논문 링크 : https://arxiv.org/pdf/1902.00751.pdf
ICML 2019
첫번째 논문 리뷰이다.
Abstract
현재 Downstream tasks들을 풀기 위해서 Fine-tuning 을 사용하면, parameter inefficient문제가 있다.
여기서 parameter inefficient는 전체 새로운 모델이 매번 task에 대해 train하는 것이다.
이 논문은 Adapter module을 사용하여 위 문제를 해결한다.
Adapter module은 compact하고 extensible하다는 장점이 있다.
어댑터의 효과를 보기 위해서 BERT transformer에서 파라미터를 100% 훈련한 fine-tuning model과 Adapter module을 사용해서 파라미터를 3.6%사용한 모델을 비교했다.
full fine-tuning한 모델과 성능은 오직 0.4%차이 밖에 나지 않았다.
Introduction
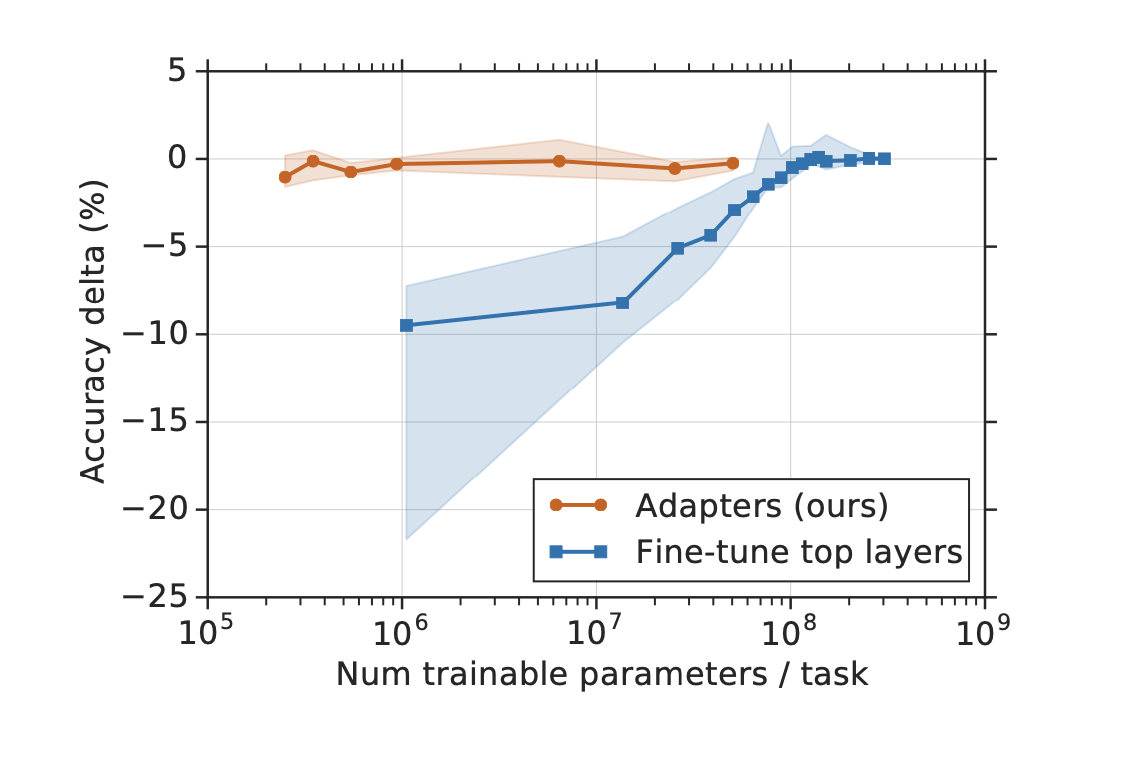
x축은 작업당 훈련가능한 파라미터 수이다. 오른쪽으로 갈수록 파라미터의 수가 늘어가는 것이다.
y축은 정확도를 의미한다.
Adapters가 파라미터가 적을 때에도, Fine-tune top layers보다 정확도가 높은 것을 알 수 있다.
나중에 Section3에서 더 자세히 다룰 예정이다.
Goal
논문 저자들의 목표는 새로운 작업에 대해 매번 새로운 모델을 훈련하는 대신, 새로운 작업 모두에 대해서도 잘 작동하는 시스템을 개발하는 것이다.
-> 모델의 파라미터를 많이 변경하지 않는것 = 모델끼리 파라미터를 많이 공유하는 것은 클라우드 서비스 같은 응용에서도 유용하다.
Adapter Module은 compact 하고 extensible한 downstream model을 만든다.
Compact model : 작업당 조금의 파라미터만을 추가해서 문제를 해결하는 모델
Extensible model : 이전 작업을 forgetting 하지 않고 점진적으로 새로운 문제를 풀 수 있도록 훈련되는 모델이다.
Transfer learning
NLP에서 transfer learning 기법으로 Feature-based와 Fine-tuning기법 2가지가 있다.
이 두가지 기법에 대해서 간단하게 알아보자.
