[Paper Review] MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer
Paper Review

논문 pdf: https://arxiv.org/pdf/2005.00052.pdf

간단하게 논문의 소개를 보자.
기존에는 어떤 문제점이 있었고, 어떻게 해결하는지 알아보자.
Introduction
기존 cross-lingual transfer 문제점
- 모든 언어를 표현하기에 capacity가 부족
- 근거로는 첫번째, vocabulary size(Artetxe et al. 2020)
- curse of multilinguality(Conneau et al. 2020)
- trade off between language coverage and model capacity
- 전세계 7000개 이상의 언어를 포함하는 것은 불가능
- 다국어로 사전 훈련된 모델에서 low-resource language(데이터 부족 언어)의 성능은 ⬇️
- 사전 훈련할 때, 학습되지 않은 언어가 나올 때는(unseen) 매우 성능 저하
그래서 MAD-X를 제안한다.
Multiple ADapters for Cross-lingual transfer(MAD-X) 이다.
😈 MAD-X 특징
- 소수의 추가 매개변수만 활용하는 프레임워크
- 최신 모델을 기반으로 Adapter를 통해 임의의 task와 언어에 대해 적용할 수 있도록 한다.
👷♀️Adapter 간단 사용법
- MLM(Masked language modelling)방법으로 라벨링되지 않은 target 언어 데이터로 language-specific adapter module을 학습
- 어떤 source 언어의 라벨링된 데이터로 task-specific adapter module을 학습
- 추론할때, 사전 훈련되지 않은 희귀언어일 때는 target language adpater로 대체한다.
multilingual 단어장과 target 단어장에 mismatch(불일치, 불균형)이 있기 때문에 Invertible adpater를 추가한다.
-> 이러한 방법으로 pretraining 동안 unseen한 언어에 대해서도 적용이 가능하고 비싸게 language specific token-level embeddings를 학습시킬 필요가 없어졌다.
🤨 왜 language specific token-level embeddings를 학습하는 것이 비용적으로 비쌀까?
그 이유는 우선 임베딩을 많이 많이 구해야 하기 때문이다. 다량의 데이터를 구하는 것은 시간, 가격면에서 비싸다.
또한 언어별로 문법, 특성이 다르기 때문에 언어에 대한 추가적인 연구와 실험이 필요하다. 이러한 이유로 특정 언어에 대한 토큰 수준의 임베딩을 구하거나 임베딩을 구했어도, 학습시키는 것은 비용이 많이 든다.
👩🏻🔬 실험 비교
- WikiANN NER dataset
- XCOPA dataset
- XQuAD QA dataset
🌟 Results
- 위 실험을 모두 경쟁력있고 parameter efficient 하게 해결
- labelled source data으로 사전학습된 모델에도 새로운 언어를 적용할 수 있음
1) 다중 언어의 저주를 완화하는 프레임워크 MAD-X 개발
2) Invertible adapters 제안, cross-lingual MLM을 위한 새로운 어댑터 변수임
3) 다양한 언어와 작업에 대해서 매우 좋은 성능과 강건함을 보임
4) 사전 학습된 언어 모델 -> 타겟 언어로 적용하는 매우 쉽고 효율적인 방법임
5) 사전 학습에 보지 못한 언어에 대해 해결하는 새로운 접근법을 제시함
🤫 Pretrained mutilingual model
Background로 사전 훈련된 다국어 언어 모델에 대해 간단하게 살펴보면,
- 임베딩 레이어
- 트랜스포머 레이어
- 피드 포워드 레이어
- 정규화 레이어
- 출력 레이어
이런 레이어들로 구성되어 있다.
특히 현재 다국어 언어 모델은 트랜프포머 아키텍처를 사용한다.
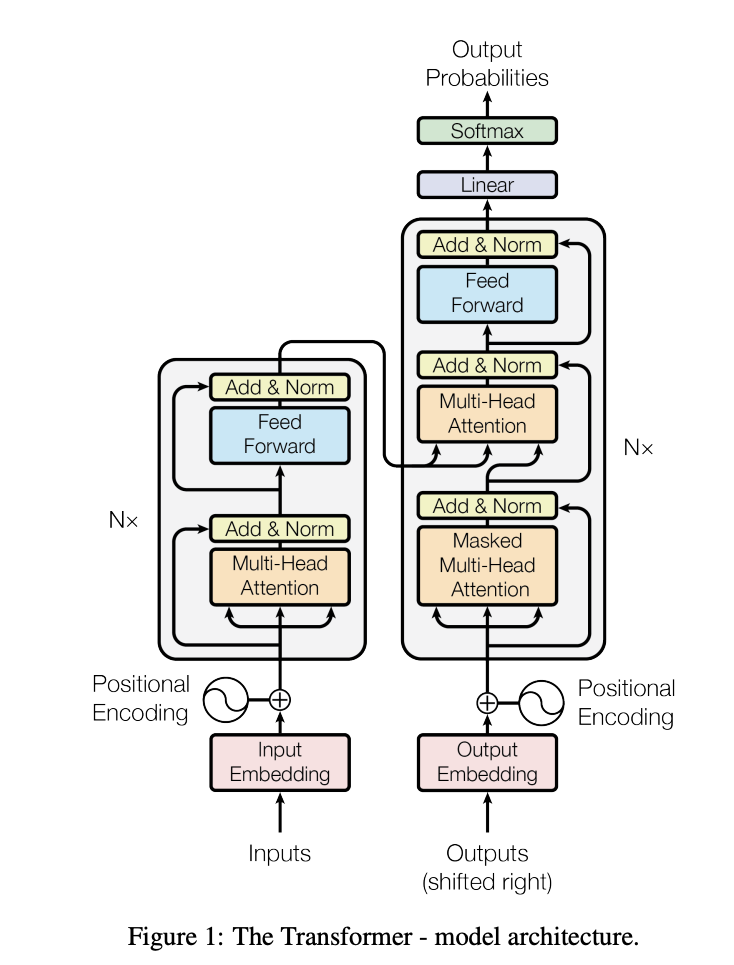
관련 연구에 대해서 알아보자
Related Work
Cross-lingual Representations
한국어로 직역하면, 교차 언어 표현이다.
