
- 본 강의는 스파르타코딩클럽 웹개발종합반 강의에 대한 요약입니다.
- 본 내용의 에디터로는 Visure Studio Code를 활용하여 진행하였다.
Python으로 웹서버구축하기
01 python으로 웹 크롤링하기
웹크롤링이란 코드를 통해서 웹에 접근하여 웹의 특정 정보를 긁어오는 기능을 말한다. 가장 대표적인 크롤링 기술은 BeautifulSoup이 있다. 그러나 BeautifulSoup은 정적이라는 이름이 붙어지는데, 웹이 실행되었을 때, 다운받은 html에 기록된 정보만을 불러올 수 있기 때문이다. 만약 웹이 동적으로 작동한다면, BeautifulSoup은 제한된다. 이때는 selenium을 틍해서 접근할 수 있다.
BeautifulSoup을 실행하기 위해서는 먼저 패키지를 실행시켜줘야 한다. 에디터의 터미널을 실행시키고(맥 단축키, ctrl+shift+₩), 아래의 명령어를 입력해주자.
pip3 install bs4
pip3 install requestsBeautifulSoup은 웹 페이지의 정보를 쉽게 긁어오는 패키지이다. 그런데 이 작업을 수행하기 위해서는 마치 웹에서 접근하는 것처럼 컴퓨터에게 접근해야 한다. 이를 가능하게 하는 것이 Requests 패키지이다. 웹에서 접근하듯이 위장하지 않으면 컴퓨터가 정보를 주지 않을 가능성이 있기 때문이다. 설치가 완료되었다면, app.py에 아래의 코드를 통해서 웹크롤링을 하기 위한 준비를 하자.