Virtual Memory: Issues of Implementation
Basic concepts
Large and contiguous address space, process protection, execution of process only partially residing in memory 등을 제공하기 위해 VM이라는 테크닉을 사용한다. 그러나 이 방법론의 구현에 완벽한 합의점이 없기에 machine dependent하고, OS의 입장에서 porting을 위해선 HAL등이 필요하다.
Main memory는 현재 진행중이 프로세스의 address space의 가장 자주 사용되고 있는 부분만을 담고 있으며, 나머지는 disk로 swapped out되어있는 것이 이상적인 형태이다. 이를 구현하기 위해 paging기법을 사용하고 있으며, Virtual Page Number(VPN)으로부터 Physical Frame Number(PFN)으로의 on the fly translation을 필요로 하는데, 이 translation 정보를 담고 있는 page table을 잘 구성하는 것이 포인트이다. Page table의 contents인 PTE는 VPN→PFN 의 translation뿐 아니라 valid, dirty, reference bit 및 protection bits를 제공하여 memory protection기법 또한 구성한다.
Page table entries
page table == collection of PTEs
최근 OS들은 PTE에 PFN을 포함하여 다양한 addtional bits를 넣어 address spave and page-level protection을 지원한다. 전형적인 PTE에 들어가는 정보들은 다음과 같다.
- the ID of page’s owner (ASID)
- VPN
- PFN
- a valid bit
- a reference bit
- a modify bit
- page-protection bits(is this page readable? writeable? executable?)
OS는 reference bit을 주기적으로 clear하고, replacement시 이 정보를 이용해 LRU를 흉내낸다(approximation한다). modify bit은 이 페이지를 swap disk로 write back해야 할지 disk operation없이 그냥 버리면 될지 결정해준다.
per process page table을 가진다면 위의 ASID같은 정보는 필요없을 것이다.
Translation Lookaside Buffers
translation을 위한 page table은 DRAM에 존재하는데, 매 instruction을 수행하기 위해 최소 1번 이상의 DRAM access 를 필요로 한다면, VM 기법은 performance 문제에 의해 구현이 불가능할 것이다. 이를 해결하기 위해 translation을 caching하는 buffer가 processor 내에 존재하고, 이를 TLB라 부른다. TLB는 VPN( +ASID) 을 받아 PFN을 내놓는데, 그 방법은 다른 캐시처럼 directed-map, set-associativity, fully-associativity가 모두 가능하지만, miss penalty가 무려 DRAM access이기 때문에 fully-associativity(아니더라도 high associativity)가 일반적이다. TLB miss의 경우, 불가피하게 main memory에 존재하는 page table walking 이 요구되며 page table entry에 valid한 translation이 존재하면 TLB를 채우게 되며, 이는 OS 또는 HW가 수행한다. 만약 해당하는 page frame이 disk로 swapped out되어 있다면, page fault가 발생하고 OS가 이를 해결하기 위한 ISR을 수행하여 page table 및 TLB를 채워 넣은 후 page fault를 일으킨 instruction을 재수행해야 한다.
Page Table Organization
TLB miss 가 발생했을 때, page table walking이 필요한데, 그 page table을 main memory상에서 어떻게 구성하냐에 따라 performance 및 memory usage에 다양한 영향을 미치게 된다. 그 구성엔 대표적으로 forward-mapped(or hierarchical page table) 와 inverse-mapped(or inverted page table)이 있다.
Hierarchical page tables
32bit machine에서 4KB page를 사용할 경우, 4MB의 contiguous and unmapped memory space가 per process로 필요하다. 따라서 OS들은 VPN을 잘라 여러 level page table로 구성하는데, 필요없는 virtual address space는 메모리 공간에 할당하지 않아도 되며, working set에 속하지 않는 page들은 page table자체를 구성하지 않아도 되기에 memory공간을 아낄 수 있다. Top-down traversal의 경우 이렇게 deallocated or paged out인 PTE를 필요로 하면 OS가 page fault를 일으켜 새로운 페이지를 할당하거나 디스크에서 swap-in하면 된다.
