[224N] Lecture 3,4 review
Lecture 3
자 저번시간에 Stochastic Gradient Descent 에 대해 배웠다.
그러면 과연..
미분은 어떻게 하는건가???
- 손으로
- 알고리즘으로
그럼 우선 손으로 해보자. 그래야 알고리즘을 만들 수 있으니까.
Matrix calculus
행렬 미분을 해보자.
우리는 일단은 간단한 미분은 모두 할 수 있다는 전제하에 수업을 진행한다.
이 정도는 중딩도 알 것이라 생각한다.
그러면, 이 관점은 어떨까?
미분이라는 의미를 통해 입력값이 주어지고 얼마나 output이 달라지는지 확인해보자.
x = 1 에서 x= 1.01로 바뀌면?
= 1.03 즉 0.01의 차이가 0.03의 차이를 만들었고 이는 3배이다.
x = 4에서 x = 4.01로 바뀌면?
= 64.48 즉 48배의 차이가 생긴다.
오호
즉 미분식에 값을 넣으면, 그 만큼의 차이가 생긴다. (3*16 = 48)
이 의미는 미분이 어떤 의미를 가지고 있는지 짐작하게 해준다.
미분
일단 f(x) = f(x1,x2,x3,,,xn)
를 보면 n inputs과 1개의 output임을 알 수 있다.
이를 각각의 input으로 편미분하면
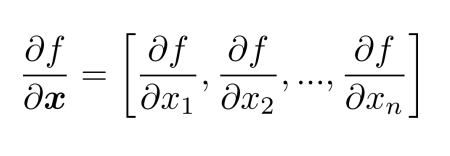
이렇게 할 수 있다.
Jacobian Matrix
야코비 행렬은 미분의 일반화이다.
즉 이는 n개의 inputs을 m개의 output으로 나타낸 함수를 미분할 수 있다.

자코비안은 사실 더 많은 의미가 있지만
https://angeloyeo.github.io/2020/07/24/Jacobian.html#google_vignette
이 블로그를 참고해서 왜 야코비 행렬이 중요한 지 복습하자.
자코비안을 보통 나는 x,y 좌표계를 r, 좌표계로 바꾸거나 할 때 많이 사용했다.
Chain rule
체인 규칙은 뭐 ,,,

이런거다.
Jacobian 예시 1
친절하게 예시를 들어 설명한다.
h를 z에 대한 편미분을 해보자.
야코비 정의에 의해 행렬로 구할 수 있고,
편미분은 해당 변수가 아니면 0이다.
즉 다음과 같다.

그리고 우리는 다음과 같은 식을 상식선*에서 구할 수 있다.

그럼 다시 돌아가서
를 구해보자.

-
우선은 방정식을 간단하게 적는것이 중요하다.

-
그 다음 체인 규칙을 적용하자.

결국 는 가 되고 I는 항등행렬이기 때문에 가 됨을 알 수 있다.
우리가 그러면 를 구하고 싶으면 사실 다시 체인 규칙을 통해 위 과정을 반복해야하지만 다시 하기엔 너무 계산시간이 아깝다.
그래서 를 라고 정의한다.
는 local error signal이라 한다.

자 그러면 가 과연 무엇인가?
= 가 된다.

는 계산을 통해 x가 된다.
가 답같지만,
가 결국 된다하는데,
이는 note에 자세히 설명되어 있다.
쉽게 말하면 차원을 맞추기 위해 전치를 했다.

미분의 형태는 두가지 방법이 있다.
- Jacobian form
가능한 Jacobian을 사용하고 마지막엔 shape convention해야한다. - shape convention
를 계산할 때 사용한 방법. 어느정도 구한 다음 원하는 모양이 무엇인지 파악하고 셀에 무엇으로 채울지 확인한다.
Backpropagation
그럼 이제 역전파에 대해 알아보자.
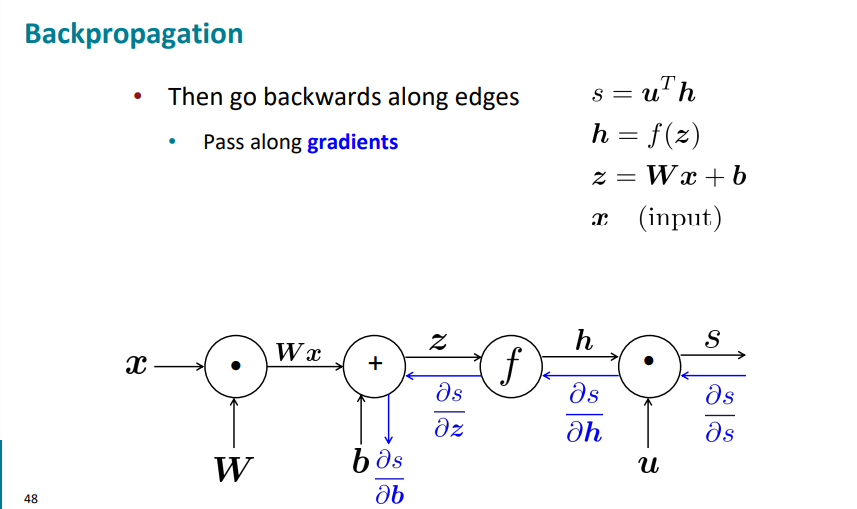
왼쪽에서 오른쪽으로 진행하는 것을 순전파 (Forward Propagation)이라 한다.
