Index
인덱스(Index)는?
DB 테이블에 대한 검색 속도를 높여주는 자료 구조
인덱싱은?
이러한 인덱스를 DB에 남기는 것
Indexing을 사용하는 이유
우리가 테이블을 생성하고 데이터가 쌓이면, 테이블의 레코드는 내부적으로 순서가 없이 뒤죽박죽으로 저장한다.
⇒ 이 상황에서는 where절에 특정 조건에 부합하는 데이터들을 조회할 때에도 레코드의 처음부터 끝까지 다 읽어서 검색 조건과 맞는지 비교해야 함. → 이것을 Full Table Scan 이라 함.
- 이 경우 테이블에 데이터가 적다면? 성능에 영향을 주지 않음.
- 수십만개의 데이터가 들어있는 경우? 성능 저하 생김.
이와 같이 DB를 다룰 때 대부분의 성능 저하는 조회 쿼리에서 나타남.
특히 where 절에서 많이 발생함.
이럴 때 가장 먼저 생각해 볼 수 있는 대안이 인덱스 가 될 수 있음.
Indexing 동작 방식
먼저 해당 테이블을 생성 시 생성하고 싶은 인덱스 컬럼을 지정
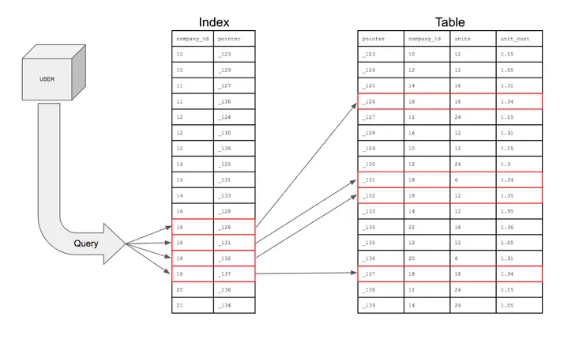
특정 컬럼에 대한 인덱스를 생성하면?
해당 컬럼의 데이터들을 정렬하여 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장된다.
- Index 생성 Query
-- 1. 테이블 생성
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
age INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 2. 단일 인덱스 생성
CREATE INDEX idx_email ON users(email);
CREATE INDEX idx_age ON users(age);
-- 3. 복합 인덱스 생성
-- 복합 인덱스는 왼쪽부터 사용가능
-- WHERE email = 'a@example.com' ✅ 사용됨
-- WHERE created_at = '2023-01-01' ❌ 인덱스 사용 안 됨
-- WHERE email = 'a@example.com' AND created_at >= '2023-01-01' ✅ 사용됨
CREATE INDEX idx_email_created_at ON users(email, created_at);
-- 4. 유니크 인덱스 (중복 방지)
CREATE UNIQUE INDEX uniq_email ON users(email);인덱스가 생성되면 해당 컬럼에 대한 Where 조건문을 사용하여 쿼리를 날릴 때
Optimizer에 의해 판단되어 생성된 인덱스를 탈 수 있게 되고,
인덱스에 저장되어 있는 데이터의 물리적 주소로 가서 데이터를 가져오는 방식으로 동작하여 검색 속도의 향상을 가져올 수 있는 것이다.

WannaB.E/D.E