In this post, I will cover about the pipe-lined structure. If we use the pipeline, we can imporve the performance in our computer architecture.

For example, if we use the multi clock cycle unit, we have to take many time to excute all of the tasks.
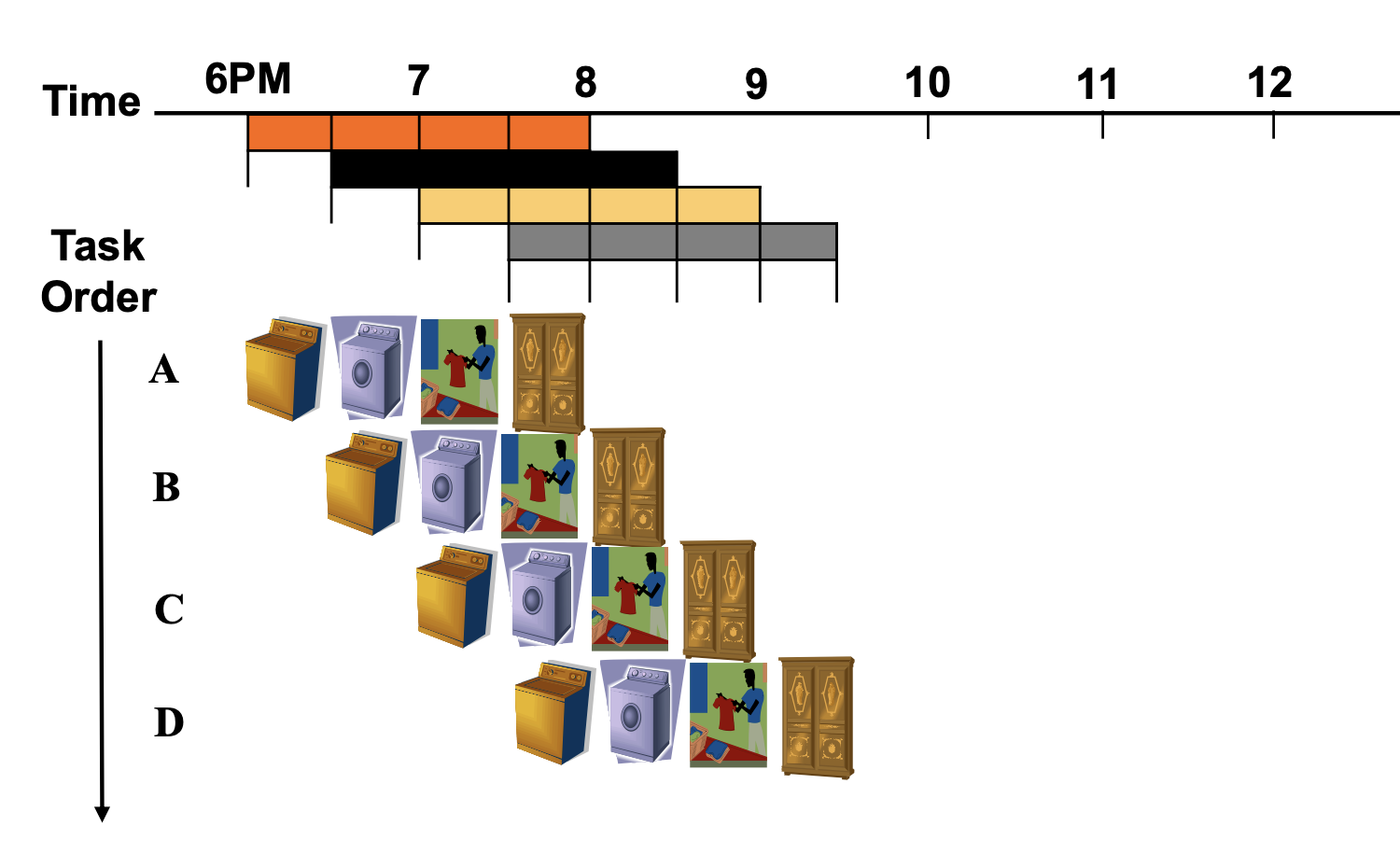
However, if we use the pipeline, we just use 7 clock cycles. So, in this architecture, we can save our time to excute.
Pipelineing doesn't help latency of single task. It helps throughput of entire workload. In the pipelining, multiple tasks operating simultaneously using different resources. It means that we have to cover about the problem of Structure Hazard.
The potential speedup is similar with the number of the pipelining stages.
Speed up
Suppose that we have n jobs to excute and each of them take T seconds. If we don't use pipelining, we have to spend Ts = n * T times. However, suppose that we have k stages, then each stage have to take T / k seconds. So, the total execution time is TP = (n+k-1) * T/k.
So, the total speedup Sp = Ts / Tp = (n*k) / (n+k-1).
