
우리는 데이터를 가지고 모델을 만들어야 한다.
즉 데이터 x1, x2, x3, ... xn 을 통해 확률 분포 p(x)를 모델링 해야하는데, 이를 밀도 추정 이라 한다.
먼저 이산 확률 변수를 배우고 그 다음 연속 확률 변수인 가우시안 분포에 대해 배워보자.
2.1 이산 확률 변수
2.1.1 베르누이 분포
베르누이 시행은 결과가 둘 중 하나인 경우이다.
- 성공 (사건 발생 o)
- 실패 (사건 발생 x)
eg. 동전 던지기, 주사위에서 '2'가 나올 경우/아닌 경우
만약 예를 들어서 공이 10개가 있는데, 검은 공이 3개 빨간 공이 7개인 경우에 검정 공이 나오는 경우를 성공이라고 하면 p(1) = 0.3 p(0) = 0.7로 할 수 있다. (x=1를 성공)
우리는
p(x) = 0.3 (x=1) 0.7 (x=0)
또는
p(x) = x
로 확률 분포를 나타낼 수 있다.
그럼 평균을 구해보자.
E(x) = = 0 p(0) + 1 p(1) = p(1) = p
즉 성공확률과 동일하다.
분산을 구해보자.
V(x) = - =
= 0p(0) + 1p(1) - = p- = p(1-p) = pq
q는 보통 (1-p) 로 나타낸다.
관측값 데이터 집합 D = {x1,x2,...xn} 일 때 관측값들이 독립적으로 추출되었다면 가능도 함수를 다음과 같이 작성할 수 있다.
우린 항상 가능도 함수를 로그를 취한다.
그래서 추정값은
이는 데이터에서 x=1의 관찰값 수를 m이라 하면 Uml=m/N이다.
2.1.2 이항 분포
베르누이 시행을 여러번 했다고 하자.
