1. Async-(비동기 처리)
비동기는 동시에 일어나지 않는다.를 의미
하나의 요청에 따른 응답을 즉시 처리하지 않아도, 그 대기 시간동안 또 다른 요청에 대해 처리 가능한 방식
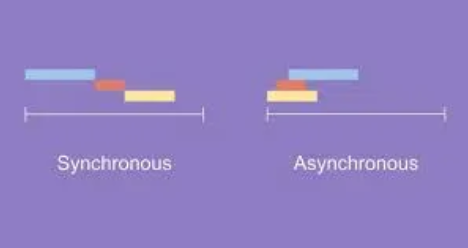
-
파이썬 특성과 연관
- I/O 바운드 작업에서 가장 큰 장점을 보임 ⇒ async 설계 방식
- Python의 동적 타이핑과 코루틴 모델을 활용하여 코드가 매우 간결하고 직관적임.
동적 타이핑?
return “string hello”
⇒ return {”data” : 123} → 정적 타입이 아님코루틴 모델?
async def로 정의 된 함수 ⇒ 비동기 함수
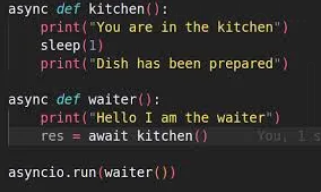
-
정책과 특징
- Python은 I/O 바운드 작업에서 뛰어난 성능을 제공한다.
- 파일 I/O, 네트워크 요청, DB Query등 블로킹 상태에서 다른 작업을 기다릴 필요 없이 병행 처리가 가능함.
- GIL의 영향: 비동기의 처리는 GIL과 무관하게 작동하므로, 멀티 스레딩이나 멀티 프로세싱에 비해 GIL의 영향을 받지 않음.
-
적합한 상황
- Web Server나 API Server 개발, 파일 I/O 작업, 네트워크 요청을 병행 처리하는 경우에 유리
- EX) 대량의 HTTP 요청을 동시에 처리해야 할 때
Python Code - 1 (with. aiohttp vs. rqeusts)
- aiohttp
import asyncio
import aiohttp
import time
# 비동기로 요청할 대상 URL 리스트
urls = [
"https://httpbin.org/delay/1" for _ in range(10) # 지연 1초짜리 요청 10개
]
# 개별 URL을 비동기적으로 fetch
async def fetch(session, url):
async with session.get(url) as response:
text = await response.text()
return text[:100] # 응답 일부만 출력
# 메인 루프
as~~ync def m~~ain():
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls] # 코루틴 객체 준비
results = await asyncio.gather(*tasks) # 코루틴 객체 동시 실
for i, result in enumerate(results):
print(f"[{i+1}] 응답 일부: {result}")
# 실행 시간 측정
start = time.time()
asyncio.run(main()) # jupyter 기준 await main()
end = time.time()
print(f"총 소요 시간: {end - start:.2f}초")awaitawait는 비동기 함수(coroutine)의 실행 결과를 기다리는 키워드async def main( )비동기 프로그램의 진입점 / 연결을 재사용
main에서await을 쓴다면async def main( )으로 선언해야 함.
⇒ 이를 실행하려면 `asyncio.sync(main( ))` 처럼 이벤트 루프를 통해 실행해야 함. ⇒ jupyter 는 이미 백그라운드에서 asyncio 이벤트 루프를 실행 중await main()으로 실행하면 됨.
aiohttp.ClientSession( )HTTP 세션을 재사용
asyncio.gather( )
⇒ return type :10개의 요청을 동시에 병렬 실행
모든 결과를 한꺼번에 기다리는 함.await된 코루틴의 결과가 들어있는list의 객체
💡async+requests를 안쓰는 이유?
requests는… 동기(blocking) 라이브러리이기 때문이다..! ⇒ 해당을 blocking I/O 라고함.
requests.get( ) : 요청을 보내고 return 값이 response 객체임. 그러면 서버 응답올 때까지 기다리게 됨.
