
본 스터디는 신백균 저 ⟦MustHave 머신러닝•딥러닝 문제해결 전략⟧ 골든래빗(Golden Rabbit) 출판사의 책을 기반으로 진행하고 있습니다.
저작권 문제 시 댓글 남겨주시면 감사드리겠습니다. 😊
1. 분류와 회귀
- 예측하려는 타깃값이
범주형 데이터면분류문제,수치형 데이터면회귀문제
1-1) 분류
- 주어진 피처에 따라 어떤 대상을 정해진(유한한) 범주(타깃값)에 구분해 넣는 작업
(ex. 개와 고양이 구분, 스팸메일과 일반 메일 구분, 질병 검사 결과가 양성인지 음성인지 등)
→ 타깃값이 두 개 분류는이진분류, 세 개 이상 분류는다중분류
1-2) 회귀
- 자연현상이나 사회 현상에서 변수 사이 관계
(ex. 학습 시간이 시험 성적에 미치는 영향, 수면의 질이 건강에 미치는 영향, 공장의 재고 수준이 회사 이익에 미치는 영향 등)
→ 영향을 미치는 변수를독립변수, 영향을 받는 변수를종속변수
- 회귀 : 독립변수와 종속변수 간 관계를 모델링 하는 방법
→ 독립변수 X, 종속변수 Y(단순 선형 회귀)
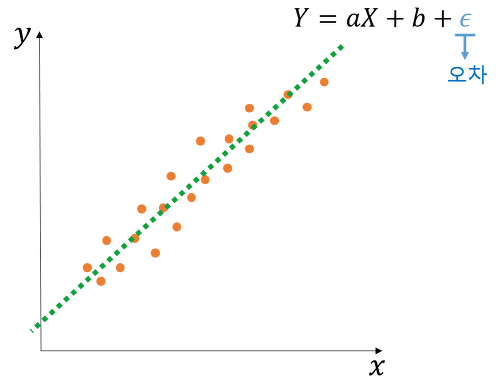
- 독립변수(피처)와 종속변수(타깃값) 사이 관계를 기반으로 회귀 모델을 훈련해
최적의 회귀계수를 찾아야 함
✅ 회귀 평가지표
- 최적의 회귀계수를 구하려면, 예측값과 실젯값의 차이(오차)를 최소화해야 함 ⇒ '데이터에 회귀 모델이 잘 들어맞는다.' 라는 뜻
- 오차가 0이면 회귀 모델이 정확히 일치하지만, 과대적합된 결과임을 의심해봐야 함
- 회귀 평가지표 값은 작을수록 모델 성능이 좋음
⬇️⬇️⬇️⬇️⬇️ 자주 쓰는 회귀 평가지표
- MAE(Mean Absolute Error) 평균 절대 오차
: 실제 타깃값과 예측 타깃값 차의 절댓값 평균
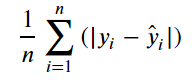
- MSE(Mean Squared Error) 평균 제곱 오차
