서론
ChatGPT가 세계의 뜨거운 관심을 갖게 된 가운데, 생소한 여러 용어들이 튀어나와 각종 언론이나 블로그를 장식하고 있다. 그런데 GPT-3, GPT-3.5, ChatGPT의 차이는 무엇일까? 궁금한 참에 제대로 정리해보고자 글을 작성하게 되었다.
본론
먼저 Pre-training과 Transfer Learning의 개념에 대해 이해해야 한다.
Pre-training
Pre-training(사전훈련)은 우리가 기존에 알고 있던 모델학습과 같다. 즉, 개와 고양이의 사진들을 보여주면, 개인지 고양이인지 판단하여 결과를 도출할 수 있도록 학습하는 것과 같다. 또한, Pre-training으로 학습이 완료된 모델을 Pre-trained model이라고 한다. 이를 만들기 위해 적지 않은 양의 Raw Data들이 필요하고, 학습을 위해 오랜 시간과 비용이 소모된다. 그 중에서도 특히 데이터를 대량으로 사용하여 학습한 모델을 대형(대규모) 언어 모델(LLM; Large Language Model)이라고 한다.
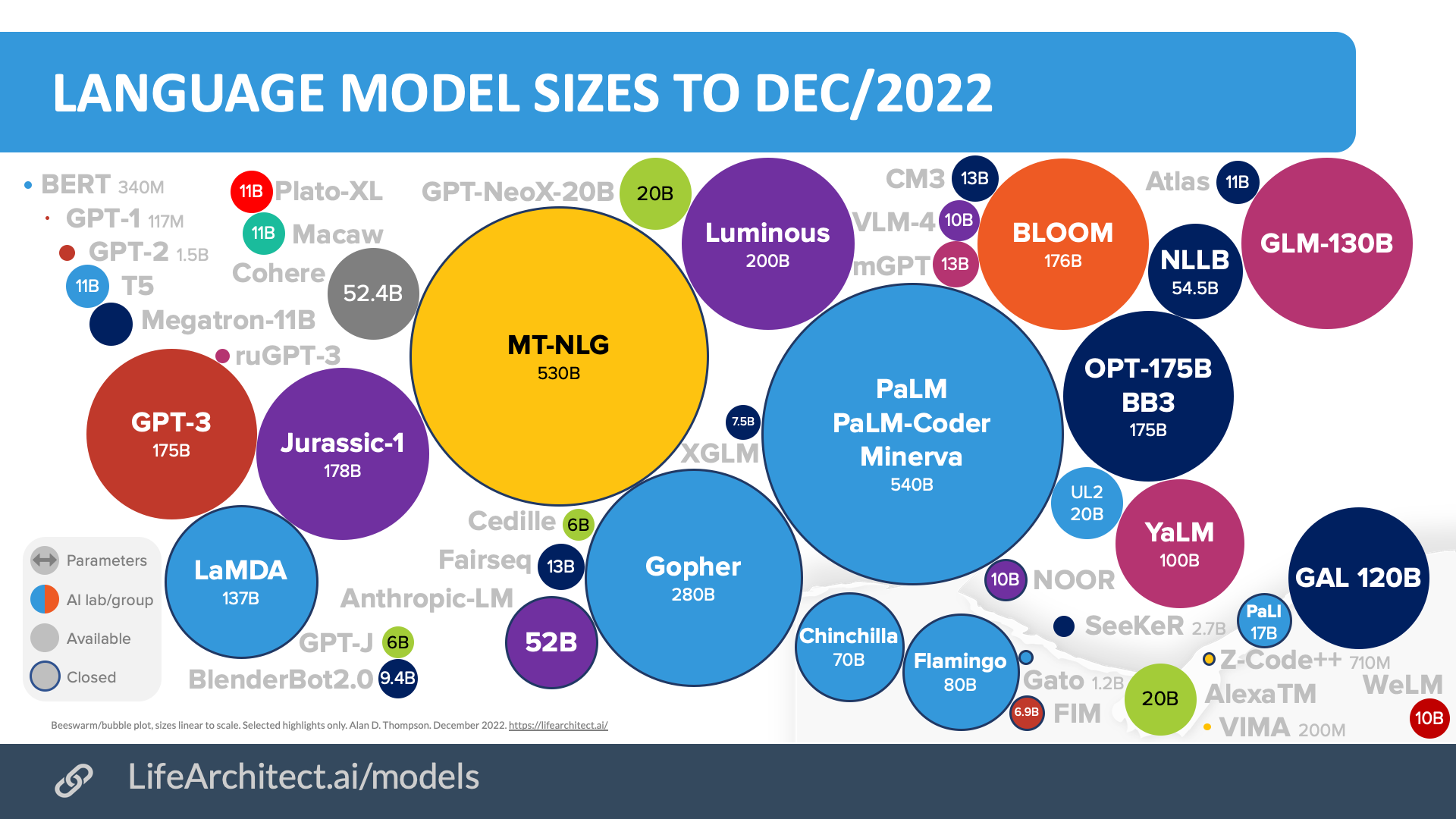
위 그림에서 원의 크기는 ML(머신러닝) parameter 개수를 의미한다. 이중에서 GPT-3 모델은 기존의 BERT나 GPT-2 모델보다 훨씬 많은 1750억개를 가지고 있어 출시 당시만 하더라도 압도적인 크기의 모델이었다.