[동작 흐름]
requests.get호출- 내부에서 HTTP 요청
- 서버 응답할 때까지 아무것도 안하고 기다림 (blocking)
- 응답이 완전히 도착하면 바로 값을 return (response 객체)
response = await requests.get(url) → 오류 발생
애초에 내부적으로 requests는 def get()으로 되어 있음.
하지만 aiohttp.ClientSession().get()
2. Multi Thread
Process는 여러 개의 Thread를 갖는다.
multi-thread는 여러가지 일을 동시에 처리하는 것을 의미
같은 프로세스 메모리를 공유한다…!
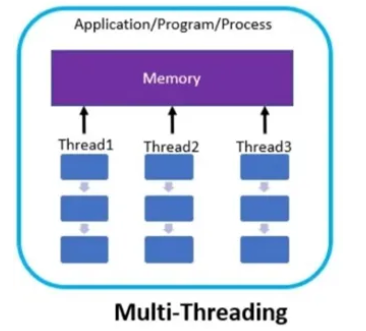
- GIL에 의해 CPU 집약적인 작업에서는 성능이 크게 향상되지 않음.
하지만 I/O 바운드 작업에서는 효율적으로 작동한다.
💡 CPU 집약적인 작업
| 작업의 대부분이 CPU 계산 능력에 의존하는 작업
- 특징
- 복잡한 연산이나 수학 계산이 많음
- EX) 암호화/복호화, 머신러닝, 과학 계산, 이미지 렌더링, 동영상 인코딩
💡 I/O 바운드 작업 ⇒ 멀티 스레드가 효율적인
| 작업의 대부분이 입출력(I/O) 대기 시간에 의존하는 작업
- 특징
- 디스크 읽기/쓰기, 네트워크 요청, 파일 열기 등 **외부 장치**와 통신이 많음
- CPU는 작업이 끝나기를 기다리며 놀고 있는 시간이 많음
- EX) Web Server, DB 쿼리, 대용량 파일 업로드/다운로드-
동적 타이핑 덕분에 스레드 간에 데이터 공유가 용이하며, GIL로 인해 스레드 간의 자원 관리가 자동으로 처리됨.
-
Why 동적 타이핑 덕분에 스레드간에 데이터 공유가 용이한가?
- 정적 typing vs. 동적 typing
- 정적 typing - Javapublic static List<String> sharedData = Collections.synchronizedList(new ArrayList<>());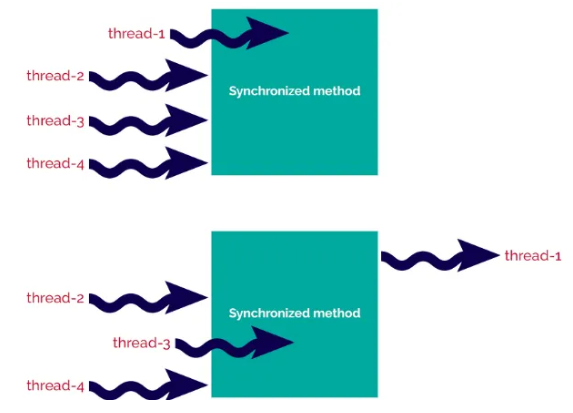
⇒ 스레드 간 공유할 때 해당과 같이
Collections.synchronizedList()⇒
synchronized처리된 메서드는 두개 이상의 thread 가 하나의 메서드에 동시에 접근할 때 Race Condition이 발생하지 않도록 한다. ⇒ 메서드에 Lock 을 건다.-
동적 typing - python
shared_data = [] # 리스트는 어떤 타입의 데이터든 담을 수 있음 def worker(): global shared_data.append shared_data.append("hello") # 그냥 전역 리스트에 추가 t1 = threading.Thread(target=worker) t2 = threading.Thread(target=worker)⇒ GIL 이 있어서 괜찮은거 아닌가?
