
모델링이 끝난 이후, csv 작업과, 본격적인 View작업이 시작 되니.... 먼가 바쁘고 시간이 정신없이 지나간것 같다. 머 하나 한것 같은 데 일요일이 끝이 났다. 내일 이면 중간 발표인데
금요일
금요일의 목표는 csv파일의 완성과, db_unloader를 완성 시키는 것이었다.
csv파일
프로젝트를 위한 데이터 빽업 파일이라고 생각하면 된다. Wadiz를 클론 코딩을 하다보니 많은 데이터가 필요했다. Aquery를 만든대로 테이블을 짜고, 데이터를 넣어야 한다. 다른 데이터를 제외하고 상품 테이블에 데이터를 넣는다고 할때 상품명, 이미지, 설명, 시작되는 날짜 등이 필요하고, 각 카테고리별로 10개씩 데이터가 들어간다고 할때 160개가 필요하다. 여기에 MTM 이면 중간테이블의 데이터도 필요하게 되는데, 만약 이 데이터를 따로 저장해 두지 않고 데이터베이스를 만들어야 할 상황이 오게 된다면........ 생각만 해도 끔찍하다. 이러한 이유로 따로 csv 파일을 만들어 두어야 한다.
db_uploader
csv 파일을 데이터베이스에 업로드 하기 위해 짠 로직을 저장해 둔 데이터이다.
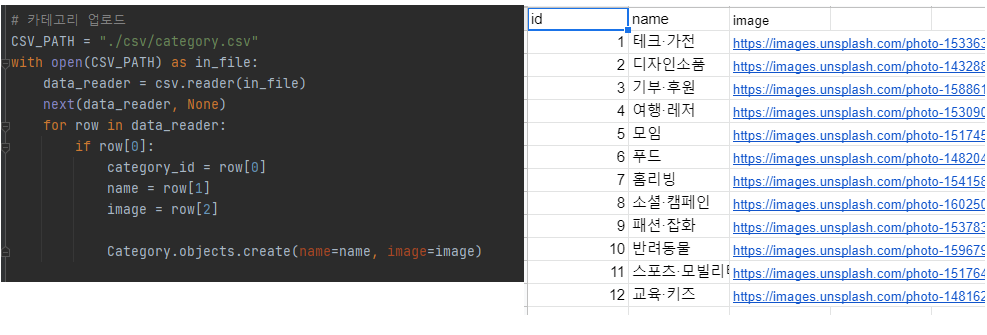
-
만들어둔 CSV 파일을 보면 id = row[0], name = row[1], image = [2] 이다.
-
CSV_PATH : 저장해둔 csv파일의 경로를 CSV_PATH에 저장해 둔다.
-
with open(CSV_PATH) as file : CSV_PATH를 가져와서 open하고 in_file 이라고 as 정의한다.!!(as 'name' 이라고 하면 정의한 함수의 이름은 name이 된다.)
-
data_reader = csv.reader(in_file) : csv.reader(in_file) 은 지정된 csvfile의 줄을 반복하는 itrater([이터레이터])하는 판독기(reader) 객체를 반환합니다. 즉 reader 속성이 CSV 파일에 있는 각 행을 읽어주는 역할을 한다.
-