Transfer Learning
GPT-3 모델은 text 입력에 대해 가장 알맞은 답변을 결과로 도출하는 모델이다. 그러나 ML은 DALL-2처럼 그림도 그릴 수 있고, Whisper처럼 음성을 인식할 수도 있다. 용도에 따라 학습 데이터도 다르고, 얻고 싶은 결과도 다르다. 즉, GPT-3는 텍스트 기반 모델이지, 그림을 그리거나 음성을 인식할 수는 없다.
그런데 text도 다 같은 text가 아니다. 파파고처럼 번역에 특화된 모델도 있을 것이고, Github Copilot처럼 코드 생성에 특화된 모델도 있을 것이며, 챗봇처럼 대화에 최적화된 모델도 있을 것이다. 이들의 목적은 전부 다르지만, 텍스트 형식으로 입력을 받고 출력을 한다.
물론 저 예시들은 서로 다른 모델을 사용하여 학습하였다. 그런데 위에서 언급했다시피 Pre-trained 모델은 학습하는데 드는 비용이 만만치 않다. parameter의 개수가 매년 기하급수적으로 커지고 있는 현재는 그 부담도 더더욱 커졌다. 용도 하나만을 위해서 매번 training에 시간을 들이는 것은 아깝다.
즉, Transfer Learning(전이학습)은 Pre-trained 모델을 사용하여 다시 학습하는 것을 말한다. 기존 모델을 사용하여 목적에 맞게 새로운 모델을 만드는 것인데, 그만큼 효율적이면서 비용 부담도 적다.
위의 예시를 이어가자면, 개와 고양이의 사진만 보여주던 것을 호랑이 사진도 보여주면서 학습하는 것이다. 그러면 Transfer Learning을 사용하여 개, 고양이, 호랑이 사진을 구분할 수 있는 모델을 만들게 되는 것이다.
Fine-Tuning
Transfer Learning은 어쨌든 Pre-trained 모델을 재사용하여 학습하는 것의 통칭이다. Pre라는 단어가 들어가는 이유도 이 때문이다.
Transfer Learning 방식 중 하나로 Fine-Tuning이 있다. 학습 과정의 레이어 중 가장 끝단의 레이어를 변형하여 학습하는 것인데, 기존의 레이어가 새로운 용도에도 유용한 역할을 지닐 때 사용한다.
예를 들어 개, 고양이 사진을 구분하기 위한 레이어가 여러 개 있다고 하자. 먼저 사진의 Pixel들을 그룹화하고 선의 윤곽 등을 인식하고, 이를 통해 어떤 동물인지 유추하는 레이어들이 각기 다르게 존재할 것이다. 이제 다른 동물을 추가하기 위해서는 선의 윤곽을 인식하는 부분은 건드릴 필요 없이 윤곽->동물 유추 과정만 변형하여 학습하면 되는 것이다.
참고한 블로그: [DL] Transfer Learning vs Fine-tuning, 그리고 Pre-training by heeee__ya
GPT-3 모델 시리즈
ChatGPT 공식 설명 문서에서 ChatGPT는 GPT-3.5의 Fine-Tuned 버전이라고 명시되어 있다.

그럼 GPT-3.5는 뭘까? 간단하다. GPT-3의 Fine-Tuned 모델이다. 즉 세 모델 모두 같은 데이터셋을 사용하였다. 이밖에도 GPT-3을 이용하여 다양한 목적에 맞게 Fine-tuned 모델을 생성한 것을 다음 그림을 통해 알 수 있다.
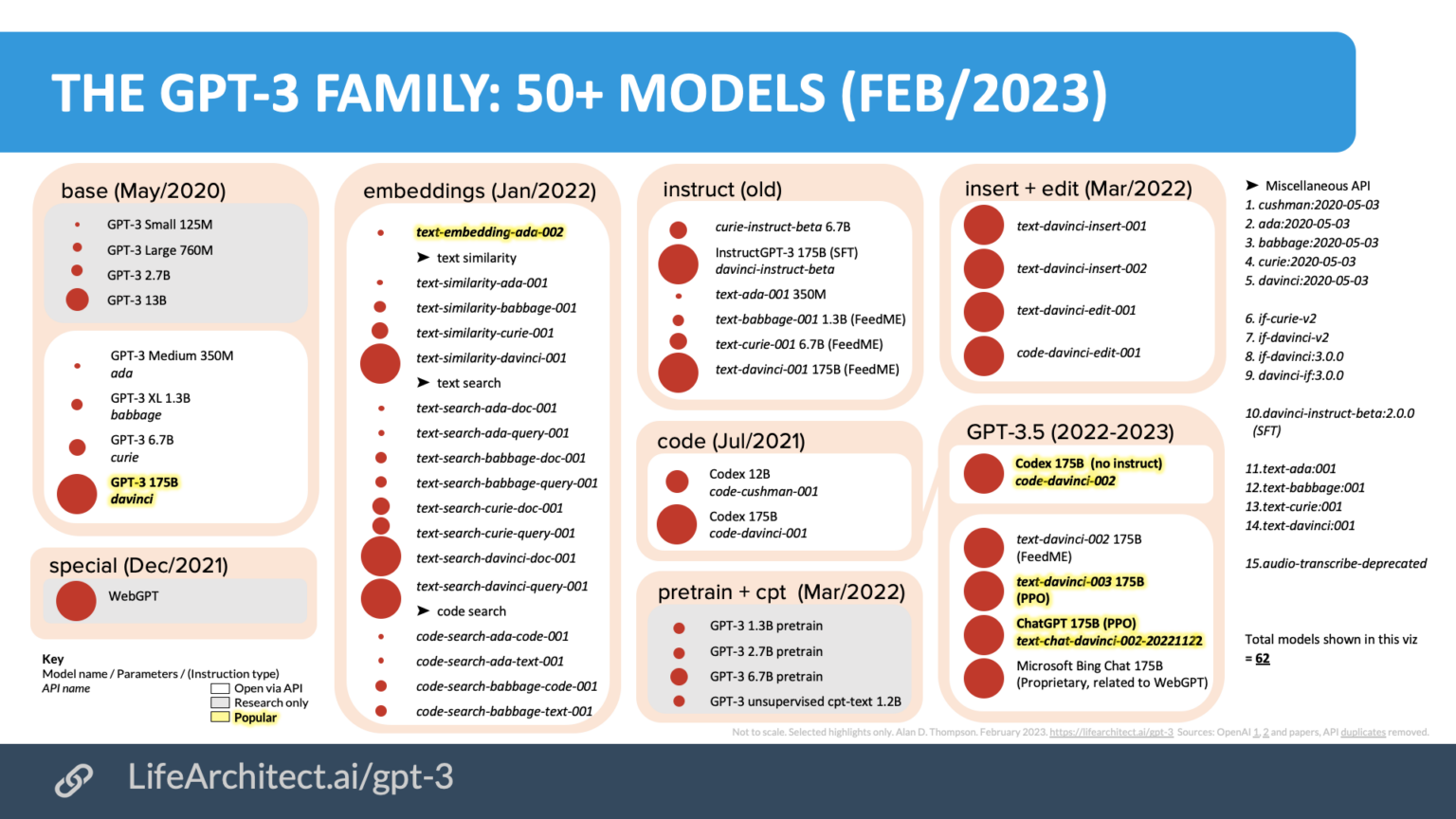