-
GIL이 있지만 Multi Thread 로 경쟁 조건(Race Condition) 발생 시키기
import threading import time shared_number = 0 def thread_1(number): global shared_number print("number = ",end=""), print(number) for i in range(number): shared_number += 1 def thread_2(number): global shared_number print("number = ",end=""), print(number) for i in range(number): shared_number += 1 if __name__ == "__main__": threads = [ ] start_time = time.time() t1 = threading.Thread( target= thread_1, args=(50000000,) ) t1.start() threads.append(t1) t2 = threading.Thread( target= thread_2, args=(50000000,) ) t2.start() threads.append(t2) for t in threads: t.join() print("--- %s seconds ---" % (time.time() - start_time)) print("shared_number=",end=""), print(shared_number) print("end of main")[설명]
- [thread_1] 과 [thread_2]는 각자 shared_number를 50,000,000 증가 시킴 - `shared_number` +=1 연산이 비원자적연산으로 수행⇒ 즉, 각 스레드가 읽기 / 수정 / 쓰기의 순서로 작업을 하게 되는데, 이 작업이 중간에 다른 스레드에 의해 끼어들 수 있다.
이로 인해, [thread_1] 이
shared_number를 읽고 값을 수정하기 전에 [thread_2]가shared_number를 읽고 값을 수정할 수 있음.# shared_number += 1 # 내부적으로는: # 1. shared_number 읽기 # 2. 1 더하기 -> 인터프리터가 GIL 을 양보하면 문제가 발생 # 3. 다시 shared_number에 저장⇒ 해당 이유로 Python - 동적 typing 에서는
threading.Lock()과 같은 명시적 동기화 도구가 존재import threading import time shared_number = 0 lock = threading.Lock() # Lock 객체 생성 def thread_1(number): global shared_number print("number = ", end=""), print(number) for i in range(number): with lock: # Lock을 사용하여 동기화 shared_number += 1 def thread_2(number): global shared_number print("number = ", end=""), print(number) for i in range(number): with lock: # Lock을 사용하여 동기화 shared_number += 1
-
⇒ 위 예와 같이 변수를 선언하고 공유하는 것 자체는 Python의 동적 타이핑과 GIL 덕분에 Java보다 상대적으로 간단하다.
단, Lock이나 Race Condition을 명시적으로 관리하지 않으면 예기치 않은 오류가 발생할 수 있으므로, Multi Threading 환경에서는 여전히 주의가 필요하다.
-
-
-
정책과 특징
- 파이썬에서 Multi Threading은 GIL 때문에 I/O 바운드 작업에 적절함.
GIL이 존재하는 한….. 여러 Thread가 CPU에서 실제로 병렬로 작업하는 것은 불가능…
BUT, I/O 대기 시간에는 다른 Thread가 실행될 수 있어 효율적 - 하지만 레이스 컨디션은 조심… Thread 는 같은 메모리 공간을 공유하므로 상태 공유가 용이하지만, 동기화 문제 발생 → Thread 안정성을 고려한 코드가 필요
- 파이썬에서 Multi Threading은 GIL 때문에 I/O 바운드 작업에 적절함.
-
적합한 상황
- I/O 바운드 작업을 병렬로 처리하는 경우에 적합
- ex) 여러 파일을 동시에 읽거나, 네트워크 작업 요청 시, 웹크롤링
Python Code - Crawl + Preprocess with Multi Thread
Racecondition 방지하기
만약 Multi Thread를 이용하여 WebCrawling 후 데이터를 preprocess한다면?
→ 어떻게 Race Condition 을 방지하여야 할까..?