Feature-based
이 방법은 사전 훈련된 모델의 출력을 특징(feature)로 사용하는 방식이다. 모델의 출력 층에서 추출된 특징들이 다른 모델의 입력으로 사용된다.
즉 사전 훈련된 모델을 수정하지 않고, 추가 학습 동안 파라미터가 변경되지 않는다. 사전 훈련 모델이 학습한 풍부한 특징을 활용하고자 할 때 유용한 방법이다.
예를 들어서 BERT와 같은 사전 훈련된 언어 모델에서 문장이나 문서의 임베딩을 추출하고, 이를 텍스트 분류, 감정 분석 등의 다른 NLP작업에 활용하는 방법이 있다.
Fine-Tuning
이 방법은 사전 훈련된 모델 전체 또는 일부를 새로운 작업에 맞게 추가학습하는 방식이다.
사전 훈련된 모델의 파라미터가 새로운 데이터셋에 맞게 조정된다. 전체 구조를 미세조정할 수 있다.
사전 훈련된 모델이 이미 가지고 있는 지식을 기반으로 새로운 작업에 대한 성능을 최대화하고자 할때 사용하고, 특히 작은 데이터셋으로 작업할 때 유용하다.
최근 연구에 따르면 Fine-tuning 방법이 Feature-based 방법보다 종종 더 좋은 성능을 보인다고 한다.
Feature-based 와 Fine-tuning 모두 각각의 작업에 대해서 새로운 가중치 세트를 필요로 한다. 만약 작업간에 네트워크의 lower-layer가 공유되고 있다면, Fine-tuning이 좀 더 parameter efficient하다고 한다.
- Lower layer는 일반적으로 더 기본적이고 범용적인 특징을 추출한다. 하위 계층이 공유가 되고 있다면 모든 계층에 대해서 학습할 필요가 없기 때문에 parameter efficient하다.
Multi-task and Continual
Adapter-based tuning은 multi-task 와 continual learning과 관련이 있다.
하지만 다른 점은 멀티 태스크는 모든 작업에 대해 동시접근(simultaneous access)을 요구하지만 adapter-based tining은 요구하지 않는다.
Continual learning 시스템은 끝없는 작업 스트림으로 부터 배운다는 점을 목표로 한다. 이러한 파라다임은 네트워크는 re-training 후 이전 태스크를 잊는 경향이 있기에 어려운 문제이다. 하지만 어댑터는 공유 매개변수가 고정되어 있고 작업이 서로 상호작용하지 않는 다는 점에서 다르다. 이 의미는 '어댑터 모델은 파라미터 숫자를 사용한 이전 모델 작업을 완벽하게 기억한다'라는 뜻이다.
Adapter tuning for NLP
Adapter tuning는 3가지 key properties를 가지고 있다.
- 좋은 성능
- 순차적으로 작업에 적용가능, 하지만 동시 엑세스는 요구되지 않음
- 작업당 소수의 매개변수만 추가함
위 속성들을 만족하기 위해서 새로운 bottleneck adapter module을 제안한다. 어댑터 모듈 Tuning하는 것은 모델에 downstream task에 대해 훈련하는 작은 수의 새로운 파라미터를 추가하는 것을 포함한다.
Vanilla fine-tuning 실행할 때, 네트워크의 top-layer부분을 수정하려고 한다. 왜냐하면 upstream과 downstream의 라벨 공간과 손실(loss)가 다르기 때문이다.
Adapter의 경우는 downstream 작업에 대해 사전 훈련된 네트워크의 용도를 변경하기 위해서 좀 더 general한 아키텍쳐 수정을 한다.
또한 Fine-tuning은 새로운 top-layer와 기존 original weights가 같이 학습된다. 대조적으로 adapter tuning에서는 original weights는 frozen
(그대로)되기 때문에 많은 작업에 대해 파라미터 공유가 가능한 것이다.
Adapter Module은 두가지 main feature를 가지고 있다.
1. 적은 파라미터
2. Near-identity 초기화
Near-identity 는 입력을 거의 그대로 출력하도록 설정하는 것이고 모델의 안정적인 학습을 위해 요구된다.
Near-identity를 활용하면 훈련 시작시, 원래의 네트워크가 거의 영향받지 않는다.
Adapter와 관련해서 발견한 사실 몇가지가 있다.
- 훈련중에, 어댑터들은 전체 네트워크의 활성화 분포를 변경하려 할 수 있다.
- 어댑터 모듈은 필요하지 않으면 무시될 수 있다.
- 몇가지 어댑터는 다른 어댑터보다 더 네트워크에 영향을 줄 수 있다.
- 초기화가 Identity function와 멀리 떨어진다면 학습이 실패할 수 있다.
더 자세한 내용은 3.6절에 가서 알아보자.
Instantiation for Transformer Networks
Transformers 아키텍처 기반으로 Adapter tuning을 진행했다.
