문득문득
1.문득문득 소개글

해당 시리즈는 제가 그냥 공부하면서 궁금하던걸 그때 그때 키워드로 넣고 공부하는 시리즈입니다.
2.[Network] : REST API vs. Web Socket
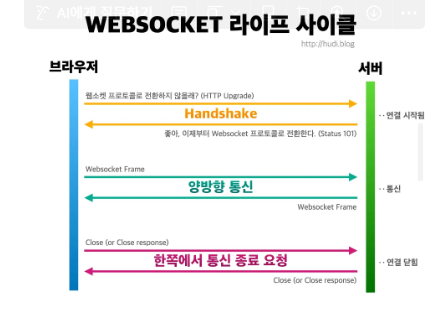
Web Socket을 관리한다고 많이 들었는데 Web Socket이 정확히 뭐고..? Rest API 이런 것들과 어떤차이인지…잘 모르겠어서 미리미리 찾아보기REpresentational State Transfer?자원을 이름으로 구분하여 해당 자원의 상태를 주고 받는
3.[DB] PostgreSQL ⇒ OLTP ..? OLAP ..? - (Citus+ cstore_fdw)
나는 RedShift는 OLAP DB로 알고 있고 PostgreSQL이 기반이 되어서 당연히 PostgreSQL이 OLAP DB라고 생각했다.그런데 왜 OLTP 라고 하는걸까…?PostgreSQL은 오픈소스 객체-관계형 데이터베이스 관리 시스템 (ORDBMS)이다.Po
4.[Python] : Python 정책
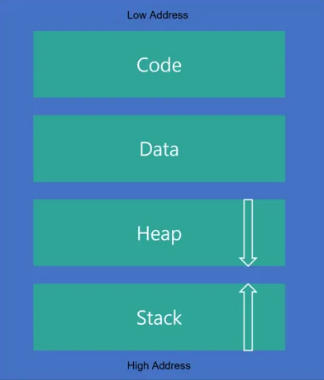
Python은 GIL 을 통해 한 번에 하나의 스레드만 실행하도록 제한한다.⇒ CPython Interpreter 에서 하나의 스레드만 동시에 Python 바이트코드를 실행하도록 제한하는 lock 이다.WhyPython Interpreter Python Interpr
5.[Python] Async & Multi Process & Multi Thread
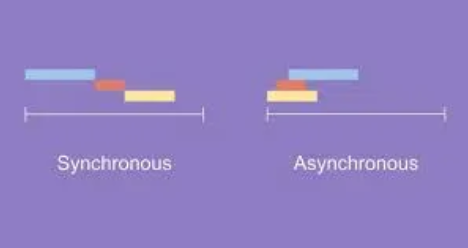
비동기는 동시에 일어나지 않는다.를 의미하나의 요청에 따른 응답을 즉시 처리하지 않아도, 그 대기 시간동안 또 다른 요청에 대해 처리 가능한 방식파이썬 특성과 연관I/O 바운드 작업에서 가장 큰 장점을 보임 ⇒ async 설계 방식Python의 동적 타이핑과 코루틴 모
6.[DB] Full Scan? Index
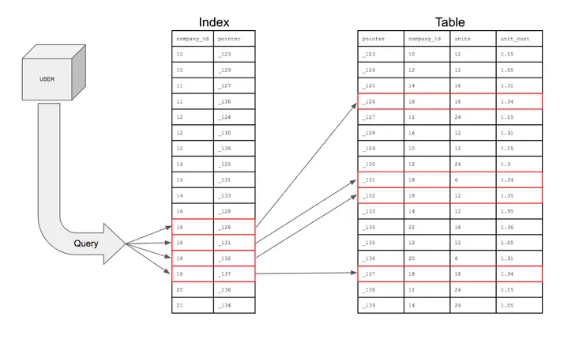
인덱스(Index) 는?DB 테이블에 대한 검색 속도를 높여주는 자료 구조인덱싱 은?이러한 인덱스를 DB에 남기는 것우리가 테이블을 생성하고 데이터가 쌓이면, 테이블의 레코드는 내부적으로 순서가 없이 뒤죽박죽으로 저장한다.⇒ 이 상황에서는 where절에 특정 조건에 부
