lec10-1: Sigmoid 보다 ReLU가 더 좋아
Let's go deep & wide !
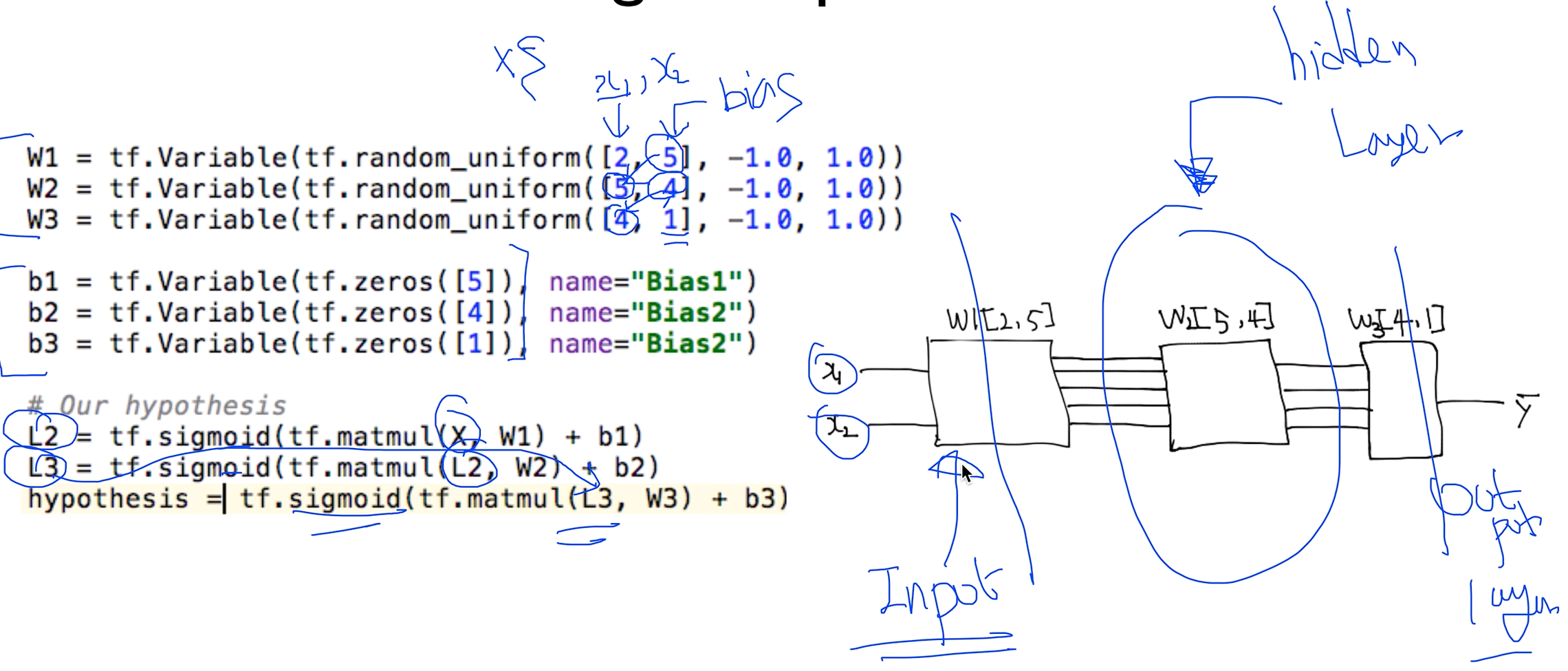
W1 = [2, 5] => x의 갯수가 2개, 출력하고 싶은 갯수 = 5개
W2 = [5, 4] => W1에서 출력한 갯수를 받아와야하니 x의 갯수가 5개, 출력하고 싶은거 4개
W3 = [4, 1] => W2에서 출력한 갯수를 받아와야하니 x의 갯수가 4개, 출력하고 싶은거 1개
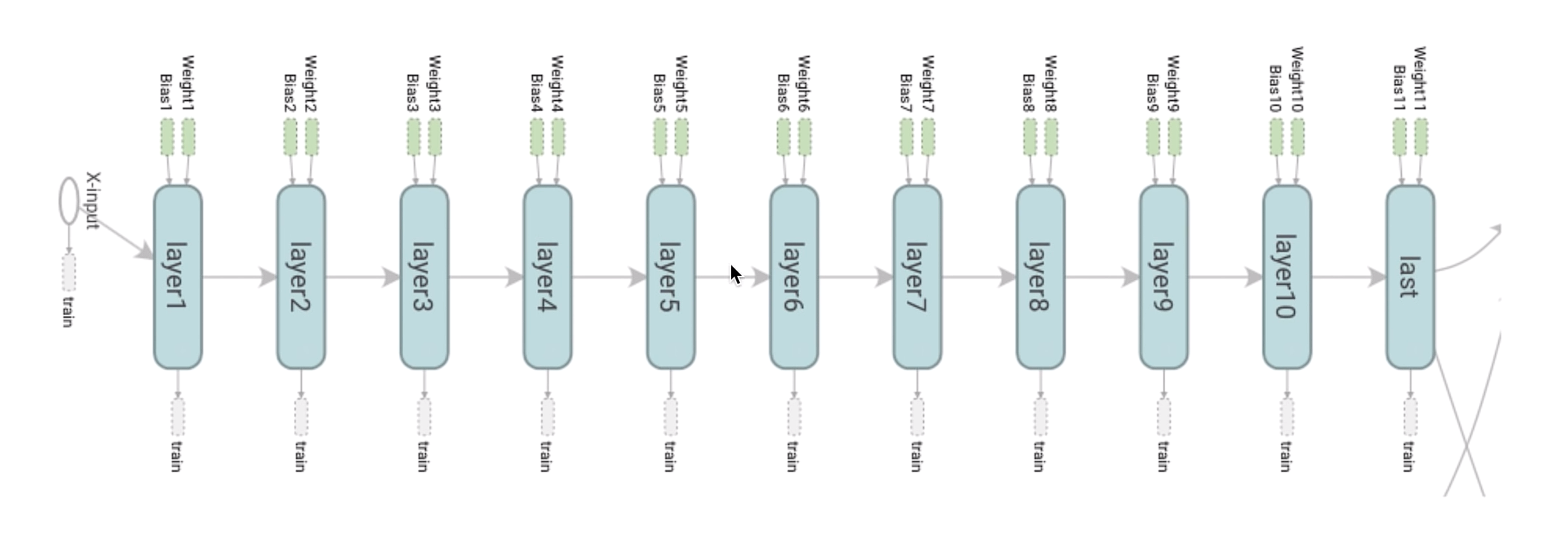
9 hidden layers!
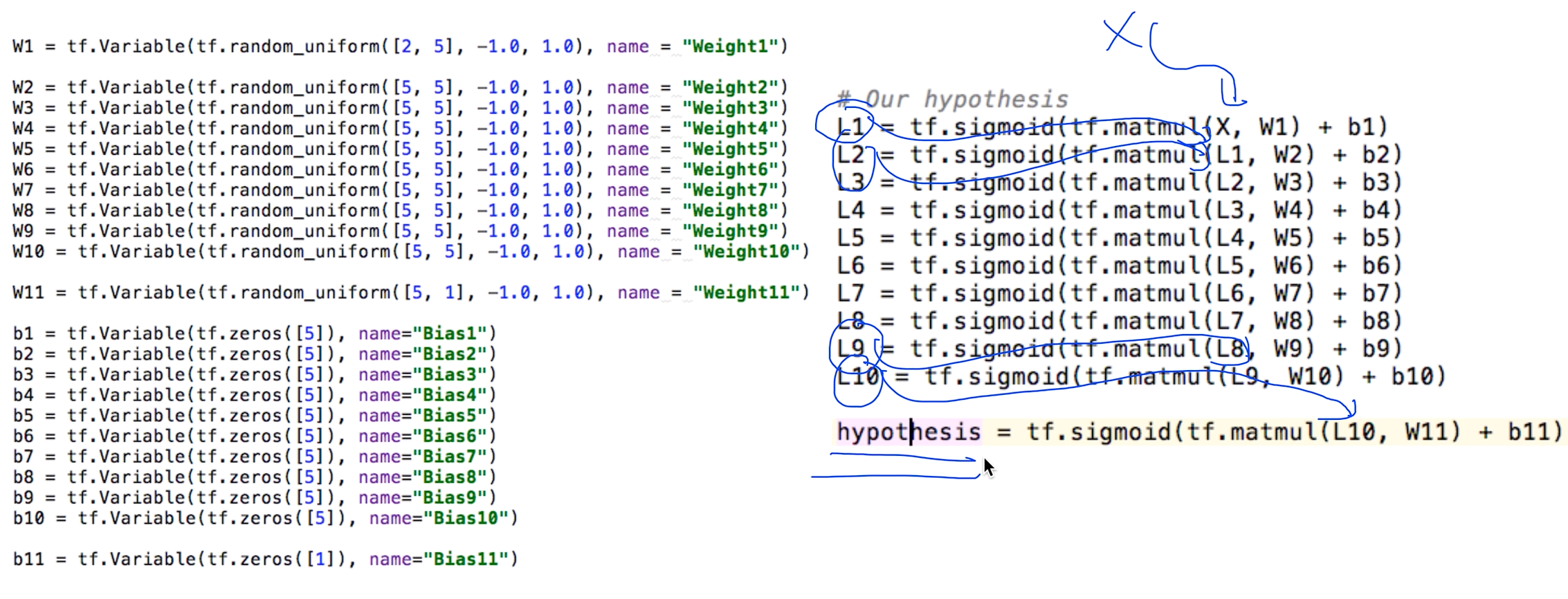
처음과 마지막만 신경 쓰면 된다!