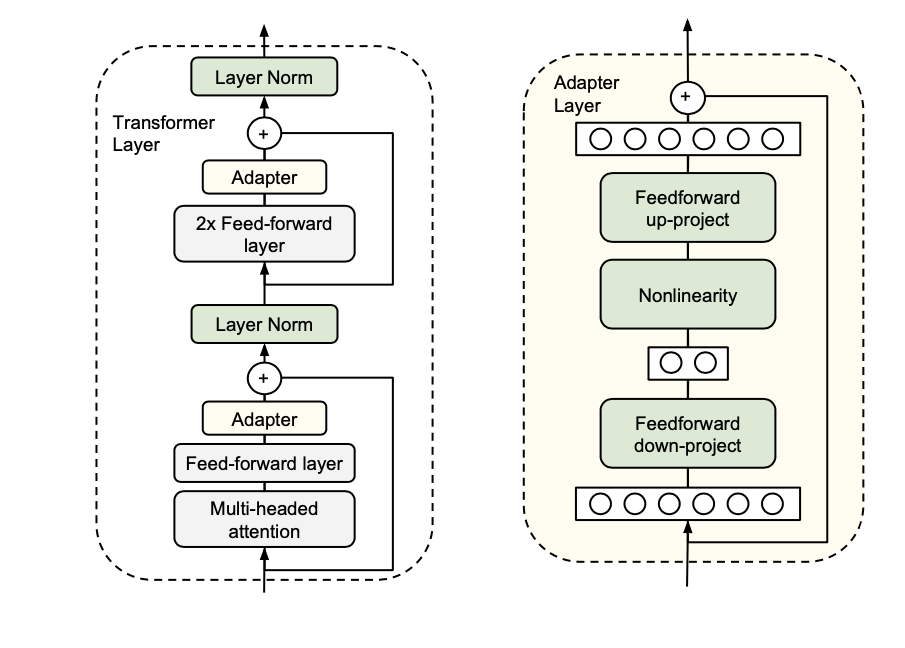
위 그림이 이 논문에서 제시한 Adapter 아키텍처이고 왼쪽은 Transformer에 적용한 것이다.
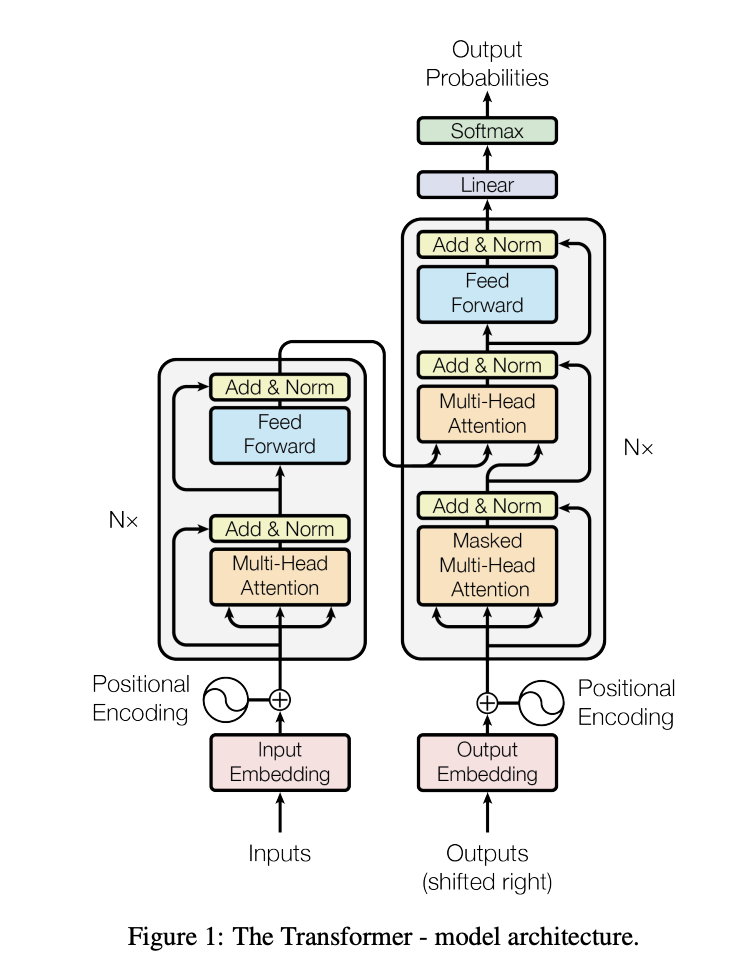
참고로 Transformer의 구조는 위와 같다. (출처: Attention Is All You Need)
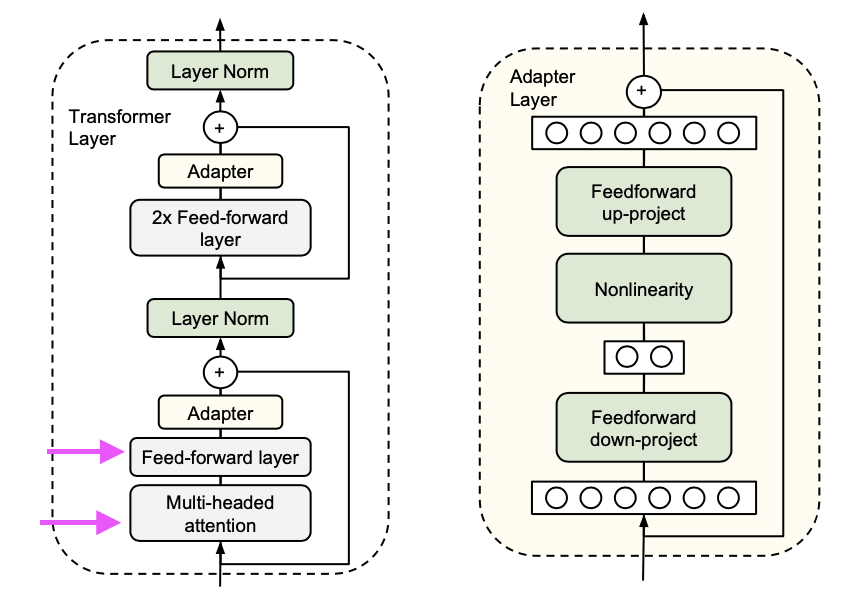
Transfromer의 각 레이어는 2개의 sub layer을 포함하고 있다.