Basic Steps of Execution
- Instruction Fetch Step (IF)
- Instruction Decode / Register Fetch Stdp (ID)
- Execution / Effective Address Step (EX)
- Memory Access (MEM)
- Register Write-Back Step (WB)
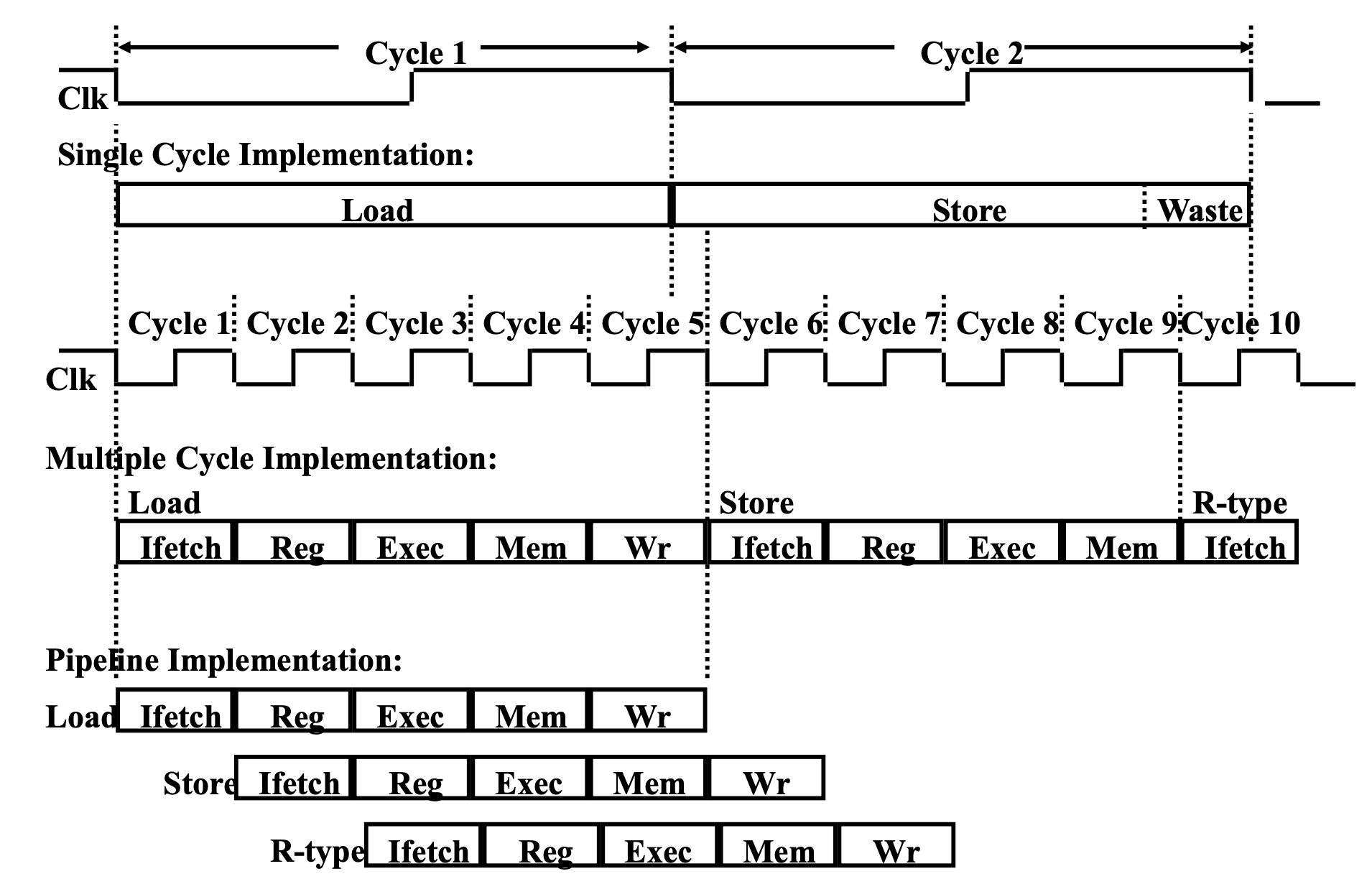
This is the summary picture of the Single, Multi, Pipelining structure.