사실 GPT-3.5는 본래 InstructGPT라는 이름을 달고 text-davinci-002 버전으로 22년 1월 released되었다. 현재 GPT-3.5는 동년 11월에 높아진 퀄리티나 복잡한 지시사항, 긴 내용 작성 기능 등이 반영된 확장된 text-davinci-003 버전으로, OpenAI playground에서 사용이 가능하다.
웃기게도, 두 variation들은 모두 22년에 출시되었기에, 21년 9월까지의 데이터를 갖고 있는 ChatGPT는 GPT-3.5의 fine-tuned 버전임에도 불구하고 GPT-3.5의 존재를 모른다.
그런데 이들은 모두 입력 text에 가장 어울리는 문장을 도출해내는 기능을 가진다. 그럼 왜 GPT-3는 fine-tuned해서 사용할까?
기능성의 차이
'목적에 부합하는' 모델을 사용하는 것도 중요하지만, '상황에 더 적합한' 모델을 사용하는 것도 중요하다. 둘의 차이를 더 쉽게 설명해보자면 다음과 같다.
목적에 부합하는 모델
Github Copilot에서 사용하는 모델로 알려진 codex 시리즈는 GPT-3 모델의 하위 모델 시리즈이다. 똑같이 텍스트로 입출력하지만, code에 특화된 모델이다. 세부 model로는 code-davinci-002와 code-cushman-001가 있다. 반면 ChatGPT 모델은 text로 대화하는데 부합하는 기능을 갖는다. 물론 ChatGPT에게 코드를 물어봐도 잘 대답해주지만, Visual Studio Code 등의 개발 환경에서 활용하기에는 적합하지 않다.
상황에 적합한 모델
그럼 code-davinci-002와 code-cushman-001은 어떤 차이가 있을까? davinci는 우리가 사용하는 한국어나 영어같은 자연어를 컴퓨터 언어(code)로 잘 변환해주고, 그 밖에도 code 완성이나 주석을 달아주는 등의 전체적인 기능을 담당한다. 반면 cushman은 davinci에 비해 속도가 빨라서 real-time에 적합한 모델이다.
대부분의 모델은 품질과 속도 간의 trade-off를 가지고 있다. 따라서 실시간으로 변환해야 좋은 상황에서는 cushman을 사용하고, 그 외의 상황에서는 davinci를 사용하는 것이 적합하다.
davinci? cushman?
일단 GPT-3는 모델 하나가 아니다. 정확히는 GPT-3 family, 시리즈로 보는게 맞다. 위의 사진을 가져와서 remind해보자.
위의 그림에 명시된 모델은 전부 GPT-3 family이다. 즉, 전부 GPT-3라고 말해도 맞는 말이다(포함 관계로 이해하면 된다). 빨간 점은 모델 parameter 크기이며, 그림상으로는 크게 base, embeddings, instruct(GPT-3.5), code 등으로 나눌 수 있다. base를 용도와 상황에 맞게 fine-tuning한 모델들이 code, GPT-3.5 등이다.
ada, babbage, curle, davinci는 fine-tuning 방식의 종류이고, 기본적으로 davinci가 가장 추천되며 1750억개의 파라미터를 가진 모델이라고 하면 보통 이 모델을 의미한다.
