
머신러닝에서 말하는 실험
주어진 데이터를 이용해 모델을 학습 후 모델을 평가하는 것
- 실험관리: 수행한 실험들을 기록하고 관리하는 것
실험 관리를 하는 이유
- 어제 실행한 코드의 학습이 잘 완료되었나?
- 가장 성능이 좋았던 모델의 파라미터는?
실험 관리의 목표
- 실험 중 발생하는 정보
- 실험을 재현하기 위해 필요한 정보 기록
- 데이터, 패키지, 코드, 파라미터, 정확도 등을 하나의 표로 관리
관리 도구

Tansorboard
- Local에서 쉽게 설치 가능
- Tensorflow에 친화적인 기능 존재
MLflow
- 자체 서버 구축이 쉬움
- 여러 실험의 평가 지표를 시각화하여 기록
WandB
- SaaS 서비스
- 다양한 시각화 기능 존재
MLflow
[MLflow Dockerfile]
FROM amd64/python:3.9-slim
RUN pip install -U pip && pip install mlflow
CMD ["mlflow", "server", "--host", "0.0.0.0"]포트 주의!
- mlflow의 디폴트 포트번호는 5000번이다.
- 컨테이너 내부에서의 mlflow 포트번호이기 때문에 컨테이너 포트와의 구별에 유의
$ docker build -t mlflow-server .
$ docker run -p 5001:5000 mlflow-server기본 순서
-
mlflow 환경설정
mlflow.set_tracking_uri("mlflow 서버") mlflow.set_experiment("설정") # 위 예시를 기준으로 하면 mlflow.set_tracking_uri("http//localhost:5001") mlflow.set_experiment("tutorial") -
파라미터 로깅 (param, params 구별)
# 방법1. 하나의 파라미터 등록 mlflow.log_param("my_param", 1) # 방법2. 딕셔너리를 통해 여러 파라미터 등록 params = {"my_param1", 1, "my_param2",5} mlflow.log_params(params) -
메트릭 로깅 (metric, metrics 구별)
mlflow.log_metric("my_metric", 0.1) # 파라미터와 마찬가지로 여러 메트릭을 딕셔너리로 설정 가능 metrics = {"my_metric1":0.3, "my_metric2":0.4} mlflow.log_metrics(metrics) # loss와 같은 히스토리가 필요한 경우: step 파라미터 활용 mlflow.log_metric("history", 0.1, step=1) mlflow.log_metric("history", 0.2, step=2) mlflow.log_metric("history", 0.25, step=3)
MLflow run
Run
- 하나의 실험을 묶는 단위
- 실험이 종료된 경우 명시적으로 종료를 선언해주어야 한다.
- 종료를 선언하지 않으면 같은 실험으로 간주
- Run 시작 파라미터 로깅 매트릭 로깅 Run 종료
주석과 함께 mlflow 기초 구성 코드를 정리해보면,
import mlflow
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