- Attention layer
- Feedforward layer
2개의 레이어를 수행하고 나서 바로 Projection이 이루어진다.
Projection의 목적은 sub-layer의 출력을 변환하여 트랜스포머 모델의 해당 계층의 입력크기와 동일하게 맞추기 위함이다.
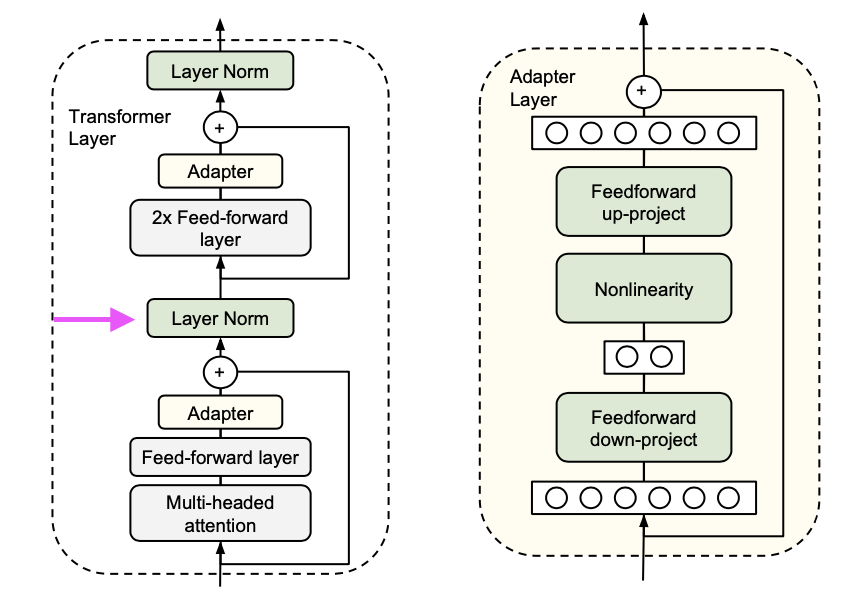
위 레이어의 출력은 Layer Normalization로 들어간다.
논문 저자는 이 sub-layer들 다음 2개의 직렬 어댑터를 삽입했다.
초록색 화살표는 Projection을 의미한다.
어댑터는 입력크기로 다시 Projection한 뒤 skip-connection을 더하기 전에 sub-layer의 출력에 적용된다. 그리고 어댑터의 결과는 layer normalization에 전달된다.
skip-connection은
자주색 선을 의미한다. 중간 과정을 생략해서 연결하는 방법이다.
Adapter Layer
이제 어댑터의 구조에 대해 알아보자.
파라미터의 수에 제약을 두기 위해서 bottle-neck구조를 제안했다.
원래의 d 차원을 m차원으로 비선형을 적용하여 투영(Projection)한 다음 다시 d차원으로 project시킨다.
layer 당 추가되는 total parameter는 이다.
- 첫번째 투영: d->m 입력 특징 d에 대한 출력 특징 m이기 때문에 파라미터의 수 dm개. 그리고 편향은 m개 추가
- 두번째 투영: m->d 입력 특징 m에 대한 출력 특징 d이기 때문에 파라미터 수 md개. 그리고 편향은 d개 추가
로 설정한다. m은 bottle-neck dimension으로 파라미터의 효율성과 성능을 절충하는 간단한 방법이다.
- m이 작아지면 작아질 수록 전체 파라미터들도 작아진다. 논문 저자는 0.5%~8%로 파라미터의 수를 조절했다.
여기서도 skip-connection을 한다.
이 skip-connection을 하면 원래 입력이 거의 그대로 다음 레이어로 전달된다. 따라서 Projection layer의 파라미터가 거의 0이면 이 레이어 또한 거의 identity fuction으로 적용된다.
Adapter 학습과 동시에 새로운 layer-Normalization도 학습한다. 하지만 이 layer-normalization만 하게되면 성능이 좋지 않았다.
Experiments
GLUE를 포함하여 매우 다양한 실험을 진행했다.
