Data Drift
머신러닝을 학습시킬 때의 데이터와 현실에서의 데이터는 차이가 있다.
- 데이터를 학습하는 동안에도 현실의 데이터 분포가 바뀐다.
- 학습한 모델을 서비스하는 동안에도 현실의 데이터 분포가 바뀐다.
컨셉 드리프트(Concept Drift)
- 예측 모델이 학습한 대상 변수의 조건부 분포가 변경되는 경우
- 예를 들어, 소비자의 구매 패턴이 시간에 따라 변할 수 있으며, 이로 인해 과거에 학습된 패턴이 더 이상 유효하지 않게 될 수 있다.
데이터 분포 드리프트(Data Distribution Drift)
- 입력 데이터의 마진 분포가 변경되었지만, 조건부 분포는 동일하게 유지되는 경우
- 특정 입력 변수의 범위나 분포가 시간에 따라 변화하지만, 출력 변수와의 관계는 일정한 경우
라벨 드리프트(Label Drift)
- 출력 변수 자체의 분포가 변하는 현상
- 예를 들어, 질병의 발병률이나 고객의 선호도 같은 것이 시간에 따라 달라질 수 있다.
시즌성 드리프트(Seasonal Drift)
- 계절성 요인으로 인해 일시적으로 데이터의 분포가 변하는 경우
- 예를 들어, 날씨 변화에 따른 의류 판매량의 변동, 휴일 시즌에 따른 소비 패턴의 변화 등이 있다.
MINIO
- 고성능, 고가용성, 클라우드 네이티브 환경을 위해 설계된 오픈 소스 객체 스토리지 솔루션
- AWS S3(Simple Storage Service)의 클라우드 스토리지 서비스와 유사한 API를 제공.
- 분산 시스템 환경에서도 확장 가능하며, 개인 클라우드 또는 공개 클라우드 인프라에서의 배포를 지원.
특징
- 고성능: 멀티 코어 CPU에 최적화. 고성능의 스루풋과 낮은 지연 시간을 제공.
- 확장성: 클러스터링을 통해 확장할 수 있고 수십 페타바이트 규모의 데이터를 저장하고 관리 가능.
- 간편성: 간단한 설치와 설정으로 빠르게 배포가 가능. 컨테이너화하여 Docker, Kubernetes와 같은 오케스트레이션 시스템에서 운영할 수 있습니다.
- 호환성: AWS S3와 호환되는 API를 제공하여, S3를 사용하는 어플리케이션을 변경 없이 MinIO로 마이그레이션할 수 있는 경로를 제공.
- 다양한 워크로드 지원: AI/ML 워크로드, 데이터 분석, 백업 및 아카이빙, 웹사이트 호스팅 등 다양한 스토리지 요구 사항을 지원.
- 보안: 기본적으로 데이터 암호화를 지원. 클라이언트 측 암호화, 서버 측 암호화(SSE)를 모두 지원하며, TLS/SSL을 통한 데이터 전송 시 암호화도 지원합니다.
MinIO는 간단한 바이너리 파일로 배포되며 고가용성과 함께 객체 스토리지 솔루션을 제공하기 위해 설계된 라이브러리와 툴을 포함하고 있다.
기본 사용법
1. 도커 컨테이너로 실행
$ docker run -p 9000:9000 -p 9001:9001 --name minio1 \
-e "MINIO_ROOT_USER=<username>" \
-e "MINIO_ROOT_PASSWORD=<password>" \
-v /mnt/data:/data \
minio/minio server /data --console-address ":9001"-p 9000:9000: 호스트의 9000 포트를 컨테이너의 9000 포트에 매핑. MinIO는 기본적으로 9000 포트에서 서비스를 제공.-p 9001:9001: 호스트의 9001 포트를 컨테이너의 MinIO의 새로운 관리 콘솔 포트에 매핑.
이 콘솔은 최신 버전의 MinIO에서 관리 및 모니터링 인터페이스를 제공.--name minio1: 실행 중인 컨테이너의 이름을 minio1로 설정.-e "MINIO_ROOT_USER=<username>": MinIO의 접근 키(유저 ID) 환경 변수를 설정-e "MINIO_ROOT_PASSWORD=<password>": MinIO의 비밀 키(패스워드) 환경 변수를 설정.-v /mnt/data:/data: 호스트 시스템의 /mnt/data 디렉터리를 컨테이너의 /data 디렉터리에 볼륨으로 마운트. MinIO가 데이터를 저장하는 위치이다.minio/minio server /data: minio/minio 공식이미지를 통해 MinIO 서버를 시작하는 커맨드. /data 디렉터리를 사용하여 객체 데이터를 저장.--console-address ":9001": MinIO의 관리 콘솔을 포트 9001에서 사용할 수 있게 설정.
2. 키 발급
- 컨테이너 url로 접속 후 설정한 아이디, 비밀번호로 로그인한다.