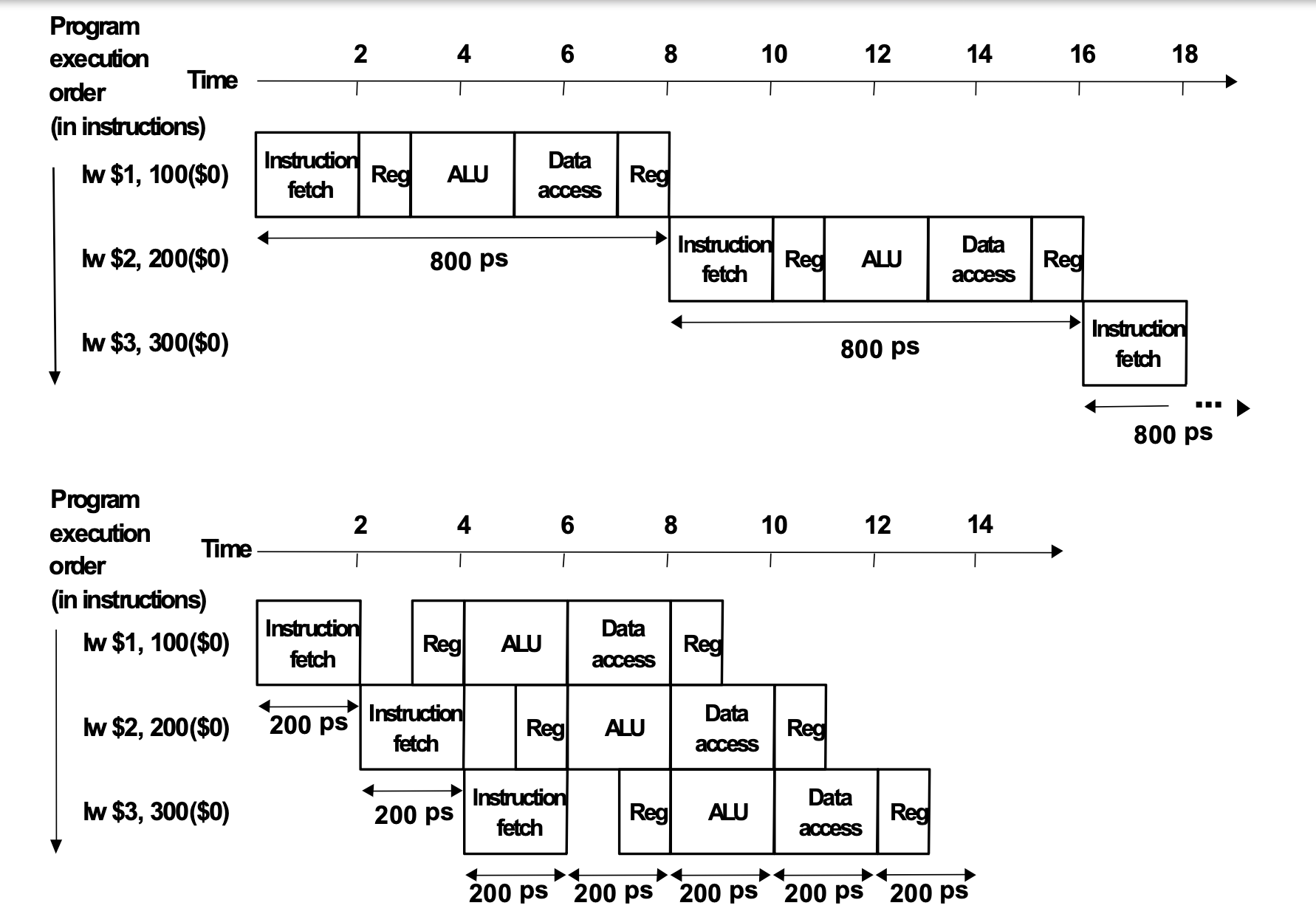
This is the structure of the multi clock cycle unit and pipelining unit.
Pros and Cons

First, we have to make all instructions are the same length. In addition, we jsut have a few instruction formats. Also, the memory operands appear only in loads and stores.
There are 3 difficult points. We have to deal about the Structure Hazards, Data Hazards, and Control Hazards.
