추천 시스템이란?
사용자의 과거 행동 데이터나 다른 데이터를 바탕으로 사용자에게 필요한 정보나 제품을 제시해주는 시스템
전통적 비즈니스에서의 추천
: 고객들을 취향이 비슷한 집단(마케팅에서는 세그먼트)으로 나누고, 각 집단에 잘 맞는 제품, 서비스 추천
- 빅데이터, 추천 알고리즘의 발전
집단의 크기를 줄일 수 있게 되었고, 이러한 집단의 크기를 극단적으로 줄여 각 집단 -> 한 사람
이렇게 각 사용자별로 맞춤형 추천과 서비스를 제공하는 것 -> 개인화 추천시스템
1) 협업 필터링(Collaborative Filtering)
구매, 소비한 제품에 대한 각 소비자의 평가를 받아서 평가 패턴이 비슷한 소비자를 한 집단으로 봄
각 집단에 속한 소비자들의 취향을 활용하는 기술
Ex) A라는 소비자와 제품평가 패턴이 비슷한 사람들을 골라서 이 사람들이 공통적으로 좋아하는 제품 중에서 A가 아직 접하지 않은 제품을 골라내서 제시하는 기술
사람들의 취향이 뚜렷이 구분되는 제품(영화, 음악, 패션) 등의 추천에 높은 정확도를 보임
한계점 : 소비자들의 평가 정보를 구하기 어려움
소비자들에게 제품을 구입한 후 평가 정보를 요청하면 이를 제공하기 어렵기 떄문에
이러한 한계를 극복하기 위해 간접적인 정보를 사용함
장바구니에 담는 제품 등 온라인 쇼핑에서의 클릭스트림(Clickstream)을 수집, 분석을 통해서 소비자의 취향이나 니즈를 알아낼 수 있음 ex) 아마존 제품 추천, 넷플릭스 영화 추천 시스템
2) 내용 기반 필터링(Content-based Filtering)
제품의 내용을 분석해서 추천해주는 기술
소비자가 소비하는 제품 중 텍스트 정보가 많은 제품(ex) 뉴스, 책 등)을 분석하여 추천할 때 많이 이용
텍스트 중에서 형태소 추출 -> 핵심 키워드 추출 후 소비자의 관심사항에 대한 분석
3) 지식 기반 필터링(Knowledge-Based filtering)
협업 필터링, 내용 기반 필터링의 공통적인 단점 : 전체적인 그림이 없다는 뜻
즉, 어떤 소비자가 어떤 제품을 좋아할지에 대한 분석은 가능하지만, “왜 그 제품을 좋아할 것인가?”에 대한 답 X
특정 분야(domain) 전문가의 도움을 받아 그 분야에 대한 전체적인 지식구조를 만들어서 활용하는 방법
전체적인 지식구조의 다양한 표현 방식
해당 도메인의 중요한 개념을 바탕으로 체계도(ontology)를 만드는 것이 일반적인 방법
이러한 체계도를 바탕으로, 소비자가 구매한, 관심 있는 제품과 관련 있는 제품을 추천할 때 이 체계도를 참고
4) 딥러닝 추천 기술
다양한 사용자와 아이템의 특징값(feature)을 사용하고, 이를 통해 얻은 출력은 각 아이템에 대한 각 사용자의 예상 선호도로 사용 -> 각 사용자에 대해 많은 아이템별 예상 선호도 계산 -> 선호도가 높은 제품 추천
장점 : 다양한 입력변수 사용 가능
But, 연속값(ex) 1~5)로 표시되는 아이템에 대한 사용자의 선호도를 딥러닝을 사용할 경우, 정확도가 다른 알고리즘에 비해 크게 우월하지는 않음
5) 하이브리드(Hybrid)
위에서 제시한 알고리즘 중 2가지 이상을 혼합하여 사용하는 형태
각각의 알고리즘은 장단점이 뚜렷하기 때문에 이들을 적절히 결합하면 좋은 효과를 볼 수 있고, 이들을 어떻게 결합할 것인가가 중요한 해결 과제
1) 협업 필터링(Collaboratice Filtering)
2) 내용 기반 필터링(Content-based Filtering)
3) 지식 기반 필터링(Knowledge-Based filtering)
4) 딥러닝 추천 기술
5) 하이브리드(Hybrid)
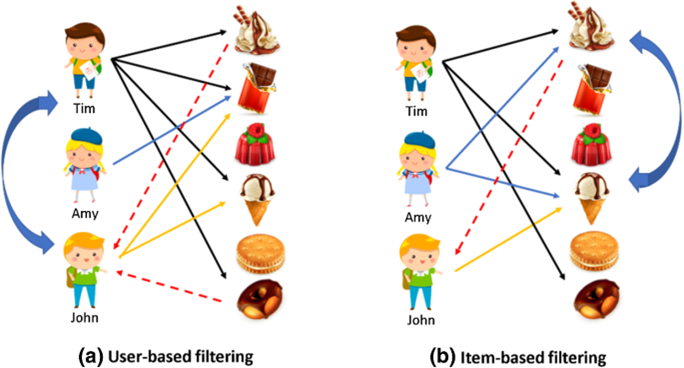
- 대표적인 User-based filtering 추천알고리즘인 Collaborative filtering
협업필터링이란?