그럼 역전파는 다시 돌아 오는 것이다.
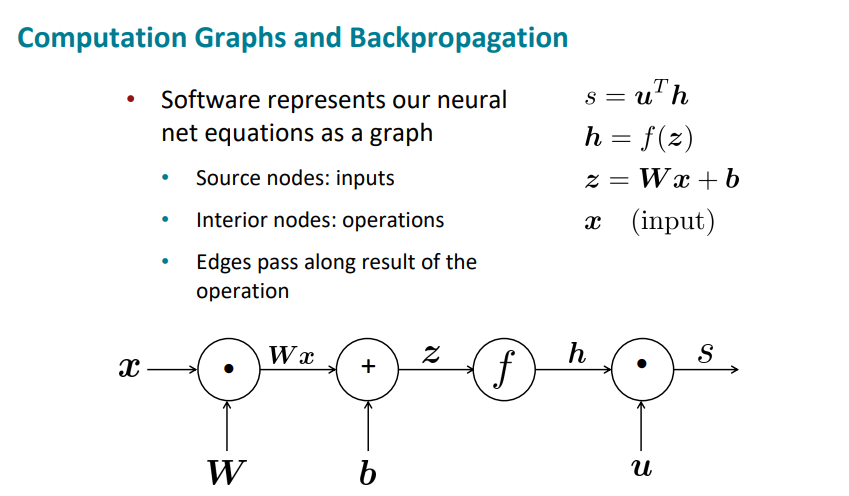
일단 Upstream gradient와 downstream gradient에 대해 알아보자.
노드의 오른쪽은 up, 왼쪽은 down이다.
그리고 각 노드는 local gradient를 가진다.
그림을 보면 이해가 쉽다.
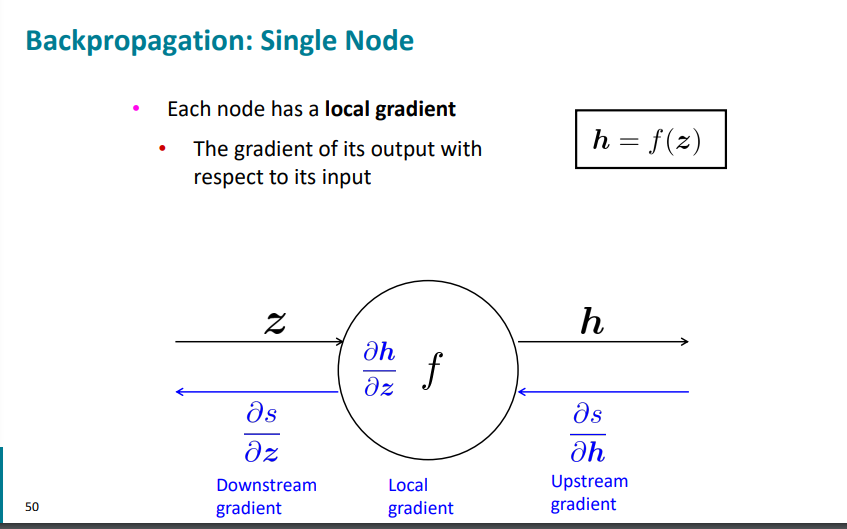
엇 근데 downstream은 chain rule로 인해서
down = up * local 임을 알 수 있다.