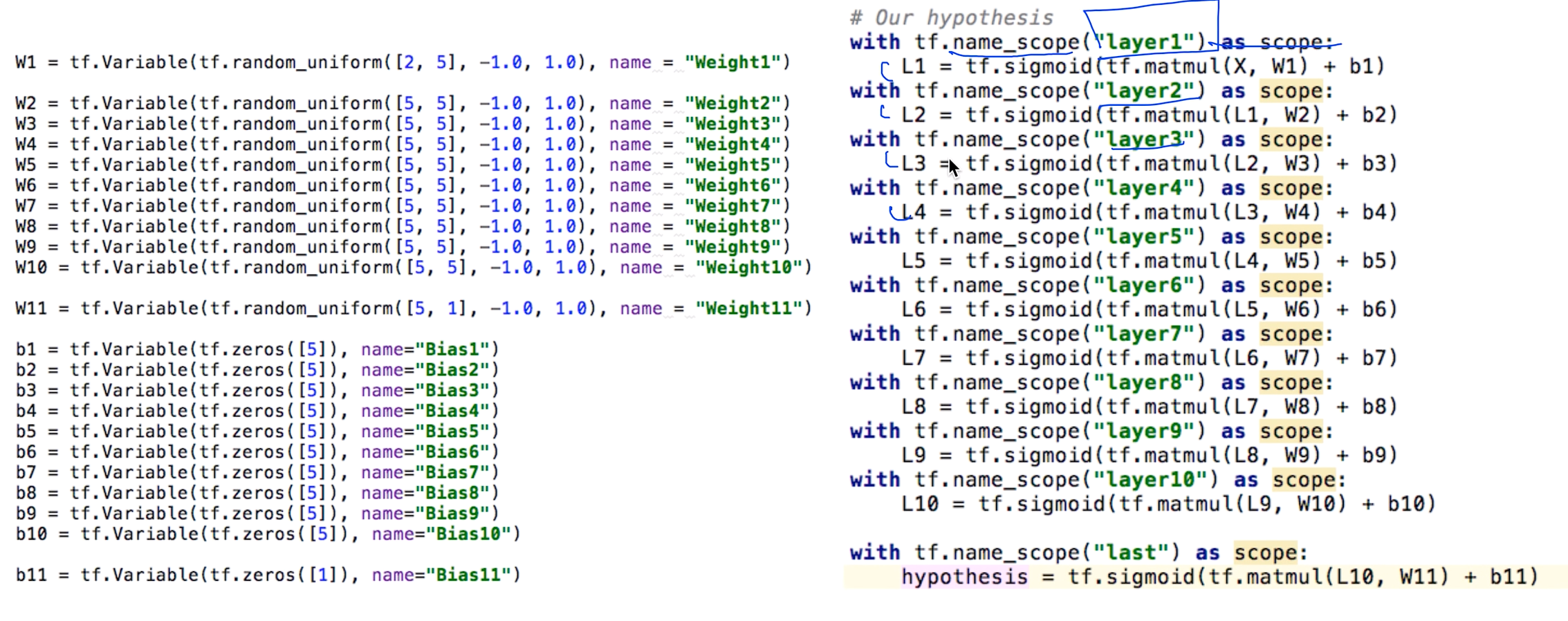
텐서보드를 이용해서 시각화 하고싶을 때
Tensorboard visualization
Poor results?
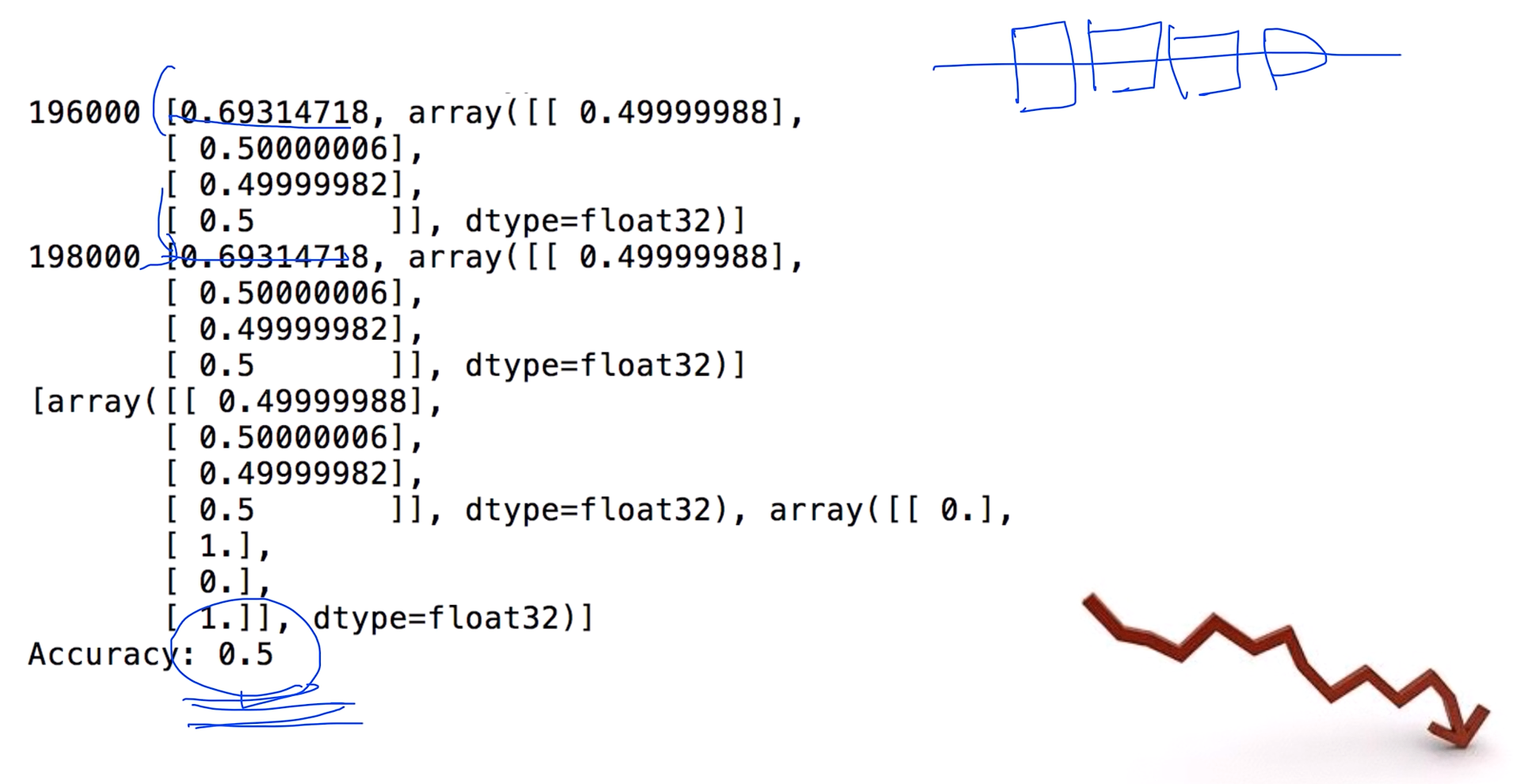
코스트 값이 떨어지지 않고 Accuracy가 0.5밖에 되지가 않는다? 왜 이러는거지?
Tensorboard Cost & Accuracy
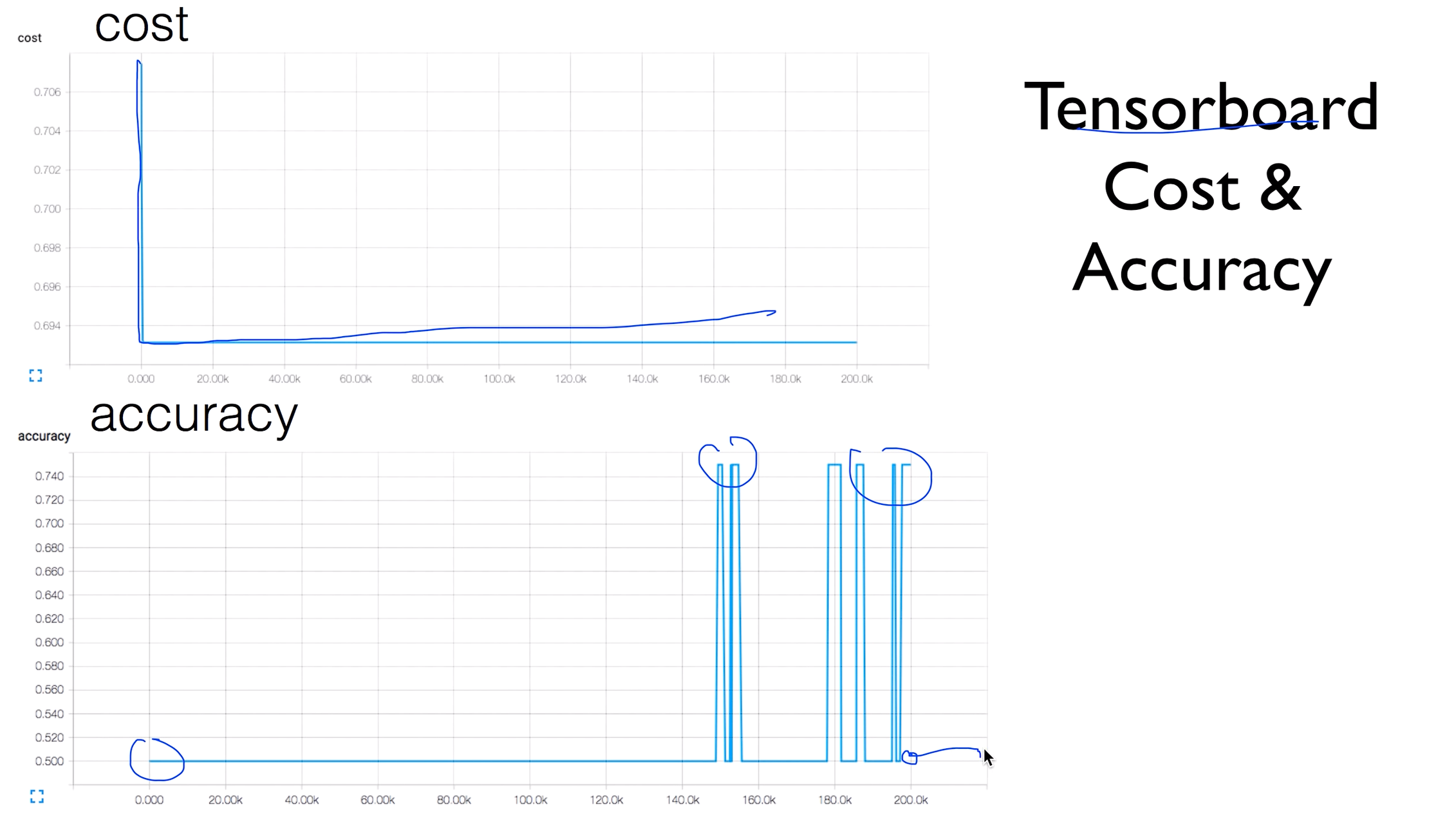
방금 생긴 문제를 텐서보드를 활용해서 그래프로 나타내보았다
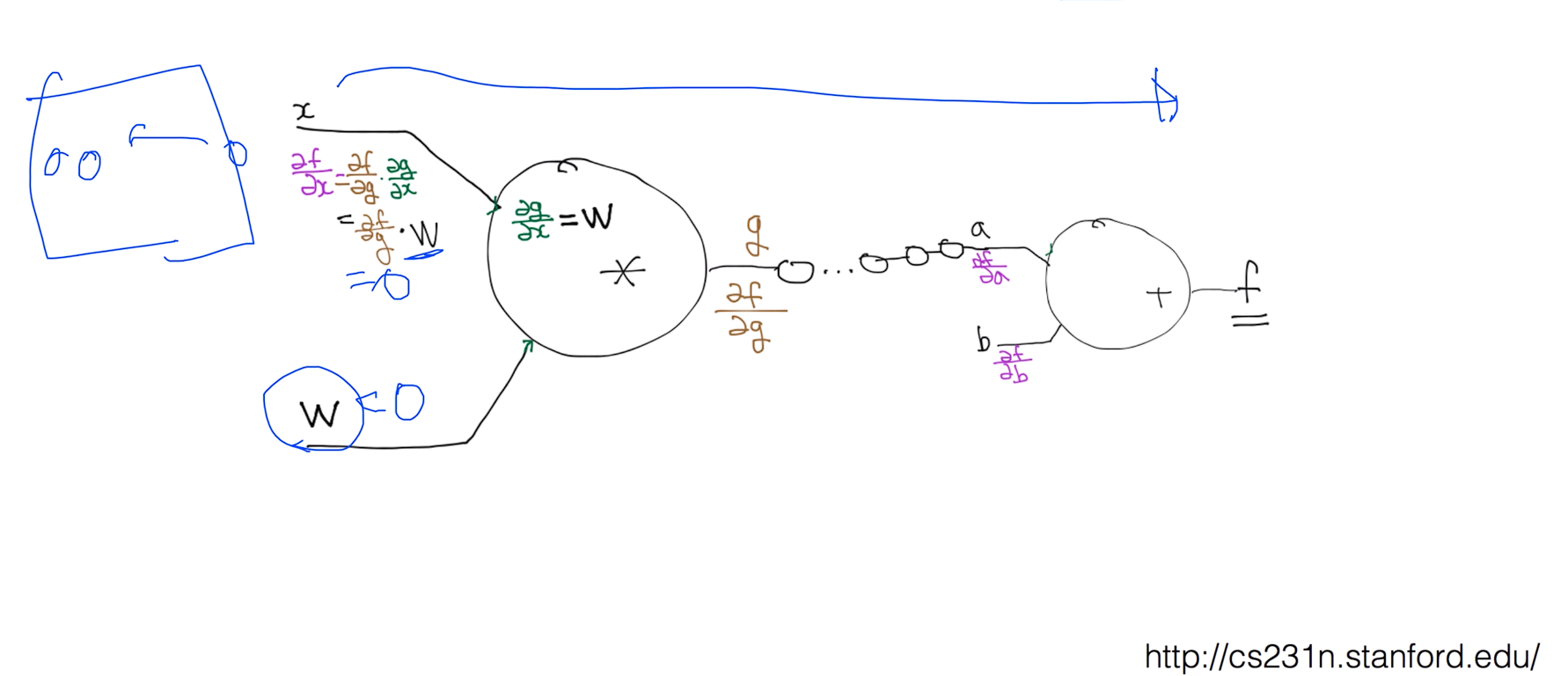