-
Thread 별로 지역변수에 저장한 후 합치기
thread = threading.Thread(target=worker, args=(url, local_results))
⇒ 해당 local_results라는 걸 for 문을 통해 생성 함첫 번째 반복 local_result1 = [] → thread1에게 전달 두 번째 반복 local_result2 = [] → thread2에게 전달 세 번째 반복 local_result3 = [] → thread3에게 전달 ⇒ 이렇게 되면 각 스레드 별로 지역 변수를 가지게 됨.import threading import requests # 결과를 담을 리스트 all_results = [] # 전처리 함수 예시 def preprocess(data): # 간단한 처리 예시 return data.get('key', '') # worker 함수 def worker(url, local_result): data = requests.get(url).json() # URL에서 JSON 데이터 가져오기 processed_data = preprocess(data) # 전처리 local_result.append(processed_data) # 지역 변수에 저장 # 메인 함수 def main(urls): threads = [] for url in urls: # 각 스레드에 지역 변수(local_results) 전달 local_results = [] # 각 스레드의 지역 변수 thread = threading.Thread(target=worker, args=(url, local_results)) threads.append(thread) thread.start() # 모든 스레드가 끝날 때까지 대기 for thread in threads: thread.join() # 병합 작업은 메인 스레드에서 수행 all_results.extend(local_results) print("결과:", all_results) # 실행 예시 urls = ["https://jsonplaceholder.typicode.com/posts/1", "https://jsonplaceholder.typicode.com/posts/2"] main(urls) -
Lock 사용
공유 자원에 접근할 때 Lock을 사용하여 동기화 하는 방식
⇒ 이전 내용에서 설명됨.
-
Queue 사용
queue.Queue는 thread-safe한 큐
Queue()의 (def put()-self.mutex): 스레드 간 서로 다른 작업이 동시에 실행되지 않도록 제어하는 락import threading import requests from queue import Queue # Queue 객체 생성 result_queue = Queue() # 전처리 함수 예시 def preprocess(data): return data.get('key', '') # worker 함수 def worker(url): data = requests.get(url).json() # URL에서 JSON 데이터 가져오기 result = preprocess(data) # 전처리 result_queue.put(result) # 큐에 결과 넣기 # 메인 함수 def main(urls): threads = [] for url in urls: thread = threading.Thread(target=worker, args=(url,)) threads.append(thread) thread.start() for thread in threads: thread.join() # 큐에서 결과를 꺼내서 리스트에 저장 all_results = [] while not result_queue.empty(): all_results.append(result_queue.get()) print("결과:", all_results) # 실행 예시 urls = ["https://jsonplaceholder.typicode.com/posts/1", "https://jsonplaceholder.typicode.com/posts/2"] main(urls)
3. Multi Process
두개 이상 다수의 프로세서(
CPU)가 협력적으로 하나 이상의 작업(Task)을 동시에 처리하는 것이다. (병렬처리)
3-1. 사전 지식 : CPU Core(Multi Core vs. Single Core) + Context Switching
Single Core vs. Multi Core
2000년 대 초반까지는 Single 코어 구조의 CPU를 사용함.
보통 CPU의 성능을 높이기 위해서는 Clock 속도(컴퓨터 프로세서의 동작 속도) 를 증가시키는 것이 일반적.
→ 그러나, 이는 전력 소모도 커지고 클럭 속도 증가만으로 성능 향상이 어려워지는 한계가 발생.
→ 이 때문에, 2005년 이후 CPU 성능 향상의 방향이 “Multi Core”로 전환 됨.
💡 Single Core CPU?
> 하나의 Core 만을 사용하여 모든 연산을 수행하는 프로세서
💡 Multi Core CPU?
> 하나의 프로세서 내부에 여러 개의 코어를 포함하여 여러 작업을 동시에 실행할 수 있도록 설계된 아키텍처CPU → Core → Hyper Threading
- CPU
- 컴퓨터의 두뇌 전체
- 여러 개의 물리적 코어를 가질 수 있음. ⇒ Multi Core
- Core
- 실질적으로 명령어를 실행하는 단위
- 기본적으로 1개의 명령어 흐름(= 1개의 스레드)을 처리 가능
- Hyper Threading
- 하나의 물리 코어가 2개 이상의 명령어 흐름을 처리할 수 있도록 만든 기술
- 하나의 물리 코어를 2개의 “논리 코어” or “하드웨어 스레드”로 나누는 기술
- 병렬성이 올라감
- 논리 코어 / 하드웨어 스레드
- OS 입장에서는 하나의 독립된 실행 단위처럼 보이는 가상 코어
- 물리 코어 내부 자원을 공유하면서 동시에 두 스드를 실행하는 것처럼 동작함.