Experimental Settings
사용한 네트워크 : pre-trained BERT Transformer network
훈련 진행 : Devlin et at(2018)에 따름.
최적화 : Adam (10%씩 학습률 증가한 다음 어느순간 선형적으로 0으로 감소)
모든 실험은 4 Google Cloud TPU, batch size는 32로 학습되었다.
다양한 하이퍼파라미터 조합을 사용하여 모델을 여러번 학습하고 가장 성능이 좋은 모델을 선택했다. (hyperparameter sweep)
분류 문제의 경우에서 GLUE의 경우엔 GLUE benchmark을 따랐고, 다른 분류 문제의 경우 논문 저자가 직접 test-set을 만들어 정확도를 보고 했다.
GLUE benchmark
훈련 모델은 pre-trained BERT-large model이다.
24개의 layer을 가지고 있고 330M개의 파라미터를 가진 모델이다.
작은 Hyperparameter sweep을 진행했다.
- learning rate : {}
- epoch : {3,20}
- fixed adapter size(number of units in the bottleneck) : {8, 64, 256} -> 어댑터 사이즈만이 어댑터내에서 조절하는 하이퍼파라미터이다.
- 검증 세트에서 가장 좋은 모델을 찾기 위해서 다른 랜덤시드에서 5번을 re-run했다.
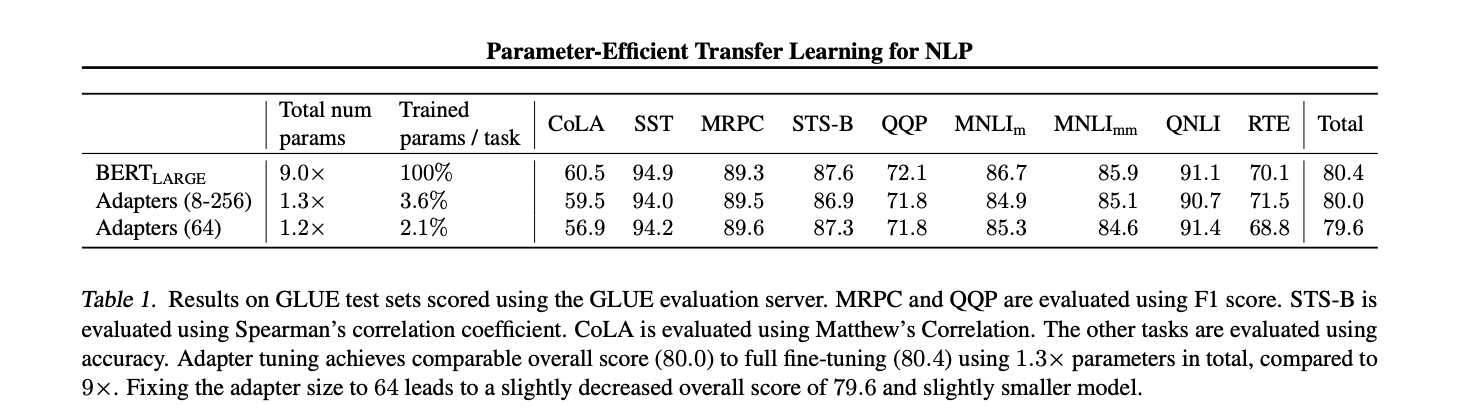
Table 1은 결과를 요약한다.
어댑터는 평균적으로 80.0점이라는 GLUE점수를 얻었다.
Full fine-tuning은 80.4점을 얻었다.
실험 결과,
- 데이터 셋 마다 최적 어댑터의 크기가 달랐다.
- MNLI에는 256, RTE에서는 8이 선택되었다.
- 항상 크기를 64로 선택하면 정확도가 79.6으로 줄어들었다.
BERT의 total number of parameter 와 비교해서
Fine-tuning : 9X
Adapter : 1.3X
의 파라미터 수의 차이를 보였다.
Additional Classification Tasks
추가적인 Task도 진행했다.
훈련 모델 : (12 layer로 구성)
훈련 예제의 숫자 : 900 ~ 330k
클래스 범위 : 2 ~ 157
평균 텍스트 길이 : 57 ~ 1.9k
Hyperparameter sweep을 진행했다.
- learning rate : {}
- epoch : {20, 50, 100}
- fixed adapter size(number of units in the bottleneck) : {2,4,8,16,32,64}
- batch size : 32
- 검증 셋에서 최적의 값을 찾음
- Variable fine-tuning을 추가적으로 진행 : 오직 N개의 top layer만 fine-tuning한다. {1,2,3,5,7,9,11,12}로 n 구성.
