MLOps 란?
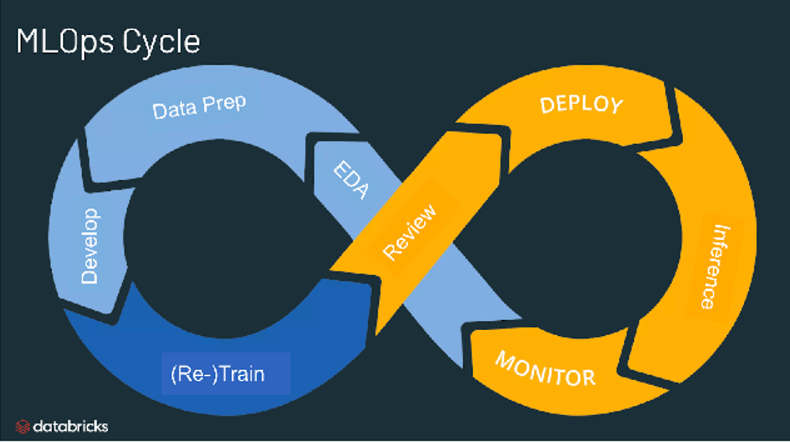
- 머신 러닝 모델을 프로덕션 환경에 배포하고 유지 관리하는 데 필요한 엔지니어링 관행
- 데이터 사이언 티스트, DevOps 엔지니어, IT 전문가의 협업 필요
| 용도 | • 머신 러닝 솔루션 제작 및 품질 관리 | • 모델 개발 및 프로덕션 속도 향상 | • 지속적인 통합 및 배포 (CI/CD) 관행 구현 |
|---|---|---|---|
| 필요성 | • 머신 러닝 프로세스의 복잡성을 관리 | • 여러 팀 간의 협업 및 전달 필요 | • 효율성, 확장성, 리스크 완화를 위한 엄격한 운영 원칙 필요 |
| 장점 | • 효율성: 모델 배포 및 프로덕션 속도 향상 | • 확장성: 수천 개의 모델 관리 및 모니터링 가능 | • 리스크 완화: 규제 준수 및 투명성 강화 |
1. 머신러닝 파이프라인에 대한 이해
eg) 헨리 포드의 자동차 조립을 제작시간을 12시간 -> 3시간 단축 시킴으로 자동차가 되중화 됨
1-1 머신러닝 프로젝트의 이점
파이프 라인을 통해 얻는 이점은 생산성 향상, 예측가능한 품질 장애, 대응능력 향상!!
1-2 머신러닝 파이프라인의 필요성
기술부채(미래오류들)를 줄이기 위한 노력 : 리팩토링, 종속성 제거, 단위테스트, API 강화, 미사용 코드 삭제, 문서화
예) 지금상황에선 최선의 코드였으나 먼훗날 버전업그레이드로 인해 제공되는 함수나 클래스가 지원되어 레거시한 코드로 바뀌는 등
하지만! 머신 러닝 시스템에서는 기존방식으로 기술 부채 제거가 쉽지않다!
2. 머신러닝 문제의 특징
2-1 쉬운/어려운 머신러닝 문제
쉬운 머신러닝 문제
- 데이터 변화가 천천히 일어남
- 재학습이 더 많은 데이터로 성능 개선 하는 경우 & 소프트웨어나 환경 변화하는 경우 일어남
라벨링이 수집한 데이터나 크라우드 소싱 기반으로 이뤄짐
어려운 머신러닝 문제
- 데이터 변화가 빠르게 일어남
- 모델 성능 저하로 인한 재학습이 일어남
라벨링이 직접적인 피드백 데이터를 기반으로 함(추천 시스템) => 서비스에서 얻은 정보를 입력 해줘야함.
2-2 머신러닝 프로그래밍 문제의 특징

- 데이터셋, 모델에서 이상치 탐색할 수 있어야 한다.
- 표준화된 방식으로 모델을 평가할 수 있어야 한다.
- 아티팩트(결과물)의 형상관리가 가능해야 한다.