"CPU가 코어로 쪼개지고,
그 코어를 또 쪼개는게 하이퍼스레딩이고
그 방법으로 논리 코어 / 하드웨어 스레드로 구현될 수 있다?”
Context Switching
프로그래밍에서 Context?
(동작, 작업들의 집합)을 (정의, 관리, 실행)하도록 하는 (최소한의 상태, 재료, 속성)을 포함하는 (객체, 구조체, 정보)이다.
def task(name):
for i in range(3):
print(f"{name} ({os.getpid()}) is working on {i}")
time.sleep(0.01) # I/O 대기: 이 시점에서 다른 프로세스로 스위칭
# 해당 함수를 이용하여 Multi Processing 실행 코드🤏 만약 위 코드처럼 process에 들어갈 함수에 time.sleep 이 있다고 하자..!
time.sleep()자체가 CPU를 계속 사용하는 게 아닙니다. 오히려 CPU 사용을 자발적으로 멈추는 신호
이해하기 쉬운 상황
(Single Core 기준으로 설명 혹은 사용 가능한 Core 개수 < 생성된 프로세스 개수 가정)
혹은 Core 1번을 기준으로 우리가 해당 두개의 Multi Process를 수행한다고 가정하자.
1. Process_1이 Core를 사용
⬇️Process_1이 Core 1번을 할당받고 실행.
⬇️Process_1의 상태(PCB)가 Core 1번에 로드.
2. Process_1이
time.sleep(0.01)을 호출
⬇️time.sleep(0.01)호출로 CPU 자원 반납.
⬇️Process_1은 대기 상태로 들어가고 Core 1번은 비어 있음.
3. Core가 비어있음
⬇️Process_1이 대기 상태이므로 Core 1번은 비어 있음.
⬇️ 다른 프로세스가 할당될 수 있는 상태.
4. Process_2가 Core를 사용
⬇️Process_2가 Core 1번을 할당받고 실행.\
⬇️Process_2의 상태(PCB)가 Core 1번에 로드됨.
5. Process_2가
time.sleep(0.01)을 호출
⬇️time.sleep(0.01)호출로 CPU 자원 반납.
⬇️Process_2도 대기 상태로 들어가고 Core 1번은 다시 비어 있음.
⇒ 이로 인해, 잦은 CPU 자원을 자주 반납하고 load(context Switching)하면서 오버헤드 발생
3-2. Multi-Processing
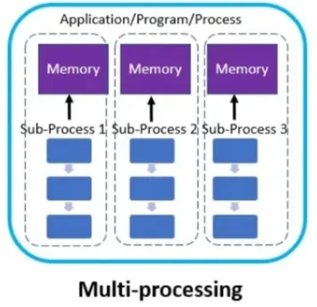
-
파이썬 특성과 연관
- 파이썬의 GIL 때문에 CPU 집약적인 작업에서는 Multi Processing 이 더 나은 성능을 보인다.
- 각 프로세스는 독립적인 메모리 공간을 가지므로 안전한 병렬 처리가 가능하다.
-
정책과 특징
- Multi Processing은 Python 에서 CPU 바운드 작업을 병렬로 처리하기에 가장 적합합니다. 파이썬의 GIL이 프로세스 간에 영향을 미치지 않기 때문입니다. ⇒ CPU를 많이 사용하는 계산이나 연산에서 효율성을 발휘합니다.
- 다만, 프로세스간 메모리를 공유하지 않고 독립적인 주소 공간을 가지므로, 프로세스 간에 데이터를 공유하려면 직렬화(Serialization)가 필요하고 프로세스 간 통신(IPC : Inter Process Communication)이 필요하기에 오버헤드가 발생할 수 있다.
- Context Switching 시 오버헤드가 많이 발생할 수 있다.
- Context Switching 시 왜 오버헤드가 많이 발생할 수 있는가? Multi Thread 보다
Multi Thread는?
메모리 공간을 공유하기 때문에 스레드 간 상태 전환이 간단Multi Process는?