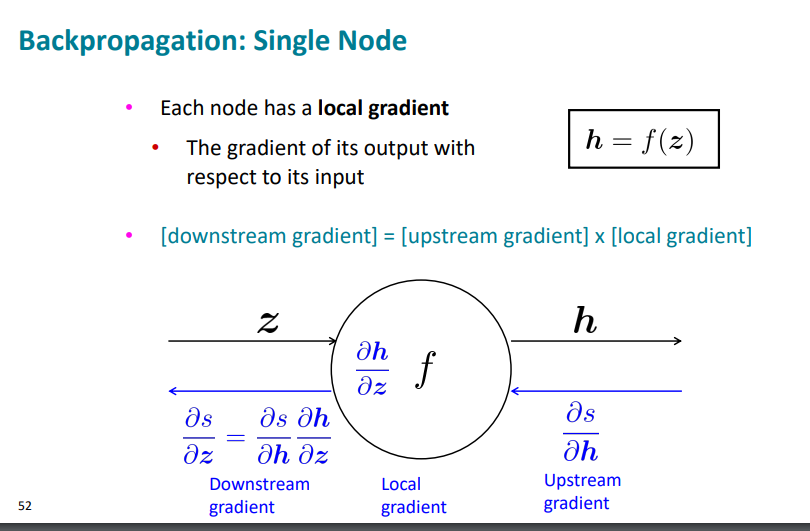
아니 그러면 만약 input이 여러개면 어쩌나?
그럼 여러개의 local gradients를 가진 것이다.
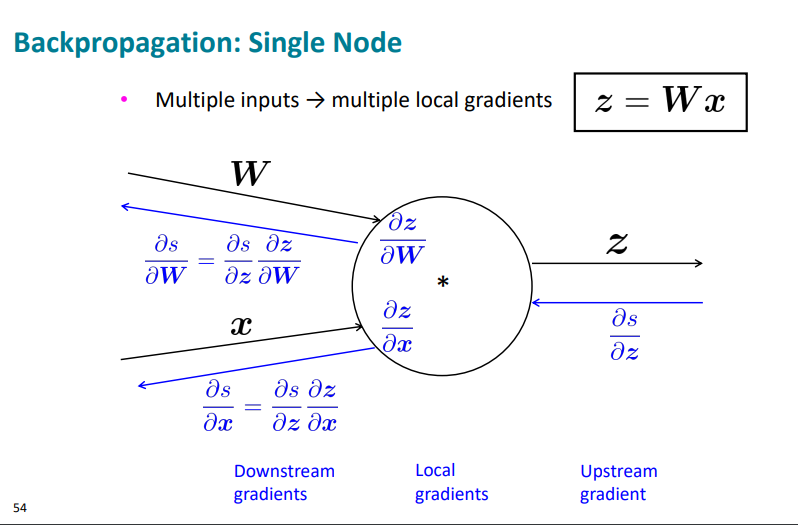
예를 들어보자.
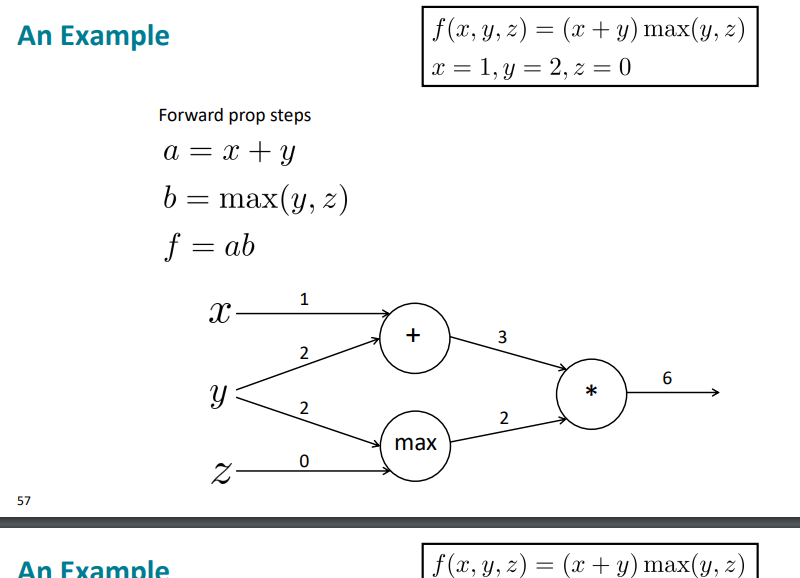
위 식을 통해 우리는 x, y, z와 노드를 그릴 수 있다.
우선, local gradients를 구해보자.
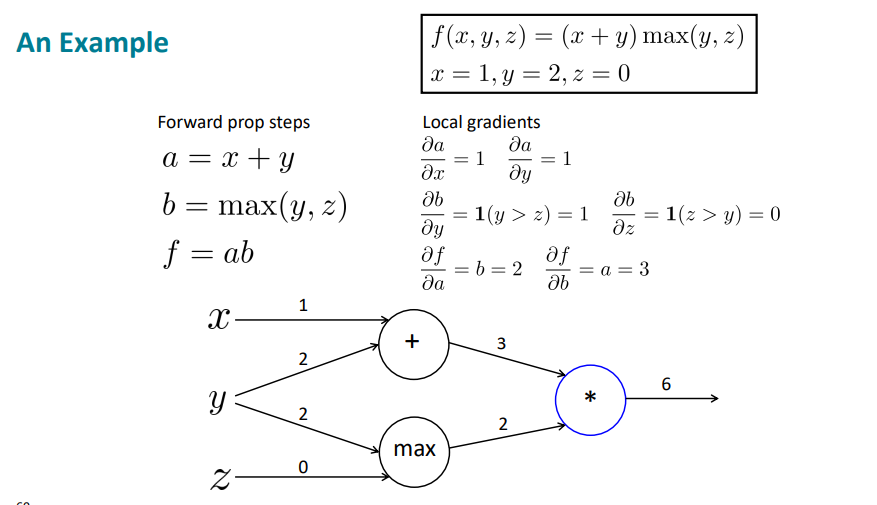
그리고 맨 오른쪽 부터 backpropagation을 실행한다.