개 - dog
고양이 - cat
이렇게 다른 표현이지만 같은 의미를 담고있는 것을 기계는 같은 정보로 인식해야한다.
Cross-lingual representations는 다양한 언어들 간의 정보를 연결하고 이해하는데 사용되는 기술과 방법론이다.
- 이전 상황
- BERT, Transformer는 다른언어로 전이학습을 하면 좋은 결과를 보였음.- XLM-R(XLM-RoBERTa)는 Glue benchmark에서 좋은 성능을 보임.
- But, 문제는 XLM-R은 많은 언어 pair에 대해서 아직 성능이 좋지 않았음 -> 모든 언어를 저장할 공간이 부족했기 때문.
Adapters
- 어댑터를 사용해서 리소스가 많은 다국어 NMT model을 fine-tuning할 수 있지만 이 방법은 사전학습때 보지못한 언어에 대해서는 적용할 수 없다는 단점이 있음.
- Artetxe et al(2020)은 어댑터를 사용하지만 학습 중 보지 못한 언어에 어댑터를 적용하기 위해서는 새로운 토큰 수준의 임베딩이 필요했음.
- Pfeiffer(2022a)에서는 단일 언어 모델에서 전이학습을 위해 어댑터를 여러개 사용해서 정보를 결합하기도 함.
Multilingual Model Adaptation for Cross-lingual Transfer
Standard Transfer Setup
이전 전이학습의 셋업에 대해 알아보자.
기존의 방법은
1) BERT, XLM-R 와 같은 최신 모델에 source 언어로된 labelled 된 데이터로 downstream task을 fine-tuning 시키고
2) 바로 target 언어로 추론을 시켰다.
🌧 이 방법의 단점
- 미세조정은 소스 언어의 데이터를 사용하지만 실제 추론은 다른 대상 언어의 데이터에 적용된다.
- 즉 이러한 언어 간 불일치는 모델이 대상 언어에 대해 최적화가 될 수 없는 단점이 있다.
=> Target language에 adapt 하여 해결한다.
Target Language Adaptation
한 언어의 모델을 task domain에 fine-tuning하는 것과 비슷하게
- source language에서 작업별 fine-tuning하기 전, target language의 unlabelled data에 MLM을 통해 pretrained multilingual model을 fine-tuning한다.
- 이 방법은 특정 대상 언어에 편향 시키기 때문에 더이상 여러 대상 언어 모델에 적용할 수 없다는 단점이 있다.
- 하지만 오직 특정 대상 언어에 대한 성능만 고려한다면 성능은 좋다.
- Standard setting보다 더 cross-lingual transfer 성능이 좋았다.
- Catastrophic forgetting 현상도 일어나지 않았다.
🌧 기존 모델의 단점
- 모델의 제한된 용량은 low-resource와 unseen language에 대한 효과적인 적용을 방해한다.
- 전체 모델을 fine-tuning하는 것은 많은 다양한 task와 language에 적용되기 어렵다.
Adapters for Cross-lingual Transfer
MAD-X는 위에서 말한 단점들을 모두 해결한다.
3가지 종류의 Adapter가 있다.
1) Language
2) Task
3) Invertible
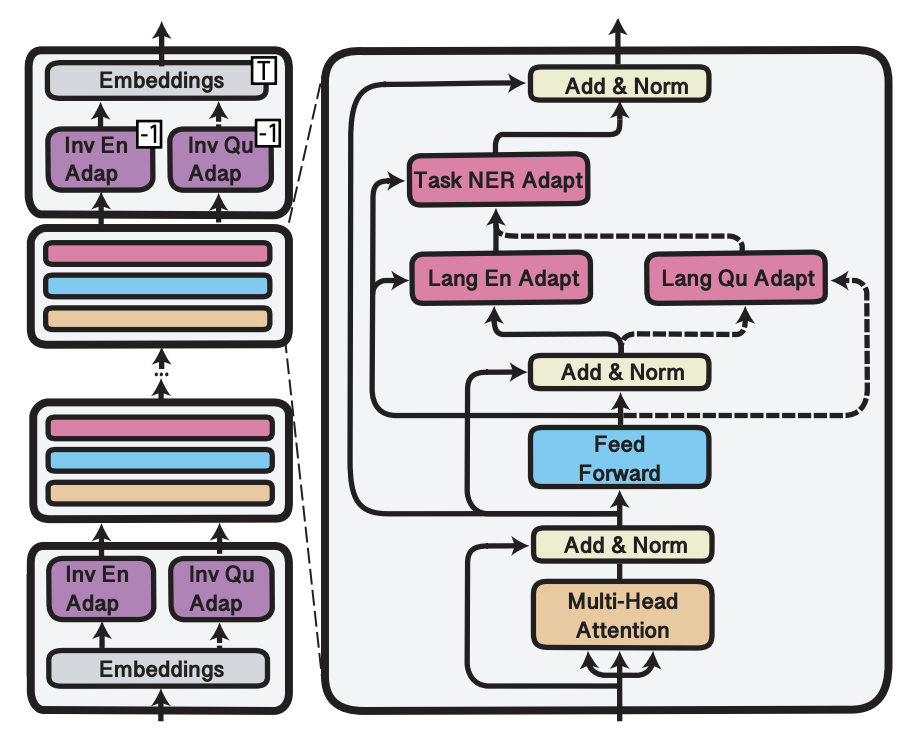
이 그림은 MAD-X의 프레임워크를 그린 것이다.
어댑터 대해 하나씩 알아보자.
Language Adapter
어댑터의 내부 구조는 Houlsby가 내부 구조를 디자인 한 것을 따른다.