이항 분포는 사건이 발생한 횟수를 확률 변수로 하는 분포이다.
만약 농구선수의 자유투 성공률을 80%라 했을 때, 10번을 던졌다고 하자.
만약 모두 다 실패했을 확률은?
그러면 한번은 성공하고 나머지는 모두 실패했을 확률은?
우리는 확률 분포를 유추할 수 있다.
그럼 이항 분포의 평균과 분산을 구해볼까..?
마크다운 수식으로 쓰기엔 오백년이 걸릴 것 같아 그림을 첨부한다.
<아이패패드 그림>
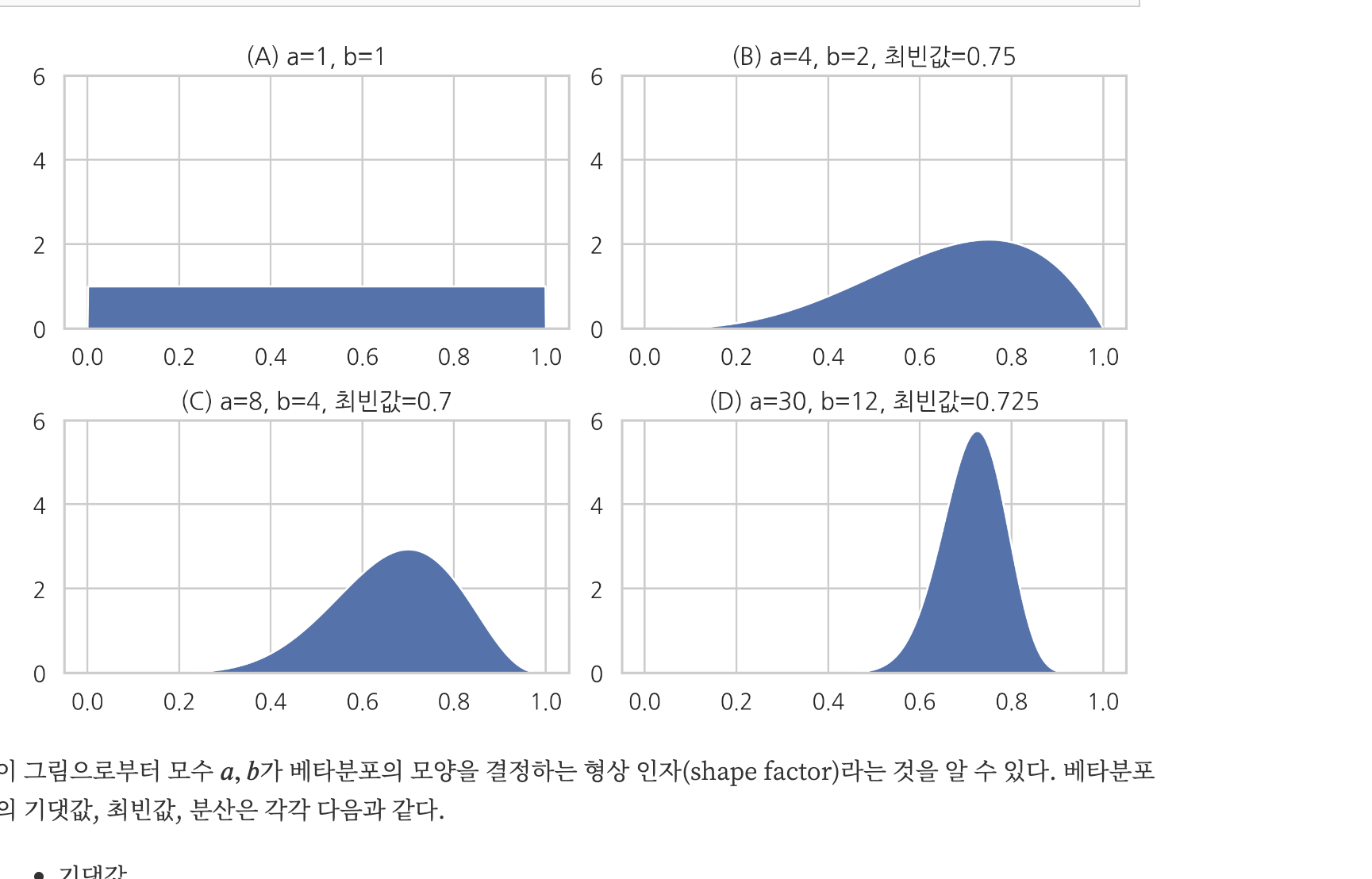
2.1.3 베타 분포
데이터 수가 작을 때 이항 분포를 사용하면 심각한 과적합이 일어나기 쉽다.
이 문제에 베이지안적으로 접근하기 위해서 매개변수 x에 대해 사전분포 p(x)를 도입하자.
사전 분포로 베타 분포를 사용한다.
이것또한 마찬가지로 평균과 분산을 구할 수 있으며, 마크다운 수식으로 작성하기 너무 귀찮아 직접 작성한 필기를 업로드 한다.
<아아이이패패드 그림>
매개변수 알파와 베타를 a,b라고 하면 이들은 x의 분포를 조절하기 때문에 초매개변수라고 한다.
이는 분포의 모양을 결정한다.
우리는 이항 가능도 함수와 사전 분포인 베타 사전 분포를 구해서 사후 분포를 구할 수 있다.
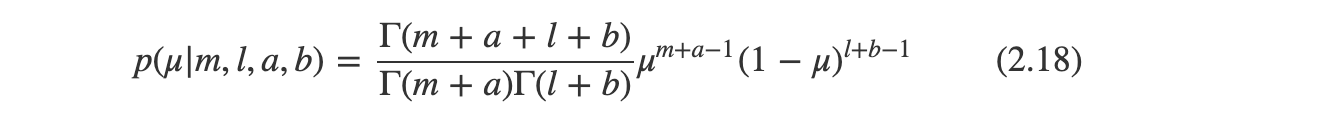
이는 x=1인 값이 m개 있고 x=0 인 값이 l개가 있는 데이터 집합을 관찰한 결과 사전 분포와 비교했을 때, a의 값이 m만큼, b의 값이 l만큼 증가함을 알 수 있다.
이사실로 a,b를 x=1,x=0에 대한 유효 관찰수라고 할 수 있다.
