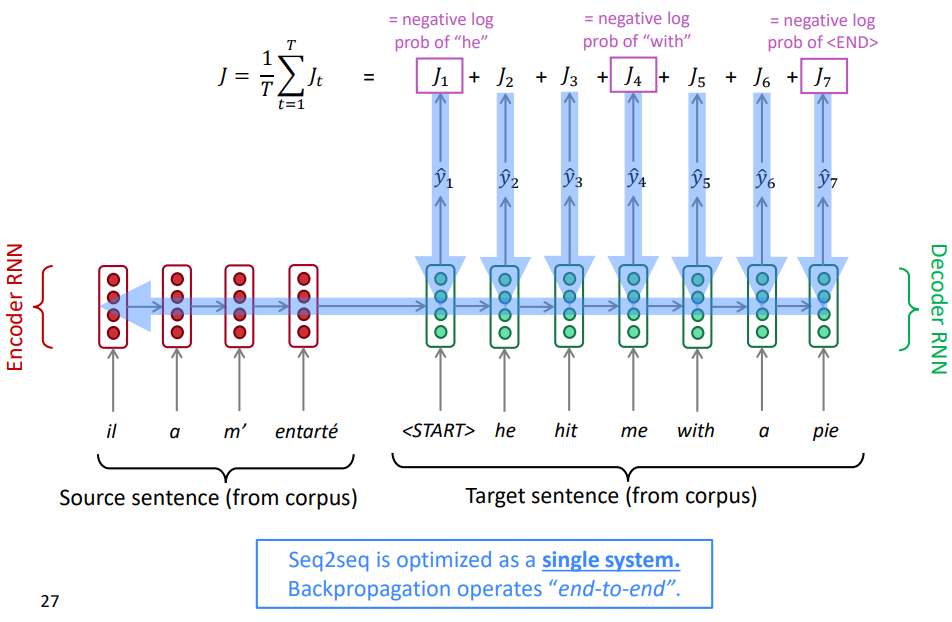
- 소스 문장과 타켓 문장을 가져온다.
- 소스 문장을 인코딩한다.
- 인코딩한 마지막 hidden state를 타겟(디코딩)에 제공한다.
- 디코딩에서 생성될 가능성이 가장 높은 단어라고 예측하는 단어와 실제 단어를 비교하고, 잘못 예측할 만큼 손실을 얻는다.
- 전체 문장에 대한 전체 손실을 계산한다.
최종 손실부터 시작해 시스템을 통해서 역전파 한다. 역전파는 "end-to-end"로 실행된다.
디코더 모델의 모든 매개변수를 업데이트할 뿐만 아니라 인코더의 모든 매개변수도 업데이트한다.
Multi-layer RNNs
이전에 진도를 나가지 않은 부분이 있다.
기존에 우리가 배운 RNN은 하나의 차원에서만 "deep"했다.
여러 RNN을 서로 겹쳐서 적용하면 다른 차원에 깊게 만들 수 있다. 다층 RNN이라고 하는데 간단히 말해 낮은 RNN은 lower-level 수준에서의 계산만 가능하지만, 높은 RNN은 higher-level 수준의 계산도 가능해진다. 낮은 수준의 RNN의미는 어떤 단어의 품사는 무엇이고, 어떤 단어는 사람의 이름인지 아니면 회사 이름인지 등을 이야기하는 것이다. 높은 수준의 RNN 의미는 문장의 전체 구조에 대해 더 잘 알고, 그 의미가 무엇이고, 문장의 긍정 부정 표현등을 더 많이 아는 것이다.
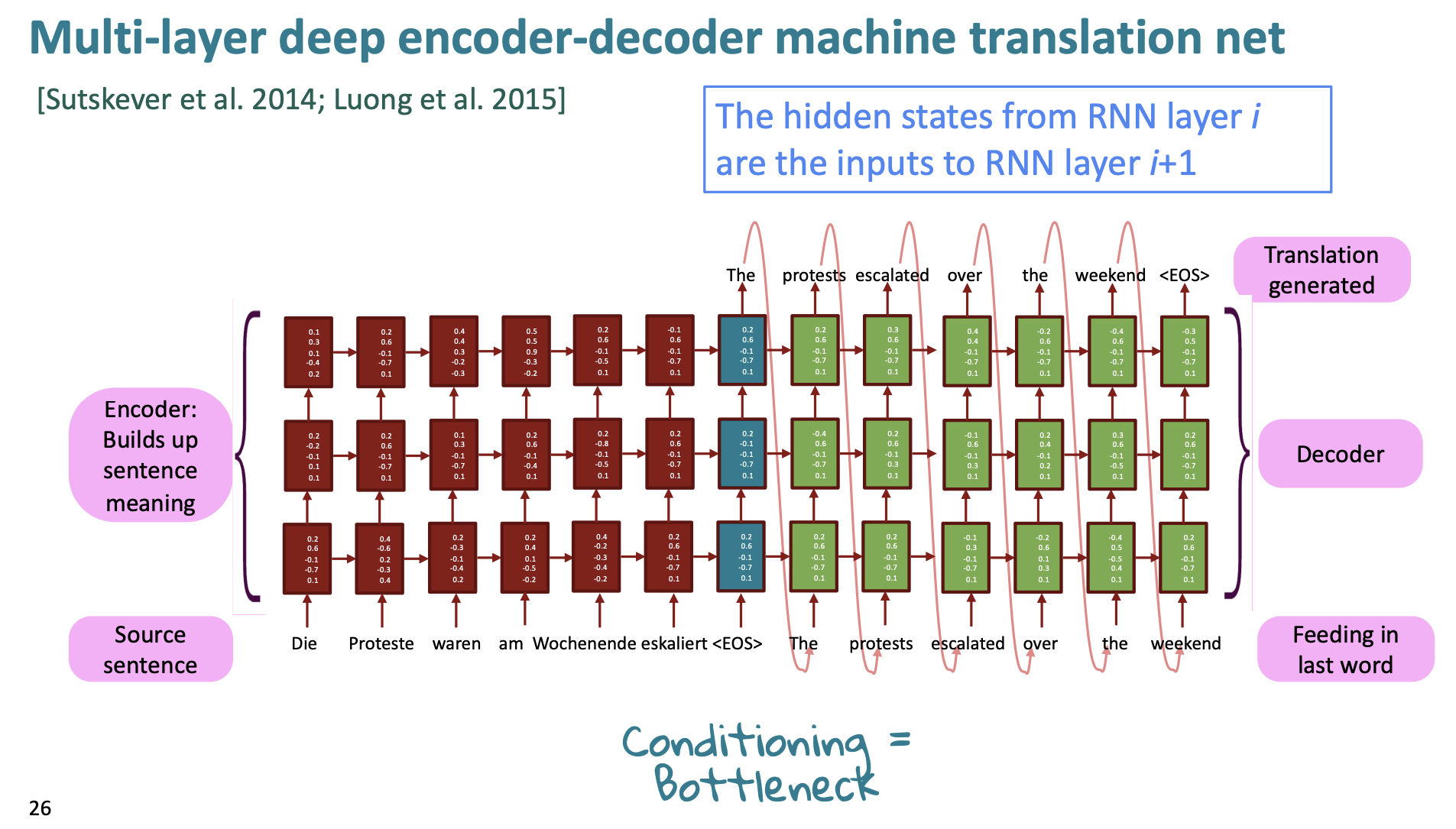
그리고 이를 실제로 번역에 활용하면 성능이 꽤 좋다고 한다.