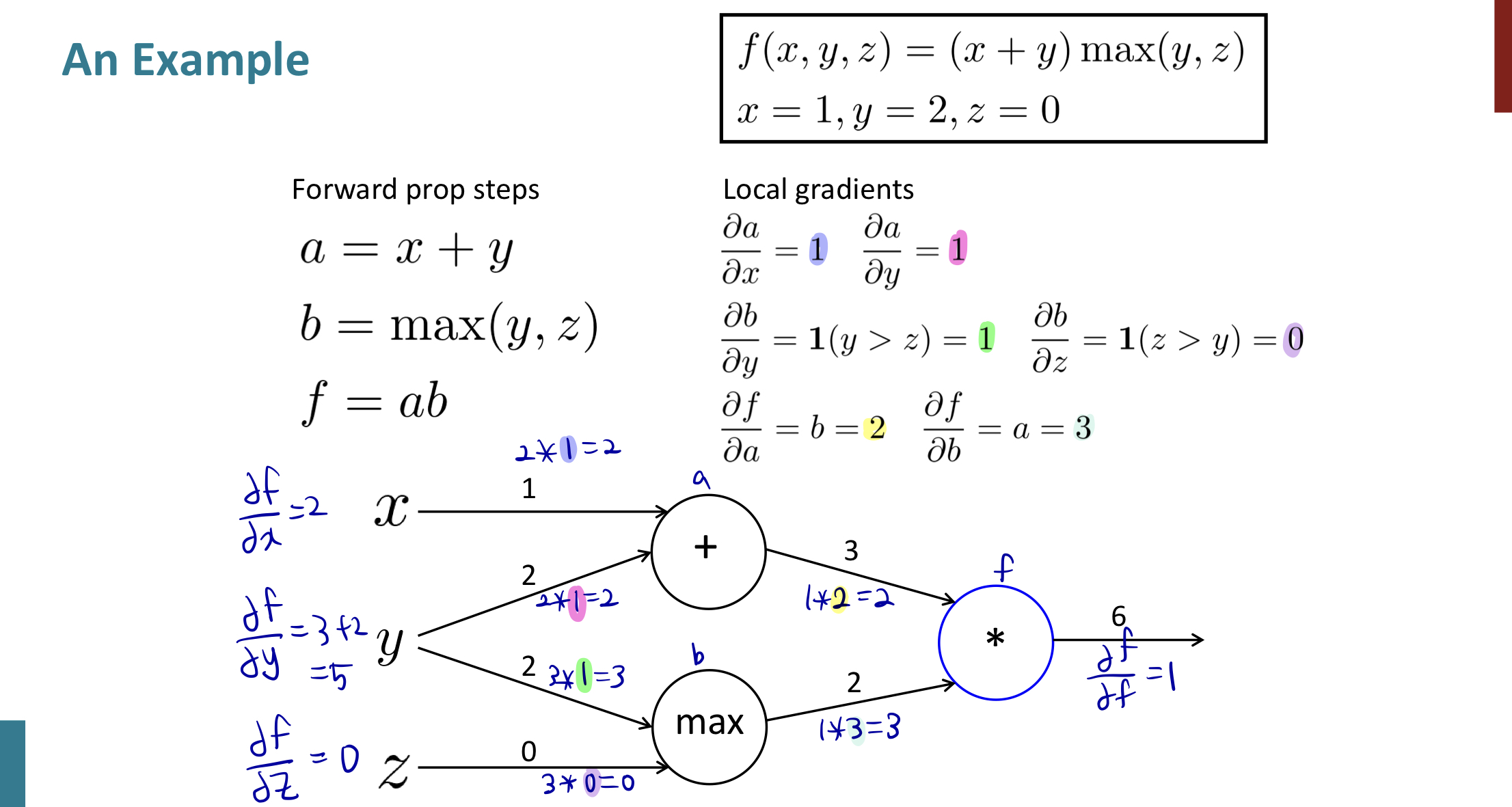
최종적으로 2, 5, 0을 구할 수 있다.