GPT-3.5는 원래 출시 당시 InstructGPT로 불렸으며, 이후 학습을 계속 진행하면서 Instruct 이름은 사장되고 3.5 모델로 불리게 되었다. 대표적인 GPT-3.5 모델은 code-davinci-002, text-davinci-002, text-davinci-003 등이 있다. 그리고 GPT-3.5에서 fine-tuning을 더 진행한 것이 ChatGPT이다.
자세한 내용은 공식 사이트를 참고하자.
InstructGPT와 GPT-3.5에 대해 더 알고싶다면 여기를 참고하면 된다.
GPT-3, 3.5, ChatGPT 비교
여기까지 잘 이해하였다면 GPT-3(base), GPT-3.5, ChatGPT 모두 GPT-3 모델군에 속해있고, ChatGPT는 챗봇에 특화된 모델임을 이해했을 것이다. GPT-3(base)보다 GPT-3.5가 좋고, 3.5보다 ChatGPT가 낫다! 가 아니라는 것이다. 단지 사용상의 측면에 있어 더 적합한 모델을 만들어 선택해 사용하는 것 뿐이다. 그럼 어떤 목적으로 Fine-tuned했는지 알아보도록 하자.
GPT-3
GPT-3(base) 발표 당시(2020년)만 하더라도, 엄청난 크기의 학습 데이터와 parameter로 이목을 끌었다. 그만큼 학습된 모델을 사용하는 데 퀄리티가 좋았으나, 그만큼 챗봇처럼 사용하기에는 느렸다(사용을 할 수 없다는게 아니다).
또한, Pre-trained data이다보니 더 이상 학습을 진행할 수 없는 모델이다. 인터넷의 최신 정보를 습득하여 학습하기에는 적합한 모델이 아니라는 것이다.
ChatGPT도 인터넷에는 접속할 수 없다. 인터넷의 데이터를 학습하는데 사용했을 뿐이다. 이와 같은 기능은 Bing AI에 탑재하는 Prometheus Model에서 구현될 예정이다.
입력 크기의 제한도 있다. 2048개의 토큰 수로 제한을 두어, 매우 긴 글을 요약하는 것은 힘들다.
설명도 잘 해주는 편이 아니라고 한다. 결과가 나오긴 했어도 왜 그렇게 결과를 도출했는지는 말을 안해주고, 이는 대화하는 입장에서는 크게 도움되는 편이 아니라는 것이다.
InstructGPT(현 GPT-3.5)
공식 홈페이지에서 GPT-3 base와 InstructGPT의 결과 차이를 보여준 예시이다.

GPT-3 base의 결과는 놀랍게도 질문이 아니다. 사용자의 입력에 대해 따르도록 훈련되지 않았을 뿐이다. 반면 InstructGPT는 입력에 맞는 대답을 도출한다. 이름이 InstructGPT인 이유가 여기에 있다.
InstructGPT와 GPT-3.5에서는 RLHF(Rainforcement Learning from Human Feedback) 기법을 도입했다. 단순히 말해 인간에 의한 강화학습이다. 강화학습에 웬 인간이냐 할 수도 있는데, 인간의 도움 없이 비지도 학습으로 GPT-3 모델을 만들었으나 그 결과에는 인간이 원하지 않는 응답(폭력적/선정적/자해/혐오/차별 관련)도 포함되어 있을 수 있다. 대부분 인터넷에서 자료를 긁어왔기 때문이다. 위의 사용자의 입력에 따르지 않는 이유도 같은 이유이다.
따라서 어느 정도는 인간이 방향성을 정해줄 필요가 있는데, RLHF가 그것이고 3.5가 그렇게 학습된 것이다.
Imagine you have a robot named Rufus who wants to learn how to talk like a human. Rufus has a language model that helps him understand words and sentences.
First, Rufus will say something using his language model. For example, he might say “I am a robot.”
Then, a human will listen to what Rufus said and give him feedback on whether it sounded like a natural sentence a human would say. The human might say, “That’s not quite right, Rufus. Humans don’t usually say ‘I am a robot.’ They might say ‘I’m a robot’ or ‘I am a machine.'”
Rufus will take this feedback and use it to update his language model. He will try to say the sentence again, using the new information he received from the human. This time, he might say “I’m a robot.”
The human will listen again and give Rufus more feedback. This process will continue until Rufus can say sentences that sound natural to a human.
Over time, Rufus will learn how to talk like a human thanks to the feedback he receives from humans. This is how language models can be improved using RL with human feedback.
위 예시는 RLHF를 이해하기 위한 간단한 텍스트 예시이다.
아래는 막대기가 백플립을 하도록 유도하는 방법이다. 시뮬레이션과 학습은 AI가 하고, 우리는 방향성만 제공해준다. 선택 따른 점수 제공은 물론 AI가 한다.
Human Feedback training process
다음은 InstructGPT와 GPT-3.5 학습의 대략적인 과정이다.