아키텍쳐를 보면 이전의 RNN보다 층이 여러개임을 알 수 있다.
2017년 논문(Britz et al)을 예시로 들면 2~4개의 layer가 인코더로 적합했고 4개의 layer가 디코더로 적합했다고 한다. 종종 2개의 층은 1개의 층보다 성능이 좋았고 3개의 층은 2개일 때보다 가끔 성능이 좋았다.
트랜스포머 기반 네트워크는 12 또는 24 층의 레이어를 사용한다고 한다. 나중에 트랜스포머를 다룰 예정이니 그때 더 자세히 배우도록 하자.
아무튼 우리는 지금까지 MT에 대해 배웠는데, 지금까지의 MT는 모두 Greedy Method였다. 그러니까 가장 확률이 높은 것을 다음 단어로 선택했다. 하지만 이러한 그리디 방식의 문제는 무엇일까?
Problems with greedy decoding
- 잘못된 단어를 되돌리기 힘들다.
: il a m’entarté (he hit me with a pie)
-> he _
-> he hit
-> he hit a _
위 예시를 보면 잘못 선택된 단어를 되돌릴 수 없다는 단점을 가지고 있다.
- 계산 비용이 너무 크다.
만약 우리의 단어 보따리가 V라고 하고 T길이의 문장을 만든다고 하자. 그러면 우리는 각각의 스텝 t에서 를 계산해야한다.
그래서 greedy에서는 가장 확률이 높은 1개를 선택했다면 일단 k개의 부분 번역을 선택하는 방법을 해보자. 이를 Beam search라고 한다.
Beam search
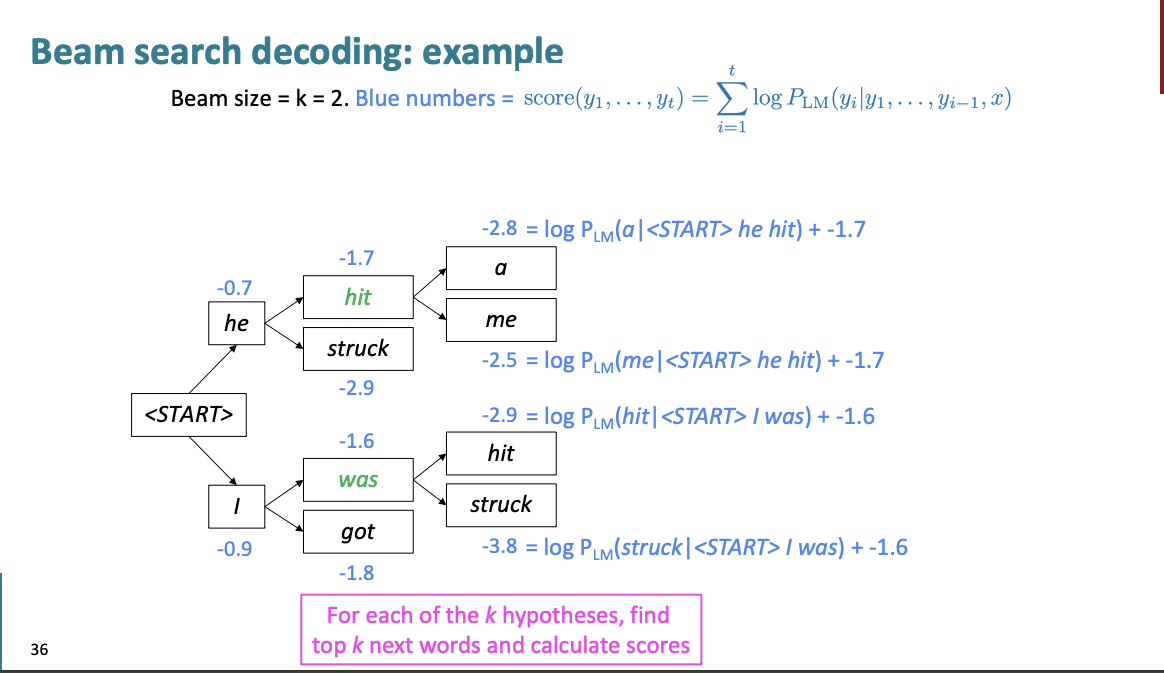
k 를 beam size라고 한다.
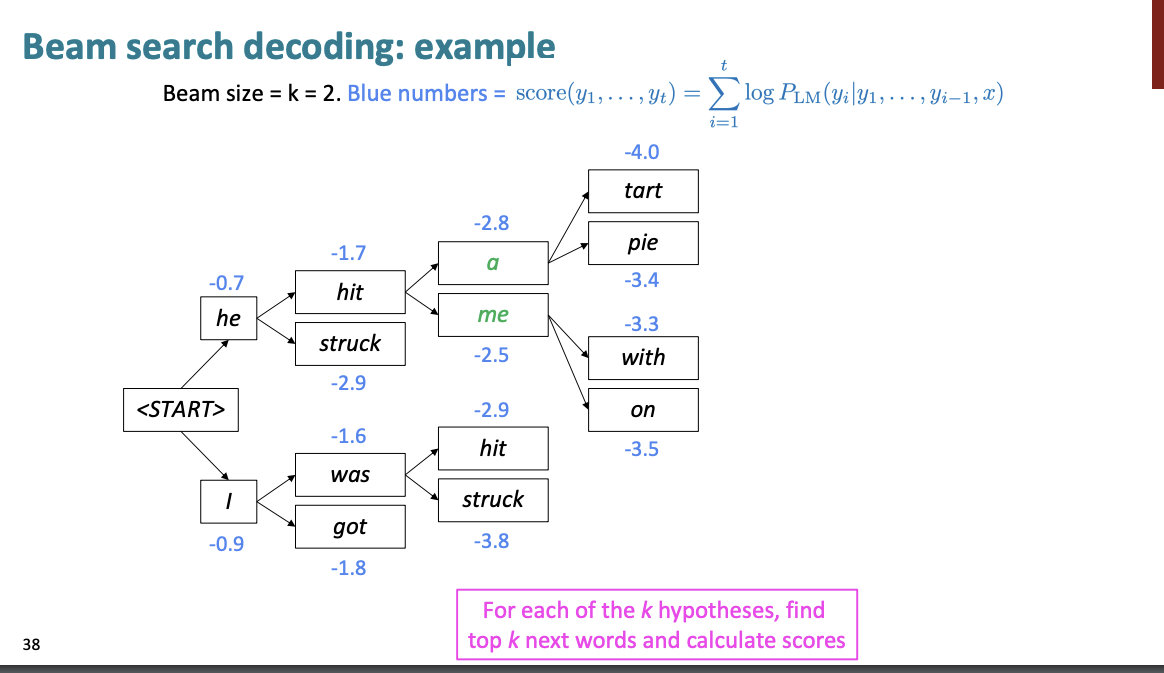
예를 들어 한번 설명해보자.

