NIAGARA : A 32-Way Multithreaded SPARC Processor
Abstraction
지난 20년간의 마이크로프로세서 디자이너들의 노력은 단일 스레드의 성능을 높이기 위해 ILP를 활용하는 것이었으나, memory latency 및 inherently low ILP of application 등의 이유로 그 리턴이 감소해왔다.
Niagara processor 에선 ‘radically different approach’를 적용한다. Thread Level Parallelism을 이용하여 multiple thread에서의 throughput을 높인다. Niagara microprocessor 는 CMP와 fine-grained MT 기술을 합쳐 32-way MT를 구현한다.
Niagara는 Solaris Operating System에서 modification 없이 동작하는데, OS layer에 의해 application SW에는 별개의 32개 processor가 존재한다는 일루젼을 제공받는다.
‘Retail and business processes to Web’ 으로 인해 Multiple threads를 필요로 하는 server workload에서 MT의 중요성은 늘어났고 ILP는 더욱 활용하기 힘들어졌다. 이러한 상황에서 single thread에 최적화된 프로세서에서 벗어날 필요가 있었다. 게다가 server workload는 memory access pattern이 random-like이며(poor locality) 큰 working set을 가져 cache miss rate가 크다. 이로 인해 AMAT가 증가하였고, TLP를 exploit해야 하는 중요성이 대두된다.
Niagara Overview
Niagara는 칩에 32개의 execution state를 가진다. 4개의 thread로 이루어진 thread group은 Sparc pipe라고 불리는 processing pipeline을 공유하고, 그러한 thread group을 8개 가진다. Switch penalty 가 0 cycle이기에, memory reference등에 의한 stall을 가릴 수 있다. 32개의 thread가 공유하는 L2 cache 4-way bank level parallelism을 활용한다. 