Simultaneous Multithreading : A Platform for Next-Generation Processors
Abstraction
어떻게 칩을 효율적으로 사용할 수 있을까
메모리를 늘린다, integration level을 높인다 (graphics accelerator, I/O controller on chip) 등의 노력은 퍼포먼스를 분명 올려 주지만 marginal.
결국 computational capabilities를 높여야 한다. How? 어떻게든 parallelism(ILP, DLP, TLP)
SMT는 ILP 및 TLP를 동시에 exploit하는 모델이다. multiprogramming workload로부터 TLP를, 개별 thread에서 ILP를 활용함으로써 리소스를 더욱 효율적으로 활용하며, throuput늘린다.
SMT는 SS의 multi-issue및 MT의 여러 HW state를 가지는 점을 혼합하여 만들어진다. 이로써 한cycle에 다양한 thread로부터 multi-issue를 가능케 한다.
How SMT works
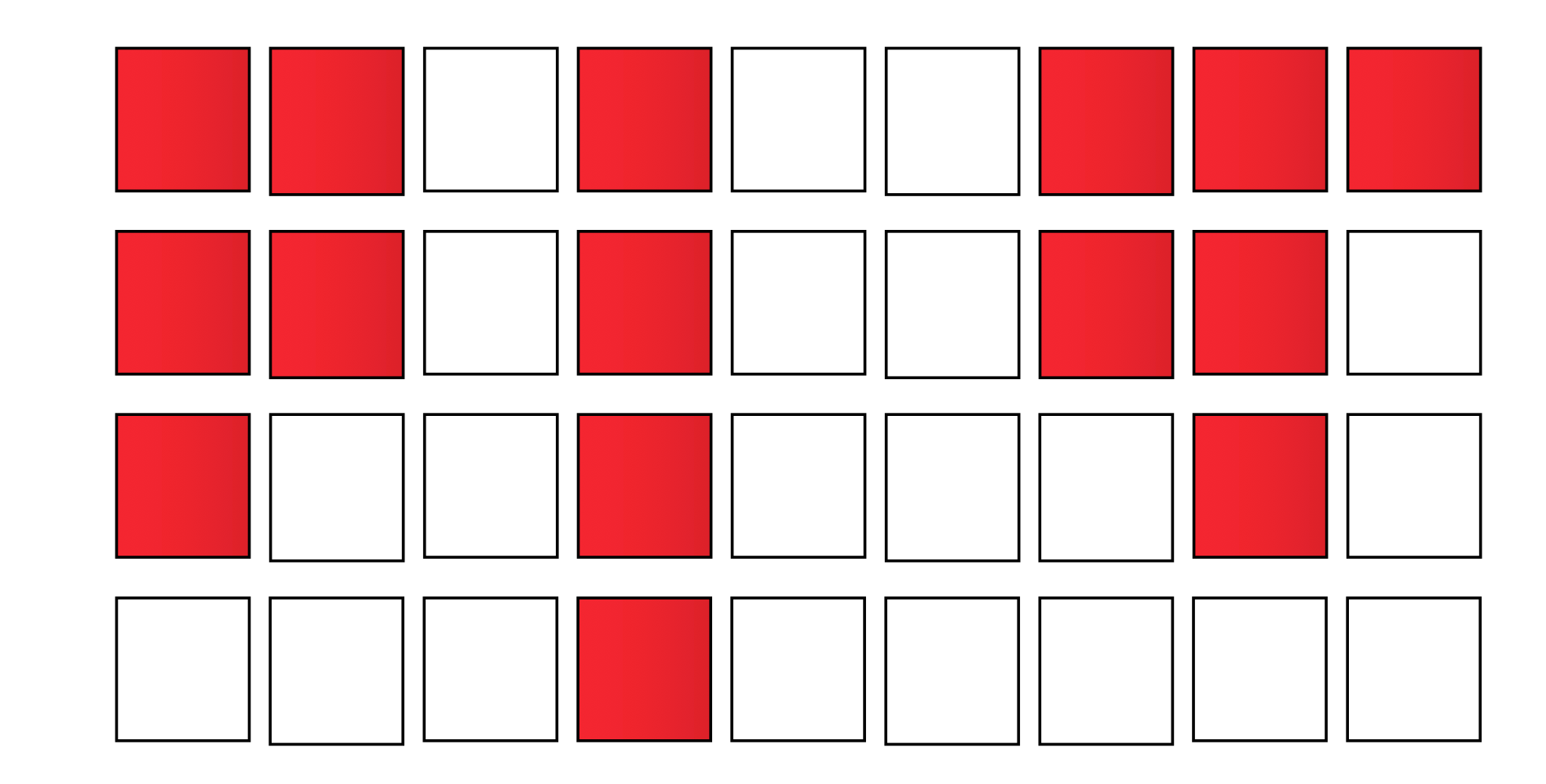
Superscalar

Multithreading
Simultaneously multithreading
SS, MT 그리고 SMT의 execution state는 위의 그림과 같이 묘사된다.