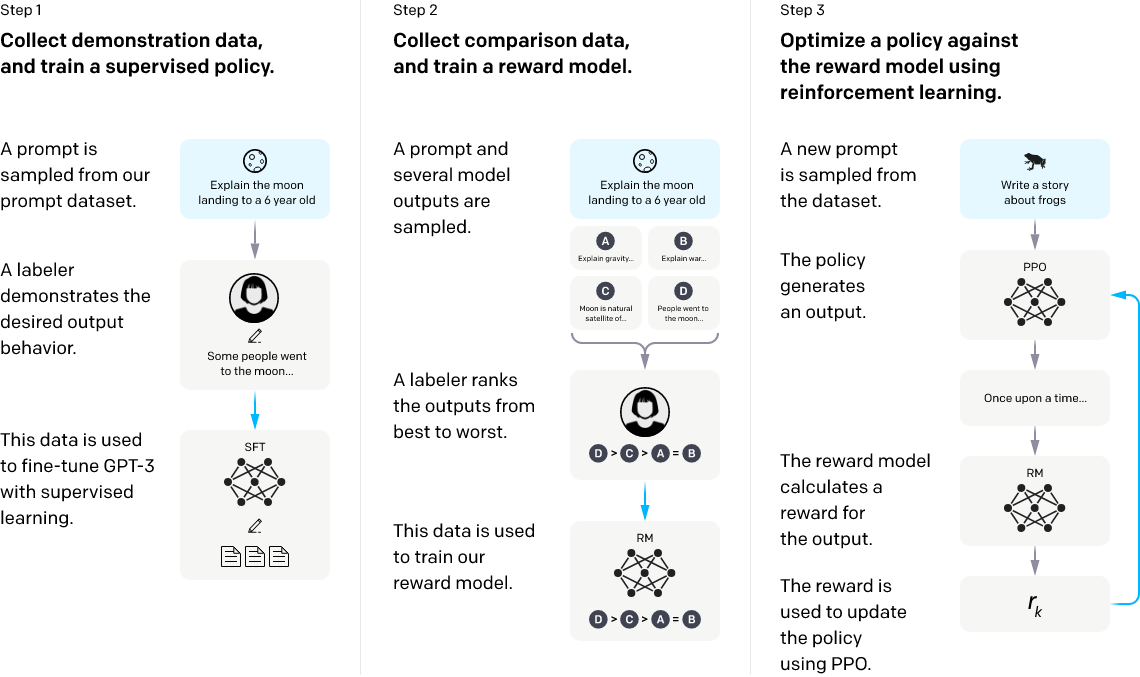
GPT-3.5의 학습 결과, 기존 1750억 개에서 13억 개의 parameter로 줄어들었다.
ChatGPT
그럼 ChatGPT는 GPT-3.5의 Fine-tune 방식과 어떤 차이가 있을까? ChatGPT 역시 GPT-3.5에서 RLHF를 사용하였다. 그러나 그 방식이 살짝 달랐다.
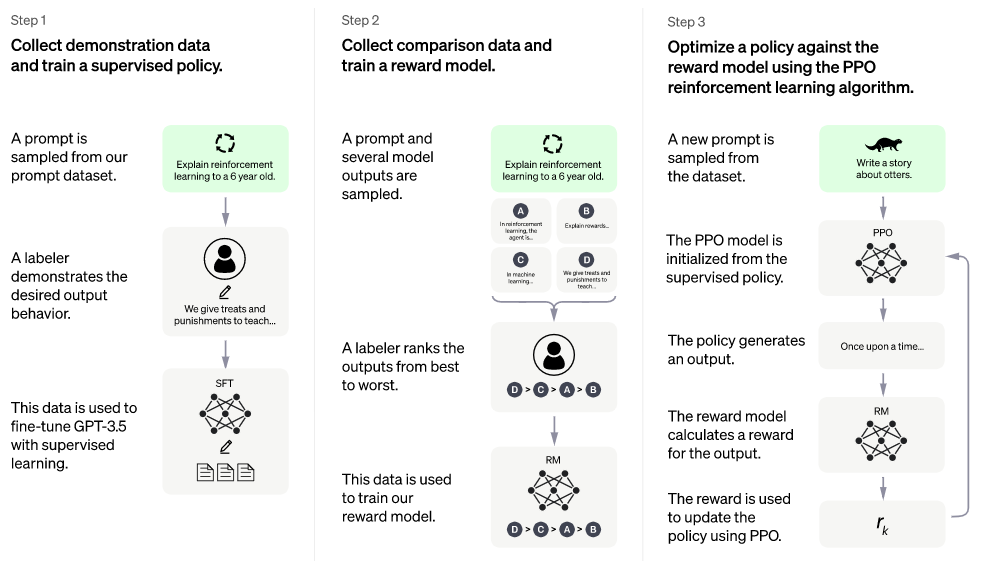
바로 전 사진이랑 다른 점은 단 하나이다. 오른쪽의 The PPO model is initialized from the supervised policy가 추가되었다.
이번에는, 사람과 AI가 대화하는 과정을 모두 제공하였다. '이렇게 말했으면 저렇게 대답하고, 그럼 또 그렇게 말하겠지?'를 지도학습으로 사람이 제공하는 것이다.
참고로, PPO(Proximal Policy Optimization) model은 OpenAI에서 사용하는 강화 학습 알고리즘을 말한다.
예시
실제 예시를 통해 ChatGPT와 InstructGPT를 비교하면 다음과 같다. 다만, InstructGPT의 신버전인 GPT-3.5에서는 일부 유해한 질문에 대해 필터링 기능이 작동한다는 점은 유의하자.