일단 "start"로 단어의 시작이 주어졌다고 하자. 그럼 k=2라고 설정했을 때, TOP 2의 단어를 가져와서 계산한다.
상위 2개의 단어는 he, I이다.
그리고 각 단어에서의 상위 2개의 단어를 또 가져와서 계산한다.

여기서
hit : -1.7
struck : -2.9
was : -1.6
got : -1.8
이다. 이는 손실함수 이기 때문에 손실이 적은 것을 선택하면 된다.
hit, was를 선택한다.
여기서는 a, me를 선택한다.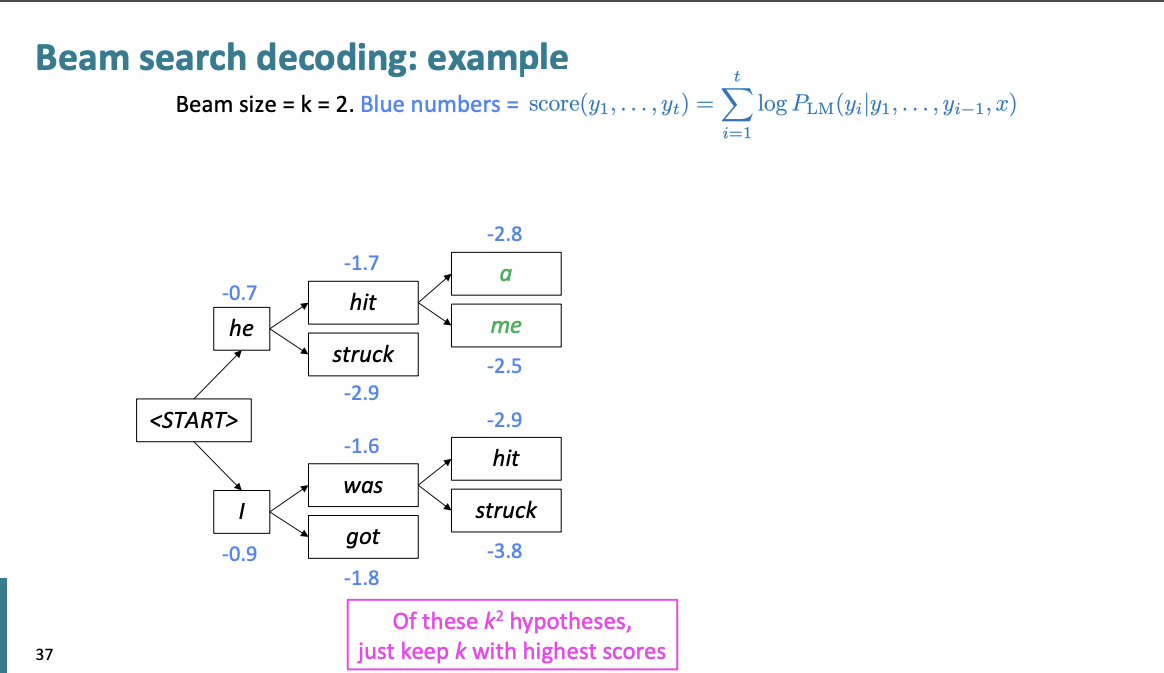
여기서는 pie, with를 선택한다.
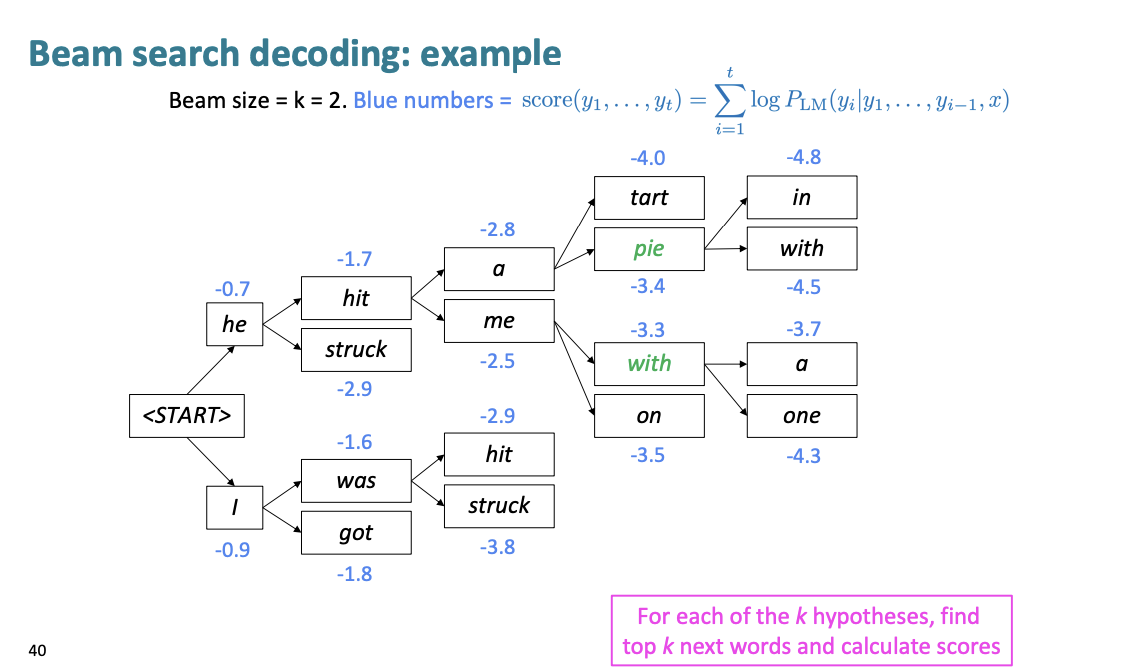
a, one를 선택한다.