Backpropagation
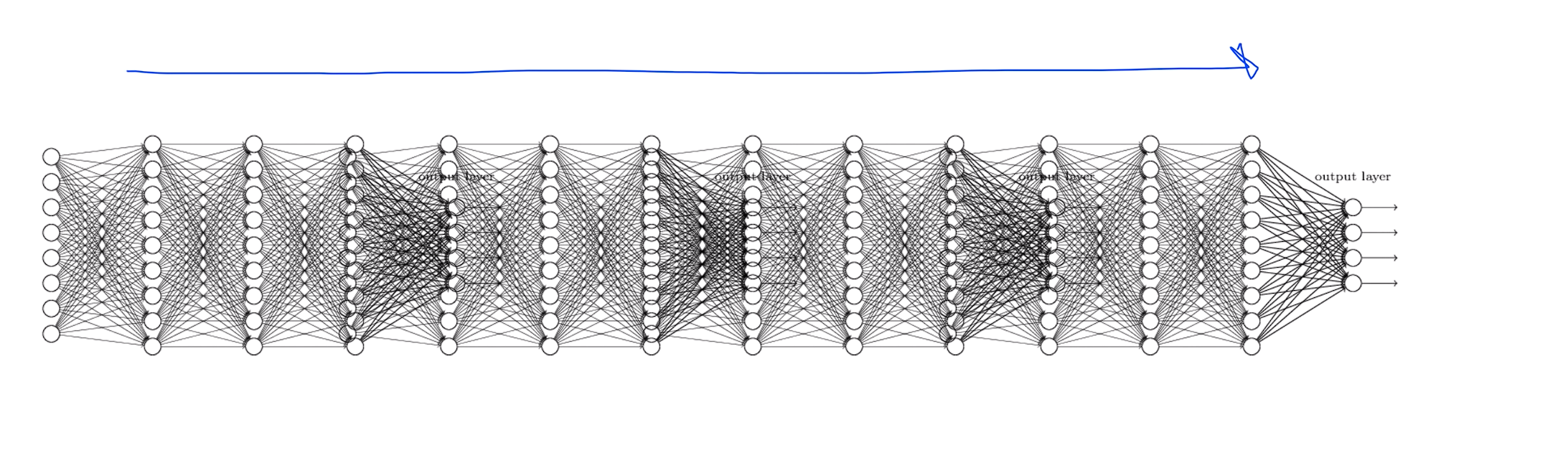
2단 3단 그래프정도는 잘 학습이 되는데 10단 이상정도의 그래프는 학습이 안된다
lec 9-2 : Backpropagation (chain rule)
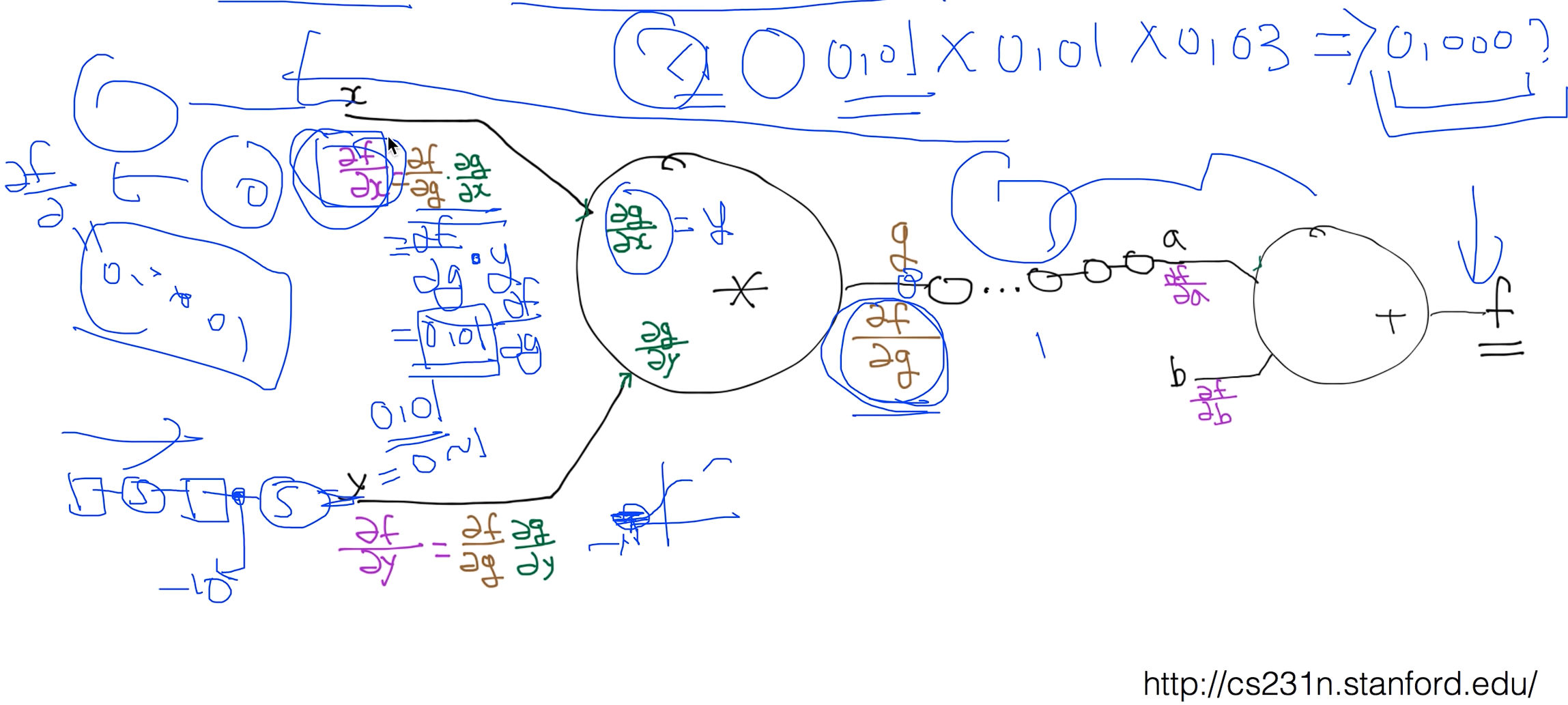
Vanishing gradient (NN winter2: 1986-2006)

기울기가 사라지는 문제이다.
그림으로 보면 앞단에 있는 경사나 기울기는 나타나는데 그러나 단수가 깊어 질수록 경사도가 사라져 버린다
Sigmoid!