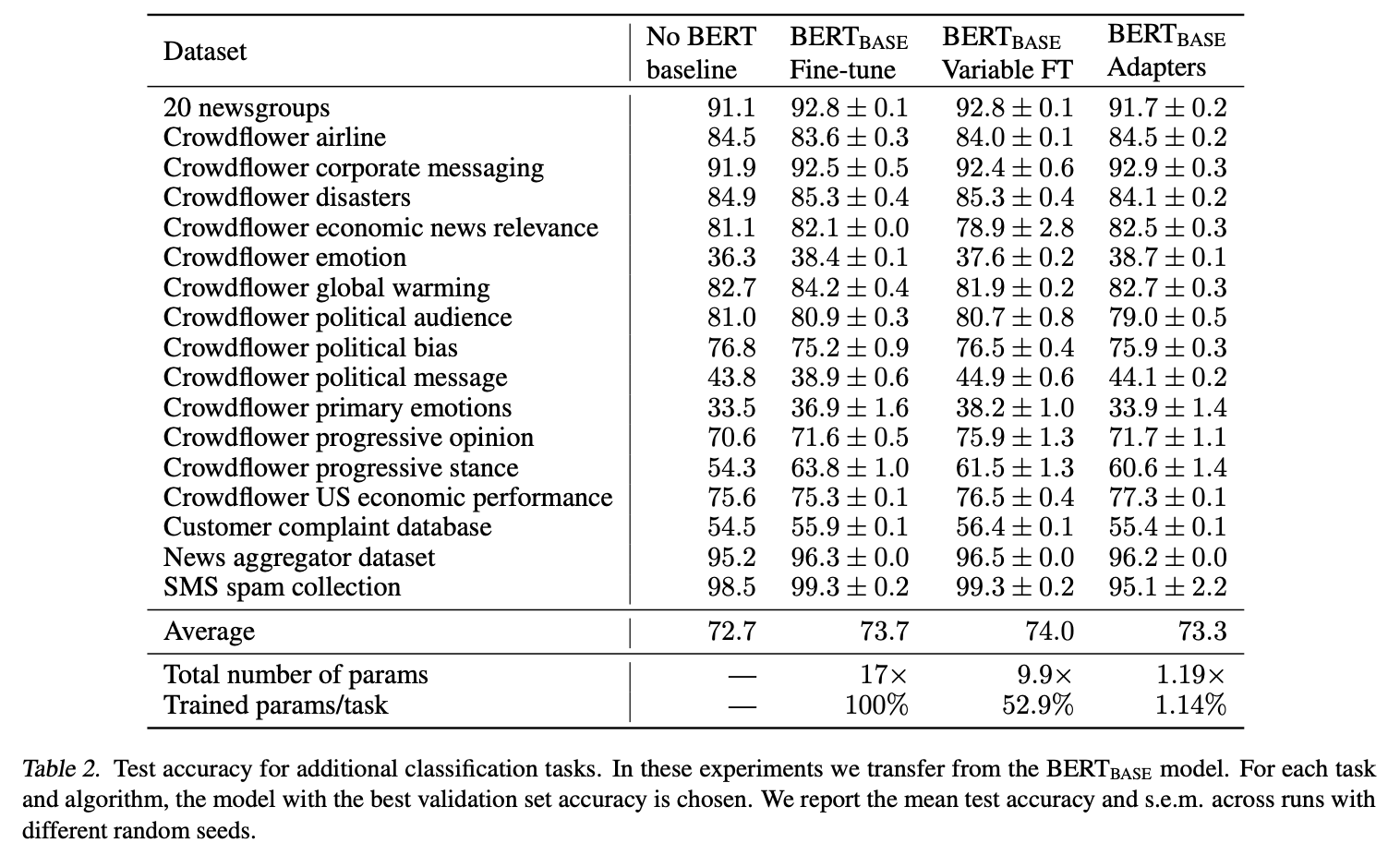
위 표를 보면 BERT fine-tuning 모델이 평균적으로 더 높은 점수를 보였다. 하지만 점수의 차이는 크게 나지 않았고 Fine-Tuning은 17배의 파라미터 수, Variable fine-tuning은 9.9배이지만, Adapter의 경우 1.19배의 파라미터만 필요했다.
GLUE 실험과 비슷한 실험 결과를 보였다.
Parameter/Performance trade-off

GLUE와 Additional Task에 대해서 parameter 와 성능의 trade-off를 보여주는 그래프이다.
- Fine-tuning : GLUE에선, 오직 상위 몇개의 layer만 fine-tune 되는 경우 성능이 급격하게 떨어지는 것을 볼 수 있다. 추가 실험의 경우, 학습을 덜 할 수록 더 좋은 이득을 보이는 경우가 있기 때문에 GLUE보다는 덜 저하되는 모습을 볼 수 있다.
- Adapter: 두개의 실험 모두에서 fine-tuning보다 좋은 성능을 보였다.