Structure
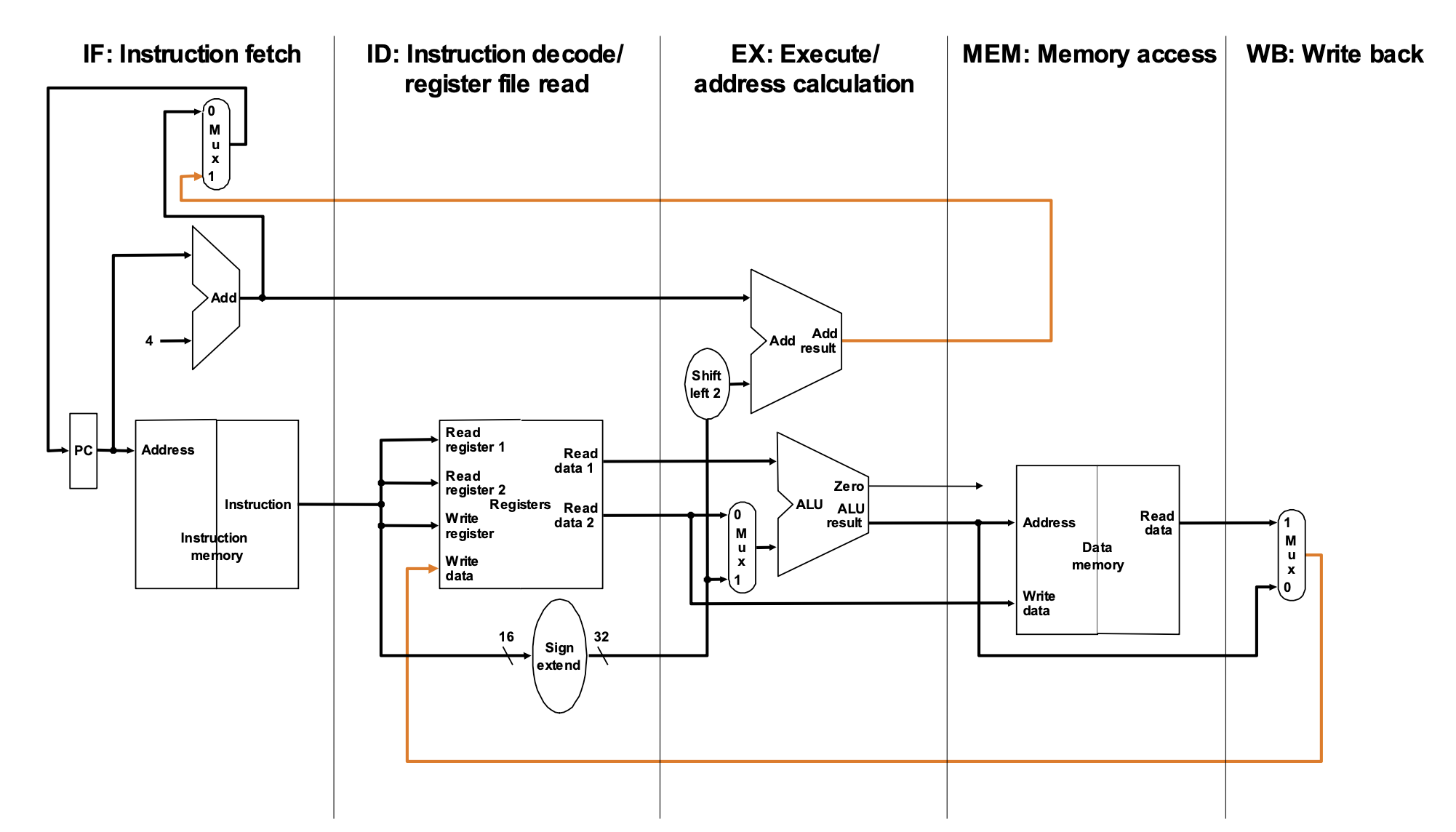
In this structure, there are 5 stages. In the pipelining unit, we have to recieve new instructions every clock cycles. So, in this section, we must keep the control signal that occured in the stage 2. In addition, we have to divide two memories. First is Instruction Memory, second is Data Memory. Because if we make one memory to use fetch and load, then we have to take two actions in one clock cycle. It means that it can make conflicts.
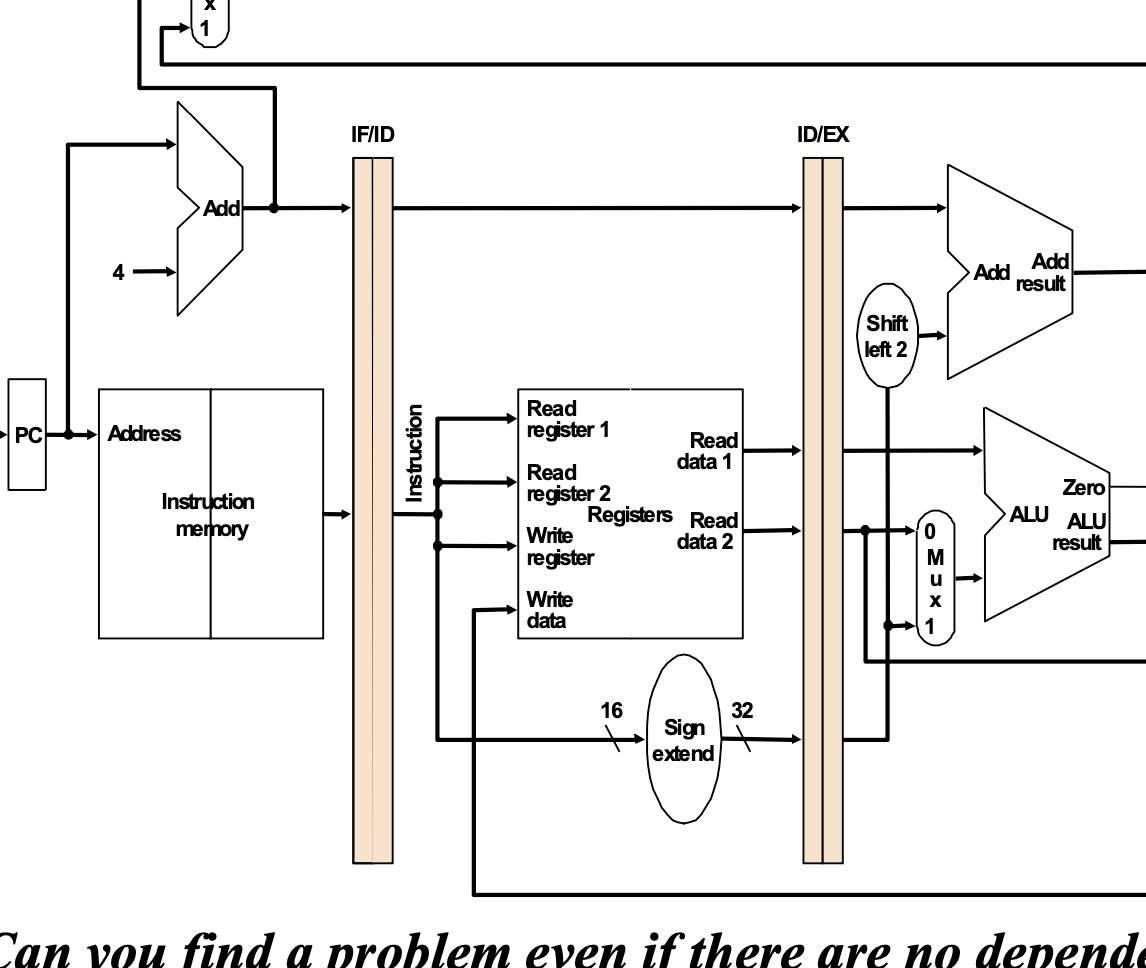