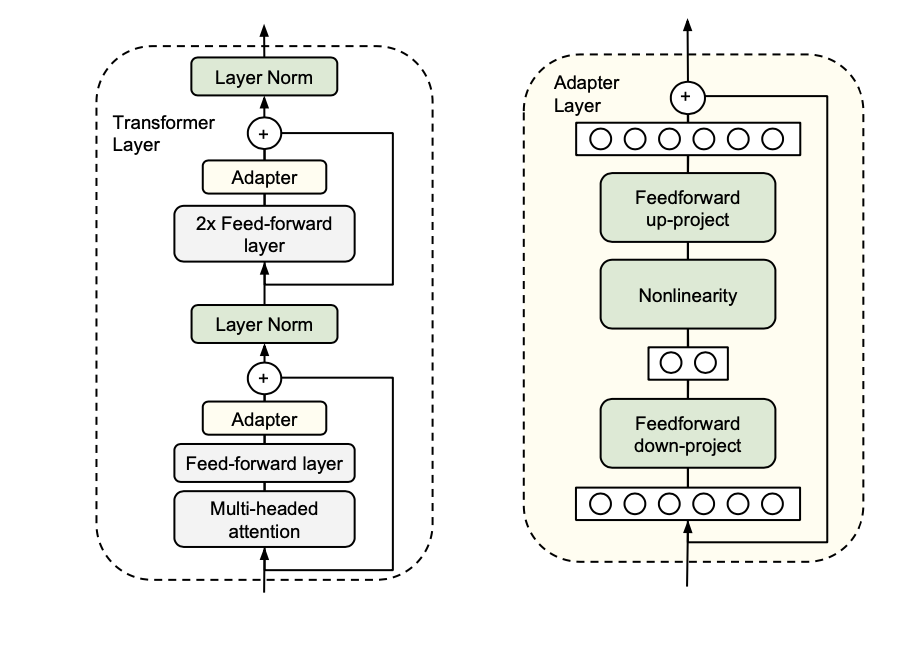
(Houlsby et al. 2019)
오른쪽 그림이 어댑터의 내부 구조이다.
어댑터는 projection down -> 비선형 함수 -> projection up 구조이다.
Language Adapter 를 줄여 LA라고 하자.
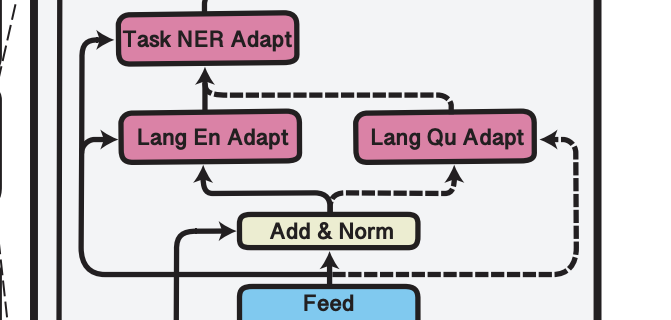
layer 에서 의 LA를이라 하자.
👨🏼💻 과정
-
우선 Projection Down에서는 Transformer output의 hidden size을 입력으로 들어온다. 여기서 입력 차원을 h라고 하면 어댑터의 size를 d라고 할때, 필요한 매개변수는 hxd + d이다. 이러한 Projection Down 과정을 D라고 하자.
-
ReLU 활성화 함수를 취한다.
-
다시 차원을 원래대로 h로 되돌려야 한다. Projection UP과정을 U라고 하자.
-
residual connection을 이라 하자. 이 잔여 연결을 더한다.
함수로 나타내면, - (1) 이 된다.
그림에서 보면 Feed forward의 결과는 이고 layer norm의 output은 을 말한다.
📝 LA 사용법
- MLM을 사용해서 unlabelled data로 LA를 학습 시킨다.
-> 사전 훈련된 다국어 언어 모델이 더욱 특정 언어에 대해 잘 맞도록 한다. - Labelled data로 Task-specific 학습중일 때, source언어에 일치하는 LA를 사용한다(대신 LA의 파라미터는 fix).
- Zero-shot을 해야할 때는 target 언어 LA로 대체한다. (점선)
예를 들어 저 위 그림 (Figure1)에서,
Inference time일 때, 영어로 훈련된 LA를 Quechua 언어 LA로 대체한다.
LA는 downstream work에 대해서는 fine-tuning을 하지 않아서 Task Adapter를 추가한다.
Task Adapter
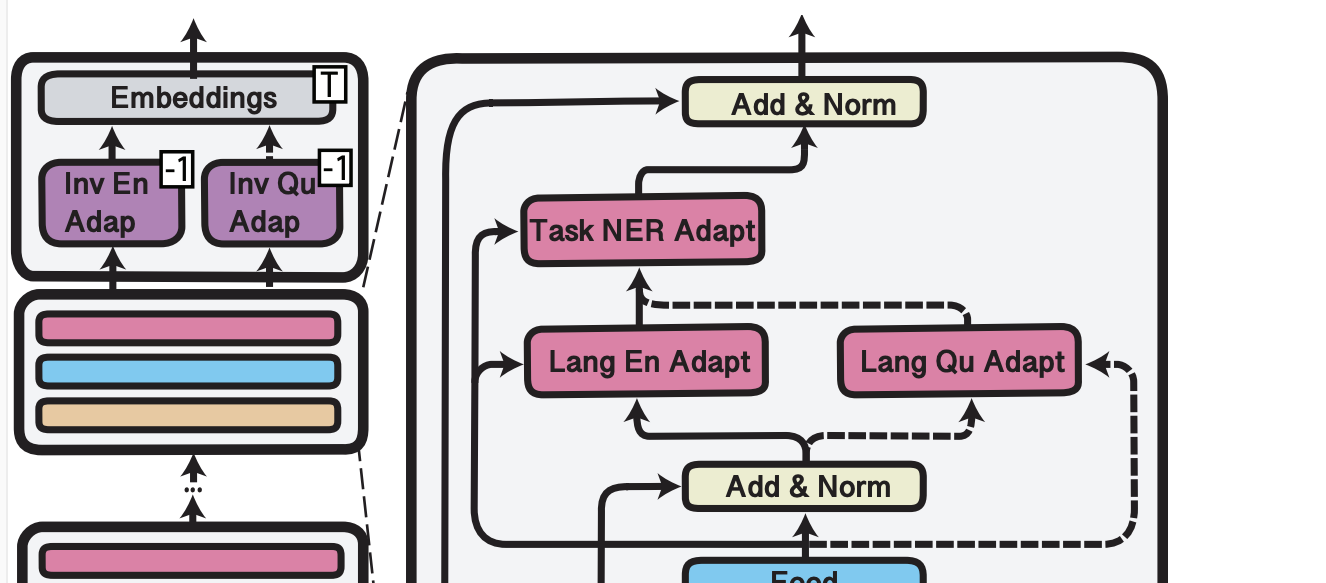
Task Adapter(TA)의 내부 구조는 LA와 동일하다.