취향이 비슷한 사람들(neighbor)의 집단이 존재한다고 가정
이 집단의 사람들이 공통적으로 좋아하는 제품, 서비스를 추천
Collaborative 알고리즘의 순서
1) 모든 사용자간의 평가의 유사도 계산(적절한 유사도 평가 공식 사용)
# train set의 모든 가능한 사용자 pair의 Cosine similarities 계산
from sklearn.metrics.pairwise import cosine_similarity
matrix_dummy = rating_matrix.copy().fillna(0)
user_similarity = cosine_similarity(matrix_dummy, matrix_dummy)
user_similarity = pd.DataFrame(user_similarity, index=rating_matrix.index, columns=rating_matrix.index)
2) 현재 추천의 대상이 되는 사람과 다른 사용자간의 유사도 추출
def CF_simple(user_id, movie_id):
if movie_id in rating_matrix:
# 현재 사용자와 다른 사용자 간의 similarity 가져오기
sim_scores = user_similarity[user_id].copy()
# 현재 영화에 대한 모든 사용자의 rating값 가져오기
movie_ratings = rating_matrix[movie_id].copy()
# 현재 영화를 평가하지 않은 사용자의 index 가져오기
none_rating_idx = movie_ratings[movie_ratings.isnull()].index
# 현재 영화를 평가하지 않은 사용자의 rating (null) 제거
movie_ratings = movie_ratings.dropna()
# 현재 영화를 평가하지 않은 사용자의 similarity값 제거
sim_scores = sim_scores.drop(none_rating_idx)
# 현재 영화를 평가한 모든 사용자의 가중평균값 구하기
mean_rating = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
else:
mean_rating = 3.0
#print(movie_ratings)
return mean_rating
3) 현재 사용자가 평가하지 않은 모든 아이템에 대해서 현재 사용자의 예상 평가값 도출
-> 다른 사용자의 해당아이템에 대한 평가를 현재 사용자와의 유사도를 가중한 것을 바탕으로 평균
# 전체 데이터로 full matrix와 cosine similarity 구하기
rating_matrix = ratings.pivot_table(values='rating', index='user_id', columns='movie_id')
from sklearn.metrics.pairwise import cosine_similarity
matrix_dummy = rating_matrix.copy().fillna(0)
user_similarity = cosine_similarity(matrix_dummy, matrix_dummy)
user_similarity = pd.DataFrame(user_similarity, index=rating_matrix.index, columns=rating_matrix.index)4) 아이템 중에서 예상 평가값이 가장 높은 N개 아이템 추천
def recom_movie(user_id, n_items, neighbor_size=30):
# 현 사용자가 평가한 영화 가져오기
user_movie = rating_matrix.loc[user_id].copy()
for movie in rating_matrix:
# 현 사용자가 이미 평가한 영화는 제외 (평점을 0으로)
if pd.notnull(user_movie.loc[movie]):
user_movie.loc[movie] = 0
# 현 사용자가 평가하지 않은 영화의 예상 평점 계산
else:
user_movie.loc[movie] = cf_knn(user_id, movie, neighbor_size)
# 영화를 예상 평점에 따라 정렬해서 제목을 뽑아서 돌려 줌
movie_sort = user_movie.sort_values(ascending=False)[:n_items]
recom_movies = movies.loc[movie_sort.index]
recommendations = recom_movies['title']
return recommendations
recom_movie(user_id=2, n_items=5, neighbor_size=30)이웃(neighbor)을 고려한 CF