next(data_reader, None) : CSV 파일의 첫 행을 무시하는 것을 의미한다.
-
for row in data_reader ~ : dat_reader의 각 row에 대해서 반복문을 통해 create 해준다. 그리고 Category_id = row[0], name = row[1], image = row[2]를 보듯이 각 row를 객체에 넣어준 후, 대응해주고, Category.objects.create(name=name, image=image) 해주면 끝!!
물론 ForeignKey로 연결이 되있거나, ManyToManyField로 연결이 되어 있으면 로직이 더욱 복잡해 진다.
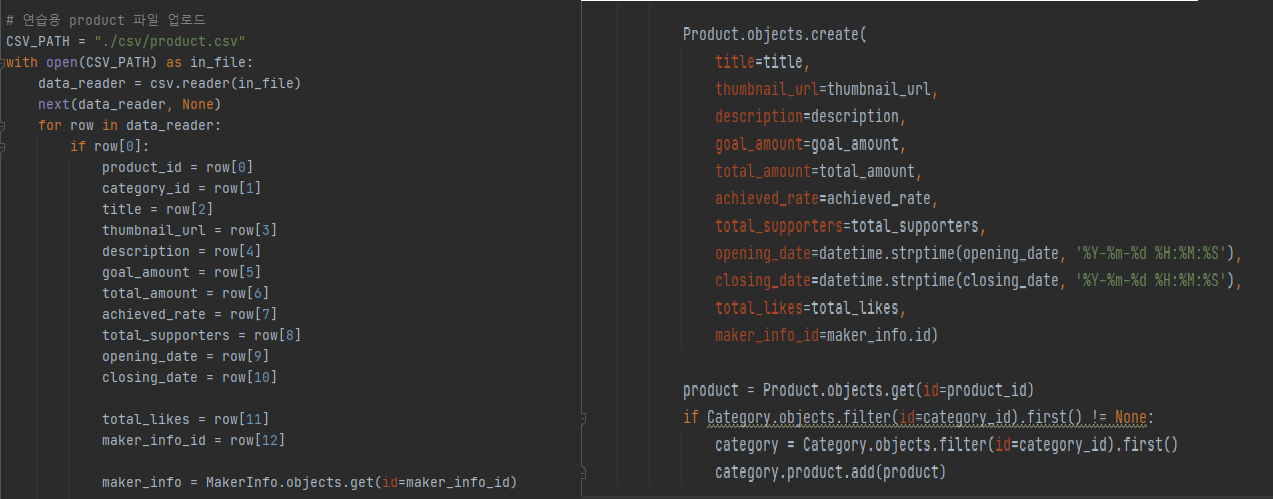
다른 내용은 다 똑같다. 우선! Maker_info를 보게 되면 'maker_info = row[12]' 여기까지는 똑같다.
그 다음줄을 보면
maker_info = MakerInfo.objects.get(id=maker_info_id) 가 있다. 이 말인 즉슨 maker_info 라는 객체에 인스턴스화 되어 있는 row[12]의 데이터를 Makerinfo 테이블에 참조된 데이터 가져온다. 참조가 성공적으로 이루어 졌다.
추가 자동으로 중간테이블에 데이터 추가 하기
반복작업을 다 한 후 마지막으로 호진님이 기가막힌 로직을 추가 해 주었다.
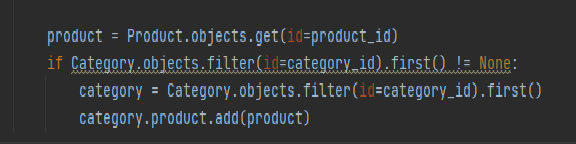
add는 주로 ManyToMany 관계에서 중간테이블에 데이터를 넣을 때 주로 사용한다.
- Product와 Category의 중간테이블에 데이터를 추가할때 사용해 줄 예정이다.
- 우선 저장할 Product의 데이터를 get로 가져와 product에 저장해준다.
- add를 이용해서 추가!!, 기억해야 할 점은 add의 괄호안에 들어가야 할 값은 '객체' 여야 한다는 점이다.
이후 python3 db_uploader로 돌려주면........ 감동 그 자체,,,, 쪽잠 자면서 만든 보람이 있었다!!!!!
금요일 하늘 사진 - 진짜 맑다...

