사전지식
- 컴퓨터 메모리 계층 구조
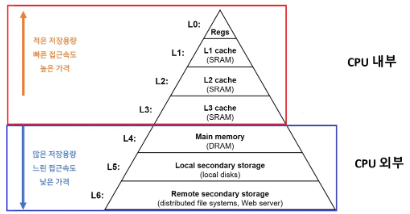
CPU Register => L1 캐시 => L2 캐시 => L3 캐시
-> CPU 내부
=> Main Memory => Disk => 네트워크 or DB
-> CPU 외부
=> CPU는 연산을 하기 전에 위 순서대로 데이터를 찾고 가까운 곳에 있으면 빠르게 처리함.
- 그럼 Python은 어떻게... 저장?
python 레벨에서는 Register ~ L1 ~ L3 캐시까지 직접 제어불가
CPU가 자동으로 L1 ~ L3로 캐싱
Main Memory(RAM) 모든 변수, 객체 함수, 코드가 여기 저장됨
=> Python 변수, List, Dict, 함수 객체 등은 모두 Main Memory(RAM)에 저장
(ex) 변수를 저장해보자.
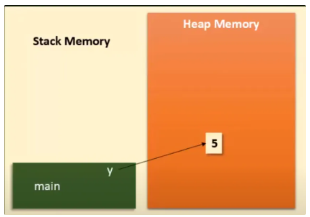
x = [1, 2, 3]-
x: 변수 이름 -> RAM의 스택 영역에 저장x는 이름일 뿐이고, 힙 영역에 있는 리스트의 주소 를 가리킴.
-
[1, 2, 3]: 객체는 -> RAM의 힙 영역에 저장- 실제 리스트 데이터가 들어있는 객체
-
파이썬 코드 실행되는 순서
파이썬 코드
↓
파이썬 인터프리터 (CPython)
↓
바이트코드 (.pyc)
↓
파이썬 가상 머신 (PVM)
↓
C 코드 → CPU 명령어
↓
CPU 메모리 계층 접근 (레지스터 → 캐시 → RAM 등)
↓
계산 수행, 결과 출력=> 여기서 레지스터 -> 캐시는 하드웨어가 자동적으로 함.
Cache 란?
Cache는 뭐 다들 아실거라 생각하지만…!
자주 쓰는 데이터를 잠깐 저장해두는 장소입니다.
왜냐? 데이터를 매번 다시 계산하거나 외부에서 불러오는 건 느리고 비효율적이기 때문…!
💡외부라…?
여기서 말하는 ‘외부’는 CPU보다 느린 저장 위치들을 의미합니다.
- RAM
- 디스크 (HDD/SSD)
- 네트워크 - API, DB 조회, 웹 요청, 파일 읽기
LRU란?
LRU는 Least Recently Used 의 줄임말
⇒ 가장 오랫동안 사용되지 않은 데이터를 버리는 방식
왜냐? 캐시 공간이 한정되어 있기에… 오래 안 쓰는 데이터는 버리고 새로운 데이터를 넣는 전략
python에서는 직접적으로 L1/L2/L3 캐시를 직접 컨트롤하지 못한다.
하지만, 파이썬 코드들로 “cache layer”를 MainMemory(RAM) 위에서 소프트웨어적으로 구현할 수 있다.
⇒ 파이썬 내부에서 자료구조와 알고리즘으로 직접 구현하다.
⇒ 그게 바로 functools의@cache,@lru_cache와collection.OrderDict이다.
python LRU Cache 구현(1)_ collection.OrderDict
OrderDict란?
기본 Dictionary 와 거의 비슷하지만 입력된 아이템들(items)의 순서를 기억하는Dictionary클래스이다.
⇒ 이걸 활용하면 가장 오래된 데이터부터 제거하는 LRU 방식을 쉽게 구현할 수 있다.