또한 pipelined 되어 bandwidth를 증가시켰으며 12-way associativity로 비교적 high associativity를 가져 다양한 thread에서 접근하기에 빈번히 발생할 수 있는 conflict miss를 줄이고자 하였다.

Sparc Pipeline
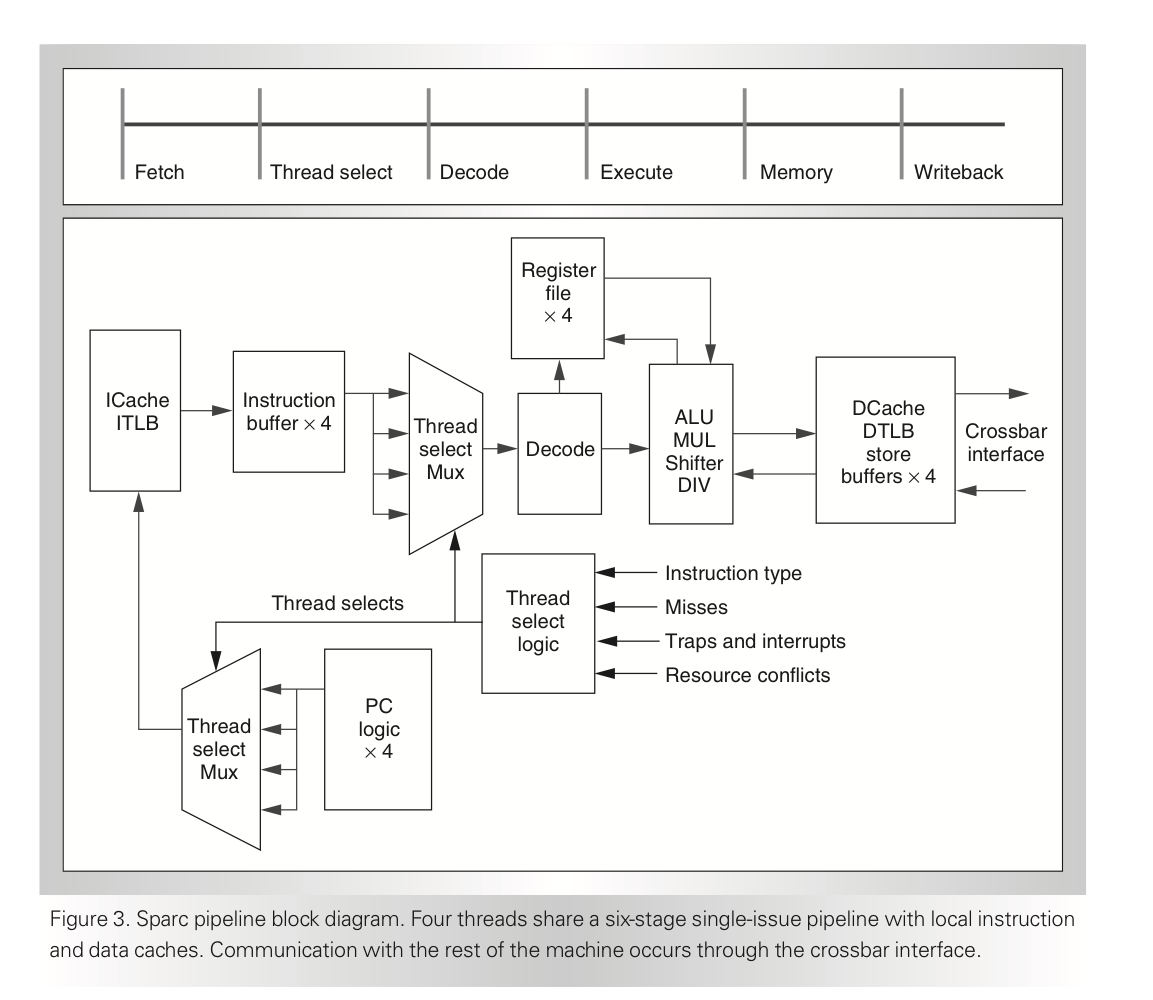
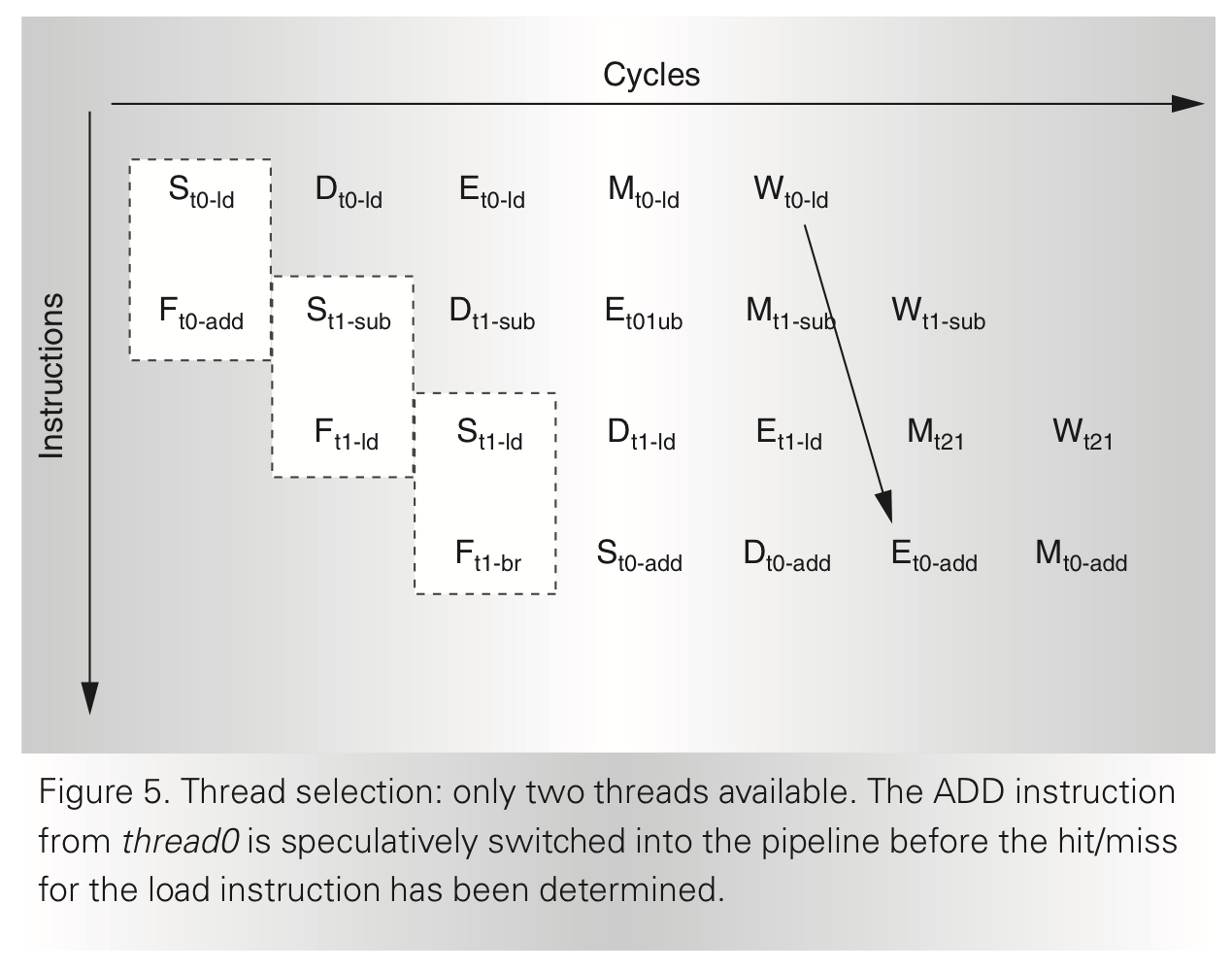
4개의 thread of execution을 가지는 sparc pipeline은 L1 cache 및 Transltaion lookaside buffer를 공유한다. Sparc pipeline은 single-issue, 6-stage pipeline(IF-thread selection-decode-..)이며 Fetch 단계에서 I-cache 및 I-TLB를 access한다. thread selection mux가 어떤 PC를 이용해 access를 할지 결정해야 한다. Thread select stage에선 downstream stages로 이슈가 가능한 스레드를 찾아 mux에서 선택해야 한다. 이 단계에서 instruction buffer를 가져 fetch되었으나 downstream stage로 진입할 수 없는 instruction들을 담아둔다. 선택된 스레드가 decode stage로 이동하면 decode, RF access 이후 execution이 진행된다. 수행하는 작업이 single cycle latency를 가지는 ALU, shift instruction이 아닌 long latency를 가지는 Multiply, Divide등이라면 execution 단계에서 결과를 도출해내지 못하므로 thread switch가 이뤄진다. Load strore instruction 은 DTLB, D-cache access 를 포함하며 8 store buffer entry per thread를 가진다. 이 store buffer로부터 load unit으로의 bypass가 이루어져 RAW hazard를 해결한다.