토 ~ 일
고등학교 시절이 생각나는 주말 이었다. 처음에는 에어비앤비를 빌려서 늦게 까지 하고 싶었지만, 시국이 시국이고 인원도 7명이나 되다 보니 너무 많았다. 2주 격리때문에 에어 비앤비를 쓰는 사람들이 많아져 단 2일 사용하는데 53만원? 정도 나왔던 것 같다. 그럴 바엔 차라리 온라인으로 하는게 나을 것 같아서, 공유 오피스를 빌려서 단 시간에 집중해서 하기로 했다. 하지만 날씨가 너무 포근하고 좋아 딴 길로 샐뻔도 했지만 정대만을 보고 마음을 다잡았다.
주말의 내용을 이야기 하자면 오스트랄로피테쿠스에서 Request.GET이 점점 진화하는 모습을 보여준다.
Project-4의 내용과 이어진다. 데이터베이스에 저장이 되어있는 데이터가 없어서 로직이 제대로 돌아가는지 확인을 하지 못했다. 역시 무한오류의 늪.........
GET - 유아기

프론트 분들에게 멘붕을 안겨준 데이터이다. 200은 떠서 각 category 별로 데이터가 넘어가기는 갔는데,,,, 전혀 알 수없게 데이더 덩어리를 던져준 듯 했다.(죄송합니다.)
어떻게든 데이터만 GET해서 Respone 해주기만 하면 된다는 생각에 그랬던 것 같다.
(이 블로그를 보시는 백엔드 분들 저렇게 주시면 프론트 분들 멘붕 옵니다. 저렇게 데이터가 들어가게 된다면 당장 연결을 끊고 로직을 수정하세요)
GET - 성장기
덩어리로 던져준 데이터들이 점점 분열해 나가기 시작했다. 하지만 아직은 부족하다 원하는 방식으로 데이터를 보내야 하는데 Category별로 Product에 대한 내용도 있어야 한다.
Product와 Category의 연결에 있어서, ManyToManyField속성을 Category에 넣어주었다. 그렇다보니 Category에서 product의 데이터를 가져와야 한다는 생각을 가지고 있었던 것 같다. 정참조 역참조 다 가능한데....... 이 때쯤 부터였을 것 같다 Prodcut테이블을 중심으로 데이터를 보내 주려고 로직을 짜나 갔다.
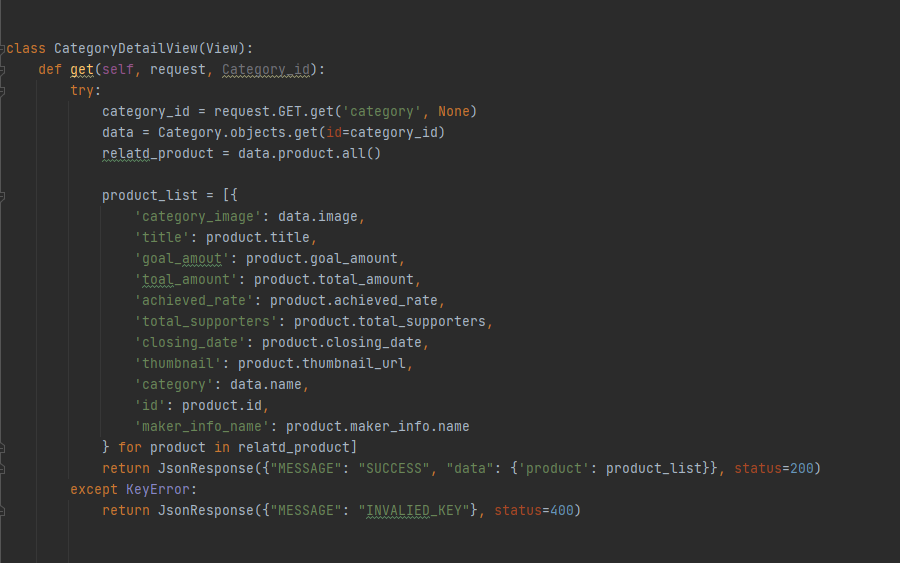
GET - 성숙기

깨달음을 얻은 뒤로 프론트와 데이터를 넘기는데 있어서 성공한 사례이다. 성공하고나서 보니 여태까지 했던 접근 방식은 완전히 잘못됬다는 것을 알았다.
GET을 단순하게 데이터베이스에 있는 내용을 가져와서 POST보다 비중을 두지 않고 django 공부를 했던 것을 후회를 무척이나 많이 했다.
데이터를 보내기 위해, 프론트와 많은 이야기를 나눴는데 이 점이 가장 중요했다. 어떤 식으로든 데이터를 보낼수는 있다. 하지만 통신이라는 것은 FE와 BF의 연결이 중요한데 위의 데이터 처럼 나몰라라 라는 식의 데이터는 좋지않다. 어떤 데이터를 필요하고, 어떤 형태로 보낼지 다 서로 맞춰나가야지만 성공할 수 있기 때문이다.
GET - 완전체
이제 전체보기가 완료되었으니, 각 카테고리별로 data를 불러올 수 있어야 한다. 어렵지는 않았다. urls.py에 Url에 '<int: Category_id>' 를 추가 해 url에 숫자를 써주면 완성이 된다.!!
현재까지의 코드

하늘 너무 이뻤는데 사진을 찍지 못했다.

화이팅!!
