[224N] Python and Numpy Review
과제1을 수행 하기전 간단한 파이썬 복습을 진행했다.
install
우선 주피터 노트북을 실행하는데, 나는 이미 미니콘다가 깔려 있어서 미니콘다 프롬프트로 주피터 노트북을 설치했고, 프롬프트를 열로 jupyter notebook을 입력하면 웹에서 실행된다.
더 자세히 알고싶다면 다음 링크를 참고하자.
미니콘다에서 주피터노트북 설치하기
Python review
그리고 파이썬을 복습했다.
사실 파이썬은 내 주언어이기 때문에, 반복문이나 함수 구문은 pass.
class
class를 잘 안써서 class는 복습한다.
# define class
class Foo:
# optinal constructor
def __init__(self, x):
# first parameter "self" for instance reference, like "this" in JAVA
self.x = x
# instance method
def printX(self): # instance reference is required for all function parameters
print(self.x)
# class methods, most likely you will never need this
@classmethod
def printHello(self):
print("hello")
obj = Foo(6)
obj.printX()Foo라는 클래스가 있고 6으로 초기화한다.
그리고 클래스내 함수로 출력한다.
# class inheritance - inherits variables and methods
# You might need this when you learn more PyTorch
class Bar(Foo):
pass
obj = Bar(3)
obj.printX()클래스는 inheritance 특징을 가지고 있기 때문에 Bar는 Foo의 특징을 내리 받는다.
따라서 Bar를 3으로 초기화하면 Foo와 똑같이 3으로 초기화 되고 출력함수를 가진다.
nametuple
그리고 nametuple에 대한 것도 배운다.
"""
Named tuples for readibility
"""
from collections import namedtuple
Point = namedtuple('Point', 'x y')
pt1 = Point(1.0, 5.0)
pt2 = Point(2.5, 1.5)
print(pt1.x, pt1.y)보면 nametuple의 첫번째 인수는 튜플함수의 이름이 되는 것 같고, 두번째 인수는 튜플의 내장함수이름인 것 같다. 알다시피 튜플은 [0]과 [1] 등등으로 접근을 해야하는데 이는 가독성이 좋지 않아 이렇게 설정할 수도 있다.
또한 딕셔너리에서 없는 key에 대해 value를 출력할 때 따로 설정할 수 있다.
# default_dictionary returns a value computed from a default function
# for non-existent entries
from collections import defaultdict
adict = defaultdict(lambda: 'unknown')
adict['cat'] = 'feline'
print(adict['cat'])
print(adict['dog'])
Counter
그리고 Counter라는 라이브러리를 사용하면 딕셔러니의 값을 쉽게 카운트 할 수 있고, 이는 문자열에 대해 접근할 때, '문자'별로 인식하기에 알파벳등을 사용할 때 유용할 듯하다.
# counter is a dictionary with default value of 0
# and provides handy iterable counting tools
from collections import Counter
# initialize and modify empty counter
counter1 = Counter()
counter1['t'] = 10
counter1['t'] += 1
counter1['e'] += 1
print(counter1)
print("-"*10)
# initialize counter from iterable
counter2 = Counter("letters to be counted")
print(counter2)
print("-"*10)
# computations using counters
print("1", counter1 + counter2)
print("2,", counter1 - counter2)
print("3", counter1 or counter2) # or for intersection, and for unionCounter({'t': 11, 'e': 1})
Counter({'e': 4, 't': 4, ' ': 3, 'o': 2, 'l': 1, 'r': 1, 's': 1, 'b': 1, 'c': 1, 'u': 1, 'n': 1, 'd': 1})
1 Counter({'t': 15, 'e': 5, ' ': 3, 'o': 2, 'l': 1, 'r': 1, 's': 1, 'b': 1, 'c': 1, 'u': 1, 'n': 1, 'd': 1})
2, Counter({'t': 7})
3 Counter({'t': 11, 'e': 1})
그리고 Numpy를 복습한다.
Numpy
import numpy as np당연히 Numpy를 사용하기 전 import를 해준다.
eye
항등행렬은 eye를 통해 만들 수 있다.
# create identity matrix
c = np.eye(5)
print(c)
print(c.shape)reshape
내 기준 가장 헷갈릴만한 reshape 총정리이다.