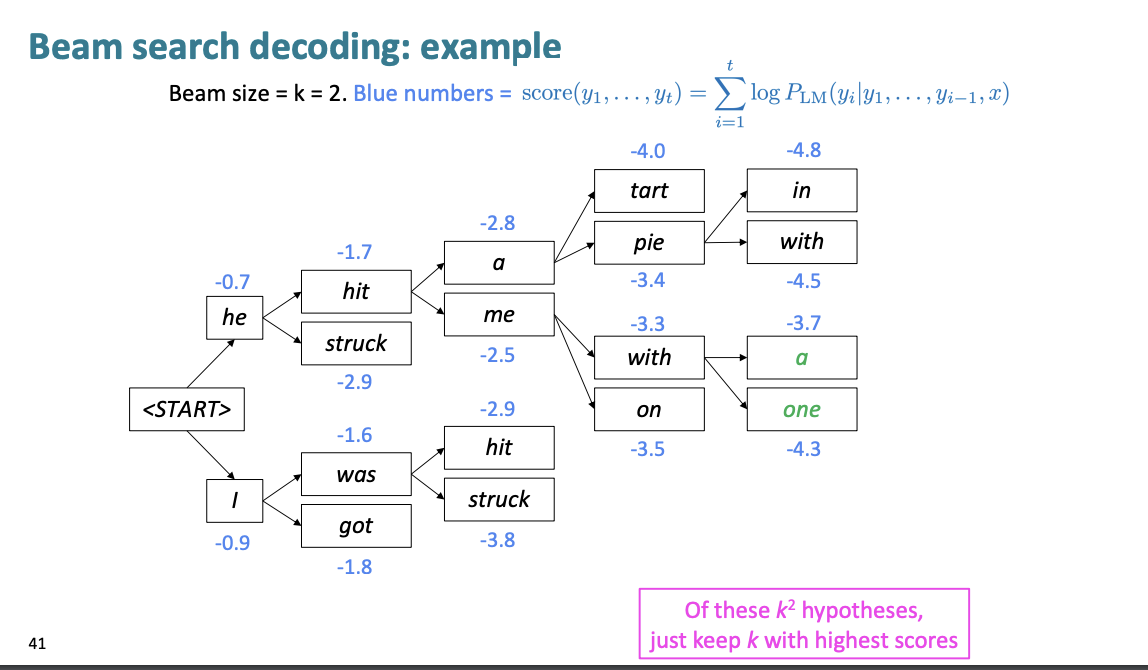
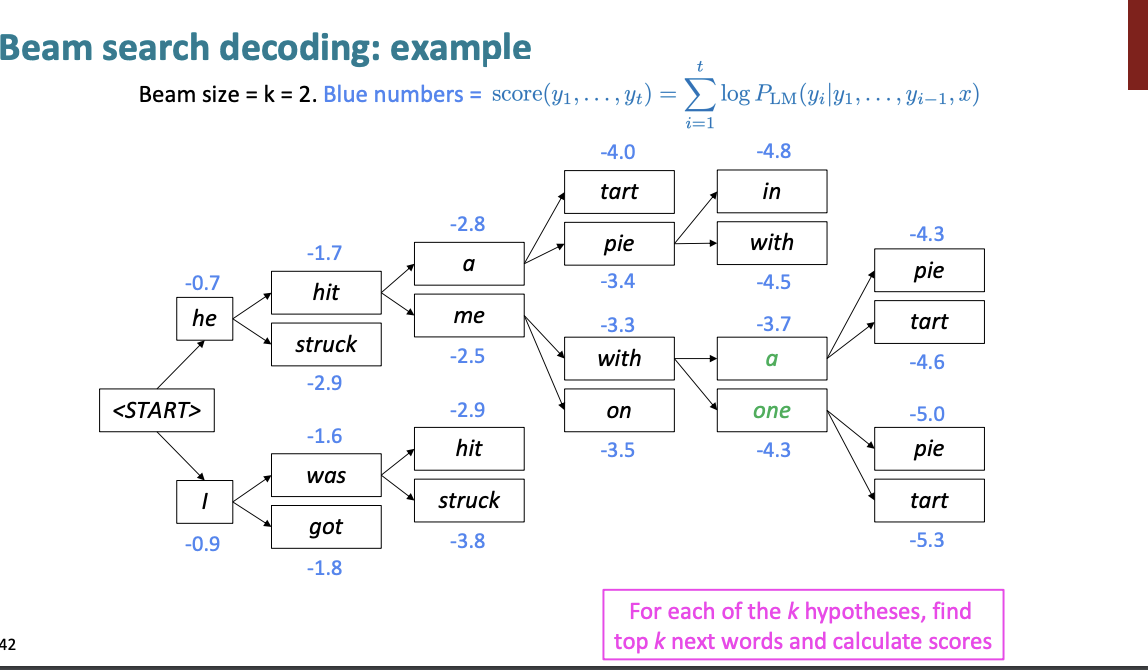
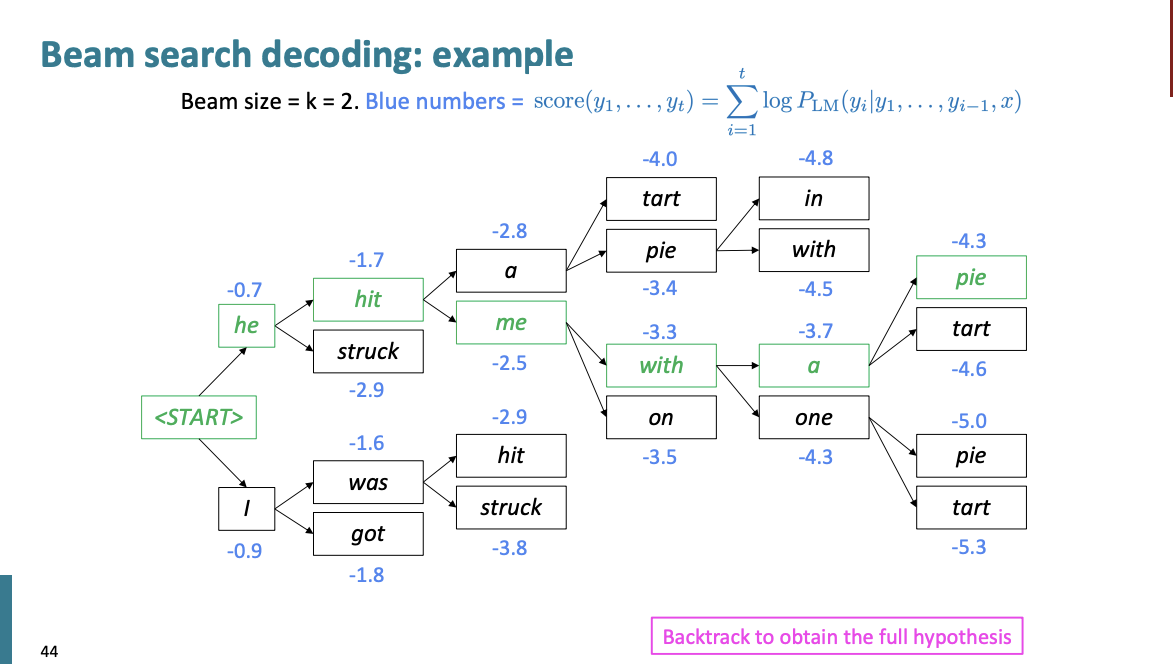
pie에서부터 문장의 처음으로 다시 Backtracking을 하여 문장의 가설을 만든다.