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get("url",headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')위의 코드에서 눈여겨 보아야 할 것은 4번째 줄에 있는 requests.get("url",headers=headers)의 url부분이다. 해당 url에 웹크롤링을 실행하고 싶은 웹페이지의 url을 기록하자.
지니뮤직 크롤링
웹크롤링을 할 부분은 다음과 같다.
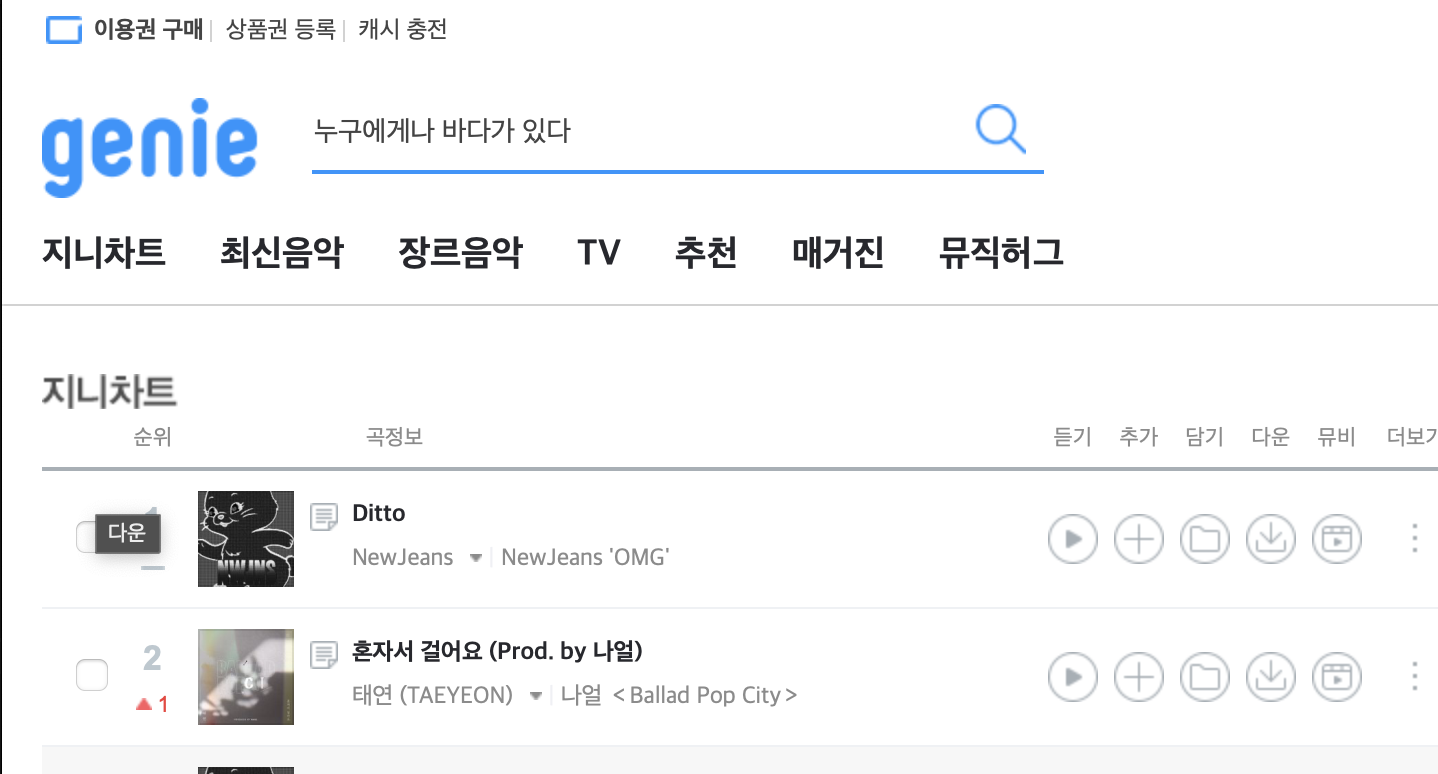
- 순위 곡제목 가수 순으로 크롤링 실시하기

1) soup.select 실시하기
- select : 해당전부를 가져오기
- select_one : 해당부분에서 하나만 가져오기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get("https://www.genie.co.kr/chart/top200",headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
m1 = soup.select('#body-content > div.newest-list > div > table > tbody > tr')m1은 soup.select('#선택자경로')을 통해서 웹페이지의 정보를 가져온다.
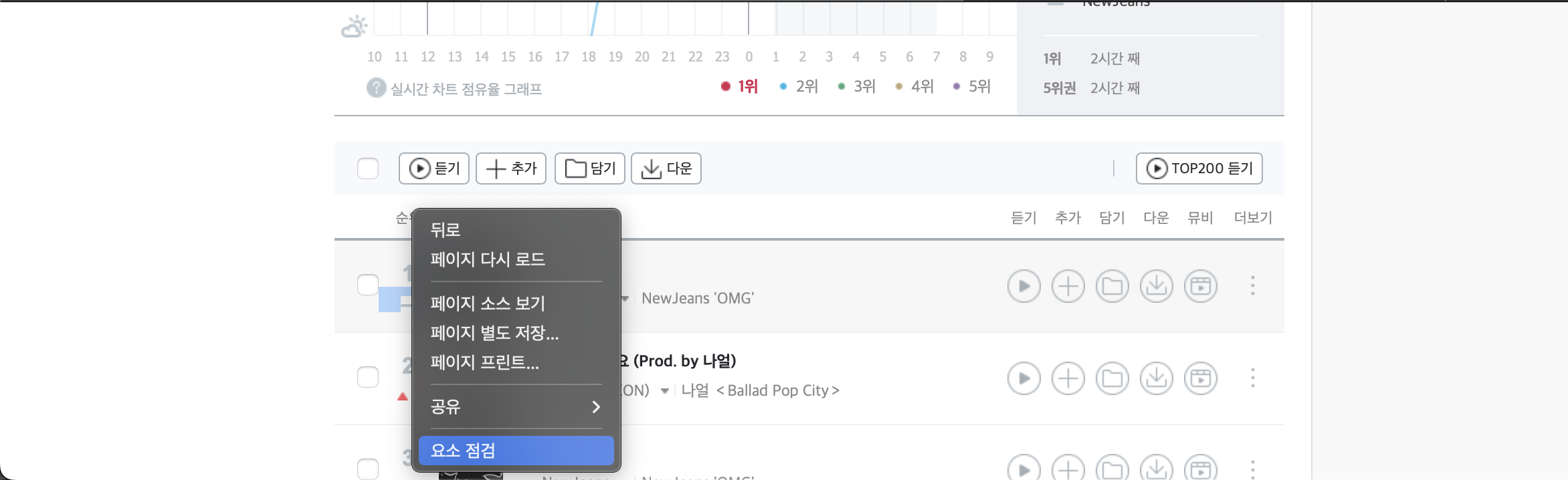
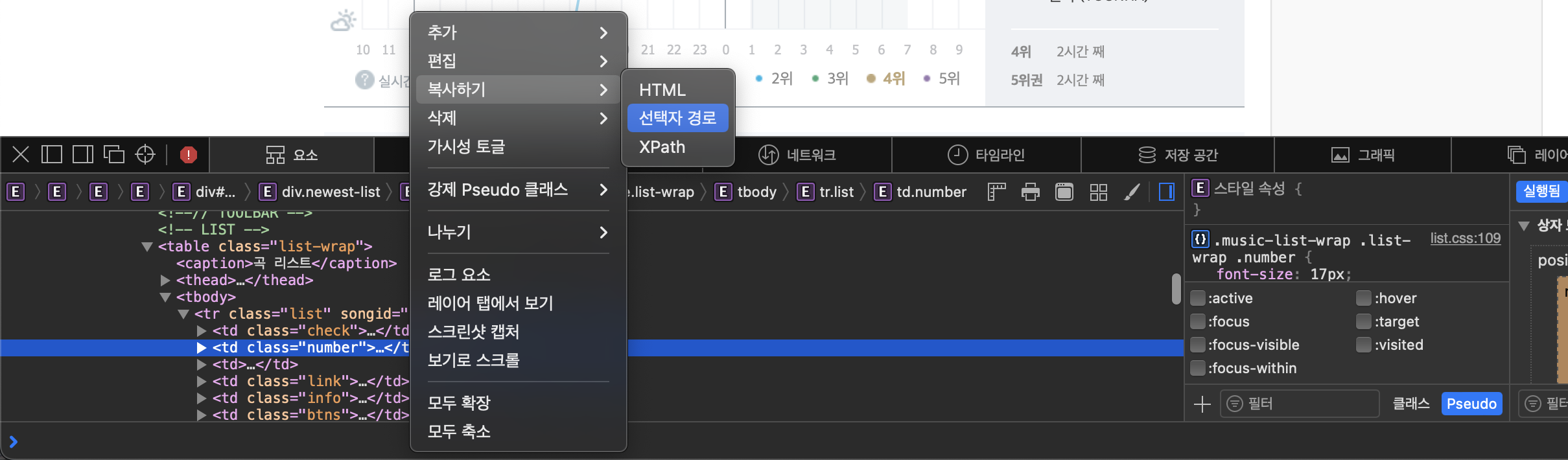
- rank 선택자경로 : #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
- title 선택자경로 : #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
- singer 선택자경로 : #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
지니뮤직에서 웹크롤링을 할 때 3가지 정보를 가져오고자 한다. 이때 반복문을 통해서 복수의 정보들을 불러올 수 있는데, 이를 위해서 중복되는 코드를 변수에 담고 가변적인 부분을 반복문을 통해서 불러오면 된다. 이를 위해서 위의 코드에서 m1 = soup.select('##body-content > div.newest-list > div > table > tbody > tr') 이라 기록되었고 이를 for문을 통해서 아래와 같이 기록하였다.
m1 = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for m2 in m1:
rank = m2.select_one('td.number').text[0:2].strip()
title = m2.select_one('td.info > a.title.ellipsis').text.strip()
singer = m2.select_one('td.info > a.artist.ellipsis').text
print(rank, title, singer)m2.select_one('선택자경로')와 기타명령들
.text 선택자의 텍스트만 가져오기
위와 같이 입력하고 실행하면, 해당 부분의 <html></html>태그 전체를 불러오게 될 것이다. 그런데 우리는 정보만을 가져오고 싶다. 그렇다면 어떻게 설정하면 될까? 가능하다. 위의 코드 옆에 .text를 붙여주면 된다.