👨🏼💻 과정
---> (2)
다른 점은 이제 Projection Down의 입력이 LA의 결과값인 것이다.
의 결과는 layer nomalisation으로 넘어간다.
📝 TA 사용법
- TA의 파라미터들은 오직 downstream task(eg NER)을 수행할 때만 업데이트 된다.
- task-specific 하지만 언어 전반에 걸쳐 일반화되는 지식을 포착하는 것을 목표로 한다.
Invertible Adpater
다국어 어휘 단어장과 타켓 언어 단어장의 불균형을 완화하기 위해서 Invertible Adpater를 추가했다.
Invertibility(역전성)은 동일한 파라미터 세트를 사용하여 input, output 두 표현에 대해 적응할 수 있게 해서 파라미터의 효율적인 사용을 가능하게 한다.
과적합 방지: 출력 임베딩이 미세 조정할 때 종종 제거되기 때문에 이 과정에서 과적합이 발생할 수 있는데 이를 Invertible Adapter가 방지할 수 있다.
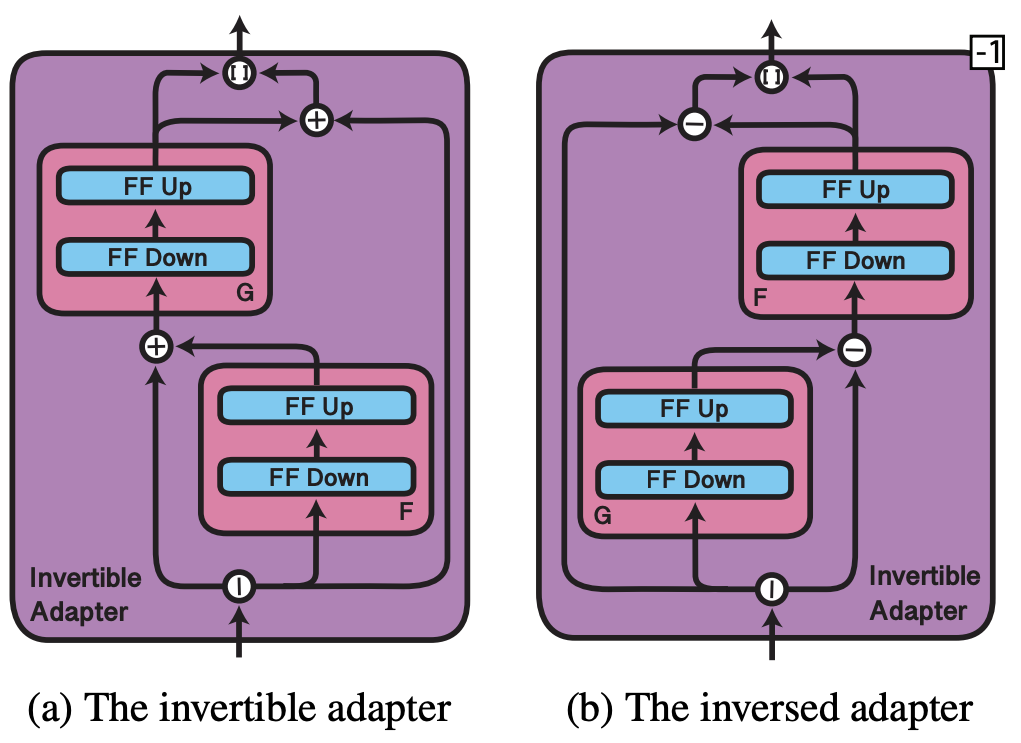
Invertible Adapter의 구조를 살펴보자.
👨🏼💻 구조
- 일단 i번째 토큰의 input 임베딩 벡터 를 두개의 벡터로 나눈다. e1, e2
- 두개의 비선형 함수 F,G가 있다.
- ,
그럼 반대 Invertible Adater의 구조는
👨🏼💻 구조
이다
여기서 F,G는 이전 adapter와 비슷한 역할을 한다.
인 것을 보아 일단 기존 hidden state를 두개의 벡터로 나눈 것이 h/2이고, Projection을 1/2로 하는 것 같다. -> 🤯 정확하지 않음!!!
📝 IA 사용법
- LA와 비슷하다. 다른점은 IA token-level 수준의 언어 특화 변환에 집중된다는 점.
- 특정 언어의 Unlabelled data로 MLM 방법을 통해 LA와 함께 훈련된다.
- Task-specific training을 할 때는 고정된 source language의 IA사용
- Zero shot transfer할 때는 target language IA로 변환한다.
=> 매우 parameter efficient 한 방법!!!
Experiments
3가지 실험을 함
🧶 DATASET
- NER : Named entity regonition, WikiANN dataset
- QA : question answering, XQuAD dataset
- CCR : causal commonsense reasoning, XCOPA dataset
👥 Language
- 176개의 언어
- 언어 선택 기준
- variance in data availability
- their presence in pretrained multilingual models (보다 정확하게는, 다국어 BERT, XLM-R의 사전훈련에 해당 언어가 포함되어있는지의 여부)
- typological diversity(다양한 언어가 포함되도록)
- 언어 집합 4가지로 나눌 수 있었음.