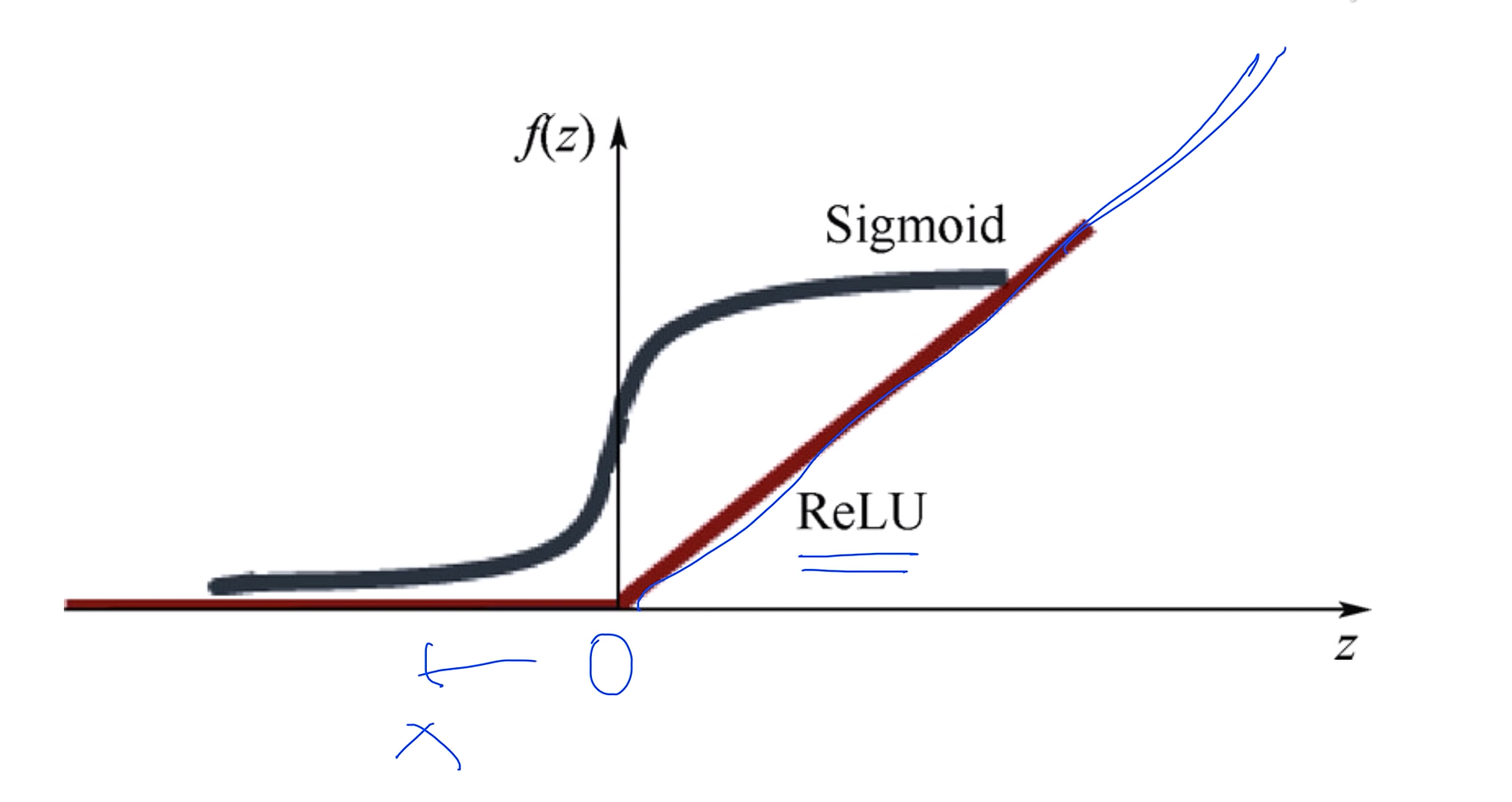
0보다 작을경우 버리고 0보다 클 경우 갈때가지 가
ReLU: Rectified Linear Unit
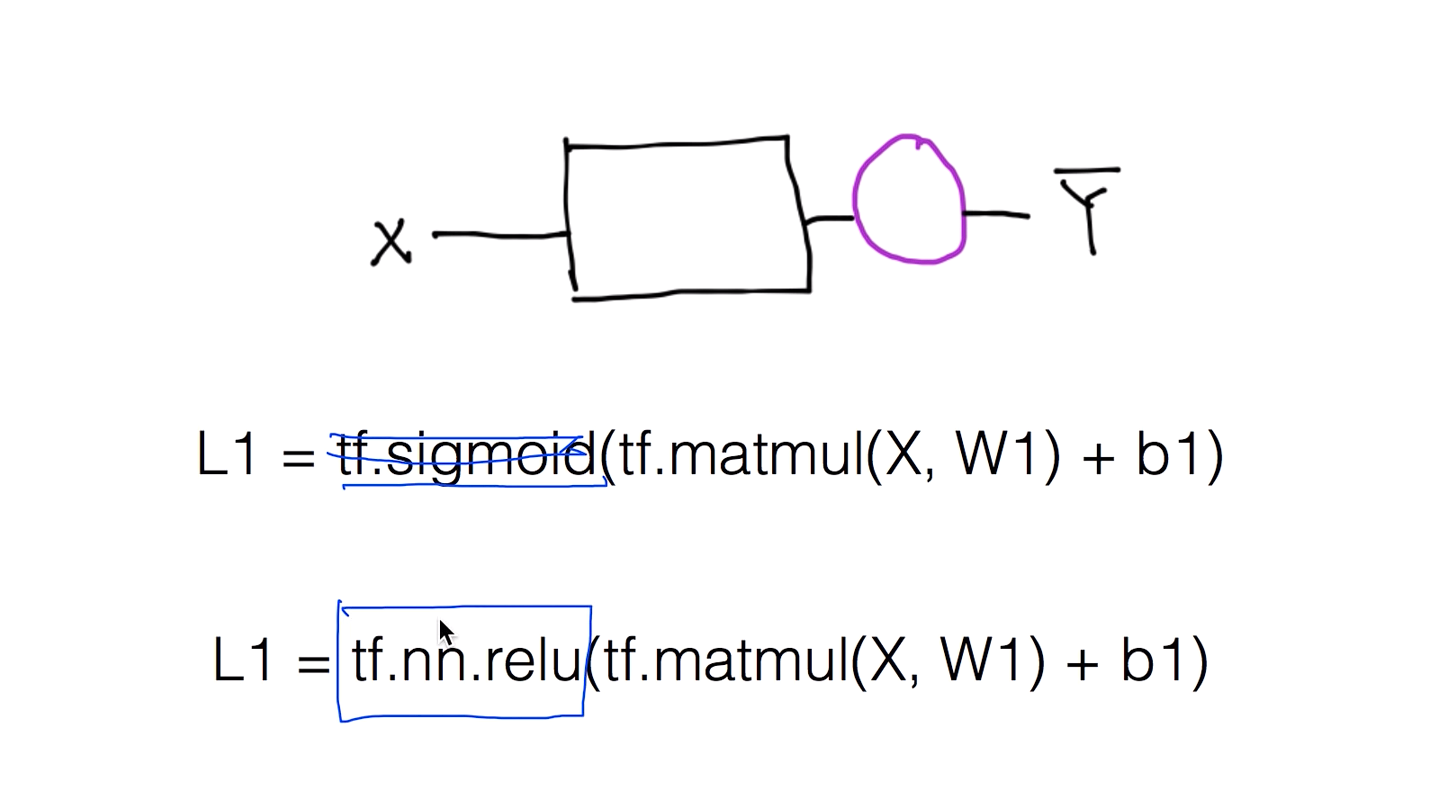
기존에 시그모이드 함수 있던곳에 렐루 함수를 넣으면 된다!
ReLu

마지막 단은 시그모이드를 써야하는데 마지막 단의 출력은 0~1사이여야 하기 때문에
Works very well
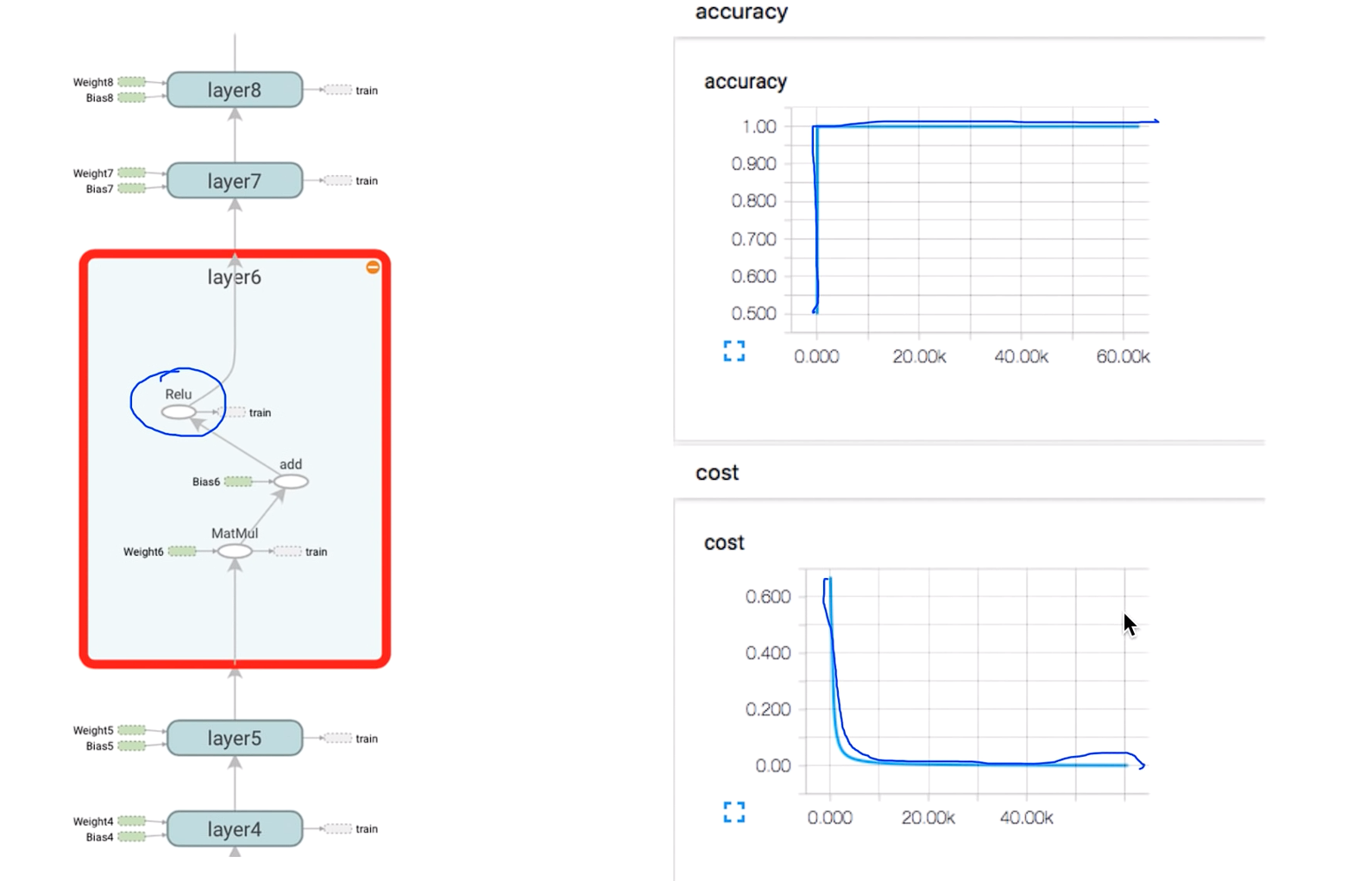
학습이 잘 되는것을 볼 수 있다.
