
- 본 강의는 스파르타코딩클럽 웹개발종합반 강의에 대한 요약입니다.
- 본 내용의 에디터로는 Visure Studio Code를 활용하여 진행하였다.
Python으로 웹서버구축하기
01 python으로 DB활용하기
이전 포스트에서 웹페이지로부터 특정한 정보를 긁어오는 크롤링 기술에 대해서 살펴보았다. 이번 포스트에서는 긁어온 정보를 저장하고, 불러오는 부분에 대해서 다뤄보고자 한다.
1) SQL의 두가지 모습
DB를 저장하고 활용하는 것을 SQL이라고 부른다. SQL은 인터넷이 등장한 뒤 10년 뒤인 1970년대에 IBM의 도널드 D. 챔벌린과 레이먼드 F. 보이스가 처음 개발하여 소개한 프로그래밍 언어이다. 연도로만 보았을 때는 HTML보다 앞선 컴퓨터 프로그래밍 언어이다. SQL(구조적 쿼리 언어)은 관계형 데이터베이스에 정보를 저장하고, 처리하는 기능을 수행하는데, 크게 2가지의 모습이 있다.
- 첫째, 엑셀에서 보는 것과 같이 열과 행을 가진 정밀한 정리체계의 SQL
- 둘째, 조각적인 내용들을 정밀한 체계보다는 조금 느슨한 체계에 의해서 정리된 SQL
정보처리가 방대한 경우에는 첫번째 SQL의 방식을 채택해야 할 것이다. 대표적인 프로그램이 MySQL이다. 정보처리가 방대하지 않은 경우에는 조금 체계가 자유로운 SQL방식을 사용하게 되는데 대표적인 프로그램이 MongoDB이며, 웹상에서 접근이 가능하다. 이번 포스트에서는 두번째 방식인 MongoDB에 정보를 저장하고 활용하는 방법에 대해서 다뤄보고자 한다.
2) app.py에 MongoDB 연결하기
pip3 install pymongo
pip3 install certifipymongo패키지는 MongoDB을 파이썬에서 제어할 수 있도록 해주는 패키지이다. 그런데 맥북의 경우에는 호환성에 문제가 발생하여, 이를 해결해주기 위해서 certifi 패키지까지 추가로 설치해 주어야 한다.
- window의 경우
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:userId@cluster0.mongodb.net/Cluster0?retryWrites=true&w=majority')
db = client.정보를저장할DB명
- Mac의 경우(certifi 패키지)
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://test:userId@cluster0.mongodb.net/Cluster0?retryWrites=true&w=majority', tlsCAFile=ca)
db = client.정보를저장할DB명준비 끝이다. 웹브라우저에서 MongoDB에 접속하고, 이전 포스트에서 가져왔던 지니뮤직의 정보들을 해당 DB에 추가하며, 이를 실습해보자.
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://test:<password>@cluster0.mongodb.net/Cluster0?retryWrites=true&w=majority', tlsCAFile=ca)
db = client.정보를저장할DB명
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get("https://www.genie.co.kr/chart/top200",headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
m1 = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for m2 in m1:
rank = m2.select_one('td.number').text[0:3].strip()
title = m2.select_one('td.info > a.title.ellipsis').text.strip()
singer = m2.select_one('td.info > a.artist.ellipsis').text
doc = {
'rank' : rank,
'title' : title,
'singer' : singer
}
db.genie.insert_one(doc)이전 포스트에서 작성한 웹크롤링의 반복문 안에 각각의 정보를 print 하는 것이 아니라 DB에 저장할 것을 명령해보자. 일단 긁어온 내용을 처리하기 위해서 하나의 변수 doc안에 담아서 처리했다. 그리고 그 변수를 db에 저장하기 위해서 db.genie.insert_one(doc) MongoDB를 불러올 때 설정했던 큰 방(7번째줄, 정보를저장할DB명)에 하나의 서랍으로 genie을 만들고 그 안에 정보를 하나씩 기록하도록 설정하였다. 결과는 아래의 이미지와 같다.