Thread select logic는 아래 그림과 같이 Instruction type(from predecoded bits), Misses, Interrupts, HW resource availibility등의 정보를 이용해 선택되어 Instruction buffer → Decode 단계로 어떤 명령어가 진입될지 결정된다. 이때 Fetch 단계에서도 같은 thread가 선택되어 Instruction buffer에서 빠진 Entry에 명령어를 채우게 된다.
Pipeline interlocks and scheduling
add와 같은 single cycle instruction들에 대해 같은 thread의 더 최신 명령어들에게 full-bypassing을 제공한다. (RAW를 해결하기 위해) load의 경우 그 값을 받아오기까지 3cycle이 소요되었다. 따라서 같은 thread의 그 값을 필요로 하는 명령어는 최소 2번의 stall을 필요로 한다.
MT의 경우 여러 thead가 shared hardware resource를 공유하므로 structural hazard또한 발생한다. 1cycle 을 소요하는 ALU의 경우 발생하지 않지만 divider, multiplier는 resource conflict의 가능성이 존재한다. 위의 그림에서 thread selection logic의 input으로 resource conflicts가 들어가는 것을 확인하라. 이를 위한 것이다.
Thread Seletion Policy
수행가능한 thread들 중 하나를 선택하는 policy는, least recently executed thread에게 우선권을 부여한다. thread가 수행가능하지 않도록 만드는 요인은 load/store, branches, mult and div와 같은 long latency instruction이나 cache miss, traps(also interrupts), resource sharing으로 인한 structural hazard이다.