- 기본 구조 : Hash Table + 이중 연결 리스트
(last=True): 맨 끝 항목(최근 사용.)(last=False): 맨 앞 항목(가장 오래됨.)- OrderDict Method
from collections import OrderDict
od = OrderDict()| Method | Descript |
|---|---|
| od[key] = value | 항목 추가 |
| od.get(key) | key 조회 |
| del od[key] | 특정 key 삭제 |
| od.pop(key) | key 제거 및 반환 |
| od.popitem(last=True) | 마지막(또는 처음)의 항목을 제거하고 반환(last=True) : 맨 끝 항목(last=False) : 맨 앞 항목 → LRU |
| od.move_to_end(key, last=True) | key를 맨 끝이나 맨 앞으로 이동(last=True) : 맨 끝 항목(최근 사용.)(last=False) : 맨 앞 항목(가장 오래됨.) |
| od.clear() | 전체 항목 삭제 → 캐시 비우기와 같음 |
Class 정의
from collections import OrderDict
class LRUCache:
def __init__(self, capacity):
self.cache = OrderDict()
self.capacity = capacitycapacity: LRU 캐시나 담을 수 있는 최대 아이템 수self.cache: 실제 데이터를 저장할OrderDict
⇒ 최신 데이터는 뒤에, 오래된 데이터는 앞에 위치
Method : get - 값 읽기
def get(self, key):
# cache에 key가 존재하지 않으면?
if key not in sellf.cache:
return -1
# key가 존재하면?
self.cache.move_to_end(key) # 최근 사용 -> 맨 뒤로 이동(갱신)
return self.cache[key] # 값 returnMethod : put - 값 삽입/갱신
def put(self, key, value):
if key in self.cache:
self.cache.move_to_end(key) # key가 이미 있으면 위치 갱신
self.cache[key] = value
if len(self.cache) > self.capacity: # 현재 cache 된 크기 > 최대 cache 크기
self.cache.popitem(last=False) # 가장 오래된 key (맨 처음 요소) 제거해당을 구현하여 놓고 어떻게 쓰느냐?
예제 문제
[Fibonacci 수열 문제]
정수 n 이 주어졌을 때, n! 팩토리얼을 구하는 함수를 작성하세요. 팩토리얼은 n이 0일 때는 1 이고, 그 외에는 n (n-1) … * 1 이다.
ex)
- 5! = 5 4 3 2 1 = 120
- 3! = 3 2 1 = 6
- 0! = 1
(n은 0이상의 정수)
[접근 방식? 왜 LRU 인가?]
Fibonacci 특성 상 반복문 혹은 재귀를 사용하여 n! 값을 계산하는 것이다.
⇒ 그러나 이 문제에서 LRU Cache를 사용하는 이유는 중복 계산을 방지하고 이미 계산된 팩토리얼 값을 캐시하여 효율적인 성능 개선을 도모 할 수 있다.
1. no LRU_Cache
# 반복문 => 연산량
def factorial(n: int) -> int:
result = 1
for i in range(2, n+1):
result*=i
return result
# 첫 번째 호출
factorial(5)
# 두 번째 호출
factorial(5)
# 문제점
# => 동일한 연산을 두번해야 함...
# => 이 숫자가 커진다면 매번 동일한 큰 계산을 반복하게 됨.def factorial(n: int) -> int:
if n == 0:
return 1
return n * factorial(n - 1)
# 테스트
print(factorial(5)) # 120
# 문제점
# => factorial(5) 호출 시 => 5 * factorial(4) 호출
# => factorial(4) 호출 시 => 4 * factorial(3) 호출
# => factorial(3) 호출 시 => 3 * factorial(2) 호출
# => factorial(2) 호출 시 => 2 * factorial(1) 호출
# => factorial(1) 호출 시 => 1 * factorial(0) 호출 => facotrial(0)은 1을 반환
# 해당도 위와 동일하게 두번째 호출될 때도 같은 계산을 반복하게 됨. 2. Using LRU_Cache
import time
from collections import OrderedDict
# LRU Cache Class ~~~
# LRU 캐시를 사용하는 팩토리얼 계산
def factorial_with_cache(n: int, cache: LRUCache) -> int:
# cache 된 것이 있다면? 바로 사용
if cache.get(n) != -1:
return cache.get(n)
if n == 0:
return 1
result = n * factorial_with_cache(n - 1, cache)
cache.put(n, result)
return result
# 기본 재귀적 팩토리얼 계산
def factorial_recursive(n: int) -> int:
if n == 0:
return 1
return n * factorial_recursive(n - 1)# 성능 비교 함수
def performance_comparison(n: int):
# LRU 캐시 초기화
cache = LRUCache(100) # 충분히 큰 캐시 크기 설정
# 기본 재귀적 팩토리얼 계산 성능
start_time = time.time()
factorial_recursive(n)
end_time = time.time()
print(f"Recursive factorial time: {end_time - start_time:.6f} seconds")
# LRU 캐시를 사용하는 팩토리얼 계산 성능
start_time = time.time()
factorial_with_cache(n, cache)
end_time = time.time()
print(f"LRU Cache factorial time: {end_time - start_time:.6f} seconds")
# 테스트: 팩토리얼 계산에 대해 성능 비교 (예: n = 20000)
performance_comparison(2000)
⇒ 극적인 결과지만, 항상 이런 것은 아니다.