So, we have to make new control signals in stage 2 at every clock cycles, there must be some registers to keep the information instruction needs.
In our structure of the pipeline, we have 5 stages to execute instructions. Then, we should know about the control signal that each stage needs.
1. Instruction Fetch and PC Increment
-> All of the instruction must executed, so there are no specific control signals.
2. Instruction Decode / Register File Read
-> This stage just decodes the instruction. So, there are no specific control signals.
3. Execution
-> In the stage 3, we have to execute ALU Logic and branch instrucion. So, we have to use RegDst, ALUOp, ALUSrc control signal.
4. Memory Stage
-> In this stage, we should execute branch, and memory actions. Therefore, Branch, MemRead, MemWrite are needed.
How to deliver control signal?
In the pipelining unit, every stages need differet control signals. So, we will pass the control signals to next stage.
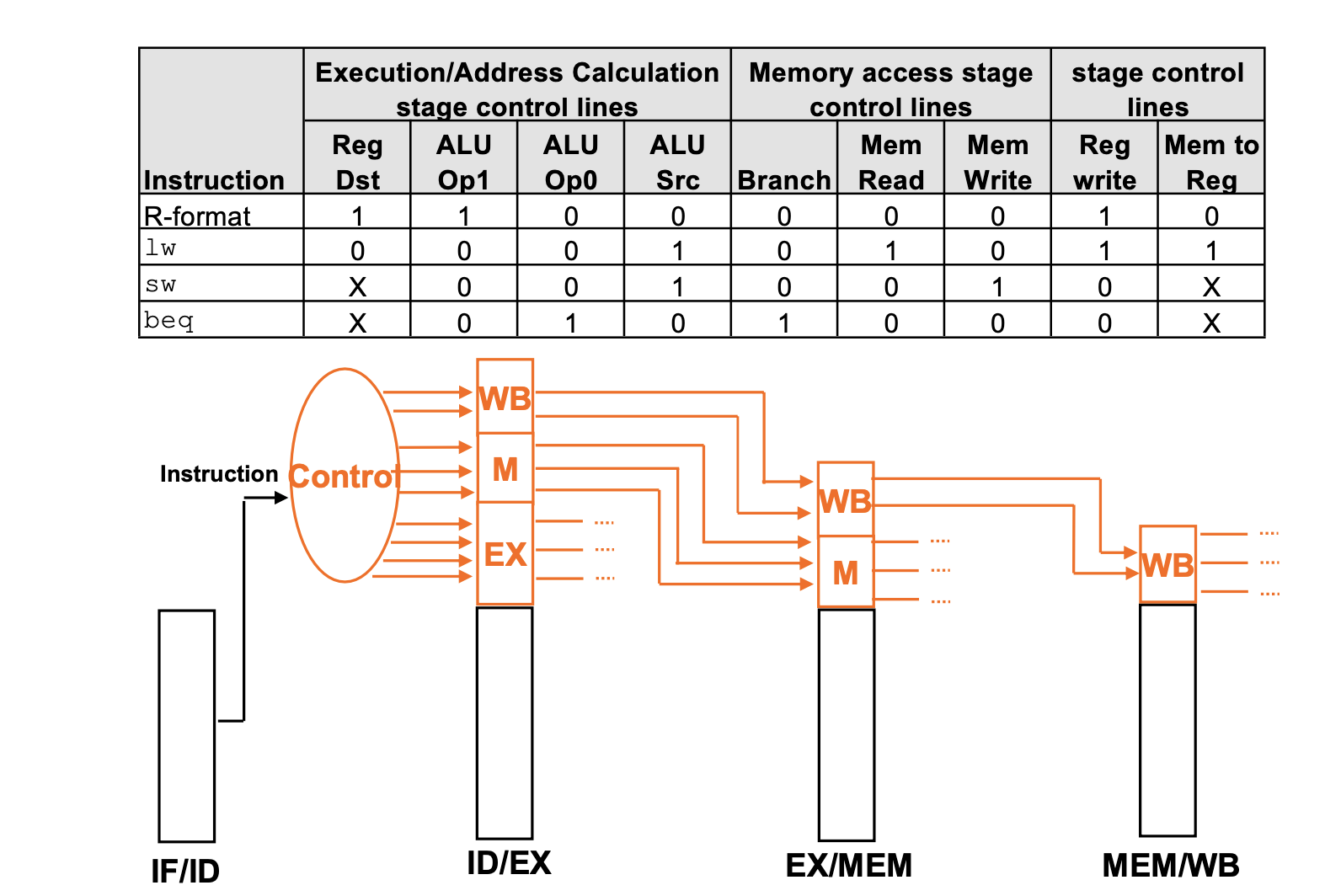
In this picture, we can see that our control signals are passed to next stage.
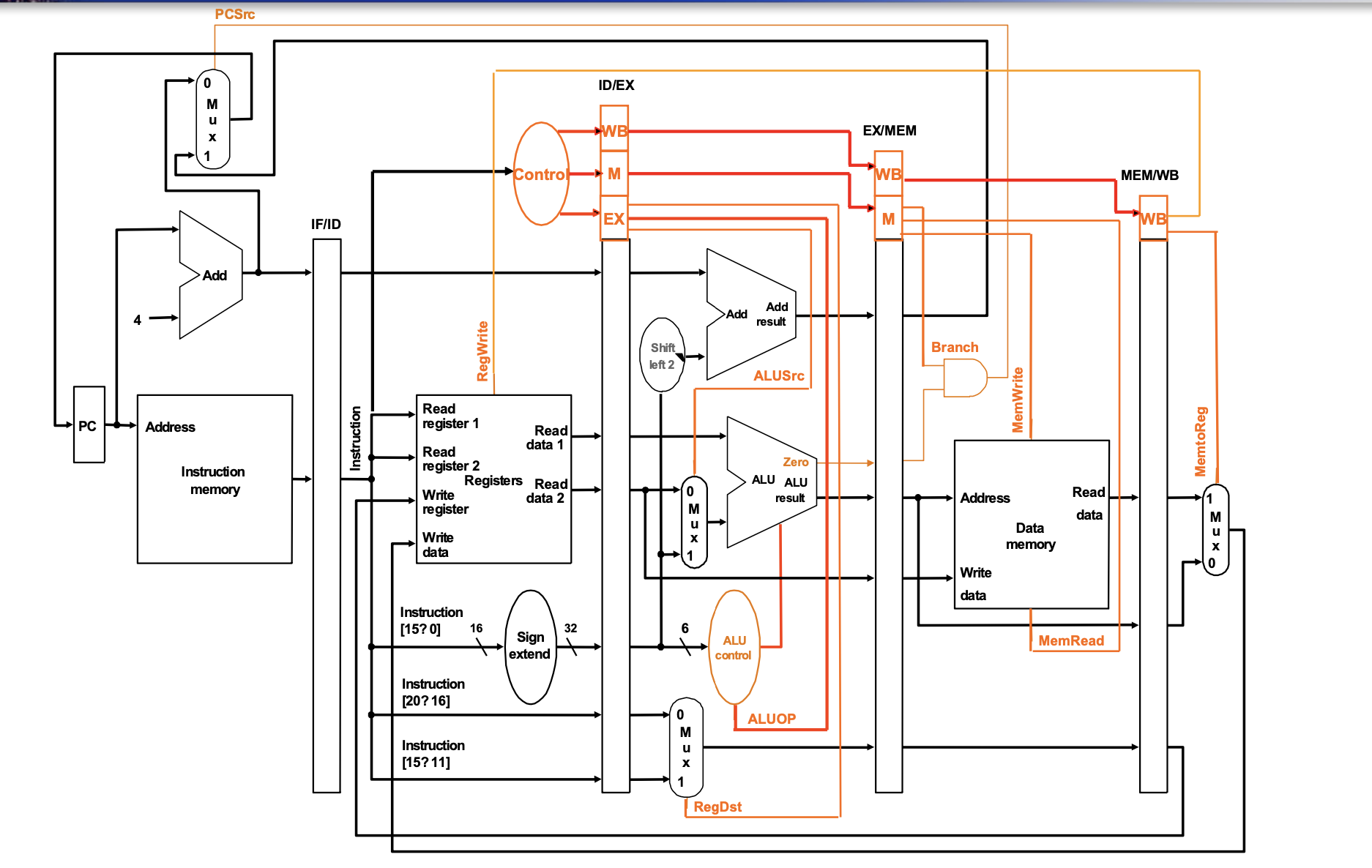
This is the full architecture about the pipelining unit.