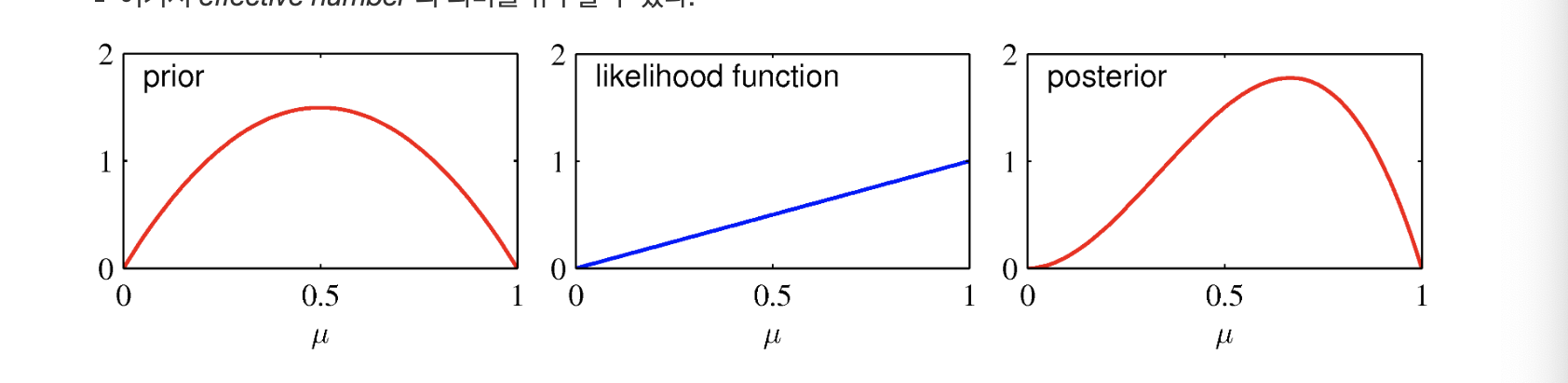
만약 추가적으로 데이터를 얻게 되면 지금의 사후 분포가 새로운 사전 분포가 될 수 있다. 매번 업데이트 단계에서 새로운 관측값에 해당하는 가능도 함수를 곱하고 새로운 수정된 사후 분포를 얻게 된다.
사전 분포에서 a=2, b=2인 베타 분포가 있다하고
가능도 함수는 N=m=1 즉 x=1이라는 관측값에 해당한다고 했을 때,
사후 분포는 a=3, b=2인 베타 분포가 된다.
만약 우리 목표가 다음 시도의 결과값을 가장 잘 예측하는 것이라면 데이터 집합 D가 주어진 상황에서 x의 예측 분포를 계산할 수 있다.
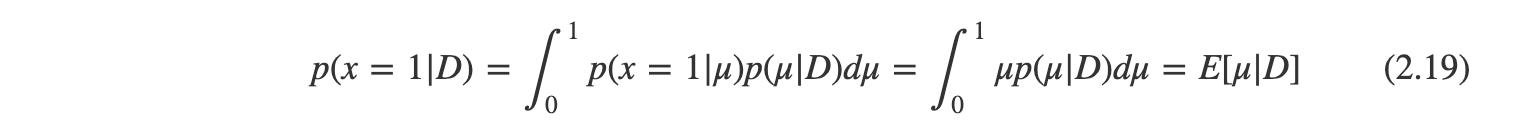
이는 x에 대한 평균값을 구하기만 하면 된다.
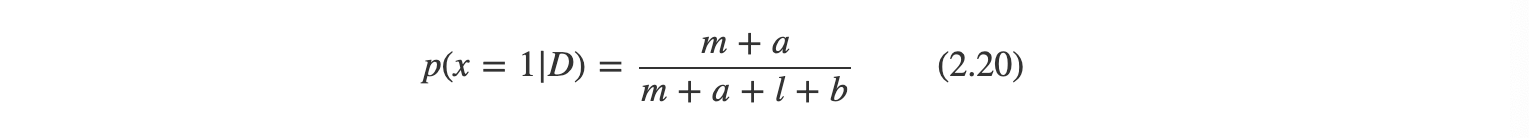
만약 관측값이 무한히 크다면, 최대 가능도의 결과값과 식 2.20는 같아진다.
이는 베이지안의 결과값과 최대 가능도의 결과값이 무한하게 큰 데이터집합 하에서 동일한 건 일반적이다.
위 4개의 그래프가 있었다.
그림에서 관측값이 클수록 그래프 모양이 뾰족하고 날카로워진다.
데이터 집합이 무한에 가까울 수록 분산이 0에 가까워지는 것이다.
데이터를 더 많이 관측할 수록 사후 분포의 불확실성의 정도는 꾸준히 감소하게 된다.
2.2 다항 변수
지금 껏 2개의 가능한 변수 중 하나만을 선택하는 문제를 다뤘다.
하지만 많은 경우 서로 다른 k개의 변수 중 하나를 선택하는 문제를 다루게 된다.
이 예를 원 핫 인코딩을 통해 설명한다.