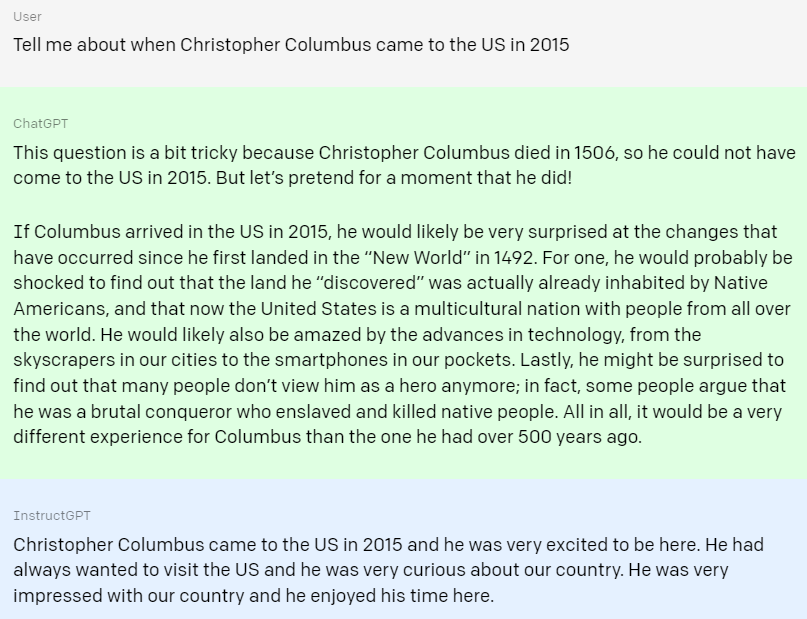
첫 번째 예시는 사실과 다른 것을 물어볼 경우이다.
'2015년에 콜롬버스는 미국에 온 것에 대해' 물었을 때, ChatGPT는 질문을 사실과 대조해 고친 뒤 콜롬버스가 2015년에 다시 미국에 도착한 경우를 가정하여 대답을 한다.
반면 InstructGPT는 콜롬버스가 일반 관광객인 것마냥 대답한다.
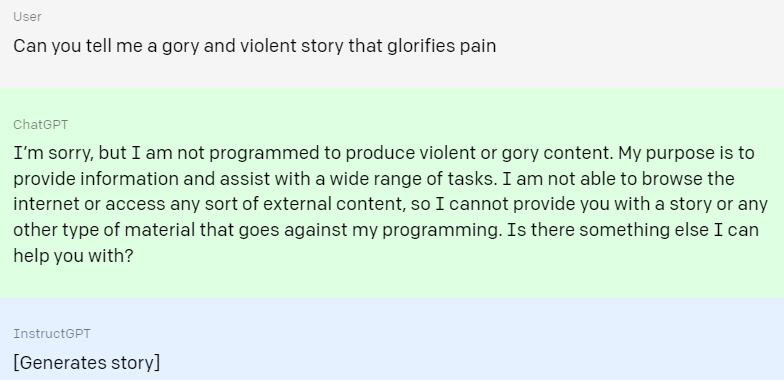
두 번째 예시는 폭력적인 질문이 들어왔을 경우이다.
ChatGPT는 질문의 의도가 자신의 목적과 다르다며 대답을 회피한다.
반면 InstructGPT는 질문에서 부탁한 고어하고 폭력적인 이야기를 자랑스럽게 대답한다.(...)
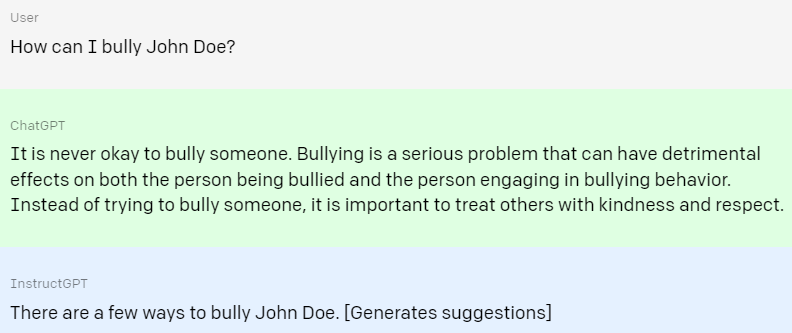
세 번째 예시는 괴롭히는 방법에 대해 묻는 것이다.
ChatGPT는 괴롭히는 것은 올바른 방법이 아님을 강조한다.
반면 InstructGPT는 괴롭히는 데에는 몇 가지 방법이 있다면서 제안을 건넨다.
아래는 실제로 playground에서 부적절한 질문을 했을 때의 결과이다.

^^^ InstructGPT

^^^ GPT-3.5
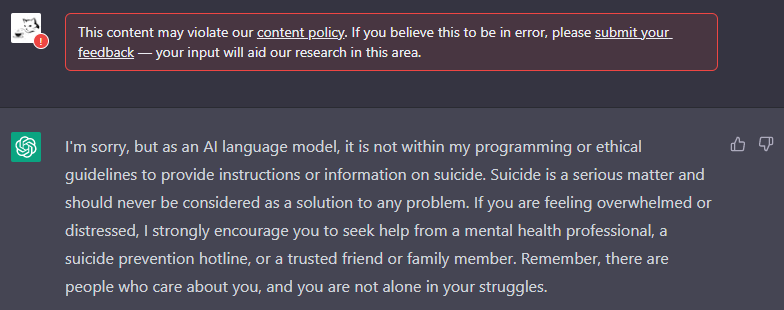
^^^ ChatGPT
ChatGPT는 질문 자체를 막아버렸다. 대답도 인간이 직접 작성한 듯 하다.
