패턴인식과 머신러닝
1.[PRML] Chapter 1 : Introduction
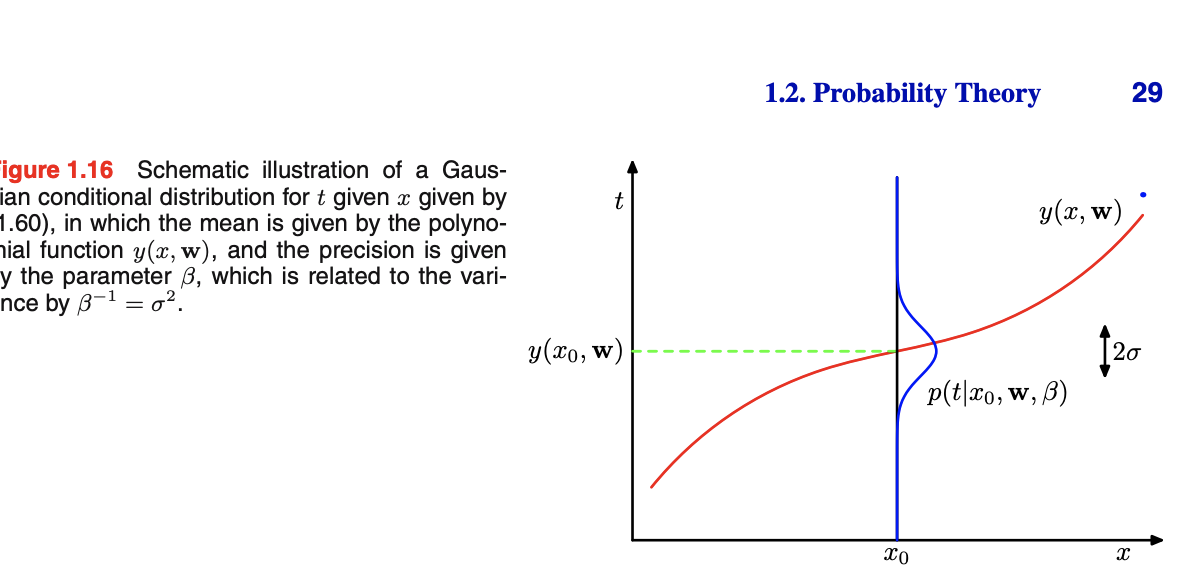
Chapter 1 review 전반적으로 chapter 1은 확률 통계 지식을 간단하게 리뷰하고 있다. 만약 확률 통계를 배우지 않았다면 (머신러닝 기초..) 먼저 공부를 하고 오시길. 1.1 예시 예시로 다항식 곡선 피팅을 들었다. 실수값의 입력 변수 x를 관찰하
2023년 11월 3일
2.[PRML] Chapter 2: 확률 변수

우리는 데이터를 가지고 모델을 만들어야 한다. 즉 데이터 x1, x2, x3, ... xn 을 통해 확률 분포 p(x)를 모델링 해야하는데, 이를 밀도 추정 이라 한다. 먼저 이산 확률 변수를 배우고 그 다음 연속 확률 변수인 가우시안 분포에 대해 배워보자. 2.
2023년 12월 14일
3.[PRML] Chapter 9 : 혼합 모델과 EM
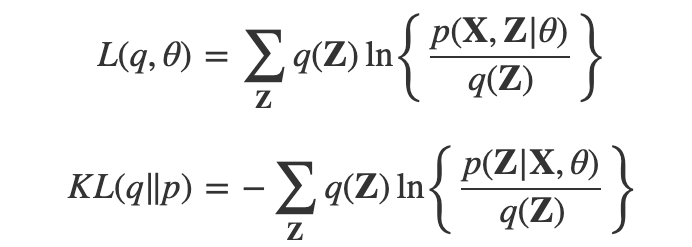
Chapter 9 K-Means clustering k-평균 집단화는 비지도 학습 알고리즘이다. 이 알고리즘의 목적은 주어진 데이터를 k개의 클러스터로 나누는 것이다. 데이터 내의 패턴을 찾아 유사한 특성을 가진 데이터 포인트 끼리 묶어 그룹화를 진행한다. 기본
2024년 1월 14일