Summary
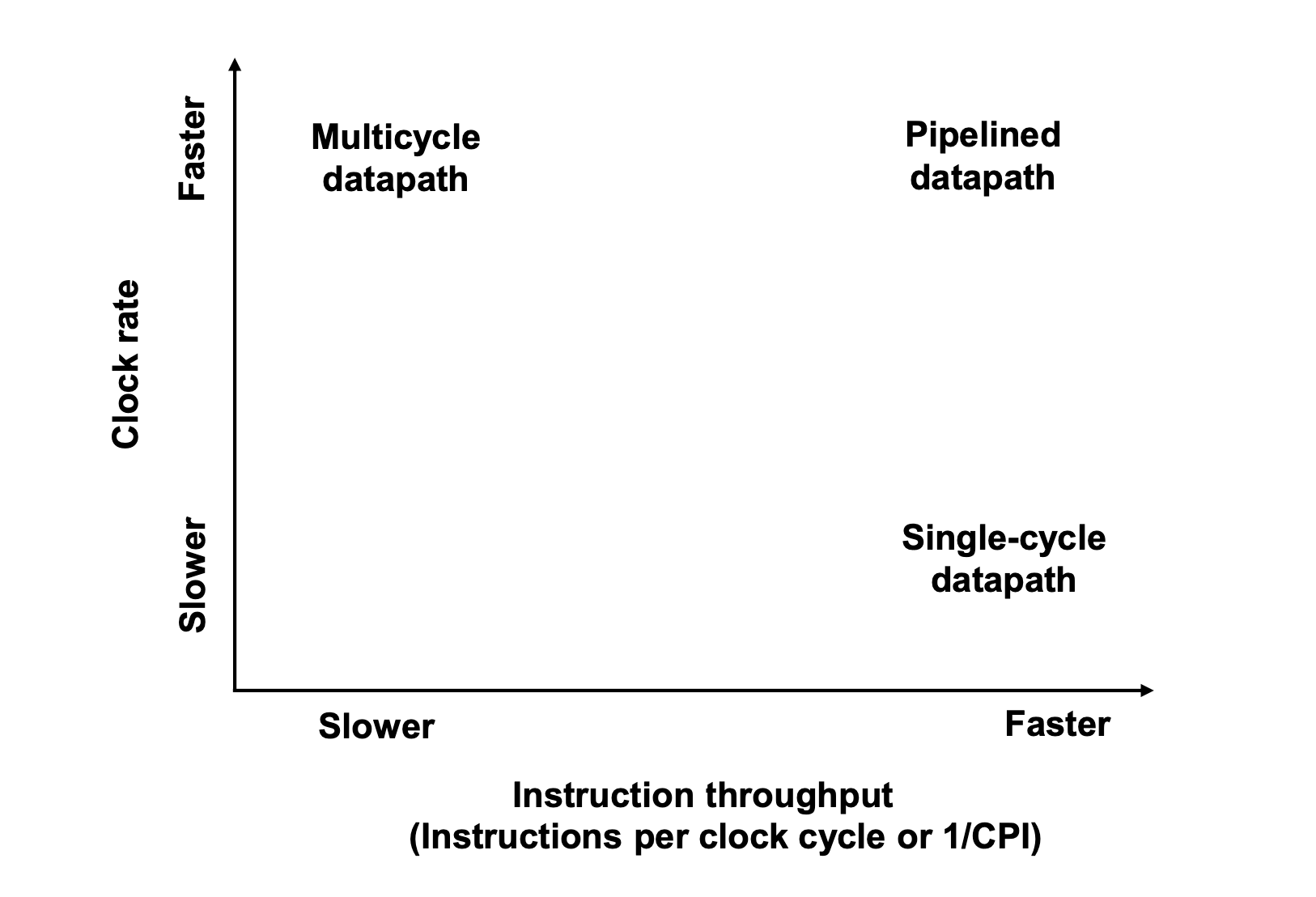
We already know about the characteristc about the Single, Multi, and Pipelining.