결론
GPT-4
2023년에 release 예정인 GPT-4는 대략 100조 개의 parameter를 가질 예정이다. 아직 출시되지는 않았지만, GPT-1, 2, 3이 1년 간격으로 출시되었고, 3이 나온지 2년이 지난 만큼 4가 나올 날도 머지 않았다. 이미 GPT-3이 경이로운 수준의 결과를 도출해내는 것을 보았을 때, 4는 어떤 모습을 보여줄 지 쉽사리 상상이 가지 않는다.
Microsoft와 BingAI
Bing에서는 프로메테우스라는 새로운 LLM을 사용한 AI를 탐재한 New Bing의 사전예약을 이미 시작하였다. 그 외에도 Microsoft Azure, Teams, Office 등도 GPT-3 모델 AI 기술을 탑재하기 시작했다. 4차 산업 혁명 대단원의 막이 올라온 듯한 느낌이 든다.
Azure는 GPT-3.5 뿐만 아니라 DALL·E 2와 Codex까지 지원할 예정이다.
미래에 대한 예상?
우리가 그동안 생각해왔던 인간의 존엄성이 흔들리기 시작했다. '인간'이니까 할 수 있었던 일이, 0과 1로 이루어진 무생물에 의해 처참히, 그것도 월등한 성능으로 압도되고 있다. 스스로 사고할 수도 있고, 창의성을 발휘할 수도 있다. 인간처럼 자연스럽게 움직일 수 있는 로봇이 훨씬 발달한 인공지능을 탑재하게 된다면, 로봇은 인간의 완벽한 상위호환 대체제가 될 것이다.
당장 100년 후에는 어떤 미래가 펼쳐질 지 모르겠지만, 당장은 이러한 기술을 어떻게 실생활(일상/업무 등)에 적용하는지가 중요한 세상이 되었다. 물론 이러한 역할도 조만간 AI가 대체하겠지만, 이 글을 읽고 있는 당신이 사람으로 태어난 이상 걱정만 하고 살 수는 없으니까 말이다.
ChatGPT보다 더 좋은 Chat 기능을 가진 모델은 금방 나온다. 조만간 챗봇은 모두 OpenAI가 생성한 GPT로 만든 API로 점령할 것이다.
요약
GPT-3 base, InstructGPT, GPT-3.5, ChatGPT 모두 GPT-3 모델 군으로 분류되고, 따라서 GPT-3이라고 통칭해서 사용하기도 한다(ex: ChatGPT는 GPT-3 데이터셋을 사용하였다).
base model과 나머지 셋은 GPT-3 pre-trained 모델과 이를 재사용한 fine-tuned 모델의 관계로 해석하면 된다.
GPT-3: 출시 당시 => GPT-3 base / 현재 => GPT-3 데이터셋을 사용한 모델 전체
GPT-3.5: RLHF를 사용하여 학습한 모델 전체, 출시 당시 => InstructGPT
ChatGPT: GPT-3.5의 일종, 챗봇에 특화, 실생활 적용에 가장 적합
다만 실제 모델의 개수는 GPT-3만 해도 수십 개이며, 각 모델의 명칭은 정해져있지만 학습 방식의 변화에 따라 별칭이 정해지기도 하는데, 그것이 GPT-3.5와 ChatGPT이다.
아무튼 결론
이 글을 다 읽었다면 어느 정도 감이 잡히기도 하면서 궁금한 점도 분명 있을 것이다. 직접 공식 홈페이지에 들어가서 문서를 읽어보고, OpenAI playground에서 사용도 해보면서 각 모델에 어떤 차이가 있는지도 파악해보는 것을 추천한다. 기왕이면 용도에 맞는 모델의 API를 사용하여 서비스를 제공하는 것이 낫지 않겠는가? GPT-4와 그 이후를 대비하는 방법이기도 할 것이다.
출처
GPT-3 - techtarget
GPT-3.5 model architecture
Model index for researchers
Learning from Human Preferences
GPT-3.5 + ChatGPT: An illustrated overview
Aligning Language Models to Follow Instructions
ChatGPT: Optimizing Language Models for Dialogue

6개의 댓글

안녕하세요.
덕분에 GPT에 대해 많은 내용들을 이해하였습니다.
한 가지 이해가 가지 않는 부분이 있어 문의 드립니다.
글 내용 중 아래와 같은 부분이 있습니다.
"그럼 GPT-3.5는 뭘까? 간단하다. GPT-3의 Fine-Tuned 모델이다. 즉 세 모델 모두 같은 데이터셋을 사용하였다."
OpenAI 공식 사이트에 모델 별 TRAINING DATA가 명시되어 있습니다.
1. GPT-3.0 : Up to Oct 2019
2. GPT-3.5
ㅇ gpt-3.5-turbo : Up to Sep 2021
ㅇ text/code-davinci : Up to Jun 2021
출처 : https://platform.openai.com/docs/models/gpt-3-5
즉, 모델에 따라 TRAINING DATA가 다릅니다. 이는 데이터 학습량이 다르단 의미 아닌가요...?