여기서 유추할 수 있는 것은,
'+' : 분배가 되고
max : route 역할 (둘 중 하나로 보냄)
'*' : 둘을 바꿈
역할을 한다는 것이다.
여기서도 계산의 효율성을 따질 수 있는데, 를 구하고 또를 따로 구하는 건 멍청한 짓이라는 점.
여기서도 초록색을 로 두면 계산을 한번만 하고서 구할 수 있다.
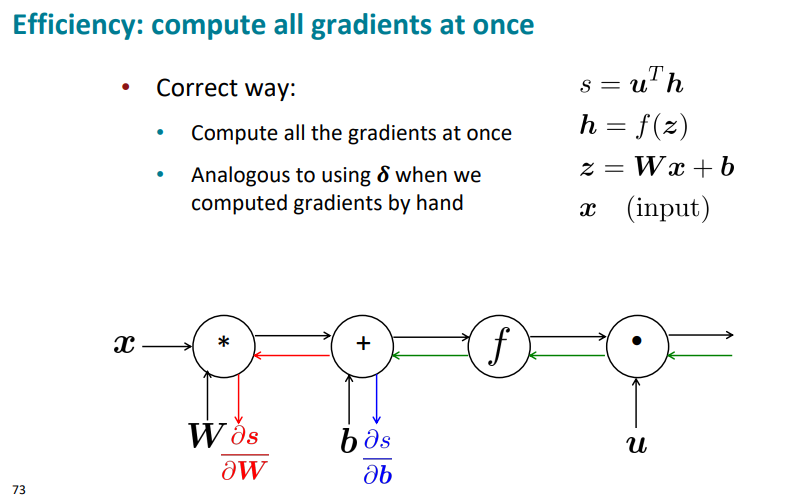
요약하면
- Backpropagation : recursively (and hence efficiently) apply the chain rule along computation graph
- Forward pass : compute results of operations and save intermediate values
- Backward pass : apply chain rule to compute gradients
Lecture 4
저번 시간엔 계속 수학 수학 수학~~~을 다뤘다면, 이번 시간에는 국어 국어,, 아니 영어 영어 영어를 다뤄 보자.
Syntactic Structure
Dependency
여기서 Constituency를 어떻게 번역을 해야할 지 모르겠다.
아무튼 이 문법을 간단하게 설명하면,
nested 한 constitudents로 단어를 구성하는 것이다.
예를 들어
the, cat, cuddly, by, door
가 있다면
Words combine into phrases해서
the cuddly cat, by the door로 묶는 것이고 이를 더 큰 구절로도 묶을 수 있다.
=> the cuddly cat by the door
다음 시간에 더 자세히 배우고 이시간에는 dependency만 배운다고 한다.
Dependency grammar는 한 단어가 어떤 단어에 의존적이라면 화살표로 표시해서 관계를 표시한다. 그리고 이를 tree형식으로 나타낼 수 있다.
Look in the large crate in the kitchen by the door
이 것을 화살표로 표시해서 한번 종속성을 나타내보자.
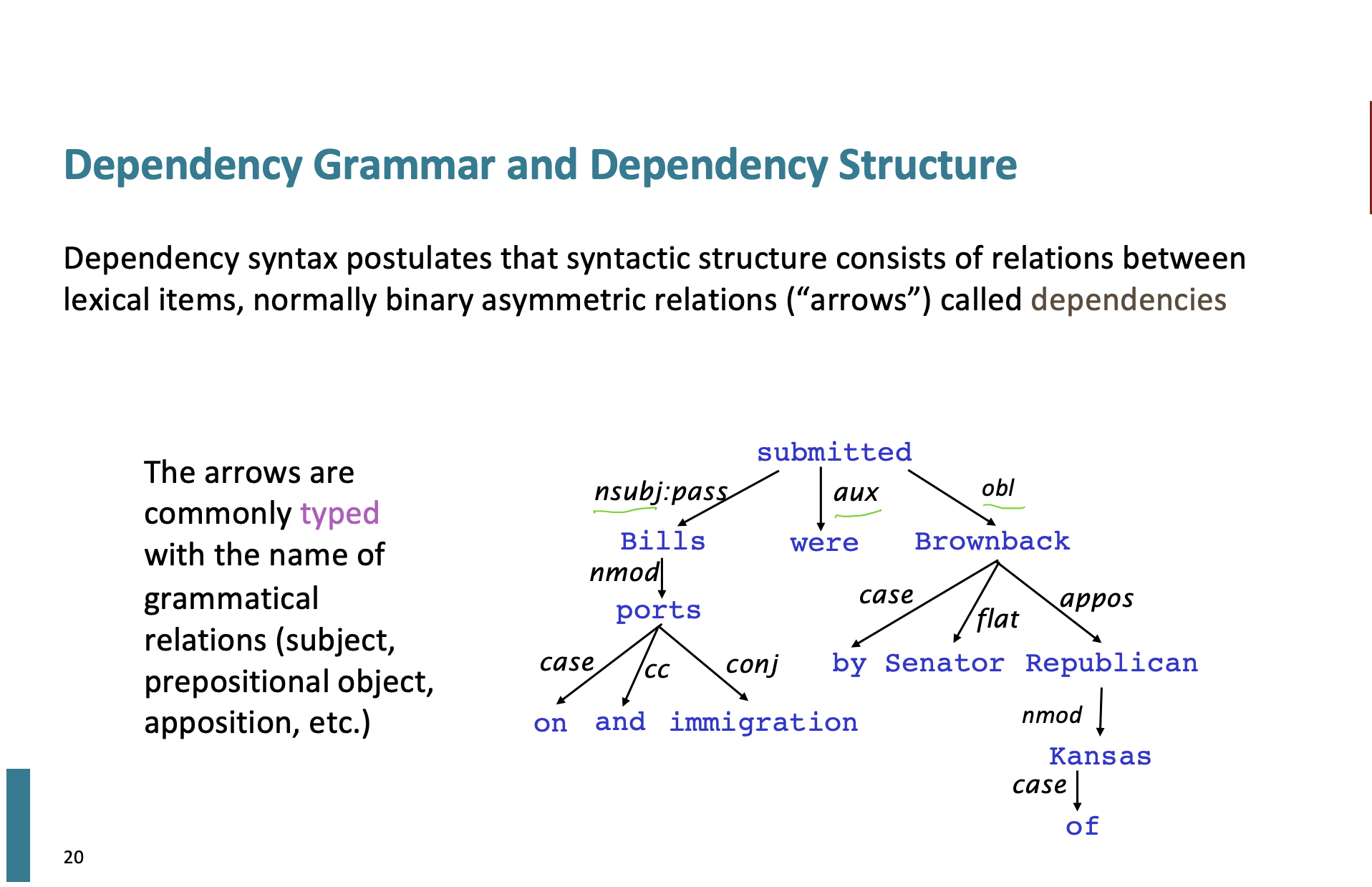
Look 은 crate에 superior, crate는 Look에 inferior한 관계이다.
그러니까 화살표를 시작하는 head는 governor, superior, regent라고 하고 화살표를 받는 dependent는 modifier, inferior, subordinate라고 한다.