2가지 고려할 사항
- Neighbor 집단 크기
- Neighbor 선정 기준
1) K Nearest Neighbor(KNN)
2) Thresholding(유사도의 기준을 충족하는 사용자를 이웃으로 선정)
# Neighbor size를 정해서 예측치를 계산하는 함수
def cf_knn(user_id, movie_id, neighbor_size=0):
if movie_id in rating_matrix:
# 현재 사용자와 다른 사용자 간의 similarity 가져오기
sim_scores = user_similarity[user_id].copy()
# 현재 영화에 대한 모든 사용자의 rating값 가져오기
movie_ratings = rating_matrix[movie_id].copy()
# 현재 영화를 평가하지 않은 사용자의 index 가져오기
none_rating_idx = movie_ratings[movie_ratings.isnull()].index
# 현재 영화를 평가하지 않은 사용자의 rating (null) 제거
movie_ratings = movie_ratings.drop(none_rating_idx)
# 현재 영화를 평가하지 않은 사용자의 similarity값 제거
sim_scores = sim_scores.drop(none_rating_idx)
##### (2) Neighbor size가 지정되지 않은 경우
if neighbor_size == 0:
# 현재 영화를 평가한 모든 사용자의 가중평균값 구하기
mean_rating = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
##### (3) Neighbor size가 지정된 경우
else:
# 해당 영화를 평가한 사용자가 최소 2명이 되는 경우에만 계산
if len(sim_scores) > 1:
# 지정된 neighbor size 값과 해당 영화를 평가한 총사용자 수 중 작은 것으로 결정
neighbor_size = min(neighbor_size, len(sim_scores))
# array로 바꾸기 (argsort를 사용하기 위함)
sim_scores = np.array(sim_scores)
movie_ratings = np.array(movie_ratings)
# 유사도를 순서대로 정렬
user_idx = np.argsort(sim_scores)
# 유사도를 neighbor size만큼 받기
sim_scores = sim_scores[user_idx][-neighbor_size:]
# 영화 rating을 neighbor size만큼 받기
movie_ratings = movie_ratings[user_idx][-neighbor_size:]
# 최종 예측값 계산
mean_rating = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
else:
mean_rating = 3.0
else:
mean_rating = 3.0
return mean_rating사용자의 평가 경향을 고려한 CF
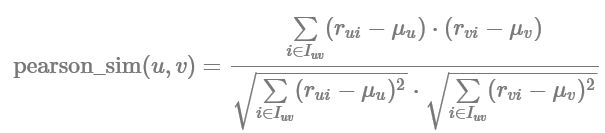
두 유저의 영화 평점 벡터(5, 5, 5), (1, 1, 1) 의 코사인 유사도를 계산해보면 1
영화에 대한 유저의 평가는 극명하게 갈림에도, 이렇게 코사인 유사도에서는 유저마다의 개인적인 평가 성향을 반영하지 못한다는 단점
이를 보완하기 위해 기존 코사인 유사도에 약간의 보정 과정을 거친, 피어슨 유사도(Pearson Similarity)를 사용
특정 유저의 점수기준이 극단적으로 너무 낮거나 높을 경우 유사도에 영향을 크게 주기 때문에, 이를 막기 위해 상관계수를 사용하는 방법
각 User별 평균값을 구해 그 값을 뺀 뒤 코사인 유사도 계산
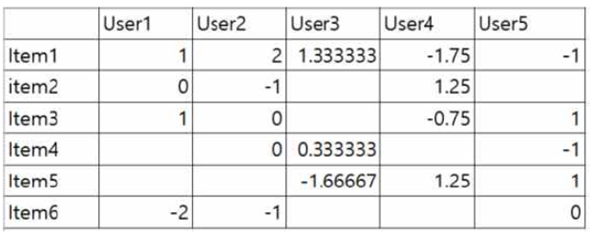
# train 데이터의 user의 rating 평균과 영화의 평점편차 계산
rating_mean = rating_matrix.mean(axis=1)
rating_bias = (rating_matrix.T - rating_mean).T
def CF_knn_bias(user_id, movie_id, neighbor_size=0):
if movie_id in rating_bias:
# 현 user와 다른 사용자 간의 유사도 가져오기
sim_scores = user_similarity[user_id].copy()
# 현 movie의 평점편차 가져오기
movie_ratings = rating_bias[movie_id].copy()