그리디 디코딩에서는 우리는 보통 end 토큰을 만날때까지 생성을 했다.
빔 서치 디코딩에서는 가설이 생성되기 때문에 서로 다른 가설은 end 토큰이 만들어지는 시간이 다를 수 있다.
- 만약 하나의 가설이 end 토큰을 만들었다면 이 가설은 complete한 것이다.
- complete한 가설을 제쳐두고 빔 서치를 통해 다른 가설을 또 만든다.
- 일반적으로 정해진 길이에 도달하거나 n개의 완전한 가설을 만들었다면 종료한다.
자 이제 우리는 여러 n개의 가설이 있다고 하자.
그럼 이 가설 중에 어떤 문장을 선택할 것인가?
아무래도 가장 높은 점수를 받은 상위 항목을 선택할 것이다. 이러한 가설은
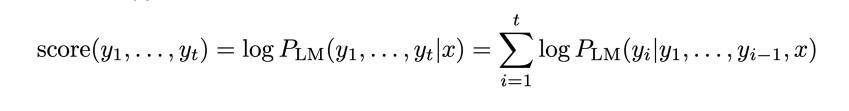
이렇게 점수를 계산한다.
이것의 문제점은 무엇일까?
바로 긴 문장일 수록 확률이 감소한다.
1보다 작은 수를 곱하면 결과값은 이전 값보다 작아진다. 따라서 20 단어의 문장의 확률은 10단어의 문장의 확률보다 작을 수밖에 없다. 이는 자연어에서는 불합리적이다. 충분히 긴 단어를 우리는 많이 사용하기 때문이다. 이를 해결하는 방법은 무엇일까?
길이를 기준으로 정규화를 하는 것이다. 위 점수를 길이인 t로 나누는 것이다.
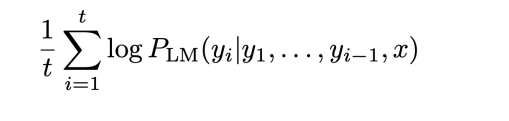
Compare SMT vs NMT
확률 기반 번역보다 신경망 기반 번역이 뭐가 더 좋은가?
- 더 나은 성능 : 더 유창하고, 문맥을 잘 이해하고, 구문 유사성을 잘 이해한다.
- single neural network은 end to end로 최적화 된다 : 최적화해야하는 하위 구성요소들이 필요 없다.
- 인력이 비교적 적게 들어간다.
그럼 단점은 무엇일까?
- 시스템을 해석하기 힘들다. : 디버깅하기 어렵다.
- 컨트롤하기 힘들다. : 규정과 가이드라인을 쉽게 제정할 수 없다.
Evaluate MT
우리는 어떻게 기계 번역을 평가할 수 있을까?
BELU(Bilingual Evaluation Understudy)가 있다.
이는 기계가 번역한 것과 사람이 번역한 것을 비교하여 유사성 점수를 계산한다.
- 유사성 점수는 n-gram 정밀도를 통해 계산한다.
- 너무 짧게 번역한 것에 대해 패널티를 부과한다.
BLEU는 유용하나 완벽하진 않다. 그래서 좋은 번역도 n-gram 중복이 낮으면 BAD score를 받을 수 있다.
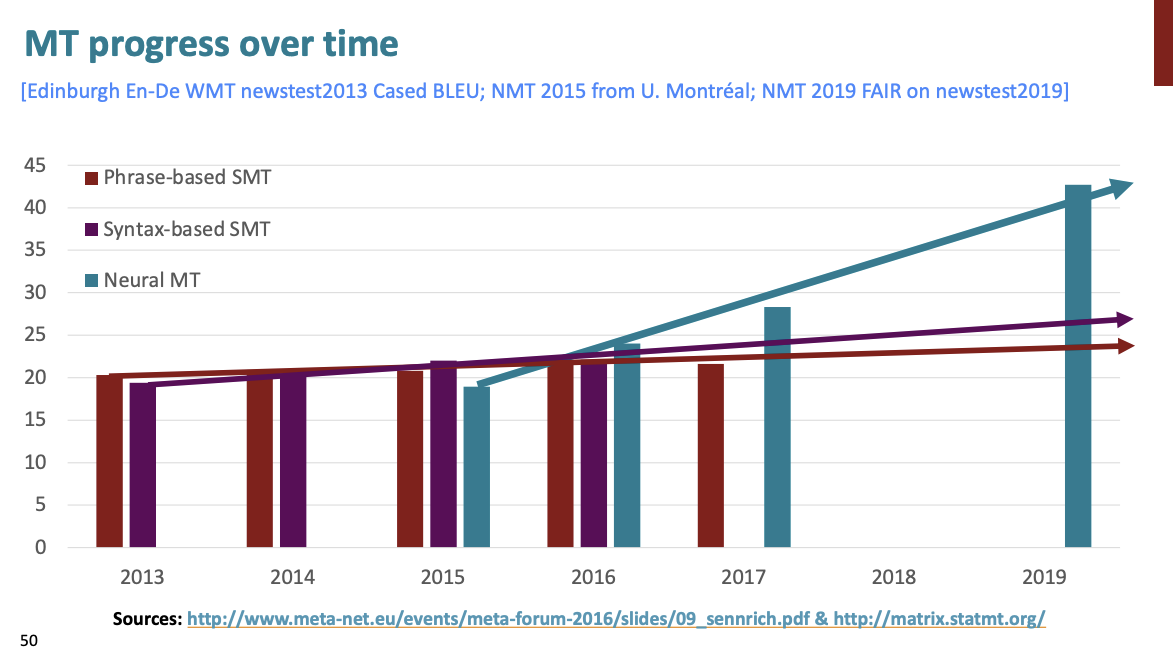
BELU 점수를 보면 확실히 신경망 구조의 기계번역이 성능이 좋은 것을 알 수 있다.
그래서 기계번역이 완벽하다? 는 것은 아니다.
아직도 해결해야할 많은 문제들이 남아있다.