2-3 개발 프로세스
- ML은 본질적으로 실험이기 때문에 다양한 시도(Feature, 알고리즘, 모델링, 파라미터)를 하며 빠르게 문제점을 찾아야 한다
- 이 때 무엇이 효과있었는지 없었는지 추적해서 관리 해야한다 이를 위해 코드 재사용을 최대한 가능케하여 재현성을 계속해서 유지하며 실험하는 것이 과제이다
2-4. 테스팅 방법 / 배포
- ML 시스템 테스트는 SW 시스템 테스트보다 어렵다.
잘동작하는 지 확인하는 게 명확하지 않다. - 배포는 오프라인에서 훈련된 모델 구축하는 것만큼 간단치 않다.
- 트리거 포인트는? ML 모델은 여러군데이다.
2-5. 프로덕션
- ML모델은 코딩뿐만 아니라 지속적으로 발전하는 데이터 프로파일 때문에 성능이 저하될 수있다.
- 따라서 데이터의 통계치를 추적하고 모델의 온라인 성능을 모니터링해 예상치를 벗어날 때 알림을 보내거나 롤백해야한다.
MLOps의 핵심 문제
3-1. 모델 학습/배포 트리거

3-2. 지속적 통합(CI) & 지속적 배포(CD) & 지속적 학습(CT)
- 지속적 통합(Continuous Integraion) CI
- 지속적 배포(Continuous Deployment) CD