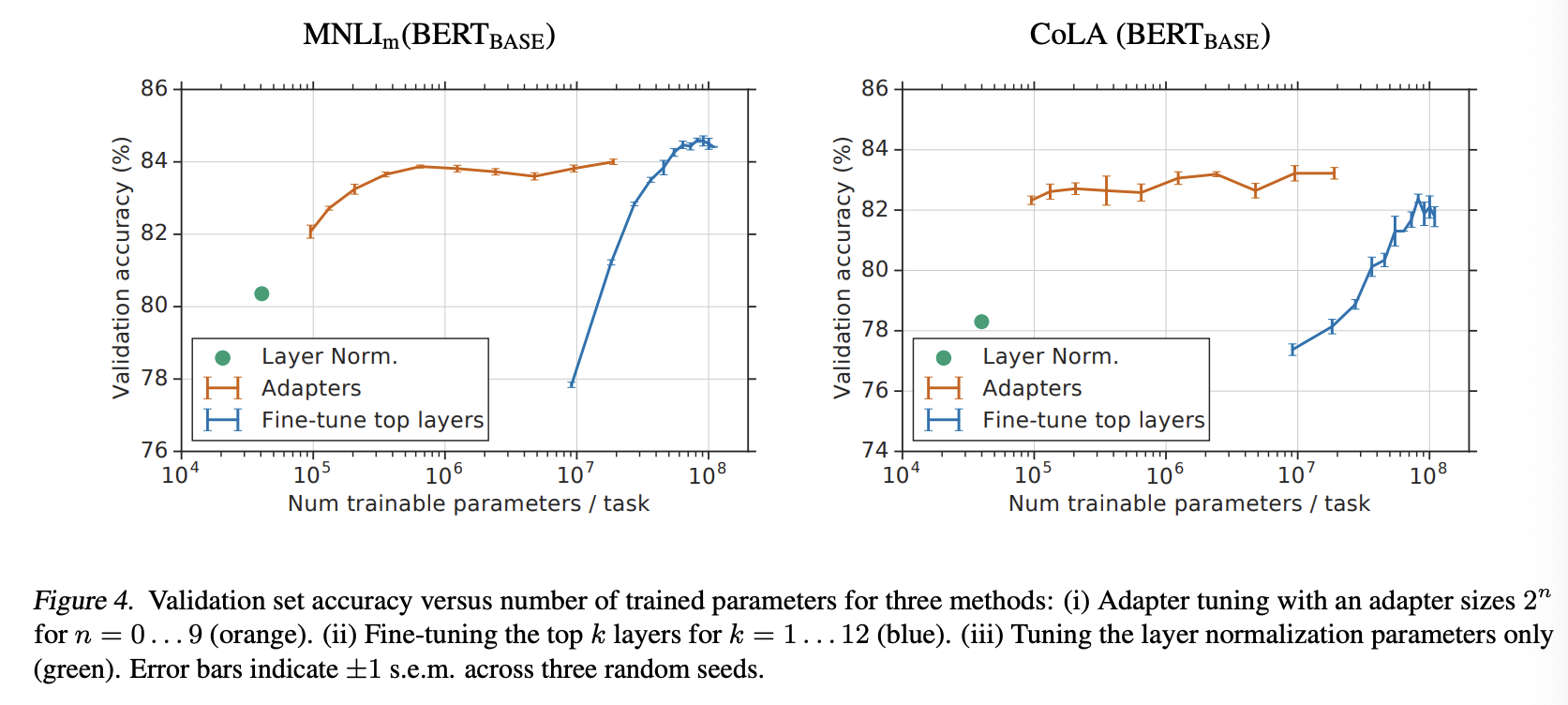
Figure4는 GLUE Task에 대해서 더 자세한 설명을 보여준다.
와 COLA에 대한 실험이다.
네트워크의 top-layer는 좀 더 task-specific 한 파라미터를 훈련한다.
Fine-tuning은 Adapter와 비교해서 대체적으로 파라미터를 줄이면 성능이 줄어드는 경향이 있다.
예를 들어서 맨 위 layer만 학습했을 때, Fine-tuning의 경우는 9M의 파라미터와 약 77.8%의 validation 정확도를 보였다.
사이즈가 64인 Adapter의 경우에는 2M의 파라미터와 약 83.7%의 정확도를 보였다.
그리고 layer normalization의 파라미터만 tune한 경우도 실험했다. 오직 40k의 파라미터만 훈련가능했는데, 결과는 나빴다.
결과적으로 Adapter를 사용함으로써, 원래 모델의 0.5%~5%의 파라미터 학습만으로 Fine-tuning과 비교했을 때의 결과가 1% 차이밖에 나지 않았다.
SQuAD Extractive Question Answering
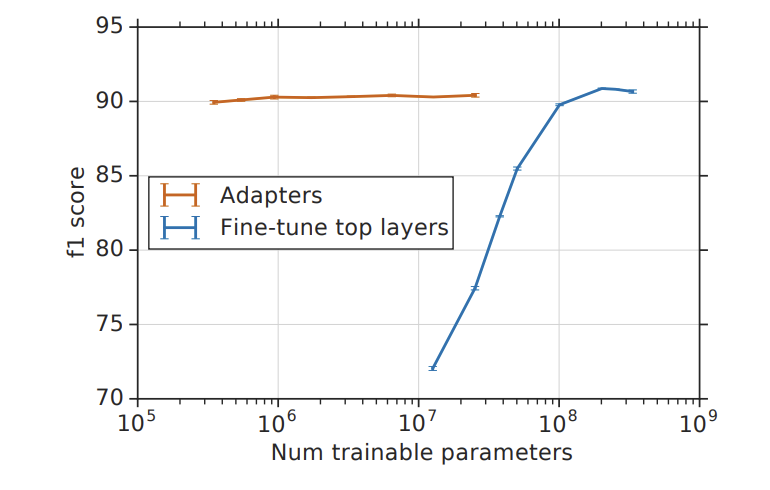
SQuAD v1.1에 대한 실험도 진행했다.