LRU Time이 더 느리게 나오는 이유?
factorial_recursive가 더 빠르게 실행된 이유는 LRU 캐시를 사용하면서 발생한 추가적인 오버헤드 때문입니다.
작은 수에 대해서는 캐시의 이점이 거의 없고, 캐시 관리 작업에서 발생하는 오버헤드로 인해 성능이 더 낮게 측정될 수 있습니다.
반면, 큰 n 값에서는 LRU 캐시의 효과가 더 뚜렷해져서 성능 차이가 발생할 수 있습니다.
[결론]
캐시가 큰 n 값에 대해 유리하므로, 성능 비교 시n을 더 크게 설정하면 더 명확한 성능 차이를 볼 수 있습니다.
[추가]
캐시 용량 증가:LRUCache의 용량을 충분히 크게 설정하여, 더 많은 값을 캐싱할 수 있도록 합니다.
python LRU Cache 구현(1)_functools.lru_cache
-
@cache내용- python code
from functools import cache, lru_cache def fibonacci(n): if n<2: return n return fibonacci(n-1) + fibonacci(n-2) @cache def fibonacci_cache(n): if n < 2: return n return fibonacci_cache(n-1) + fibonacci_cache(n-2)[결과]
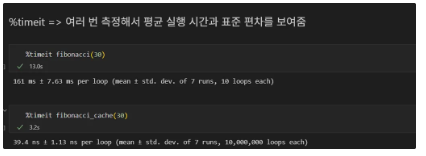
[한계]
@cache는 메모리와 관련된 한계가 있다.@cache는 캐시 크기를 제한할 수 없다…..
⇒ 프로세스가 중지될 때까지 남아 있기에 메모리 폭주 위험이 있다…
⇒ 실제 서비스 한다면? 캐싱이 얼마나 많은 메모리가 필요한지 추측이 불가 함..
Ref : https://devocean.sk.com/blog/techBoardDetail.do?ID=165900&boardType=techBlog
@lru_cache(maxsize = ?)내용functools에는 캐싱 메커니즘에서 사용하는 알고리즘이기도 하지만,
@cache의 메모리 폭주를 막아 줄 수 있는lru_cache기능이 존재한다.
그 이유는maxsize때문이다.import random import string import tracemalloc from functools import lru_cache @lru_cache(maxsize=1000) def get_user_data(user_id): return { "유저ID": user_id, "이름": "유저 " + str(user_id), "이메일": f"user{user_id}@example.com", "나이": random.randint(18, 60), "자기소개": ''.join(random.choices(string.ascii_letters, k=1000)) } def simulate(n): tracemalloc.start() for i in range(n): _ = get_user_data(i) if i % 100 == 0: current, peak = tracemalloc.get_traced_memory() print(f"Iteration {i}: 현재 메모리 사용량(MB): {current/(1024**2):.3f} MB") tracemalloc.stop()
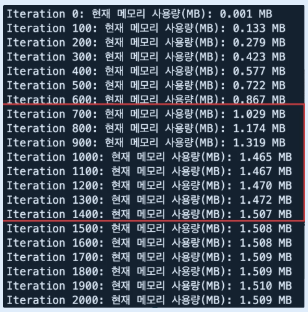
1.5MB 부터 메모리가 안정화 되는 것을 볼 수 있다.
⇒ 그 이유는 maxsize를 걸어놓고 캐시를 계속하다가 maxsize보다 커지려고 할 때 앞쪽에 오랫동안 사용되지 않은 것은 삭제하기 때문이다!
💡 이 친구들도 내부적으로
OrderDict로 구현하였는가?[GPT]
Python 3.2~3.7까지는OrderedDict를 직접 사용했고
⇒ 간단하지만 상대적으로 느림Python 3.8부터
functools.lru_cache는 C로 구현된 이중 연결 리스트 (doubly linked list) 와 dict의 조합을 사용하여 LRU 캐시를 최적화합니다.
⇒ 빠르고 메모리 효율도 좋음
