딥러닝 기반 추천 알고리즘
앞서 다룬Matrix Factorization 모델의 구조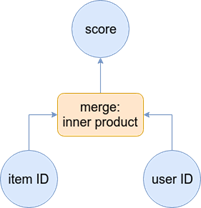
Keras로 구현한 은닉층이 없는 신경망 모형 = MF 알고리즘과 기본적으로 같은 모형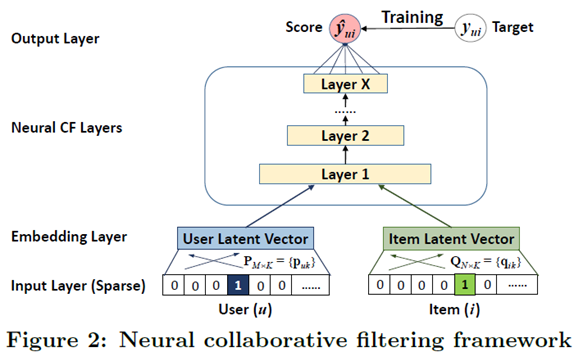 User one-hot representation / Item one-hot representation
User one-hot representation / Item one-hot representation
M명의 사용자와 N개의 아이템이 있는 경우
사용자의 입력은 M(사용자의 수) x M(feature 속성의 수) 행렬
K(잠재요인의 수)개의 모든 feature에서 사용자 embedding Layer의 모든 node는 연결되어 있음
-> Input 이 One-hot Encoding이기 때문에 사용자 하나에 대해서 각각 K개씩의 연결 활성화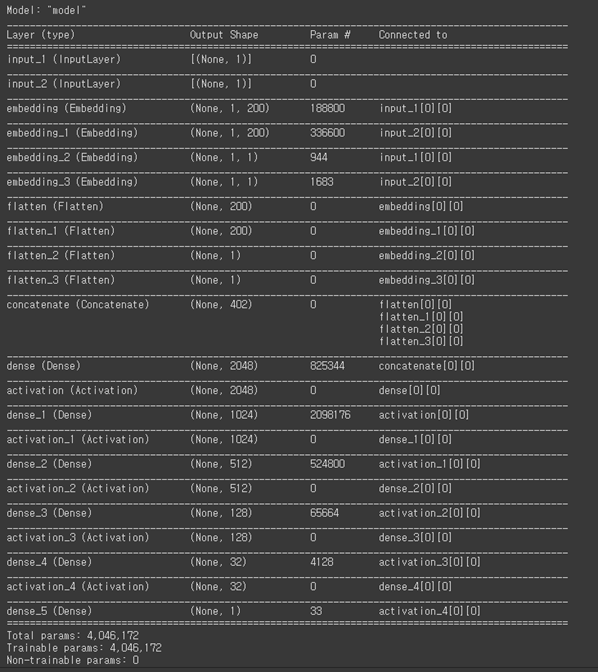
-
User embedding layer -> M X K개의 연결 + user bias embedding layer -> MX1의 연결
(944X200 = 188,800개의 파라마터) + 944X1 -
Item embedding layer -> N X K개의 연결 + Item bias embedding layer -> NX1의 연결
1683X200 = 336,600개의 파라마터) + 1683 X 1
concat시킨 하나의 layer는 402개의 노드 수를 가진 레이어
2048개의 노드를 갖는 dense layer와 연결
이때 파라미터 수 (402 + 1) X 2048
# train test 분리
from sklearn.utils import shuffle
TRAIN_SIZE = 0.75
ratings = shuffle(ratings)
cutoff = int(TRAIN_SIZE * len(ratings))
ratings_train = ratings.iloc[:cutoff]
ratings_test = ratings.iloc[cutoff:]
##### (1)
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Embedding, Dot, Add, Flatten
from tensorflow.keras.regularizers import l2
from tensorflow.keras.optimizers import SGD, Adam, Adamax
# Variable 초기화
K = 200 # Latent factor 수
mu = ratings_train.rating.mean() # 전체 평균
M = ratings.user_id.max() + 1 # Number of users
N = ratings.movie_id.max() + 1 # Number of movies
# Defining RMSE measure
def RMSE(y_true, y_pred):
return tf.sqrt(tf.reduce_mean(tf.square(y_true - y_pred)))
##### (2)
# Keras model
user = Input(shape=(1, )) # User input
item = Input(shape=(1, )) # Item input
P_embedding = Embedding(M, K, embeddings_regularizer=l2())(user) # (M, 1, K)
Q_embedding = Embedding(N, K, embeddings_regularizer=l2())(item) # (N, 1, K)
user_bias = Embedding(M, 1, embeddings_regularizer=l2())(user) # User bias term (M, 1, )
item_bias = Embedding(N, 1, embeddings_regularizer=l2())(item) # Item bias term (N, 1, )
# Concatenate layers
from tensorflow.keras.layers import Dense, Concatenate, Activation
P_embedding = Flatten()(P_embedding) # (K, )
Q_embedding = Flatten()(Q_embedding) # (K, )
user_bias = Flatten()(user_bias) # (1, )
item_bias = Flatten()(item_bias) # (1, )
R = Concatenate()([P_embedding, Q_embedding, user_bias, item_bias]) # (2K + 2, )
# Neural network
R = Dense(2048)(R)
R = Activation('linear')(R)
R = Dense(256)(R)
R = Activation('linear')(R)
R = Dense(1)(R)
model = Model(inputs=[user, item], outputs=R)
model.compile(
loss=RMSE,
optimizer=SGD(),
#optimizer=Adamax(),
metrics=[RMSE]
)
model.summary()
# Model fitting
result = model.fit(
x=[ratings_train.user_id.values, ratings_train.movie_id.values],
y=ratings_train.rating.values - mu,
epochs=65,
batch_size=512,
validation_data=(
[ratings_test.user_id.values, ratings_test.movie_id.values],
ratings_test.rating.values - mu
)
)
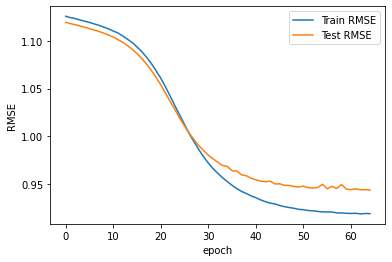
# Plot RMSE
import matplotlib.pyplot as plt
plt.plot(result.history['RMSE'], label="Train RMSE")
plt.plot(result.history['val_RMSE'], label="Test RMSE")
plt.xlabel('epoch')
plt.ylabel('RMSE')
plt.legend()
plt.show()
# Prediction
user_ids = ratings_test.user_id.values[0:6]
movie_ids = ratings_test.movie_id.values[0:6]
predictions = model.predict([user_ids, movie_ids]) + mu
print("Actuals: \n", ratings_test[0:6])
print()
print("Predictions: \n", predictions)Actuals:
user_id movie_id rating
51483 655 732 3
48054 577 147 4
58844 625 144 4
71493 618 403 4
49535 201 202 3
7716 8 301 4
Predictions:
[[3.0499847][3.6674016]
[3.523291 ][3.072978 ]
[3.2514324][3.5055091]]
# 정확도(RMSE)를 계산하는 함수
def RMSE2(y_true, y_pred):
return np.sqrt(np.mean((np.array(y_true) - np.array(y_pred))**2))
user_ids = ratings_test.user_id.values
movie_ids = ratings_test.movie_id.values
y_pred = model.predict([user_ids, movie_ids]) + mu
y_pred = np.ravel(y_pred, order='C')
y_true = np.array(ratings_test.rating)
RMSE2(y_true, y_pred)0.9440081064329731