사실 아직 이 관계를 어떻게 정하는지 애매하다.
crate가 door의 superior라는 건 살짝 의심?스럽다.
하지만 교수님께서 상자는 문 옆에 있기 때문에 상자에도 '문'의존 구조를 가지고 있다고 한다.
왜 문장 구조가 필요하지?
우리는 단어를 사용하지만 단어만으로 복잡한 의미를 설명할 수는 없다.
더 큰단위인 구문을 통해 의미를 생성하고 더 많은 구조를 통해 문장으로 청자에게 전달한다.
청취자는 단어가 어떤 단어에 의존적인지, 문장의 의미릴 이해해야한다.
우리는 기계가 사람처럼 문장을 이해할 수 있도록 만들어야 한다.
Ambiguity
간단하게 문장의 모호성에 대해 알아보자.
약간 우리말로 하면 문장의 중의성이라고 할 수 있다.
Prepositional phrase (전치사구)
San Jose cops kill man with knife
라는 문장이 있을 때,
1. 경찰이 살인의 주체가 되고 칼로 남자를 죽였다.
2. 칼을 든 남자를 경찰이 죽였다.
이 두가지 의미를 가질 수 있다.
대체로 전치사구는 모호성을 더한다.
Coordination scope
그리고 범위 모호성을 가지고 있다.
Shuttle veteran and longtime NASA executive Fred Gregory appointed to board
-> 셔틀 베테랑이랑 프레드 그레고리가 이사회에 임명 (2명이 임명)
-> 셔틀 베테랑이자 오랫동안 나사 전문가로 일한 프레드 그레고리가 이사회에 임명 (1명)
이렇게 두가지 의미를 가지고 있다.
Doctor: No heart, cognitive issues
에서도
No heart and cognitive issues와
No ( heart, cognitive) issues 이렇게 두가지로 의미가 확 달라진다.
Adjectival/ Adverbial Modifier
Students get first hand job experience
여기서 first를 hand 에 의존적일지 아니면 experience에 둘지에 따라 또 의미가 달라진다.
Verb Phrase attachment ambiguity
Mutilated body washed up on Rio beach to be used for Olympics beach volleyball
- 회손된 시신이 올림픽 배구 대회로 사용될 리우 해변에 떠밀려 왔다.