7.[DB] 데이터베이스의 캐싱 계층 with Redis (Backend 관점)
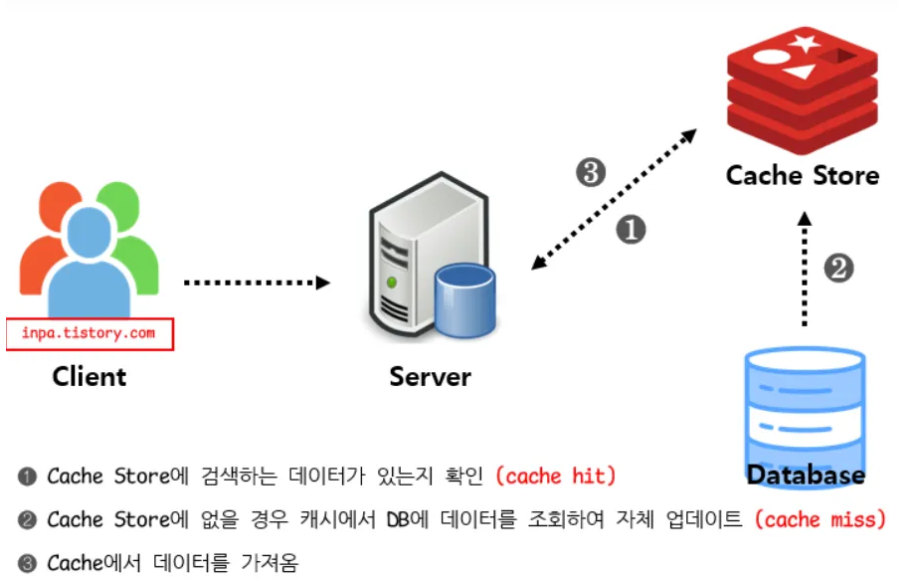
자주 사용하는 데이터를 메모리 기반 저장소(In-Memory DB)에 저장해 두고 성능을 올리는 계층데이터베이스 시스템을 구축할 때도 메인 데이터베이스 위에 redis 데이터 베이스 계층을 캐싱 계층 으로 둬서 성능을 향상시키도 한다.DB 를 직접 조회하는 대신, 캐시
8.[SQL Engine] Apache Impala 파헤치기
Apache Impala? > 아파치 임팔라(Apache Impala)? > Apache Hadoop을 실행하는 컴퓨터 클러스터에 저장된 데이터를 위한 오픈 소스 대규모 병렬 처리(MPP) SQL 쿼리 엔진 입니다. > 빅데이터 분석을 In-Memory 기반 의 실시
9.[SQL Engine] Trino 파헤치기 - 정리중
Trino > ### Trino? 하나 이상의 heterogeneous data sources (서로 다른 종류의 데이터 저장소들)에 분산된 대규모 데이터를 쿼리하도록 설계된 오픈소스 분산 SQL 쿼리 엔진 리브랜딩 Presto 고성능, 확장성, 다양한 데이터 소스
10.[Python] LRU Cache With Python

사전지식 컴퓨터 메모리 계층 구조 > CPU Register => L1 캐시 => L2 캐시 => L3 캐시 -> CPU 내부 => Main Memory => Disk => 네트워크 or DB -> CPU 외부 => CPU는 연산을 하기 전에 위 순서대로 데이터를
11.[DB] 다중 Pod에서 트랜잭션 동시성과 롤백, 트랜잭션 설계방식 및 Temporal 개념
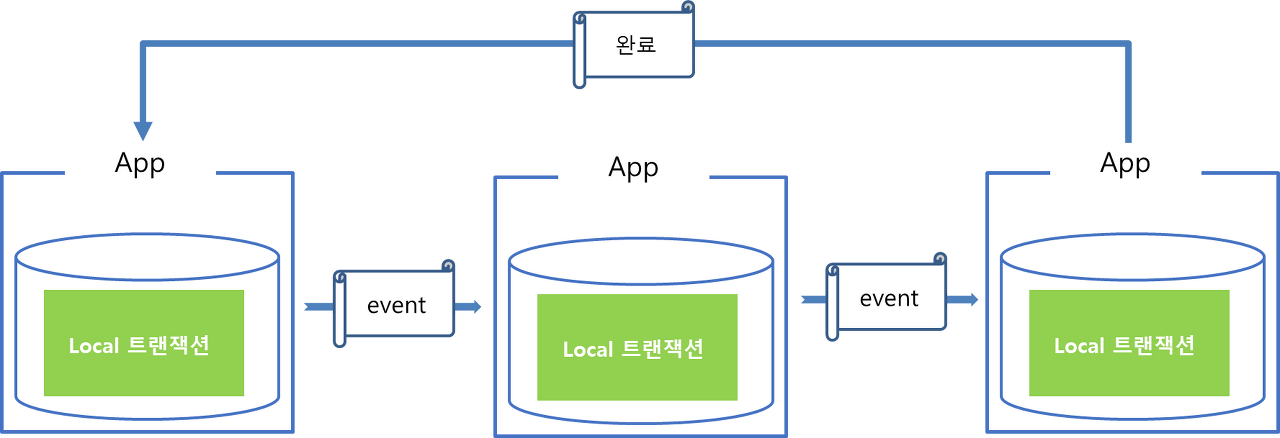
📘 책: 주니어 백엔드 개발자가 반드시 알아야 할 실무지식을 공부하다가‘글로벌 트랜잭션(Global Transaction)’이라는 개념을 접하게 되었다.여러 자원(예: 서로 다른 데이터베이스나 외부 시스템)에 대한 변경을하나의 트랜잭션으로 묶어 일관성 있게 처리할 수
12.[Backend] : Session? Cookie? Token?