lec10-2: Weight 초기화 잘해보자
Cost function
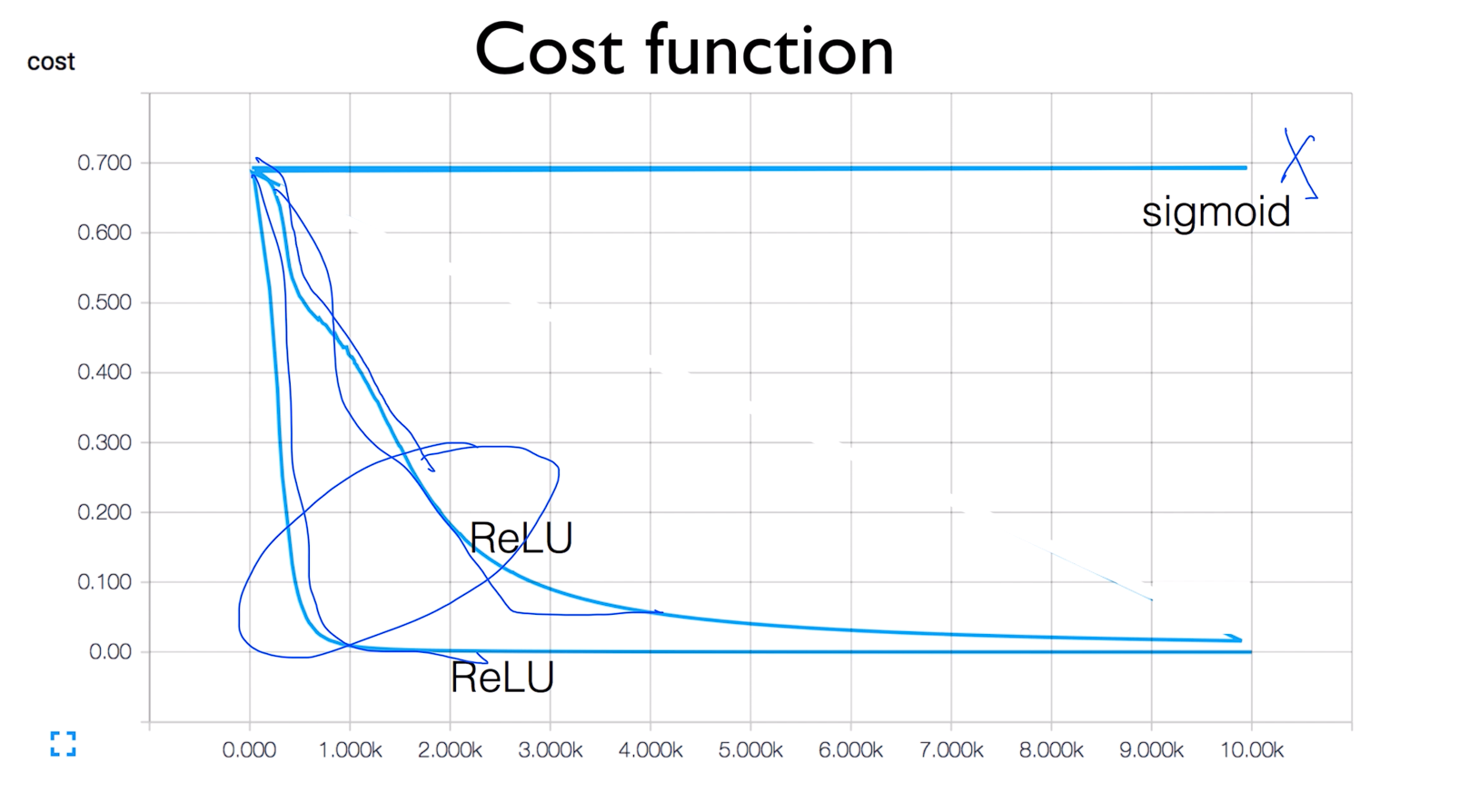
ReLu를 두번 실행시키면 그래프의 값이 좀 다르게 나온다 그 이유는 실행 시킬때 W를 랜덤값으로 줘서 그런거임
Set all initial weights to 0
W값을 다 0으로 줘버린다면.. x의 값들을 계산을 다 하더라도 결국 w를 곱해야하는데 w가 0이 되버린다면 결과적으로 0이 나와서 안된다
Need to set the initial weight values wisely
- Not all 0's
- Challenging issue
- Hinton et al. (2006) "A Fast LearningAlgorithmforDeep Belief Nets"
- Restricted Boatman Machine(RBM)
Good news
- No need to use complicated RBM for weight initializations
- Simple methods are OK
- Xavier initialization: X. Glorot and Y. Bengio, "Understandingthe difficulty of training deep feedforwardneural networks," in International conference on artificialintelligence and statistics, 2010
- He's initialization: K. He, X. Zhang, S. Ren, and J. Sun, "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification," 2015
Xavier/He initialization

Still an active area of research
- We don't know how to initialize perfectweight values, yet
- Many new algorithms
- Batch normalization
- Layer sequential uniform variance
- ...
lec10-3: Dropout 과 앙상블
Overfitting
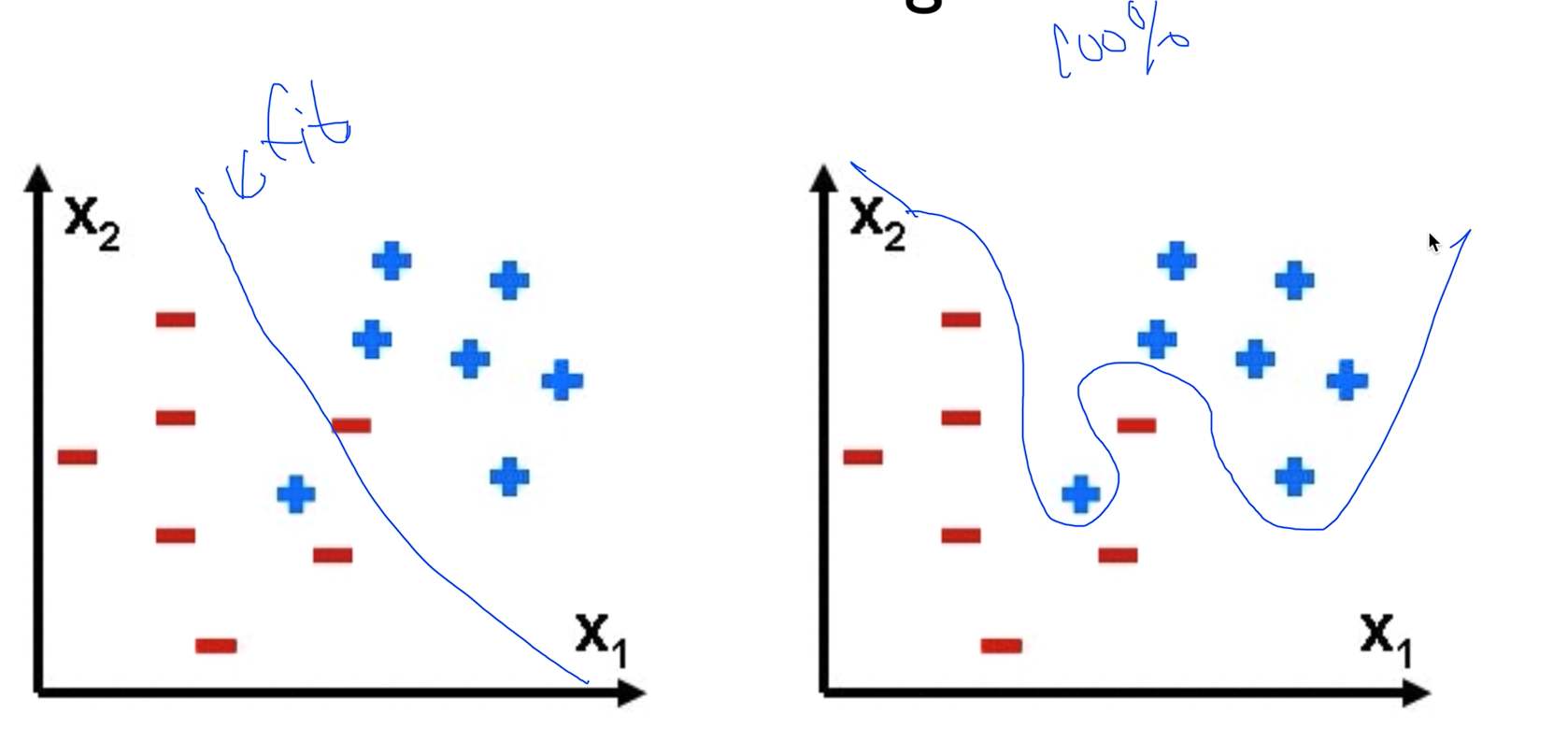
Am I overfitting?