- 회손된 시신이 올림픽 배구 대회로 사용되기 위해 리우 해변에 떠밀려왔다.
보통 우리는 전자를 생각하지만 놀랍게도 이를 파파고에 돌려 해석하면
리우 해변에 떠밀려 올림픽 비치발리볼에 사용될 훼손된 시신
이렇게 해석해버린다;;;;;;;
그래서 한번 종속성을 나타내는 트리를 예를 들어보자.
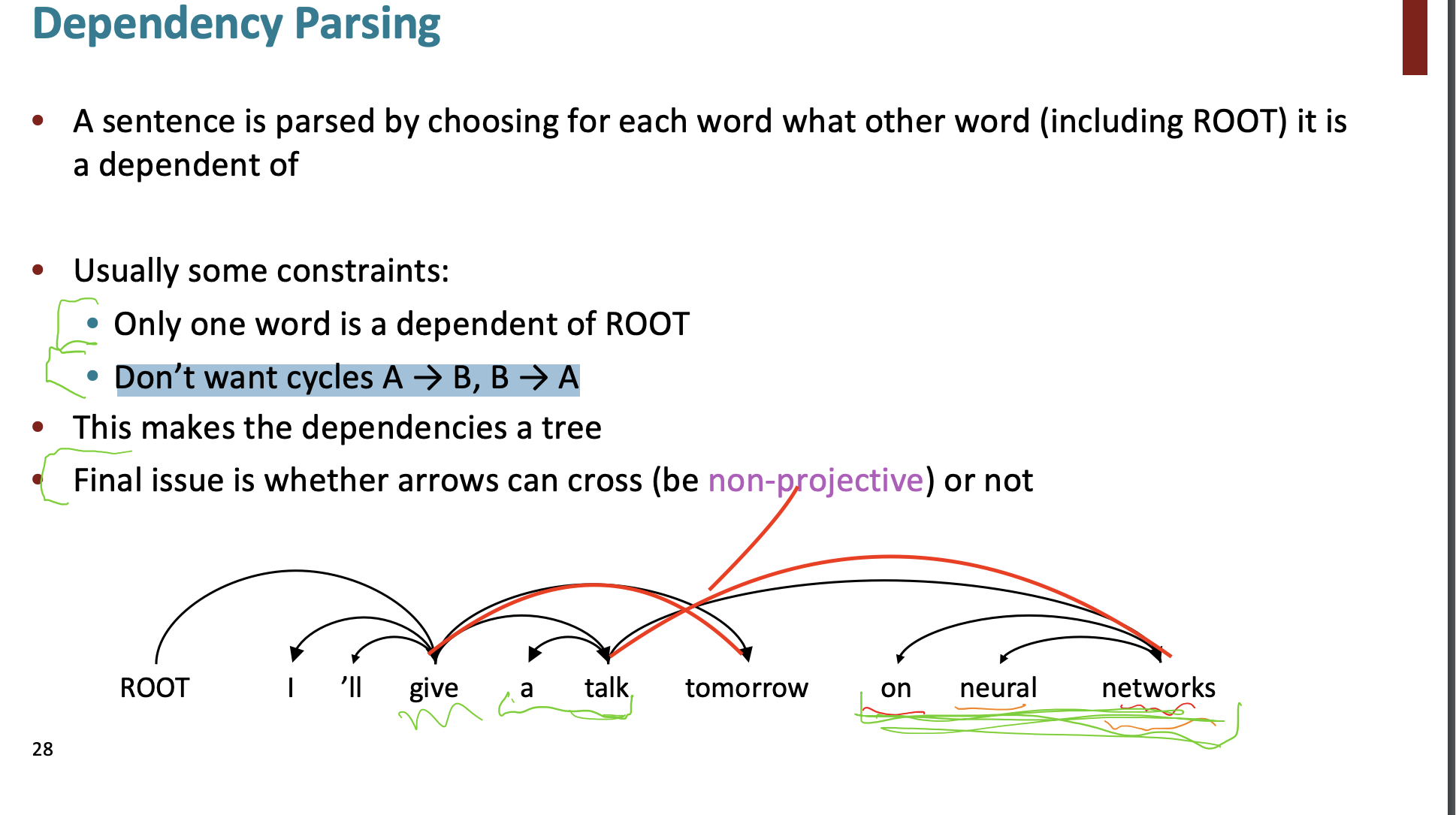
이렇게 문법이름으로 typed하여 화살표로 표시한다.
맨위 submitted를 여기서 root라고 한다.
가끔 fake Root를 추가하는데 이는 문장을 하나의 트리로 묶기 위함이다.