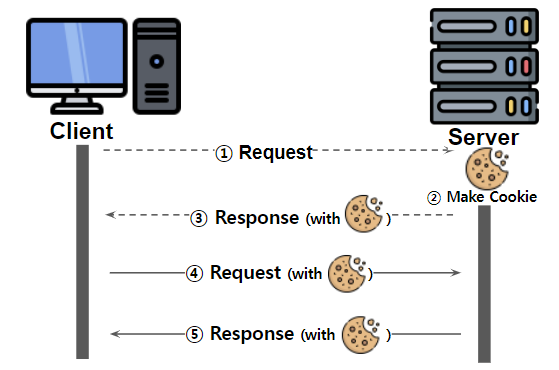
Session Cookie?
13.[Network] HTTPS / CA인증서 / Cert-Manager / Lets'Encrypt? 정리

해당 글을 쓰는 이유 > 사내 서버에 gitlab을 구축하려다보니, 기존에 구축되어 있는 cert-manager 리소스들과 충돌이 날 거 같아, gitlab yaml 을 커스텀하고 cert-manager 충돌을 막을려고 하다보니, CA / SSL/TLS/KEY / Ce
14.[CICD] GitLab 기본 개념 및 설치
해당 글을 쓰는 이유는 현재 학교 프라이빗망 내의 Infra에서 CICD를 구축하고자 하였다. 하지만 깃허브와 같은 SCM(Source Code Management)에서 프라이빗망 내의 인프라로 CI나 CD가 안될거 같았다. 다음과 같은 구조다. > SCM : GitH
15.[CICD] Jenkins 기본 개념 및 설치
Jenkins? > ### [특징] 가장 오래되고 강력한 CI 서버 모든 기능 커스텀 가능 온프레미스 또는 클라우드 어디든 설치 가능 > ### [구조] Master / Contrller : Jenkins 서버 Agent / Node : 실제 빌드가 돌아가는 서버
16.[DB] CDC - 개념 및 실습(KafkaConnect, Debezium) - 작성 중(수정 필요)
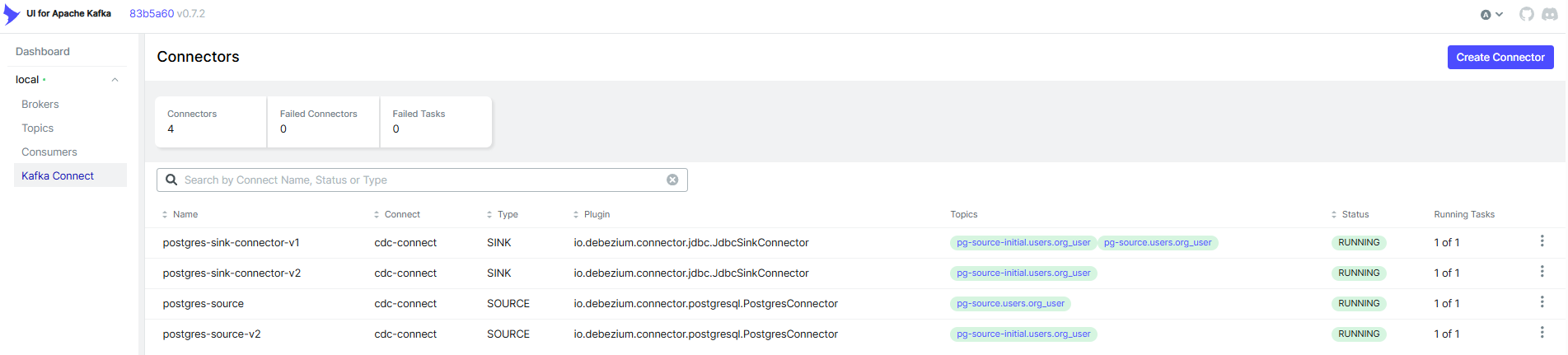
오랜만에 velog를... 최근에는 notion 에 AWS-DEA 내용을 정리하고, 뭐 이래저래 바빴구만... > 오늘은 CDC 개념 및 실습이다. > 계속 Debezium 과 메시징 큐를 이용해서 이기종 DB 동기화를 어느정도 해보고 싶었어서, 개념 및 기술 플로우