• Out-of-vocabulary words
• Domain mismatch between train and test data
• Maintaining context over longer text
• Low-resource language pairs
• Failures to accurately capture sentence meaning
• Pronoun (or zero pronoun) resolution errors
• Morphological agreement errors
하지만 NMT는 NLP에 상당부분 중요한 Task이다.
NMT 연구는 자연어처리의 많은 혁신을 개척했다.
2021년에도 NMT 연구는 번창하고 있다.
여러 개선점들을 연구원들은 연구하여 seq2seq 를 개선했다. 하지만 중요한 one improvement가 있다.
바로
ATTENTION 이다.
Attention
기존 seq2seq에는 문제가 있다.
바로 병목 현상이다.
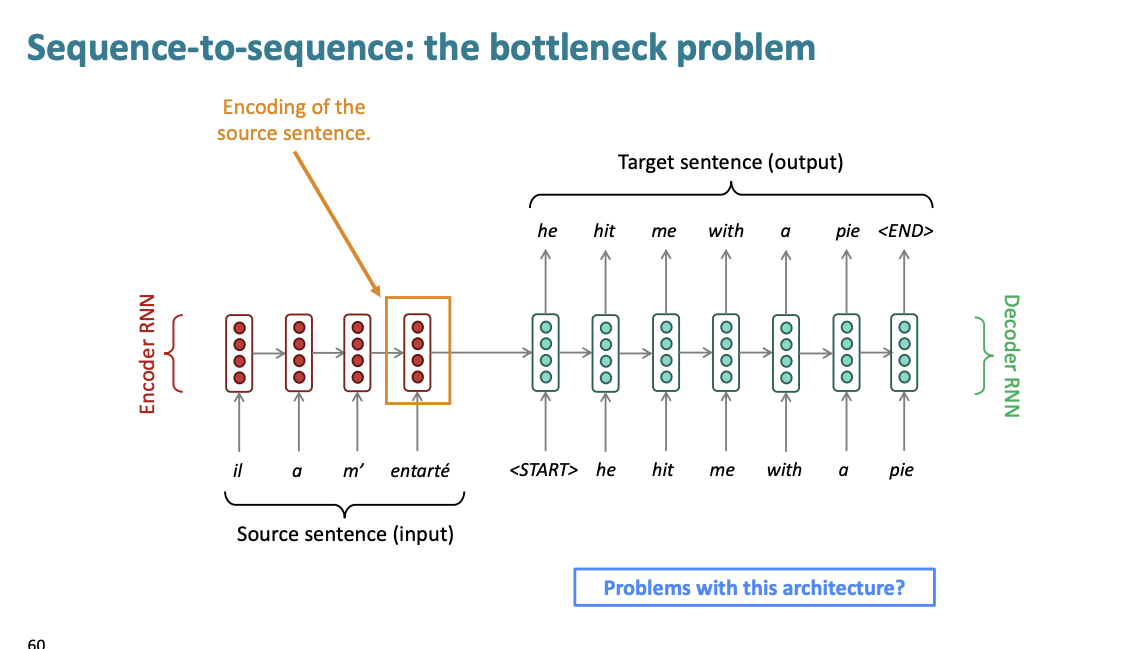
우리는 소스 문장을 인코딩할 때 소스 문장의 모든 정보를 capture해야한다. 하지만 마지막 hidden state에서 정보 병목 현상이 발생한다.
감정 분석에는 꽤나 용이하나 단어의 순서를 유지하는 기계 번역에는 적합하지 않다고 한다.
그럼 Attention이 이걸 해결하는가? 맞다.
각각의 디코더 스텝에서 인코더와 연결되는 direct connection을 사용하여 소스 시퀀스의 특정 부분에 대해 더 집중하고자 하는 것이다.
그림을 통해 이해해보자. 일단 아까와 비슷하게 입력 문장이 있고 각 단어에 해당하는 hidden state가 있고, decoder의 hidden도 있다고 하자.
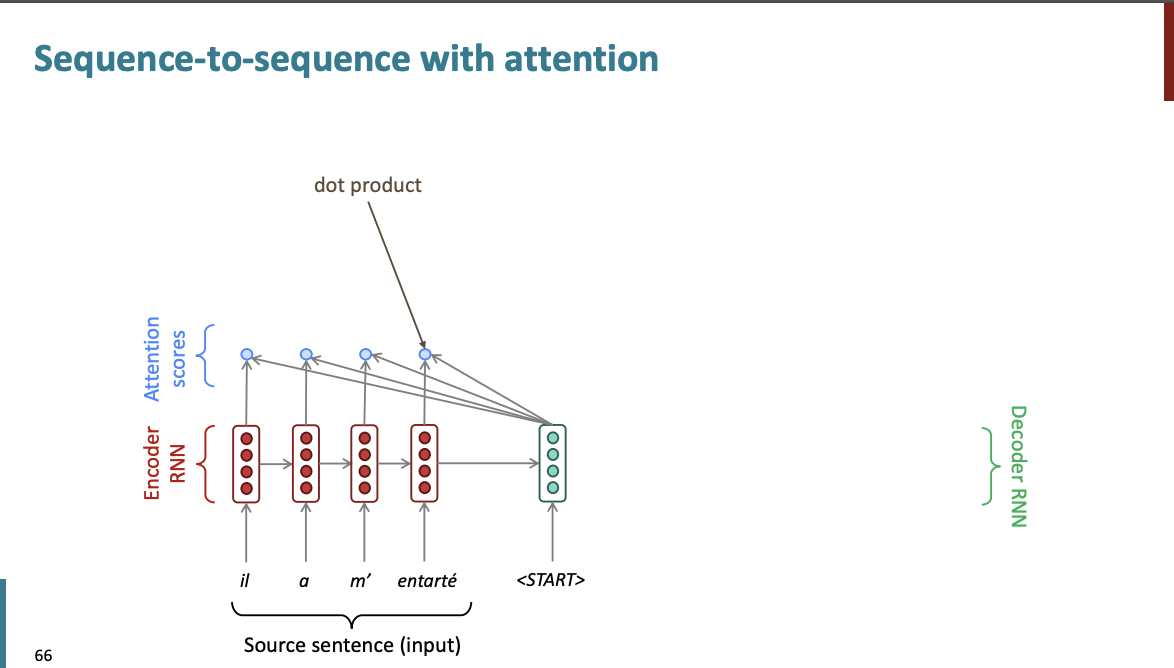
우리는 디코더의 히든 상태와 인코더의 히든 상태를 각각 내적해서 곱해서 Attention score를 만든다.
그리고 평소와 같이 softmax를 사용해서 점수들을 확률 분포로 바꾼다.