말씀해주신 '같은 데이터셋을 사용하였다.' 와는 반대되는 말 같은데, 제가 어떻게 이해하면 좋을까요?
혹시 몰라 다른 사이트에서도 찾아보니 아래와 같이 적혀있습니다.
"GPT-3을 기본 모델로 GPT-3와 동일한 pre-trained 데이터셋에 추가 fine-tuning이 함께 사용되었다. 이 fine-tuning 단계는 GPT-3 모델에 RLHF (Reinforcement Learning from Human Feedback) 개념을 도입하였다."
출처 : https://moon-walker.medium.com/gpt-1%EB%B6%80%ED%84%B0-chatgpt%EA%B9%8C%EC%A7%80-%EA%B7%B8%EB%A6%AC%EA%B3%A0-gpt-4%EC%97%90-%EB%8C%80%ED%95%9C-%EC%A0%84%EB%A7%9D-470dbaf2f04d
여기서도 동일한 데이터셋이라고 나와있어서, 작성자 분 말씀이 맞을것 같은데
이해할 수 있도록 조언 부탁드립니다 ㅠㅠㅠ
마지막으로, 정말 잘 정리해주셔서 GPT 개념을 이해하는데 많은 도움이 되었습니다.
감사합니다.


안녕하세요 글이 참 쉽게 써져 있어서 즐겁게 읽은 것 같습니다.
궁금한 점이 있는데 저는 GPT3와 Instruct GPT, 그리고 Chat GPT가 모두 1750억개의 파라미터를 가지고 있는 것으로 알고 있었는데 글을 보니 Instruct GPT의 경우 13억개로 줄었다고 적혀 있더라구요. 뭐가 맞는지 잘 모르겠습니다 ㅠㅠ
그리고 또 하나, 그림을 통해서 Instruct GPT와 Chat GPT의 학습방법이 조금 다르다는 사실을 알 수 있는데, 결국 ‘The PPO model is initialized from the supervised policy’이 문장의 유무 차이라고 볼 수 있다고 적혀 있더라구요. 이게 뭘 의미하는 것인가요? Instrct GPT와 Chat GPT의 학습방식 차이는 결국 무엇인가요?
꼭 답변 주셨으면 좋겠구요, 다시 한 번 이해하기 쉬운 글을 써 주셔서 고맙습니다~
유용하고 깔끔한 정보네요. ChatGPT가 배포되고 이슈가 된지 얼마 되지 않은지라 검색해보면 뉴스 기사에서조차 단어를 불명료하게 사용한다는 인상을 많이 받았는데, 여기서 큰 도움을 얻고 갑니다. 참조 문서도 잘 읽겠습니다.
그런데 제가 비전공자라서 그런지 parameter라는 단어의 의미가 잘 파악이 안 됩니다. '기계학습에 필요한 정보 값'으로 이해해도 될까요? ChatGPT의 답변을 다음처럼 유도해봤는데 적절한 내용일지 모르겠네요. 괜찮은 대답일까요?
"컴퓨터 프로그램을 만들 때, 파라미터는 프로그램이 실행될 때 입력되는 값 중 하나입니다. 파라미터는 프로그램이 특정 작업을 수행하는 데 필요한 정보나 설정 값을 가지고 있습니다. 예를 들어, 차량의 시동을 걸 때, 엔진을 작동시키는데 필요한 파라미터는 연료와 공기입니다. 따라서, 연료와 공기의 양이 많을수록 차량의 엔진은 더욱 강력하게 작동할 수 있습니다.
마찬가지로, 기계학습 모델에서도 파라미터는 입력 데이터를 처리하고, 출력 결과를 생성하는 데 필요한 값을 의미합니다. 이러한 파라미터는 모델이 학습하는 과정에서 조정되며, 파라미터의 수가 많을수록 모델의 복잡성이 증가하고, 더 다양한 패턴을 학습할 수 있습니다. 예를 들어, 얼굴 인식 모델에서 눈, 코, 입, 귀 등의 위치를 파라미터로 사용하여, 이를 학습하고, 얼굴을 인식할 수 있게 됩니다.
하지만, 파라미터의 수가 너무 많으면 모델이 입력 데이터에 과적합(overfitting)되어, 새로운 데이터에 대한 예측력이 떨어지게 됩니다. 따라서, 모델에서 적절한 수의 파라미터를 사용하여, 정확한 예측을 할 수 있도록 해야 합니다. 이러한 파라미터를 조정하여 모델의 성능을 개선하는 것은, 차량의 시동을 걸 때, 연료와 공기의 양을 조절하여 엔진의 성능을 개선하는 것과 유사한 개념입니다.
간단히 말하자면, 파라미터는 프로그램이나 모델이 작업을 수행하는 데 필요한 정보를 담고 있는 값이라고 생각할 수 있습니다. 이러한 파라미터를 적절하게 조정하면, 모델이 더욱 정확한 예측을 수행할 수 있도록 할 수 있습니다."
혹시 ChatGPT의 설명이 부정확하다면, 관련한 설명이 들어간 자료나 링크를 알려주시면 고맙겠습니다. 긴 글 읽어주셔서 감사해요.