In the Single-cycle datapath and Pipelined datapath, instructions are executed at every clock cycles. On the other hand, Multicycle datapath is excuted a instruction at some clock cycles.
However, Multi-cycle datapath and Pipelined datapath are executed several clock cycles. But the Single-cycle datapath is executed long clock rate.
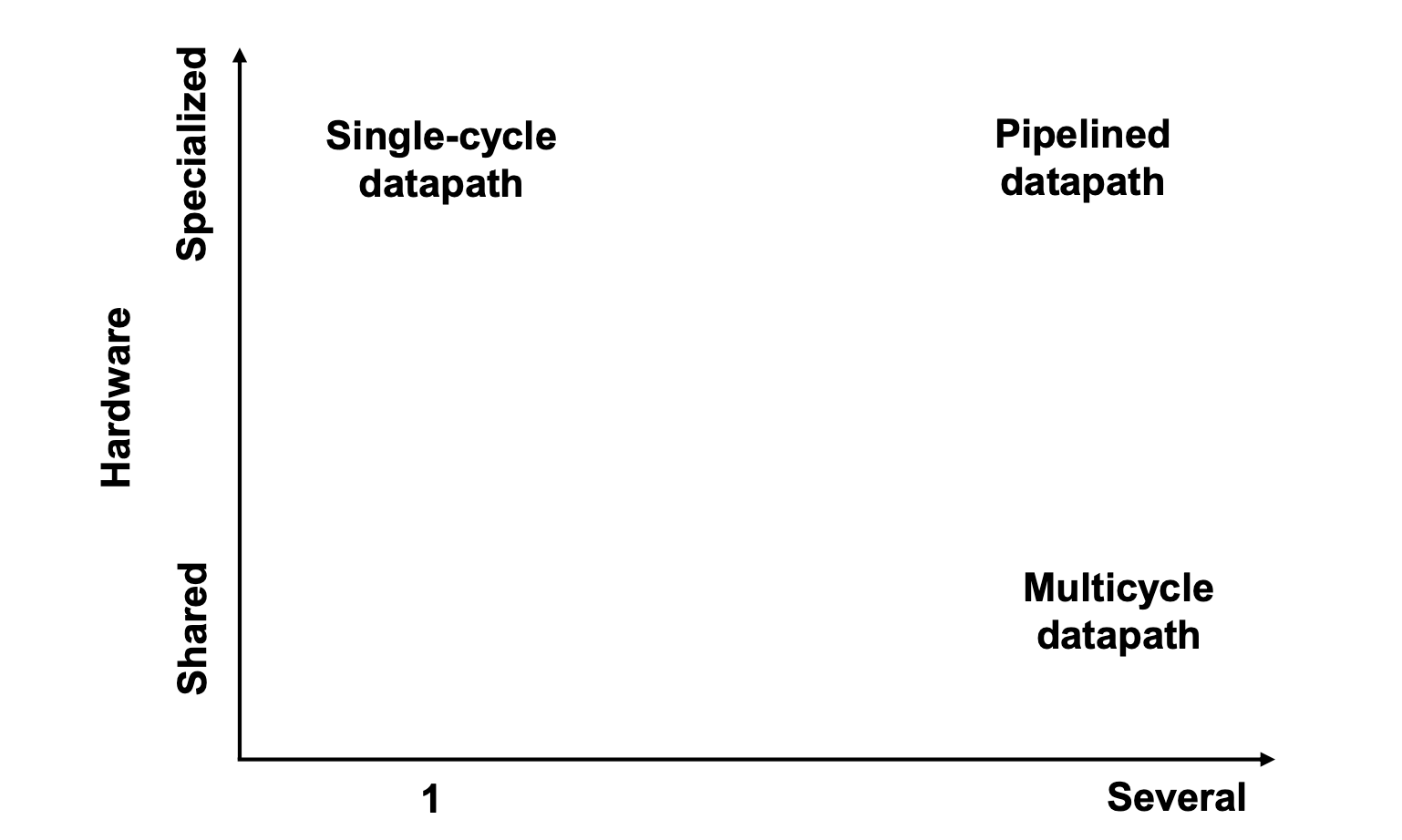
In addition, Single-cycle datapath and Pipelined datapath have some special hardware architecture because they cover the structure hazard.
However, if we use Multi-cycle datapath, then we can reuse same units like ALU, ADDER.
