1) Sparse Self-attention
-
트랜스포머 모델 : 모델의 크기나 입력 토큰의 수가 증가할 때 복잡도 증가 (O(n^2))
-
Big-bird : block sparse attention을 활용하여 4096 토큰까지 활용 가능하도록
-
성능 개선보다는 효율성 개선에 초점
-
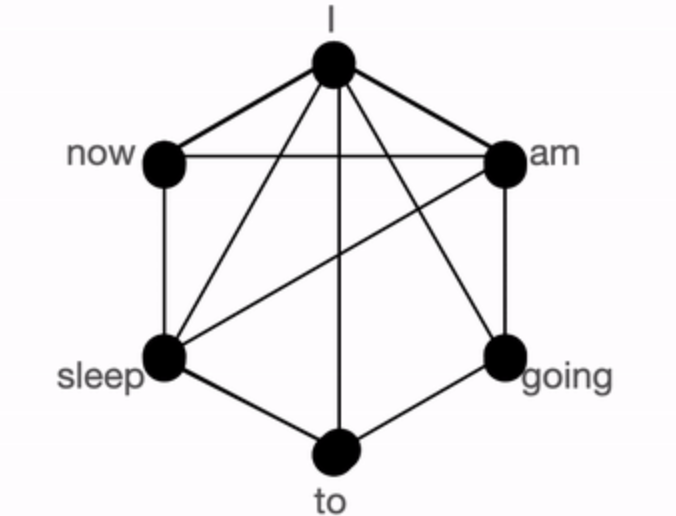
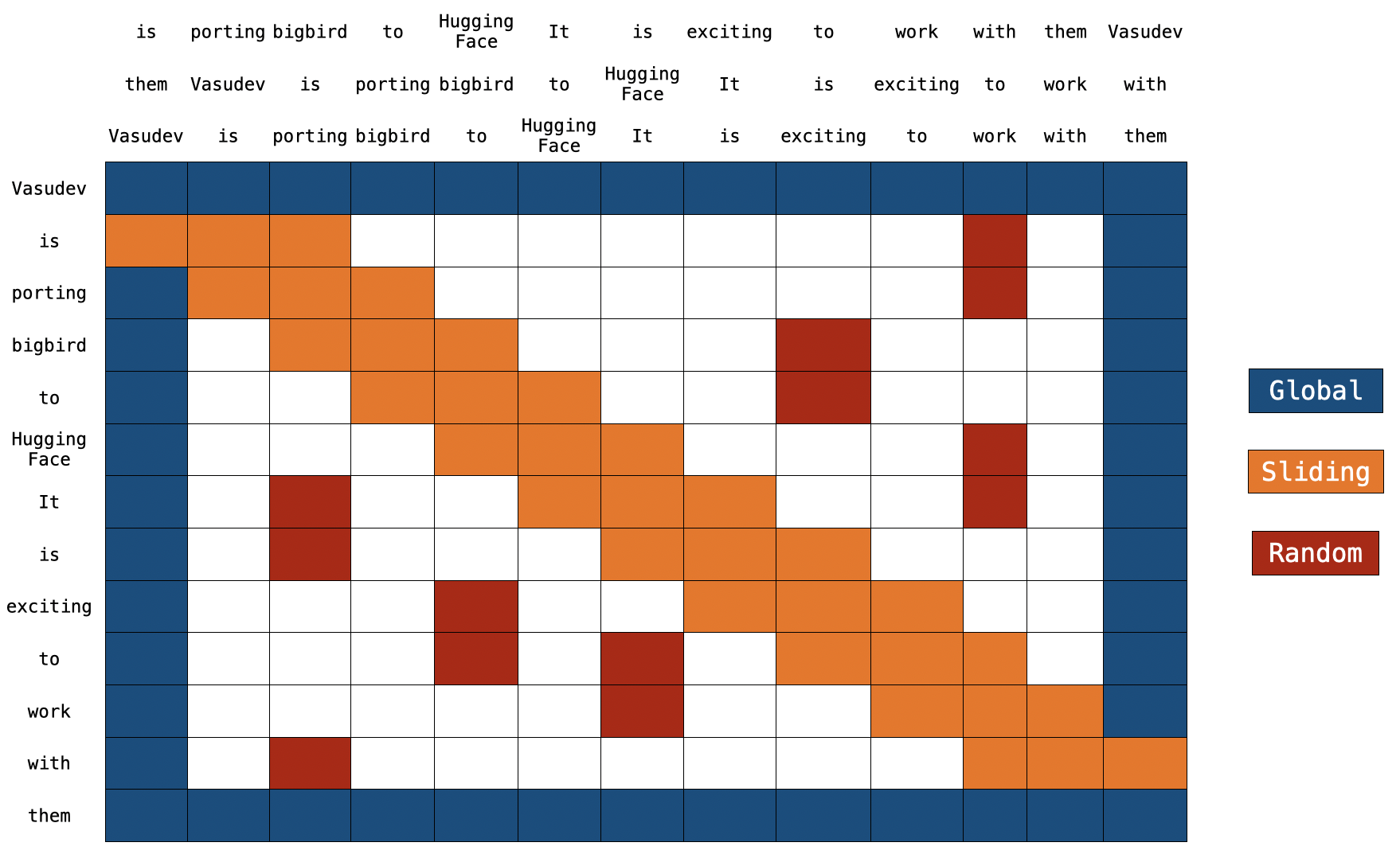
global + sliding + random connection
- global
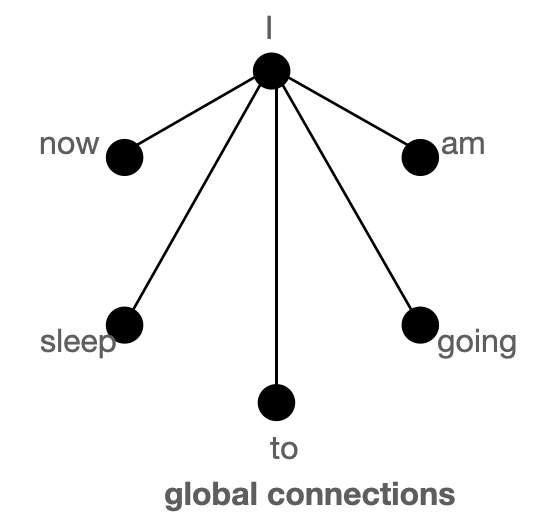