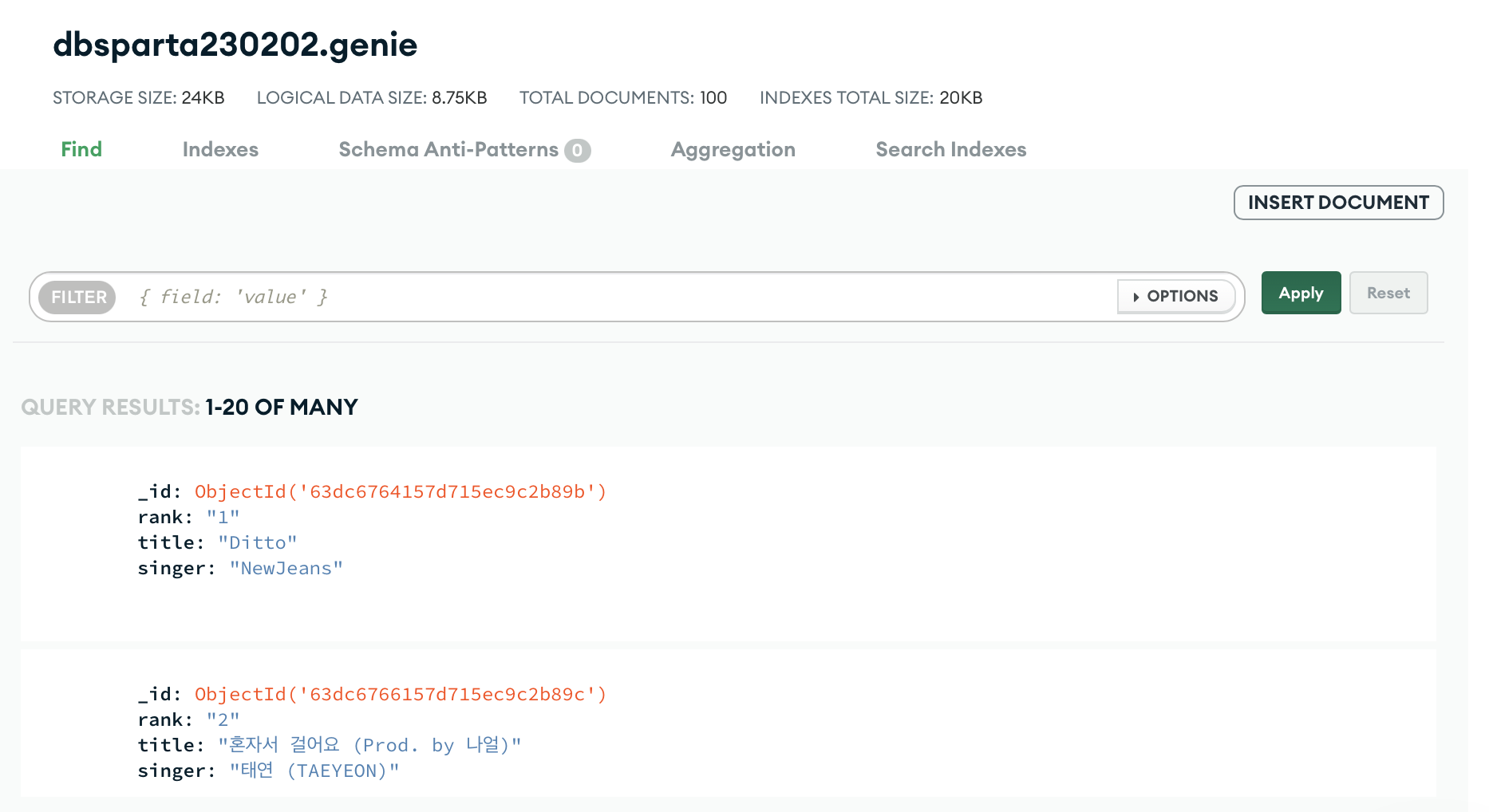
이와 같은 방법으로 정보를 서버를 통해서 DB에 저장할 수 있다. 그렇다면, 정보를 업데이트하고, 삭제하는 방법도 가능할까?
02 python으로 DB에 있는 정보를 가공하기
1) 정보를 저장하기
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)2) 정보 가져오기(단수)
user = db.users.find_one({'name':'bobby'})3) 정보 가져오기(복수)
all_users = list(db.users.find({},{'_id':False}))4) 정보 변경하기
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})5) 정보 삭제하기
db.users.delete_one({'name':'bobby'})위에서 하나의 정보에 접근하는 2), 4), 5)은 해당 정보에 접근하기 위해서 key:value를 기록해 주었다. 구체적인 정보를 통해서 해당 DB의 정보에 접근해서 가공할 수 있게 된 것이다. 서버에 대한 이해를 위해 조각기능 2개를 위와 같이 실시하였다. 다음포스트에서는 1) 클라이언트로부터 받은 정보를 토대로 2) 서버에서 크롤링을 실시하고 3) 이를 DB에 저장하고 4) 완료가 되면 클라이언트가 리로드되면서 DB에 담겨있는 정보를 가져와 웹브라우저에 표시하는 것까지 진행해보겠다.
author. EDWIN
date. 23/02/03