# reshaping arrays
a = np.arange(8) # [8,] similar range() you use in for-loops
b = a.reshape((4,2)) # shape [4,2]
c = a.reshape((2,2,-1)) # shape [2,2,2] -- -1 for auto-fill
d = c.flatten() # shape [8,]
e = np.expand_dims(a, 0) # [1,8]
f = np.expand_dims(a, 1) # [8,1]
g = e.squeeze() # shape[8, ] -- remove all unnecessary dimensions
print(a)
print(b)
print(c)
print(d)
print(e)
print(f)
print(g)[0 1 2 3 4 5 6 7]
[[0 1]
[2 3]
[4 5]
[6 7]]
[[[0 1]
[2 3]]
[[4 5]
[6 7]]]
[0 1 2 3 4 5 6 7]
[[0 1 2 3 4 5 6 7]]
[[0]
[1]
[2]
[3]
[4]
[5]
[6]
[7]]
[0 1 2 3 4 5 6 7]concatenate
# concatenating arrays
a = np.ones((4,3))
b = np.ones((4,3))
c = np.concatenate([a,b], 0)
print(c.shape)
d = np.concatenate([a,b], 1)
print(d.shape)결과는 8,3 이랑 4,6이다. 즉 두번째 인수에 따라 어떻게 더할지 정한다.
그리고 만약 3차원 벡터를 더하는 경우에는 다음과 같이 수행한다.
(32,32,3)을 3개 더해서 (3,32,32,3)의 모양을 만들고 싶을 때는
우선 3개를 리스트화하고,
하나씩 차원을 추가한다음
concatenate한다.
# one application is to create a batch for NN
x1 = np.ones((32,32,3))
x2 = np.ones((32,32,3))
x3 = np.ones((32,32,3))
# --> to create a batch of shape (3,32,32,3)
x = [x1, x2, x3]
x = [np.expand_dims(xx, 0) for xx in x] # xx shape becomes (1,32,32,3)
x = np.concatenate(x, 0)
print(x.shape)traspose
# transposition
a = np.arange(24).reshape(2,3,4)
print(a.shape)
print(a)
a = np.transpose(a, (2,1,0)) # swap 0th and 2nd axes
print(a.shape)
print(a)3차원 전치는 이렇게 된다.
(2, 3, 4)
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
(4, 3, 2)
[[[ 0 12]
[ 4 16]
[ 8 20]]
[[ 1 13]
[ 5 17]
[ 9 21]]
[[ 2 14]
[ 6 18]
[10 22]]
[[ 3 15]
[ 7 19]
[11 23]]]역함수와 norm
벡터의 norm은
(1,2,3,4) = 이렇게 구한다.
c = np.array([[1,2],[3,4]])
# pinv is pseudo inversion for stability
print(np.linalg.pinv(c))
# l2 norm by default, read documentation for more options
print(np.linalg.norm(c))
# summing a matrix
print(np.sum(c))
# the optional axis parameter
print(c)
print(np.sum(c, axis=0)) # sum along axis 0
print(np.sum(c, axis=1)) # sum along axis 1내적
내적은 dot 을 통해 할 수 있다.
# dot product
c = np.array([1,2])
d = np.array([3,4])
print(np.dot(c,d))또는 기호 @를 통해 할 수 있다.
# matrix multiplication
a = np.ones((4,3)) # 4,3
b = np.ones((3,2)) # 3,2 --> 4,2
print(a @ b) # same as a.dot(b)
c = a @ b # (4,2)
# automatic repetition along axis
d = np.array([1,2,3,4]).reshape(4,1)
print(c + d)
# handy for batch operation
batch = np.ones((3,32))
weight = np.ones((32,10))
bias = np.ones((1,10))
print((batch @ weight + bias).shape)NUMPY가 LIST보다 훨씬 속도가 빠르니 NUMPY를 쓰자
matplotlib
import matplotlib.pyplot as plt그래프를 그려주는 강력한 도구이다.
line
선을 그릴때는 plot를 사용한다.
# line plot
x = [1,2,3]
y = [1,3,2]
plt.plot(x,y)점 분포
점들을 그릴때는 sactter를 사용한다.
# scatter plot
plt.scatter(x,y)bar
막대 그래프를 그릴때는 bar를 사용한다.
# bar plots
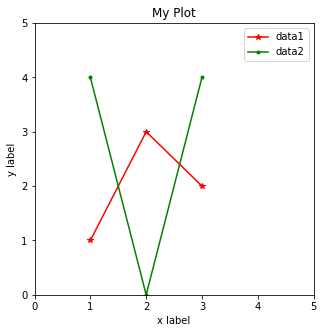
plt.bar(x,y)그림을 그려보면 이렇게 그래프를 그릴 수 있다.
# plot configurations
x = [1,2,3]
y1 = [1,3,2]
y2 = [4,0,4]
# set figure size
plt.figure(figsize=(5,5))
# set axes
plt.xlim(0,5)
plt.ylim(0,5)
plt.xlabel("x label")
plt.ylabel("y label")
# add title
plt.title("My Plot")
plt.plot(x,y1, label="data1", color="red", marker="*")
plt.plot(x,y2, label="data2", color="green", marker=".")
plt.legend()