Introduction
Computation, Dimension, and Model size of Self-Attention

Model size of transformer block
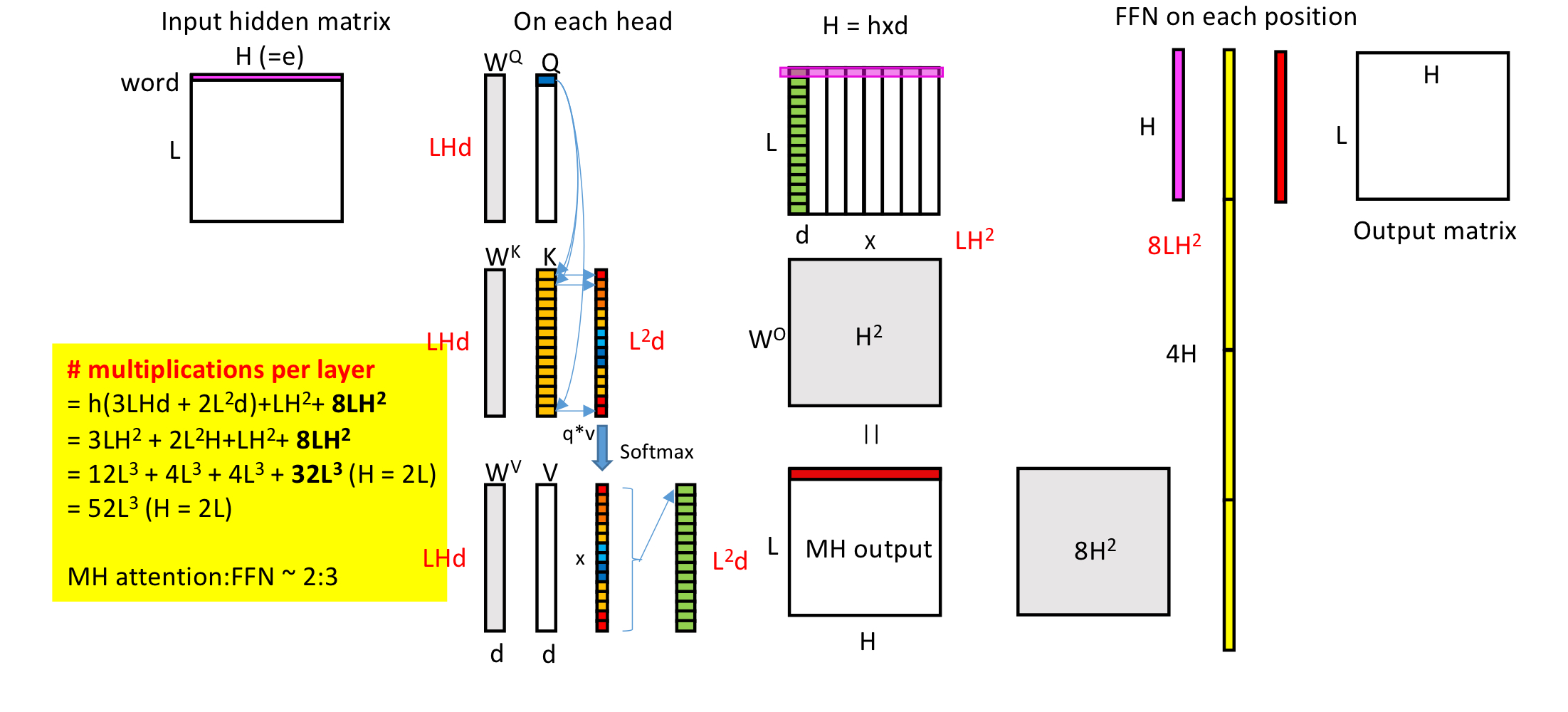
#of multiplication of transformer block
Transformer는 NLP task에서 도입돼서 parallelism을 늘렸고, long-range-dependency를 더욱 잘 잡고 뭐 그렇다. 이걸 vision task에서 쓸 수 없을까 ? →ViT, DeiT등 존재 → # of token이 이미지 사이즈에 비례하는데, transformer는 token개수에 quadratic한 computational cost를 가진다. → General vision backbone으로 사용하는데 무리가 있다. → 이미지 사이즈에 linear한 computation cost를 가지는 shifted window method를 제안!!
