Trino

Trino?
하나 이상의 heterogeneous data sources (서로 다른 종류의 데이터 저장소들)에 분산된 대규모 데이터를 쿼리하도록 설계된 오픈소스 분산 SQL 쿼리 엔진
- 리브랜딩 Presto
- 고성능, 확장성, 다양한 데이터 소스 지원을 갖춘 분산 SQL 엔진으로, 데이터 웨어하우스 및 데이터 레이크에서 실시간 분석 및 이종 데이터 통합 분석을 가능하게 한다.
Why Trino - 주요 특징
고성능 SQL 쿼리 엔진
Trino는 데이터 웨어하우징 및 분석(데이터 분석, 대량 데이터 집계 및 보고서 생성)을 처리하도록 설계되었습니다.
=> 이러한 작업은 OLAP로 분류됩니다.
MPP
Trino는 MPP 아키텍처를 사용하여 분산 환경에서 빠른 쿼리 처리가 가능함.
다양한 데이터 소스 지원
하나의 Trino 클러스터에서 여러 데이터 소스(Hive, Iceberg, MySQL, PostgreSQL, Kafka, MongoDB 등)에 동시에 쿼리 가능.
데이터 이동 없이 직접 분석할 수 있어, => 데이터 엔지니어링 및 ETL 비용 절감 가능.
클라우드 및 온프레미스 환경 지원
AWS, GCP, Azure 같은 클라우드 환경에서도 데이터 웨어하우스 대체 솔루션으로 사용 가능.Kubernetes, Docker 등 컨테이너 기반 배포 및 관리 가능.
대규모 확장성(Scalability)
수천 개의 노드로 확장 가능하여 페타바이트(PB) 단위의 데이터도 빠르게 분석할 수 있음.고성능 쿼리 실행을 위해 메모리 내 처리 방식(memory-based processing) 사용.
Trino Architecture
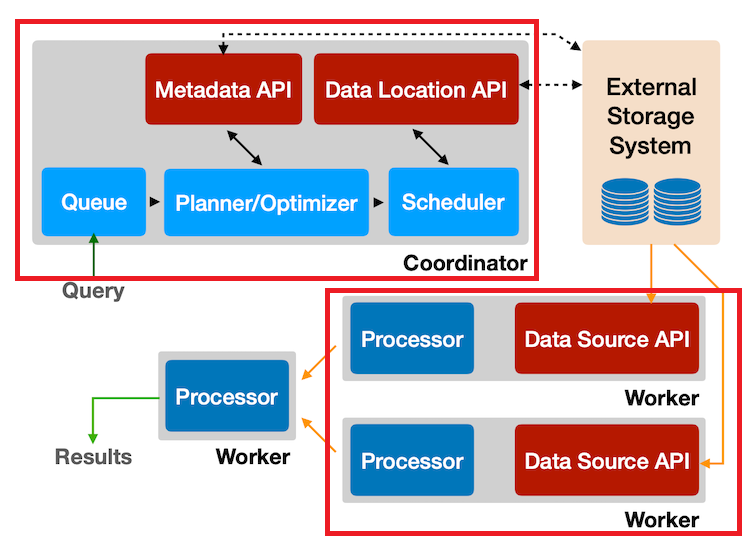
Trino는Coordinator(조정 노드)+Worker(작업 노드)로 구성
Coordinator
Coordinator는 구문 분석, 쿼리 계획, Worker 노드 관리와 같은일을 함.
Worker
Worker는 실제 Task를 실행하고 데이터 처리를 담당함.