- User/Access Keys 란에서 키 발급 후 json 파일 저장
{ "url":"http://localhost:9001/api/v1/service-account-credentials", "accessKey":"QDBS194oK7vbYR516knJ", "secretKey":"1bikmj3guo2z5Ej05NCsf9GZhhFAUQLXbjCrRZi1", "api":"s3v4", "path":"auto" }
- Access Key: 외부에서 사용할 때는 아이디, 패스워드 유출을 막기 위해 임시적인 액세스 키를 통해 접근한다.
3. Object Browser
Object Browser에 들어가여 버킷을 생성하면 다음과 같은 UI가 뜬다.
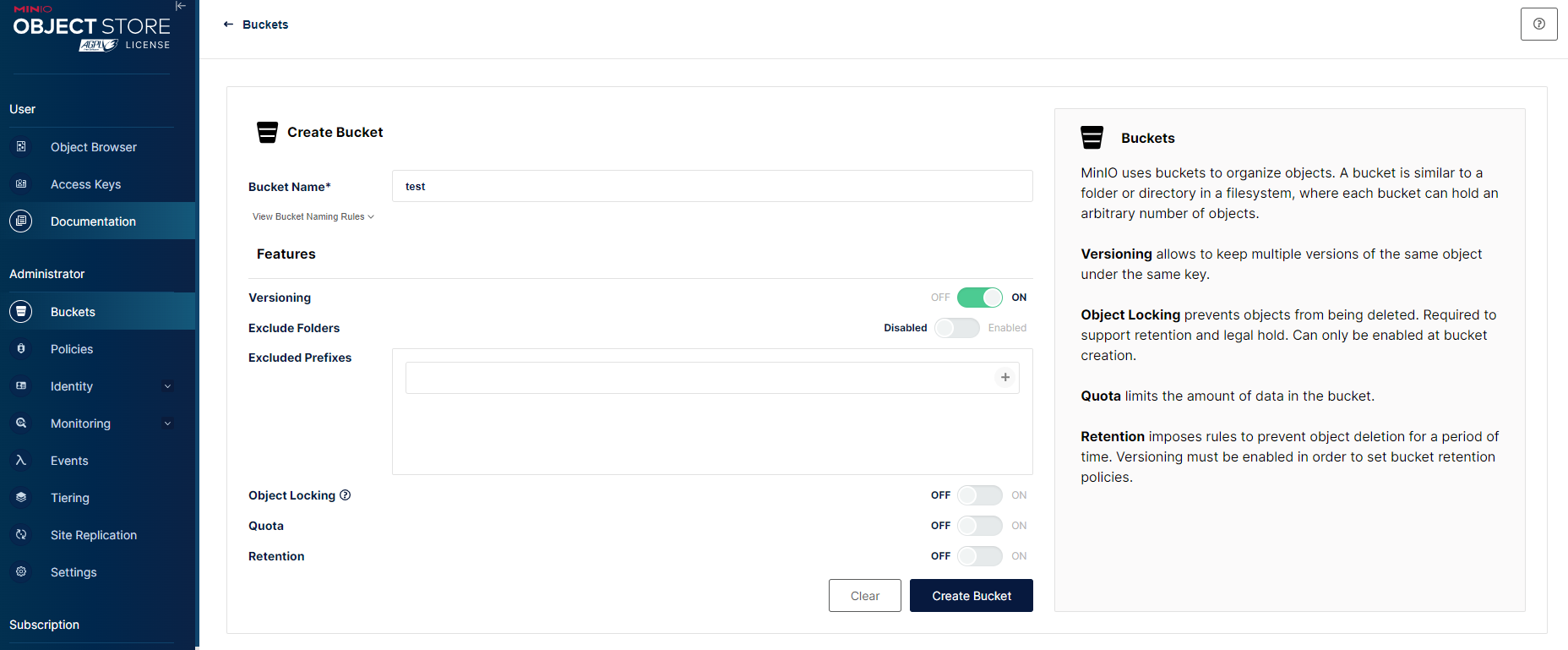
옆의 설명을 해석해보면,
- MinIO는 버킷을 사용하여 개체를 구성하고 파일시스템의 디렉토리 구조와 유사하다.
- Versioning: 이 기능을 통해 동일 객체의 여러 버전을 관리 가능하다.
- Locking: 객체 삭제 방지.
- Quota: 버킷의 데이터 양 제한
- Resuming: 이정 기간동안 객체 삭제 방지를 하기 위한 규칙 지정.
AWS S3와 호환되는만큼 아주 유사한 구조이다.