위 그림인 Figure 5는 SQuAD validation set에 대한 실험 결과이다. 이전 실험과 비슷한 결과를 보였다.
Analysis and Discussion
Adapter가 정말 영향력이 있는 건지 더 정확히 알아보기 위해 re-evaluate 해본다.
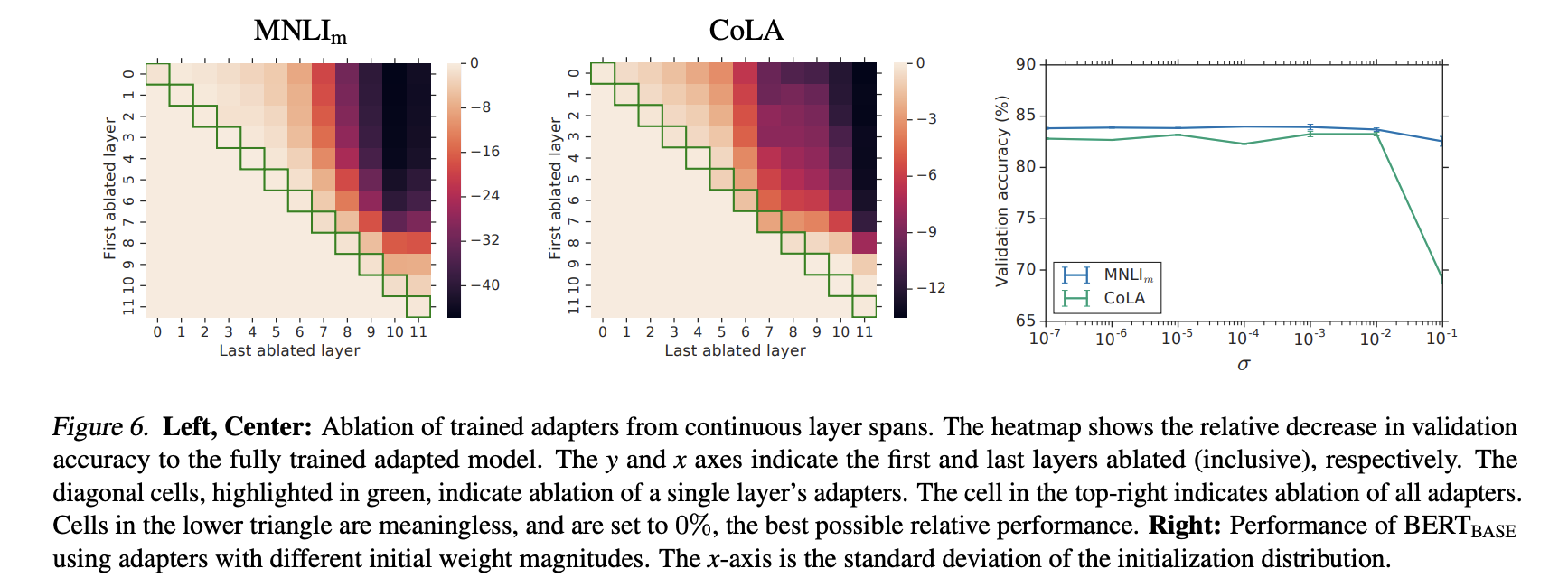
Adapter가 제거되었을 때, 모델의 검증 정확도가 어떻게 감소하는지 나타내는 실험이다.
Figure 6은 히트맵 diagonal을 보여준다. x축은 마지막으로 제거된 층이고 y축은 첫번째로 제거된 층을 의미한다.
대각선 셀(녹색 칸)은 단일 계층의 어댑터만 제거했을 때 정확도 감소를 나타낸다. 각 계층이 개별적으로 얼마나 중요한지 파악할 수 있게 한다. 하지만 단일 계층만 제거 된 경우는 최대 2%만 감소했다.
하지만 모든 어댑터가 제거된 경우 MNLI에서는 37%, CoLA에서는 69%가 감소했다.
어댑터 하나는 전체 네트워크에 적은 영향을 주지만 전체 어댑터의 효과는 크다는 것을 알 수 있다.
대각선에서 멀어질 수록 더 많은 계층이 제거 된다. Figure 6은 lower layer에서는 Adapter가 higher layer와 비교해서 더 적은 영향을 주는 것을 알 수 있다. 0~4층을 제거함에도 거의 영향이 없는 것을 알 수 있다.
어댑터는 higher layer를 더 우선순위로 둔다.
우리는 어댑터 모듈의 뉴런의 수와 초기화 규모의 Robustness를 조사할 것이다.
초기화 규모 영향을 분석하기 위해서 표준 편차를 로 설정했다.
Figuer 6의 오른쪽 그래프를 보면 에 대해서는 두 선 모두 robustness를 보였지만, CoLA의 경우 초기화가 너무 커지면 성능이 떨어지는 경우를 보였다.