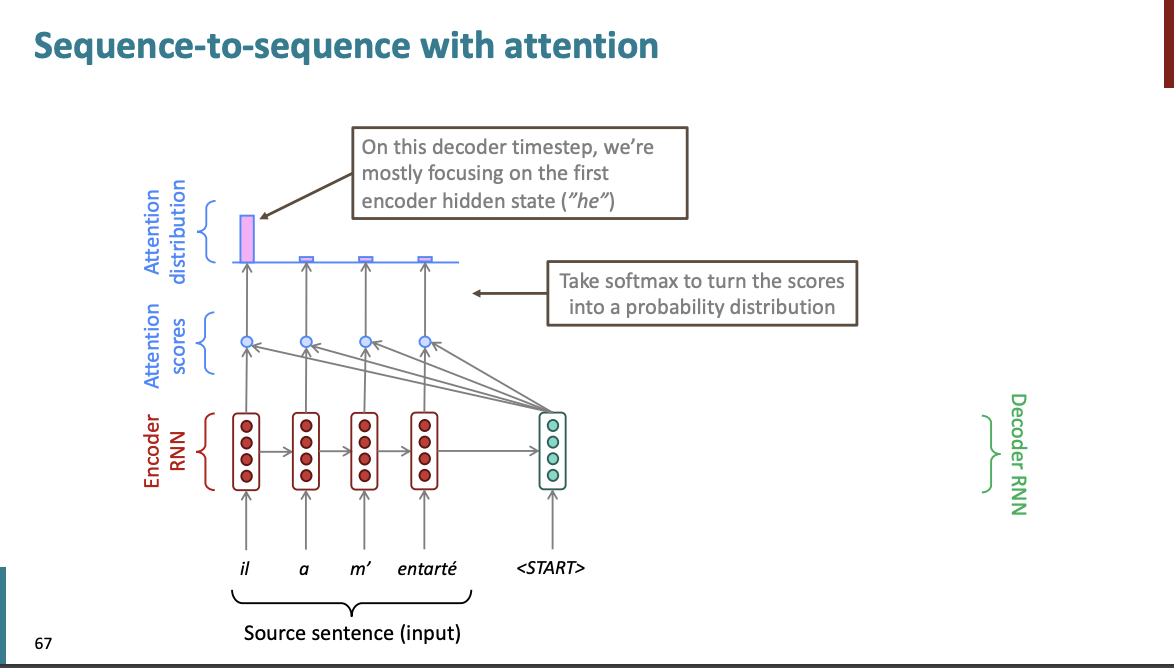
일단 처음 문장이기 때문에, 맨 앞에 단어에 주의를 기울이는 attention 분포가 나왔다
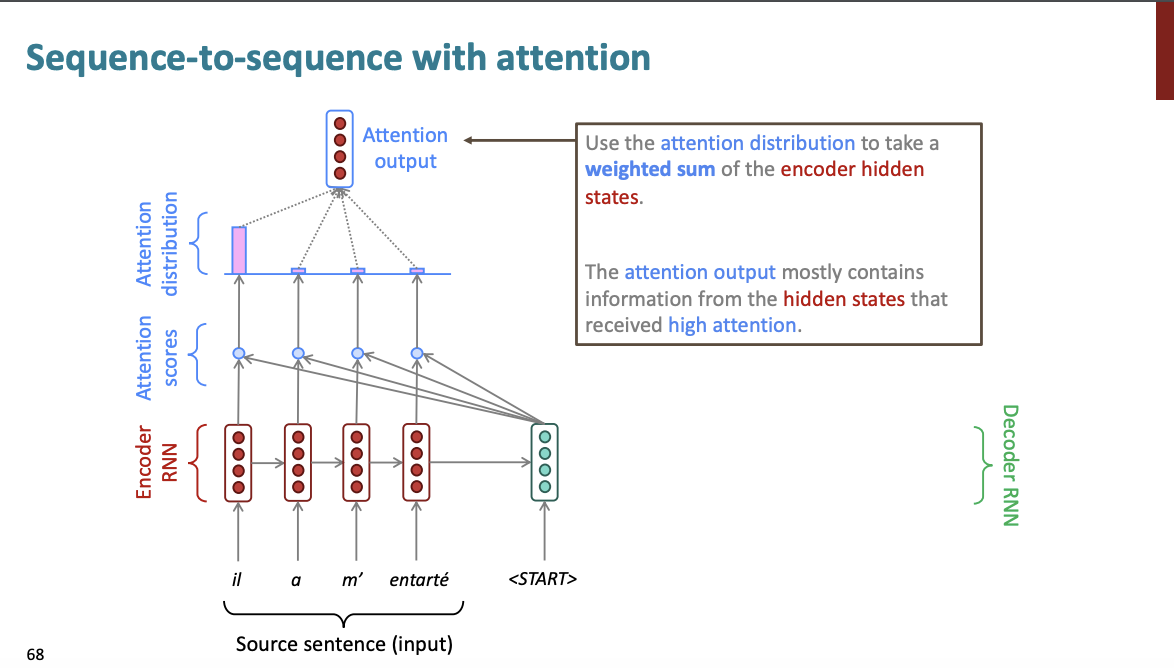
그리고 이 분포를 기반으로 Attention output을 생성한다. 이 출력은 인코더 모델의 hidden state의 평균이 될 것이다. 이는 Attention 분포를 기반으로 한 가중 평균이 될 것이다.