- sliding
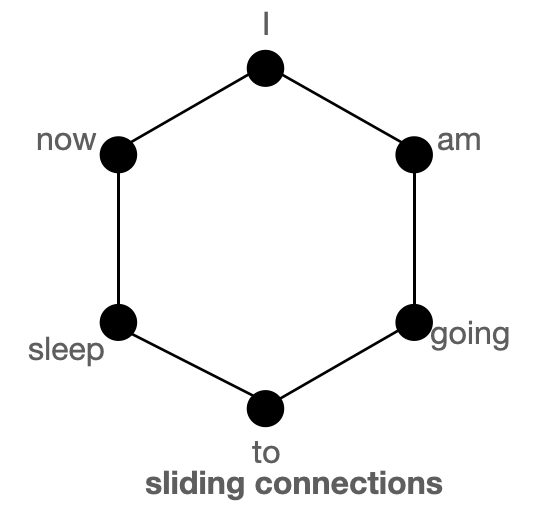
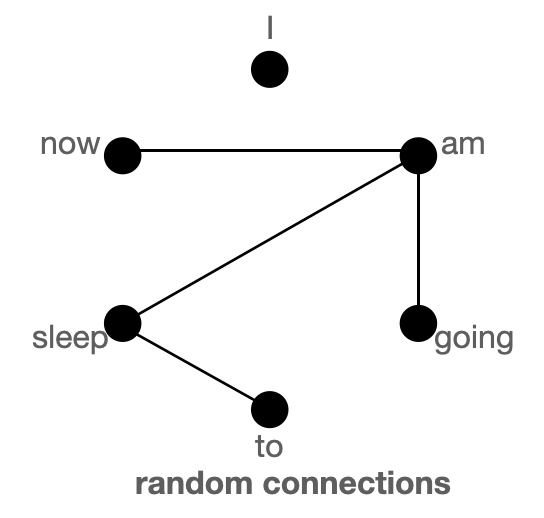
- random
- global + sliding + random
- global
-
full connection에 비해 그 연결이 적어 복잡도 개선
-
global 토큰이 많은 경우, global connection으로도 정보를 전달하기에 충분하기에 random connection이 필요하지 않을 수 있다. 이러한 아이디어는 num_random_tokens=0으로 유지하며 BigBird 활용 가능하도록

Steadily