for m2 in m1:
rank = m2.select_one('td.number').text
title = m2.select_one('td.info > a.title.ellipsis').text
singer = m2.select_one('td.info > a.artist.ellipsis').text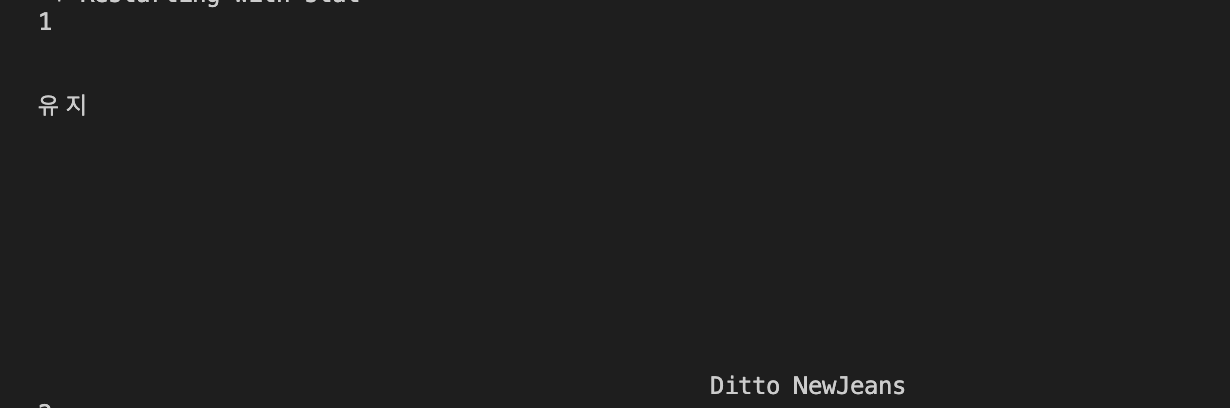
.strip() 공백제거
그런데 text만 불러와도 지니뮤직의 경우에는 문제가 있다. 여백이 많이 발생된다는 점이다. 이를 어떻게 해결할까? python에서는 공백을 제거해주는 코드로 .strip()를 사용한다.
for m2 in m1:
rank = m2.select_one('td.number').text.strip()
title = m2.select_one('td.info > a.title.ellipsis').text.strip()
singer = m2.select_one('td.info > a.artist.ellipsis').text
print(rank, title, singer)
그런데도, 깔끔하게 정리된 느낌은 아니다. 보면 rank를 불러오는 부분에서 문제가 발생한 것 같다. rank의 정보를 보면 순위와 더불어서 이전대비 해당 타이들과 가수가 유지 되었는지, 상승되었는지, 하강되었는지에 대한 정보도 해당 선택자 경로는 가지고 있기 때문인 것으로 보인다. 그렇다면 우리가 필요한 순위만 가져오기 위한 약간의 가공이 필요하다.
.text[a:b] 텍스트에서 특정위치만 가져오기
불러온 텍스트에서 특정한 부분만 가져오면 될 것으로 보여진다. python에서는 .text[a:b]으로 특정부분을 추출할 수 있다.
for m2 in m1:
rank = m2.select_one('td.number').text[0:3].strip()
title = m2.select_one('td.info > a.title.ellipsis').text.strip()
singer = m2.select_one('td.info > a.artist.ellipsis').text
print(rank, title, singer)
이미지에서 보듯이 이런식으로 특정한 url에 접근하여, 해당 웹페이지가 가지고 있는 html의 정보를 가져와서 가공할 수 있는 것이 웹크롤링 기술이다. 그렇다면 가져온 정보를 어떻게 처리해야 할까? 일단 어딘가에 저장을 해야, 언제든이 해당 내용을 불러와서 사용할 수 있지 않을까? 바로 이러한 고민에서 등장한 것이 데이터베이스(DB)이다. 이 내용은 다음포스트에서 살펴보고자 한다.
author. EDWIN
date. 23/02/03