: 실제 타깃밗과 예측 타깃값 차의 제곱의 평균
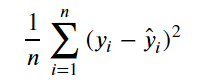
- RMSE(Root Mean Squared Error) 평균 제곱근 오차
: MSE에 제곱근을 취한 값
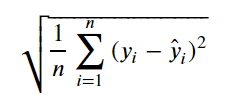
-
MSLE(Mean Squrared Log Error)
: MSE에서 타깃값에 로그를 취한 값 -
RMSLE(Root Mean Squrared Log Error)
: MSLE에 제곱근을 취한 값
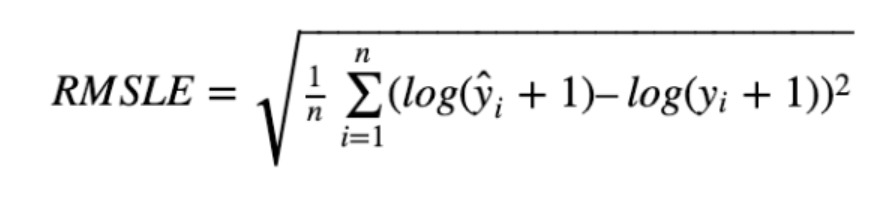
- R² 결정계수
: 예측 타깃값의 분산/실제 타깃값의 분산
** MSLE와 RMSLE에서 log(y)가 아닌 log(y+1)을 사용한 이유는 로그값이 음의 무한대(-∞)가 되는 상황 방지하기 위함
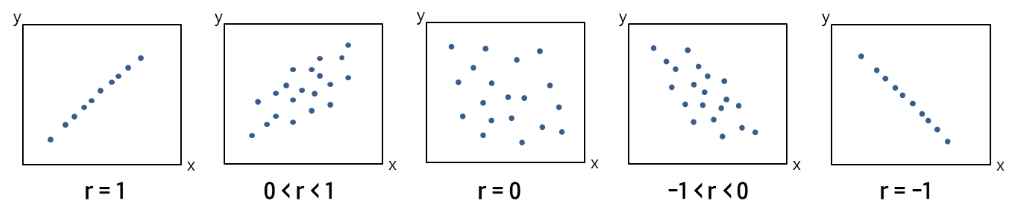
✅ 상관계수
- 피어슨 상관계수
: 선형 상관관계의 강도와 방향을 나타내며, -1~1사이의 값을 가짐
2. 분류 평가지표
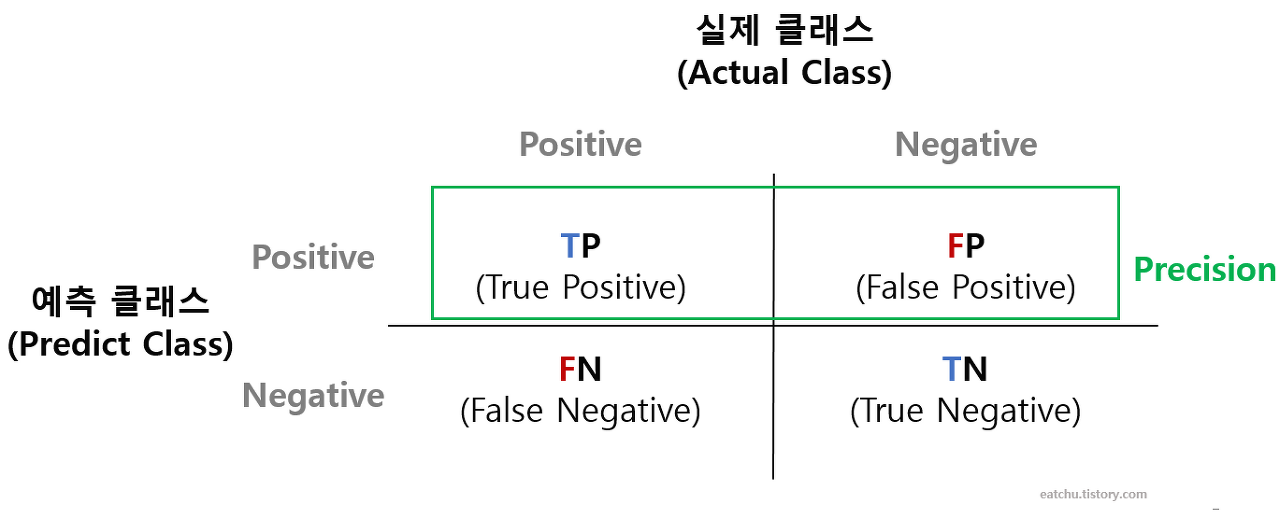
2-1) 오차행렬
- 실제 타깃값과 예측 타깃값이 어떻게 매칭되는지 보여줌
Tip) '참(T)'오로 시작하면 올바로 예측한 것, '거짓(F)'으로 시작하면 틀린 것
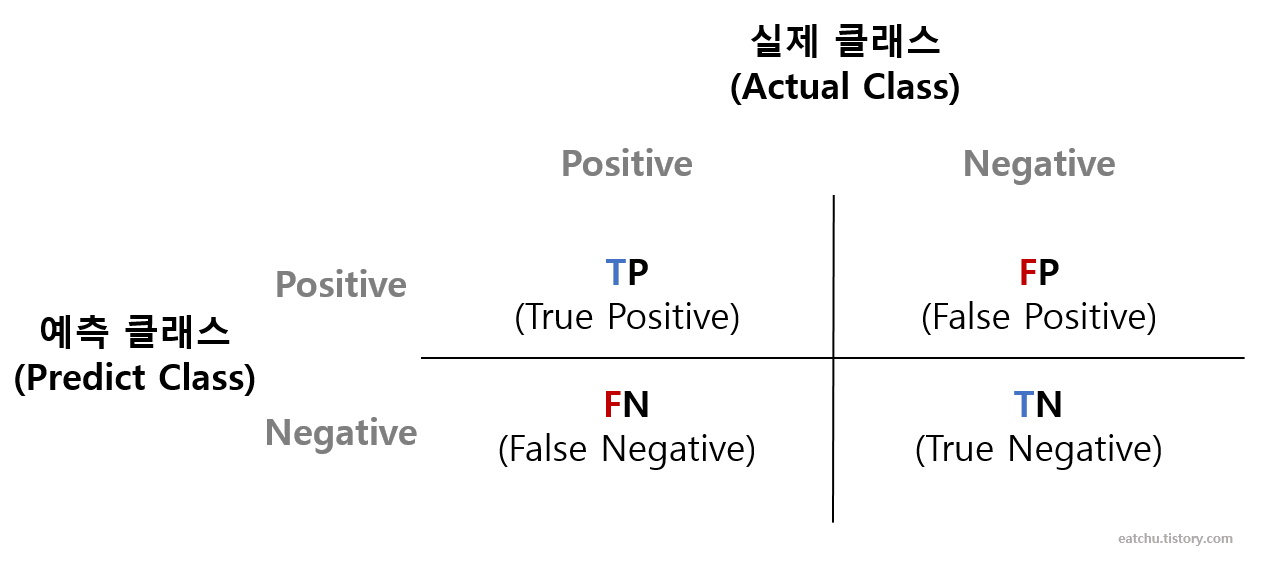
- 오차행렬을 활용한 주요 평가지표는 정확도, 정밀도, 재현율, F1 점수가 있으며
모두 값이 클수록좋은 지표
✅ 정확도
- 정확도(Accuracy) = (TN + TP) / (TN + FP + FN + TP)
: 불균형한 데이터를 다룰 때 모델의 신뢰도를 떨어뜨릴 수 있음 → 평가지표로 잘 쓰이지 않음
✅ 정밀도
- 정밀도(Precision) = TP / (TP + FP)