- 프로세스 상태 저장
현재 실행 중인 프로세스의 상태(레지스터, 스택 등)를 메모리에 저장 - 새로운 프로세스의 상태 로드
새로운 프로세스를 CPU에서 실행하려면 해당 프로세스의 상태를 메모리에서 불러와야 합니다. 이때 메모리 영역이 바뀌고, 프로세스 간 상태 전환
⇒ 이 때, 캐시 미스나 페이지 폴트가 발생하면, CPU는 메모리에서 데이터를 읽어오는 시간이 추가로 발생하고, 이로 인해 오버헤드가 커집니다.
- 프로세스 상태 저장
- Context Switching 시 왜 오버헤드가 많이 발생할 수 있는가? Multi Thread 보다
-
적합한 상황
- CPU 집약적인 작업을 병렬로 처리해야 할 때 (이미지 처리, 대규모 수치 계산, 데이터 분석)
- EX) 데이터 과학에서 큰 데이터 셋을 여러 프로세스로 분할하여 처리할 때
Code - Basic : Multi Process
from multiprocessing import Pool
def square(n):
return n * n
if __name__ == "__main__":
numbers = list(range(10))
with Pool(processes=4) as pool:
results = pool.map(square, numbers)
print(results)with Pool() as pool 은 밑에서 한번에 설명하겠음…!
Code- Data Preprocess : Multi Process (pandas)
- library
import pandas as pd import os import time from multiprocessing import Pool from concurrent.futures import ThreadPoolExecutor - def read_csv(file_path)
def read_csv(file_path): return pd.read_csv(file_path) - def read_multiple_csv(files)
여러 개의 파일을 병렬로 읽음.
⇒ I/O 작업 ⇒ Multi Threading 으로 실행def read_multiple_csv(files): with ThreadPoolExecutor(max_workers=4) as executor: return list(executor.map(read_csv, files)) # => func,with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:`return list(executor.map(func, iterable))`- 멀티 스레딩 기반 → 내부적으로
threading을 사용 max_workers: 최대 스레드 개수func: 함수iterable: 반복 가능한 객체 (ex) [1,2,3,4,5])
- 멀티 스레딩 기반 → 내부적으로
- def process_data(data)
Pandas Dataframe에 대해 평균 값을 계산하는 간단한 처리
⇒ CPU 사용 작업 ⇒ 멀티 프로세스를 사용def process_data(data): return data.mean() - def process_files(files):
CSV 파일 스레드로 병렬 읽기 → 반환된 리스트는 Dataframe 목록
def process_files(files): data_frames = read_multiple_csv(files) # 스레드로 병렬 CSV 읽기 with Pool(processes=4) as pool: results = pool.map(process_data, data_frames) # 프로세스로 병렬 데이터 처리 return resultswith multiprocessing.Pool(processes=processes) as pool:`results = pool.map(func, iterable)`- multiprocessing 사용
processes: 최대 프로세스를 사용 개수func: 함수iterable: 반복 가능한 객체
- main
main 함수
if __name__ == "__main__": # CSV 파일 경로들 (여러 개) file_paths = ['data1.csv', 'data2.csv', 'data3.csv', 'data4.csv'] # 데이터 처리 시작 시간 start_time = time.time() # 데이터 파일 처리 results = process_files(file_paths) # 결과 출력 print("각 CSV 파일의 열 평균값:", results) # 소요 시간 출력 print(f"총 소요 시간: {time.time() - start_time:.2f}초")
최종 정리
💡병렬처리 극대화하기
상황 용량이 큰 여러 개 CSV를 불러오고 큰 CSV들을 처리해야 한다…?
데이터 불러오기 ⇒ I/O Bound 작업 ⇒ Multi Thread
데이터 처리 ⇒ CPU Bound 작업 ⇒ Multi Process
[나의 생각]
어차피 Process 안에서 thread로 나눠지면 리소스 사용량을 극대화하려면 Multi Process 안에 Multi thread로 처리할 수 있는 경우도 있지 않을까?
- 해당 프로세스 내에서 스레드 간의 Race Condition 을 주의한다는 가정하에?
- 또한 프로세스와 스레드의 이점을 정확히 이해하고 쓸수있는 작업과 코드라면?