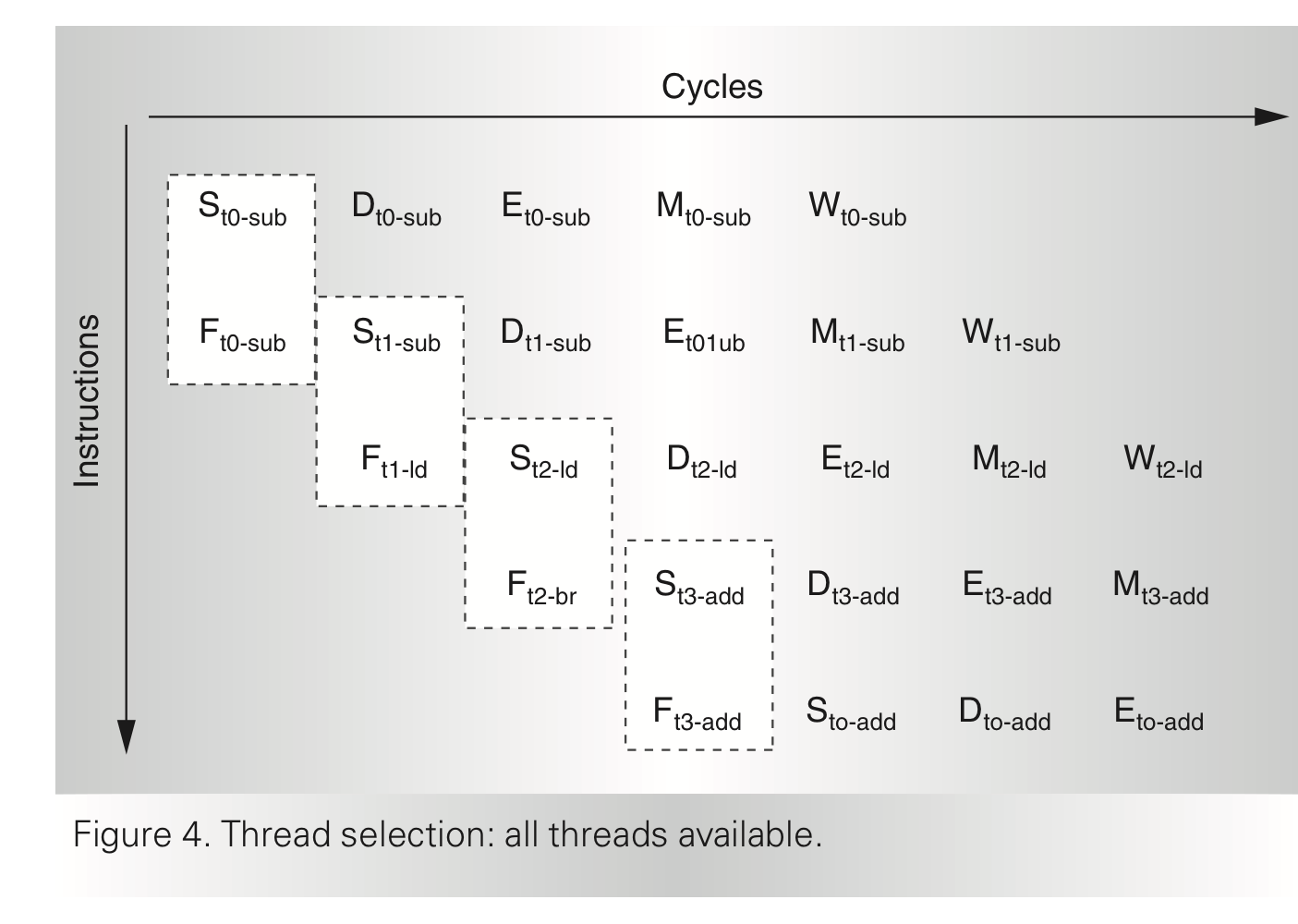
위의 그림은 모든 thread가 available일 때 least recently executed policy에 의해 어떻게 thread가 선택되는지 보여준다.
Integer Register File
Integer register file 은 3개의 read ports와 2개의 write ports 를 가진다. 두 개의 write ports는 각각 single cycle operation과 long-latency operation을 담당한다. Load, mult, div에서 동시에 결과를 만들어 RF에 적으려고 할 때 적절히 중재되어 들어가야 한다. SPARC V9 architecture 는 위의 그림과 같은 register window 기법을 사용한다. 하나의 window는 8개의 in, local, out register들로 구성된다. (이들은 한 시점에 한 thread에게 모두 visible)
multiport register를 지원하기 위해선 큰 area 및 access time을 요구하기에 이 문제를 해결하는 것이 포인트이다. 이 문제를 다루기 위해 본 마이크로아키텍쳐는 windowing기법을 사용하는 것.