- 두개 합쳐서 CI/CD 라고 부름 git-action 기능 사용
git-adction이란?
깃 커밋할때 클린코드등으로 제약을 걸 수있다
메서드는 매개변수 몇 개이상이냐?
함수는 4줄이하냐?
... 등으로 만들어서 커밋할때 해당 조건에 걸리면 디나이드 된다
4. MLOps 성숙도 레벨
출처 : mlopsLevel 설명 맛있다 ㅋㅋ 잘써놓음
4-1. 성숙도 레벨 0
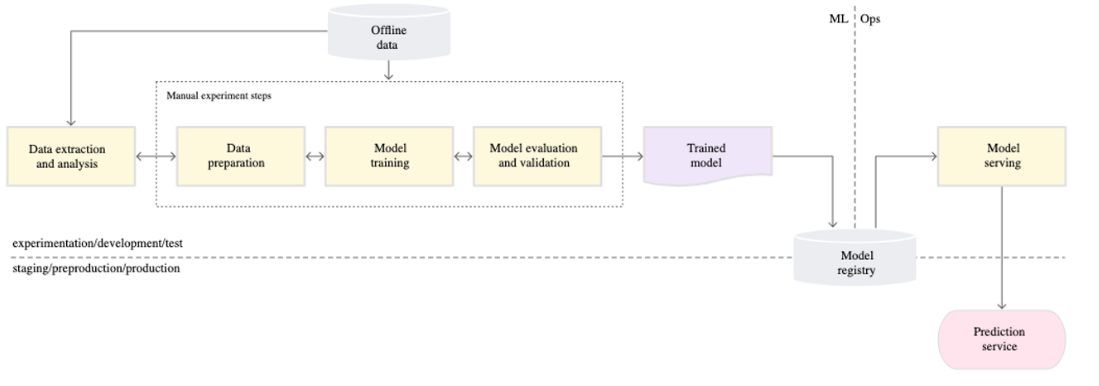
- 수동, 스크립트 중심, 대화식 프로세스 코랩으로 띡
- ML과 운영의 분리
- 드문 릴리즈(배포) 반복
- CI/CD 없음
- 배포는 예측 서비스를 의미
- Active 성능 모니터링 부족
4-2. 성숙도 레벨 1
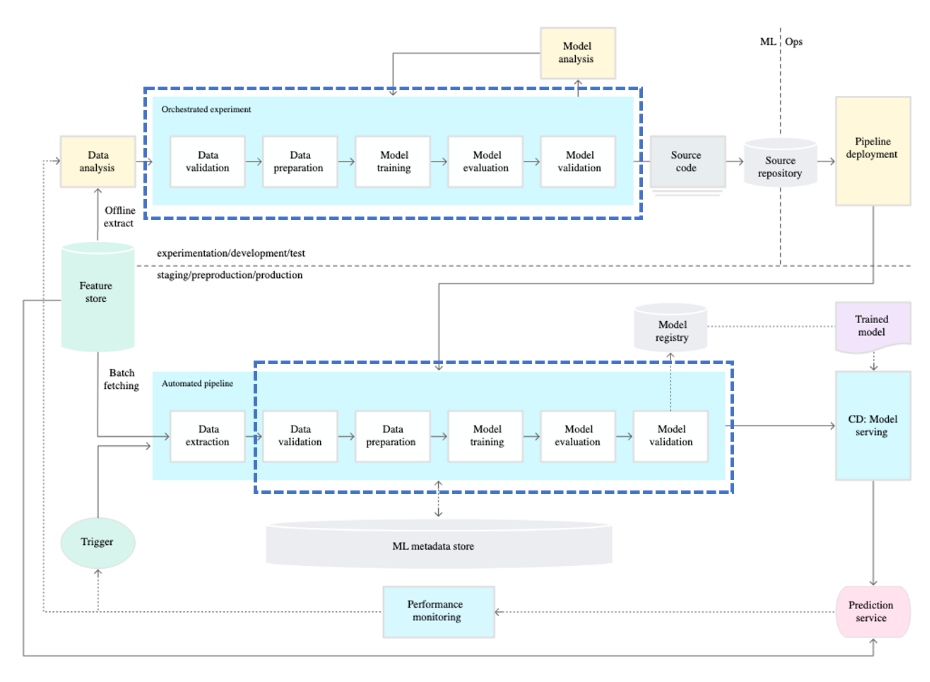
- 빠른 실험
- 실험 운영 환경의 조화
- 구성 요소 및 파이프라인을 위한 모듈화된 코드
- 지속적인 모델 제공
- 파이프라인 배포
4-3. 성숙도 레벨 2
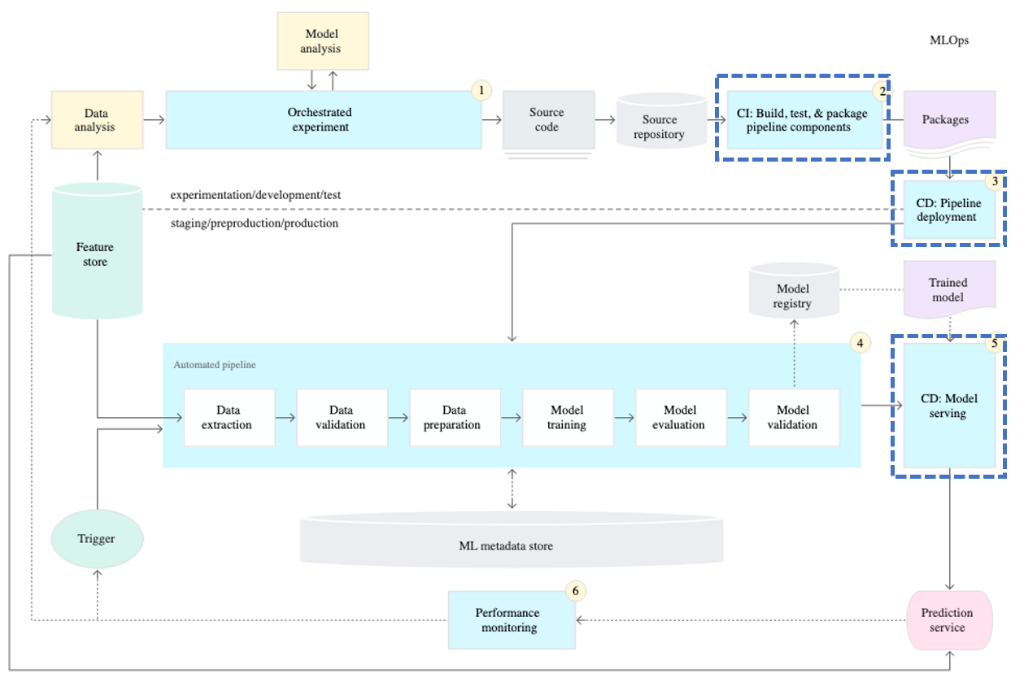
- Production에서 파이프라인을 빠르고 안정적으로 업데이트하려면 자동화된 CI/CD 시스템이 필요하다.