Method
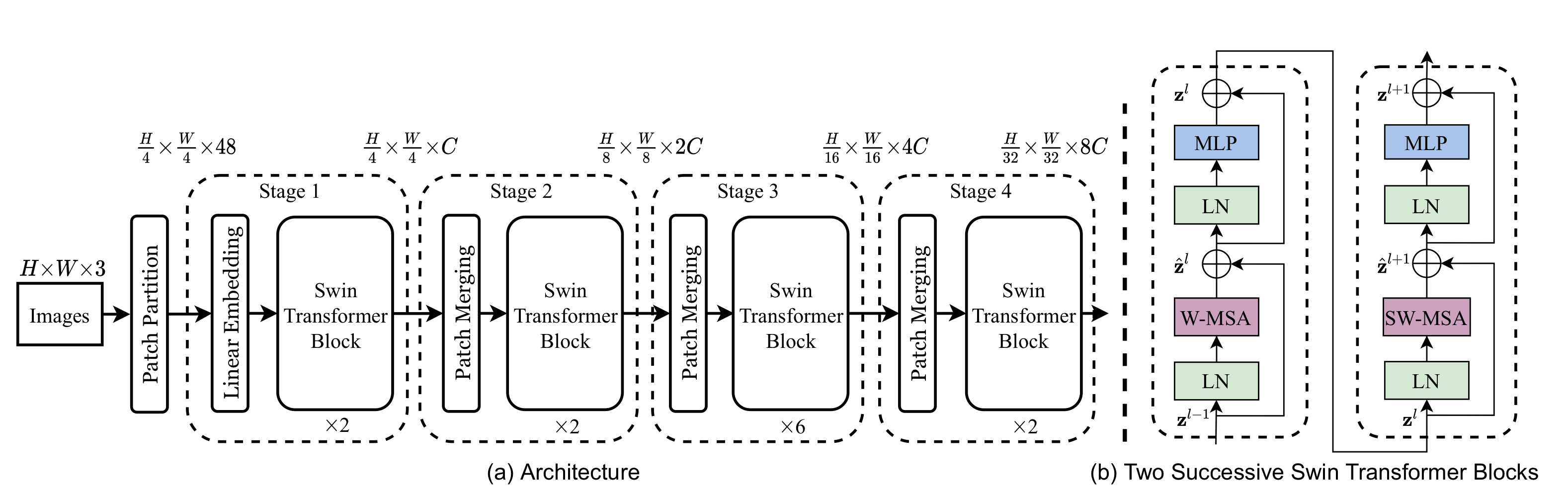
Overall Architectire
첫째로, ViT에서와 같이 patch splitting module을 이용하여 non-overlapping patch들을 만든다. 4x4 patch를 사용하여 channel로 concat한다. 이리하면 4x4x3 → 48짜리 token이 만들어짐. Linear embedding layer를 거쳐 임의의 차원 C로 매핑한다. 위 그림의 patch partitioning 및 linear embedding layer를 거쳐 (H,W,3) → (H/4,W/4,C)가 되면, Swin Transformer Block에 입력으로 쓰일 준비를 마친 것이다.
이제 Swin Transformer Block과 Patch Merging layer를 순차적으로 거치는데, patch merging은 token들을 2x2 사이즈로 downsampling하여 feature map size를 줄여나간다. 2x2이기에 위의 그림에서 patch merging을 거칠 때마다 Height, Width는 2배로 줄고 Channel은 2배씩 늘어남을 확인할 수 있다. 위 그림의 feature map resolution은 기존의 몇몇 CNN based model과 일치한다. (VGG, ResNet)
Swin Transformer Block
위 그림의 오른쪽이 swin transformer block의 구조를 나타낸다. 첫 블락에선 W-MSA(Windowing Multi-head Self-Attention)을, 두번째 연속되는 블락에서 SW-MSA(Shifted Windowing —)을 배치한다. 각각의 MLP는 2-layer이며 activation으로 GELU를 사용하였다.