Horizontal, vertical waste 는 각각 poor ILP, some long latency operations like memory access등에 의해 발생한다. Multithreading은 long latency operation에 의한 사이클 낭비를 줄여줌을 확인할 수 있다.
SMT는 실행가능한 다양한 스레드에서 instruction을 선택하여 issue함으로써 ILP를 활용하고, 개별 스레드의 ILP가 낮다면 다양한 스레드에서 instruction들이 issue됨으로써 그를 보완한다.
SMT model
OoO, SS architecture인 MIPS R10k와 같은 모델로부터 SMT를 derive할 수 있다. 본 논문의 SMT 모델에선 이와 비슷하게, 8개의 HW context가 존재한다.(MIPS R10k의 경우 8-issue SS) 이를 구현하기 위해선 기존 SS모델의 HW resource를 여러개 배치해야 하는데, RF,PC가 그 종류이며, per thread flushing, trapping, precise interrupt, subroutine return mechnism이 존재하고 BTB및 TLB 또한 thread id를 이용해 접근해야 한다. IF 및 pipeline의 간단한 redesign을 제외하면, 기존의 SS-OoO 의 dynamic scheduling algorithms를 사용하여 SMT를 구현할 수 있다. Register renaming은 스레드 간의 또한 스레드 내부의 dependency를 해결해준다. 여러 개(8 in this paper)의 RF로부터 하나의 큰 physical register file로 register renaming이 이루어지기 때문에 execution window에서 tid를 고려하지 않고 명령어를 이슈할 수 있다!
2.8 fetching scheme
SMT는 fetch 단계에서 다양한 스레드로부터 instruction을 받아와야 하므로 이 부분에서 병목현상이 발생한다.
본 논문에선 2.8 fetch scheme을 제안한다. 각 사이클에, 2개의 다른 스레드(I-cache miss를 발생시키지 않는)에서 각 8개의 instruction을 fetch한다. Decode stage에 넘겨 줄 땐 이 instruction의 부분집합을 넘긴다.
첫 스레드가 branch instruction을 만나거나 cache line 마지막에 도달할 때까지 가져오고 이후 두번째 스레드에서 남은 instruction을 가져온다. 두 개의 개별 스레드에서 명령어를 가져오기에, 유용한 명령어들을 fetch할 가능성이 올라가게 된다. 이를 구현하기 위해선 i-cache의 port를 늘리고 이 과정에서 branch인지 아닌지를 인식하는 정도의 추가적 로직만이 필요하다.
Icount feedback
프로세서는 2개의 스레드에서 명령어를 fetch하기 때문에 어떻게 2개의 스레드를 선정할지 결정할 필요가 있다. 어떤 스레드에서 fetch할 때 가장 작은 딜레이를 발생시킬지 예측할 수 있다면, 퍼포먼스가 향상될 것이다.
Icount feedback이라는 방법이 사용되는데, decode, renaming, queue pipeline stage에 가장 적은 양의 명령어가 적재된 스레드에 높은 priority를 주는 방식이다. 그 이유는 무엇일까?
Dispatching queue에 적게 적재된 스레드는 dependency가 빠르게 resolution되거나 long latency operation을 적게 하는 등의 이유로 빠르게 수행 가능한 스레드일 것이다. 이러한 스레드에게 우선순위를 부여함으로써 dispatch queue가 꽉 차는 상황을 방지할 수 있다. 또한 Starvation의 문제를 해결하기도 한다.
Icount feedback을 구현하기 위한 HW cost또한 적다. 스레드당 하나의 카운터를 두고 이 스레드에서 명령어가 decode stage에 진입할때 올리고, dispatch queue에서 나갈 때 낮추는 정도의 일을 하면 된다. Icount feedback 방법은 dispatch queue가 비효율적으로 운영(fairness issues나 꽉차는 문제 등)되는 것을 해결하기 위한 방법들 중 가장 좋은 퍼포먼스를 보였다.