만약 k=6인 상태에서 인 경우를 표현하면
로 표현할 수 있다.
만약 이 될 확률을 Uk라 한다면 x의 분포는
p(x|u) =
이다.
이를 통해 다음 식은 쉽게 증명할수 있단다.(증명은 pass)
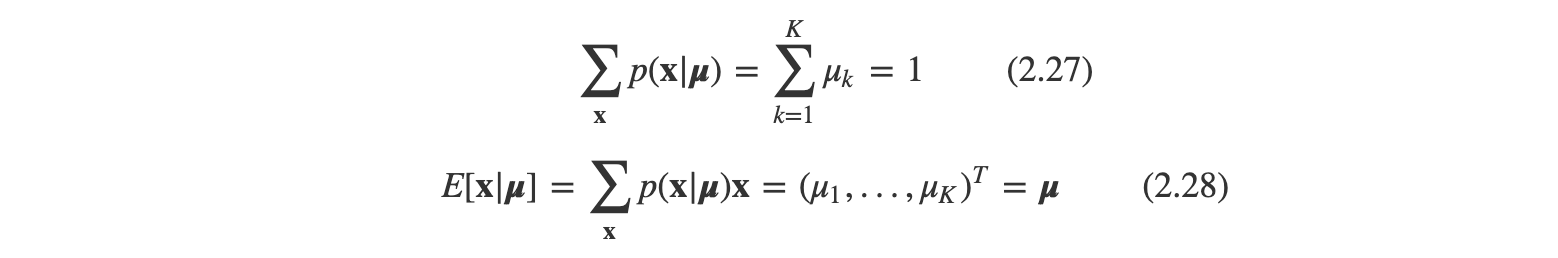
N개의 독립적인 관측값을 가진 데이터집합 D를 고려해본다면 해당 가능도 함수는

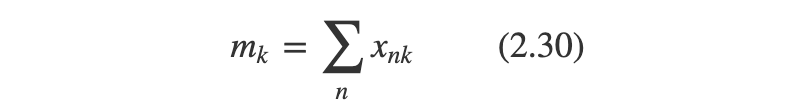
식 2.30를 = 1관측값의 숫자에 해당한다. 이를 충분 통계량이라 한다...
의 최대 가능도 해를 찾기 위해 여러식..(생략) 통해
라고 한다. 즉 이는 N개의 관측값 중에서 의 비율이다. (엇 어디서 많이 본듯한 느낌)
매개변수 와 관측값 숫자에 의해 결정되는 수량 m1,m2,,mk의 결합 분포를 고려해보면
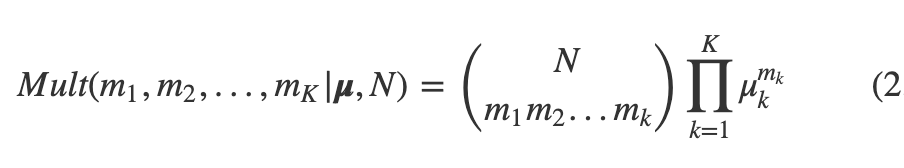
이런 형태를 띄고 이를 다항 분포라고 한다.
(m의 제약조건은 다음과 같다)

디리클레 분포
그럼 다항 분포의 사전 분포로 디리클레 분포에 대해 알아보자.
디리클레 분포는 베타분포의 확장판이라 할 수 있다.
디리클레 분포는 0과 1사이의 값을 가지는 다변수 확률 변수의 베이지안 모형에 사용된다.
예를 들어 k=3인 디리클레 분포 확률 변수 표본을 살펴보면
(0.2,0.2,0.6)
(0.5,0.5,0)
(1,0,0) 이렇게 들 수 있다.
사실상 베타분포의 확장이기 때문에 디리클레 분포는 베타분포의 모양과 비슷하다.
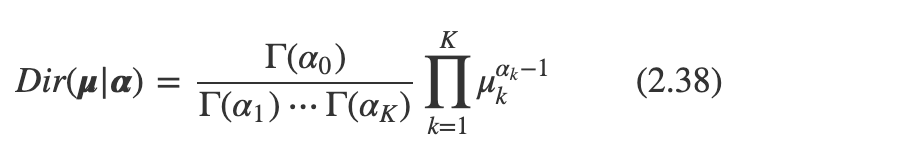
그리고 여기서 정의한 는 알파 1부터 k까지의 합을 의미한다.