Shifted Window based Self-Attention
기존의 standard Transformer architecture와 image classification에서의 적용인 ViT등은 모든 token들에 대해 self-attention 계산이 이루어진다. (기본적(?)인 self-attention은 이런 의미에서 global이다. CNN의 kernel은 locality를 잡는데 specialist인 반면) 이런 global computation은 전체 토큰 개수(vision task의 경우 이미지 사이즈에 비례하는)에 대해 quadratic complexity를 가진다. vision taks, 특히 high resolution을 요구하는 일에 대해 적용하는데 큰 overhead라고 할 수 있다.
self-attention in non-overlapping windows: 위에서 전술한 문제를 해결하기 위해 본문에선 self-attention을 local window내부 토큰들에 대해서 적용한다. 각 window가 MxM 개의 patches를 포함한다고 하면, 그 computational cost가 다음과 같이 계산된다.
살펴보면, 이미지 size인 hw에 quadratic한 관계를 가지는 MSA와 달리 W-MSA는 hw에 대해 linear이다. M의 경우 hw에 비해 작으며 고정된 수이다.
Shifted window partitioning in succesive blocks: window-based self-attention은 inter-window connection이 부족한 문제가 생기고, 이는 modeling power를 제한하는 큰 문제이다. cross-window connection은 높이며 non-overlapping window내에서 효율적인 연산을 하기 위해 shifted window partitioning 방법을 사용한다.
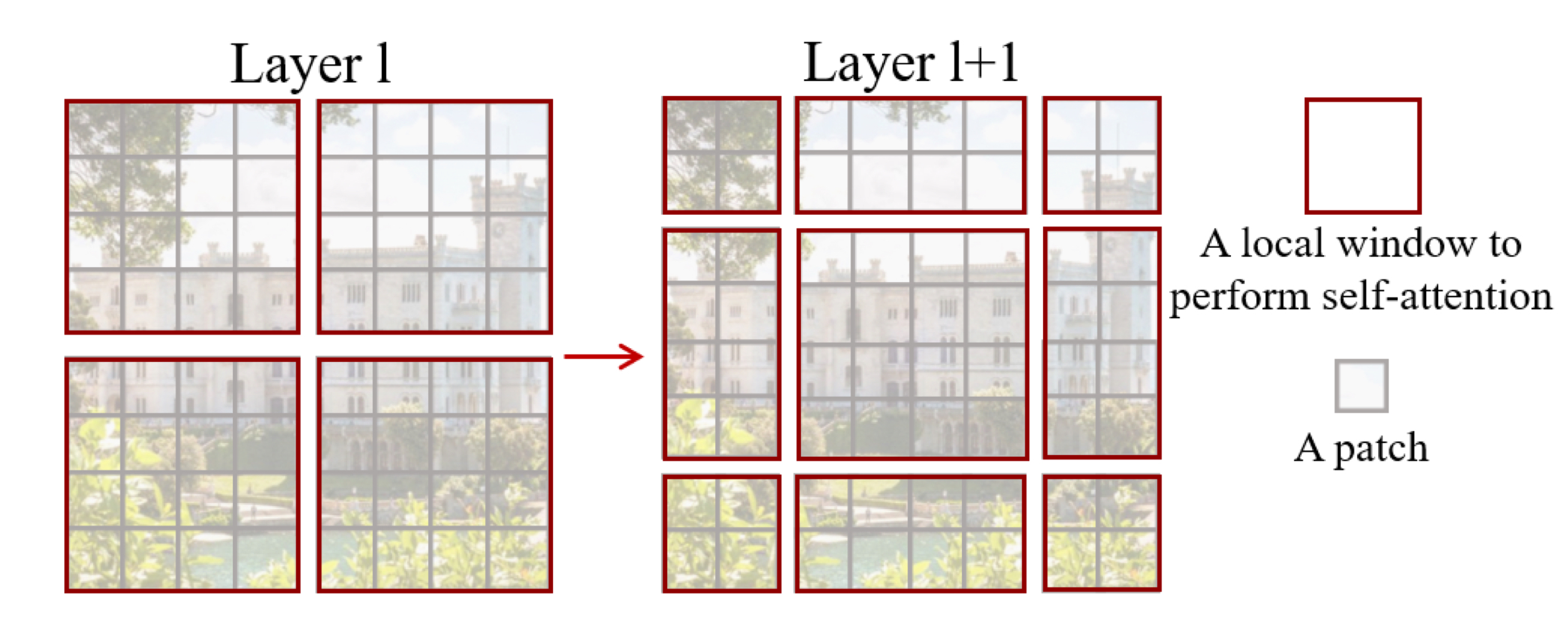
위 그림에서 보이듯, 2개의 consecutive block에서 첫번째 블락은 일반적인 W-MSA가 적용되고, 두번째 SW-MSA layer에서는 이전 layer에서의 window와 pixel 만큼의 displacement를 가지고 shift된다.