- 이 자동화된 CI/CD 시스템을 통해 데이터 과학자는 Feature Engineering, 모델 아키텍처 및 하이퍼 파라미터에 대한 새로운 아이디어를 신속하게 탐색할 수 있다.
5. 머신러닝 파이프라인 단계 래요
5-1. 머신러닝 프로젝트 이점
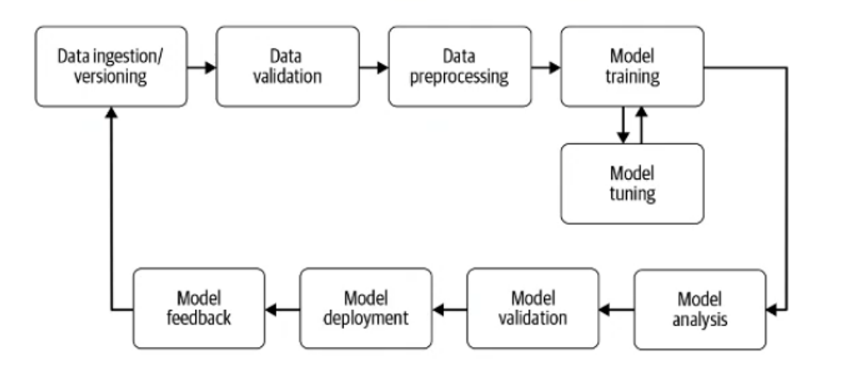
data validation : train data로만 검증하면 항상 100이니 validation set 을 통해 모델이 데이터를 실제로 학습을 잘하는지 필요한 test set이다
라벨링도 되어 있다
실제 상황은 모델이 보지않을 테니..
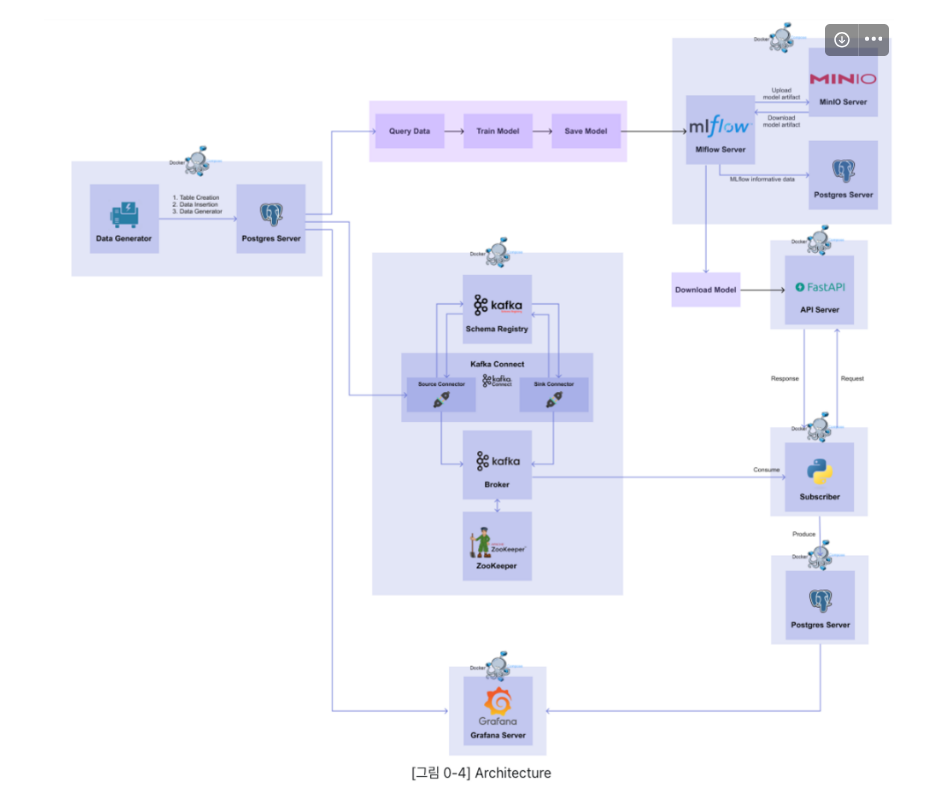

초보개발자