- High resource language
- 사전 훈련된 SOTA 모델이 다루는 low resource language
- low resource language
- 다언어 모델로 커버되지 않는 완전 low resource language
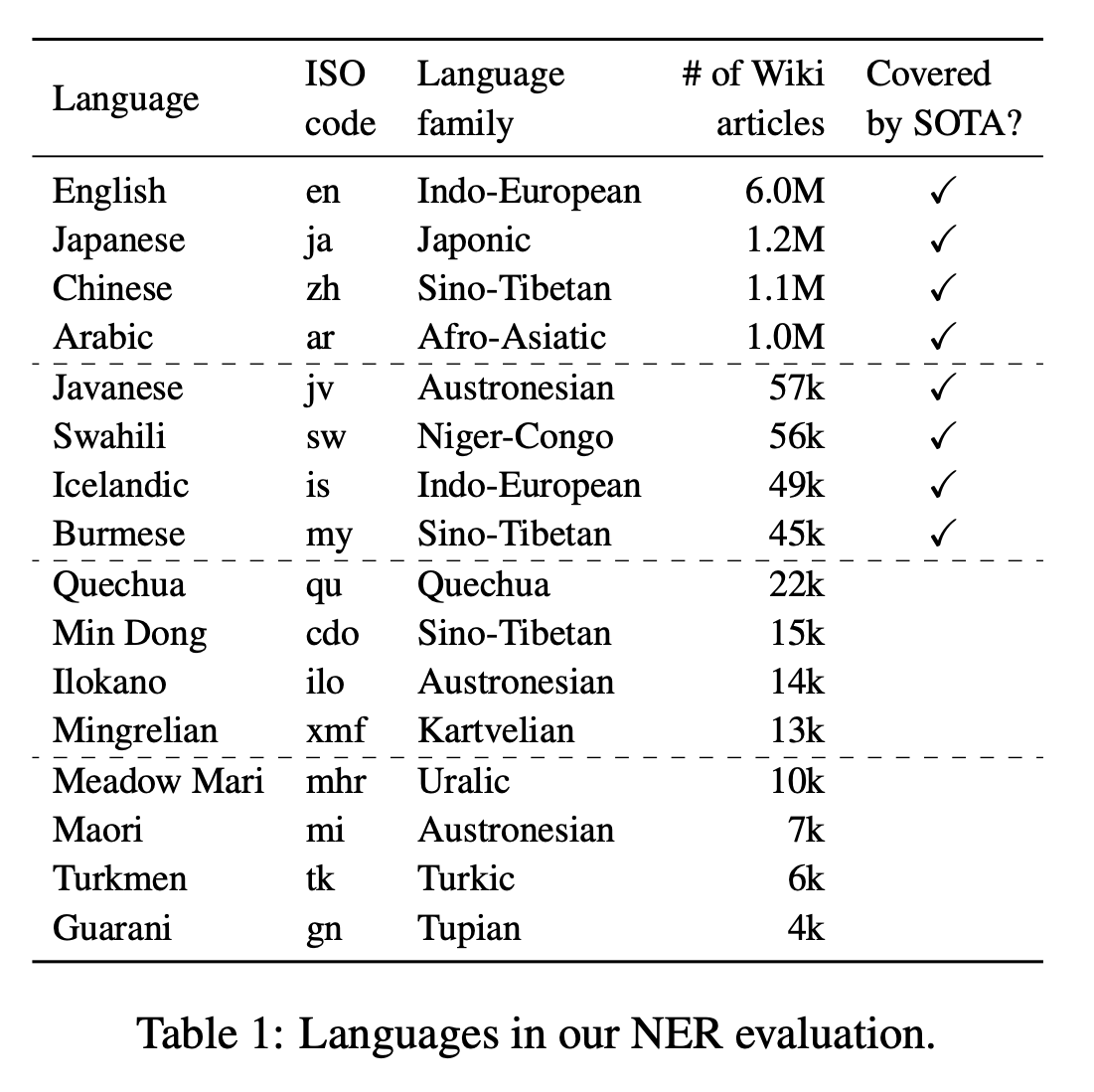
16개의 언어를 11개의 language family로 나누어서 Table 1에 정리했다.
각 언어를 source 언어로, 다른 언어들을 target으로 설정해서 모든 언어 쌍을 평가했다.
CCR : XCOPA에서 12개의 언어 제공해서 평가 -> 유형적으로 다양한언어 포함(Haitian Creole, Quechua를 포함)
QA : XQuAD에서 11개의 언어 제공해서 평가 -> 주로 자료가 많은 언어를 위주로, 유형적으로 덜 다양함
둘 다 영어를 소스언어로 함
Baselines
일단 실험의 기초로 XLM-R을 선택했다.
하지만 BERT와 같은 다른 사전학습된 모델을 선택해도 된다.
일단, 전체가 source 언어로 된 라벨링된 데이터로 미세조정된 XLM-R 모델과 비교했다.
XLM-R 모델은 트랜스포머 베이스 모델로, 100개의 언어가 large cleaned Common Crawl corpora에서 학습되었다고 한다.
또한 사전학습을 따로 한 모델로도 비교한다.
XLM-RBase MLM-SRC: Source 언어로 MLM 방식의 XLM-R을 Fine-tuning
XLM-RBase MLM-TRG: Target 언어로 MLM 방식의 XLM-R을 Fine-tuning
MAD-X : Experimental Setup
실험을 하기전 어떻게 실험을 세팅했는지, 보자
첫번째로, XLM-R과 MAD-X를 비교하는데, MAD-X에서 LA, IA를 제거한 것도 같이 비교한다.
- Transformers library 사용
- MLM 방법의 Finetuning을 하기 위해서 Wikipedia data
- 250,000 steps
- batch size 64
- learning rate 5e-5(XLM-R) 1e-4(adapters)
NER
-
100 epochs
-
batch size 16(high-resource), 8(low-resource)
-
learning rate 5e-e(XLM-R), 1e-4(adapters)
-
검증을 통해 가장 좋은 모델 선택
-
LA :384, IA: 192, task:48 차원으로 설정
XLM-R BASE는 hidden layer가 768이다.
Adapter의 크기는 2,2,16으로 줄임.