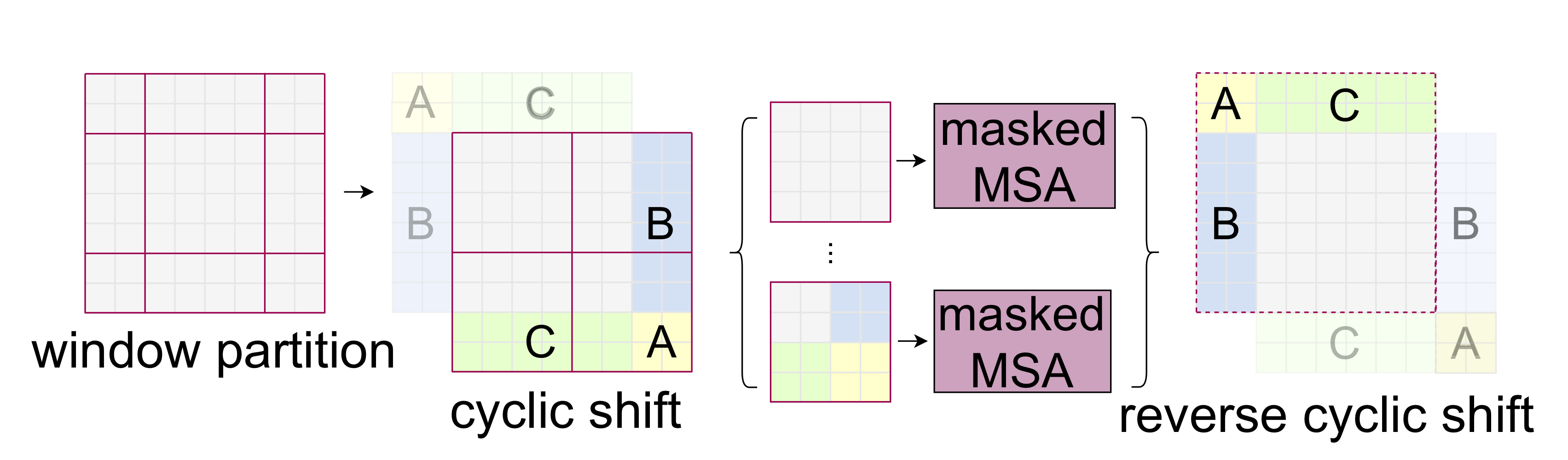
따라서 W-MSA와 SW-MSA는 window의 위치가 조금 다른 점 외엔 큰 차이가 없다.
Relative position bias
self-attention을 계산할때, 기존의 NLP에서나 ViT에서와 조금 다른 점이 있다면, positional embedding에 대한 부분이다. 본 모델에선 relative position bias 를 이용한다.
큰 의미는…없어보이긴 하는데,,.,.,anyway
Experiments
논문을 참조하자.