Top-down traversal
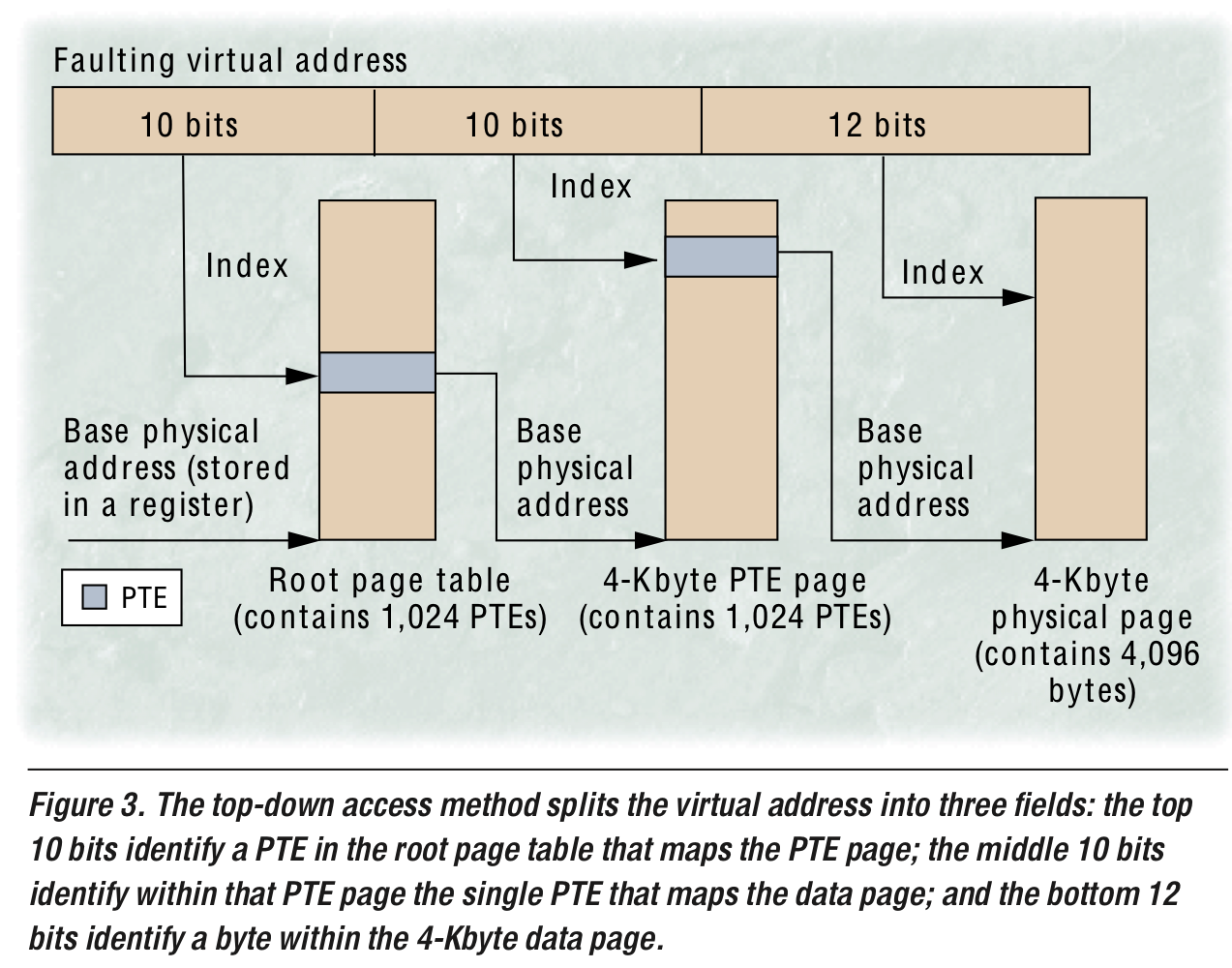
Bottom-up traversal
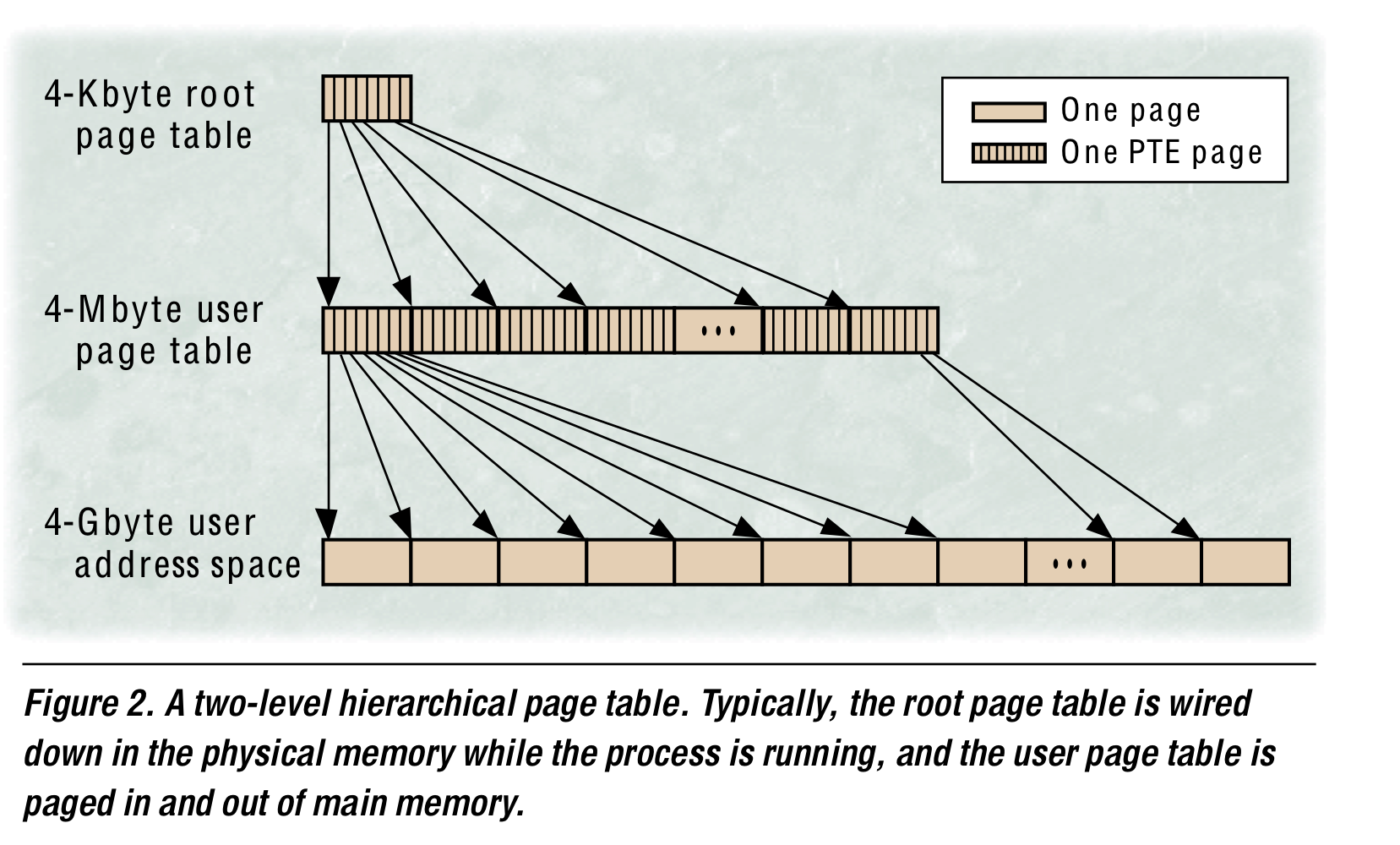
위의 top-down approach는 너무 많은 memory reference를 필요로 함을 확인하라. TLB가 page table walking을 하지 않게 잘 구성되거나 MMU cache가 recently accessed page directories들을 caching하는 방법도 존재하지만 MIPS는 bottom-up traversal이라는 방법을 사용했다. 어떻게 이 방법에서 one-shot에 translation을 해결하는지 확인해보자.