Register file and pipeline
SMT는 8 * 32 architectural RF(FPRF) + additional renaming register 만큼의 physical register file을 필요로 한다. 이 큰 RF는 access time이 크기에 cycle에 영향을 미칠 수 있다. 이를 방지하기 위해 2사이클에 나누어 RF read & write를 수행하도록 한다. 그러나, IF와 execution단계의 distance 증가로 branch misprediction penalty의 증가, renaming register pressure(Register renaming으로부터 commit까지의 거리가 증가함으로써 physical register가 한 명령어에 더욱 오랜 시간 bound)가 증가한다.
Implementation parameters
- 8 instruction fetch/decode width
- 6 integer units, 4 load/store units
- 4 floating-point units
- 32-entry integer and fp dispatch queues
- HW context for 8 threads
- 100 additional integer register and 100 addtional fp register
- retirement(commit) of 12 instructions per cycle
Simulation environment
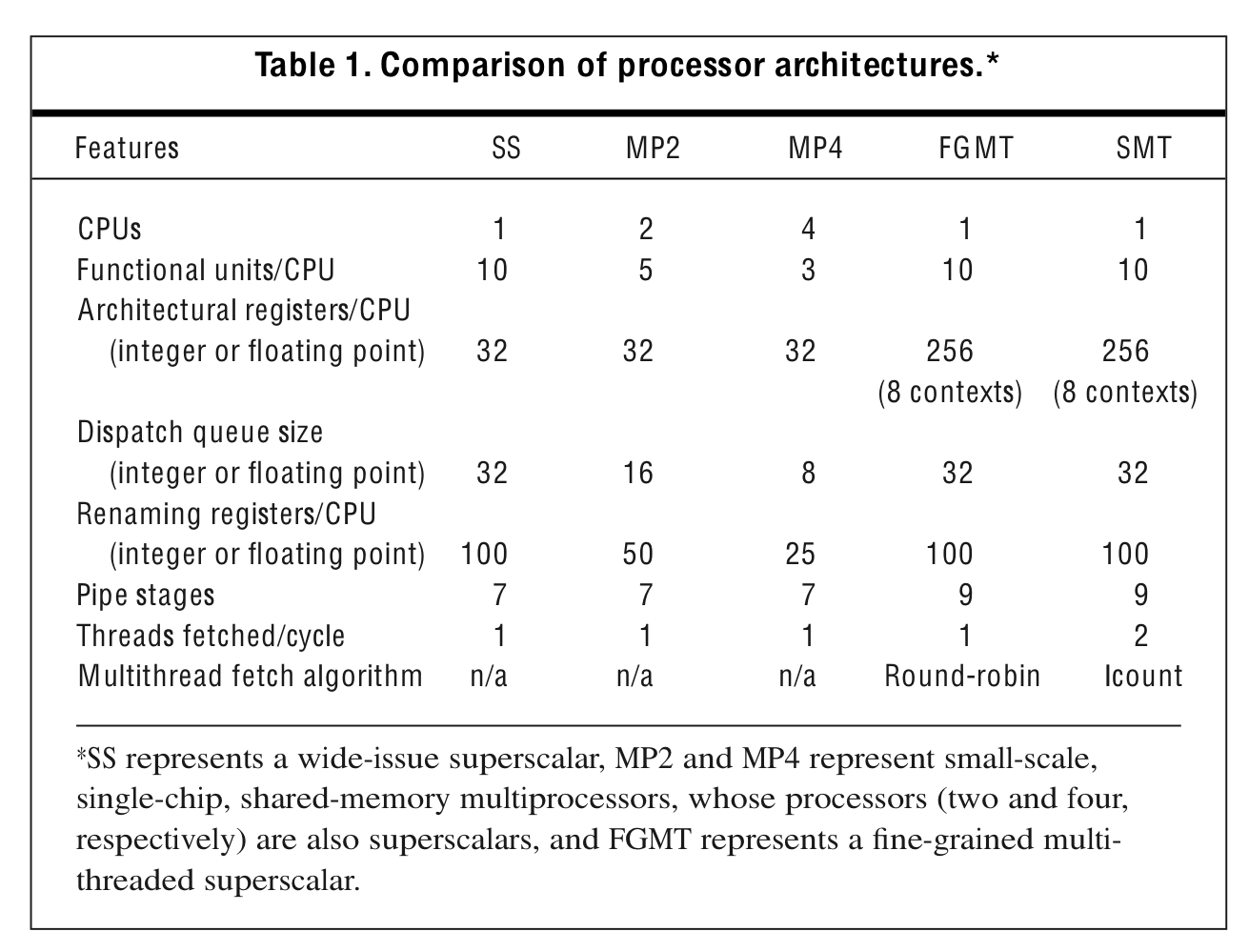
Simulation results