- Very high accuracyon the training dataset (eg:0.99)
- Pooraccuracy on the test dataset (0.85)
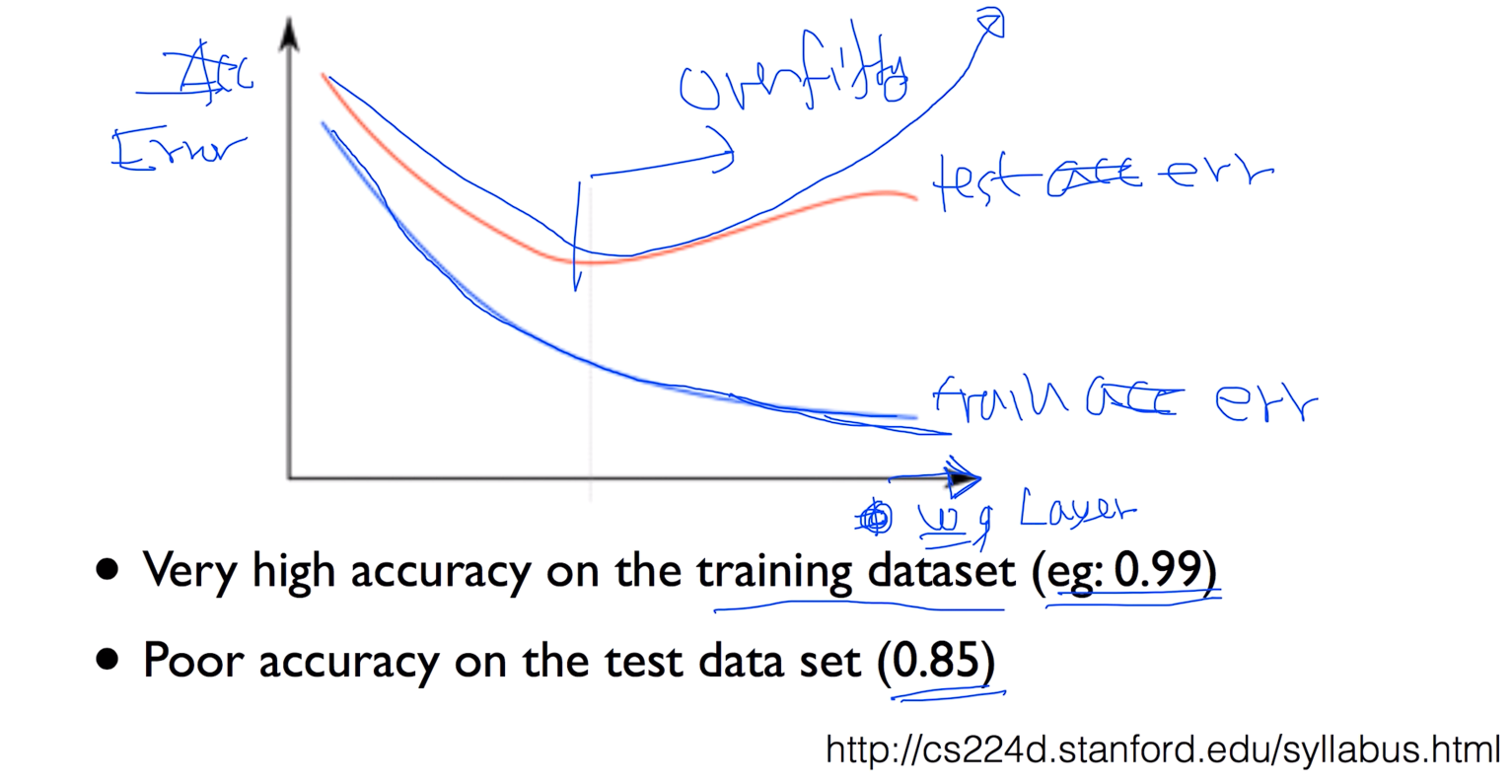
파란색 선이 training error 빨간색 선이 test error
y축이 acc x축이 w를 몇개를 사용했는지 하는 Layer
Solutionsfor overfitting

딥러닝에서는 굳이 features의 수를 줄일 필요는 없다
Regularization
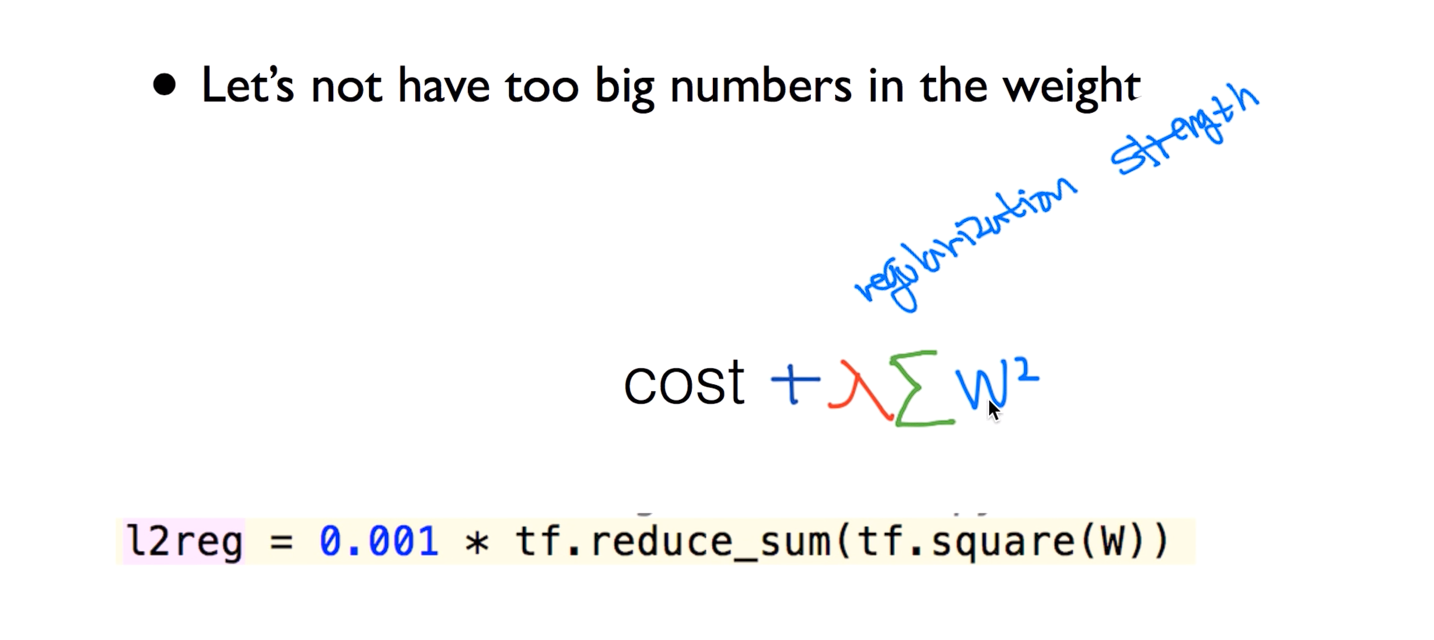
Dropout: A Simple Way to Prevent Neural Networks form Overfitting [Srivastavaet al. 2014]
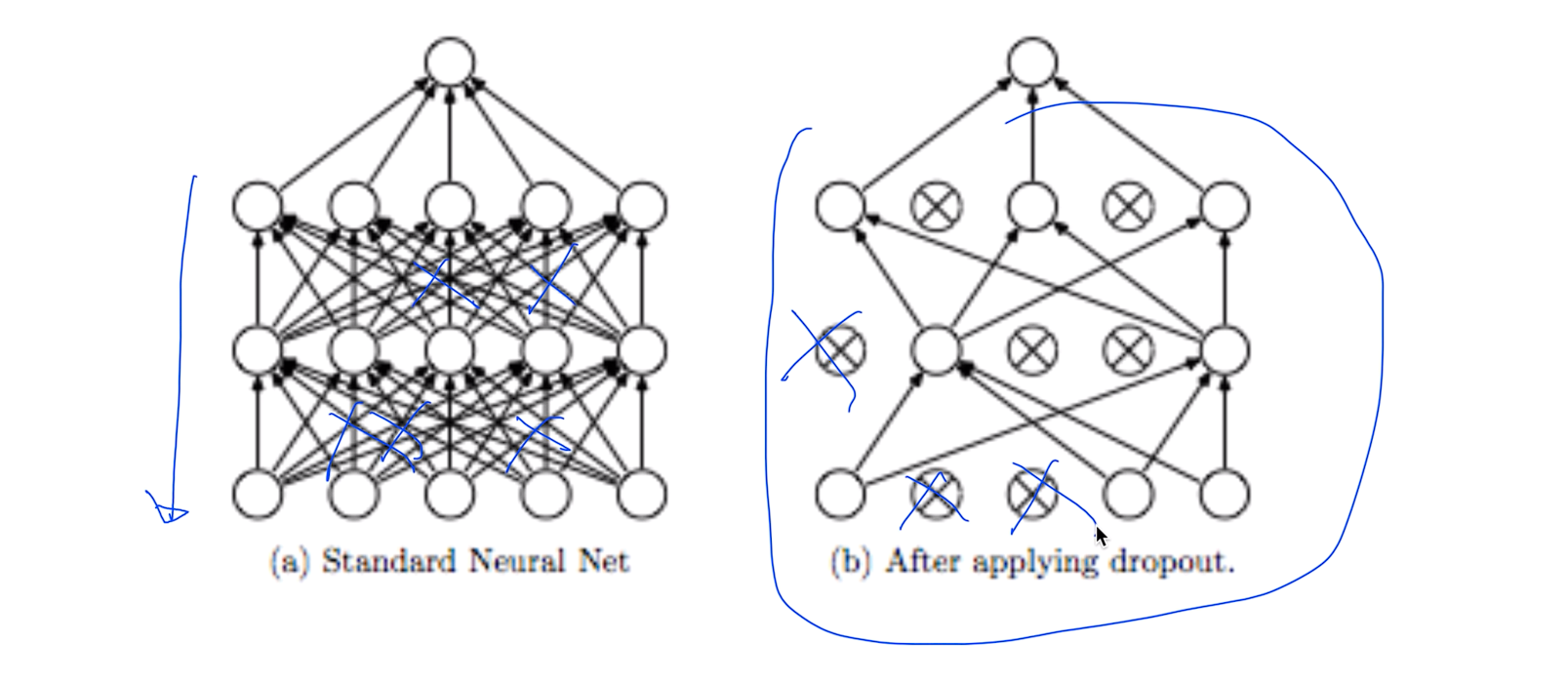
랜덤하게 몇개의 노드를 죽여보자 라고 얘기 나온게 Dropout
Waaaait a second... Howcould this possiblybe agood idea?