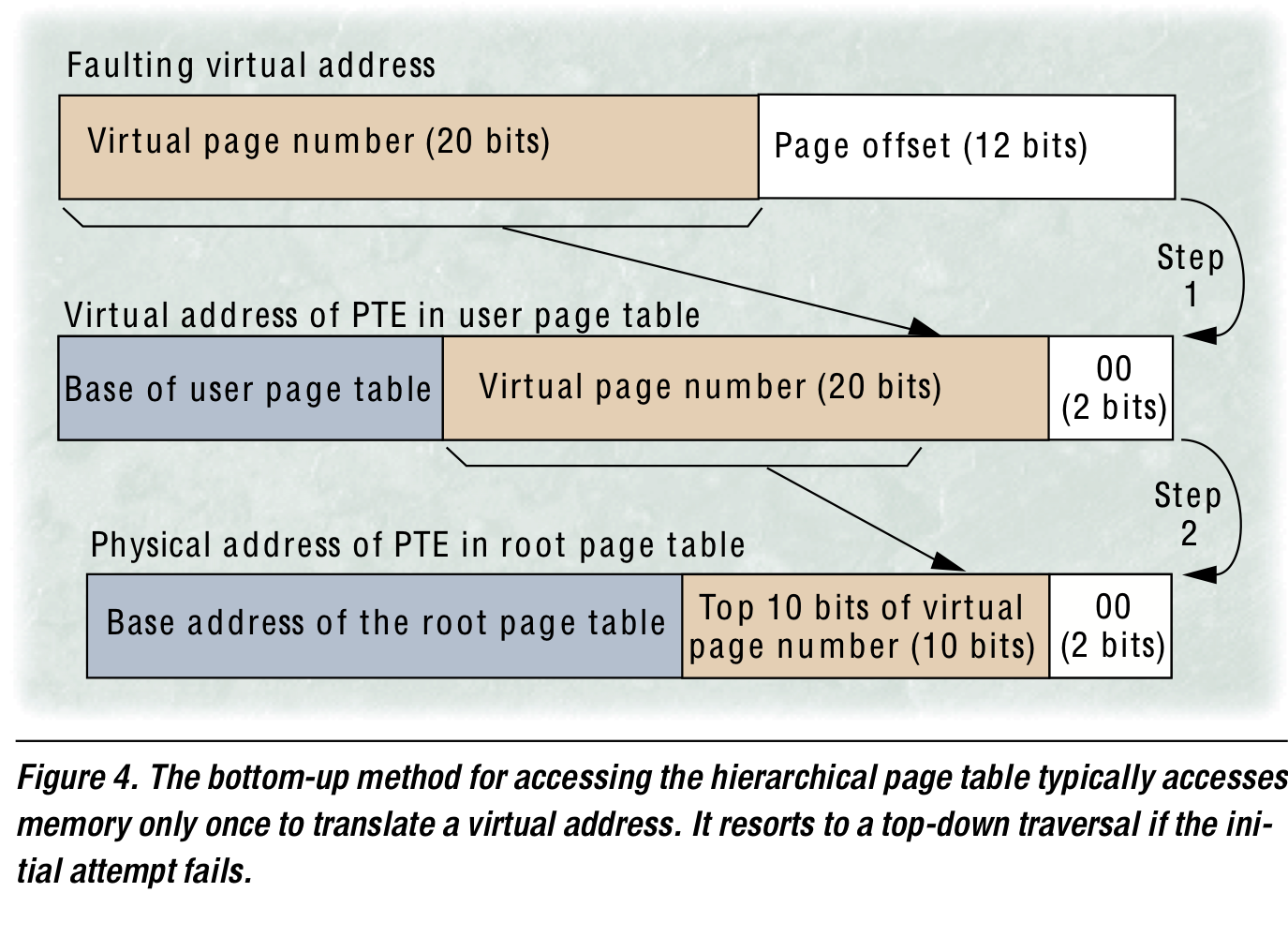
- user level TLB miss 발생 → 그 faulting VPN을 virtual address of PTE를 구성하는데 사용한다.