NER
- WikiAnn training set of source language
- 5번
- XLM-R bse MLM-TRG는 1번만 돌림(효율을 위해서)
QA
- 3번
- English SQuAD training set
- SQuAD에서 훈련, XQuAD target language에서 평가
CCR
- 3번, 각각 English training set
- XCOPA target language에서 평가
좀더 쉽게 실험을 이해하기 위해 그림을 그렸다.
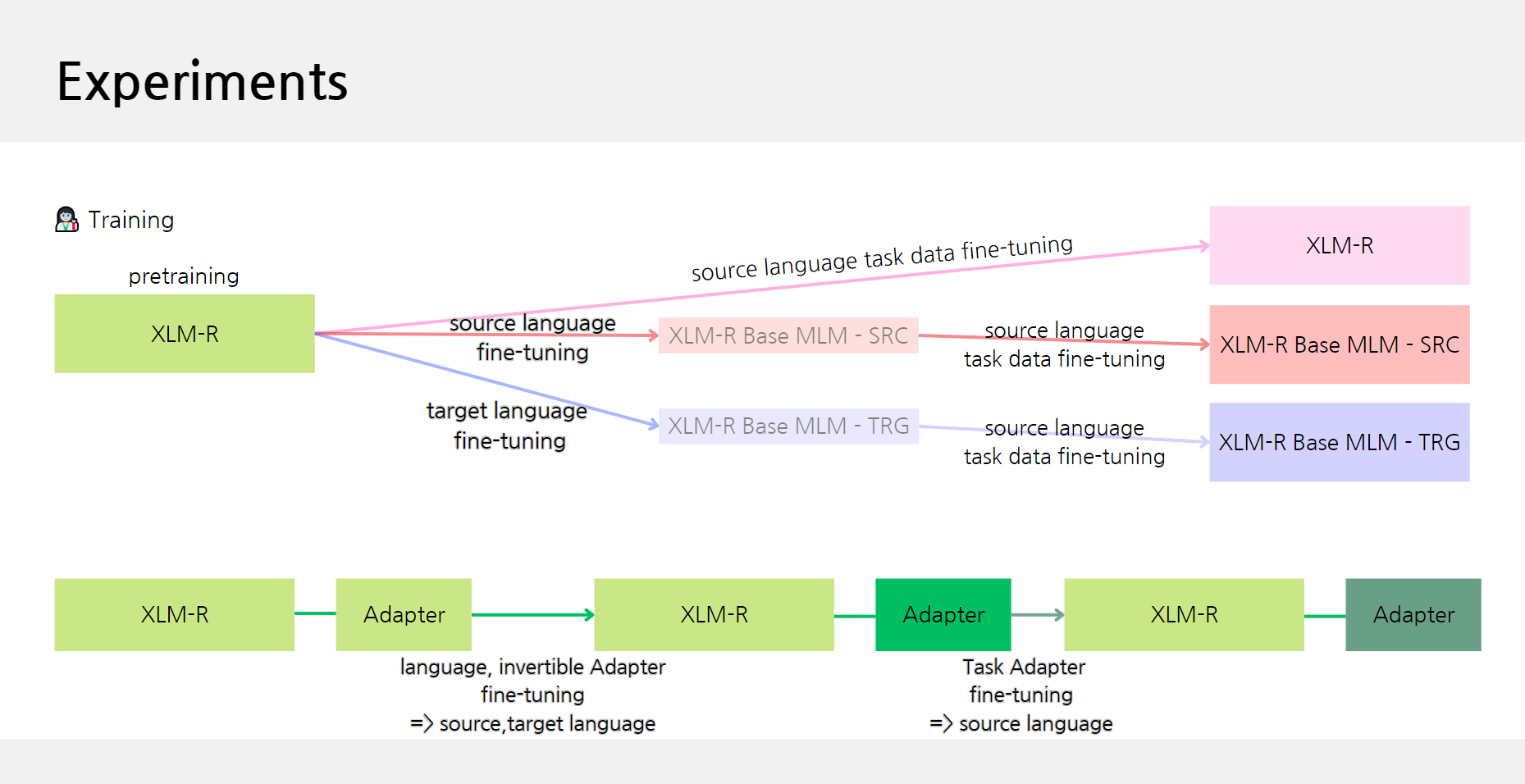
이 그림은 학습할 때 그림이다.
먼저 언어에 대해서 공부한 뒤, Task에 대해 공부한다.
총 4개의 모델이 생성되었다.
그 다음 Test를 진행한다.