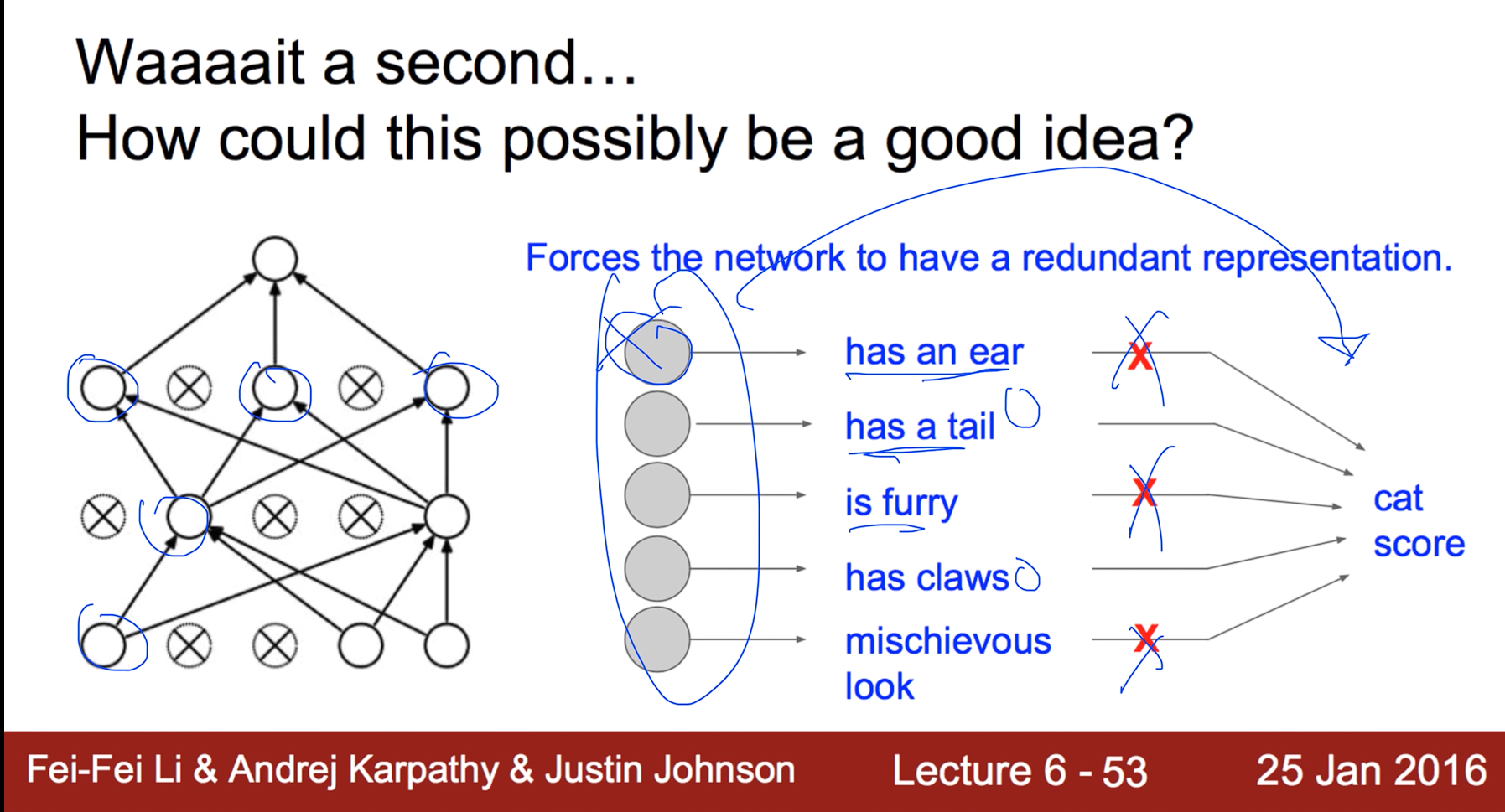
랜덤하게 노드를 죽여서 쉬게 만든 다음 학습시키고 마지막에 총동원해서 예측을 하니 더 잘된다
TensorFlow implementation

텐서플로우에서는 tf.nn.dropout로 랜덤하게 죽이는 메소드가 있다. 무조건 학습할때만 드랍아웃을 시키고 테스팅을 할땐 시키지말아야한다
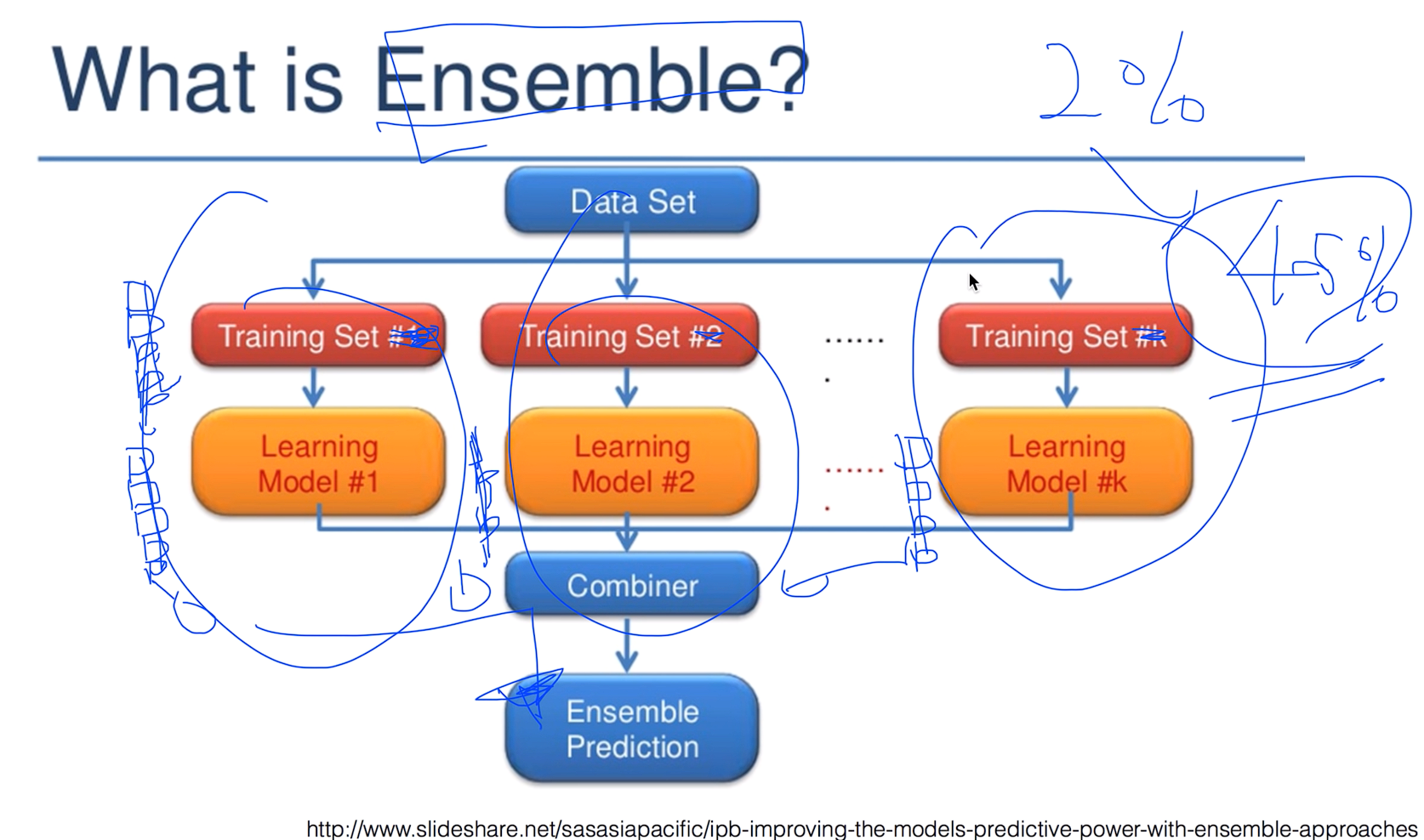
What is Ensemble?