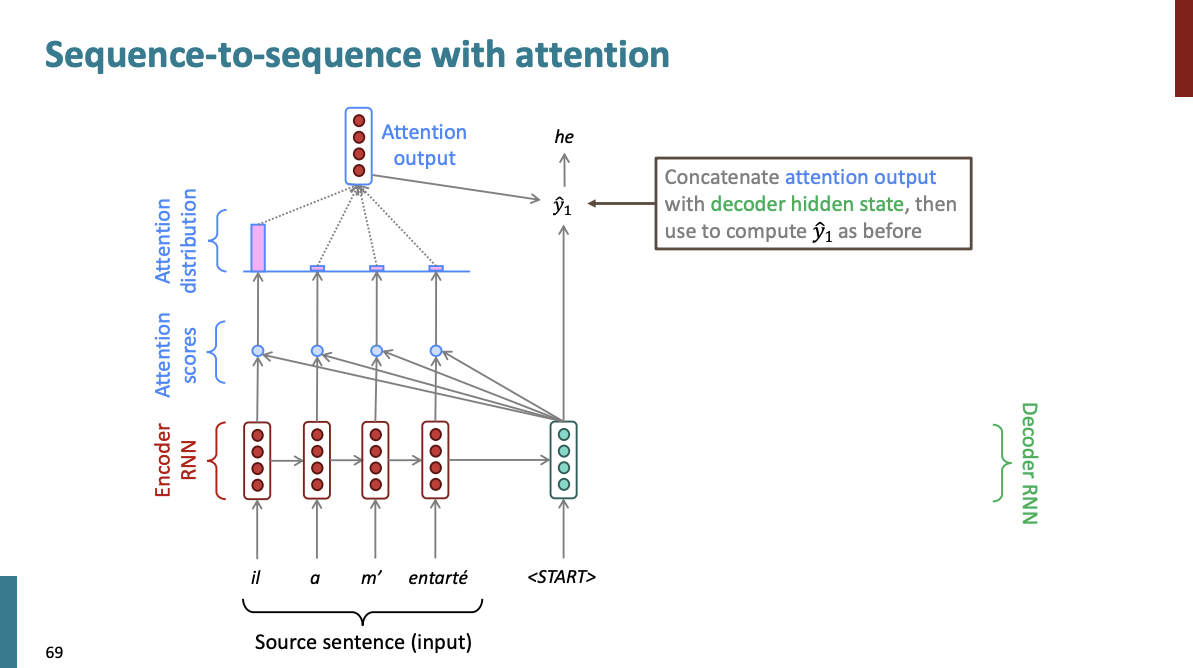
이 Attention output을 가져와서 디코더 RNN의 hidden state와 concatenate한다. 그리고 이전처럼 를 계산한다.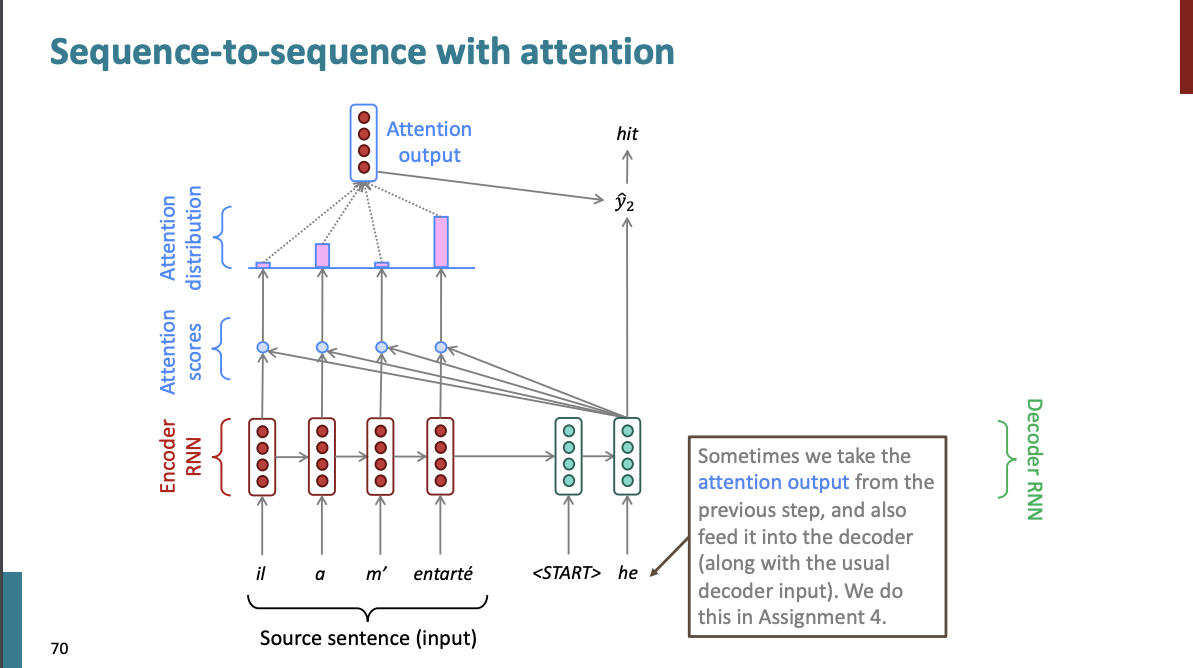
그리고 각 디코더는 이전과 똑같이 동일한 종류의 계산을 수행한다.
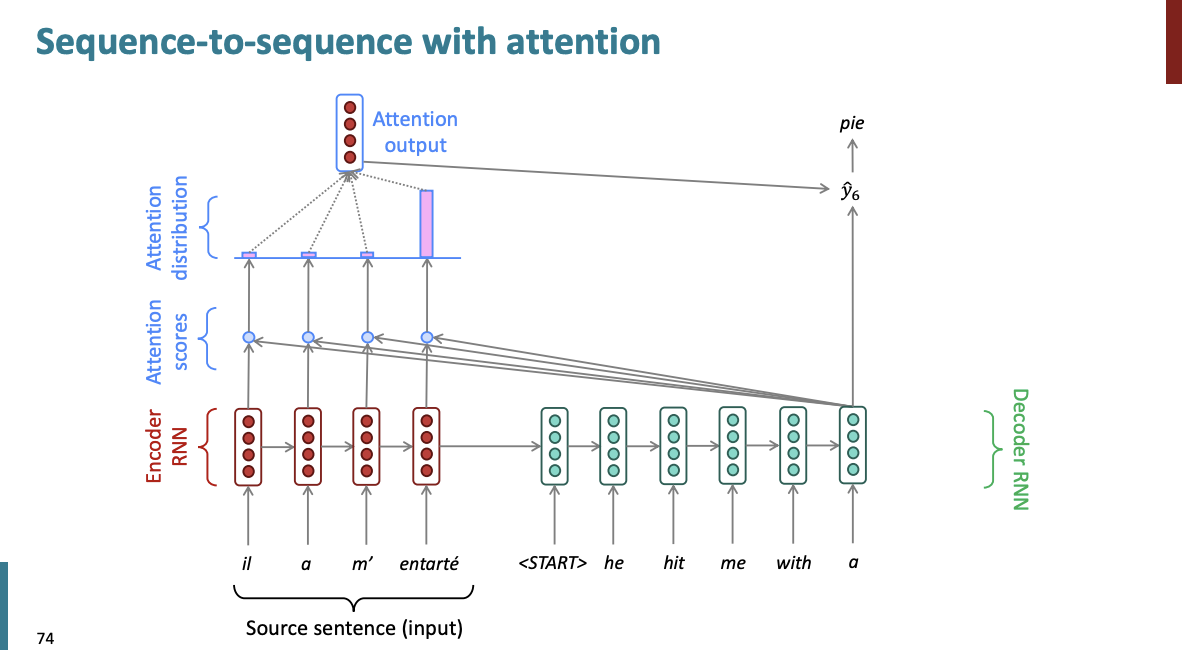
위처럼 모든 디코더에 입력에 Attention output을 사용한 것을 알 수 있다. 이는 이전보다 유연하고 좋은 번역을 생성할 수 있는 효과적인 방법으로 입증되었다.
다음 시간에는 Attention의 방정식 부분을 알아보자.
끗!