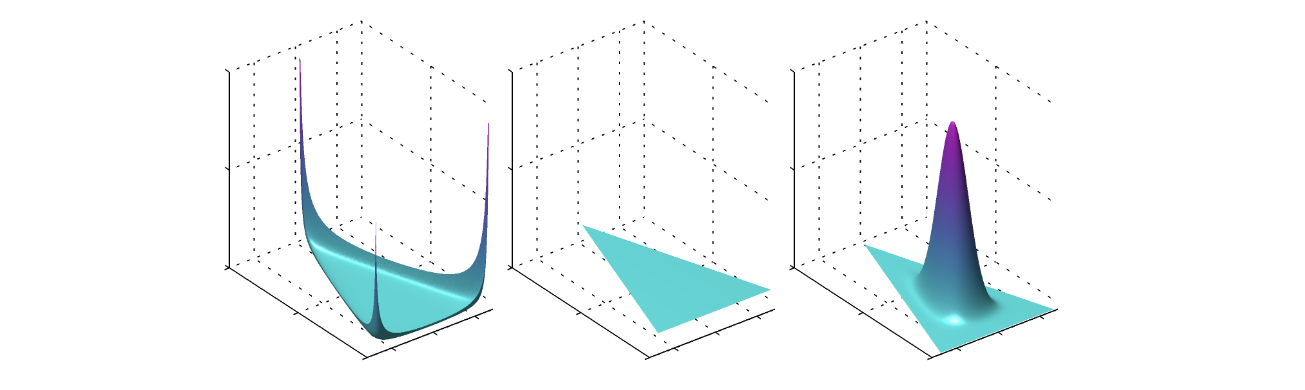
이 그림의 왼쪽은 를 0.1로, 가운데는 1로, 오른쪽은 10으로 설정한 것이다. 즉 이것 또한 마찬가지로 관측값이 클수록 뾰족한 형태의 분포가 됨을 알 수 있다.
이 때의 가능도 함수는
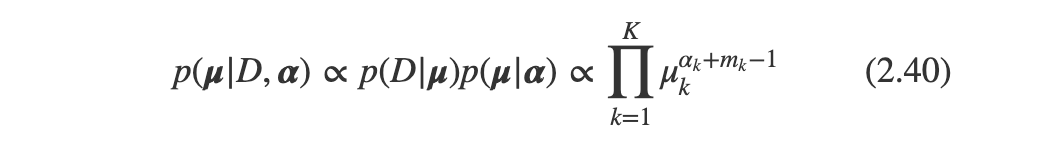
로 설정할 수 있고 이 또한 베타분포와 비슷한 형태임을 알 수 있다.
=> 마찬가지로 디리클레 분포는 다항 분포의 켤레 사전 분포이다.
식 2.38과의 비교를 통해 구해보자.
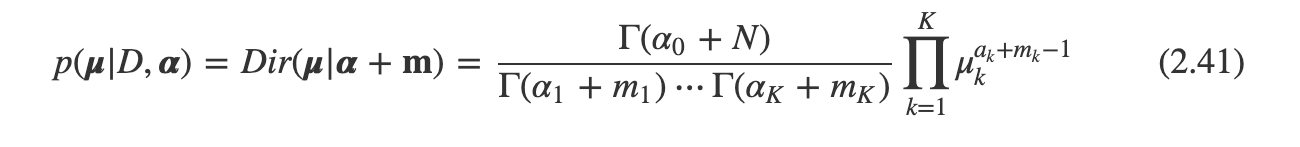
여기서 m = 이며 디리클레 사전 분포의 매개변수 를 인 관측값의 유효 숫자로 해석한다.
만약 k=2가 된다면 디리클레분포는 베타 분포가 된다.
2.3 가우시안 분포
여기서부터는 Youtube 강의 자료 위주로 공부한다.
책이 너무 어렵기 때문이다...
가우시안 분포가 무엇인지, 가우시안 함수를 유도하는 강의이다.
함수는 그냥 외워도 좋고 아래 강의를 통해 공식을 유도하는 것도 좋다. 하지만 후자가 더 가슴속에 와닿는 것이 분명 있다고 생각한다.
그리고 책이 너무 이해가 안되서 가우시안에 대한 내용을 검색하다가 찾은 강의 영상이다.
1,2,3,4,5 총 5개의 강의가 있는데 순서대로 처음부터 강의를 들으면 왜 좌표계에서부터 가우시안을 설명하는지 이해가 된다.