#
# set mlflow
#
mlflow.set_tracking_uri("http://localhost:5001") # 위에서 사용하고있는 mlflow 서버와 포트
mlflow.set_experiment("tutorial")
with mlflow.start_run():
#
# log parameter: 파라미터를 설정한다.
#
params = {"n_estimators": 100, "max_depth": 5}
mlflow.log_params(params)
#
# load data: 훈련, 테스트 데이터를 로드한다. (현재는 사이킷런 데이터셋)
#
iris = load_iris(as_frame=True)
X, y = iris["data"], iris["target"]
X_train, X_valid, y_train, y_valid = train_test_split(
X, y, test_size=0.3, random_state=2024
)
#
# train model: 모델 트레이닝
#
clf = RandomForestClassifier(
n_estimators=params["n_estimators"],
max_depth=params["max_depth"],
random_state=2024,
)
clf.fit(X_train, y_train)
#
# evaluate train model: 모델 평가
#
y_pred = clf.predict(X_valid)
acc_score = accuracy_score(y_valid, y_pred)
#
# log metrics: 메트릭 기록
#
print("Accuracy score is {:.4f}".format(acc_score))
mlflow.log_metric("accuracy", acc_score)
mlflow 서버에 접속해보면 tutorial 실험이 생겨있고
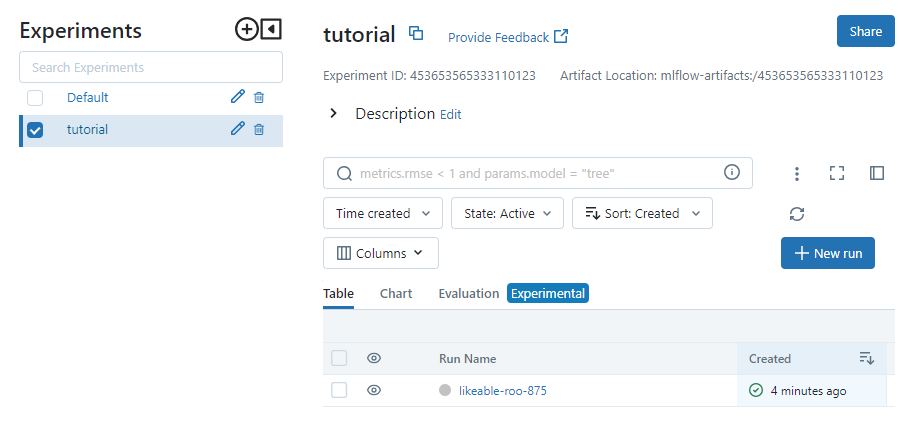
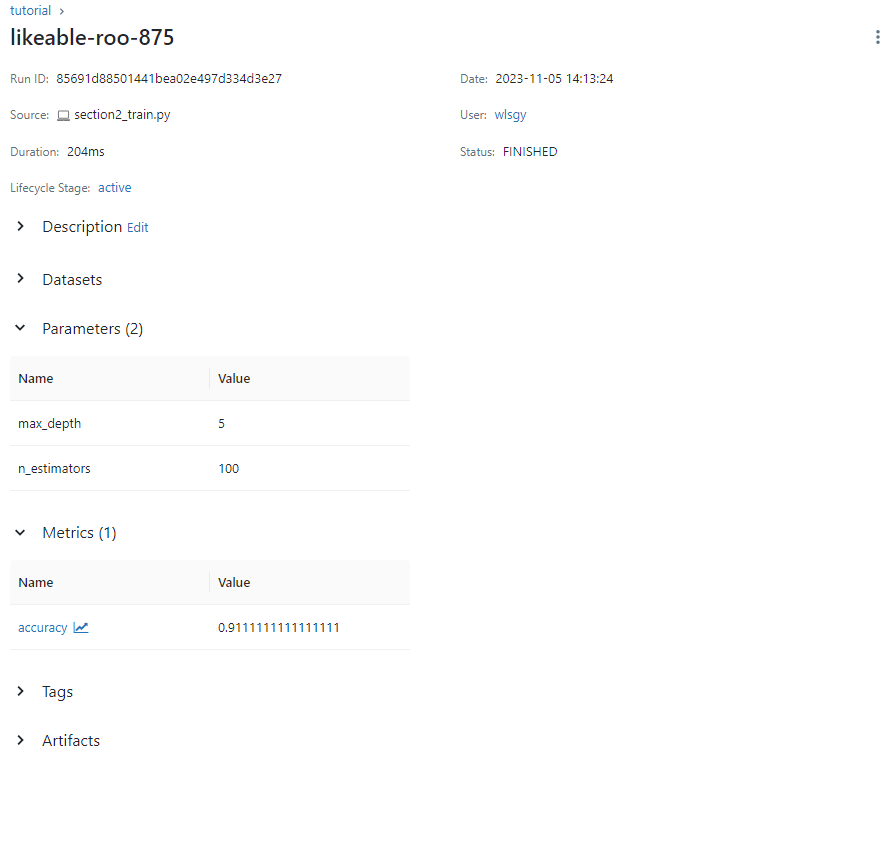
들어가보면 사용한 설정들이 정리되어 있는 것을 볼 수 있다.
HPO (HyperParameter Optimization)
- HPO: 주어진 목적 함수를 최대/최소화 하는 최적의 파라미터를 탐색하는 행위
- 주요 최대화 목적 함수: Accuracy, F1-Score, ...
- 주요 최소화 목적 함수: MSE(Mean squred error), MAE(Mean absolute error), ...
- 다양한 ML모델에 맞는 최적 파라미터가 모두 다르고 목적에 따라서도 바뀔 수 있기 때문
HPO Framework
효율적인 HPO를 위한 조건
- 적절한 파라미터 후보군 추출: OPTUNA, RAY
- 컴퓨팅 자원의 효율적 사용: RAY
OPTUNA, RAY의 간단한 동작 과정
- OPTUNA에서 적절한 파라미터 후보군 추출
- RAY에서 파라미터 후보군을 컴퓨팅 서버에 밸런싱하여 전달
- 결과값을 OPTUNA에 전달하여 이를 바탕으로 OPTUNA에서 새로운 파라미터 후보군 추출
- 최적의 결과가 나오기까지 1~3 반복
OPTUNA의 역할에 RAY를 사용하여 RAY만 사용하는 것도 충분히 가능하다.
단 RAY는 서버들을 묶어 클러스터로 관리하기 때문에 숙련도가 필요
만약 컴퓨팅 서버가 단일 서버라면 밸런싱의 역할이 필요없고 OPTUNA또한 자원을 효율적으로 사용하기 떄문에 OPTUNA 만으로도 충분하다.