Trino WorkFlow
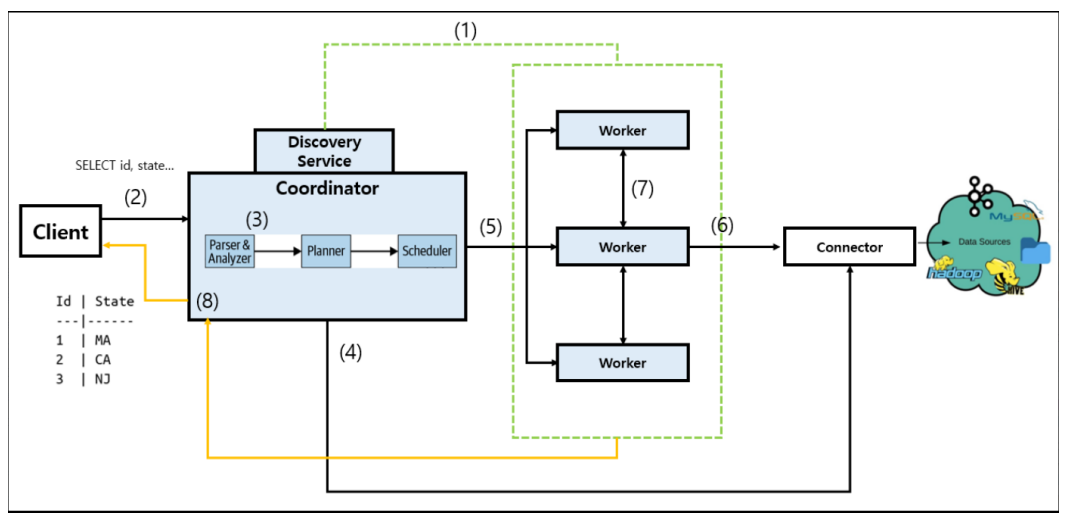
(1). Trino Worker 프로세스가 시작하면?
Coordinator의 Discover Service에 등록합니다.
=> 해당 과정을 거쳐야 Coordinator가 Task를 Worker에 배정할 수 있습니다.
(2). Client는 HTTP 기반 프로토콜을 사용하여 Coordinator에게 쿼리를 전송합니다.
(3). Coordinator는 쿼리를 구문 분석하고 query plan이라고하는 실행 계획을 생성합니다.
Parser/analyzer: 테이블 / 컬럼 / 타입에 대한 정보 수집Planner: Row 개수 및 테이블 크기에 대한 정보 수집Scheduler: Query Plan 생성Query Plan: 데이터를 처리하고 결과를 반환하는데까지의 모든 단계
(4). Coordinator가 Query plan에 필요한 스키마 데이터를 connector Plugin에 요청합니다.
(5). Coordinator에서 Worker로 수행해야할 Task를 전달함.
(6). Worker는 Connector Plugin을 통해서 Data Sources로 부터 데이터를 읽어옴.
(7). Worker들은 Query Plan에 따라 할당된 task를 메모리에서 수행
(8). 실행 결과를 Coordinator를 거쳐 Client에 전달함.
Trino Query
Trino Query는 기본적으로 ANSI SQL을 따르지만,
다른 DB와 달리 데이터 소스 구분을 위해catalog.schema.table형식을 씀.
[Example : SQL Template]SELECT a.col1, b.col2 FROM catalog1.schema1.table1 a JOIN catalog2.schema2.table2 b ON a.id = b.id WHERE a.col3 > 100;
Query Example
1. 기본 SELECT (Hive 테이블)
SELECT order_id, total_amount
FROM hive.sales.orders
WHERE order_date >= DATE '2025-09-01'
LIMIT 10;2. MySQL + Hive 조인
SELECT c.customer_id, c.name, o.total_amount
FROM mysql.crm.customers c
JOIN hive.sales.orders o
ON c.customer_id = o.customer_id
WHERE o.order_date >= DATE '2025-09-01';3. Kafka 토픽 조회
=> 더 알아볼 필요가 있음.
SELECT user_id, page, timestamp
FROM kafka.default.pageviews
WHERE page = '/home'
LIMIT 20;4. Kafka + MySQL 조인
SELECT p.user_id, p.page, u.name
FROM kafka.default.pageviews p
JOIN mysql.crm.users u
ON p.user_id = u.id
WHERE p.page = '/checkout';5. S3 데이터 직접 분석 (Iceberg / Parquet)
SELECT region, COUNT(*) AS orders, SUM(total_amount) AS revenue
FROM iceberg.analytics.orders
WHERE order_date BETWEEN DATE '2025-09-01' AND DATE '2025-09-29'
GROUP BY region
ORDER BY revenue DESC;