Implmentation
import torch
from torch import nn, einsum
import numpy as np
from einops import rearrange, repeat
class CyclicShift(nn.Module):
def __init__(self, displacement):
super().__init__()
self.displacement = displacement
def forward(self, x):
return torch.roll(x, shifts=(self.displacement, self.displacement), dims=(1, 2))
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(x, **kwargs) + x
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, dim),
)
def forward(self, x):
return self.net(x)
def create_mask(window_size, displacement, upper_lower, left_right):
mask = torch.zeros(window_size ** 2, window_size ** 2)
if upper_lower:
mask[-displacement * window_size:, :-displacement * window_size] = float('-inf')
mask[:-displacement * window_size, -displacement * window_size:] = float('-inf')
if left_right:
mask = rearrange(mask, '(h1 w1) (h2 w2) -> h1 w1 h2 w2', h1=window_size, h2=window_size)
mask[:, -displacement:, :, :-displacement] = float('-inf')
mask[:, :-displacement, :, -displacement:] = float('-inf')
mask = rearrange(mask, 'h1 w1 h2 w2 -> (h1 w1) (h2 w2)')
return mask
def get_relative_distances(window_size):
indices = torch.tensor(np.array([[x, y] for x in range(window_size) for y in range(window_size)]))
distances = indices[None, :, :] - indices[:, None, :]
return distances
class WindowAttention(nn.Module):
def __init__(self, dim, heads, head_dim, shifted, window_size, relative_pos_embedding):
super().__init__()
inner_dim = head_dim * heads
self.heads = heads
self.scale = head_dim ** -0.5
self.window_size = window_size
self.relative_pos_embedding = relative_pos_embedding
self.shifted = shifted
if self.shifted:
displacement = window_size // 2
self.cyclic_shift = CyclicShift(-displacement)
self.cyclic_back_shift = CyclicShift(displacement)
self.upper_lower_mask = nn.Parameter(create_mask(window_size=window_size, displacement=displacement,
upper_lower=True, left_right=False), requires_grad=False)
self.left_right_mask = nn.Parameter(create_mask(window_size=window_size, displacement=displacement,
upper_lower=False, left_right=True), requires_grad=False)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
if self.relative_pos_embedding:
self.relative_indices = get_relative_distances(window_size) + window_size - 1
self.pos_embedding = nn.Parameter(torch.randn(2 * window_size - 1, 2 * window_size - 1))
else:
self.pos_embedding = nn.Parameter(torch.randn(window_size ** 2, window_size ** 2))
self.to_out = nn.Linear(inner_dim, dim)
def forward(self, x):
if self.shifted:
x = self.cyclic_shift(x)
b, n_h, n_w, _, h = *x.shape, self.heads
qkv = self.to_qkv(x).chunk(3, dim=-1)
nw_h = n_h // self.window_size
nw_w = n_w // self.window_size
q, k, v = map(
lambda t: rearrange(t, 'b (nw_h w_h) (nw_w w_w) (h d) -> b h (nw_h nw_w) (w_h w_w) d',
h=h, w_h=self.window_size, w_w=self.window_size), qkv)
dots = einsum('b h w i d, b h w j d -> b h w i j', q, k) * self.scale
if self.relative_pos_embedding:
dots += self.pos_embedding[self.relative_indices[:, :, 0], self.relative_indices[:, :, 1]]
else:
dots += self.pos_embedding
if self.shifted:
dots[:, :, -nw_w:] += self.upper_lower_mask
dots[:, :, nw_w - 1::nw_w] += self.left_right_mask
attn = dots.softmax(dim=-1)
out = einsum('b h w i j, b h w j d -> b h w i d', attn, v)
out = rearrange(out, 'b h (nw_h nw_w) (w_h w_w) d -> b (nw_h w_h) (nw_w w_w) (h d)',
h=h, w_h=self.window_size, w_w=self.window_size, nw_h=nw_h, nw_w=nw_w)
out = self.to_out(out)
if self.shifted:
out = self.cyclic_back_shift(out)
return out
class SwinBlock(nn.Module):
def __init__(self, dim, heads, head_dim, mlp_dim, shifted, window_size, relative_pos_embedding):
super().__init__()
self.attention_block = Residual(PreNorm(dim, WindowAttention(dim=dim,
heads=heads,
head_dim=head_dim,
shifted=shifted,
window_size=window_size,
relative_pos_embedding=relative_pos_embedding)))
self.mlp_block = Residual(PreNorm(dim, FeedForward(dim=dim, hidden_dim=mlp_dim)))
def forward(self, x):
x = self.attention_block(x)
x = self.mlp_block(x)
return x
class PatchMerging(nn.Module):
def __init__(self, in_channels, out_channels, downscaling_factor):
super().__init__()
self.downscaling_factor = downscaling_factor
self.patch_merge = nn.Unfold(kernel_size=downscaling_factor, stride=downscaling_factor, padding=0)
self.linear = nn.Linear(in_channels * downscaling_factor ** 2, out_channels)
def forward(self, x):
b, c, h, w = x.shape
new_h, new_w = h // self.downscaling_factor, w // self.downscaling_factor
x = self.patch_merge(x).view(b, -1, new_h, new_w).permute(0, 2, 3, 1)
x = self.linear(x)
return x
class StageModule(nn.Module):
def __init__(self, in_channels, hidden_dimension, layers, downscaling_factor, num_heads, head_dim, window_size,
relative_pos_embedding):
super().__init__()
assert layers % 2 == 0, 'Stage layers need to be divisible by 2 for regular and shifted block.'