Dependency Grammar and Treebanks
그래서 언어학자들을 불러 언어 트리 뱅크를 만들었다고 한다.
treebank는 문법을 손으로 작성하는 것보다 훨씬 느리고 덜 유용해보이지만 많은 장점이 있다고 한다.

- Reusability of the labor : 재사용이 쉽다
- Broad coverage, not just a few intuitions : 폭 넓은 적용 범위
- Frequencies and distributional information
- A way to evaluate NLP systems : 가장 중요한것! nlp를 평가하는 방법이 된다.
Dependency parsing
그러면 이를 통해 parsing이 가능할까?
우리는 종속성 파싱을 어떤 정보를 통해 해야할까?
- Bilexical affinities : Bilexical를 한국어로 뭐라하는 건지 모르겠지만, 두 단어 사이에 실제 의미가 드러나는 관계로 파싱하는 것 같다.
- Dependency distance : 단어 사이가 가까우면 보통 종속성을 가지고 있다.
- Intervening material : 중간 동사 또는 마지막 구두점에 종속성이 있는 경우는 없다.
- Valency of heads : 어느 방향에 더 dependents가 많은지? (the cuddly cat을 예로 들면 cat 오른쪽보다 왼쪽에 the, cuddly가 있는 확률이 더 높다.)
dependency parsing
몇개의 제약사항들이 있다.
- Only one word is a dependent of ROOT: 각 단어에 대해 하나의 선택을 받아야 한다.
- Don’t want cycles A → B, B → A 사이클이 있으면 안된다.
마지막으로 생각할 사항은 projective 이다.
위 그림처럼 cross 되어도 될까?
Dependencies corresponding to a CFG tree must be projective.
CFG tree는 projective할 수 밖에 없다는 답을 가지고 있다.
- Most syntactic structure is projective like this, but dependency theory normally does
allow non-projective structures to account for displaced constituents
대부분 투영적 구조를 가지고 있지만 비-투영적 구조로 허용한다.
다음과 같은 예를 들면
Who did Bill buy the coffee from yesterday?
에서 Who 부터 From에 화살표를 그려 cross될 수 있지만, From을 앞으로 가져와서
From who did Bill buy the coffee yesterday?
이렇게 비 투영적 문장으로도 만들 수 있다.
그래 그러면 어떻게 파싱하는데??
여러가지 방법이 있지만 우리는 여기서 Transition-based parsing에 대해 알아볼 것이다.
이는 greedy method이다.
Transition-based parsing
우리는 4가지를 가지고 있다.
- stack : root 부터 시작한다.
- buffer : input sentence가 들어간다.
- arcs A : 의존성 세트이다. 시작은 empty set.
- actions 집합
그리고 3가지 행동 중 하나를 선택한다.
- Shift : buffer에서 stack으로 단어들이 옮겨간다.
- Left - Arc : 왼쪽에 있는 단어를 삼킨다(? 나중에 그림을 보면 이해가 된다.)
- Right - Arc : 오른쪽에 있는 단어를 삼킨다.
여기서는 행동을 결정하는 분류기를 만드는 것도 중요하게 된다.
그럼 예를 들어보자.
"I ate fish"
- start
stack : root
buffer : I ate fish - Shift : 일단 stack에는 아무 것도 없으니까 shift
stack : root I
buffer : ate fish - Shift : root 와 I는 아무 관계가 없다고 판단하여 shift
stack : root I ate
buffer: fish - Left Arc : I와 ate은 종속성이 있음. ate가 I를 수식함.
ate -> I 관계가 set of Arcs로 이동.
stack : root ate
buffer : fish
set of Arcs : ate -> I - Shift: root 와 ate의 관계 없음. shift
stack : root ate fish
buffer :
set of Arcs : ate -> I - Right Arc : ate 은 fish를 수식. ate->fish 가 set of Arcs로 이동.
stack : root ate
buffer :
set of Arcs : ate -> I, ate -> fish - Shift: 버퍼에 토큰이 존재하지 않지만 모든 토큰은 하나의 dependent를 가진다는 전제(제약조건)이 있기에 set of Arcs로 이동.
stack :
buffer :
set of Arcs : ate -> I, ate -> fish, root->ate
이러한 과정으로 수행되기 된다.
어떠한 state를 기반으로 행동을 결정하는 분류기가 필요해진다. (classifier) eg. softmax classifier
이 방법은 very fast linear time parsing이다. 왜냐하면 한방향으로 나아가기 때문이다.
논문을 살펴보면 state를 임베딩하는 방법으로 여러 Indicator features가 사용되었다.
그리고 많은 이러한 특징들을 계산하는데에 연산 비용의 95%를 차지했다고 한다.
정확도를 판단하면
꽤나 UAS (단어 관계)는 잘 판단했지만, 단어 관계사이 label의 정확도는 낮음을 알 수 있었다.