# 현 movie에 대한 rating이 없는 사용자 삭제
none_rating_idx = movie_ratings[movie_ratings.isnull()].index
movie_ratings = movie_ratings.drop(none_rating_idx)
sim_scores = sim_scores.drop(none_rating_idx)
##### (2) Neighbor size가 지정되지 않은 경우
if neighbor_size == 0:
# 편차로 예측값(편차 예측값) 계산
prediction = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
# 편차 예측값에 현 사용자의 평균 더하기
prediction = prediction + rating_mean[user_id]
##### (3) Neighbor size가 지정된 경우
else:
# 해당 영화를 평가한 사용자가 최소 2명이 되는 경우에만 계산
if len(sim_scores) > 1:
# 지정된 neighbor size 값과 해당 영화를 평가한 총사용자 수 중 작은 것으로 결정
neighbor_size = min(neighbor_size, len(sim_scores))
# array로 바꾸기 (argsort를 사용하기 위함)
sim_scores = np.array(sim_scores)
movie_ratings = np.array(movie_ratings)
# 유사도를 순서대로 정렬
user_idx = np.argsort(sim_scores)
# 유사도와 rating을 neighbor size만큼 받기
sim_scores = sim_scores[user_idx][-neighbor_size:]
movie_ratings = movie_ratings[user_idx][-neighbor_size:]
# 편차로 예측치 계산
prediction = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
# 예측값에 현 사용자의 평균 더하기
prediction = prediction + rating_mean[user_id]
else:
prediction = rating_mean[user_id]
else:
prediction = rating_mean[user_id]
return prediction유사도 측정 함수
1) Euclidean distance
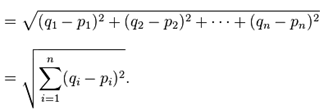
2) Cosine distance
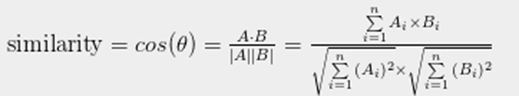
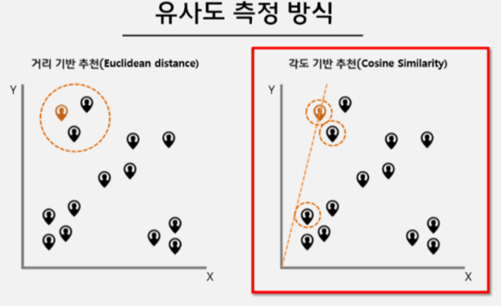
Euclidean distance 와 Cosince disatance의 차이
Ex) 책 A : 게임, 액션이라는 단어가 각각 1개씩 2단어, 책 B : 게임, 액션이라는 단어가 각각 1000개씩 2000단어
거리기반 -> (1,1) (2000,2000)의 큰 차이 -> 유사도가 낮다?
각도기반 -> 기울기가 같고, 방향이 같이 때문에 높은 유사도
3) Tanimoto coefficient
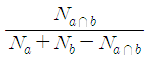
데이터가 이진값을 갖는 경우 사용 가능(특정 단어, 특징의 포함 여부, 물건 구매 여부 등)
simil(x,y) = c / a + b – c
a : 사용자 x가 1의 값을 갖는(구입한 혹은 클릭한) 아이템의 수
b : 사용자 y가 1의 값을 갖는(구입한 혹은 클릭한) 아이템의 수
c : 사용자 x, y가 공통적으로 1의 값을 갖는 아이템의 수
4) Jaccard’s distance
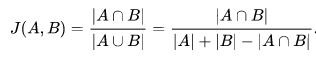
5) Correlation coefficient(상관계수)
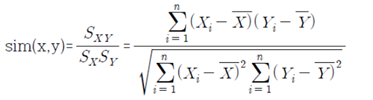
- 공분산을 표준편차로 나누어 정규화 - -1 ~ 1의 값으로 선형관계 판단
상관계수는 이해하기 쉬운 유사도 측정치이기는 하지만 협업 필터링에서 사용하는 경우 늘 좋은 결과를 가져오지는 못하는 것으로 알려져 있다.
잠재변수(lurking variable) : 상관관계가 높다는 것은 두 변수 사이에 연관성이 높다는 것, 인과관계를 의미하지는 않는다 -> 따라서 이를 정확하게 이해하고 적용하기 위한 해당분야의 전문적인 해석이 필요함
두 사용자의 선호가 겹쳐지는 아이템의 숫자를 고려하지 않음
1) 두 사용자의 아이템 선호 중 하나만 겹친다면 계산방식을 어떻게 정의할지 모르기 때문에 상관관계 계산 X
2) 선호값의 열이 모두 일치하는 경우에도 판단 불가