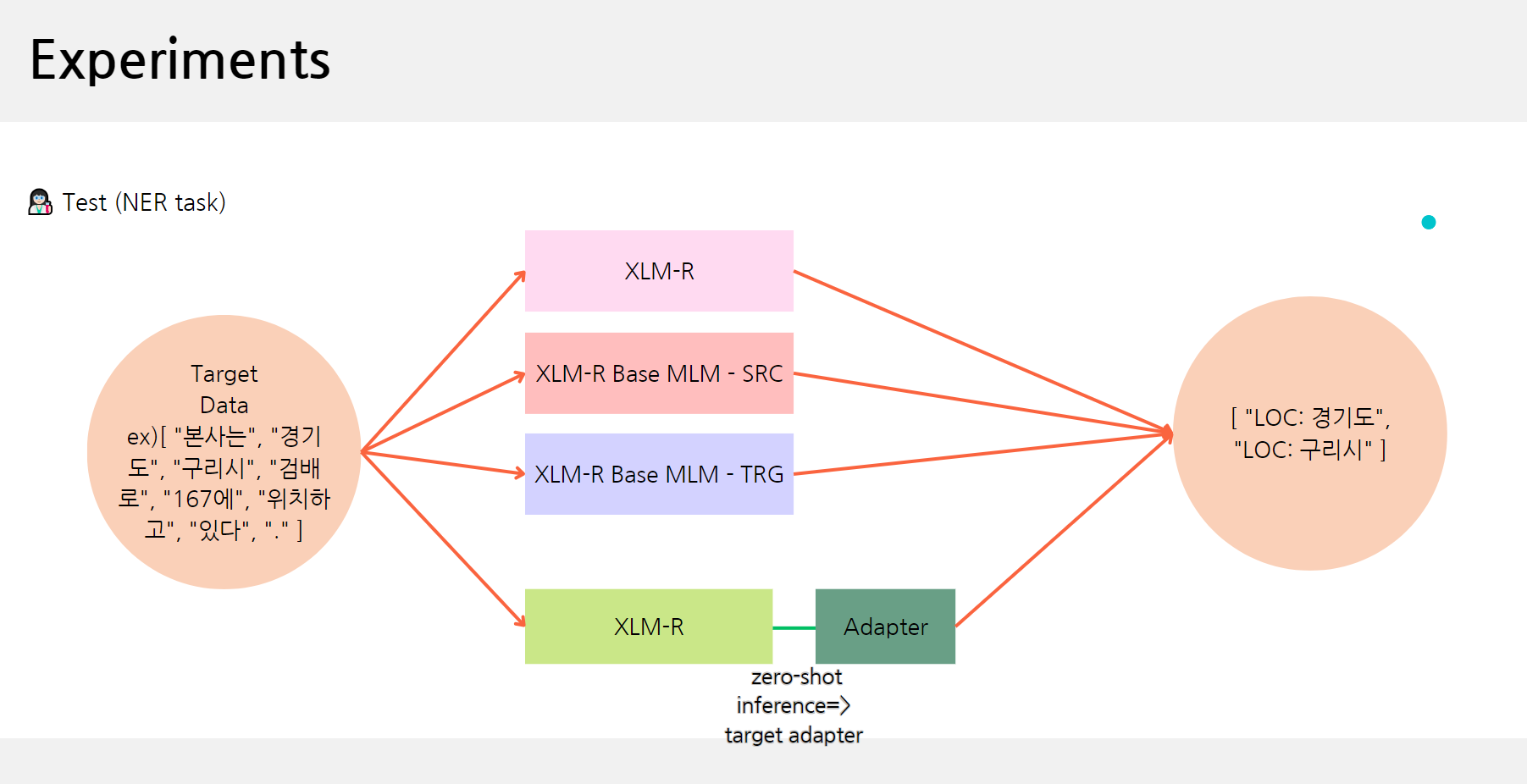
만약 Target 언어가 한국어라면 WikiANN의 데이터도 한국어이다.
MAD-X의 경우 한국어 Adapter를 사용해서 추론을 진행한다.
Results and Discussion
Named Entity Recognition
16개의 target언어에 대한 평균을 낸 점수이다.
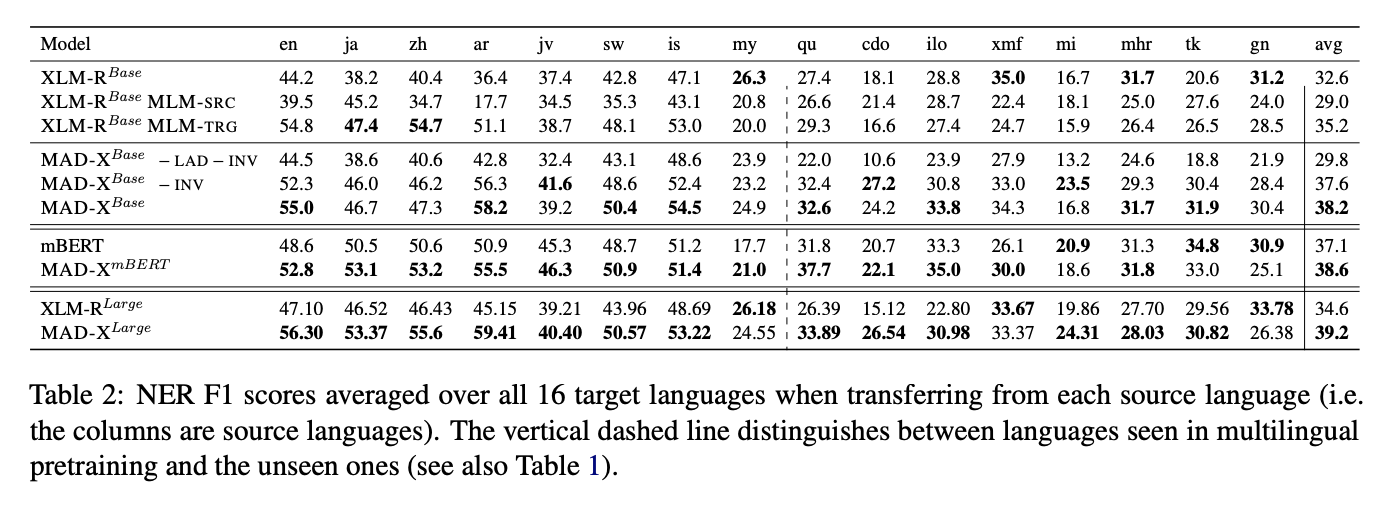
각각의 열들은 Source language를 의미한다.
점선의 왼쪽은 seen language, 오른쪽은 unseen language를 의미한다.
-
XLM-R
- 오른쪽을 보면 XLM-R의 점수가 unseen language인 곳에서 점수가 그렇게 좋지 않았다.
- 성능: XLM-R Base MLM-SRC < XLM-R Base 이었고,
XLM-R Base MLM-TRG < XLM-R Base 였다. -> 하지만 low-resource에서는 그닥. - Target 언어에 하나씩 finetuning을 해야하기 때문에 비용적으로 매우 비싸다.
-
MAD-X
- LA를 추가하면 unseen language에서 성능이 좋아짐.