: 양성 예측의 정확도, 양성이라고 예측한 값(TP + FP) 중 실제 양성인 값(TP)의 비율
ex) 실제 스팸 메일(양성)을 일반 메일(음성)로 분류하게 되면 사용자가 불편함을 느끼겠지만 일반 메일을 스팸 메일로 분류할 경우 필요한 메일을 받지 못하는 업무상 차질이 생길 수 있음
✅ 재현율
- 재현율(Recall) = TP / (TP + FN)
: 민감도 또는 참 양성 비율(TPR), 실제 양성 값(TP + FN) 중 양성으로 잘 예측한 값(TP)의 비율
ex) 암환자를 음성이 아닌 양성으로 잘못 판단했을 경우 오류의 대가는 재검사를 하는 수준의 비용이지만 양성인 환자를 음성으로 잘못 판단했을 경우 오류의 대가는 생명임
✅ F1 점수
- F1 점수
: 정밀도와 재현율을 조합한 평가지표
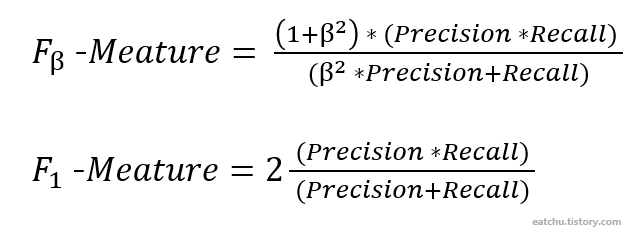
2-2) 로그 손실
- 분류 문제에 타깃값을 확률로 예측할 때 사용하는 평가지표 → 값이 작을수록 좋은 지표

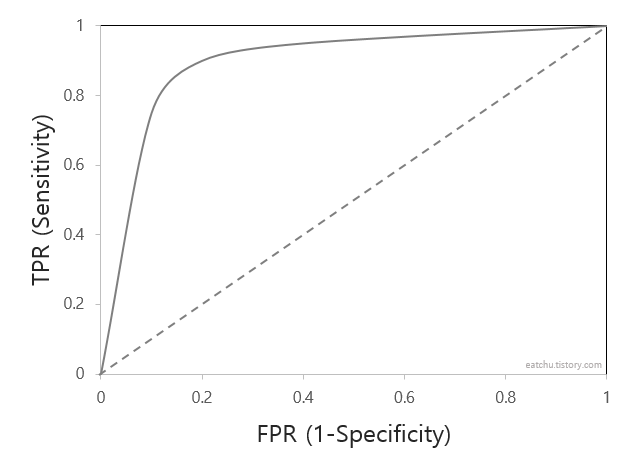
2-3) ROC 곡선과 AUC
- ROC(Receiver Operating Characteristic)
: 참 양성비율(TPR)에 대한 거짓 양성비율(FPR) 곡선
- TPR = TP / (TP + FN) : 실제 Positive 중에 모델이 Positive로 잘 예측한 비율
- FPR = FP / (TN + FP) = 1 - (TN / (TN + FP))
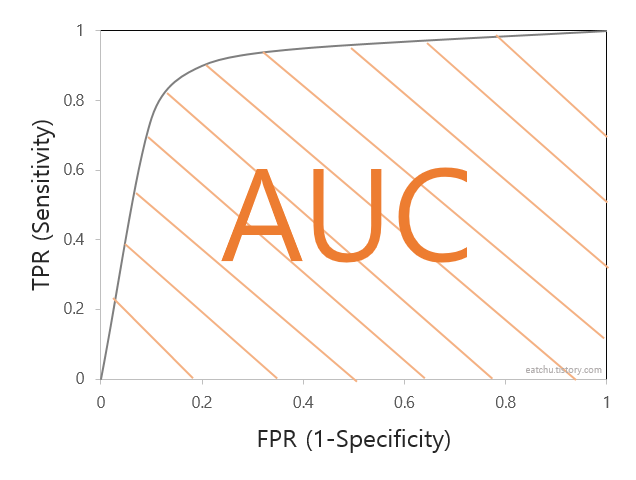
- AUC(Area Under Curve)
: ROC곡선 아래 면적
Tip) 타깃값(이산값)으로 예측 시 분류 평가지표 → 정확도, 정밀도, 재현율, F1 점수
타깃 확률로 예측 시 분류 평가지표 → 로그 손실, AUC
3. 참고

공부하는 데이터 분석가 👩💻