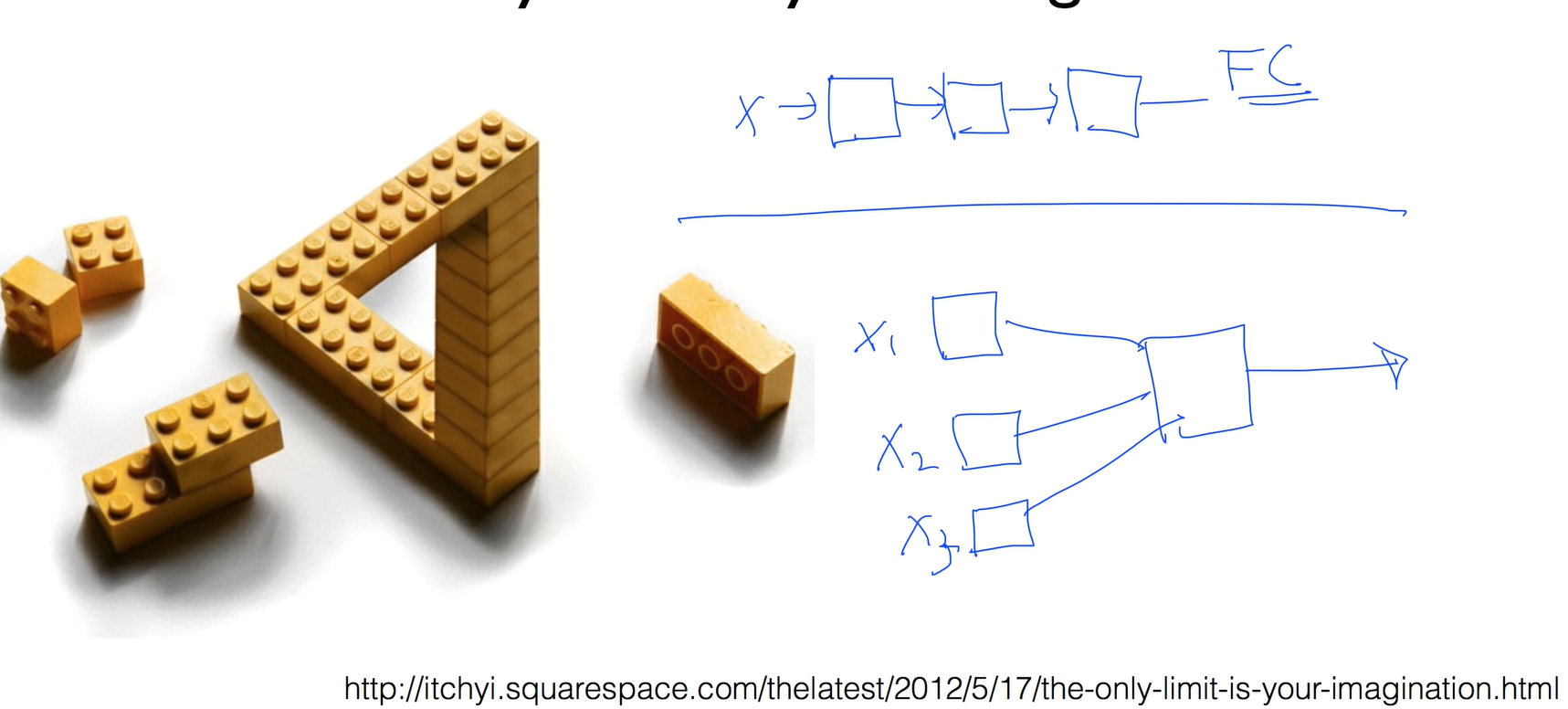
lec10-4: 레고처럼 넷트웍 모듈을 마음껏 쌓아 보자
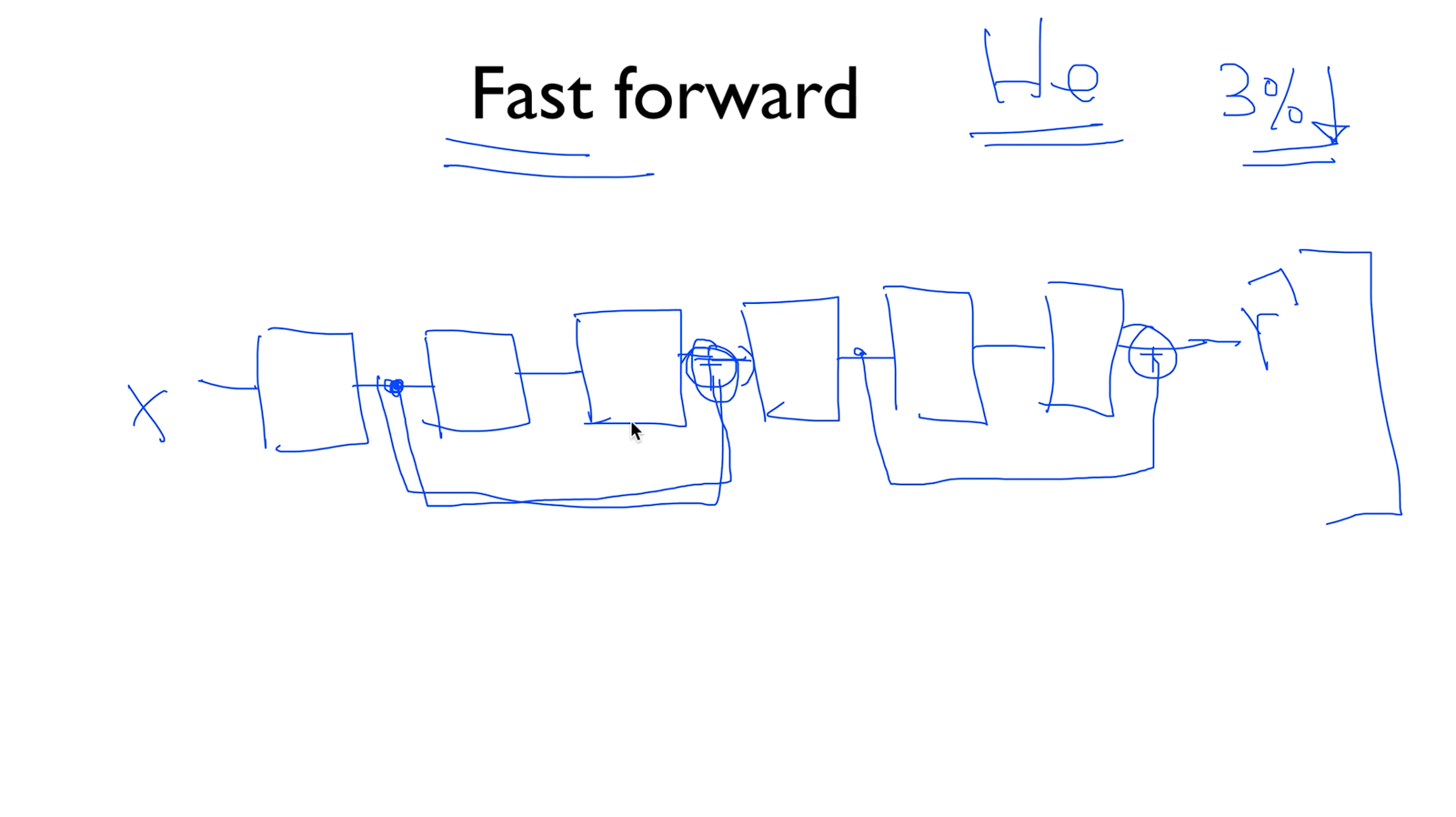
Fast forward
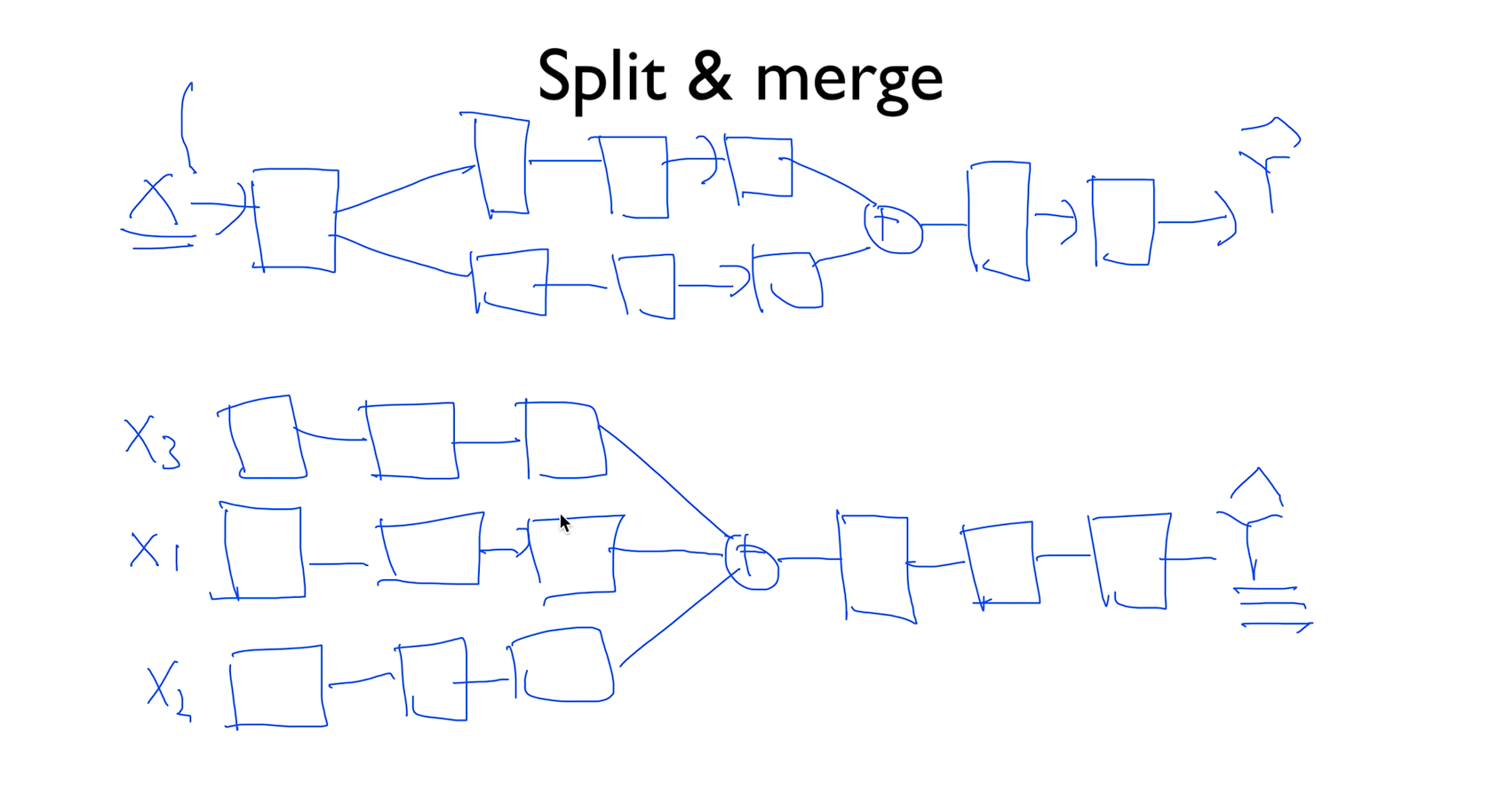
Split & merge
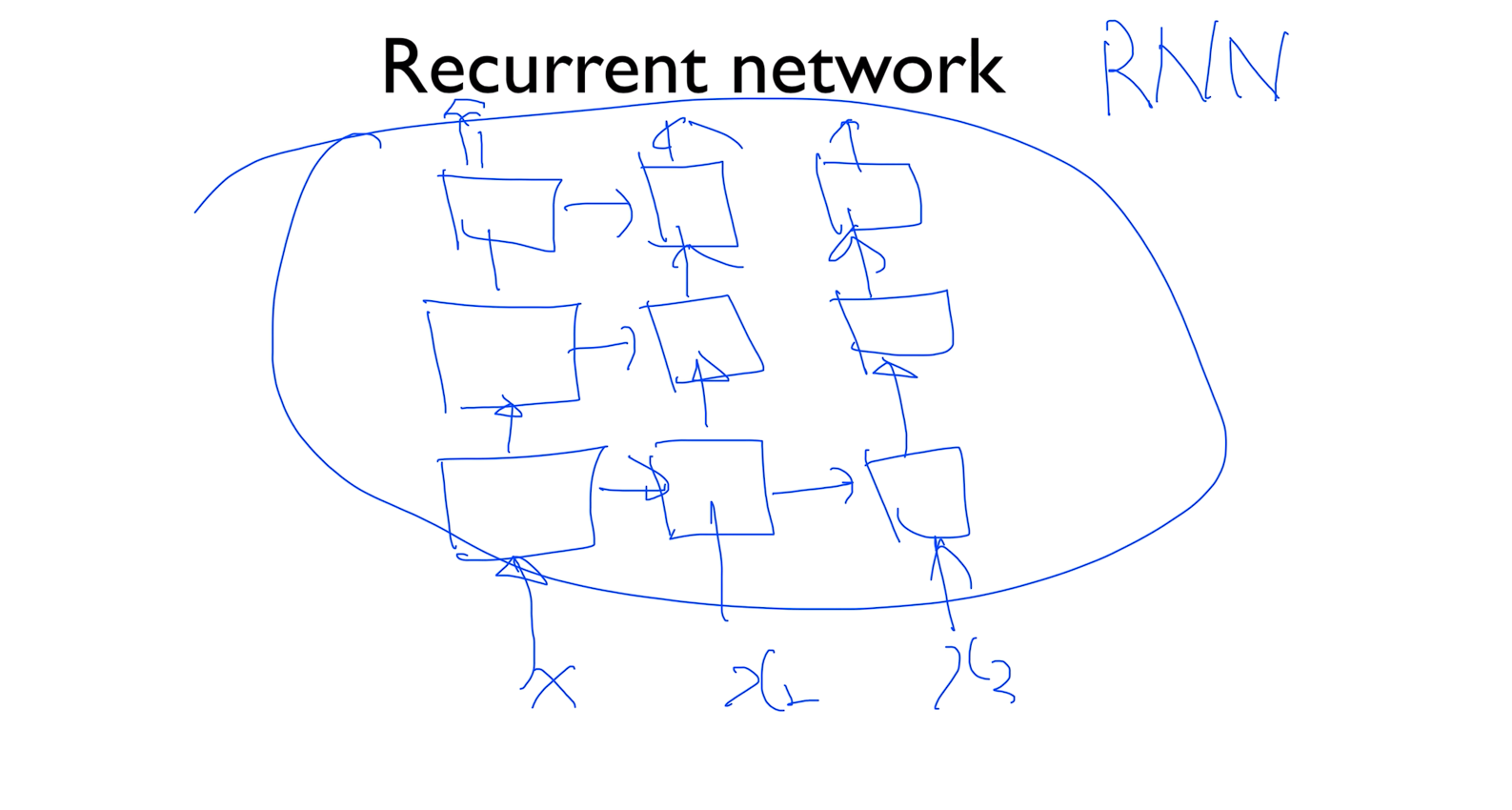
Recurrent network
'The only limit isyour imagination'