self.patch_partition = PatchMerging(in_channels=in_channels, out_channels=hidden_dimension,
downscaling_factor=downscaling_factor)
self.layers = nn.ModuleList([])
for _ in range(layers // 2):
self.layers.append(nn.ModuleList([
SwinBlock(dim=hidden_dimension, heads=num_heads, head_dim=head_dim, mlp_dim=hidden_dimension * 4,
shifted=False, window_size=window_size, relative_pos_embedding=relative_pos_embedding),
SwinBlock(dim=hidden_dimension, heads=num_heads, head_dim=head_dim, mlp_dim=hidden_dimension * 4,
shifted=True, window_size=window_size, relative_pos_embedding=relative_pos_embedding),
]))
def forward(self, x):
x = self.patch_partition(x)
for regular_block, shifted_block in self.layers:
x = regular_block(x)
x = shifted_block(x)
return x.permute(0, 3, 1, 2)
class SwinTransformer(nn.Module):
def __init__(self, *, hidden_dim, layers, heads, channels=3, num_classes=1000, head_dim=32, window_size=7,
downscaling_factors=(4, 2, 2, 2), relative_pos_embedding=True):
super().__init__()
self.stage1 = StageModule(in_channels=channels, hidden_dimension=hidden_dim, layers=layers[0],
downscaling_factor=downscaling_factors[0], num_heads=heads[0], head_dim=head_dim,
window_size=window_size, relative_pos_embedding=relative_pos_embedding)
self.stage2 = StageModule(in_channels=hidden_dim, hidden_dimension=hidden_dim * 2, layers=layers[1],
downscaling_factor=downscaling_factors[1], num_heads=heads[1], head_dim=head_dim,
window_size=window_size, relative_pos_embedding=relative_pos_embedding)
self.stage3 = StageModule(in_channels=hidden_dim * 2, hidden_dimension=hidden_dim * 4, layers=layers[2],
downscaling_factor=downscaling_factors[2], num_heads=heads[2], head_dim=head_dim,
window_size=window_size, relative_pos_embedding=relative_pos_embedding)
self.stage4 = StageModule(in_channels=hidden_dim * 4, hidden_dimension=hidden_dim * 8, layers=layers[3],
downscaling_factor=downscaling_factors[3], num_heads=heads[3], head_dim=head_dim,
window_size=window_size, relative_pos_embedding=relative_pos_embedding)
self.mlp_head = nn.Sequential(
nn.LayerNorm(hidden_dim * 8),
nn.Linear(hidden_dim * 8, num_classes)
)
def forward(self, img):
x = self.stage1(img)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = x.mean(dim=[2, 3])
return self.mlp_head(x)
def swin_t(hidden_dim=96, layers=(2, 2, 6, 2), heads=(3, 6, 12, 24), **kwargs):
return SwinTransformer(hidden_dim=hidden_dim, layers=layers, heads=heads, **kwargs)
def swin_s(hidden_dim=96, layers=(2, 2, 18, 2), heads=(3, 6, 12, 24), **kwargs):
return SwinTransformer(hidden_dim=hidden_dim, layers=layers, heads=heads, **kwargs)
def swin_b(hidden_dim=128, layers=(2, 2, 18, 2), heads=(4, 8, 16, 32), **kwargs):
return SwinTransformer(hidden_dim=hidden_dim, layers=layers, heads=heads, **kwargs)
def swin_l(hidden_dim=192, layers=(2, 2, 18, 2), heads=(6, 12, 24, 48), **kwargs):
return SwinTransformer(hidden_dim=hidden_dim, layers=layers, heads=heads, **kwargs)
글 잘 봤습니다, 감사합니다.