- Frequently, the OS will successfully load the PTE with this address → requiring only one memory reference to handle a TLB miss
- 만약 2번이 실패하면 위 그림의 step2에 해당하는 root page table을 위한 physical address를 구성하여 addtional memory reference를 진행한다.
아래는 이에 관한 pseudo code.
load user data /* load misses TLB */
/* invokes TLB-miss handler */
construct virtual address for user PTE
load user PTE /* load misses TLB */
/* invoke root TLB-miss handler */
construct physical address for root PTE
load root PTE /* cannot cause TLB miss,
because it uses a physical address */
put root PTE into TLB
jump to faulting instruction
/* return to user TLB-miss hanler */
load user PTE /* this time, load succeeds */
put user PTE into TLB
jump to faulting isntruction
/* return to user mode */
load user data /* this time, load succeeds */Inverted page tables
page table을 process별로 구성하여 VPN으로 indexing하는 기법 대신 physical memory의 frame개수에 비례하는 system-wide page table을 구성할 수 있다. VPN은 특정 hash function에 의해 hashing되어 hash anchor table을 indexing하고, 이 enrty에서 Inverted page table을 indexing하여 VPN과 비교한다. 비교 결과, 일치하면 그 Inverted page table의 index가 PFN으로 이용되고 일치하지 않을 시 collision chaining 기법을 이용해 enrty가 제공하는 다른 index에서 같은 동작을 반복한다. 이를 통해 physical frame개수에 scale되는 page table을 구성할 수 있다.
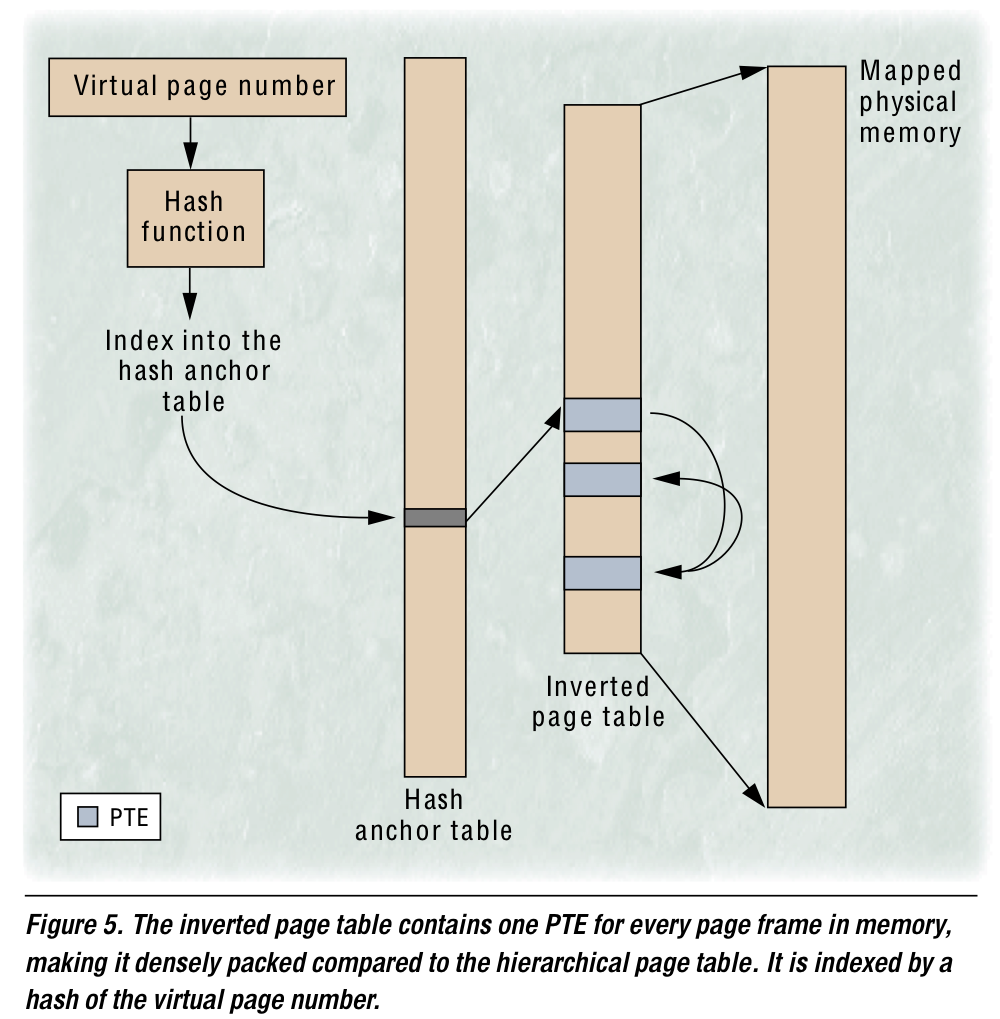
그러나 hierarchical과 비교했을 때, 이 방법엔 upper bound가 없기에 worst-case access time이 더욱 길어질 수 있다는 점을 유의해야 한다.
이 방법이 inverted라고 불리는 이유는 PTE의 index가 VPN이 아니라 PFN이기 때문이다. 그러나 PFN을 찾기 위한 translation이기에 PFN을 search를 위해 사용하진 못하고, VPN을 기반으로 hashing하는 방법을 이용한다. 위의 그림에서와 같이 다른 VPN이 collision을 발생시킬 수 있으므로 collision-chaining과 같은 방법을 사용해야 한다. table의 entry 마지막에 pointer를 다는 등으로 해야하는데 한 TLB miss를 서비스하기 위해 몇번의 hopping이 필요할진 알 수 없어진다…
너무 많은 hopping을 피하기 위해 hash value range를 naive하게 넓히자면 page table index를 PFN으로 활용하지 못하고 PFN을 삽입하기 위해 entry size가 커져야만 한다. 이미 pointer(collision-chains)를 위해 한 entry의 크기가 크다는 것도 유의하라! 이 문제를 다루기 위해 연구진들은 HAT(hash anchor table)을 중간에 끼워넣게 된다. HAT를 2배로 키우는 것은 inverted page table의 변화 없이 average collision chain length를 반으로 줄였다. HAT의 엔트리 크기는 page table의 그것보다 작기에 더욱 쉽게(memory efficient하게) size를 늘일 수 있다.