4. 데이터 업로드, 다운로드
업로드 코드
import pandas as pd
from sklearn.datasets import load_iris
# minio 패키지에서 Minio 클래스를 임포트. MinIO 서버와 상호작용하기 위한 클라이언트 인터페이스를 제공.
from minio import Minio
# minio 패키지에서 버전 관리 설정을 위한 VersioningConfig 클래스와 상수 ENABLED를 임포트.
from minio.versioningconfig import VersioningConfig, ENABLED
############# 데이터 준비 #############
# Iris 데이터셋을 로드하여 pandas 데이터프레임으로 변환.
iris = load_iris(as_frame=True)
# 데이터 프레임에서 feature 값(X)과 타겟 값(y)을 추출.
X, y = iris["data"], iris["target"]
# Features 데이터프레임(X)과 target 시리즈(y)를 하나의 데이터프레임으로 결합.
data = pd.concat([X, y], axis="columns")
# 데이터프레임에서 무작위로 100개의 샘플을 선택하고 'iris.csv' 파일로 저장. 인덱스는 저장X.
data.sample(100).to_csv("iris.csv", index=None)
############# minio클라이언트 #############
# MinIO 클라이언트 객체를 생성. MinIO 서버의 URL과 접근 키, 비밀 키를 설정하고, 보안 연결(HTTPS)을 사용하지 않음.
url = "0.0.0.0:9000"
access_key = "minio"
secret_key = "miniostorage"
client = Minio(url, access_key=access_key, secret_key=secret_key, secure=False)
############# 업로드 코드 #############
# MinIO의 버킷 'raw-data'가 존재하는지 확인하고, 없으면 새로 생성.
bucket_name = "raw-data"
object_name = "iris"
if not client.bucket_exists(bucket_name):
client.make_bucket(bucket_name)
# 버킷에 대한 버전 관리를 활성화.
config = client.set_bucket_versioning(bucket_name, VersioningConfig(ENABLED))
# 'iris.csv' 파일을 'raw-data' 버킷의 'iris' 오브젝트 이름으로 MinIO 서버에 업로드.
client.fput_object(bucket_name, object_name, "iris.csv")다운로드 코드
object_stat = client.stat_object(bucket_name, object_name)
print(object_stat.version_id)
client.fget_object(bucket_name, object_name, file_path="download_data.csv")- 클라이언트 선언은 업로드 부분과 같다.
MINIO, MLflow 기본 구조
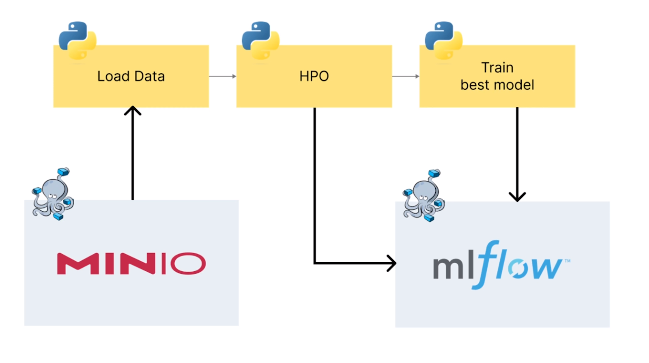
import uuid
import mlflow
import optuna
import pandas as pd
from minio import Minio
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
UNIQUE_PREFIX = str(uuid.uuid4())[:8]
BUCKET_NAME = "raw-data"
OBJECT_NAME = "iris"
# 데이터를 MinIO에서 다운로드하는 함수
def download_data():
# MinIO 클라이언트 설정
url = "0.0.0.0:9000"
access_key = "minio"
secret_key = "miniostorage"
client = Minio(url, access_key=access_key, secret_key=secret_key, secure=False)
# MinIO에서 데이터 오브젝트의 메타데이터를 가져오고, 데이터의 버전 ID를 추출
object_stat = client.stat_object(BUCKET_NAME, OBJECT_NAME)
data_version_id = object_stat.version_id
# MinIO에서 데이터 파일을 로컬 시스템으로 다운로드
client.fget_object(BUCKET_NAME, OBJECT_NAME, file_path="download_data.csv")
# 데이터 버전 ID 반환
return data_version_id
# 데이터 로딩과 전처리를 위한 함수
def load_data():
# 다운로드 함수를 호출하여 데이터와 데이터의 버전 ID를 가져옴
data_version_id = download_data()
# CSV 파일을 데이터프레임으로 로딩
df = pd.read_csv("download_data.csv")
# 독립변수와 종속변수를 분리하여 X와 y에 할당
X, y = df.drop(columns=["target"]), df["target"]
# 데이터와 레이블, 버전 ID를 포함하는 딕셔너리 생성
data_dict = {"data": X, "target": y, "version_id": data_version_id}
return data_dict
def objective(trial):
.
.
#
# load data
#
data_dict = load_data()
mlflow.log_param("bucket_name", BUCKET_NAME)
mlflow.log_param("object_name", OBJECT_NAME)
mlflow.log_param("version_id", data_dict["version_id"])
X, y = data_dict["data"], data_dict["target"]
.
.
def train_best_model(params):...
if __name__ == "__main__":
# MLflow 실험 설정
experiment_name = "hpo-tutorial"
mlflow.set_tracking_uri("http://0.0.0.0:5001")
mlflow.set_experiment(experiment_name)
# Optuna 실험 설정, 랜덤 샘플러 사용
sampler = optuna.samplers.RandomSampler(seed=2024)
# Optuna 스터디 생성
study = optuna.create_study(sampler=sampler, study_name=experiment_name, direction="maximize")
# 스터디 최적화 실행
study.optimize(objective, n_trials=5)
# 최적의 하이퍼파라미터를 가진 모델을 훈련
best_params = study.best_params
best_clf = train_best_model(best_params)
공부!