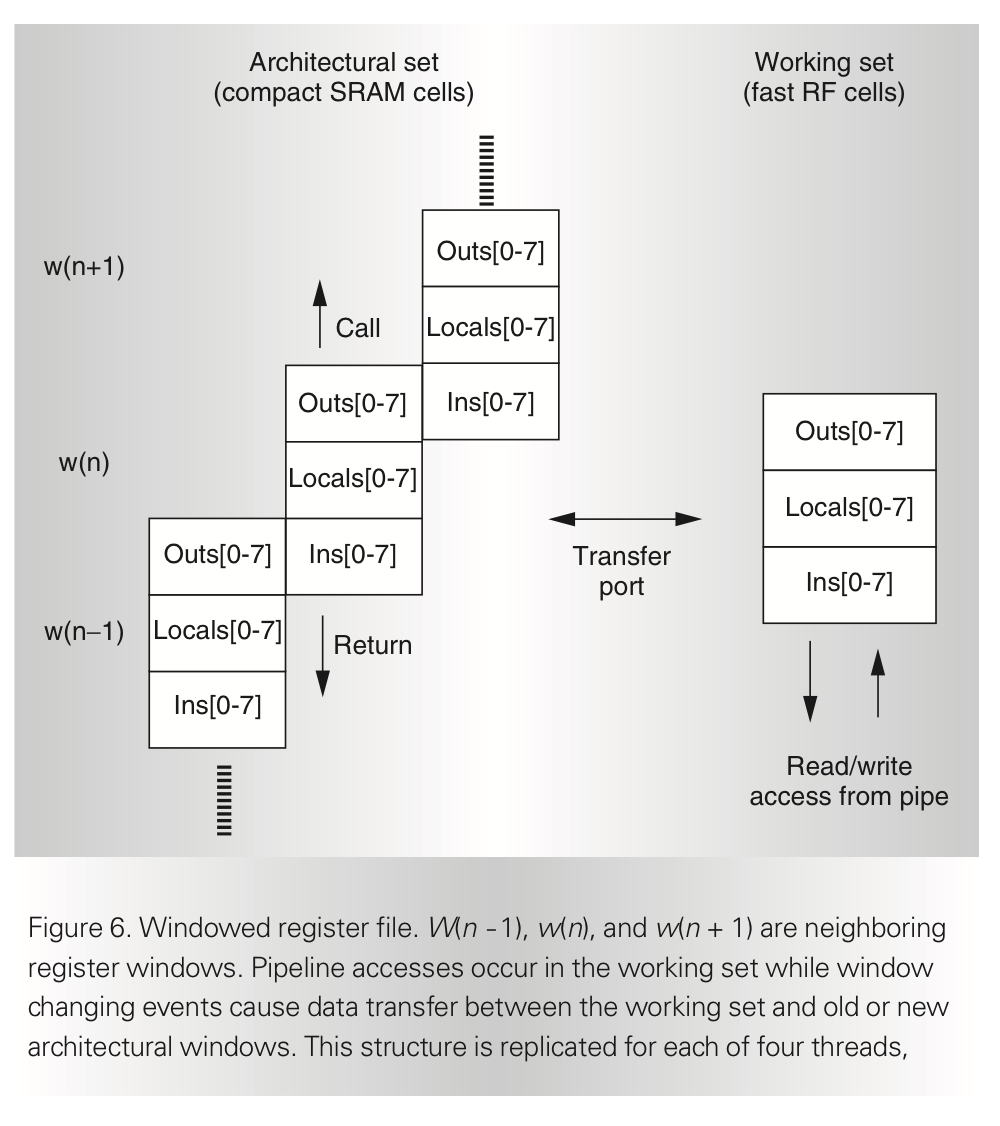
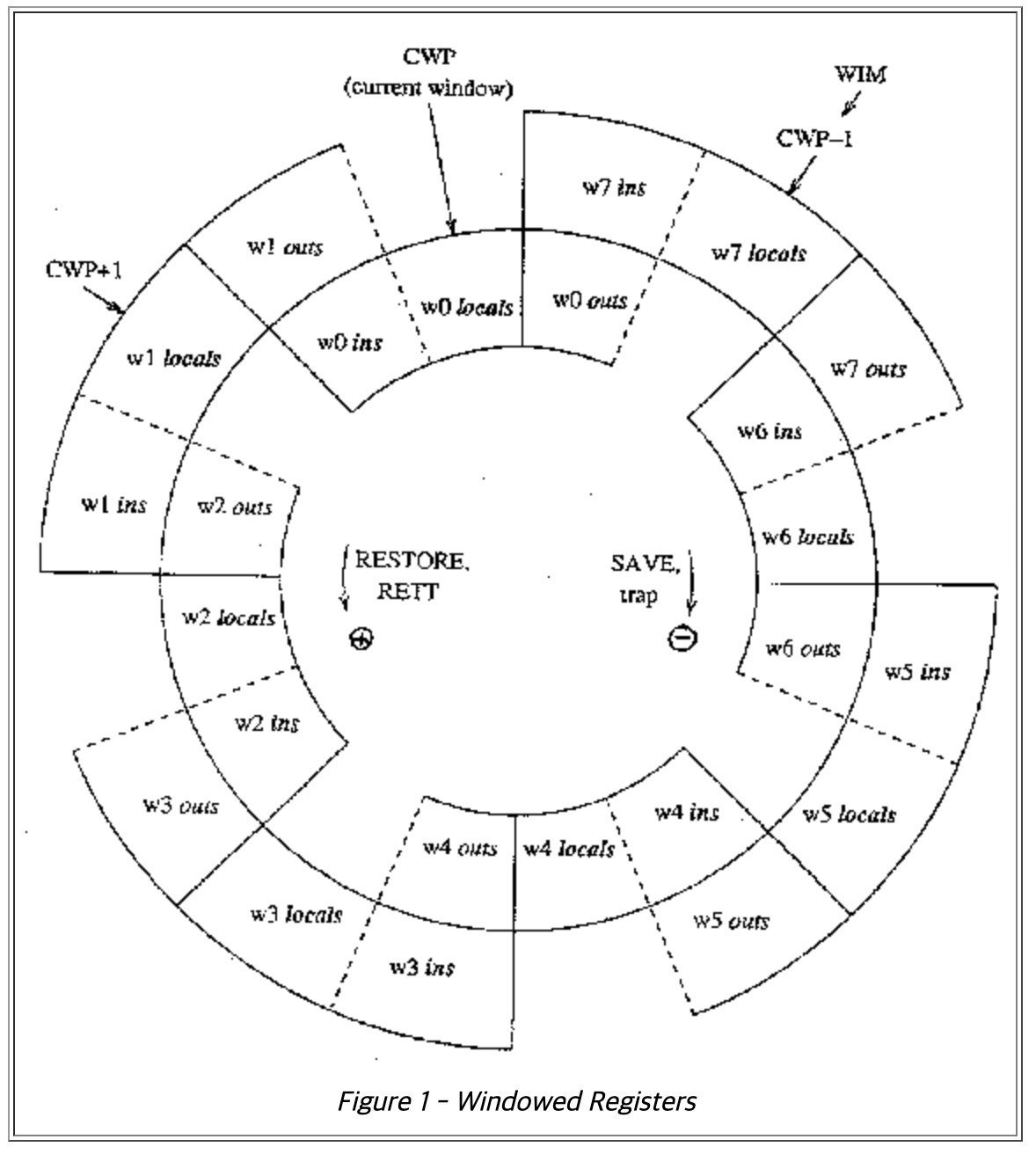
Register windows are generally used to support procedure calls, so they can be viewed as a cache of the stack contents.
Procedure call이 일어나면 새로운 window를 요구하고 이에 따라 CWP(stands for current window pointer)가 slide up(왼쪽 그림 기준, 오른쪽 그림 기준 시계방향으로 바뀐다.) 하면서 old out registers가 new in registers가 된다. return from procedure은 그 반대로 행동하게 됨. complete set of registers를 architectural set이라 부르며 SRAM cell로 만들고, thread에게 보이는 32개의 register(global + local + outs + ins)는 working set이라 부르며 RF cell로 구성한다. 서브루틴 호출이나 리턴으로 인해 current window pointer가 바뀌어야 하면, transfer port를 통해 SRAM cell과 RF cell이 통신한다. 이 통신이 대략 1~2 cycle 소요하기 때문에 이 또한 thread selection policy에서 deselection되어야 하는 요인이 된다. 그러나 이 data transfer은 하나의 thread에서 일어나는 일이기 때문에 다른 thread를 수행하면 된다. (latency hiding이 가능하다는 뜻!)


Memory Subsystem