- seen language에서도 좀 좋아짐
- IA를 추가하면 더 성능이 좋아짐
- FULL MAD-X > MAD-X-INV
- XLM-R 보다 점수 낮은게 5개 밖에 없음
-
Model - agnostic
- mBERT에서도 실행
- 거의 대부분 기본 사전학습 모델보다 성능이 좋았음

왼쪽이 Source language, 오른쪽이 Target language

- 성능의 차이를 가장 많이 보인 것은 오른쪽 위 4분면이다. ( high -> low transfer)
- Arabic(source)을 전이 학습할 때 가장 좋은 결과. -> XLM-R 단어장에 없기 때문에
MAD-X는 다국어모델과 단일 언어 모델의 약저을 연결하는데 도움을 준다!
Causal Commonsense Reasoning
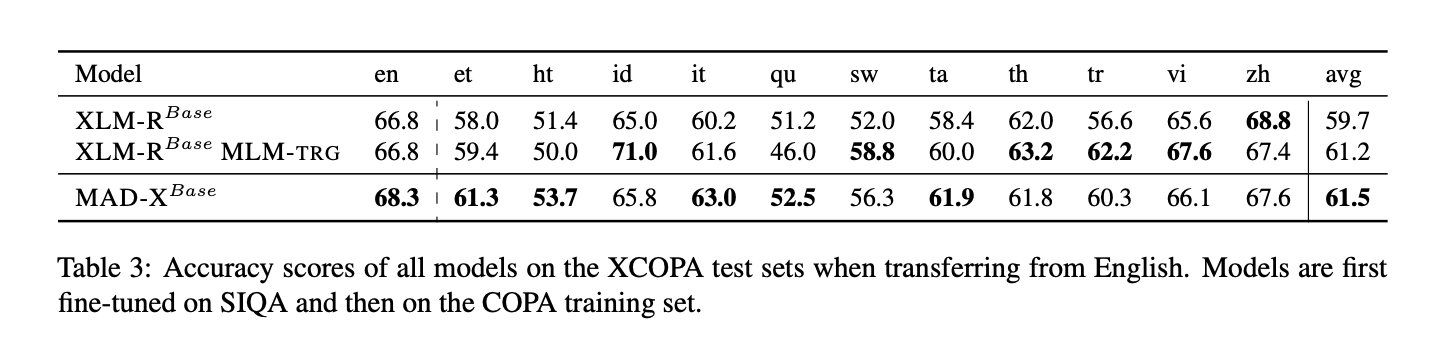
English에서 each target language로 전이학습을 한 것을 보여준다.
가장 좋은 모델을 선택해서 했다.
- 맨 처음 fine tuning은 SIQA, 그리고 그 다음 영어 COPA에서 진행했다.
결과적으로 XLM-R < MAD-X 였다. (5<6)
두가지 unseen language인 ht, qu언어에서 특히 두드러짐. 다른 언어는 비슷하거나 조금 나은 결과를 보였다.
Question Answering
English -> Each Target language (XQuAD)

MAD-X는 XLM-R과 비슷한 성능!
XQuAD의 언어들은 모두 high-resource language로 보였다.
각각 Wikipedia 기사들이 100,000개 이다.
이러한 결과는 MAD-X는 자원이 적거나 없는 언어에서는 뛰어난 성능을 보여주고 high-resource에서는 기존 모델과 비슷하거나 살짝 낮은 성능이지만 충분히 경쟁력이 있는 결과를 보였다.
Futher Analysis
Impact of Invertible Adapters
IA의 역할을 분석하기 위해서 더 자세히 실험을 해보았다.
부록에 있는 Figure 16을 보자.

초록색이 보이면 MAD-X가 ?MAD-X-INV 보다 더 좋은 성능을 보인 것이다.
IA는 대부분의 초록색 칸을 보였지만 mi언어에서만 지속적으로 낮은 성능을 보였는데 이는 데이터의 변동성 때문이라 한다.
Sample Efficiency
MAD-X의 주요 기능은 바로 IA와 LA이다.
이러한 어댑터는 다양한 작업에서 재사용이 가능하다.

Figure 4는 다양한 숫자의 iterations를 통한 영어에서 다른 대상언어로 IA와 LA로 전이학습을 통해 NER 성능을 보여준다.
5번의 다른 수행을 음영으로 색칠하여 보여주었다.
low-resource 언어에서 이미 20k 일때 좋은 성능을 보여주고 있다.
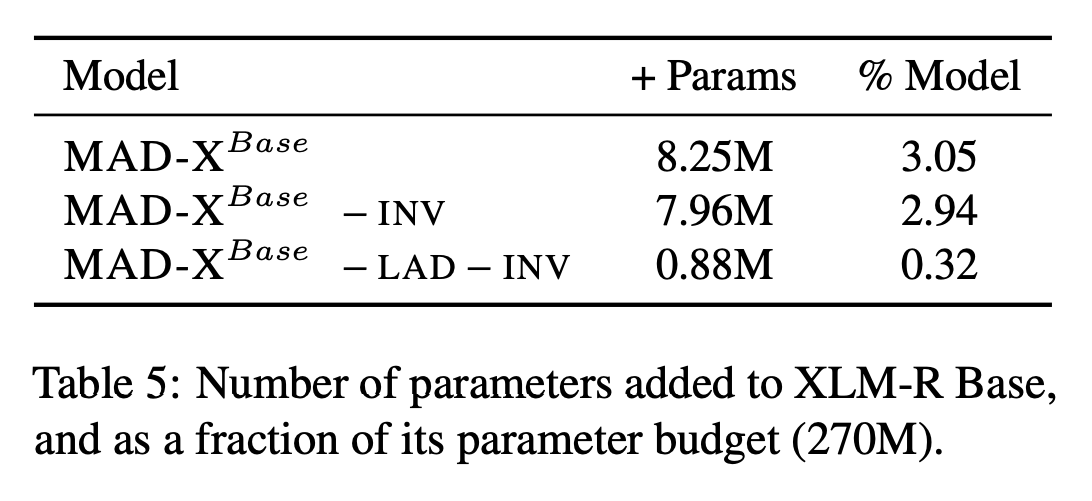
Table 5에서는 XLM-R 모델에 추가된 매개변수의 수를 보여준다.
오직 3.05%만 사용된 것을 알 수 있어서 모델이 매우 parameter - efficient함을 보여준다.