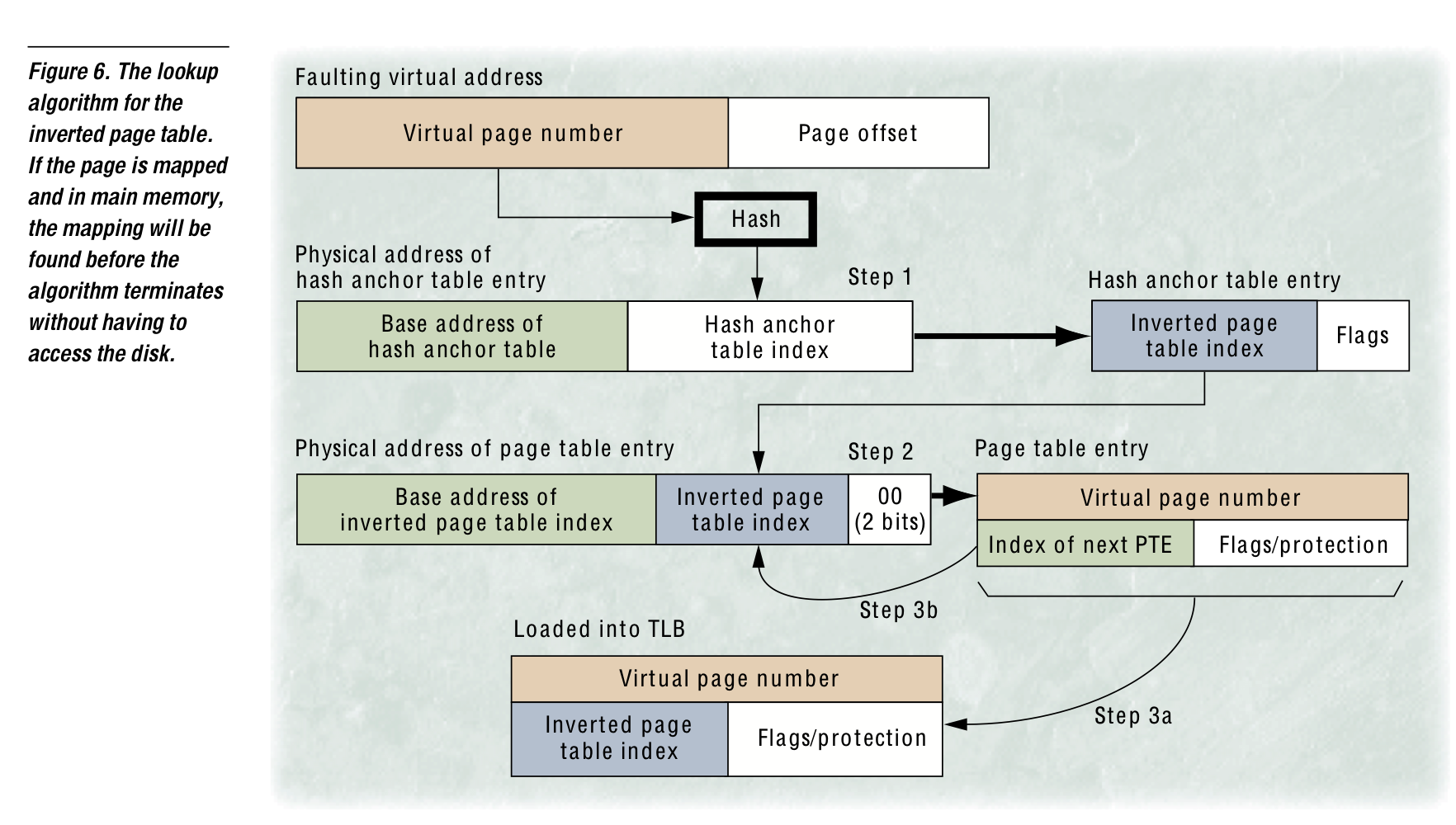
Large hash anchor table ⇒ average memory reference를 2로 줄일 수 있음. 이를 더욱 최적화하기 위해, PowerPC나 PA-RISC의 경우 HAT를 없애고 inverted page table에 직접 접근하도록 하였다. inverted page table사이즈를 키우고, 이젠 index를 PFN그자체로 사용할 수 없기에 PTE의 사이즈를 키워서 PFN을 넣어야만 한다. 이는 page table이 위로도 자라고 옆으로도 자라서 memory area를 더욱 먹지만(그래도 physical memory size에 비례한다는 점을 유의), minimun number of memory reference를 1로 줄인다.!
inverted page table이 정확히 physical frame 만큼의 enrty를 가져야만 했던 제한이 사라지고 OS나 designer가 collision-chain length를 줄일 수 있는 선에서 그 사이즈를 선택할 수 있게 된다. (commercial solution 에서는 보통 physical frame 개수의 2-3배로 잡는다. e.g. PowerPC)
Details
위와 같은 기법들은, memory usage와 performance에서 trade-off가 존재한다.