OPTUNA
Objective 함수 작성 study생성 파라미터 탐색
import optuna
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
def objective(trial):
# suggest_int(파라미터명, 최소, 최대, 스텝값(디폴트:1)): int값을 추천
trial.suggest_int("n_estimators", 100, 1000, step=100)
trial.suggest_int("max_depth", 3, 10)
########### load data ############
iris = load_iris(as_frame=True)
X, y = iris["data"], iris["target"]
X_train, X_valid, y_train, y_valid = train_test_split(
X, y, test_size=0.3, random_state=2024
)
########### train model ############
clf = RandomForestClassifier(
n_estimators=trial.params["n_estimators"],
max_depth=trial.params["max_depth"],
random_state=2024,
)
clf.fit(X_train, y_train)
########### evaluate train model ############
y_pred = clf.predict(X_valid)
acc_score = accuracy_score(y_valid, y_pred)
return acc_score
if __name__ == "__main__":
########## study ##########
# 샘플러 작성을 통해 시드값 설정
sampler = optuna.samplers.RandomSampler(seed=2024)
study = optuna.create_study(
sampler=sampler, study_name="hpo-tutorial", direction="maximize"
)
########## optimize ##########
study.optimize(objective, n_trials=5)[실행결과]
[I 2023-11-05 15:18:06,762] A new study created in memory with name: hpo-tutorial
[I 2023-11-05 15:18:08,002] Trial 0 finished with value: 0.8888888888888888 and parameters: {'n_estimators': 600, 'max_depth': 8}. Best is trial 0 with value: 0.8888888888888888.
[I 2023-11-05 15:18:08,240] Trial 1 finished with value: 0.9111111111111111 and parameters: {'n_estimators': 200, 'max_depth': 3}. Best is trial 1 with value: 0.9111111111111111.
[I 2023-11-05 15:18:08,586] Trial 2 finished with value: 0.9111111111111111 and parameters: {'n_estimators': 300, 'max_depth': 3}. Best is trial 1 with value: 0.9111111111111111.
[I 2023-11-05 15:18:09,466] Trial 3 finished with value: 0.9111111111111111 and parameters: {'n_estimators': 800, 'max_depth': 8}. Best is trial 1 with value: 0.9111111111111111.
[I 2023-11-05 15:18:10,010] Trial 4 finished with value: 0.8888888888888888 and parameters: {'n_estimators': 500, 'max_depth': 6}. Best is trial 1 with value: 0.9111111111111111.MLflow + OPTUNA
import uuid
import mlflow
import optuna
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# mlflow에 기록된 run들을 구별하기 위한 이름 설정
UNIQUE_PREFIX = str(uuid.uuid4())[:8]
def objective(trial):
#
# suggest new parameter
#
trial.suggest_int("n_estimators", 100, 1000, step=100)
trial.suggest_int("max_depth", 3, 10)
#
# mlflow logging run name
#
run_name = f"{UNIQUE_PREFIX}-{trial.number}"
with mlflow.start_run(run_name=run_name):
#
# log params
#
mlflow.log_params(trial.params) # trial에 설정된 파라미터를 등록한다.
#
# load data
#
iris = load_iris(as_frame=True)
X, y = iris["data"], iris["target"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=2024
)
#
# train model
#
clf = RandomForestClassifier(
n_estimators=trial.params["n_estimators"],
max_depth=trial.params["max_depth"],
random_state=2024,
)
clf.fit(X_train, y_train)
#
# evaluate train model
#
y_pred = clf.predict(X_test)
acc_score = accuracy_score(y_test, y_pred)
mlflow.log_metric("accuracy", acc_score)
return acc_score
def train_best_model(params):
run_name = f"{UNIQUE_PREFIX}-best-model"
with mlflow.start_run(run_name=run_name):
#
# log parameter
#
mlflow.log_params(params)
#
# load data
#
iris = load_iris(as_frame=True)
X, y = iris["data"], iris["target"]
#
# train model
#
clf = RandomForestClassifier(
n_estimators=params["n_estimators"],
max_depth=params["max_depth"],
random_state=2024,
)
clf.fit(X, y)
return clf
if __name__ == "__main__":
experiment_name = "hpo-tutorial"
mlflow.set_tracking_uri("http://localhost:5001")
mlflow.set_experiment(experiment_name)
sampler = optuna.samplers.RandomSampler(seed=2024)
study = optuna.create_study(
sampler=sampler, study_name=experiment_name, direction="maximize"
)
study.optimize(objective, n_trials=5)
# get best_param
best_params = study.best_params
best_clf = train_best_model(best_params)- mlflow에는 run이름으로 기록들이 구분되기 때문에 처음에 이름을 지정해준다. (예시에선 uuid로 임의 생성)
trial.suggest_int로 파라미터를 설정하고 이후엔trial.params를 이용하여 mlflow의 파라미터를 설정한다.

공부!